1. 데이터셋 제작과 가이드라인
가이드라인은 좋은 데이터를 확보하기 위한 과정을 정리한 문서
1.1 가이드라인이란?
가이드라인: 좋은데이터를 확보하기 위한과정을 정리해 놓은 문서
- 데이터 구축의 목적
- 라벨링 대상 이미지 소개
- 기본적인 용어 정의
- BBOX,“전사”,“태그"등등
- Annotation규칙
- 작업 불가 이미지 정의
- 작업불가영역(illegibility=True)영역정의
- BBOX 작업방식정의
- 최종 format
👉 깃헙 컨벤션을 다루는 것처럼, 협업에 필요한 세팅을 가이드한다고 보면 된다.
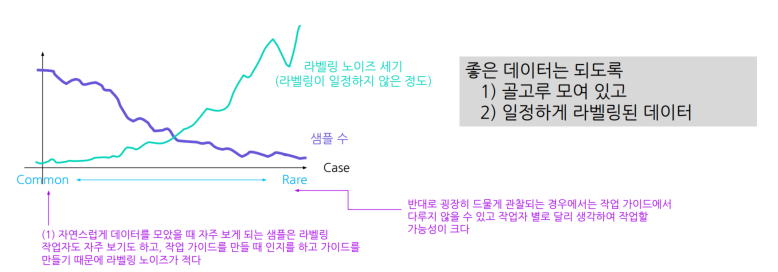
위 이미지에서 처럼
자주 보는 샘플 -> 노이즈 적음
적게 보는 샘플 -> 노이즈 많음
따라서 이러한 특이경우를 발견하고 해당 샘플들을 확보하려고 노력해야 하며, 이를 포함한 라벨링 가이드를 만들어야 한다.
가이드 라인의 필요성-학습목적
학습목적에 따라 어떤게 맞을지 알 수 있따.

가이드 라인 3가지 요소
- 특이 케이스
- 단순함
- 명료함
1.2 학습데이터셋 제작 파이프라인
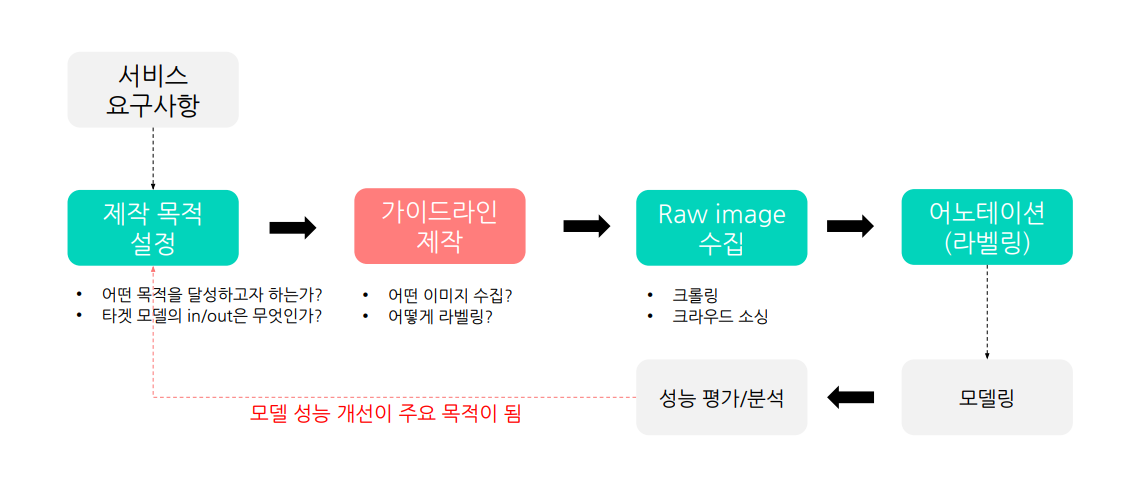
ex1) Crawling

ex2) Crowd Sourcing

2. 가이드라인 작성 고려사항
2.1 개요
가이드라인 작성 시 고려되는 내용
기본적인용어정의
Annotation(Labeling)규칙
• BBOX작업방식정의
• 작업불가이미지(HOLD이미지)정의
• 작업불가영역(illegibility=True)영역정의
• 작업대상영역
최종format
Annotation 규칙 : HOLD 이미지 기준

Annotation 규칙 : BBOX 작업 방식 정의-Points 영역

Annotation 규칙 : BBOX작업방식 정의-구부러진 글자영역

구부러진 polygon point 를 중점으로 사각형 박스가 만들어지는 것이 좋다.
Annotation 규칙: BBOX작업방식 정의- 진행방향 및 그에 따른 좌표순서
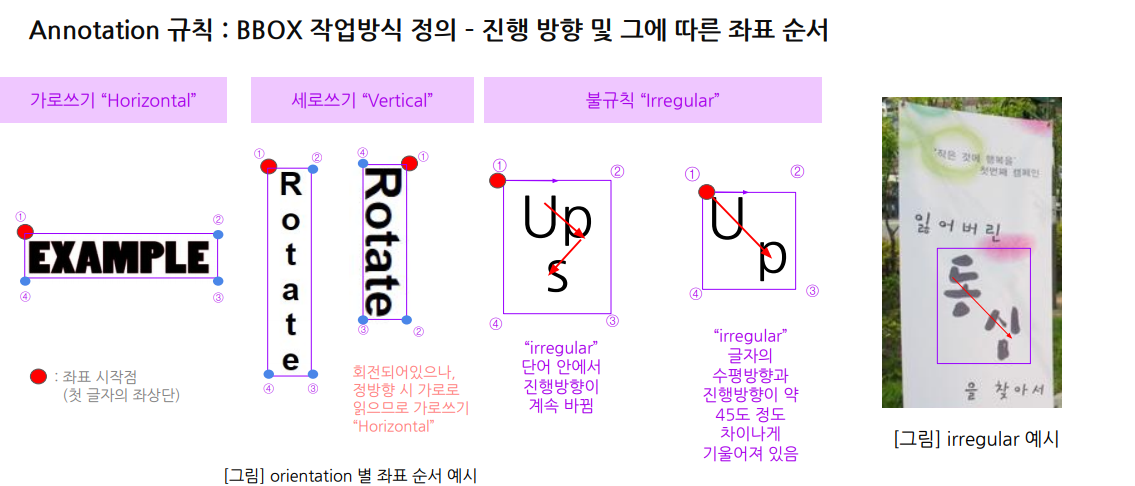
가로로 있는 text랑 세로로 있는 text 완전 세로 text로 각각 봐야함.-> 이를 라벨순서대로 정해주어서 어떻게 처리할 것인지에 대한 '합의'가 필요함.
Annotation 규칙: 작업불가 영역-예시
Rule 1: 글자를 알아보기 어려울 정도로 밀도가 높거나, 글자가 일부 뭉개져서 알아보기 어려운 영역에 대해서 illegibility: True
Rule 2: 글자가 존재하지만,글자가 겹쳐져 있거나 잘려있어 육안상 글자를 정확하게 입력할 수 없다면 illegibility:True
Annotation 규칙 : 최종포멧
예시임.

2.2 노하우:가이드라인 구성요소
가장 중요한 것은 일관성이다. 같은 케이스를 다르게 처리하는 경우가 없도록 하는 것이 중요하다.
또한 가이드라인에도 우선 순위 가 필요하다.!!
2.3 가이드라인으로 데이터 구축하기
3. Metrics for Data Evaluation
3.1 Inter-Annotator Agreement(IAA)
IAA 는 어노테이터가 생성한 레이블이 얼마나 일관성 있는지에 대해서 측정.
Cohen's Kappa
2명이상의 어노테이터가 생성한 레이블이 얼마나 일관성 있는지
Fleiss' Kappa
3명이상의 어노테이터가 생성한 레이블이 얼마나 일관성 있는지에 관한 지표
Krippendorff's Alpha
: avg. distance observed
: avg. distance expected
3.2 Recent Work in Data Measurement
KS(Kolmogorov-Smirnov) Test statistics
KS : 관찰한 데이터가 주어진 분포에서 표집되었는지를 검정하기 위한 통계량
-
KS: Kolmogorov-Smirnov 통계 값으로, 두 데이터 집합의 누적 분포 함수(CDF) 간의 최대 차이를 측정합니다.
-
max : 모든 𝑥 값에 대해 차이가 최대가 되는 지점을 찾는다는 의미입니다. KS 통계는 두 분포 간의 차이가 가장 큰 지점에서의 차이를 기반으로 계산됩니다.
-
: 관찰된 데이터 의 누적분포함수 나타내며, 이는 관찰된 데이터가x 이하일 확률을 의미합니다.
-
: 예상된 데이터 의 누적분포함수. 비교 대상이 되는 이론적 또는 추정된 분포를 기준으로 함.
4. 참고자료
- 다양한 task에 적용 가능한 IAA에 관한 논문
https://dl.acm.org/doi/10.1145/3485447.3512242 - Large Language Models for Data Annotation: A Survey
https://arxiv.org/abs/2402.13446
