0. Intro
앞서 Object detection 같은 경우에는, 통합된 라이브러리가 없어 처음에 어떤 라이브러리를 선택할지가 굉장히 중요하다.
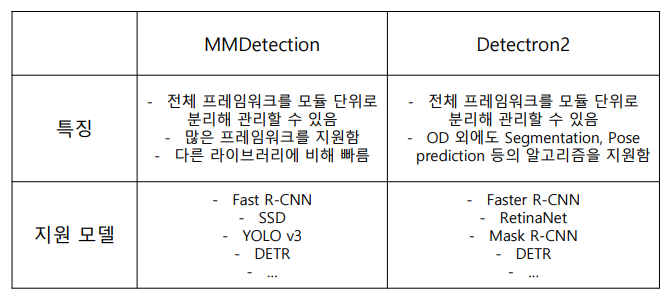
1. MMDetection

- Pytorch 기반의 Object Detection 오픈소스 라이브러리.
- MM은 Multi-Media의 약자.
- 특히 MM detection은 모듈화된 설계로 확장성이 용이.
- 난이도 허들이 높이지만, 그 허들을 넘기면 쉬움.
- Custom이나 좀더 잘 쓰기 위해서는 라이브러리에 대한 완벽한 이해가 필요함..😥😥
1.1 pipeline
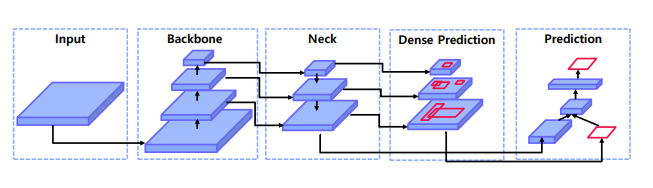
간략하게 설명
① input image 넣으면
② backbone을 통해 feature 추출
③ neck 을 통해 이미지층의 특징들을 재결합
④ dense prediction 을 neck에서 나온 특징맵을 바탕으로 객체의 대략적인 위치와 크기를 예측
⑤ 최종 prediction 함.
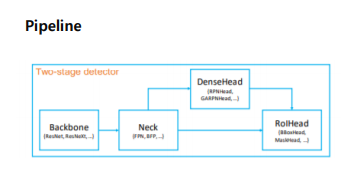
-> 각 모듈별로 customizing 할 수 음
이러한 시스템은 config 파일을 통해서 통제.
- Backbone – 입력 이미지를 특징 맵으로 변형
- Neck – backbone과 head를 연결, Feature
map을 재구성 (ex. FPN) - DenseHead – 특징 맵의 dense location을
수행하는 부분임 - RoIHead –RoI 특징을 입력으로 받아 box 분류, 좌표 회귀 등을 예측하는 부분임
대략적인 Code 를 통해서 살펴보자.
# 1. 라이브러리 및 모듈 import
from mmcv import Config
from mmdet.datasets import build_dataset
from mmdet.models import build_detector
from mmdet,apis import train_detector
from mmdet.datasets import (build_dataloader, build_dataset, replace_ImageToTensor)
# 2. Config 파일 불러오기
cfg = Config.fromfile("~")
# 3. Config 본인에게 맞게 수정하기
cfg.data.sample_per_gpu = 4
cfg.seed =2020
cfg.work_dir = ""
cfg.model.roi_head.bbox_head.num_classese = number
# 4. 모델, 데이터셋 build
model = build_detector(cfg.model)
datasets = [build_dataset(cfg.data.train)]
# 5. 학습
train_detector(model, datasets[0], cfg, distributed = False, validate = True)
👉 구조를 살펴보면,
- configs를 통해 데이터셋부터 모델, scheduler, optimizer정의 가능
- 특히, configs에는 다양한 object detection 모델들의 config 파일들이 정의돼 있음
https://github.com/open-mmlab/mmdetection <- 여기서 configs 에 들어가서 자세하게 학습볼 수 있음.
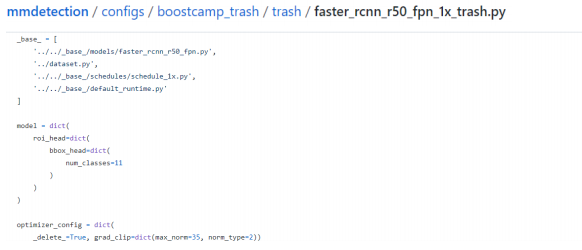
1.2 Config file
틀이 갖춰진 config 를 상속받고 필요한 부분만 수정해 사용.
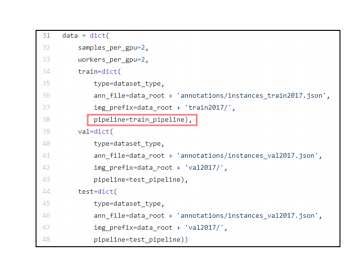
1.3 Dataset
-
sample_per_gpu, workers_per_gpu, train,val, test,
-
Data Pipeline
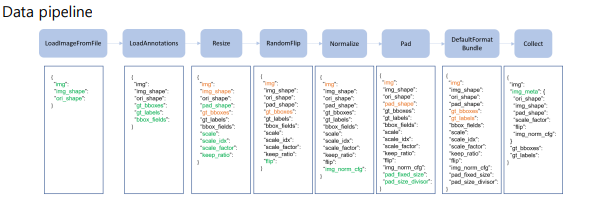
LoadImageFromFile -> LoadAnnotations -> Resize -> RandomFlip -> Normalize -> Pad -> DefalutFormatBundle -> Collect
1.4 Model
2stage model
• type
모델 유형을 적어줌.
ex) type = FasterRCNN
• backbone
인풋 이미지를 feature map 으로 변형해주는 네트워크
model = dict(
type = "FasterRCNN",
backbone = dict(
type = "ResNet",
depth = 40,
num_stages = 4,
out_indices = (0,1,2,3),
frozen_stages = 1,
norm_cfg = dict(type = "BN", requires_grad = True), #BN = BatchNormalize
norm_eval = True,
style = "pytorch",
init_cfg = dict(type ="Pretrained", checkpoint =""))
• neck
backbone과 head 를 연결, feature map을 재구성함
neck = dict(type = "FPN",
in_channels = [256,512,1024,2048],
out_channels = 256,
num_outs = 5)• rpn_head
rpn_head=dict(
type='RPNHead',
in_channels=256,
feat_channels=256,
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0))• roi_head
roi_head = dict(
type='StandardRoIHead',
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32],
),
bbox_head=dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=80,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[0.1, 0.1, 0.2, 0.2],
),
reg_class_agnostic=False,
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0,
),
loss_bbox=dict(type='L1Loss', loss_weight=1.0),
)
)❗Custom backbone을 만들 수도 있다.
① 새로운 backbone 등록
import torch.nn as nn
from ..builder import BACKBONES
@BACKBONES.register_module()
class MobileNet(nn.Module):
def __init__(self, arg1, arg2):
psas
def forward(self,x):
pass② 모듈 임포트
from .mobilenet import MobileNet③ 등록한 backbone 사용
model = dict(
backbone = dict(
type = "MobileNet",
arg1 = xxx
arg2 =xxx
)
이렇게 backbone을 새로 등록하고 임포트하고 config에 넣어주기만 하면 커스텀 백본을 만들 수 있다.
1.5 Runtime settings
학습적인 부분들을 정의해 줄 수 있는 부분
- optimizer
optimizer= dict(type ="SGD", lr = 0.02, momentum = 0.9, weight_decay = 0.0001)
optimizer_config = dict(grad_clip = None)
- training scheduler
lr_config = dict(
policy = "step",
warmup ="linear",
...
)
runner = dict(type = "EpochBasedRunner", max_epochs = 12)✍️ 파이프라인 복습해보자.
라이브러리 및 모듈 임포트 -> config 파일 불러오기 -> config 수정하기 -> 모델,데이터셋 build -> 학습
config 가 수정하면, 내가 원하는 대로 만들 수 있다.!
2. Detectron2

- Facebook pytorch기반 라이브러리
- ObjectDetection외에도 segmentation, pose prediction 등 알고리즘도 제공.
2.1 pipeline
Setup Config -> Setup Trainier -> Start Training
① Setup Config

② Setup Trainer
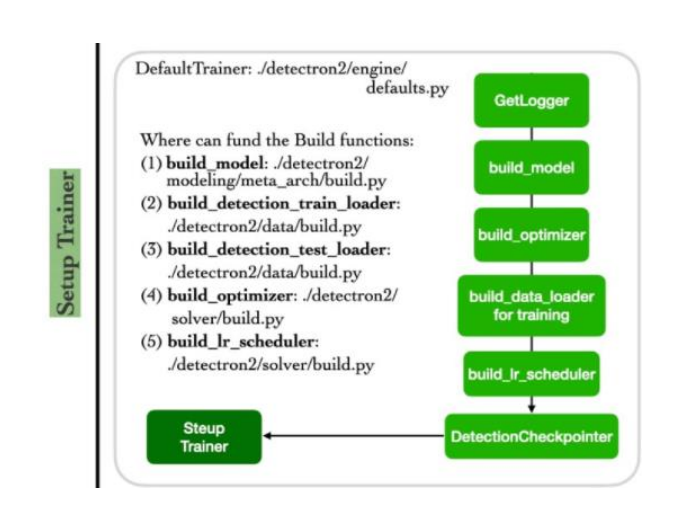
- Build_model -> Build_detection_train/test_loader -> build_optimizer -> build_scheduler
③ Start Training
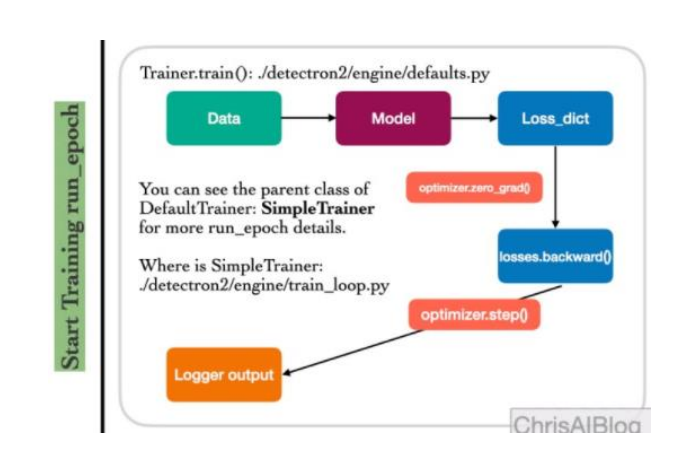
파이프라인 미리보기
# 1. 라이브러리 및 모듈 import
import os
import dectron2
from detectron2.utils.logger import setup_logger
setup_logger()
from detectron2 import model_zoo
from detectron2.config import get_cfg
from detectron2.engine import defaultTrainer
from detectron2.data import DatasetCatelog, MetadataCatalog
from detectron2.data.dataset import register_coco_instances
# 2. 데이터셋 등록하기
# Register Dataset
register_coco_instances("coco_trash_train", {}, "/home/data/data/train.json", "/home/data/data/")
register_coco_instances("coco_trash_val", {}, "/home/data/data/val.json", "/home/data/data/")
# 3. Config 파일 불러오기
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("~.yaml"))
# 4. Config 본인에게 맞게 수정하기
cfg.DATASETS.TRAIN =("coco_trash_train")
cfg.DATASETS.TEST = ("coco_trash_val")
cfg.data.sample_per_gpu = 4
cfg.seed =2020
cfg.work_dir = ""
cfg.model.roi_head.bbox_head.num_classese = number
# 5. Augmentation mapper 정의 (mmdectection같은 경우는 config 파일에서 불러오면 되는데, Dectron2는 직접 augmentation mapper를 만들어 줘야한다.)
# 5. Trainer 정의
from detectron2.evaluation import COCOEvaluator
from detectron2.data import build_detection_test_loader, build_detection_train_loader
class MyTrainer(DefaultTrainer):
@classmethod
def build_train_loader(cls, cfg, sampler=None):
return build_detection_train_loader(
cfg, mapper=MyMapper, sampler=sampler
)
@classmethod
def build_evaluator(cls, cfg, dataset_name, output_folder=None):
if output_folder is None:
os.makedirs("./output_eval", exist_ok=True)
output_folder = "./output_eval"
return COCOEvaluator(dataset_name, cfg, False, output_folder)
train_detector(model, datasets[0], cfg, distributed = False, validate = True)
# 6.학습
os.makedirs(cfg.OUPUT_DIR, exist_ok = True)
trainer = MyTrainer(cfg)
trainer.resume_or_load(resume =False)
trainer.train()
2.2 Config file
- MMDetection과 유사하게 config파일을 수정, 이를 바탕으로 파이프라인을 build 하고 학습함.
- 틀이 갖춰진 기본 config를 상속 받고, 필요한 부분만 수정해 사용함.
2.3 Dataset
2.3.1 Dataset 등록
- 커스텀 데이터셋을 사용하고자 할 때는, 데이터셋을 등록해야함.
- (옵션) 전체 데이터셋이 공유하는 정보를 메타 데이터로 등록할 수 있다.
- config 파일에 train,test 데이터셋을 명시해 사용할 수 있도록 한다.
cfg.DATASETS.TRAIN =("coco_trash_train")
cfg.DATASETS.TEST = ("coco_train_val")2.3.2 Data augmentation
① augmentation 정보가 담긴 mapper 정의
def MyMapper(dataset_dict):
"""Mapper which uses `detectron2.data.transforms` augmentations"""
dataset_dict = copy.deepcopy(dataset_dict)
image = utils.read_image(dataset_dict['file_name'], format='BGR')
transform_list = [
T.RandomFlip(prob=0.4, horizontal=False, vertical=True),
T.RandomBrightness(0.8, 1.8),
T.RandomContrast(0.6, 1.3)
]
image, transforms = T.apply_transform_gens(transform_list, image)
dataset_dict['image'] = torch.as_tensor(image.transpose(2, 0, 1).astype("float32"))
annos = [
utils.transform_instance_annotations(obj, transforms, image.shape[:2])
for obj in dataset_dict.pop("annotations")
if obj.get("iscrowd", 0) == 0
]
instances = utils.annotations_to_instances(annos, image.shape[:2])
dataset_dict["instances"] = utils.filter_empty_instances(instances)
return dataset_dict② Dataloader에 mapper를 input으로 넣어줌
class MyTrainer(DefaultTrainer):
@classmethod
def build_train_loader(cls, cfg, sampler=None):
return build_detection_train_loader(
cfg, mapper=MyMapper, sampler=sampler
)
@classmethod
def build_evaluator(cls, cfg, dataset_name, output_folder=None):
if output_folder is None:
os.makedirs("./output_eval", exist_ok=True)
output_folder = "./output_eval"
return COCOEvaluator(dataset_name, cfg, False, output_folder)2.4 Model
-
BACKBONE
인풋 이미지를 특징맵으로 변형해주는 네트워크
Ex. ResNet, RegNet… -
FPN
Backbone과 head를 연결, Feature map을 재구성 -
ANCHOR_GENERATOR
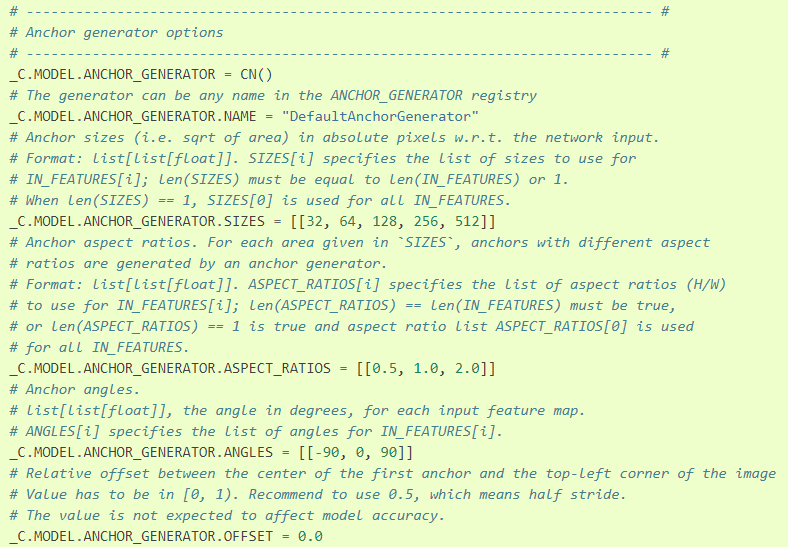
-
RPN

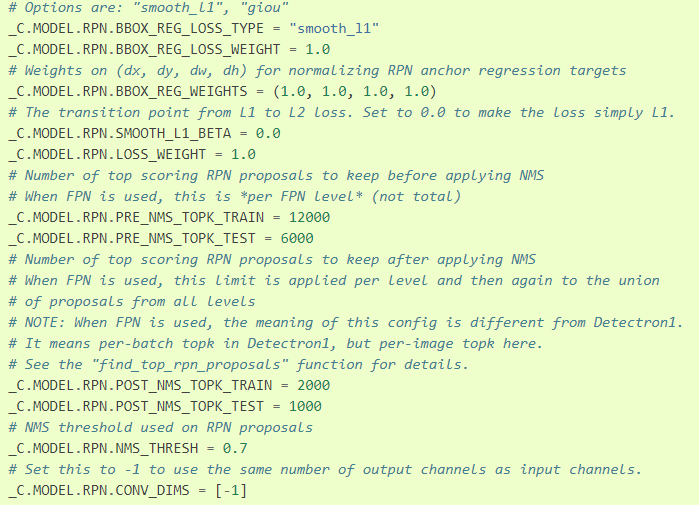
-
ROI_HEADS
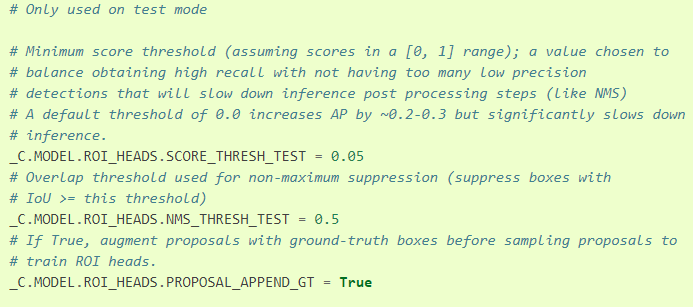
-
ROI_BOX_HEAD
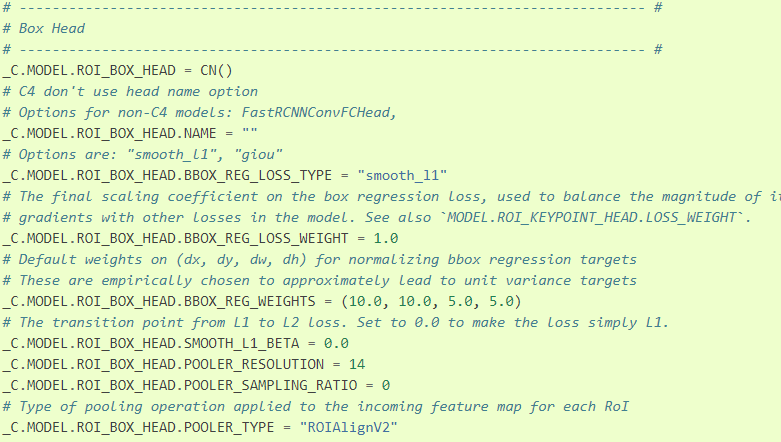

2.5 Solver
-> mmdetection에서 runtime 과 관련된 부분,
- LR_SCHEDULER
- WEIGHT_DECAY
- CLIP_GRADIENTS
3. 참고사항
1) “MMDetection : Open MMLab Detection Toolbox and Benchmark”
2) https://github.com/open-mmlab/mmdetection
3) https://christineai.blog/category/computer-vision/object-detection
4) https://github.com/facebookresearch/detectron2
5) https://detectron2.readthedocs.io/en/latest/
6) Alexey Bochkovskiy, Chien-Yao Wang, Hong-yuan Mark Liao, YOLOv4: Optimal Speed and Accuracy of Object Detection
