1.성능평가개요
1.1 성능평가의 중요성
성능평가 == 새로운 (학습에서 사용되지 않은) 데이터가 들어왔을 때 얼마나 잘 동작하는가?
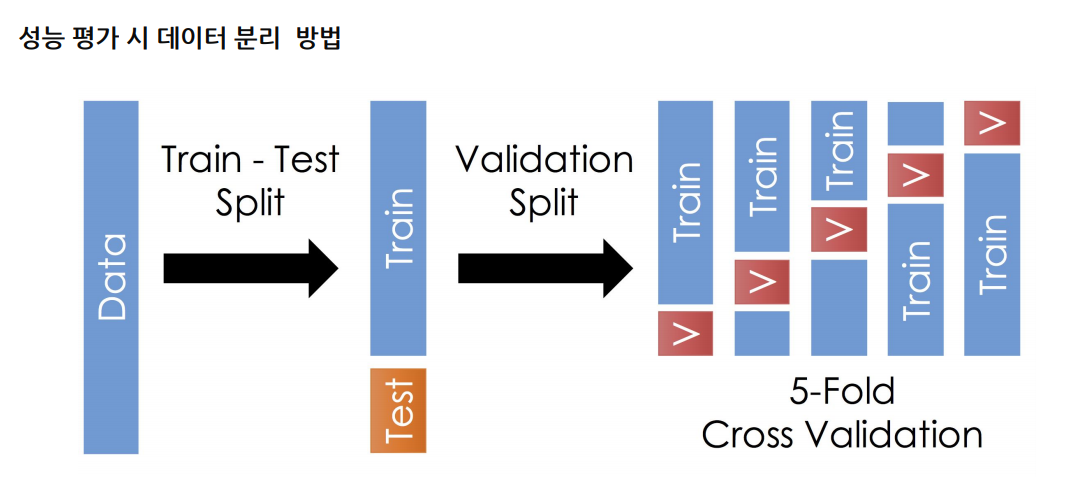
성능평가시 데이터 분리방법
모델 성능이 올라감에 따라,pre-trained model로 inference한 결과를 평가에 활용하는것이 효율적
- confidence level을 바탕으로 train,testset을구성
- 모델의pseudo-label을 활용해 Human-In-the-Loop으로 annotation을진행
1.2 정량평가 & 정성평가
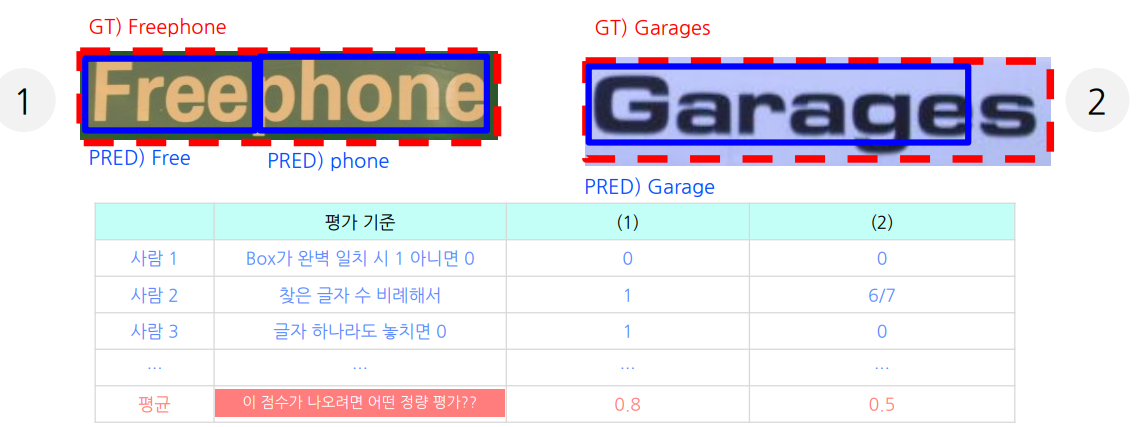
Question) OCR결과가 다음과 같은 경우에 점수를 매겨본다면?
2.글자 검출 모델 평가방법
2.1 글자검출 모델평가
1단계 : 테스트 이미지에 대해,결과값을 뽑습니다.
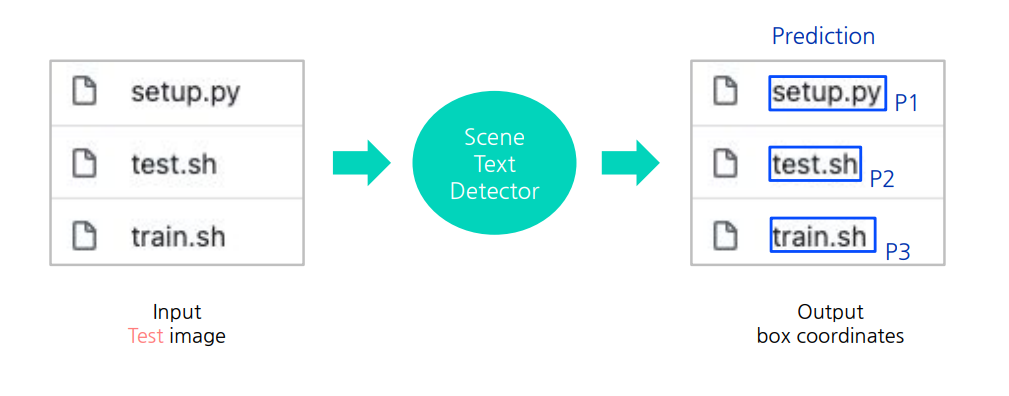
2단계 : 예측결과와 정답간매칭 / 스코어링과정을 거쳐 평가합니다.
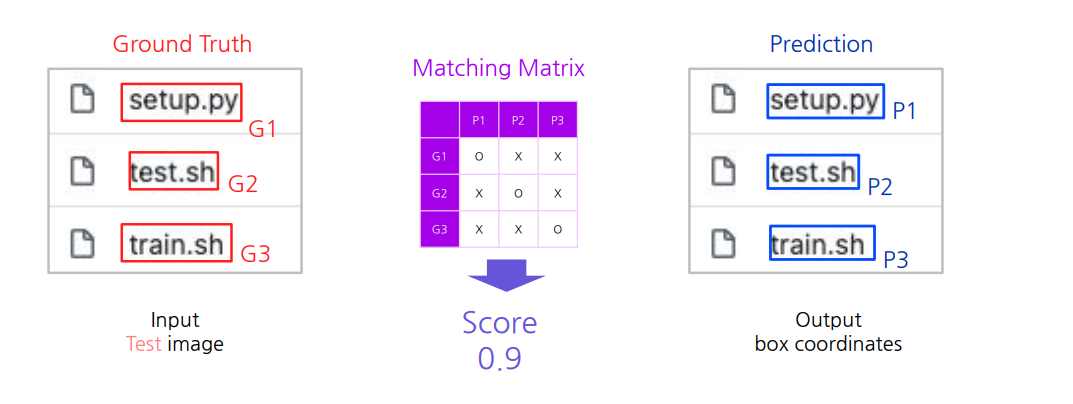
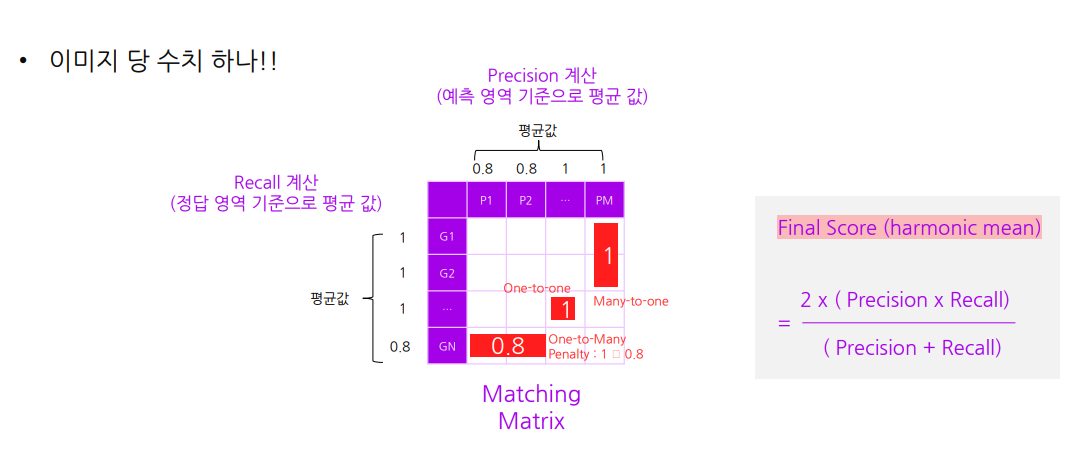
정리하면..
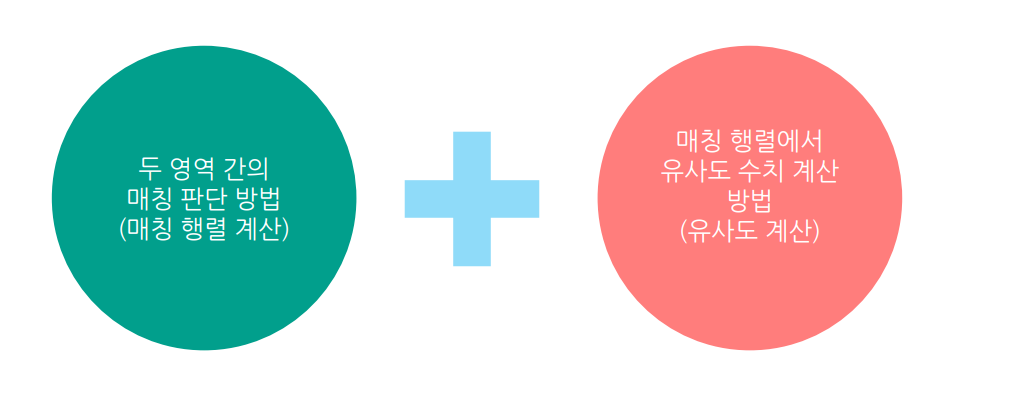
매칭되는지 확인하고 -> 유사도 계산 하는 것.
2.2 Glossary
IoU(Intersection of Union)
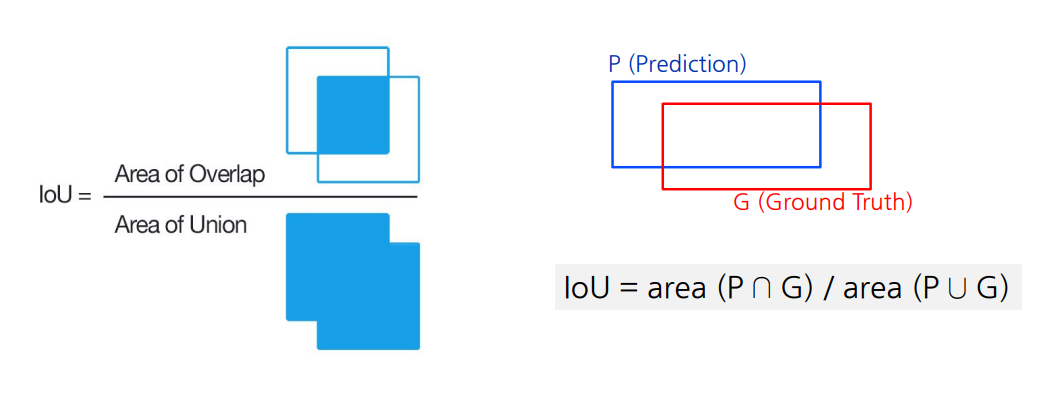
Area Recall/ Area Precision

One-to-One|One-to-Many|Many-to-One Match
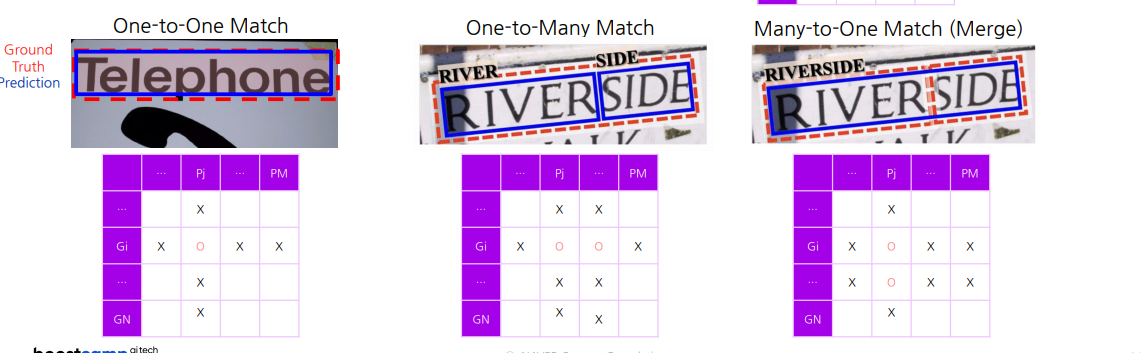
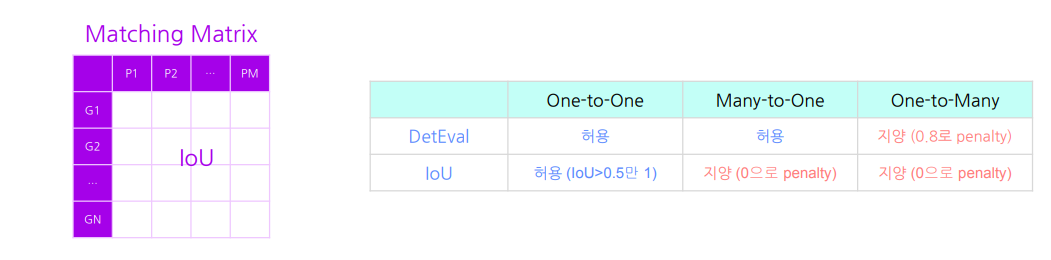
2.3 DetEval(Detection Evaluation)
GT
Detected
recall
precision
=> 모든 정답 영역, 예측 영역 간의 매칭 정도 계산. 각 관계당 area recall, area precision 두 개의 수치 확보
overlap matrice
is the constraint on area reall
is the constraint on area precision
=> binary scoring 으로 조건을 충족시키면 1 아니면 0
DetEval은 하나의 예측 bbox가 여러 정답 bbox와 매칭되는 것(merge)은 허용하지만, 여러 개의 예측 bbox가 하나의 정답 bbox와 매칭되는 것(split)은 페널티를 준다. -> 이는 실제 상황에서 발생할 수 있는 유효한 검출을 과소 평가하게 될 가능성이 있다.
2.4 IoU(Intersection of Union)
IoU는 one-to-one match 만 허용하고 IoU value > 0.5 -> correct if not -> incorrect
example
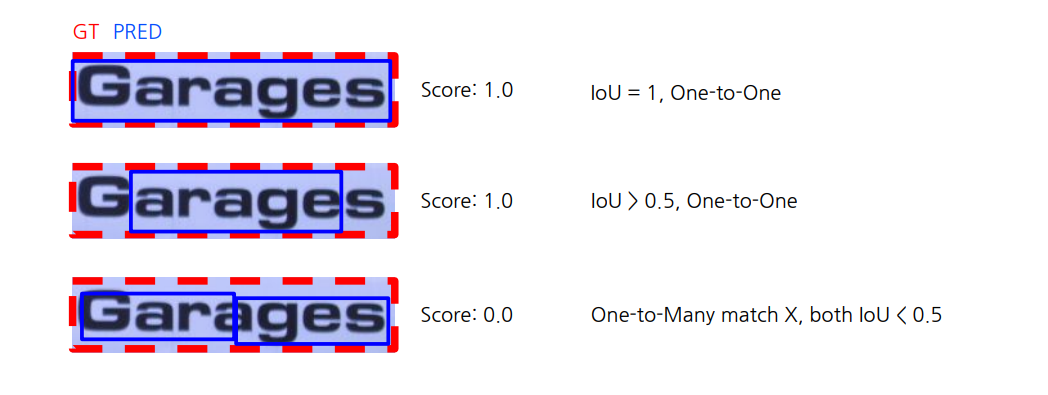
첫번째 예시를 보면, 하나의 GT에 하나의 Predict 가 되었으므로 이상적으로 잘 검출되었다.
두번째 예시에서, 하나의 GT에서 부분적으로 Predict 가 되었지만 Threshold >0.5 이상이므로 통과되어서 score는 1.0
마지막 예제는, 하나의 GT에서 여러개의 box가 predict 되었다. 이는 각각 IoU가 낮아서 잘 되지 않음을 알 수 있다.
2.5 TIoU(Tightness - aware IoU)
논문 : https://arxiv.org/abs/1904.008130
부족하거나 초과된 영역 크기에 비례하여 IoU점수에 대해 penalty를 부여.
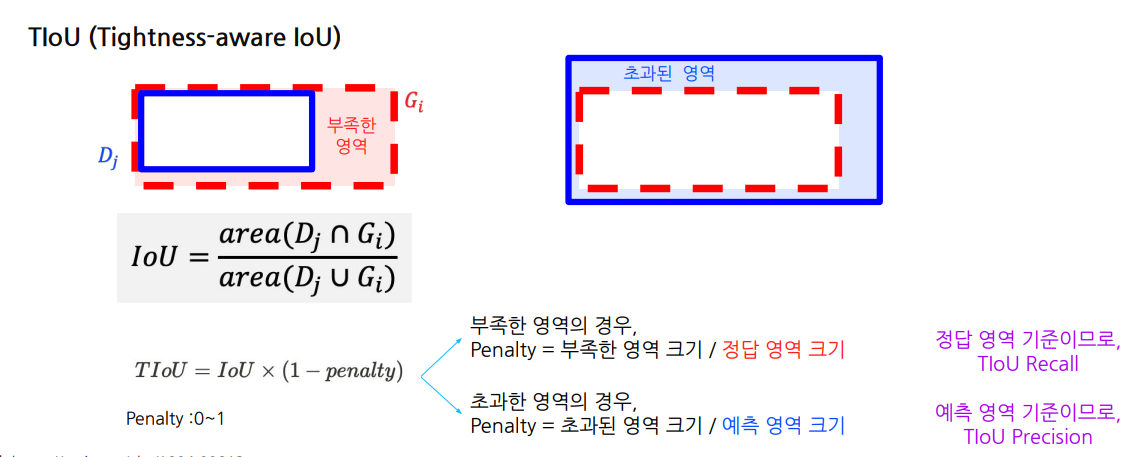
👉 TIoU는 IoU에 부족하거나 초과된 영역을 반영하여 더 정확하게 예측의 타이트함을 평가할 수 있는 지표입니다. 이를 통해 객체 검출의 정확도를 더욱 정밀하게 평가할 수 있습니다.
example & Drawbacks

여기서 두번째와 세번째를 비교해봤을때, 2번째는 Garage라는 text를 완벽하게 했지만 부족한 공간이 있어서 penalty를 받은 반면에 3번째는 인식공간은 좋지만 text를 완벽하게 못했다.
하지만 상식적으로 두번째가 더 좋은 점수를 받아야 하는데 score 점수는 똑같다. 이러한 한계점이 존재한다. -> 이때문에 CLEval 이 탄생하였다.
2.6 CLEval(Character-Level Evaluation)
논문 : https://arxiv.org/abs/2006.06244
얼마나 많은 글자(Character)를 맞추고 틀렸느냐를 가지고 평가.
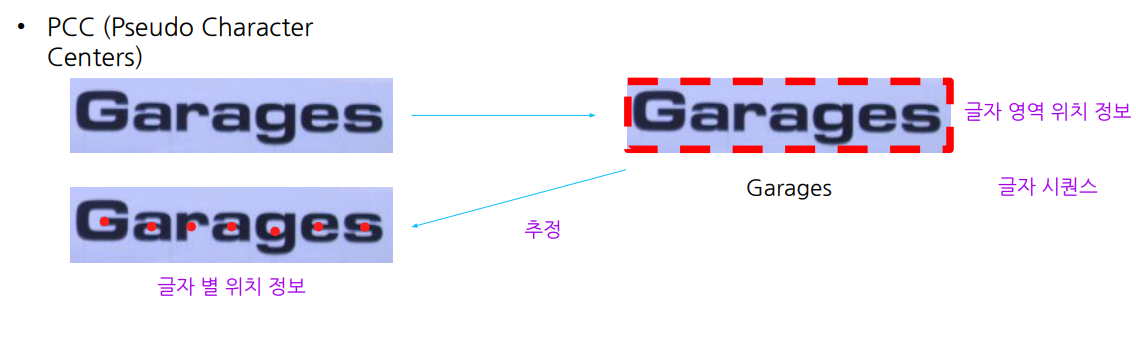
전체 글자 위치 정보를 추출하여 -> 글자 별 위치정보를 추출한다. 이를 통해 전체 단어의 배치 추정
즉 , Pseudo Character Centers (PCC)는 텍스트 인식에서 글자 각각의 위치를 바탕으로 전체 단어의 배치를 추정
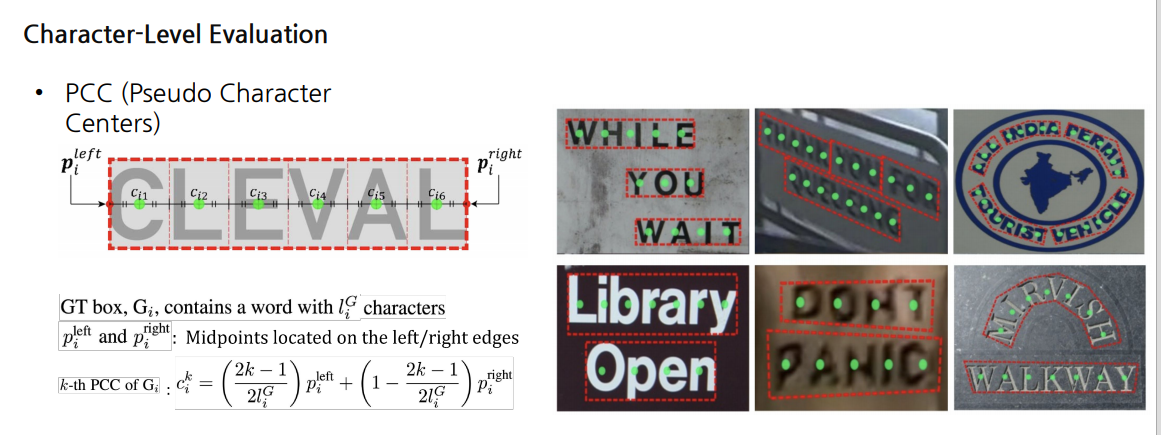
- : 박스 에 있는 글자의 총 갯수
- :박스 의 왼쪽 오른쪽 경계점의 중간위치

Matching Matrix : 각 예측 문자(,..) 와 실제 문자 의 일치를 나타내는 매트릭스
각 셀에 대한 일치도를 점수로 계산
-> 위 이미지에서는 각문자영역을 예측한 결과와 실제 문자 위치를 비교하는 과정을 보여줌.
2.7 Summary of Metrics

