🧢이번글에 대한 소개
- 이번 글 에서는 Improving Language Understanding by Generative Pre-Training 논문을 리뷰하고자 합니다.
🧢GPT1
1. Introduction
1.1 Annotated resource problem & Semi-supervised Learning
- NLP에서 대부분의 딥러닝 모델은 상당한 양의 수작업된 labeled 데이터가 필요하다. 이런 상황 때문에 많은 Domain에서 annotated resource 문제를 겪고 있다.
- 이런 상황에서 model이 unlabeled data로부터 언어학적 정보를 추출(leverage)할 수 있다면 annotation resource를 줄일 수 있을 것이다.
- 더욱이, 위의 상황에서 상당한 양의 지도학습이 가능하다면, 비지도 학습에서 학습한 good representaion이 더 좋은 성능을 낼 것이다.
1.2 problems in Semi-supervised Learning
- unlabeled text로부터 단어 수준 이상의 정보를 추출(leverage)하는데 2가지 문제가 있다.
- Text representation을 학습할 때 어떤 목적함수가 Transfer 과정에서 효과적인지 불명확하다.
- 비지도 학습으로 학습된 모델을 Target Task에 효과적으로 Transfer 할 수 있는 consensus가 없다.
1.3 Unsupervised pre-training + Supervised fine-tuning
- 본 논문에서는 unsupervised pre-training과 supervised fine-tuning으로 결합된 semi-supervised 접근을 제안한다.
- 본 논문의 목표는 unsupervised pre-training으로 universal representation을 학습한 이후 약간의 변형을 통해 다양한 Task들을 해결하고자 한다.
- 또한, unsupervised pre-training에서 사용되는 unlabeled corpus와 supervised fine-tuning을 진행하는 Target Task가 같은 domain일 필요가 없다.(다양한 domain에 적용될 수 있는 일반화된 pre-trained 모델을 생성했다.)
1.4 2 Stage Procedure
- GPT1을 학습하기 위해 두 단계를 거친다.
- Unsupervised pre-training : language modeling을 통해 unlabeled data로 모델의 초기 파라미터를 학습.
- Supervised fine-tuning : Target Task에 부합하는 labeled data로 supervised fine-tuning을 진행해 파라미터를 업데이트.
2. Related Work
2.1 Semi-supervised Learning for NLP
-
word-level embedding
- NLP에서 Semi-supervised Learning의 초기 연구는 단어 단위, 구문 단위의 통곗값을 계산하여 지도학습의 feature로 사용하는 방식으로 연구가 진행되었다. 지난 몇 년간의 연구들은 라벨 되지 않은 말뭉치를 사용하여 word embedding을 했을 때 다양한 테스크에서 좋은 성능을 보임을 입증했다. 하지만 이런 연구들은 주로 단어 단위의 정보를 전달하고 있으며 본 논문은 더 고차원의 의미를 추출하는데 목표를 두고 있다.
-
Pharse-level or Sentence level Embedding
- 최근에는 라벨 되지 않은 말뭉치를 사용하여 구문 단위, 문장 단위의 임베딩을 하여 텍스트를 Target task를 풀기 위한 적절한 vector representation으로 인코딩할 수 있게 되었다.
2.2 Unsupervised pre-training
- Purpose and Advantages of Unsupervised pre-training
- Unsupervised pre-training은 semi-supervised learning의 특별한 케이스로서 지도학습의 목표(objective)를 수정하지 않을 수 있도록 좋은 초기화 포인트를 제공하는데 목적을 두고 있다.
- 후속 연구에 따르면 사전 훈련은 정규화 역할을 하며 모델의 일반화에 도움을 준다.
2.3 Auxiliary training objectives
- Adding auxiliary training objectives
- 보조의 비지도 학습 목표를 추가해 주는 것은 준 지도 학습의 대안 형태로 사용된다.
- 최근 연구(Rei)에 따르면 sequence labeling 과제에서 language modeling 보조 목표를 더했을 때 더 좋은 성능을 보여줬다.
- 본 논문에서도 auxiliary objective를 사용하지만 unsupervised pre-training이 이미 Target Task에 관련된 언어학적 특성들을 학습했음을 보여준다.
3. Framework
- GPT은 총 2단계를 거쳐 학습된다.
- Unsupervised pre-training : 대량의 텍스트 말뭉치를 사용하여 언어 모델을 학습한다.
- Supervised fine-tuning : 라벨링 된 데이터를 사용하여 모델을 Target Task에 맞춰 학습한다.
3.1 Model Architecture
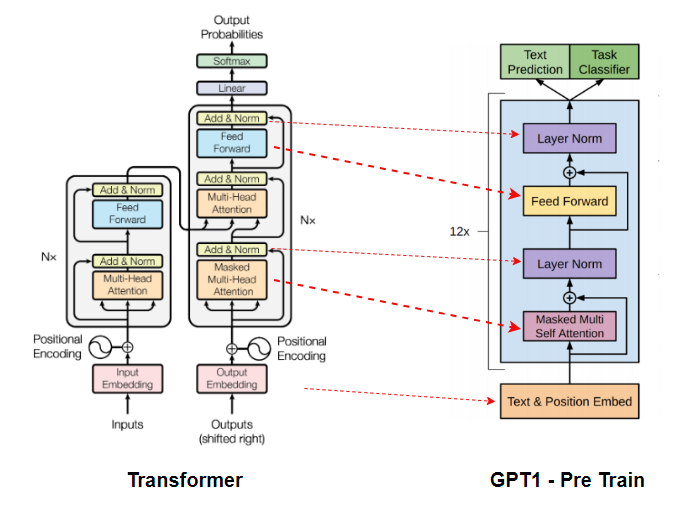
- Using Transformers decoder
- GPT-1에서는 Transformer의 Decoder 부분만 사용합니다. Transformer의 Decoder는
Masked Multi Head Self Attention,Encoder-Decoder Multi Head Attention,position-wise feedforward layer로 구성되어 있는데 GPT-1에서는Encoder-Decoder Multi Head Attention를 제외한Masked Multi Head Self Attention과position-wise feedforward layer로만 구성되어 있습니다. - Transformer에 대한 자세한 설명은 여기에 있습니다.
- "왜 인코더를 제외했을까?(더 고민하고 추가하겠습니다.)"
- GPT-1에서는 Transformer의 Decoder 부분만 사용합니다. Transformer의 Decoder는
3.2 Unsupervised pre-training
- Next word prediction
- Unsupervised pre-training은 다음 단어를 맞추도록 학습합니다. 예를들어 "나는 오늘 아침에 김치찌개를 먹었다."라는 문장이 있을 때, {"나는", "오늘", "아침에", "김치찌개를"}이 주어지면 "먹었다"를 예측하도록 학습합니다.
- 토큰으로 구성된 말뭉치 가 주어졌을 때 아래의 MLE를 구합니다.
-
Multi-layer Transformer decoder
- GPT-1의 사전 훈련은 Transformer의 decoder 부분을 사용하며 아래와 같은 과정을 거칩니다.
-
문맥 벡터 에 token embedding matrix를 행렬곱하고 position embedding matrix를 더하여 위치정보를 입력해준다.
- GPT1의 Positioinal Embedding Matrix()는 Transformer와 달리 학습 가능하도록 설정하였습니다. 이를 통해 조금 더 유연하게 포지션 정보를 입력할 수 있습니다.
-
를 Transformer Decoder block에 입력하고 을 출력해준다. Decoder block이 총 n개가 있다면 이를 n번 반복하여 을 출력한다.
-
최종 출력 에 token embedding matrix의 전치행렬을 곱하고
softmax함수를 통해 예측하려는 토큰에 대한 output distribution을 출력한다.
3.3 Supervised fine-tuning
-
Supervised fine-tuning
- 사전 훈련된 모델을 사용하여 Target Task를 학습합니다. 이때, 라벨이 있는 데이터를 사용하여 지도학습을 진행합니다. 또한, 사전 훈련 모델에
Linear Layer를 추가하여 Target Task를 맞추도록 학습합니다.
- 사전 훈련된 모델을 사용하여 Target Task를 학습합니다. 이때, 라벨이 있는 데이터를 사용하여 지도학습을 진행합니다. 또한, 사전 훈련 모델에
-
Little Structure Modification
-
입력 데이터를 사전 훈련된 모델에 입력하고 Transformer의 마지막 블록에서 활성화 함수를 거친 을 출력합니다. 이를, 파라미터 를 갖는
Linear Layer에 입력하고 나온 결과를softmax함수를 거쳐 확률로서 표현합니다. -
Supervised fine-tuning의 MLE는 아래와 같습니다.
-
-
Add Auxiliary objective
- fine tunning 과정에서 auxiliary objective를 추가하면 지도학습 모델의 일반화 능력을 향상시키고, 모델 수렴을 가속화를 도와준다.
- fine tunning 과정에서 language modeling의 objective를 더하여 사용하였다.
3.4 Task-specific input transformations
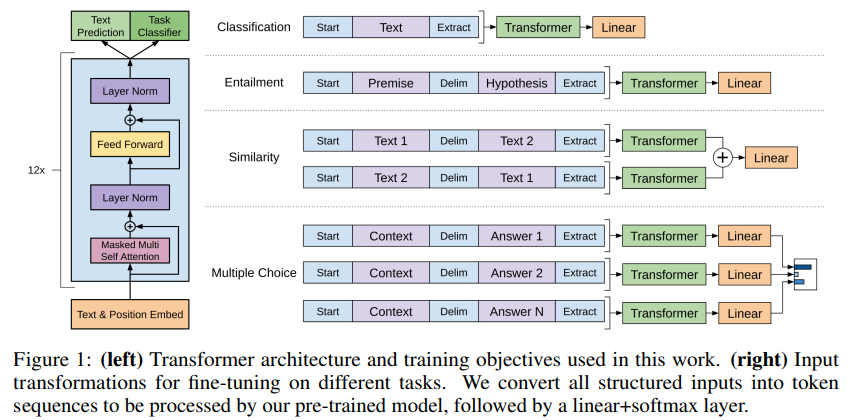
-
: start token, : end token, : delimiter token
-
Input data : Traversal-style approach
- Target Task 마다 주어지는 입력 데이터의 특징들이 다르다. GPT-1에서는 Traversal-style의 접근 방식을 사용하여 구조화된 입력값들을 연속적으로 붙여서 입력 데이터를 구성했다.
- 이런 접근 방식을 통해 모델 구조를 크게 변형할 필요가 없어졌다.
- 아래에서는 각 테스크별로 어떻게 입력 데이터를 변형했는지 설명한다. 모든 변형된 문장의 앞뒤에는 , 를 붙여준다.
-
Classification
- Text를 분류하는 문제로서 대표적으로 스펨 메일 분류 문제가 있다.
- 단순히 입력 문장을 모델에 입력으로 넣어준다.
- Input : + Text +
-
Textual entailment
- 2개의 문장을 입력받아 두 문장의 관계를 분류하는 문제이며 일반적으로 Entailment(함축), Contrafiction(모순), Neutral(중립)을 구분합니다.
- 첫 번째 문장(Premise)에 구분자 를 붙여준 뒤 두 번째 문장(Hypothesis)을 붙여서 만들어 줍니다.
- Input : + Premise + $ + Hypothesis +
-
Similarity
- 2개의 문장의 유사 정도를 측정하는 문제이며 두 문장의 선후관계가 존재하지 않습니다. 따라서 단순히 Textual entailment처럼 구성한다면 첫 번째 문장이 두 번째 문장에 선행한다는 오해를 할 수 있으므로 "Tex1 $ Text2", "Text2 $ Text1"과 같이 번갈아 가며 두 개의 문장을 생성해 주고 각각 Transformer 모델에 입력해 줍니다.
- Transformer 모델에서 나온 결과를 element wise 합을 계산해서 합쳐줍니다.
- Input1 : + Text1 + $ + Text2 +
- Input2 : + Text2 + $ + Text1 +
-
Question Answering and Commonsense Reasoning
- 질문에 대한 대답, 상식적 추론 문제는 Multiple Choice 문제입니다.
- 문제 상황에 대한 문맥(z)과 질문(q) 그리고 대답들({})로 구성되어 있습니다.
- 각 대답 에 대해 각각 를 생성하고 Transformer 모델에 독립적으로 학습한 뒤 Linear Layer를 거쳐 softmax로 확률값을 계산합니다.
- Input_k : + Context + Question + $ + Answer_k +
4. Experiments
4.1 Setup
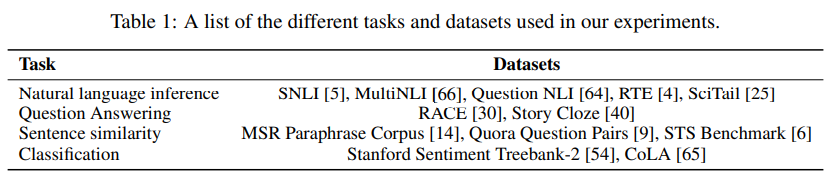
- Dataset
- 사용하는 데이터셋의 정보는 아래와 같다.
-
Model specifications
parameter Description State dimension decoder: 768, inner state: 3072 Batch size 64 random sample × 512 token/sample Schedule 100 epochs Optimizer Adam Learning Rate 0~2000 step까지 2.5e-4까지 증가, 이후 cosine 함수를 따라 0으로 서서히 감소 warmup_steps 4000 Regularization L2(=0.01) Activation GELU(Gaussian Error Linear Unit) 표 출처 사이트 링크 -
Fine Tuning details
- 비지도 사전학습에서 사용한 hyperparameter를 그대로 사용했다. classifier에 dropout을 0.1 비율만큼 적용하였다. 대부분에 테스크에서 learning rate를 6.25e-5로 사용했고 batch size는 32로 설정했다.
- 대부분의 테스크에서 3 epoch이면 충분히 fine tunning 되었다. 학습당 0.2%의 warmup과 를 적용한 linear learning rate decay 스케쥴러를 사용하였다.
4.2 Supervised fine-tunning
-
GPT-1의 실험결과는 다음과 같습니다.
-
Natural Language Inference
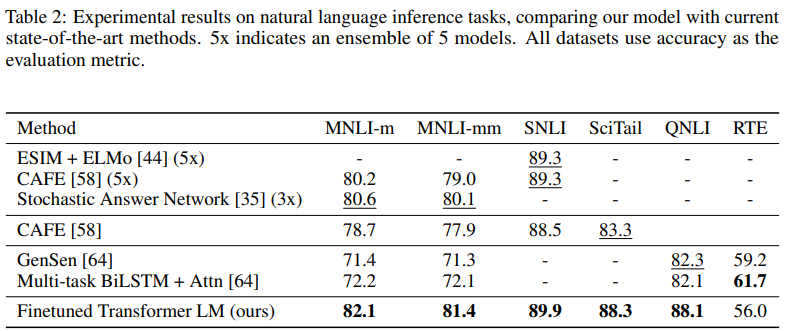
- 모든 데이터셋에서 기존 방법들보다 좋은 성능을 보여줍니다. RTE 데이터셋은 뉴스 기사 데이터셋으로 데이터의 개수가 적은 특징을 가지고 있습니다.
-
Question answering and commonsense reasoning
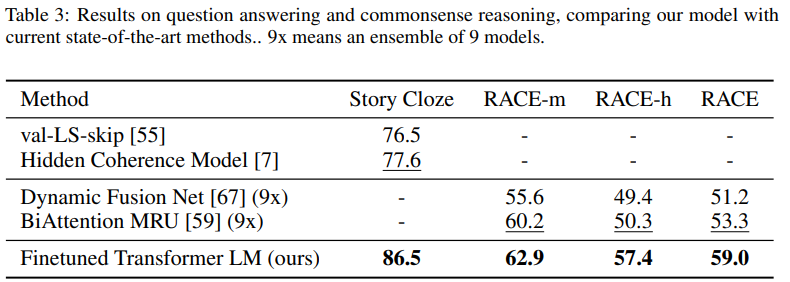
- 모든 데이터셋에서 기존 방법들 보다 좋은 성능을 보여줍니다.
-
Semantic Similarity & Classification
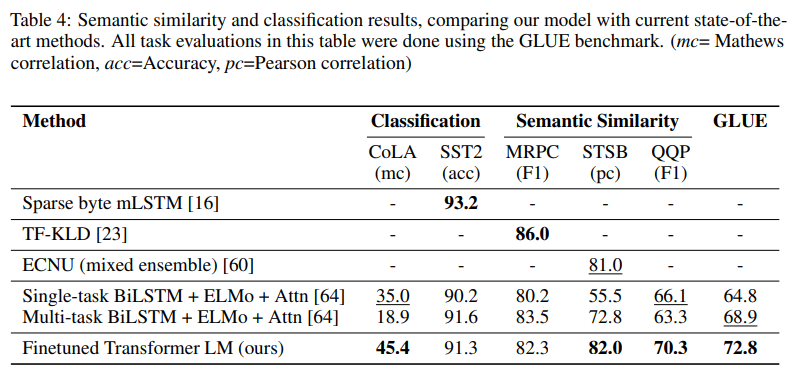
-
대체로 좋은 성능을 보여주고 있습니다.
-
5. Analysis
-
Impact of number of layers transferred & Zero-shot Behavior
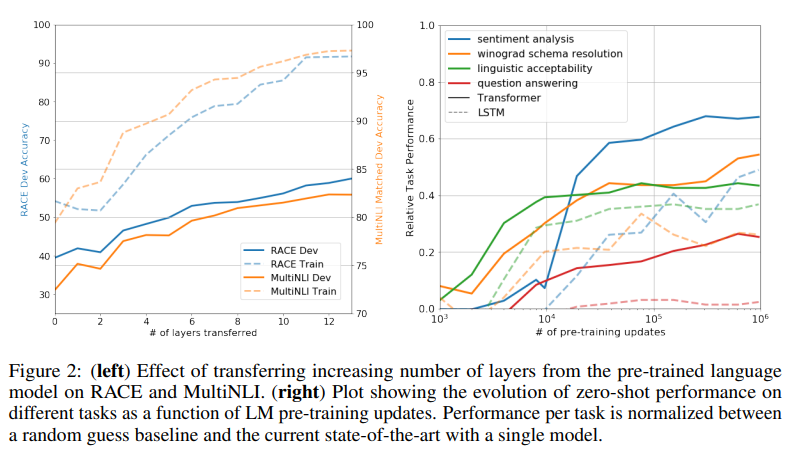
- Impact of number of layers transferred : 왼쪽 그래프를 통해 사전 훈련에 사용한 Layer의 개수가 많아질수록 더 좋은 성능을 보여준다는 것을 알 수 있다. 이는 사전 훈련된 정보를 더 많이 사용할수록 성능이 좋다는 것과 Pretrained Model이 Target Task를 해결하기 위한 유용한 정보들을 많이 가지고 있다는 것을 의미한다.
- Zero-shot Behavior : 오른쪽 그래프에서 대부분의 과제에서 Pre-Training을 많이 할수록 성능이 좋아진다는 것을 알 수 있습니다. 이를 통해 Pre-Training 과정이 Target Task를 해결하는 데 도움이 된다는 것을 알 수 있습니다. 또한, Transformer 구조가 LSTM 구조보다 더 좋은 성능을 낸다는 것을 알 수 있습니다.
-
Ablation Studies
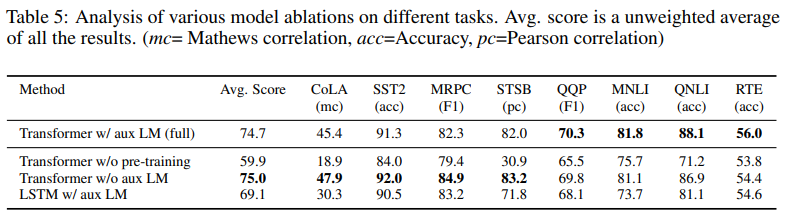
- 본 논문에서는 3가지 추가실험을 진행했다.
- Auxiliary LM objective Effect
- auxiliary LM objective을 제외하고 fine-tuning을 진행해 보았다. 이를 통해, auxiliary objective가 NLI와 OOP를 수행하는 데 도움이 되는 것을 확인했다. 또한, 대량의 데이터셋에 대해서는 auxiliary objective가 도움이 되지만 작은 데이터셋에서는 그렇지 않다.
- Transformer Effect
- Transformer와 같은 형태의 2048 layer의 LSTM으로 대체하여 분석하였다. 이를 통해 거의 모든 과제에서 Transformer가 LSTM보다 우세하다는 것을 알 수 있었다.
- Pre-Training Effect
- 사전 훈련 없이 지도 학습만 진행해 보았다. 이를 통해 Pre-Train을 진행한 LM이 Target Task를 더 잘 수행할 수 있다는 것을 알 수 있었다.
🧢Reference
- Improving Language Understanding by Generative Pre-Training
