0. Intro
-
1 Stage Detection
이미지 내에서 한번에 classification + detect!
즉, 분류(classification)와 위치 검출(localization)을 동시에 수행 -
2 Stage Detection
이미지 내에서 classfification 후에 -> detect!
첫 번째 단계: 객체가 있을 만한 영역 제안(region proposal)
두 번째 단계: 제안된 영역에 대해 분류 및 정확한 위치 검출
어렵지 않아요~~😎😎
1. Background

배경이미지가 어디가 다른지 파악하고 -> 저게 무엇인지 classification
2. R-CNN
논문: https://arxiv.org/abs/1311.2524
(딥러닝을 이용해 처음으로 Detection 함)
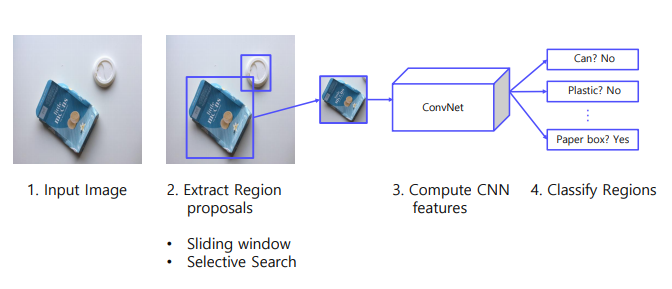
먼저 Region 영역을 엄청나게 뽑음 -> 거기중에서 있을법 한 곳을 하나 찾아서 Extract Region Proposal 함 -> 이후 Resize 를 통해 CNN모델에 들어갈 준비를 함. (이때, CNN은 사전학습된 모델임) -> 후에 Region마다 Classificiation 을 합니다.
특히 R-CNN은 Extract Region 하기 위해서 Selective Search 알고리즘을 썻다!

이미지에 존재하는 색갈, 질감 shape 등등 이미지에 존재하는 feature 를 사용하여, 이미지를 무수히 많은 영역으로 나눈 다음에 이 영역을 점차 통합해가는 방식으로 함.
위 이미지를 보면, 후보영역이 처음에는 정말 많다가 segmentation 후보영역을 좀더 줄여가는 방식.
더 깊게 알고 싶으면 밑에 블로그 참조하자.
Selective Search 참고 자료
• Selective Search에서 사용하는 segmentation 방법
https://blog.naver.com/laonple/220925179894
• Greedy Algorithm 사용한 영역 병합 방법
https://blog.naver.com/laonple/220930954658
2.2 Pipeline
① 입력이미지를 받습니다.

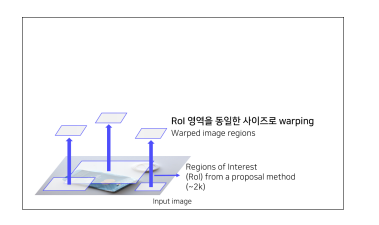
② Selective Search 알고리즘을 통해 약 2,000개의 RoI 추출합니다.

🙄 RoI(Region of Interest)란?
👉 이미지나 영상 내에서 분석하고자 하는 "흥미로운" 부분을 의미함.
즉, 찾고자 하는 영역을 말하는 거임.
③ RoI의 크기를 조절하여, 모두 동일한 사이즈로 변형(왜냐하면 CNN의 마지막 FC layer 의 입력 사이즈가 고정이므로)
④ 각각의 RoI를 CNN에 넣어서, feature 추출
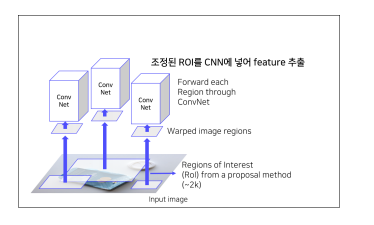
-> 이 때, Pretrained 된 Alexnet 구조 활용하였음.(그때 당시에 feature extractor 로 Alexnet이 좋았다)
⑤ CNN을 통해 나온 Feature를 SVM에 넣어 분류진행.
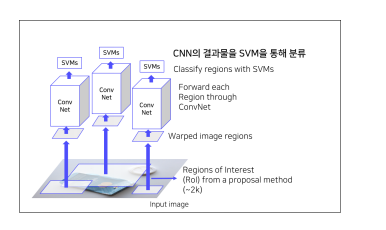
Final: CNN을 통해 나온 featrue 를 Regression 을 통해 Bounding box 예측.
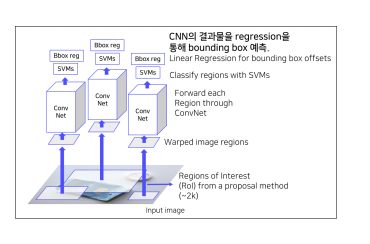
R-CNN에서 SVM은 "무엇"을 분류하는 데 사용되고, 회귀는 "어디에" 있는지를 예측하는 데 사용
2.3 Training
Training 은 각각 3부분으로 나뉘는데, 파이프라인 순서대로 살펴보자.
① Alexnet
-> Domain 에 맞게 specific 하게 finetuning 해야함.
② Linear SVM
- Hard Negative Mining 함
Hard Negative Mining이란, FP 인 것들 즉, 실제로는 False 이지만 모델이 True 라고 판단한 것들을 강제로 다음에는 False 로 넣게 하는 것이다.-> 왜냐하면 FP인 것들은 모델이 학습하기 어려운 객체들이니까 이러한 샘플들을 집중적으로 케어함으로써 모델의 성능을 높임.
③ Bbox Regressor
- loss function : MSE
3. SPPNet(Spatial Pyramid Pooling Network)
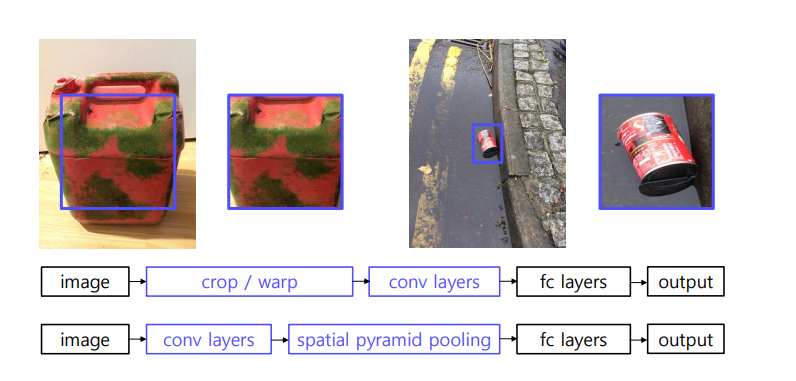
기존의 모델은, input으로 image 넣고 crop/warp한 다음에 Conv layers 에 넣었으나,
SPPNet은 바로 Conv layers어 넣은 다음에 Spatial pyramid pooling 의 방법으로 차원을 줄여나간다.
3.1 Overall
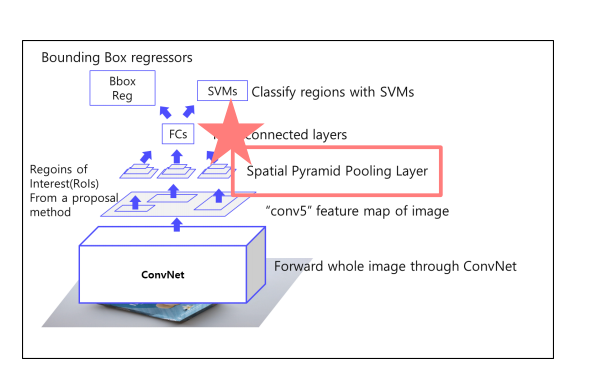
SPPnet을 이해하기 위해선 2가지를 이해해야함
첫번째로, Conv layers 를 통과한 feature map으로부터 2,000개의 region을 뽑아내는 과정과
두번째로, Spartial pooling 을 알아야함.
첫번쨰는 Fast-RCNN에서 보고 여기서는 Spartial pooling 에 대해서 알아보자.
3.2 Spatial Pyramid Pooling
다양한 RoI를 고정된 feature map으로 뽑아내기 위해서 Spatial pooling 이 필요!!
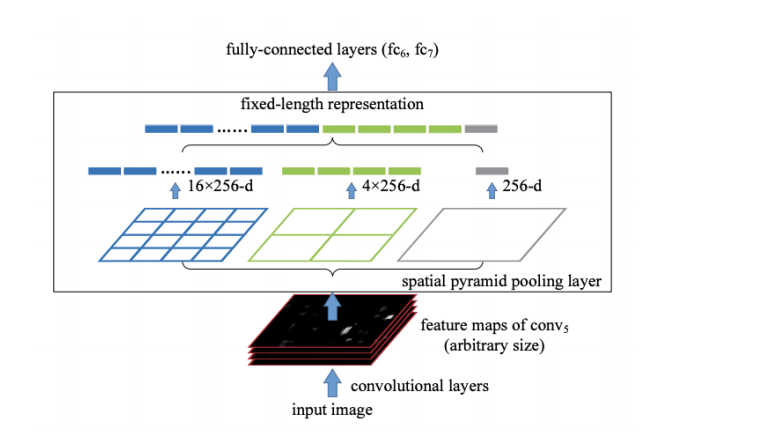
타켓 binning size를 먼저 지정함 -> 다양한 RoI로 부터 타겟 feature size를 정함. 위 이미지에서 오른쪽에서부터 보면 1x1(global pooling), 2x2, 4x4 인데, RoI를 이 크기로 맞추어서 feature를 뽑아내는 것.
Binning 과정
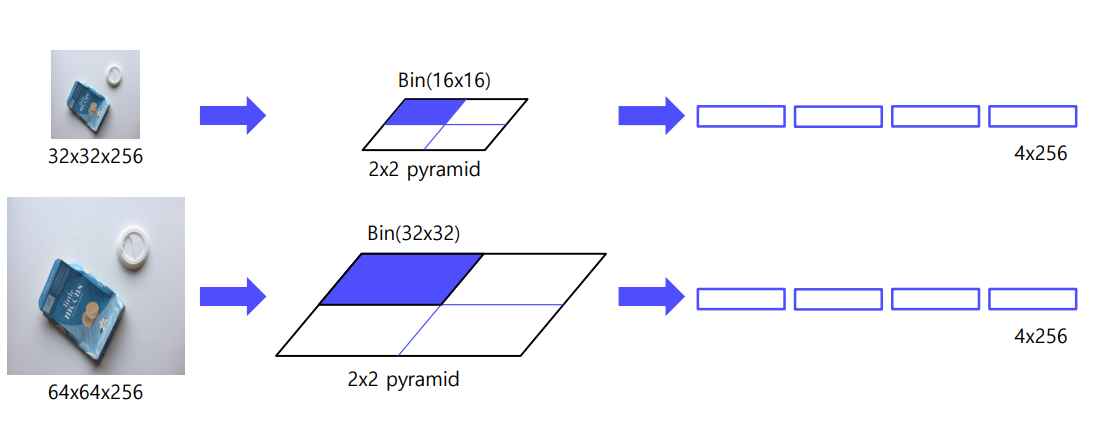
32x32 는 ->2x2로 나타내기 위해서 하나의 bin이 16x16 인것을 구한다.
반면에 64x64는 하나의 bin이 32x32인 경우로 함
이렇게 하면 RoI가 어떤 사이즈이던간에 원하는 feature size를 만들 수 있다.
SPP는 먼저 CNN을 통과시켜 RoI를 뽑아내고 -> warpping을 하지 않고 Spatial pooling을 이용하여 고정된 feature vector 로 변환해서 , 2000개의 RoI가 각각 CNN 통과하거나 강제 warping 시킬 필요성을 없애줌.
하지만 R-CNN과 마찬가지로 CNN,SVM clssifier , Bounding box regression을 각각 따로 학습시켜야 하는 문제가 남아 있었다.
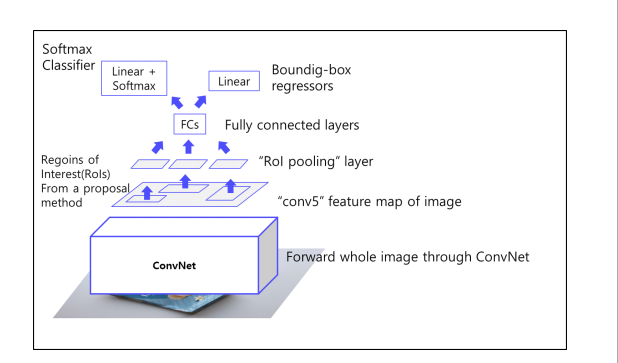
4. Fast R-CNN
4.1 Overall
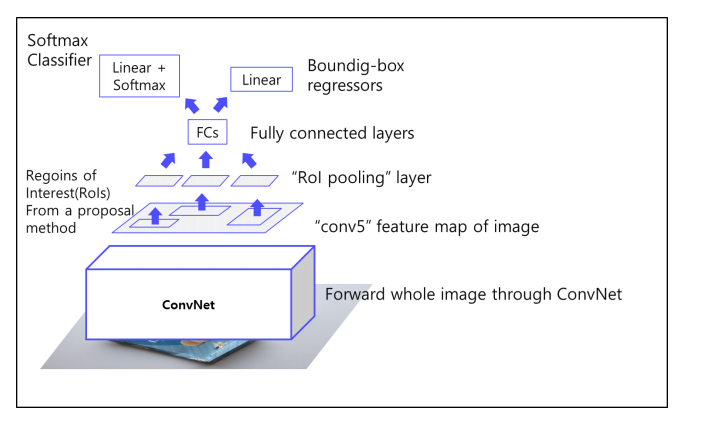
전체적인 개요를 살펴보면
input image -> Conv layers통과 -> feature map 생김 -> RoI pooling layer를 통과시켜 원하는 사이즈의 feature vector 만들고 -> FC 통과 -> softmax classification, bounding box regression 함.
4.2 Pipeline
① 이미지를 CNN에 넣어 feature 추출(여기서 CNN은 VGG16사용)
② RoI Projection 을 통해 feature map 상에서 RoI를 계산
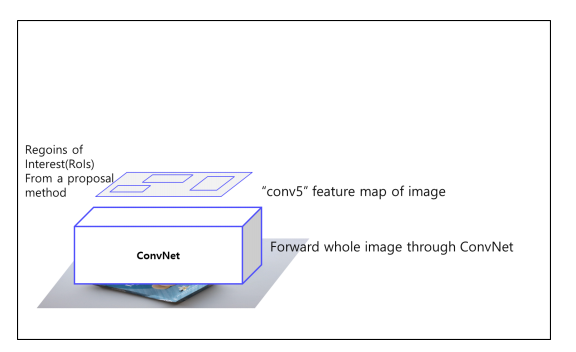
selective search를 사용하는 것은 불가.
🤔 RoI Projection 이란?
👉 원본 이미지에 맞추어서 Conv layers 를 통과한게 그대로 나오게 하는것.즉, RoI Projection은 원본 이미지에서 찾은 관심 영역(Region of Interest, RoI)을 CNN을 통과한 feature map에 맞게 투영하는 과정이다.
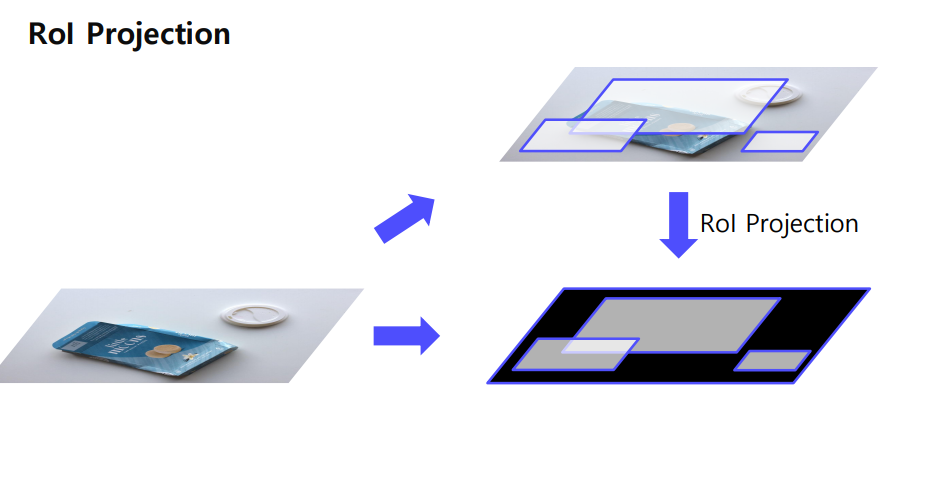
만약에 원본이미지가 400x400x3, feature map이 300x300이고 Conv layers를 통과한게 40x40x64 라고 해보자 그렇다면
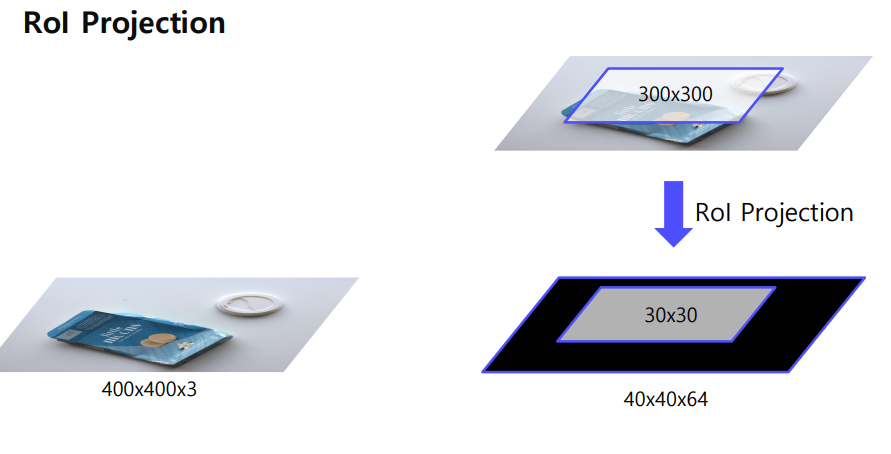
이처럼 Conv 에 맞게 RoI projection 이 맵핑이 되는셈이다.
③ RoI Pooling 을 통해 일정한 크기의 feature 가 추출
-> 고정된 feature vector를 얻기 위한 과정.
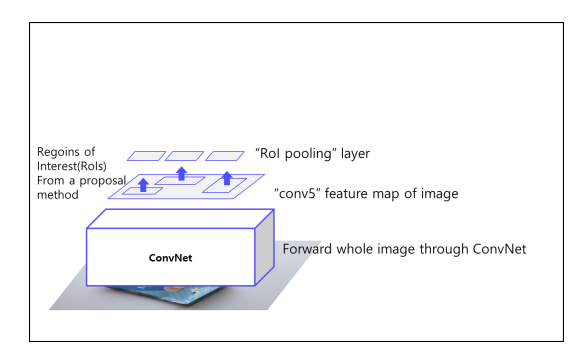
🤔 RoI Pooling 이란?
👉 RoI pooling은 RoI 에서 고정된 크기의 특징 맵을 추출하는 과정.
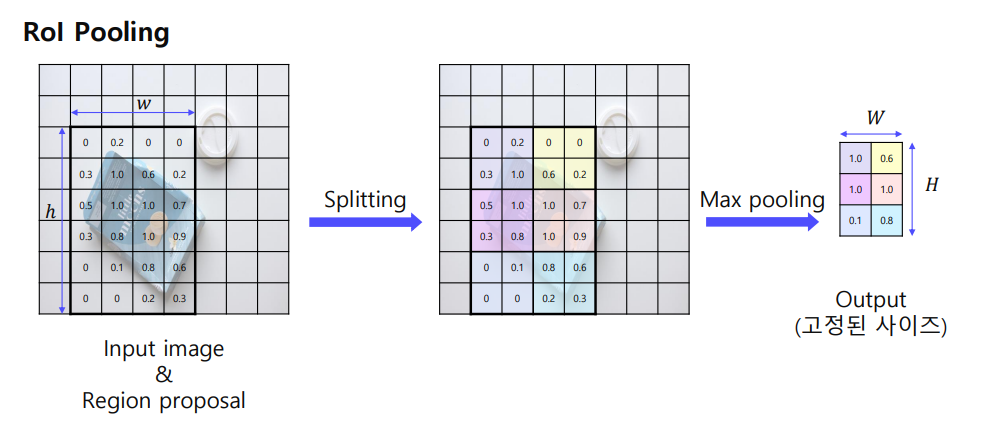
과정)
(1) 입력 특징 맵과 RoI 목록을 받습니다.
(2) 각 RoI를 고정된 수의 섹션(예: 7x7)으로 나눕니다.
(3) 각 섹션에서 최대값을 찾아 출력 버퍼에 복사합니다1.
즉,RoI projection 이랑 pooling의 차이점을 간단히 살펴보면,
-
RoI projection: 입력 이미지를 통째로 CNN에 통과시켜 feature map을 추출하고, 입력 이미지로부터 따로 추출한 RoI를 feature map 위에 그대로 매핑하는 방법을 사용하여 약 2000번의 CNN 연산을 단 한번으로 줄일 수 있었다.
-
RoI pooling: CNN의 fc layer에 입력하기 위해서는 고정된 크기의 벡터가 필요하기 때문에 R-CNN에서는 강제 warping을 사용하였다. 이 방식은 정보 또는 성능의 손실 가능성이 있기 때문에, SPPNet의 아이디어를 차용하여 고정된 크기의 vector로 변환해주는 RoI pooling 방식으로 대체하였다.
④ FC 이후, Softmax Classifier 와 Bounding Box Regressor
4.3 Training
-
multi task loss 사용 (classification loss + bounding box regression)
-
Loss function
-- Classification : Cross entropy
-- BB regressor : Smooth L1 -
Cross Entropy Loss:
수식:
여기서:
는 실제 확률 분포
는 예측 확률 분포
Cross Entropy는 두 확률 분포 간의 차이를 측정합니다. -
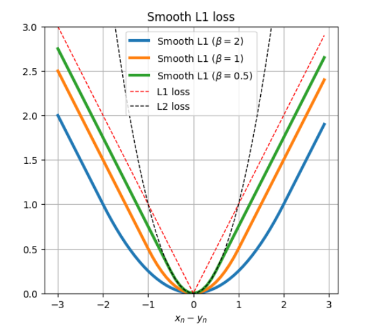
Smooth L1
Smooth L1 Loss는 L1 Loss와 L2 Loss의 장점을 결합한 손실 함수. 미분가능하면서 outlier 에 영향을 덜 받는 것으로 알려짐.
-> Fast R-CNN은 end-to-end 가 아니라는 한계점이 존재함!
5. Faster R-CNN
5.1 Overall
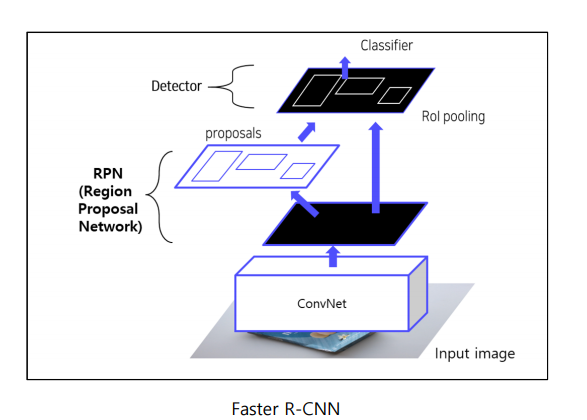
RPN이 fast R-CNN에서 추가되었다.
5.2 Pipeline
① 이미지를 CNN에 넣어서 feature map 추출 그리고 RPN을 통해 RoI 계산
- 기존의 selective search 대체
- Anchor box 개념 사용.
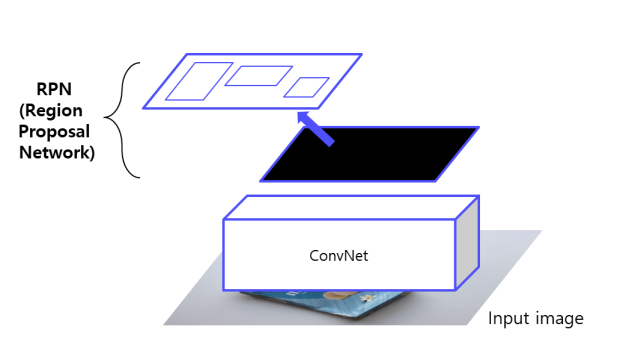
🤔 Anchor box??(내가 아는 anchor는 설득할때 쓰는거 밖에 없는뎅ㅎㅎ)
👉 Anchor box는 미리 정의된 크기와 비율을 가진 기준 박스이다.
하지만,각 셀마다 scale 를 다르게 두어, 각 셀마다 n개의 anchor box를 정의해 둘 수 있다. 그러면 고정된 크기가 아닌 객체의 사이즈에 따라 anchor box를 객체의 크기에 대한 대응이 가능해진다.
RPN(Region Proposal Network)
Region Proposal Network (RPN)은 물체 탐지에서 사용되는 신경망으로, 입력 이미지에서 객체가 있을 가능성이 높은 영역(프로포절)을 제안하는 역할을 한다.
즉, 이미지 내에서 잠재적인 객체위치를 빠르고 효울적으로 식별.
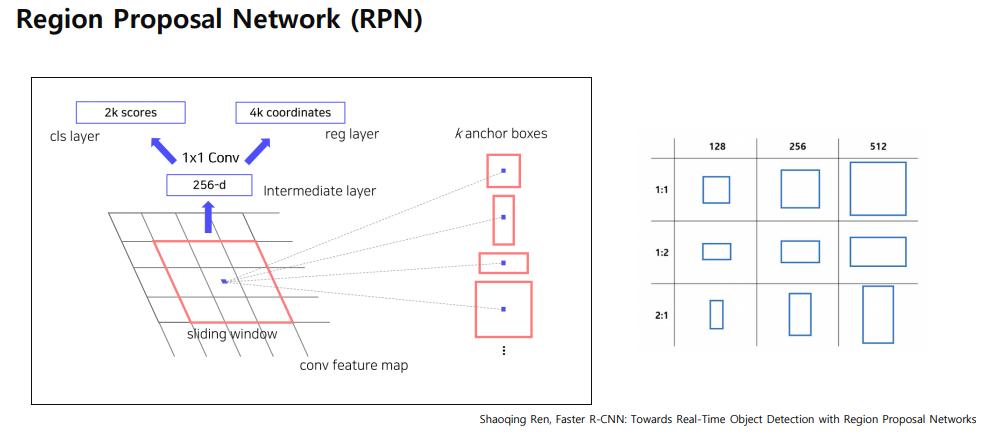
RPN의 작동 방식
-
Conv Feature Map: 입력 이미지를 CNN을 통해 특성 맵으로 변환합니다. 이 특성 맵은 RPN의 입력이 됩니다.
-
Sliding Window: 특성 맵 위를 일정한 크기의 윈도우가 이동하면서 각 위치에서 객체가 존재할 가능성을 평가합니다.
-
Intermediate Layer: 1x1 컨볼루션 레이어로, 각 윈도우에 대해 256차원의 벡터를 생성하여 정보를 축약합니다.
-
Anchor Boxes: 각 슬라이딩 윈도우 위치에서 다양한 크기와 비율의 앵커 박스를 생성합니다. 일반적으로 3가지 크기(128, 256, 512)와 3가지 비율(1:1, 1:2, 2:1)이 사용됩니다.
-
Cls Layer (Classification Layer): 각 앵커 박스에 대해 객체가 존재할 확률을 계산합니다. 여기서 2k 점수는 k개의 앵커 박스에 대해 각각 객체일 확률과 배경일 확률을 나타냅니다.
-
Reg Layer (Regression Layer): 각 앵커 박스에 대해 정확한 경계 상자를 제안하기 위해 오프셋을 계산합니다. 4k 좌표는 k개의 앵커 박스를 조정하는 데 필요한 정보를 제공합니다.
🚀 좀더 예시를 들어가면서 말해보자
만약에 2개 object, 9개 anchor box가 필요하다면?
① HxWxC 인 것을 3x3x512 Conv 이용하여 -> HxWx512 로 만듦
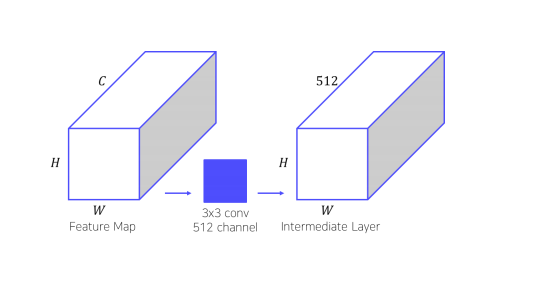
② 1 x 1 conv 수행하여 binary classification ,bounding box regressor 수행.
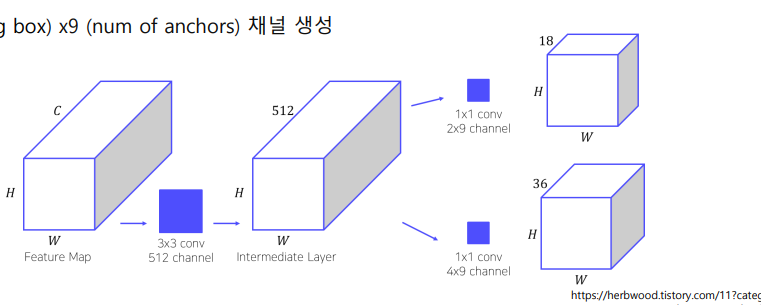
- binary classification :2 (object or not) x 9 (num of anchors) 채널 생성
- bounding box regressor: 4 (bounding box) x9 (num of anchors) 채널 생성
간단하게 살펴보면 이렇게 나온다.
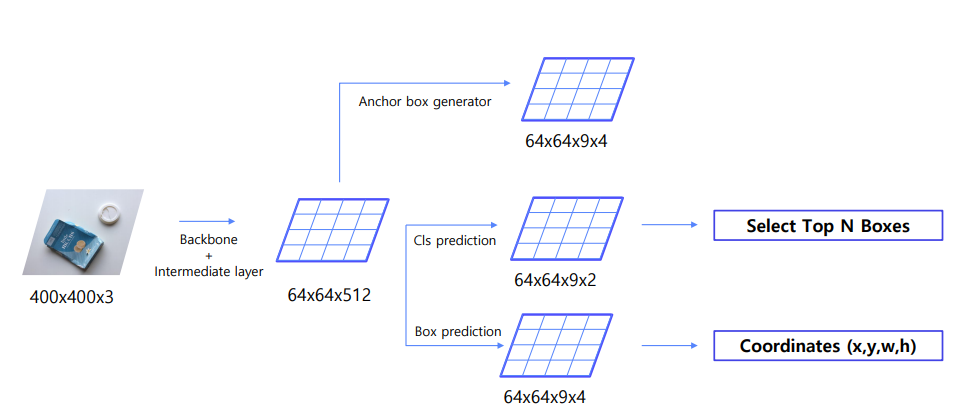
참고로, NMS 라고 필요없는 앵커박스를 제거하는 NMS기법이 있는데, 잠깐만 살펴보자.
NMS(Non-Maximum Suppression)
Non-Maximum Suppression (NMS)는 객체 탐지에서 중복된 경계 상자를 제거하고 가장 관련성이 높은 상자를 선택하는 후처리 기법
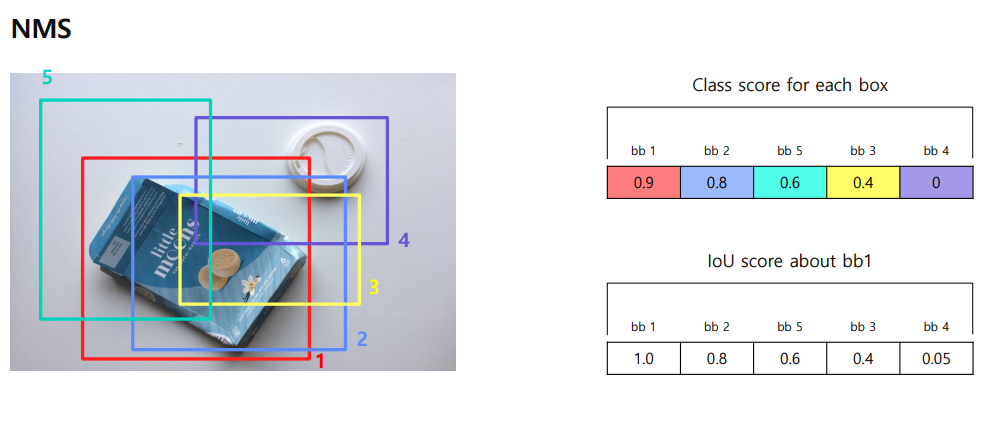
bb1을 기준으로 봤을때, 많이 겹치는 bbox 는 제거해준다.
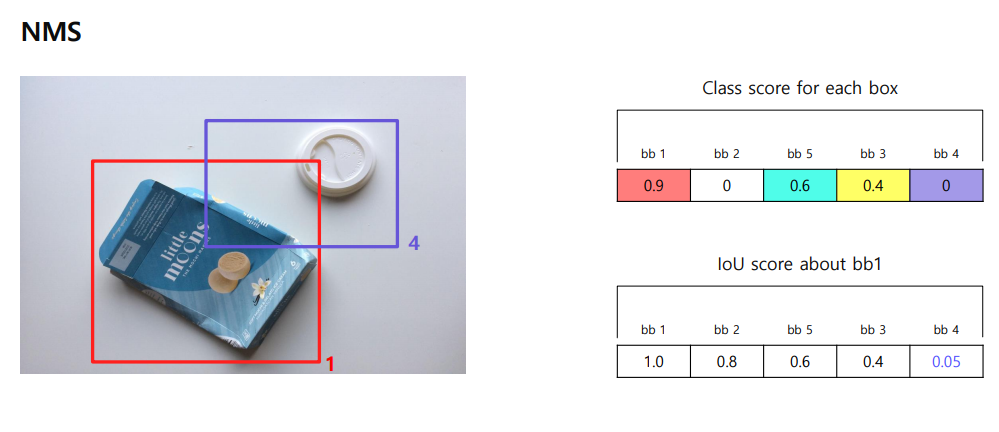
지금은 bb1을 기준으로 했는데, bb2, bb3등을 기준으로 할 수도 있다~
5.3 Training
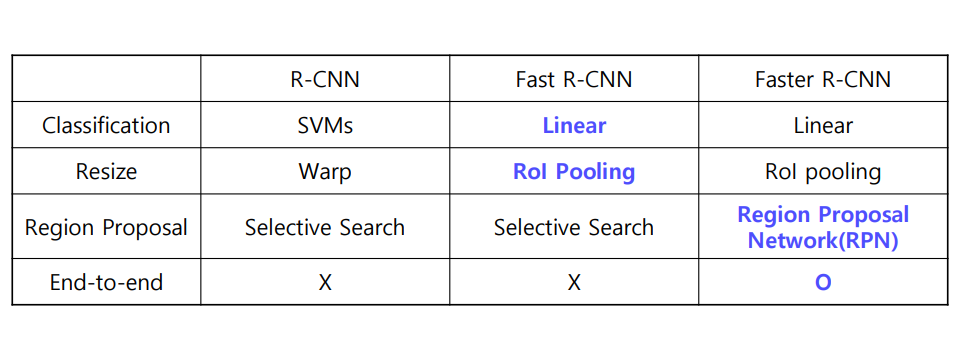
6. Summary
7. 참고사항
1) Hoya012, https://hoya012.github.io/
2) 갈아먹는 Object Detection, https://yeomko.tistory.com/13
3) Deepsystems, https://deepsystems.ai/reviews
4) https://herbwood.tistory.com
5) https://towardsdatascience.com/understanding-region-of-interest-part-1-roi-pooling-e4f5dd65bb44
6) https://ganghee-lee.tistory.com/37
7) https://blog.naver.com/laonple
8) https://arxiv.org/pdf/1311.2524.pdf (Rich feature hierarchies for accurate object detection and semantic segmentation)
9) https://arxiv.org/pdf/1406.4729.pdf (Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)
9) https://arxiv.org/pdf/1504.08083.pdf (Fast R-CNN)
10) https://arxiv.org/pdf/1506.01497.pdf (Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks)
