1. Understanding Model
🤔 어떻게 모델은 그러한 복잡한 data들을 다 이해하는 것일까?
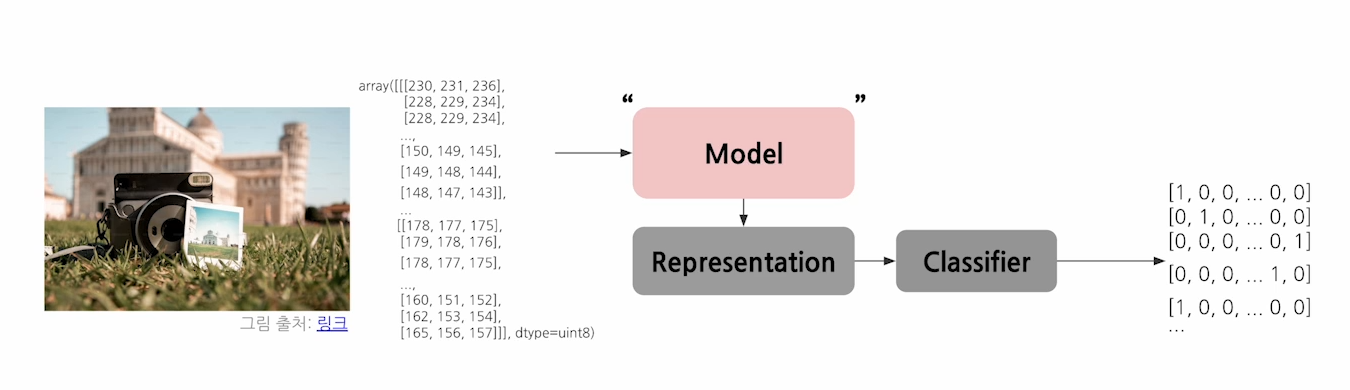
1.1 Model
Model is an informative representation of an object, person, or system
1.2 Inductive Bias
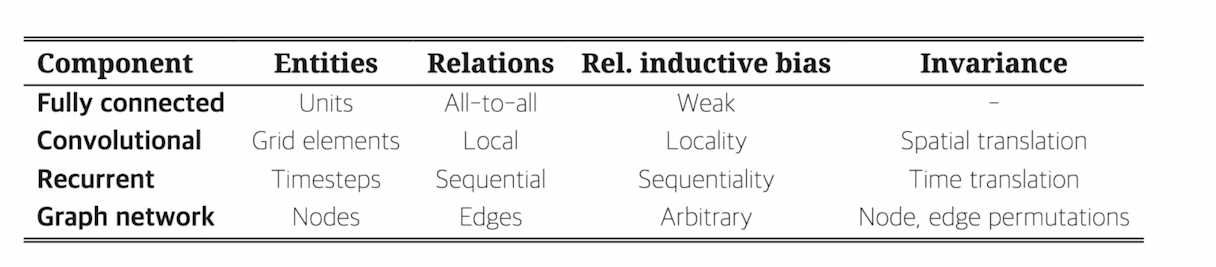
Inductive Bias 란, 모델 학습과정에서 특정 유형의 패턴을 잘 학습하도록 하는 사전 가정(지식)
-
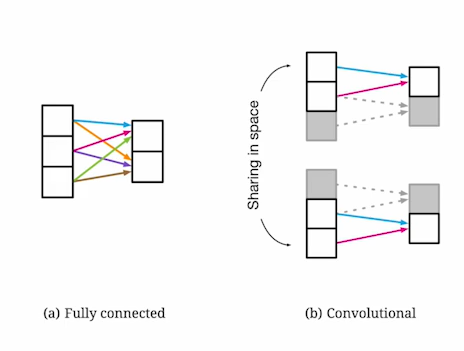
CNN
-> Locality & Translation Invariacne : 이미지의 어디서든 나타나는 지역패턴에 집중
-> Hierarchical Feature Learning : 단순한 특징에서 복잡한 특징으로 학습
-> Weight Sharing : 동일한 필터를 이미지 전체에 적용
🤔CNN은 무조건 이미지 표현에만 쓰인다? -> 거짓(False)
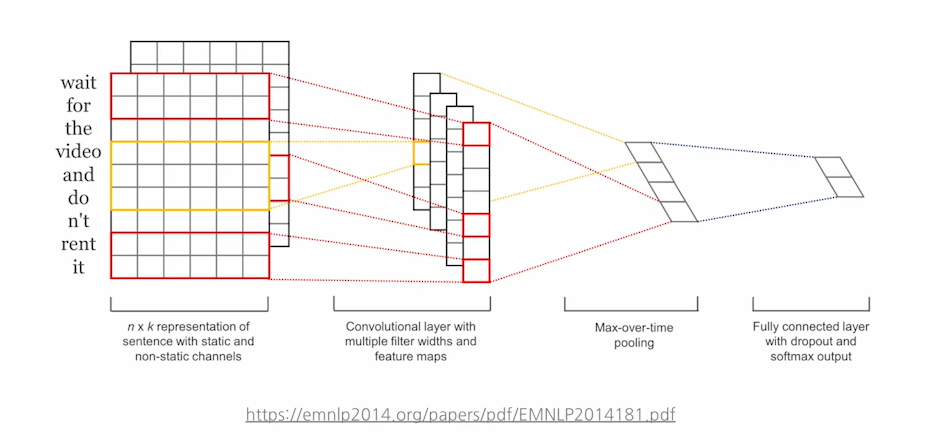
NLP에서 CNN은, 커널의 크기에 따라 텍스트를 N-gram 단위로 처리. text를 이해하는 과정이랑 비슷.
-
Transformers
-> Long-Range Dependeneis : 먼 거리의 관계 포착
-> Flexible Input Handling : 다양한 입력 크기를 처리
-> Self-Attention : 입력 부분의 중요도를 동적으로 가중.
🤔 문제를 해결하기 위해 데이터를 어떠한 방식으로 바라보아야 하는가?
👉 주어진 데이터를 사용하여 문제 해결에 가장 걸 맞는 Representation을 낼 수 있는 모델 가정
-> Inductive Bias는 모델이 어떤 관점에서 데이터를 보려고 하는가를 설명하는 것.
2. CNN vs Transformer
2.1 CNN
① 고전적 모델
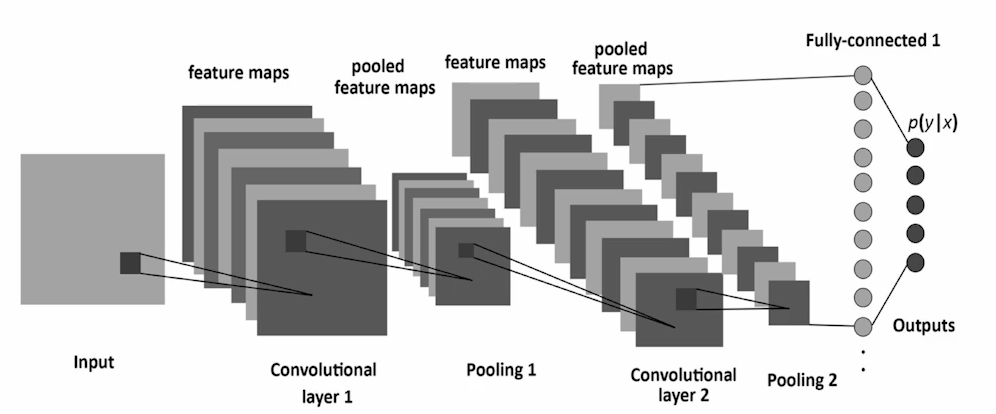
- Grid 형태의 데이터를 처리하도록 설계
- Convolutional layer, pooling layer, fully connected layer 로 구성됨
- 시각적 특징의 계층적 표현을 학습.
-> 커널이라는 부분이 이미지를 스캔하면서 결과를 바탕으로 특징을 만들어내고, 계층적 층으로 의미론적인 것을 뽑아낼려고 한다.
② 최근 CNN_ConvNeXt(2022)
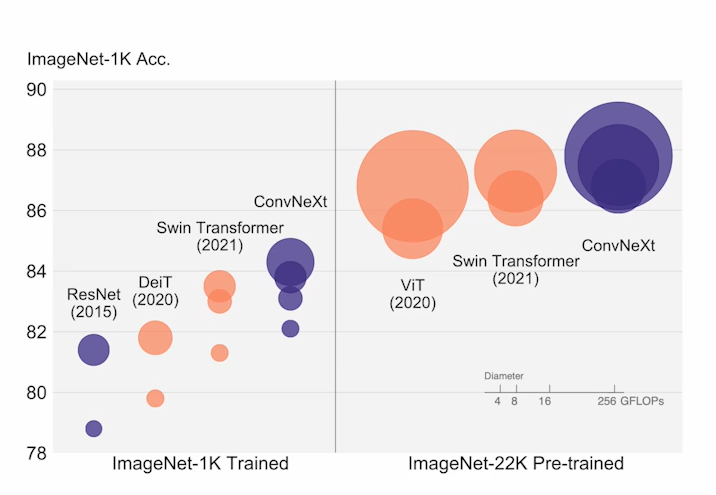
- Transformer도 좋지만 CNN도 명확히 장점이 있기때문에 CNN계열 모델 디자인을 재설계하여 성능을 극한으로 끌어올릴려고 함.
- ConvNet의 단순성과 효율성 유지
ConvNeXt의 Architecture
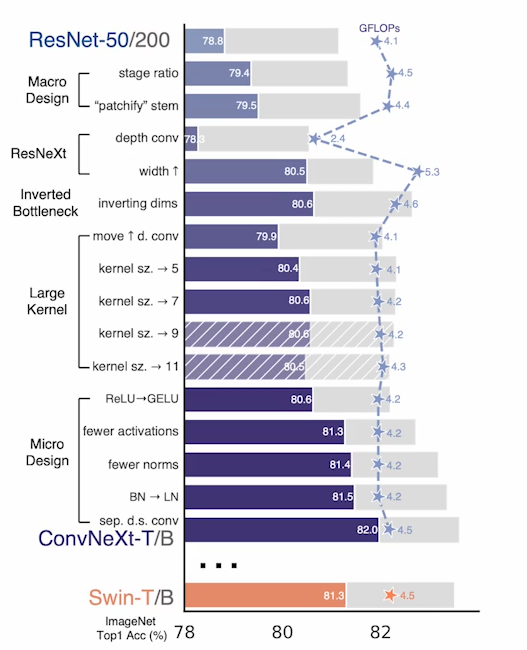
● KeyInnovation
- Macro디자인:ResNeXt-ify,inverted bottleneck,Large kernel size
- Micro디자인:GELU,Layer Normalization(LN)
● 아키텍쳐 설계 선택
- Depthwise Convolutional 과 Inverted bottlenect
- 더 넓은 수용영역을 포착하기 위한 커널크기(7 x 7)
- 더 적은 활성화 함수와 LN
2.2 Transformer
NLP에서 나온 혁신적인 논문. Attention is all you need
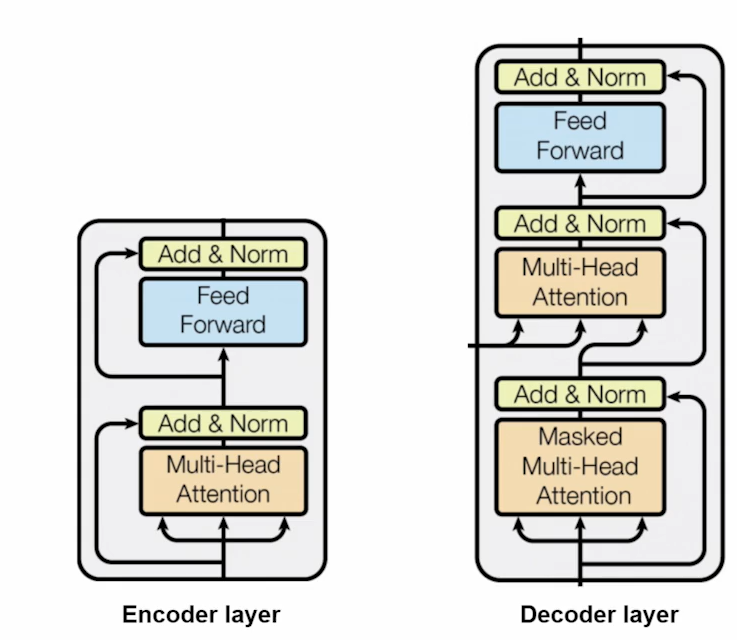
Visoin 에서 Transformer 사용_viT
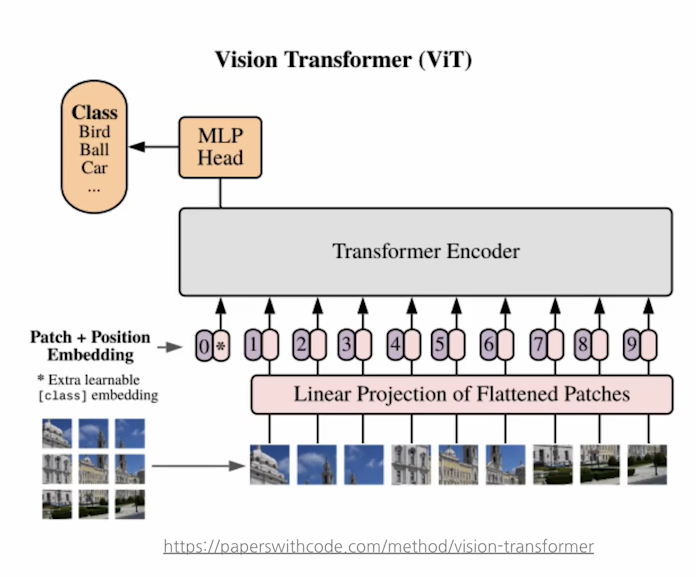
- 이미지를 패치로 분할하고 토큰 시퀀스로 처리.
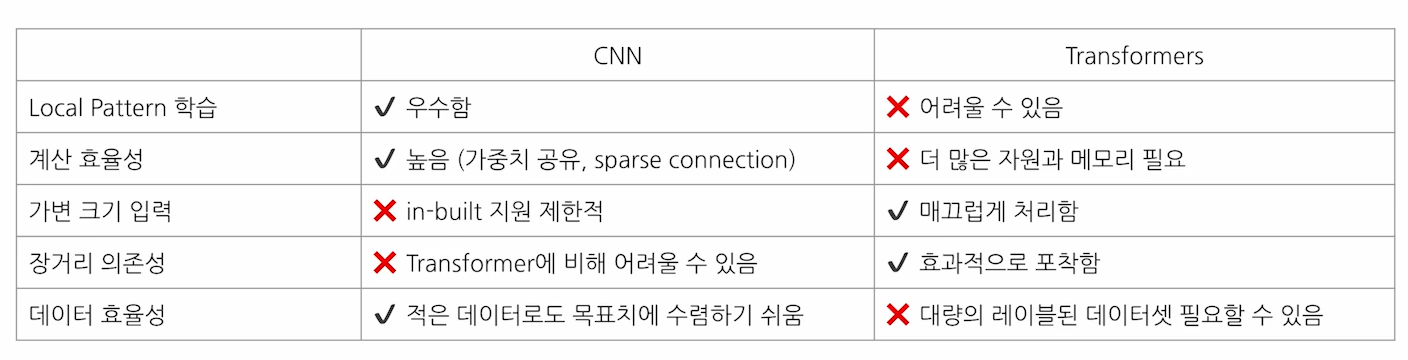
2.3 CNN 과 Transformer 장단점
2.4 Hybrid Models
CoAtNet: A Hybrid Architecture

- Depthwise Convolution 과 self-attention 의 결합
초기에는, convolution layer를 통해 지역정보를 빨리 파악하고
후기에는, 의미를 파악할 수 있는 복잡성을 이해할 수 있는 attention 으로 이해를 하자고 하는 것임. - Relative Attention을 사용하여 Depthwise conv를 attn layer에 병합
- s-stage설계: C-C-T-T레이아웃
- MBConv 블록에서 squeeze and Excitation layer사용
🤔 MBConv? Squueze and Excitation?
👉
- MBConv 블록: MobileNetV2와 같은 경량화된 신경망에서 사용하는 블록으로, Depthwise Convolution과 Linear Bottleneck을 특징
- Squeeze and Excitation (SE) Layer: 채널 간의 중요성을 학습하여, 더 중요한 채널에 더 많은 가중치를 부여하는 메커니즘. SE Layer는 먼저 채널의 정보를 압축(squeeze)한 뒤, 각 채널의 중요도를 계산하고 이를 바탕으로 각 채널의 출력을 조정(excitation)합니다.
2.5 그외 Hybrid Architecture
- ConViT : CNN에서 Gated Positional self-attention
- CvT : Conv token embedding 과 projection layers
- LocalViT : Transformer FFN 에서 Depthwise conv.
3. 참고자료
-
A ConvNet for the 2020s
https://arxiv.org/abs/2201.03545 -
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
https://arxiv.org/abs/2010.11929 -
CoAtNet: Marrying Convolution and Attention for All Data Sizes
https://arxiv.org/abs/2106.04803 -
ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases
https://arxiv.org/abs/2103.10697 -
CNN for NLP
https://emnlp2014.org/papers/pdf/EMNLP2014181.pdf
