🧢이번글에 대한 소개
-
이번 글 에서는 Attention is All You Need' 논문과 텐서플로 2와 머신러닝으로 시작하는 자언어 처리 (개정판) 책을 참고하여 자연어처리에서 두곽을 나타내고 있는 Transformer 모델을 이해하는데 방점을 두고 있습니다.
-
글의 내용은 참고 문헌의 내용과 저의 방식으로 이해하는 과정을 담고 있습니다. 자연어 처리 공부를 하며 많은 도움이 되었기에 다른 분들께 추천드리며, 책을 쓰신 저자분들께 감사의 말씀을 드립니다.
-
제가 참고한 책의 표시를 추가하면 아래와 같습니다.

🧢Transformer
1. Introduction
- 순환신경망은 모델 구조상 문장 내의 단어를 순차적으로 학습 시키기 때문에 긴 문장에 대한 정보를 잘 처리하지 못하는 문제점을 가지고 있다. Seq2Seq모델에서 사용된 Attention 구조는 이러한 문제들을 개선했지만 순환신경망의 일부로서만 사용되고 있었다.
- Transformer는 순환신경망이 없이 Attention으로만 이루어져 있으며 데이터를 평행하게(parallelization) 처리할 수 있고 문장 내 단어들 간의 관계를 잘 학습하여 좋은 성능을 보여주고 있다.
2. Model Architecture
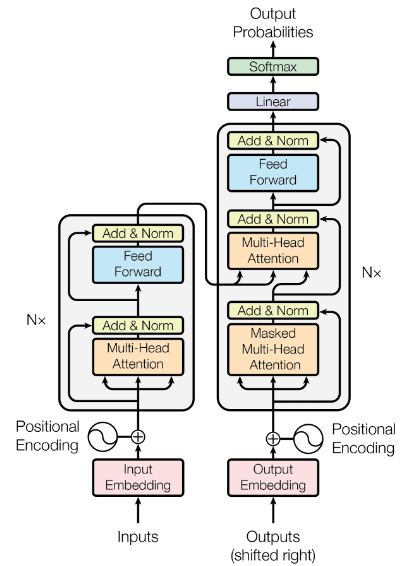
- Transformer는 Encoder와 Decoder로 구성되어 있습니다.
2.1 Encoder and Decoder Stacks
-
Encoder
- Encoder는 총 N개의 동일한 Layer로 구성되어 있고, 각 Layer안에는 Multi-Head Attention, Position-wise fully connected feed forward network라는 sub layer로 구성되어 있습니다. 또한 residual connection을 통해 각 sub layer를 normalization하는 과정을 거칩니다.
-
Decoder
- Decoder 또한 총 N개의 동일한 Layer로 구성되어 있고, 각 Layer 안에는 Encoder에 존재하는 2개의 sub layer에 추가로 Multi-Head Attention이 추가되어 있습니다. 추가된 Multi-Head Attention은 Encoder의 output을 이용하는데 사용됩니다. Encoder와 마찬가지로 residual connection을 통해 각 sub layer를 normalization합니다.
2.2 Attention
- 기존의 순환신경망 모델들은 sequence의 길이가 길어짐에 따라서 앞의 정보가 희석되는 문제와, gredient exploding, gradient vanishing 현상으로 인해 학습 정보를 잘 전달하지 못하는 Long-Term Dependency문제를 가지고 있었다. Transformer 모델에서는 Attention 기법을 사용하여 이를 극복하는 모습을 보여준다.
2.2.1 Scaled Dot-Product Attention
-
Attention은 Qeury, Key, Value Matrix를 통해 문맥 벡터(context vector)로 이루어진 Matrix를 출력합니다. Attention을 통해 문장 내 각 단어들에 대해서 단어들 간 상관관계 정보를 포함한 문맥벡터를 출력합니다.
-
Scaled Dot-Product Attention의 수식을 보며 연산과정을 살펴보면 다음과 같습니다.
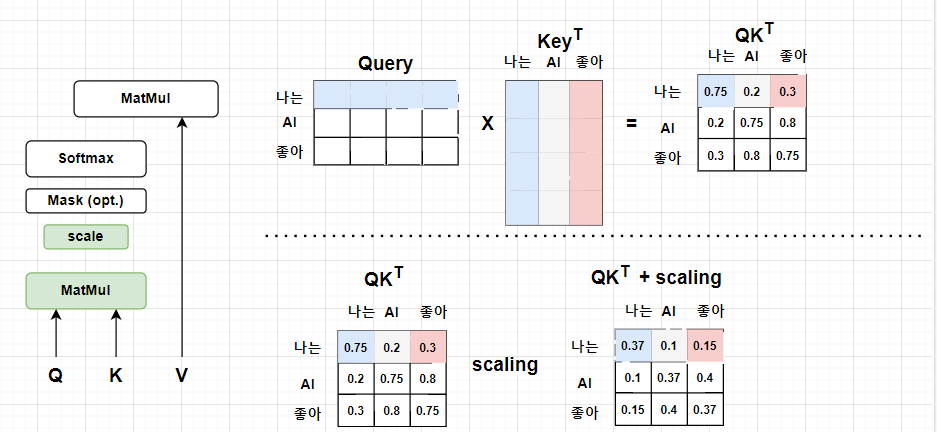
-
와 를 행렬곱하여 각 단어들에 대한 Attention Score를 계산한다.
-
Attention Score에 대해서 만큼 스케일링을 적용해준다. (scaled Dot-Product Attention)
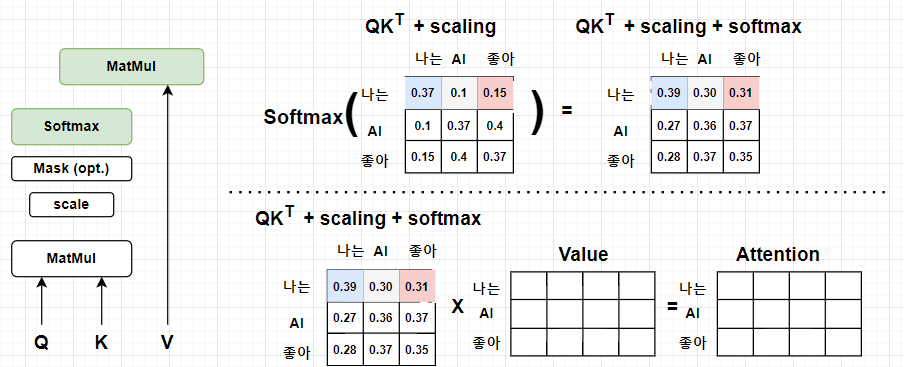
- Attention Score에 softmax함수를 적용해서 어텐션 스코어를 확률값으로 계산한다.
- Attention Score와 를 행렬곱하여 각 단어에 대한 Context vector로 이루어진 Attention값을 도출한다.
- Attention은 순환신경망에서 사용한 순차적으로 단어의 정보를 받는 방식이 아닌 한번에 모든 단어들의 유사도를 구하는 방식을 통해 Long-Term Dependency 문제를 극복했습니다.
- Attention은 어떻게 문맥벡터를 학습할 수 있을까?
Attention으로 도출된 각 단어 vector들이 문맥을 고려할 수 있는 이유에 대해 생각해보고 낸 생각을 다음과 같습니다.
1. 를 통해 각 단어들이 가지는 상관 관계정보를 계산한다.
2. 를 통해 각 단어들의 상관 관계정보를 확률로서 표기한다.
3. 를 통해 의 각 단어 벡터들이 에 의해 계산된 단어들의 상관관계정보를 학습할 수 있게 됨.
추천시스템의 코사인 유사도기반 collaborate filtering의 아이디어와 유사하다고 생각했습니다.
- 왜 로 Scaling을 했을까?
- 와 의 단어벡터들의 내적연산을 통해 의 스칼라 값이 도출되는데, 각 벡터의 차원수 가 크다면 내적연산에 관여하는 차원의 수가 증가하고 값도 증가할 수 있다.
- 이때, 의 원소들의 분포가 평균 0, 분산 1이라고 한다면, 내적값 의 평균은 0, 분산은 , 표준편차는 가 된다.
- 만약, 가 2라면 는 1.4정도의 값으로 의 값은 -1.4 ~ 1.4정도 에서 값이 형성이 되며 softmax 함수를 취했을 때 uniform한 모습을 보여줄 수 있다.
- 하지만, 가 100이라면 는 10으로 의 값은 -10 ~ 10 사이에서 값이 형성되며 softmax 함수를 취했을 때 너무 크거나, 너무 작은 모습을 보여줄 수 있다. 이는 Backpropagation 과정에서 gradient vanishing 문제를 야기한다.
- 이런 점을 고려했을 때, 표준편차 를 나눈 값을 사용한다면 평균 0, 분산 1으로 에 상관없이 안정적인 분포를 띄게 학습할 수 있다.
2.2.2 Multi-Head Attention
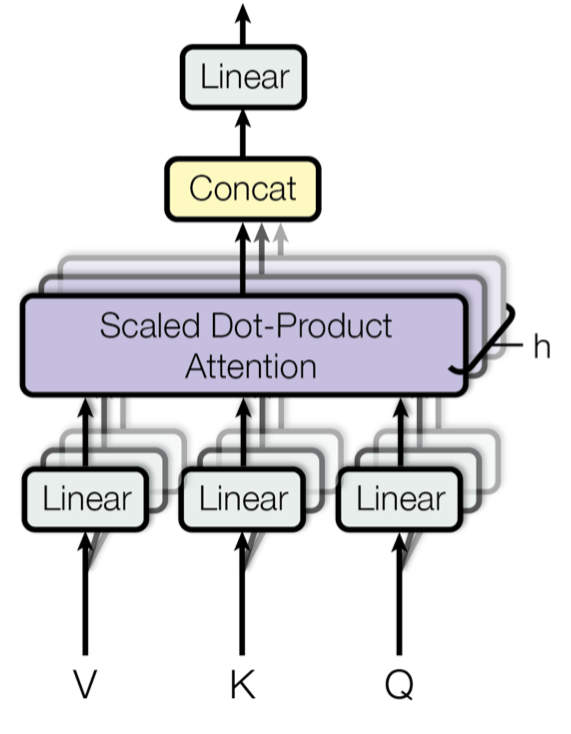
- Transformer에서는 여러개의 Attention을 계산하여 결합하는 Multi-Head Attention을 제안합니다.
- 차원의 에 개의 선형변환 을 병렬적으로 결합하여 배 낮은 차원, 를 갖는 , , 를 개를 생성합니다. 그리고, 이를 각각 Attention계산후 결합하여 Multi-Head Attention을 도출합니다.
- 같은 입력 Matrix()에 대해 각기 다른 선형변환 를 취해주는 병렬적인 Attention계산을 통해 서로다른 표상공간(representation space)를 학습할 수 있습니다.

- 또한, 선형변환이 없었다면 와 로 도출되는 유사도 Matrix는 각 단어가 자기자신과 가장 높은 유사도를 보이는 Matrix로 반환될 것 입니다. 이는, 각 단어가 자신에 대한 정보만 많이 포함하고 있고 문맥을 고려했을 때 중요한 정보를 포함하지 못할 가능성이 높습니다.
- 이를 고려하여 Transformer의 Attention연산에서는 학습이 가능한 선형변환 과정을 추가하여 문맥정보를 반영할 수 있도록 추가적인 장치를 제공했습니다.
2.2.3 Applications of Attention in out Model
- Transformer구조에는 총 3개 유형의 Attention Layer가 사용됩니다.
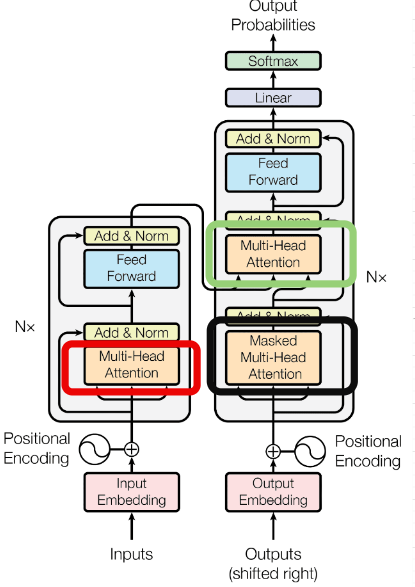
- Encoder-Decoder attention(초록 네모칸)
- 는 이전 Decoder layer에서 입력받고, 는 마지막 Encoder Layer의 출력값으로 받습니다.
- 이를 통해 모든 Decoder Layer는 Input Sequence의 모든 위치정보를 참조할 수 있습니다.
- Self-attention in Encoder(빨간 네모칸)
- Encoder Layer에서 사용되는 Attention으로서 각 단어들의 관계정보를 학습한 문맥벡터를 학습합니다.
- 이전 Encoder Layer의 출력값으로 를 입력받습니다.
- Self-attention in Decoder(검정 네모칸)
- Self-attention in Encoder와 유사하게 이전 Decoder Layer의 출력값으로 를 입력받습니다.
- 하지만, 여기에 추가로 이전 단어만 참조할 수 있도록 masking 작업을 추가합니다.
2.3 Position-wise Feed-Forward Networks
- Transformer는 Multi-Head Attention과 Normalization 이후 Feed Forward Network를 추가해주었습니다. 2개의 Linear Layer와 그 사이 하나의 ReLU 활성화 함수를 사용합니다.
- input과 output 모두 로 일치합니다.
2.4 Embeddings and Softmax
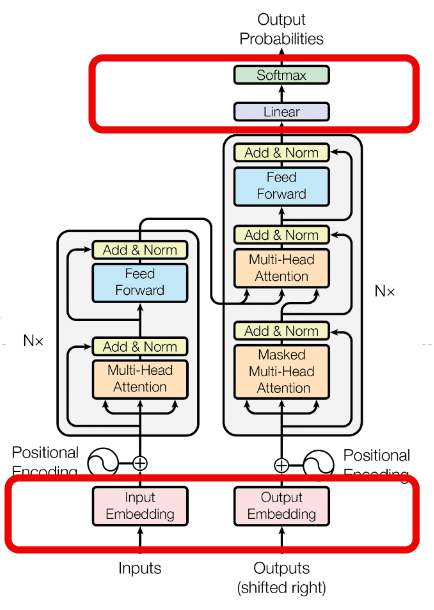
- Transformer 논문에서 사용된 Input Embedding과 Decoder 출력 이후 다음 token의 확률을 예측하는 Linear Layer는 사전학습된 embedding과 Layer를 사용했습니다.
- Learned Embedding을 통해 input, output token을 차원 벡터로 변환했습니다.
- 두개의 embedding layer와 pre-softmax linear Layer는 같은 가중치를 공유합니다.
2.5 Positional Encoding
- transformer model은 입력 데이터를 순차적으로 제공하는 것이 아니라 한번에 입력해주기 때문에 입력 시퀀스에 대한 정보를 추가로 넣어줘야 했습니다.
- "Positional Encoding" 은 트렌스포머 모델에 입력값의 순서 정보를 입력해주기 위해 사용한 방법으로서 아래와 같은 수식을 띕니다.
- 각 단어를 Embedding 했을 때 embedding된 데이터의 feature 인덱스가 짝수인 경우 함수 할당.
- 각 단어를 Embedding 했을 때 embedding된 데이터의 feature 인덱스가 홀수인 경우 함수 할당.
🧢고민하고 추가할 부분
- Position Encoding에서 함수는 어떻게 작동하는가?
🧢참고문헌
- 텐서플로 2와 머신러닝으로 시작하는 자언어 처리 (개정판)
- Attention Is All You Need
읽어주셔서 감사합니다.

AI, Data Scientist 취업 준비생 입니다. 공부한 내용을 포스팅하고자 합니다. 방문해주셔서 감사합니다