머리가 굳었다
📌 LeNet
- LeNet은 Yann LeCun에 의해 제안된 초기 Convolutional Neural Network(CNN)로, 주로 숫자 인식과 같은 이미지 분류 작업에 사용

🌝 입력 (Input):
크기: 32×32 (흑백 이미지)
형태: N×1×32×32
여기서 N은 배치 크기, 1은 채널 수(흑백 이미지), 32는 이미지의 가로와 세로 크기입니다.
🌝 첫 번째 레이어 (C1):
연산: 5×5 Convolution
커널 수: 6
스트라이드: 1
패딩: 0
출력 크기: N×6×28×28
계산: (32−5+0)/1+1=28
🌝 두 번째 레이어 (S2):
연산: 평균 풀링 2×2
출력 크기: N×6×14×14
계산: (28/2)=14
🌝 세 번째 레이어 (C3):
연산: 5×5 Convolution
커널 수: 16
스트라이드: 1
패딩: 0
출력 크기: N×16×10×10
계산: (14−5+0)/1+1=10
🌝 네 번째 레이어 (S4):
연산: 평균 풀링 2×2
출력 크기: N×16×5×5
계산: (10/2)=5
🌝 다섯 번째 레이어 (C5):
연산: 5×5 Convolution
커널 수: 120
스트라이드: 1
패딩: 0
출력 크기: N×120×1×1
계산: (5−5+0)/1+1=1
🌝 출력 (Output):
출력 크기: N×120×1×1
마지막 레이어의 출력 크기는 120×1×1입니다.
르넷의 특징은 3번째 layer에 있음!

📌 AlexNet
- 제일 처음으로 CNN 구조를 이용해서 full color를 사용함
- 메모리의 한계 때문에 network를 분리함
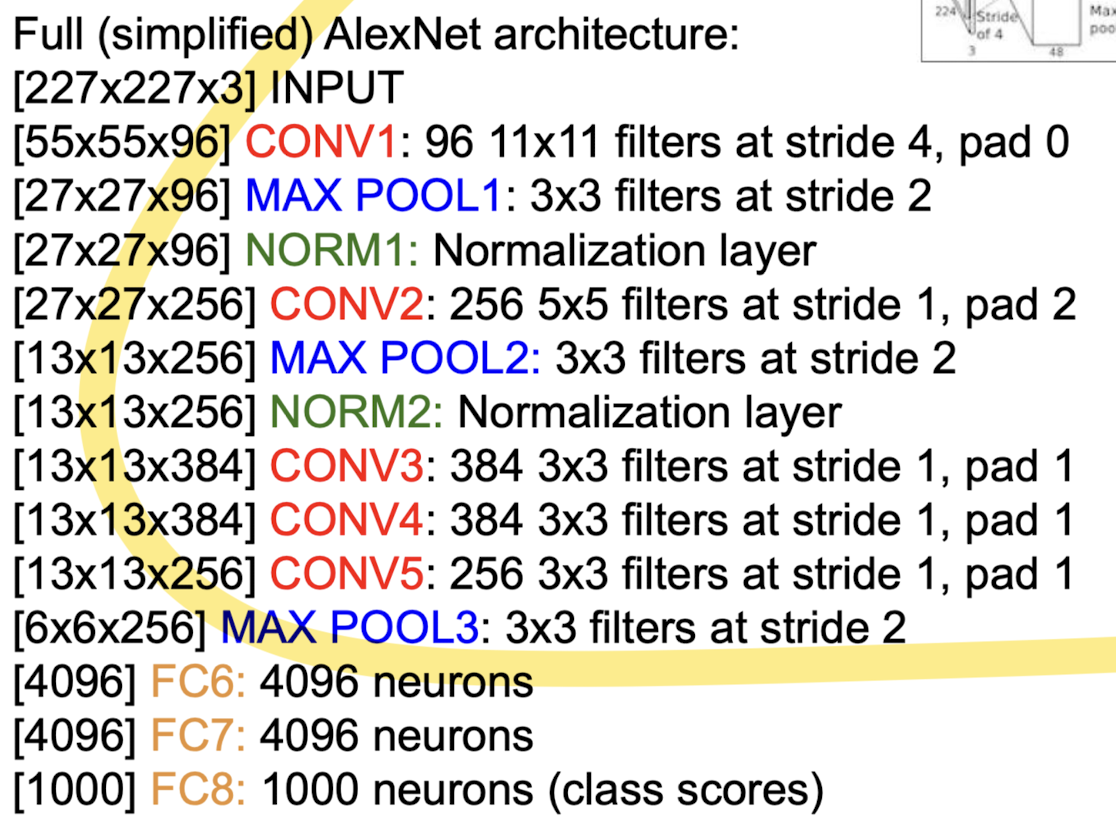
초기 신경망 연구의 문제점:
-
레이블링된 데이터셋의 크기:
- "Our labeled datasets were thousands of times too small."
- 초창기 신경망 연구에서는 레이블링된 데이터셋이 매우 작았습니다. 이는 모델이 충분한 데이터를 학습하지 못하게 하여, 일반화 성능이 떨어지는 결과를 초래했습니다.
-
컴퓨팅 파워:
- "Our computers were millions of times too slow."
- 당시의 컴퓨터는 매우 느렸습니다. 딥러닝 모델을 훈련시키기 위해서는 매우 높은 계산 능력이 필요하지만, 당시의 하드웨어는 이러한 요구를 충족시키지 못했습니다.
-
가중치 초기화 방법:
- "We initialized the weights in a stupid way."
- 초기의 연구에서는 가중치를 적절하게 초기화하는 방법이 부족했습니다. 잘못된 초기화는 학습을 방해하고, 모델이 지역 최적점에 빠지게 하거나 수렴 속도가 느려지는 문제를 일으켰습니다.
-
비선형성의 잘못된 선택:
- "We used the wrong type of non-linearity."
- 초기에는 시그모이드 함수와 같은 비선형 활성화 함수를 사용했습니다. 이러한 함수는 기울기 소실 문제를 일으켜 학습을 어렵게 만들었습니다.
현대 딥러닝의 성공 요인:
이미지 하단의 그림은 현대 딥러닝의 성공 요인을 보여줍니다.
-
대규모 데이터셋:
- "Big Data: ImageNet"
- 대규모로 레이블링된 데이터셋, 특히 ImageNet과 같은 데이터셋의 사용이 딥러닝 모델의 성능을 크게 향상시켰습니다.
-
딥러닝 아키텍처:
- "Deep Convolutional Neural Network"
- 복잡한 딥러닝 아키텍처, 특히 Convolutional Neural Network(CNN)의 발전은 이미지 인식과 같은 작업에서 매우 뛰어난 성능을 발휘하게 했습니다.
-
GPU를 통한 백프로파게이션:
- "Backprop on GPU"
- GPU의 사용은 딥러닝 모델의 훈련 속도를 비약적으로 증가시켰습니다. 대규모 병렬 처리를 통해 모델이 더 빠르게 학습할 수 있게 되었습니다.
-
학습된 가중치:
- "Learned Weights"
- 적절한 가중치 초기화 및 학습된 가중치는 모델이 더욱 안정적으로 수렴하게 하여, 더 나은 성능을 발휘하게 합니다.
ImageNet Large Scale Visual Recognition Challenge(ILSVRC)
그냥 대회
📌 ZFNet
- 큰 특징 없이 hyperparameter만 바꾼 ZFNet이 AlexNet보다 좋은 성능을 보임
- Modification of AlexNet
- CONV1: change from (11x11 stride 4) to (7x7 stride 2)
- CONV3,4,5: instead of 384, 384, 256 filters use 512, 1024, 512
ZFNet의 주요 공헌:
-
수동 작업으로 최적화된 아키텍처를 찾지 않음:
- "They did not find optimized architecture by manual labor."
- ZFNet의 아키텍처는 수동으로 최적화된 것이 아니라, 실험과 데이터에 기반하여 자동화된 방법으로 최적화되었습니다. 이는 신경망 구조의 설계에서 인공지능과 기계 학습을 더 많이 활용하는 방향을 제시했습니다.
-
DeconvNet 도구 소개:
- "They presented a very strong tool, named 'DeconvNet'."
- ZFNet은 DeconvNet(Deconvolutional Network)라는 강력한 도구를 소개했습니다. DeconvNet은 신경망의 내부 작동 방식을 시각화하는 도구로, 네트워크가 입력 이미지에서 무엇을 학습하고 있는지, 각 레이어가 어떤 특징을 추출하는지 이해하는 데 도움을 줍니다. 이 도구는 신경망의 해석 가능성을 높이는 중요한 기여를 했습니다.
-
시각화 결과에 기반한 AlexNet의 수정:
- "Modifications of AlexNet Based on Visualization Results."
- ZFNet은 시각화 결과를 통해 AlexNet의 구조를 수정하였습니다. 이를 통해 AlexNet의 성능을 더욱 향상시킬 수 있었습니다. 시각화는 신경망의 학습 과정을 더 잘 이해하고, 구조적인 문제를 발견하며, 이를 개선하는 데 중요한 역할을 했습니다.
📌 VGG NET

📌 GoogLe Net
GoogLeNet의 주요 특징:
-
깊은 네트워크:
- "Deeper networks, with computational efficiency"
- GoogLeNet은 22개의 레이어로 구성된 매우 깊은 네트워크입니다. 깊이를 늘리면서도 계산 효율성을 유지하는 데 중점을 두었습니다.
-
Inception 모듈:
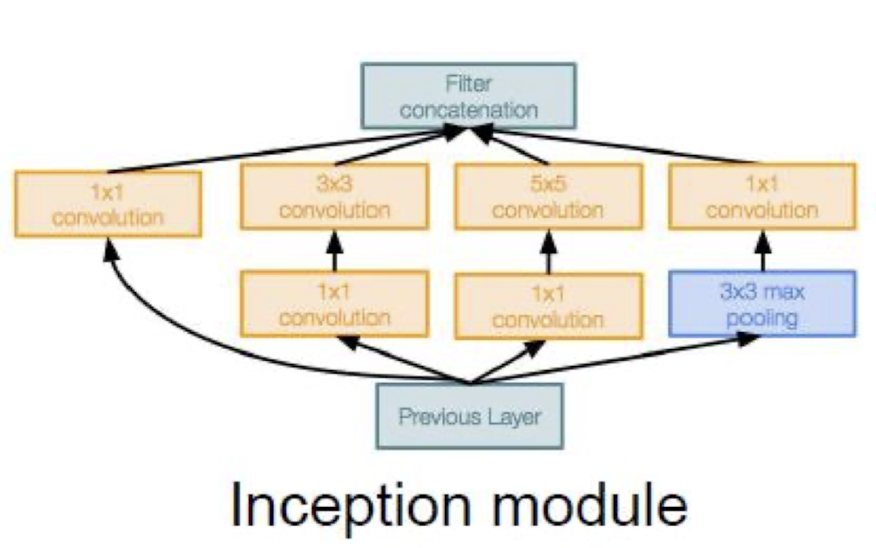
- "Efficient 'Inception' module"
- Inception 모듈은 다양한 크기의 필터를 동시에 적용하여 특징을 추출하고, 이를 결합하는 방식입니다. 이미지의 다양한 공간적 정보를 포착할 수 있도록 설계되었습니다. 이를 통해 네트워크의 표현력을 크게 향상시킬 수 있습니다.
-
FC 레이어 없음:
- "No FC layers"
- GoogLeNet은 전통적인 완전 연결층(fully connected layer)을 사용하지 않고, 대신 글로벌 평균 풀링(global average pooling)을 사용하여 파라미터 수를 줄이고 과적합을 방지합니다.
-
적은 파라미터 수:
- "Only 5 million parameters!"
- GoogLeNet은 약 5백만 개의 파라미터를 가지고 있습니다. 이는 AlexNet의 파라미터 수의 1/12에 불과합니다.
-
성능:
- "12x less than AlexNet"
- GoogLeNet의 파라미터 수는 AlexNet에 비해 12배 적습니다.
- "ILSVRC'14 classification winner (6.7% top 5 error)"
- GoogLeNet은 2014년 ILSVRC(Imagenet Large Scale Visual Recognition Challenge)에서 6.7%의 top-5 에러율로 우승했습니다. 이는 당시 기준으로 매우 높은 성능을 의미합니다.
Inception 모듈
이 모듈은 다양한 크기의 필터를 병렬로 적용하여, 입력 이미지의 다양한 공간적 정보와 규모를 동시에 포착합니다.
Inception 모듈은 다음과 같은 구성 요소로 이루어져 있습니다
- 1x1 Convolution: 크기를 줄이지 않고 채널 수를 줄이는 역할을 합니다.
- 3x3 Convolution: 중간 크기의 필터로 공간 정보를 추출합니다.
- 5x5 Convolution: 큰 크기의 필터로 더 넓은 영역의 정보를 추출합니다.
- 3x3 Max Pooling: 최대 풀링을 통해 주요 특징을 추출합니다.
- Filter Concatenation: 서로 다른 크기의 필터들을 통해 추출된 특징 맵들을 결합합니다.
GoogLeNet은 깊고 복잡한 네트워크 구조를 효율적으로 설계한 대표적인 예로, Inception 모듈을 도입하여 계산 효율성과 성능을 모두 향상시켰습니다. 전통적인 완전 연결층을 제거하고 글로벌 평균 풀링을 사용함으로써 파라미터 수를 크게 줄이고, 과적합을 방지하며, 이미지 분류 작업에서 뛰어난 성능을 보여주었습니다.
Bottleneck 레이어의 역할:
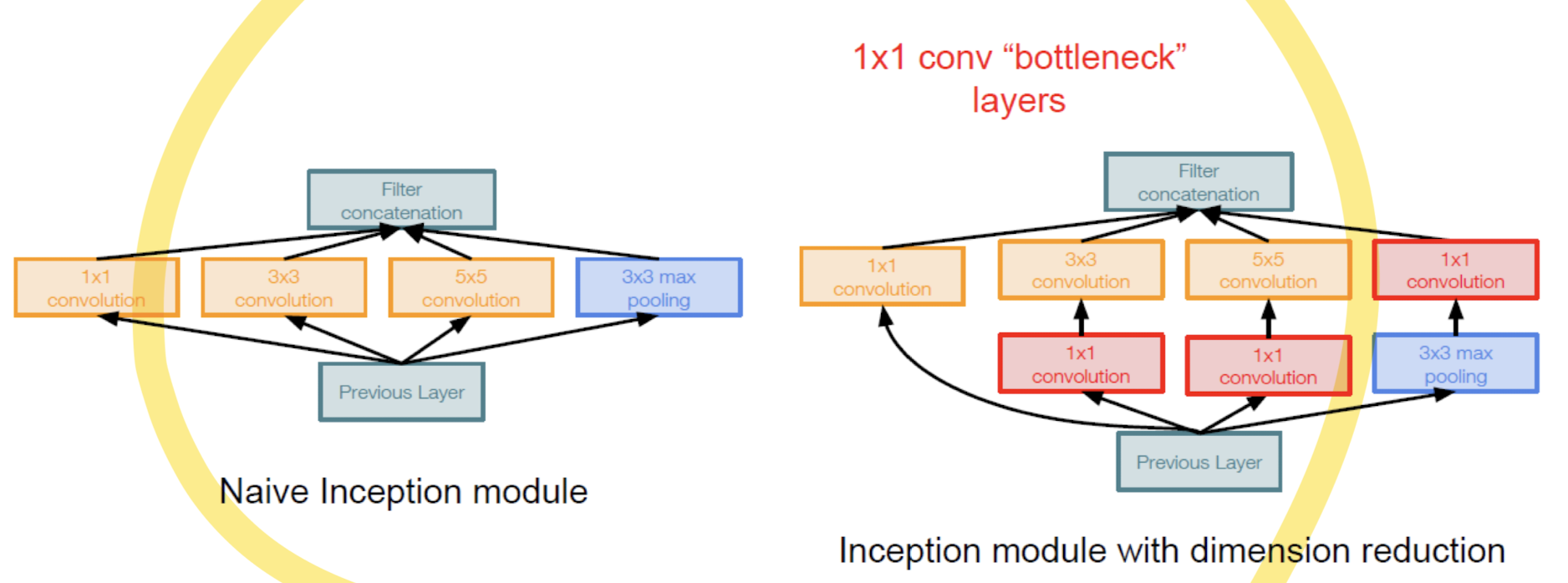
- 차원 축소: 1×1 Convolution은 입력 데이터의 채널 수를 줄여서 계산량을 줄입니다.
예를 들어, 입력 데이터의 채널 수가 256개라면 1×1 Convolution을 통해 이를 64개로 줄일 수 있습니다. - 계산 효율성: 차원 축소를 통해 나중에 적용되는 3×3 및 5×5 Convolution의 계산량을 크게 줄입니다.
이는 전체 네트워크의 계산 비용을 줄이고 학습 시간을 단축시킵니다.
비교 요약:
- Naive Inception 모듈은 다양한 크기의 필터를 병렬로 적용하여 다양한 공간적 정보를 포착하는 방식입니다.
- Bottleneck 레이어를 포함한 Inception 모듈은 먼저 차원 축소를 통해 계산 효율성을 높인 후, 다양한 크기의 필터를 적용하는 방식입니다.
이는 계산량을 줄이면서도 네트워크의 표현력을 유지할 수 있는 방법입니다.
전체 GoogLeNet 아키텍처:
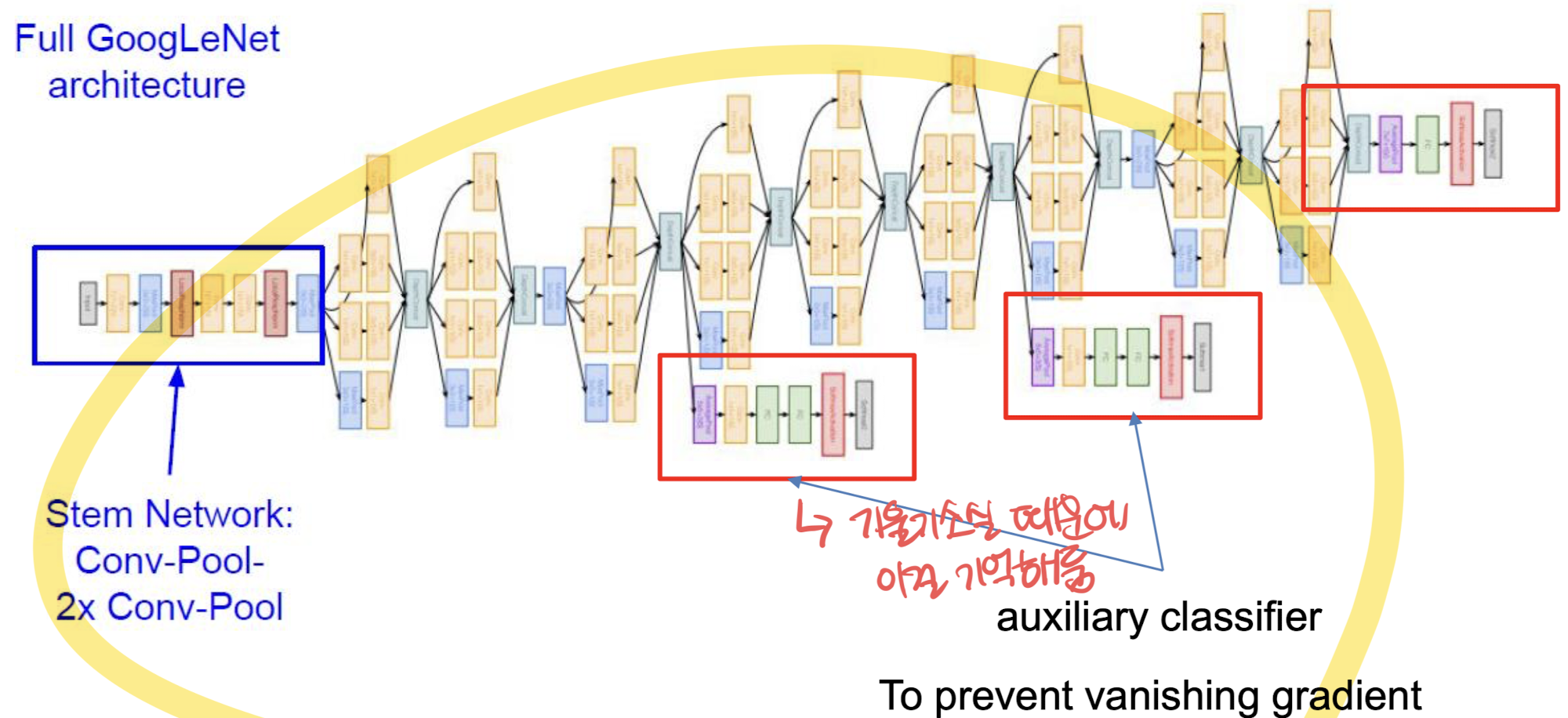
- Stem Network:
- 이미지의 왼쪽 부분은 "Stem Network"로 표시되어 있으며, 이는 초기 입력을 처리하는 부분입니다.
- Conv-Pool-2x Conv-Pool로 구성되어 있어, 초기 Convolution과 풀링 레이어를 통해 입력 데이터를 처리합니다.
Inception 모듈:
- Inception 모듈:
- GoogLeNet의 핵심 구성 요소는 Inception 모듈입니다. 여러 개의 Inception 모듈이 네트워크의 중간 단계에서 연속적으로 사용됩니다.
- 각 Inception 모듈은 여러 개의 크기가 다른 필터(1x1, 3x3, 5x5 Convolution 및 3x3 Max Pooling)를 병렬로 적용하여 다양한 크기의 특징을 추출합니다.
- 이러한 모듈을 통해 네트워크는 다양한 공간적 정보를 효과적으로 포착할 수 있습니다.
Auxiliary Classifiers (보조 분류기):
- Auxiliary Classifiers:
- 이미지의 붉은색 사각형으로 표시된 부분들은 auxiliary classifier입니다.
- 네트워크의 중간 단계에 배치되며, 네트워크가 더 깊어질수록 발생할 수 있는 기울기 소실 문제를 완화하는 역할을 합니다.
- Auxiliary classifiers는 중간 레이어의 출력을 사용하여 분류 작업을 수행하며, 이를 통해 학습 과정에서 보조적인 기울기 신호를 제공합니다. 이로 인해 주요 분류기의 성능을 향상시키고, 학습 안정성을 높입니다.
- 이 auxiliary classifiers는 최종 출력에 대한 추가적인 분류기를 제공하여, 전체 네트워크가 더 나은 성능을 발휘할 수 있도록 돕습니다.
주요 특징 요약:
- GoogLeNet은 22개의 레이어로 구성된 깊은 네트워크입니다.
- Inception 모듈을 사용하여 계산 효율성을 높이고, 다양한 크기의 특징을 추출합니다.
- Auxiliary classifiers를 도입하여 기울기 소실 문제를 방지하고, 네트워크의 학습을 안정화합니다.
📌 ResNet
주요 특징:
-
Residual Connections 사용:
- ResNet은 잔여 연결(Residual Connections)을 사용하여 매우 깊은 네트워크에서도 기울기 소실 문제를 방지합니다.
- 이러한 잔여 연결은 입력 값 (x)를 직접 출력에 더해주는 방식으로, 네트워크가 학습할 때 더 쉽게 수렴하도록 돕습니다.
-
깊은 네트워크:
- "152-layer model for ImageNet"
- ResNet은 152개의 레이어로 구성된 매우 깊은 네트워크를 사용합니다. 이는 기존의 네트워크보다 훨씬 깊은 구조입니다.
-
탁월한 성능
Residual Block 구조:
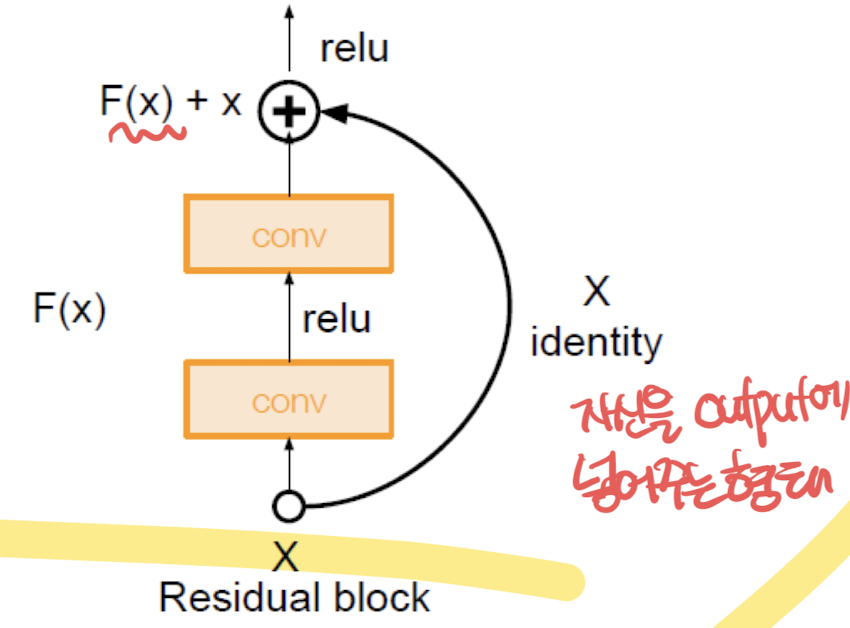
- Residual Block:
- 입력 x는 여러 개의 Convolution 레이어를 거친 출력 F(x)에 더해집니다.
- 이때, 입력 x는 직접 출력에 더해지는 "identity" 연결을 통해 잔여 연결을 형성합니다.
- 이러한 구조는 (F(x) + x)와 같이 표현됩니다.
- 이 과정은 네트워크가 더 깊어질수록 발생할 수 있는 기울기 소실 문제를 방지하고, 학습을 더 쉽게 만듭니다.
Residual Block의 장점:
- 기울기 소실 문제 방지:
- 잔여 연결은 역전파 과정에서 기울기가 0으로 소실되지 않도록 도와줍니다.
- 이를 통해 더 깊은 네트워크도 효과적으로 학습할 수 있습니다.
- 빠른 수렴:
- 잔여 연결을 통해 네트워크가 더 빨리 수렴하게 되어, 학습 속도가 향상됩니다.
- 더 나은 성능:
- 잔여 연결을 사용함으로써 네트워크가 더 좋은 성능을 발휘할 수 있습니다.
요약:
ResNet은 딥러닝에서 매우 깊은 네트워크를 사용할 때 발생하는 문제를 해결하기 위해 잔여 연결을 도입한 네트워크입니다. 이러한 잔여 연결을 통해 기울기 소실 문제를 방지하고, 네트워크의 학습과 성능을 크게 향상시켰습니다. 이로 인해 ResNet은 ILSVRC와 COCO와 같은 주요 대회에서 뛰어난 성과를 거두었습니다.
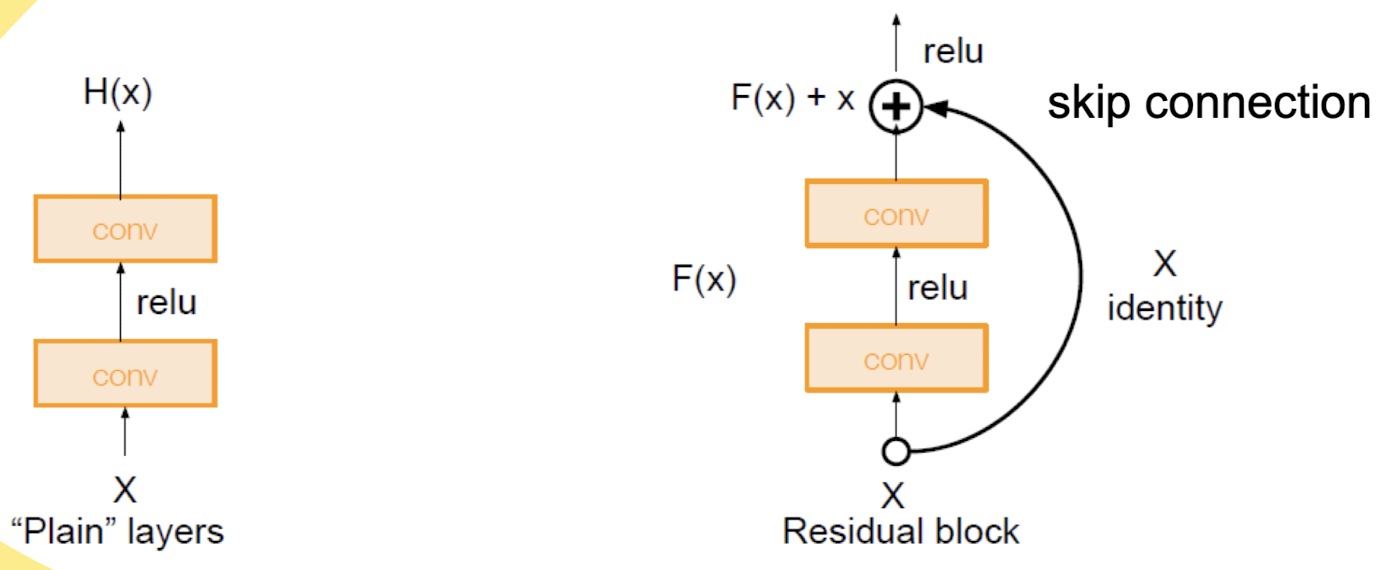
-
기존 접근법:
- 전통적인 네트워크는 입력 (x)를 받아서 직접적으로 원하는 출력 (H(x))를 학습하려고 합니다.
- 이 방식은 네트워크가 깊어질수록 기울기 소실 문제로 인해 학습이 어려워집니다.
-
ResNet 접근법:
- ResNet은 입력 x를 그대로 출력으로 전달하는 스킵 연결(skip connection)을 도입합니다.
- 네트워크는 (H(x) - x)에 해당하는 잔여 함수 (F(x))를 학습합니다. 즉, 원하는 출력 (H(x))는 잔여 함수 (F(x))와 입력 (x)의 합으로 표현됩니다.
- 이를 수식으로 표현하면 (H(x) = F(x) + x)가 됩니다.
Residual Block:
-
구조:
- 입력 (x)는 Convolution 레이어와 ReLU 활성화 함수를 거쳐 잔여 함수 (F(x))를 계산합니다.
- (F(x))는 다시 입력 (x)에 더해져 최종 출력 (H(x))를 만듭니다.
- 이 과정을 통해 네트워크가 깊어지더라도 기울기 소실 문제를 방지할 수 있습니다.
-
Skip Connection:
- 스킵 연결은 입력 (x)를 그대로 출력에 더하는 역할을 합니다.
- 이로 인해 역전파 시 기울기가 직접적으로 전달될 수 있어, 네트워크가 깊어져도 학습이 원활하게 이루어집니다.
요약:
- 기존 접근법 vs. ResNet 접근법:
- 기존 접근법은 입력을 직접 출력으로 변환하려 하지만, ResNet은 잔여 함수를 학습하여 입력을 출력으로 변환합니다.
- 이를 통해 깊은 네트워크에서도 학습이 잘 이루어지며, 기울기 소실 문제를 효과적으로 해결할 수 있습니다.
- 학습의 용이성:
- 잔여 맵핑을 학습함으로써 네트워크는 더 쉽게 학습할 수 있고, 깊은 네트워크에서도 높은 성능을 발휘할 수 있습니다.
- 이러한 접근법은 네트워크의 깊이를 증가시켜도 안정적으로 학습할 수 있게 합니다.
.jpeg)