0. Intro
Representation은 같은 대상이라도 상황에 따라, 관점에 따라 의미가 바뀌기도 한다.

같은 이미지의 고양이라도 표현은 모두 다르다.
1. Understanding Representation
1.1 Representation
Representation이란 데이터를 모델이 어떤 관점에 따라 이해하고 처리할 수 있는 형태로 변환된 것
👉 데이터를 어떤 관점에서 보고자 하는지에 따라 데이터에 기대할 Representation 이 결정될 수 있다.
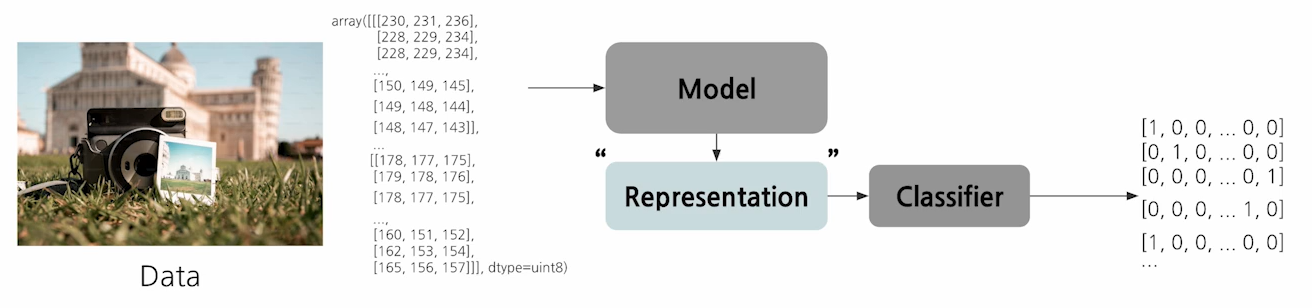
같은 이미지라도 어떤 개체가 가질 수 있는 의미는 매우 다양하다.
1.2 Representation Learning
데이터로부터 유의미한 Representation을 자동으로 학습할 수 있도록
- Feature Extraction : Raw 데이터에서 중요한 특징을 식별하고 인코딩하는 것.
- Generalization : 보편적인 패턴을 포착하여 보지 못한 데이터에서도 잘 수행할 수 있는 능력
- Data Efficiency : 효과적인 특징 학습을 통해 대구모 주석 데이터셋의 필요성을 줄이는 것.
1.3 Representation Vs Inductive Bias
- Representation은 데이터의 형식에 관한 것이고, Inductive Bias는 모델이 데이터를 해석하고 학습하는 방식에 대한 가정
- Representation은 주어진 데이터를 더 잘 이해할 수 있도록 형태를 바꾸는 것이고, Inductive Bias는 주어진 데이터에서 어떤 패턴을 학습할지 유도하는 선호를 설정하는 것
2. Representation Learning 활용
2.1 General Supervised Learning
일반적인 Supervised Learning 도 자체적으로 Representation 을 만들어 낸다.
2.2 Transfer Learning
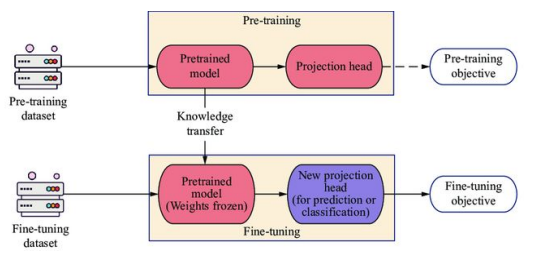
- 한 task/domain 에서 사전 학습된 모델을 다른 task/domain에 적용함.
- 특히 Target 데이터가 제한적일 때 유용
- Source Task에서 훈련 후 Target task에서 가중치 고정 또는 고정없이 전체 모델 Fine-tuning
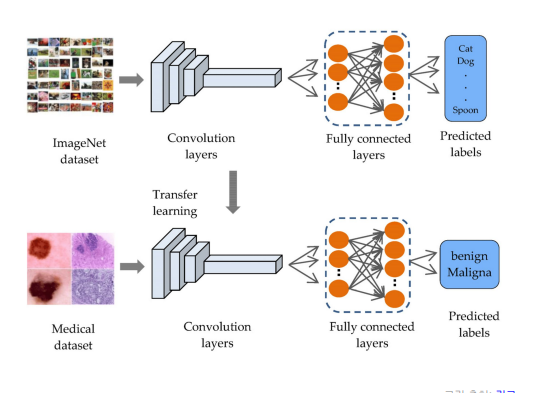
👉 위 이미지에서 처럼 대규모 학습데이터 ImageNet dataset에서 학습한 Pre-trained 모델을 다른 Medical dataset에서 그대로 적용하여 predict한다.
2.3 Self-Supervised Learning
Self-supervised learning이란, Label 이 없는 데이터에서 Representation 학습
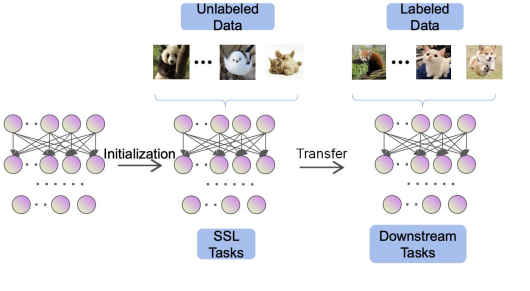
Contrastive learning
- Positive Pairs
-> 같은 이미지의 Augmentation 버전 - Negative Pairs
-> 다른 이미지의 Augmentation 버전
👉 Contrastive Loss 는 Positive를 모으고 Negative를 밀어냄.
2.4 Multimodal Learning
Multimodal learninig이란, 여러가지 modality 에서 정보를 결합.
-> 어떤 Image가 의미하는 Image의 특성으로도 확인할 수 있는 정보를 이를 Representation 할 수 있는 다른 모달로부터도 얻을 수 있다.
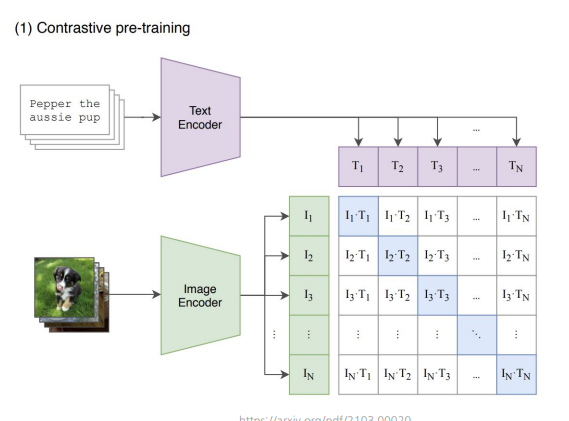
CLIP이라는 모델인데, 시각적 및 언어적 표현을 jointly 하게 학습하며 이미지와 해당 텍스트 정렬.
이미지와 text의 representation 의 통계적 언어모델까지도 학습.
example)
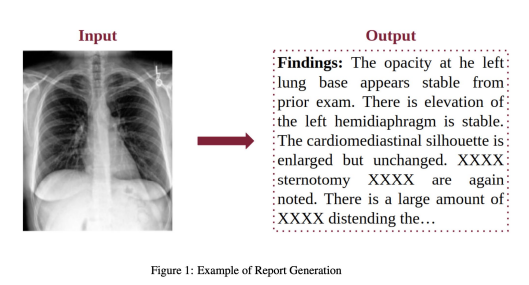
-> 이미지를 주었을때 output으로 나오게 함.
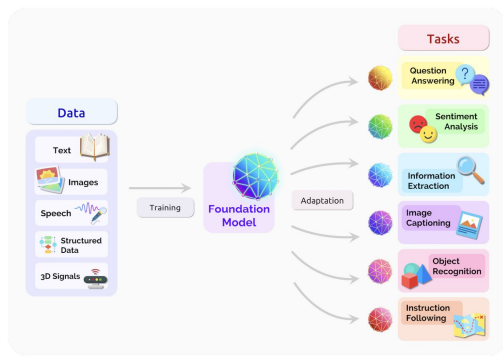
2.5 Foundation Model
Foundation Model is any model that is trained on brad data that can be adapted to a wide range of downstream tasks
-> 엄청 다양하고 massive 데이터로 학습을 하고, 여러가지로 표현할 수 있는 모델.(엄청 범용적인 모델.)
Foundation model 의 학습 패러다임
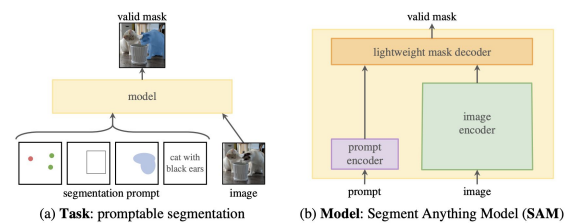
- 광범위 하고 방대한 데이터셋에서 사전 학습
- Prompting 또는 Fine -Tuning을 통해 downstrem task에 적용.
3. 참고자료
-
Multimodal Learning with Transformers: A Survey
https://arxiv.org/abs/2206.06488 -
Self-supervised Learning: Generative or Contrastive
https://arxiv.org/abs/2006.08218
