1.Data Collection
1.1 OCR 학습 및 평가데이터는 어디에서 오나요?
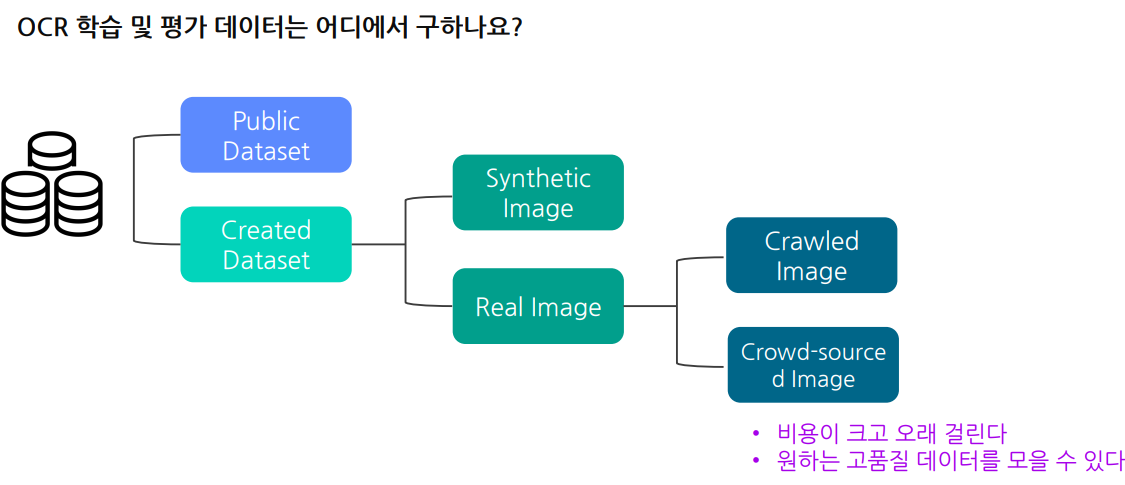
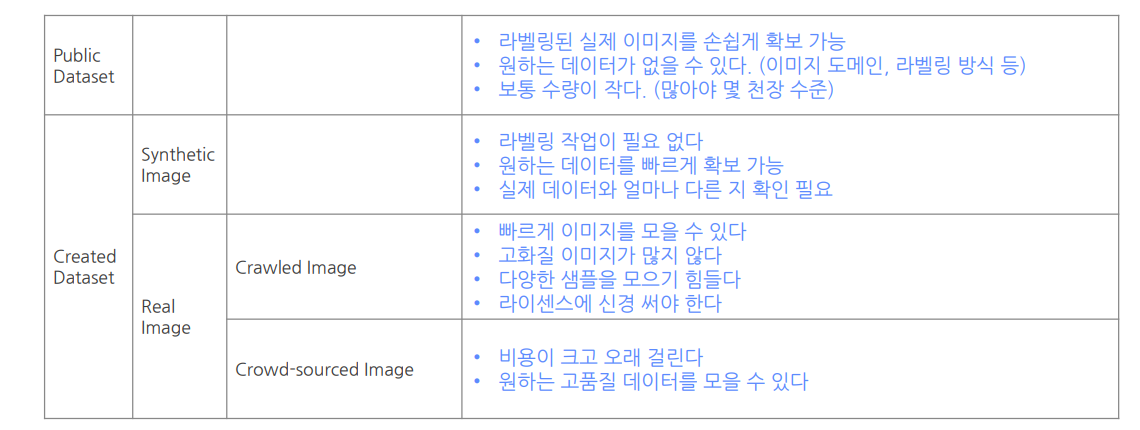
2.Public Dataset
2.1 Public Dataset 개요
서비스향 AI모델 개발시 한시라도 빨리 답을 가지고 있어야 하는 질문들
- 몇 장을 학습을 시키면 어느정도 성능이 나오는가?
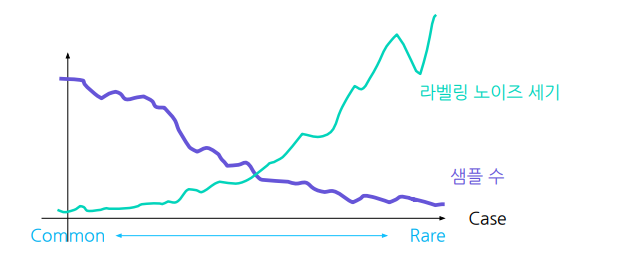
- 어떤 경우가 일반적이고 어떤경우가 희귀케이스인가?
- 현재 최신 모델의 한계는 무엇인가?
검색방법
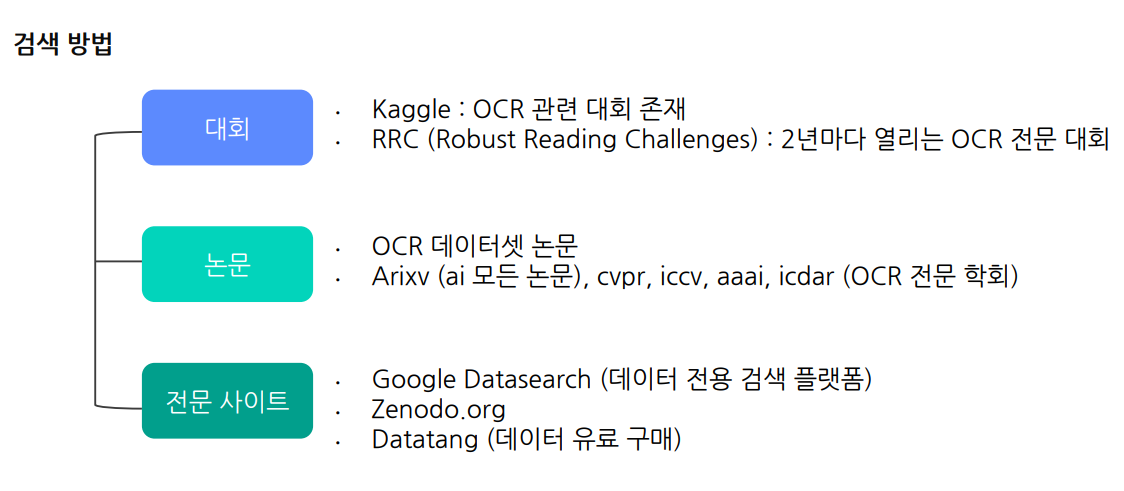
2.2 영어 및 다국어 OCR 데이터셋(ICDAR Datasets)
ICDAR(International Conference on Document Analysis and Recognition)
대표적인 OCR 대회

2.3 한국어 OCR 데이터셋(AIHub 야외실제 촬영 한글이미지)
2.4 문서 데이터셋
CORD(COnsolidated Receipt Dataset for post-OCR parsing)

3.UFO(Upstage Format for OCR)
3.1 UFO가 무엇인가요?
UFO의 목적
- 각각의 Public Dataset의 파일형식(json,txt,xml,csv등)을 하나로 통합함
- Detector,Recognizer,Parser등 서로 다른 모듈에서 모두 쉽게 사용할 수 있어야함
- 모델 개선을 위해 필요한 case에 대한 정보를 데이터에 포함시킬수있음
• 예:이미지단위의특징(손글씨,blur등),글자영역단위의특징(가려짐,글자진행방향등)
UFO 포맷의 특징
json파일 안에서 element탐색이 쉽게 GraphStructure을 기반으로 만들어졌음
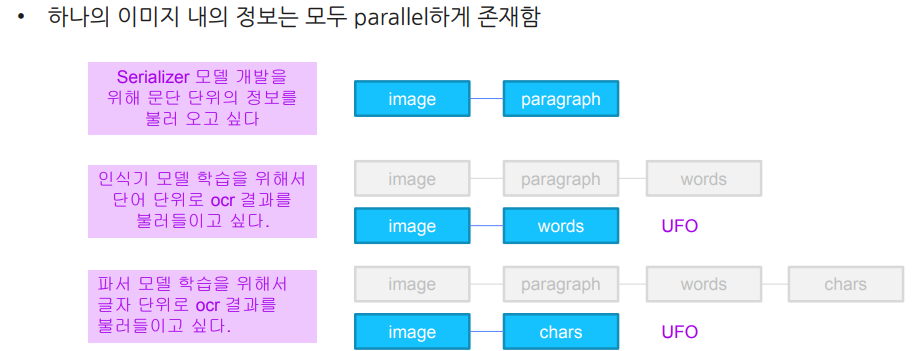
3.2 UFO포맷 자세히 알아보기
Dataset 레벨
한 데이터셋 내의 모든 이미지들에 관해 하나의 ufo 형식의 json 파일을 만든다.

Image 레벨

paragraph 레벨

word 레벨

character 레벨

Annotation log,License Tag
Annotation log:이슈추적을 위한 정보기록
License tag: 라이센스 정보
4.데이터셋EDA(Exploratory Data Analysis)
4.1 EDA가 무엇인가요?
- 탐색적 데이터 분석으로, 데이터셋을 분석하고 조사하여 주요 특성을 요약하는데 사용됨.
- 데이터셋 내 오류파악, 데이터의 분포 특징 파악, 목적 적합성등을 파악하는데 중요함.
4.2 EDA에서 살펴볼 수 있는것
- image width,height분포
- 이미지 당 단어 개수 분포
- 전체 태그별 분포
- Image tag
- Word tag
- Orientation
- Language tag
- 전체 BBOX크기 분포
- 넓이 기준
- Horizontal한 단어의 aspect ratio(가로/세로)
5. 참고자료
https://www.sciencedirect.com/science/article/pii/S2666389921001847

Lee_AA