1. 데이터증강
데이터증강(Data augmentation)은 기존 데이터를 다양한 방식으로 변형하여 , 데이터셋의 크기와 다양성을 증가시키는 방법.
1.1 Image Data Augmentation
데이터 증강이란 무엇?
데이터를 증강시켜 모델을 일반화하는 것.
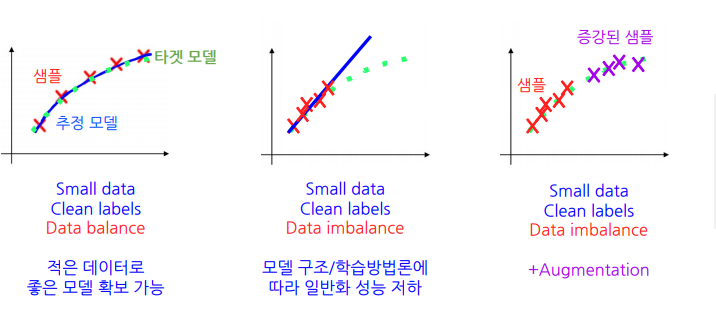
관점에 따라서 데이터 균등화 시도.
- 색상분포 -> Color Jittering
- 촬영각도 -> Rotation
- 이미지크기 -> Resize
Image DataAugmentation = Geometric + Style + ...
Geometric : Global -level 의 변화를 주는 변형

ex) Randomcrop, resize, rotate , flip, shear등
Style transformation : Local-level의 변화를 주는 변형
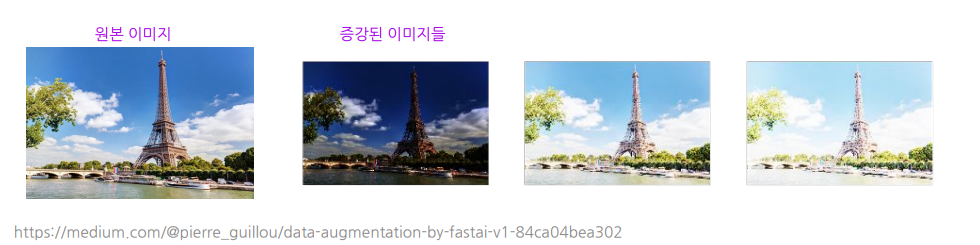
ex) Color jitter, channel shuffle, noise filter 등등
Image Data Augmentation =+ ...Others

1.2 Geometric Transformations for Text Images
올바른 Geometric Transformation을 위한 규칙
[Rule1] Positive ratio보장 : 최소1개의 개체를 포함해야 한다.
[Rule2] 개체잘림방지 : 잘리는 개체가 없어야 한다
Positive ratio를 보장할 때 생기는문제
글자와 멀리 있는 배경에서는 hard negative sampling이 잘 되지 않는다
->해결 : 별도의 hard negative mining 기법을 도입해서 해결 가능.
개체잘림을 방지할 때 생기는문제
밀집된 곳에서는 sampling이 잘 되지 않는다.
-> 해결 : 일단 최소 하나의 개체는 잘리지 않고 포함하게 함. 잘린 것들은 masking해서 학습에서 무시.
2. 합성 데이터 제작
합성데이터는 기존 데이터가 없더라고 인공적으로 새로운 데이터를 만드는 방법
2.1 합성데이터의 필요성
RealData를 확보하는 건 어려운일
Real data확보 = Public dataset 가져오기 + 직접 만들기
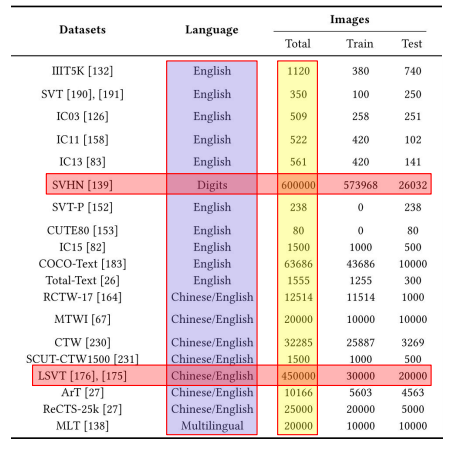
위 이미지에서 도메인에 따라(한국어) public dataset 규모가 충분하지 않을 수 있다.
또한 웹에서 수집은 라이센스 문제, 직접 촬영하는경우는 큰 데이터셋을 만들기 어렵다.
직접 annotation 하는 것은 매우 매우 어렵고 힘들다. (그냥 막노동이므로..)
Synthetic Data : Real Data에 대한 부담을 덜어준다
- 비용이 훨씬 적게 든다.
- 라이센스에 자유롭다.
- 더 세밀한 annotation 을 쉽게 얻을 수 있다.
2.2 OCR 합성데이터 예시
Text Recognition Data Generator
https://github.com/Belval/TextRecognitionDataGenerator
여기 깃헙에 들어가서 실행할 수 있다.
SynthText : DepthEstimation을 통해 적절한 위치에 표면모양에 맞춰서 글자를 합성
Synthetic Data for Text Localisation in Natural Images
https://arxiv.org/pdf/1604.06646

SynthText3D: 3D가상세계를 이용한 텍스트 이미지 합성
SynthText3D: Synthesizing Scene Text Images from 3D Virtual World
https://arxiv.org/abs/1907.06007
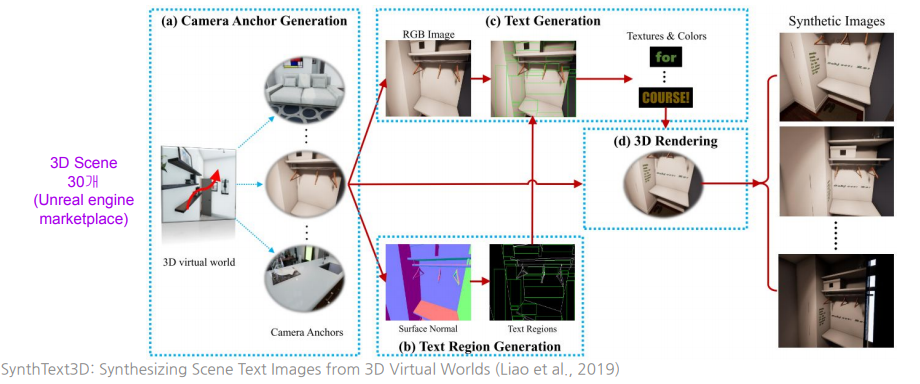
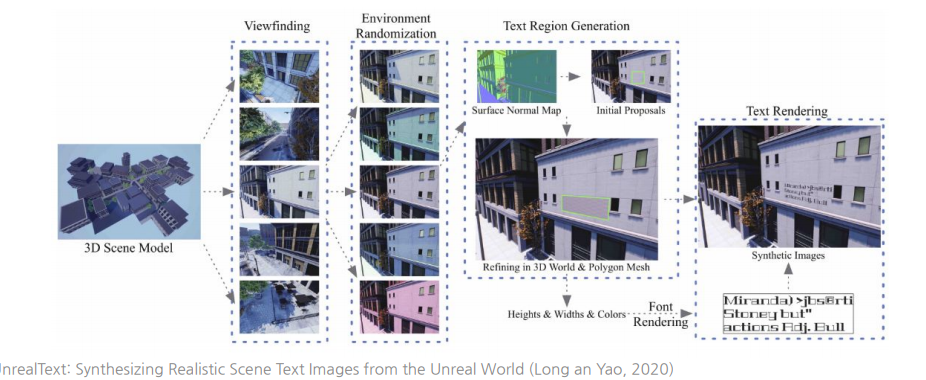
UnrealText : 3DVirtual Engine을 이용(개선된 View finding)
UnrealText: Synthesizing Realistic Scene Text Images from the Unreal World
https://arxiv.org/abs/2003.10608
2.3 합성데이터 사용방법
합성데이터를 활용한 사전훈련

합성데이터가 주어졌을때 -> 합성 데이터로 한 번 더 pretraining 해주며, 이후 target dataset 에 대해서 fine-tuning을 진행한다.
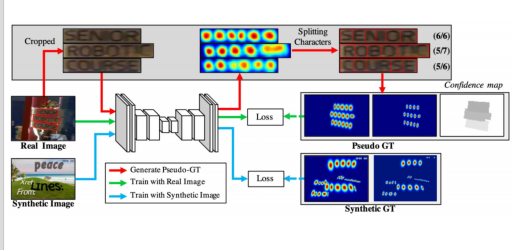
합성데이터를 활용한Weakly Supervised Learning
Character Region Awareness for Text Detection
https://arxiv.org/abs/1904.01941
3. 데이터클렌징
데이터클렌징(DataCleansing)은 데이터에서 오류나 불일치 등을 식별하고 수정하여 품질을 향상시키는 과정입니다
3.1 데이터클렌징의 필요성
3.2 CV를 위한 데이터클렌징
4. Wrap-Up
