1. Data Process 최적화
1.1 Data 캐싱
데이터 캐싱은 빈번하게 사용하는 데이터를 더욱 효율적으로 재사용할 수 있도록, 반복적인 작업을 미리 처리하고 별도의 데이터로 저장하거나 메모리에 일시적으로 저장해두는 과정.
-> 즉, 반복적인 과정을 미리 처리해서 전체적인 데이터 처리 속도 증가.
1.2 Data 캐싱전
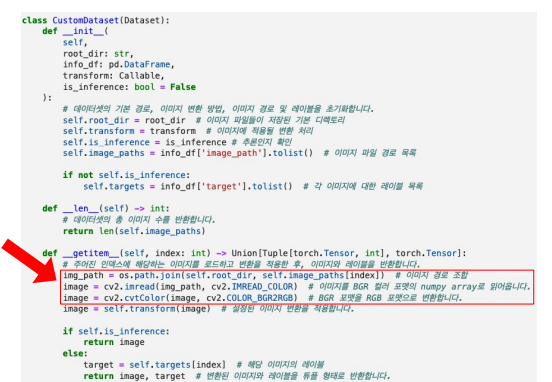
- 빨간색 부분이 매번의 Epoch 마다 동일한 이미지 File을 vector화한다. -> 이는 시간이 많이 걸림
👉 따라서 전체 이미지를 미리 vector 화 해서 npy 파일로 저장후 활용
1.2 Data 캐싱후
1.2.1 전체 이미지를 미리 vector화해서 npy 파일로 저장후 불러와서 사용.

preprocess_and_save_npy 함수를 통해서 npy 파일로 먼저 만들고 -> getitem을
2. Training 최적화
2.1 Gradient Accumulation
Gradient Accumulation이란,
- 여러 배치에서 계산된 gradient를 누적하여 업데이트 하는 기술
-> 각 배치 처리 후, gradient를 즉시 업데이트 하지 않고 누적
-> 지정된 수의 배치가 처리되고 나면 누적된 gradient를 사용하여 모델의 가중치 업데이트
def train_epoch(self, accumulation_steps = 4) ->float:
self.model.train()
total_loss = 0.0
progress_bar = tqdm(self.train_loader, desc = "Training", leave =False)
self.optimizer.zero_grad()
for i, (images,targets) in enumerate(progress_bar):
images, targets = images.to(self.device), targets.to(self.device)
outputs = self.model(images)
loss = self.loss_fn(outputs, targets)
loss = loss /accumulation_steps
loss.backward()
total_loss += loss.item()
#누적된 스텝이 충분히 쌓이면 옵티마이저 실행.
for (i +1)% accumulation_steps ==0 or (i+1) == len(self.train_loader):
self.optimizer.step()
self.optimizer.zero_grad()
self.scheduler.step()
progress_bar.set_postfix(loss =loss.item())
return total_loss / len(self.train_loader)2.2 Mixed- Precision Training
Mixed-precision을 하기전에 먼저 , FP32 FP16에 대해서 알아보자.
① Float 표현
FP32(Floating point 32)
- 1비트 부호(+,-), 8비트 지수(실수), 23비트 가수(정수)로 구성된 표준 부동소수점 형식
- 정밀도가 높음.
FP16(Floating Point 16)
- 1비트 부호(+,-), 5비트 지수(실수), 10비트 가수(정수)로 구성
- 속도와 메모리 효율성은 높지마 FP32보다 정밀도가 낮음.
bF16(brain Floating point)
- 1비트 부호(+,-), 8비트 지수(실수), 7비트 가수(정수)로 구성
- FP32와 동일한 8비트로 Float16형 보다 비교적 높은 정밀도
② FP32 vs FP16

-> FP16 더 효율적이고 빠르나, 정밀도 측면에서 떨어짐
👉 정밀도에서 큰 차이없이 사용하는 방법이 Mixed Precision
③ Mixed Precision Training
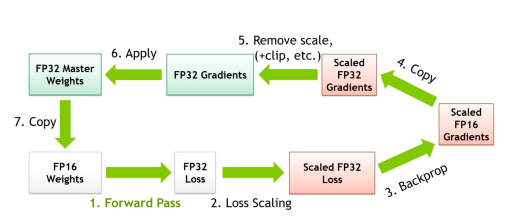
- 연산이 필요한 시점에서는 FP16
- 모델의 성능(Loss, Model weight update)와 관련된 연산에서는 FP32 로 다시 변환된 값을 사용하여 성능 보장.
Code
from torch.cuda.amp import autocast, GradScaler
def train_epoch(self) -> float:
self.model.train()
total_loss = 0.0
progress_bar = tqdm(self.train_loader, desc ="Training", leave =False)
scaler = GradScaler() #AMP를 위한 GradScaler
for images, targets in progress_bar:
images, targets = images.to(device), targets.to(device)
self.optimizer.zero_grad()
#autocast 컨텍스트 내에서 모델을 실행하여 정밀도 관리
with autocast():
outputs = self.model(images)
loss = self.loss_fn(outputs, targets)
#스케일링 된 손실을 사용하여 역전파 실행
scaler.scale(loss).backward()
scaler.step(self.optimizer)
scaler.update()
self.scheduler.step()
total_loss += loss.item()
progress_bar.set_postfix(loss =loss.item())
return total_loss / len(self.train_loader)3. Semi-Supervised Learning
3.1 Less Supervision
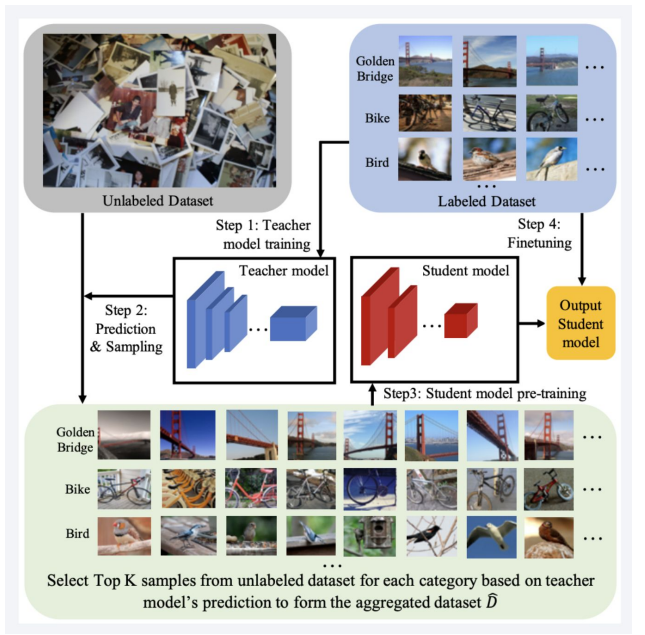
(코드 : https://pytorch.org/hub/facebookresearch_semi-supervised-ImageNet1K-models_resnext/)
일부 라벨이 있는 데이터와 많은 양의 라벨이 없는 데이터를 결합하여 학습하는 방법.
3.2 Pseudo Labeling
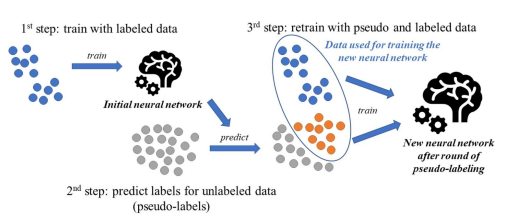
<순서>
라벨이 있는 데이터로 모델을 학습 ->
학습한 모델을 통해 라벨이 없는 데이터 예측 ->
예측한 결과에서 신뢰도가 높은 결과물을 추려, pseudo label 데이터 제작->
원본 데이터와 pseudo label데이터를 함께 사용하여 새로운 모델 학습
3.3 Generative Models
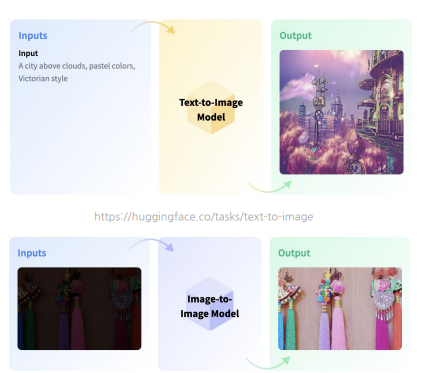
- 생성된 이미지를 학습데이터로 활용( 완전 창조경쟁)
-> generative model 을 활용하여 한 예제)
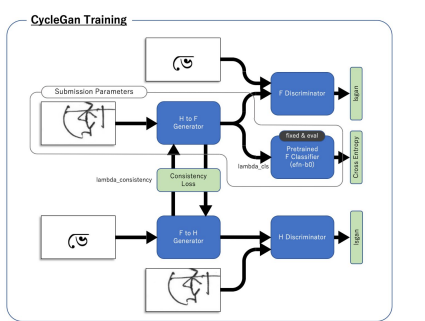
https://www.kaggle.com/c/bengaliai-cv19/discussion/135984
4. 참조자료
- pseudo label paper : https://www.nature.com/articles/s41598-023-40977-x
- less_supervision : https://pytorch.org/hub/facebookresearch_semi-supervised-ImageNet1K-models_resnext/
