
5.create function
5-1. arange

arange: array 범위를 지정해 값의 리스트를 생성하는 명령어
5-2. one, zeros and empty


- step point 0.5씩 추가로 출력하는 것이 가능

- shape을 먼저 지정해주고, 타입에 맞춰 0 or 1로 가득한 ndarrary 생성

empty를 사용하면 shape만 주어지고 비어있는 ndarray 생성 (빈공간만 잡아줌)
5-3. something_like

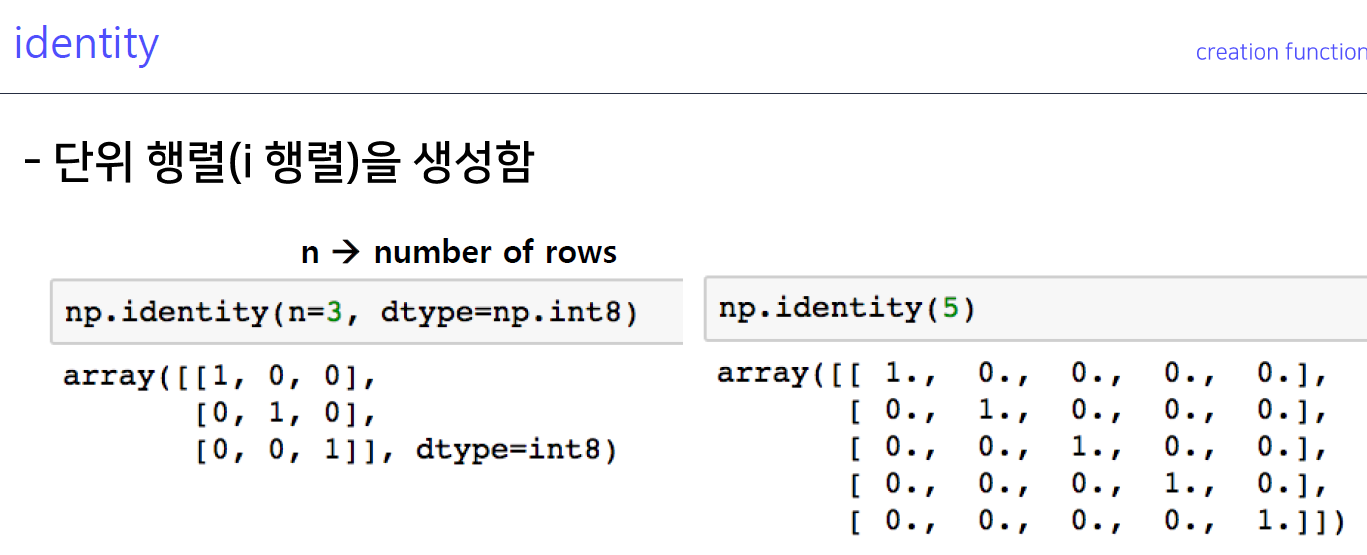
5-4. identitiy

5-5. eye
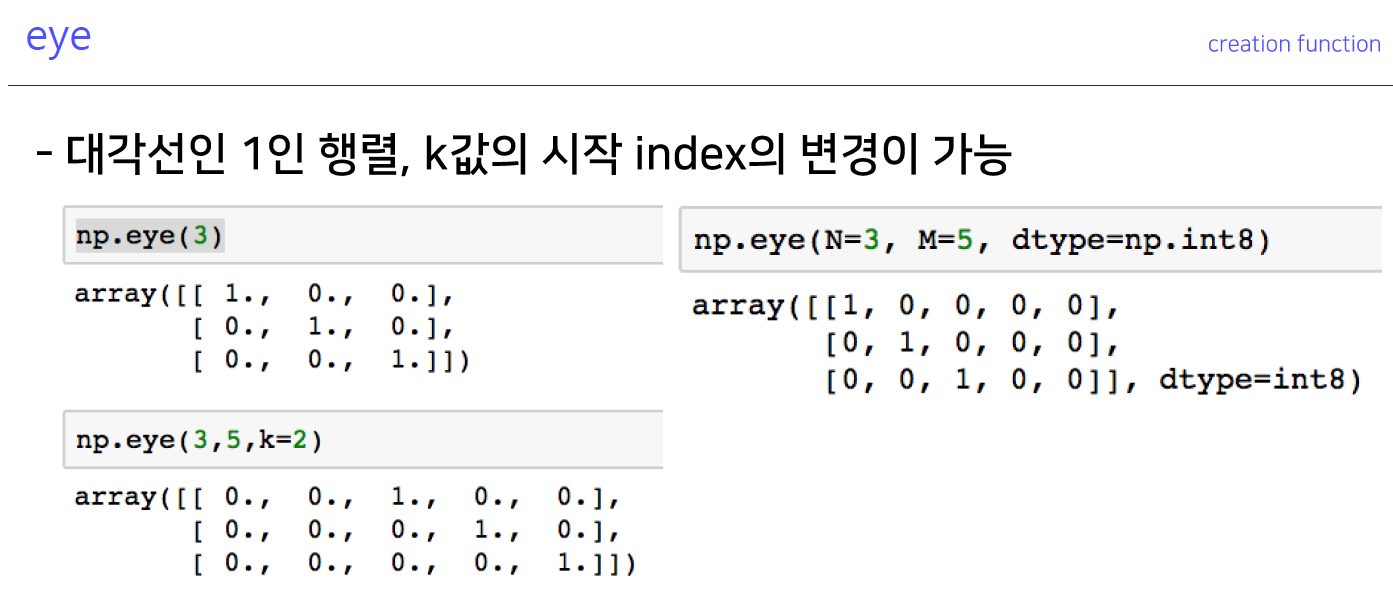
- 중간 값만 생성하는 것으로, 대각행렬이 1인 것

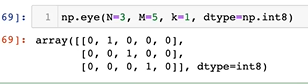
- 3 by 5의 메트랙트가 만들어지고, K=2는 2에서 시작해서 대각행렬 1을 출력 한다는 의미

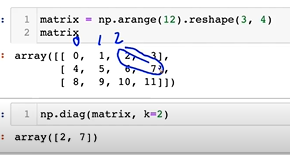
5-6. diag
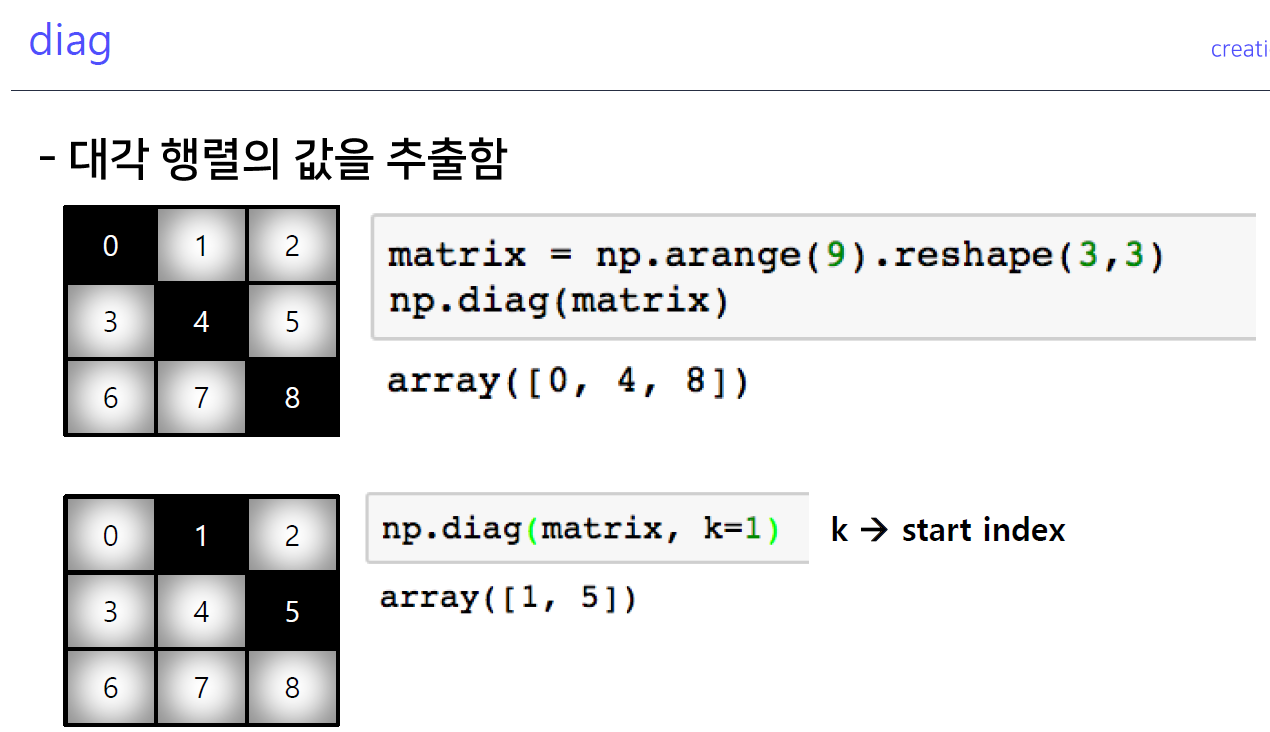
- 중간 값만 추출하는 것으로 대각행렬의 값만 뽑는 것
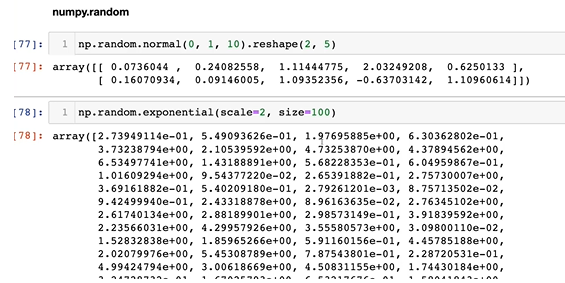
5-7. random sampling
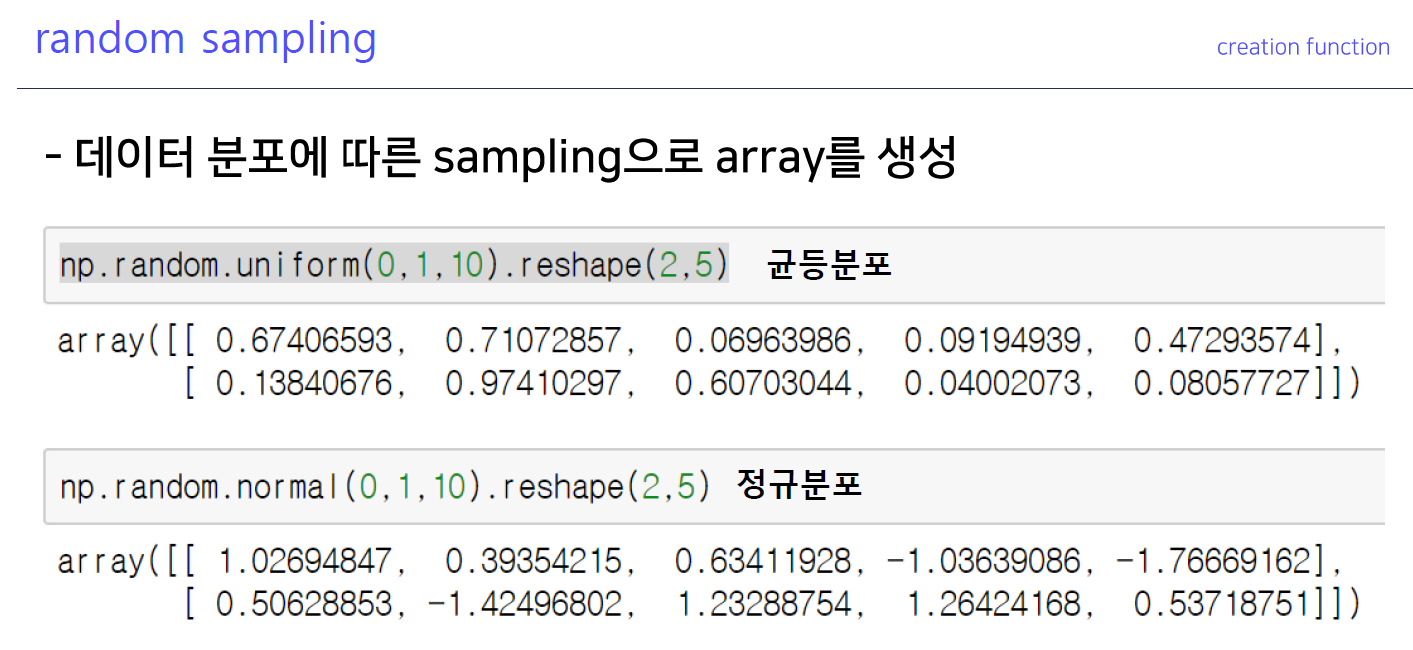
- 분포의 모수 값을 넣어주고, 사이즈를 넣어주면 됨
6. Operation function
6-1. sum

6-2. axis

- 연산을 어떻게 지원해줄까? 의 개념
- 기준이 되는 축을 정하는 것, axis=1을 기준으로 작동되면 우측, axis=0은 위에서 아래 등
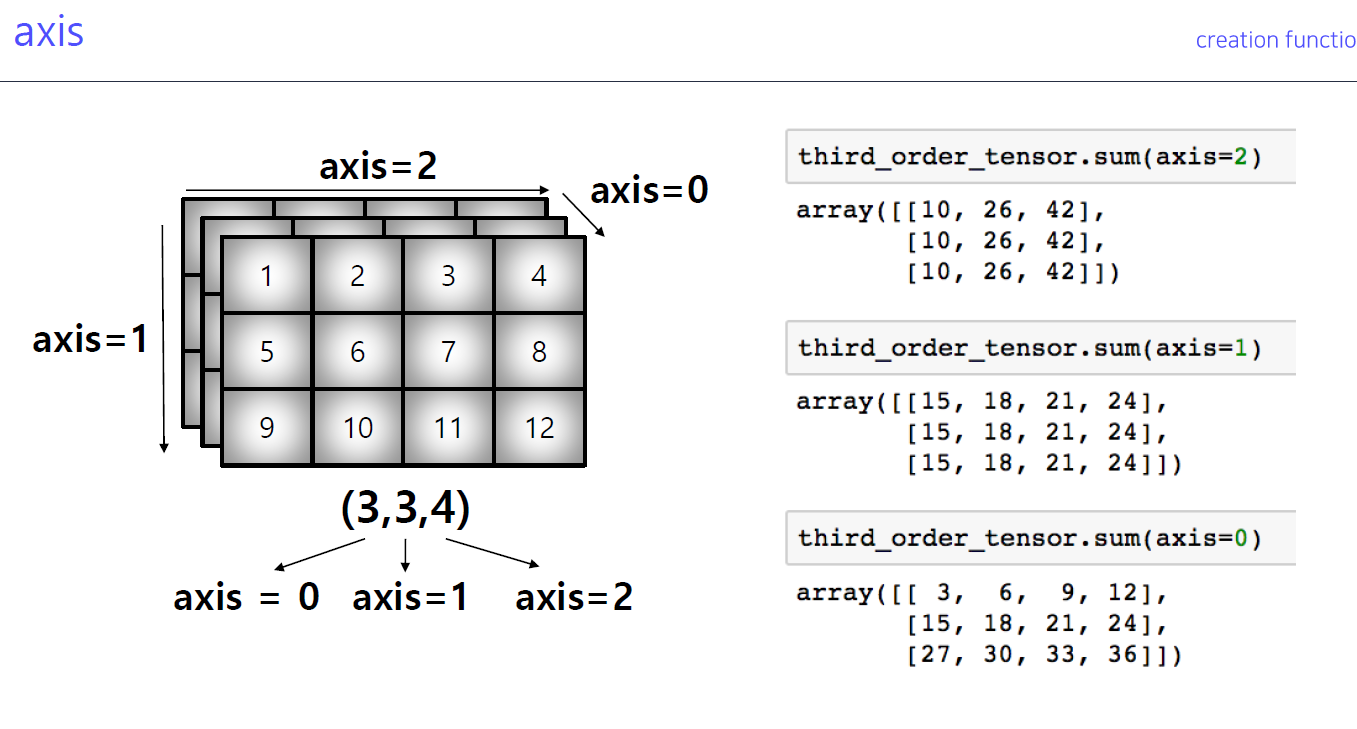
- 4d까지도 만들긴하지만 3d는 이미지 처리 시 만나기 때문에 이해해야 함
6-3. mean & std
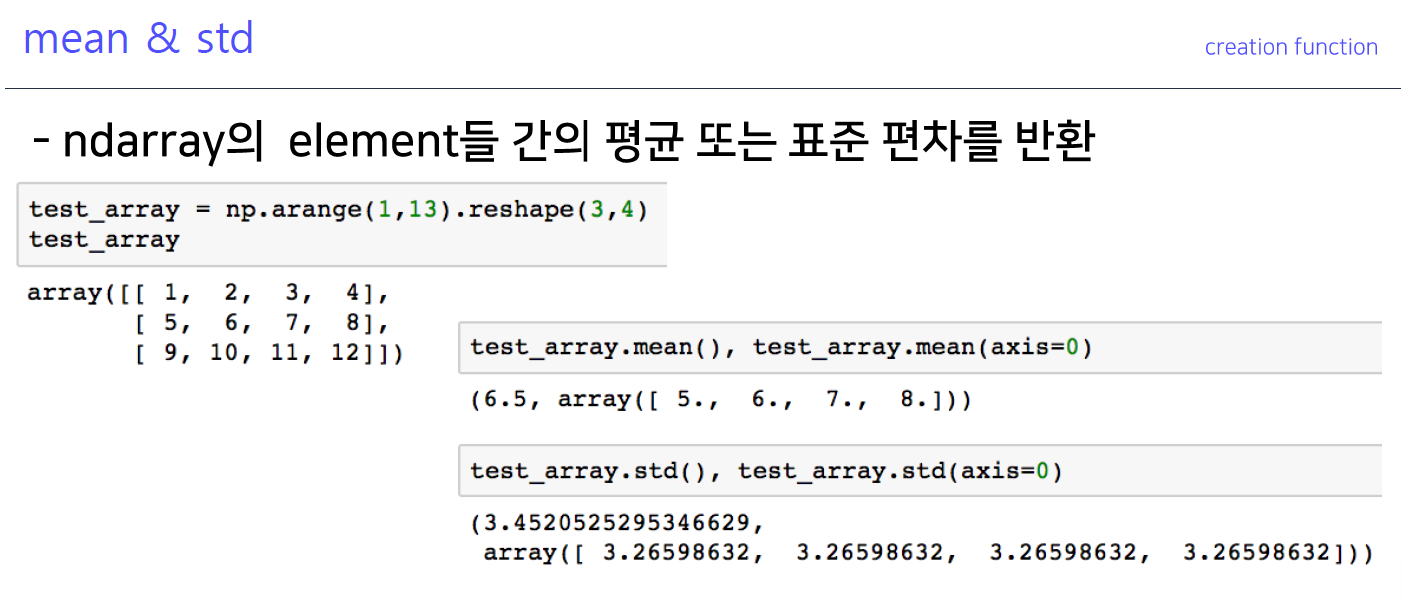

- 어떻게 생성되는지 그림과 함계 기억해야함!
- 새롭게 생성된 축이 항상 axis=0가 된다는 것을 기억
6-4. mathematical functions

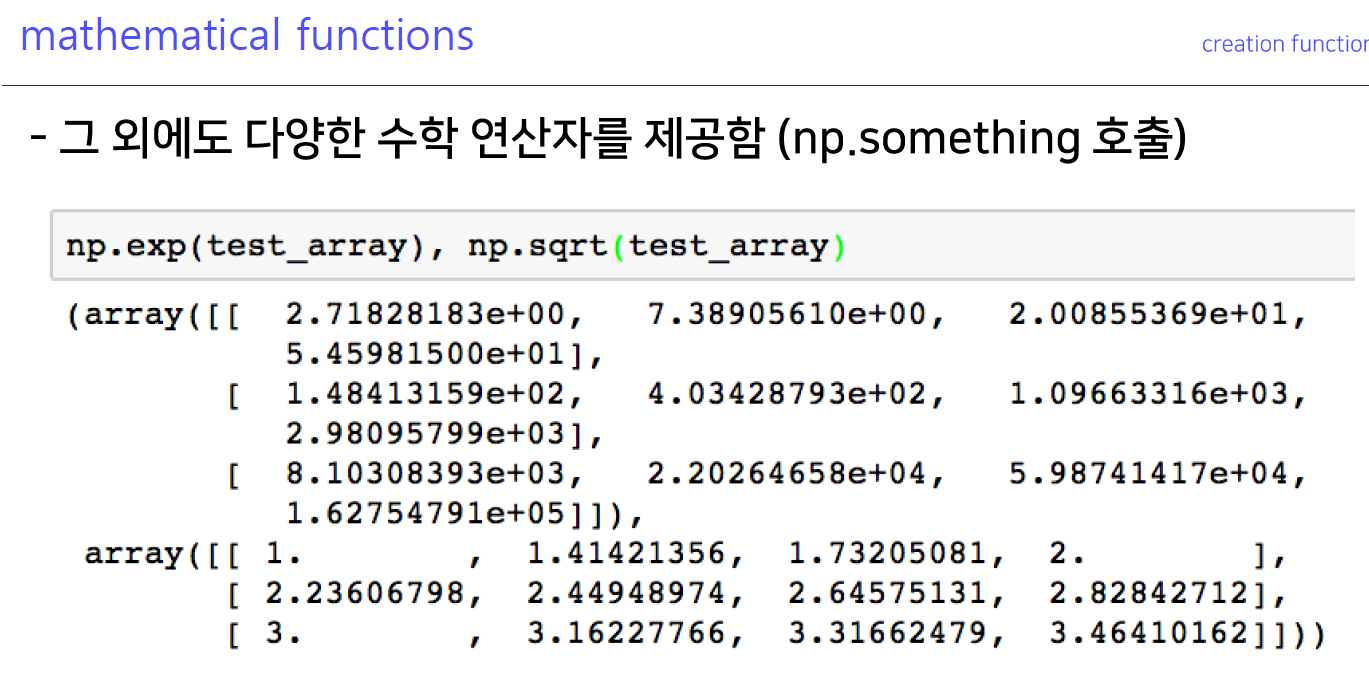
- 루트 씌우는 연산
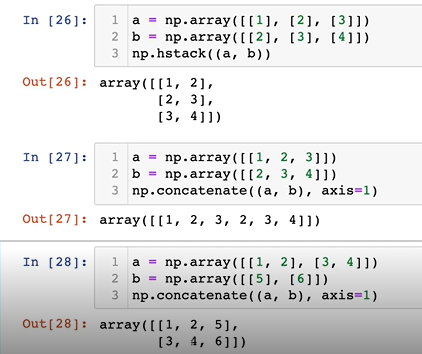
6-5. concatenate
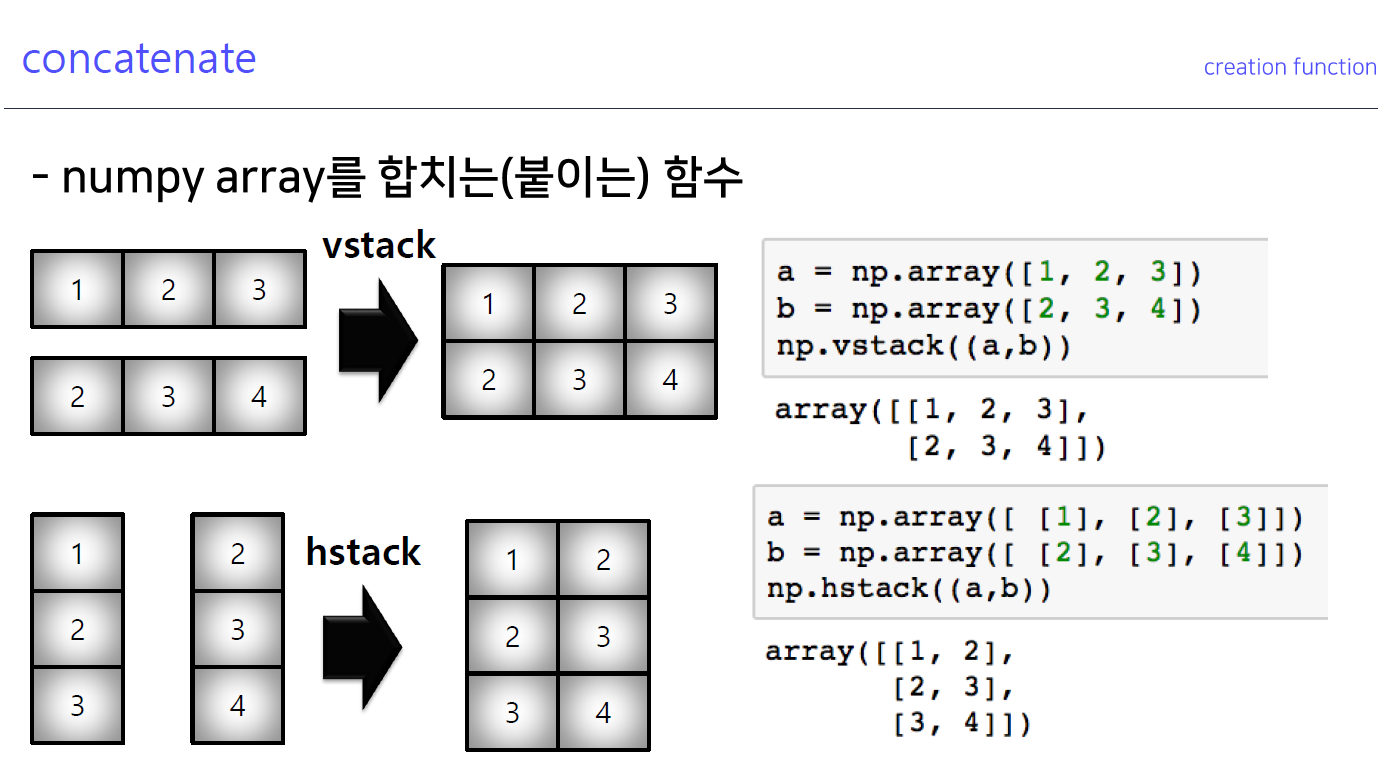
- 파이토치에도 매우 많이 쓰이는 함수
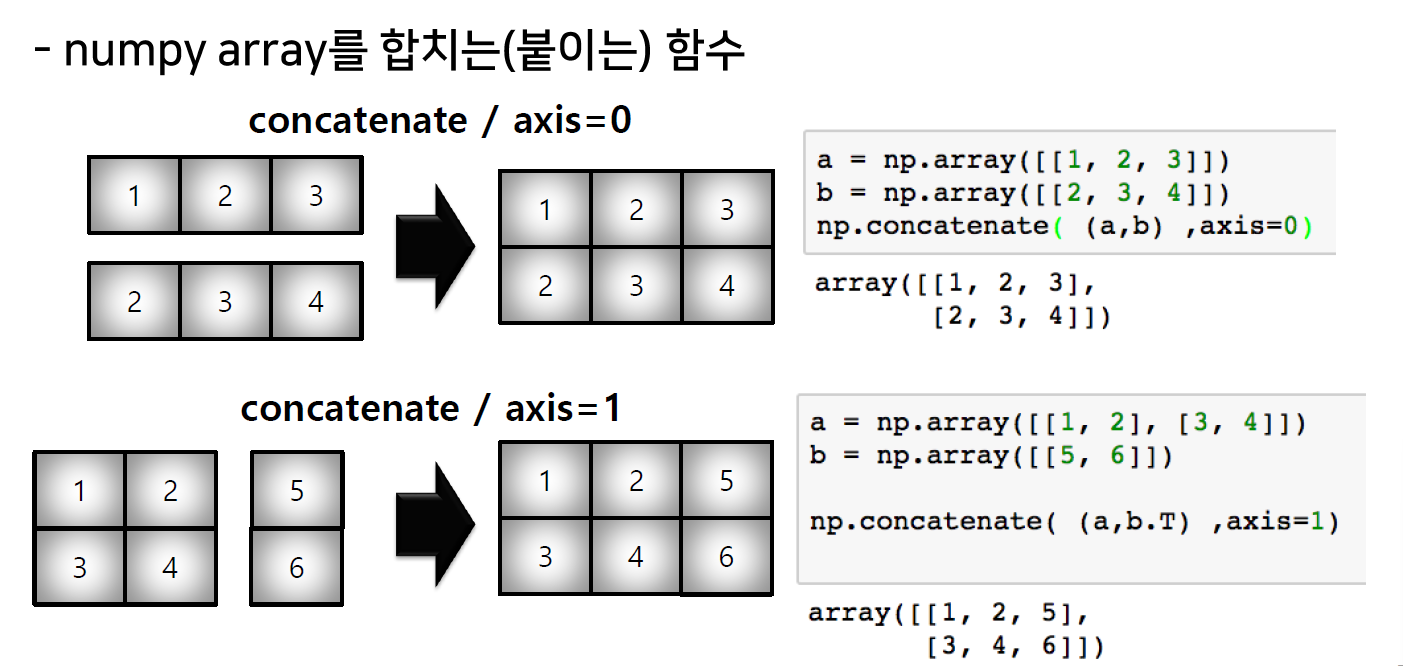
- axis 축을 기준으로 붙이게 됨
- 붙였을 때 생성되는 결과값을 axis라고 생각하면 편하다.
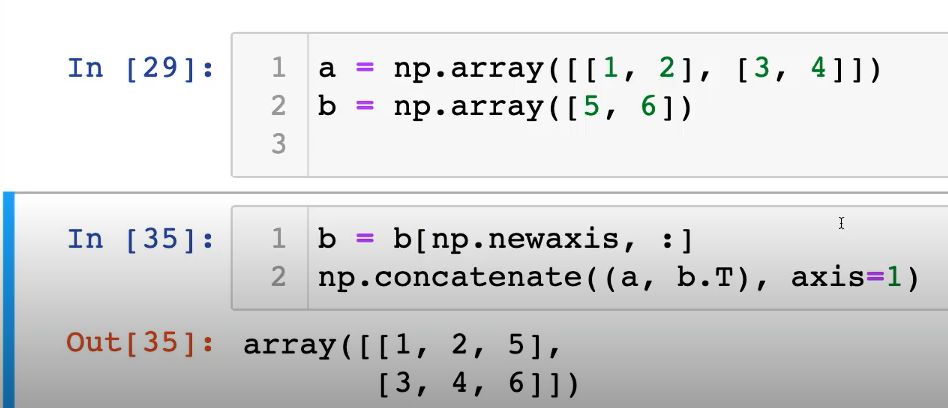
- new axis는 하나의 축을 생성할 때 쓰는 함수로 중요함
7. array perations
7-1. Operations b/t arrays

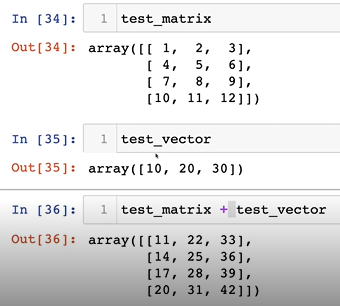
7-2. Element-wise operations
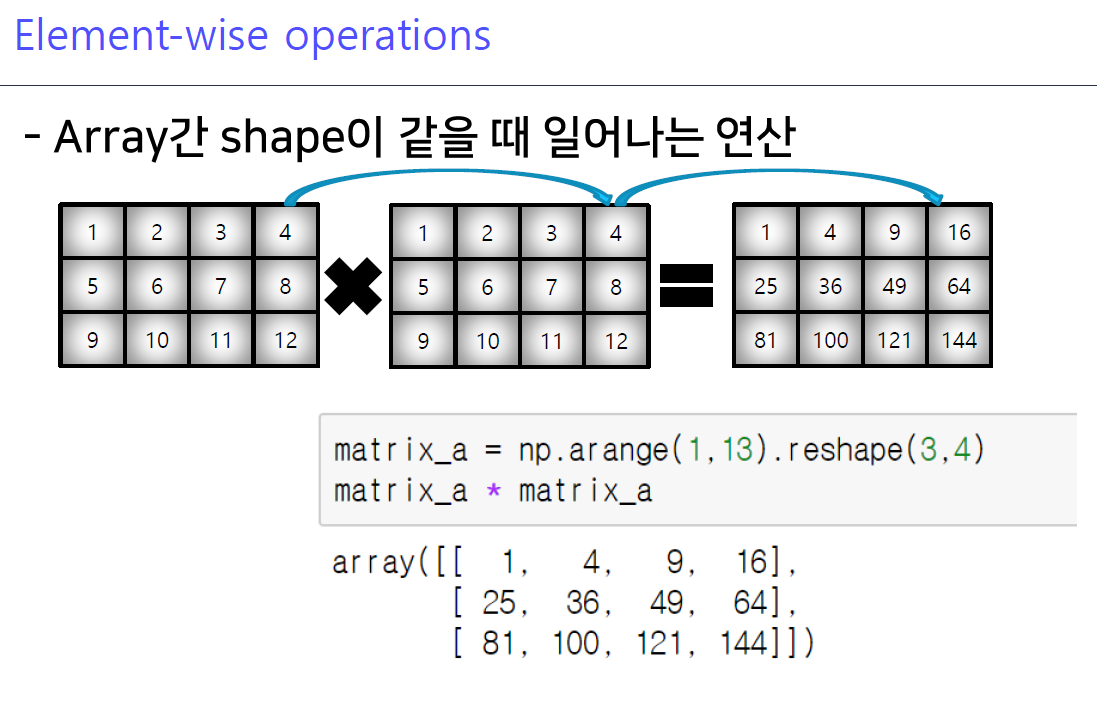
shape이 같을 때Element wise oerations기억할 것!
7-3. Dot product
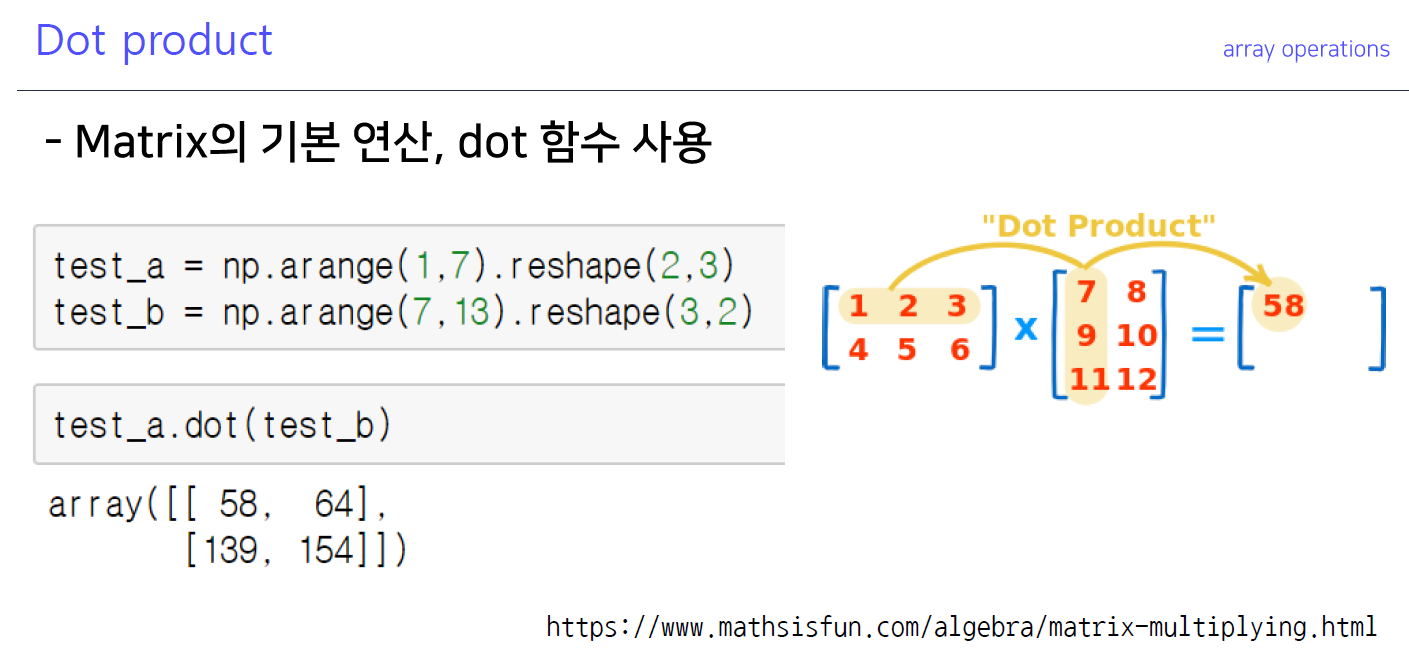
dot product: 행렬간 곱셈연산 (곱해주고 더해주고)
7-4. transpose

전치행렬: T를 붙여주면 (transpose가 됨), 로우와 칼럼이 변함
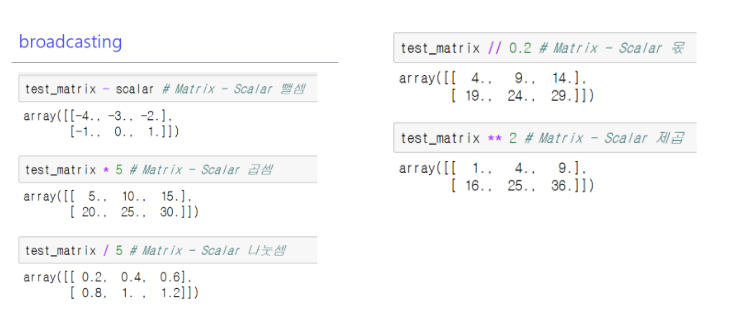
7-5. broadcasting
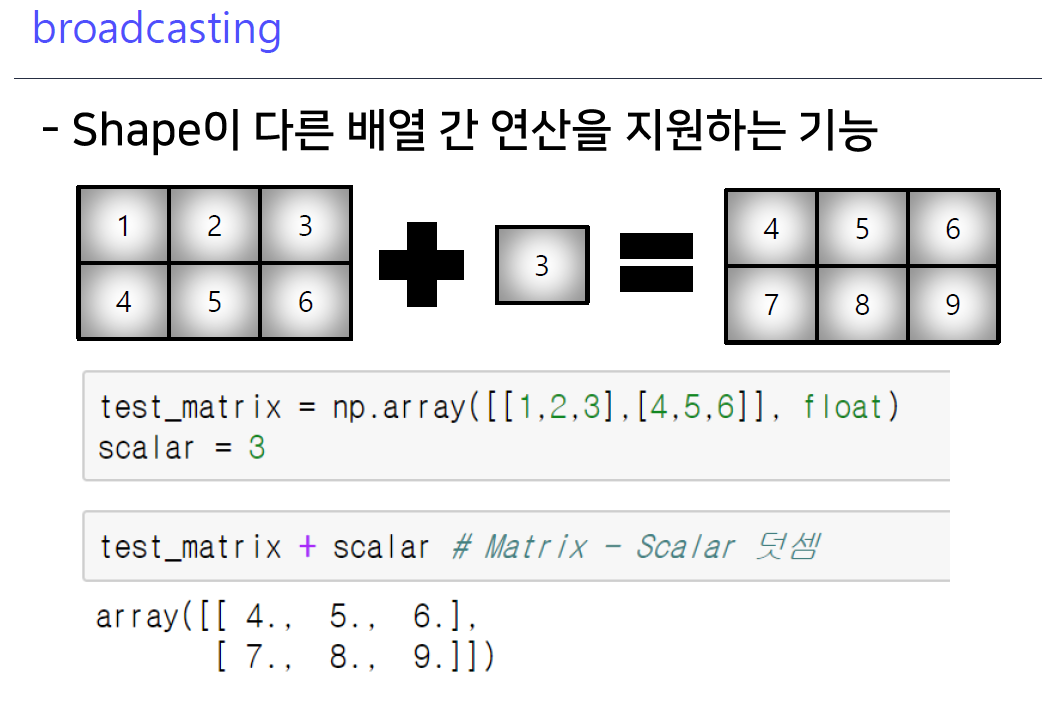
- shape의 크기가 달라도 연산을 해주며, 퍼져나가는 형태의 연산
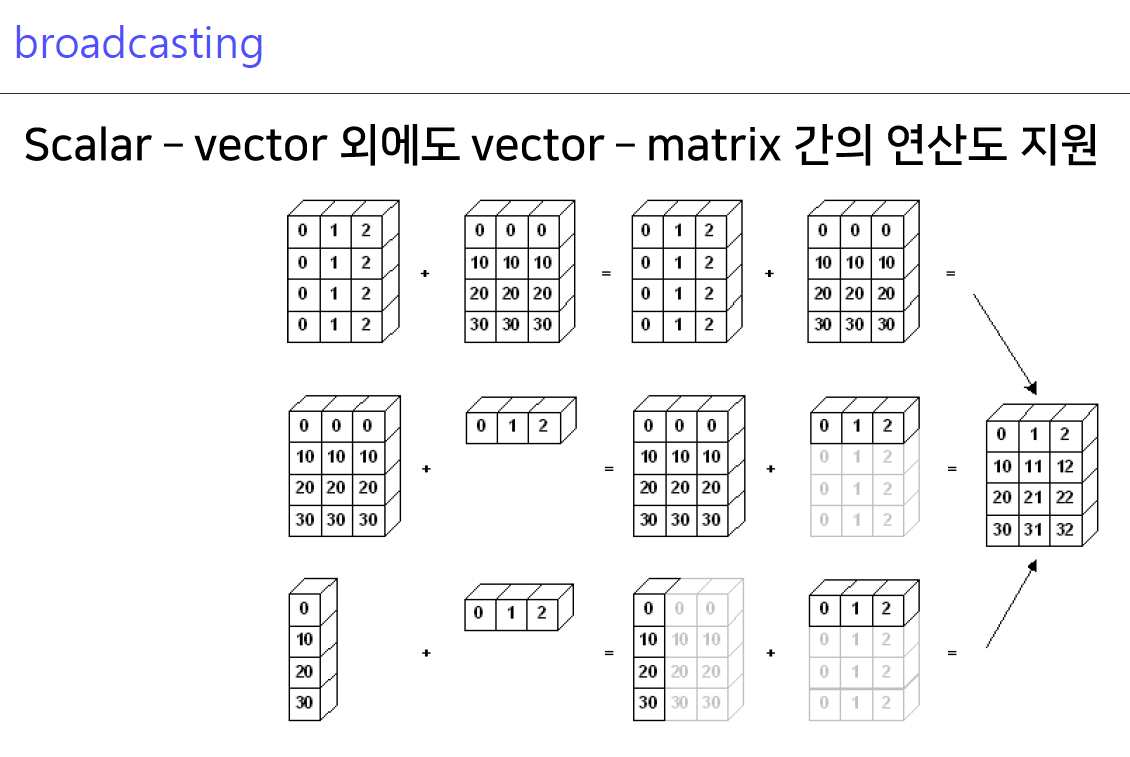
- 첫줄은 쉐입이 같음
- 둘째줄은 있다고 가정을 해주고 연산을 해줌
- 셋째줄은 알아서 퍼지면서 연산해줌

7-6. numpy performance #1

timeit: 속도를 측정 가능
7-7. numpy performance #2
- 일반적으로 속도 순서 (for loop < list comprehension < numpy
- 100,000,000번 loop가 돌 때, 약 4배이상의 성능 차이를 보임
- numpy는 C로 구현 돼 있어, 성능을 확보하는 대신 파이썬의 가장 큰 특징인 dynamic typing을 포기
- 대용량 계산에서는 가장 흔히 사용됨
- Concatenate처럼 계산이 아닌, 할당에서는 연산속도의 이점이 없음
8. Comparisons
8-1. All & Any

all과any에 대해 숙지
any: 1개라도 True 면 Trueall: 모두 True 이어야 True, 하나라도 false 면 false
8-2. comparison operation #1
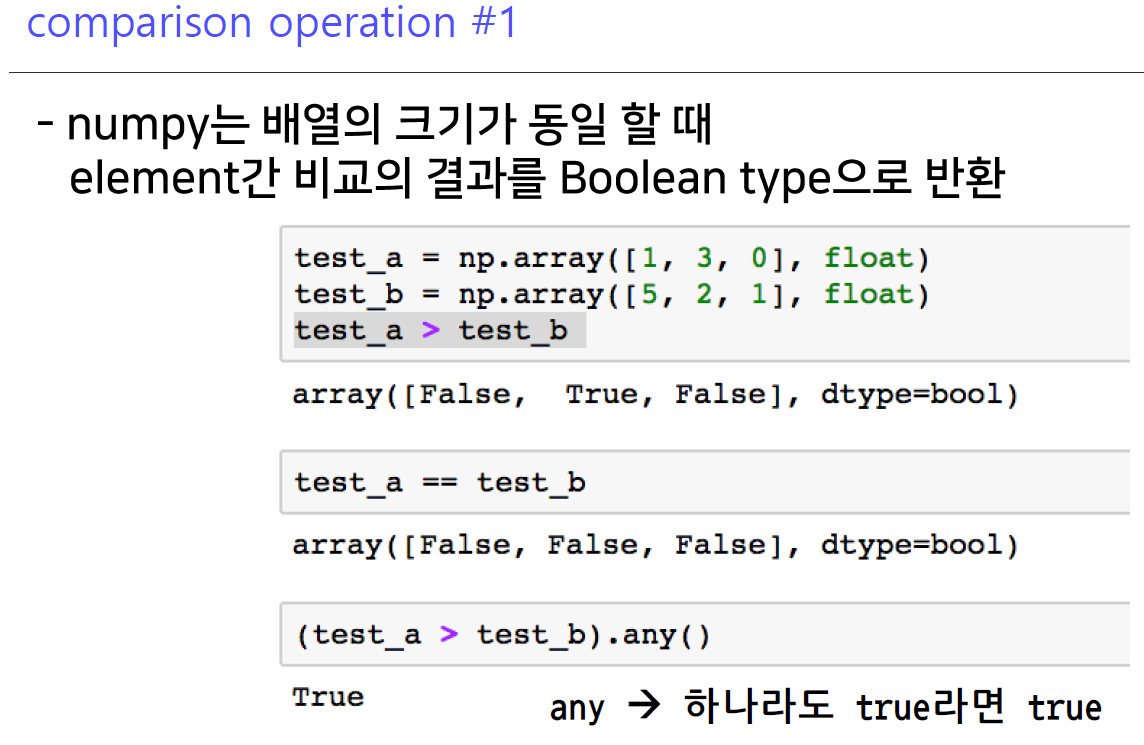
- 출력 값 :
Boolean array- 1 < 5 , 3 > 2, 0 > 1와 같이 비교
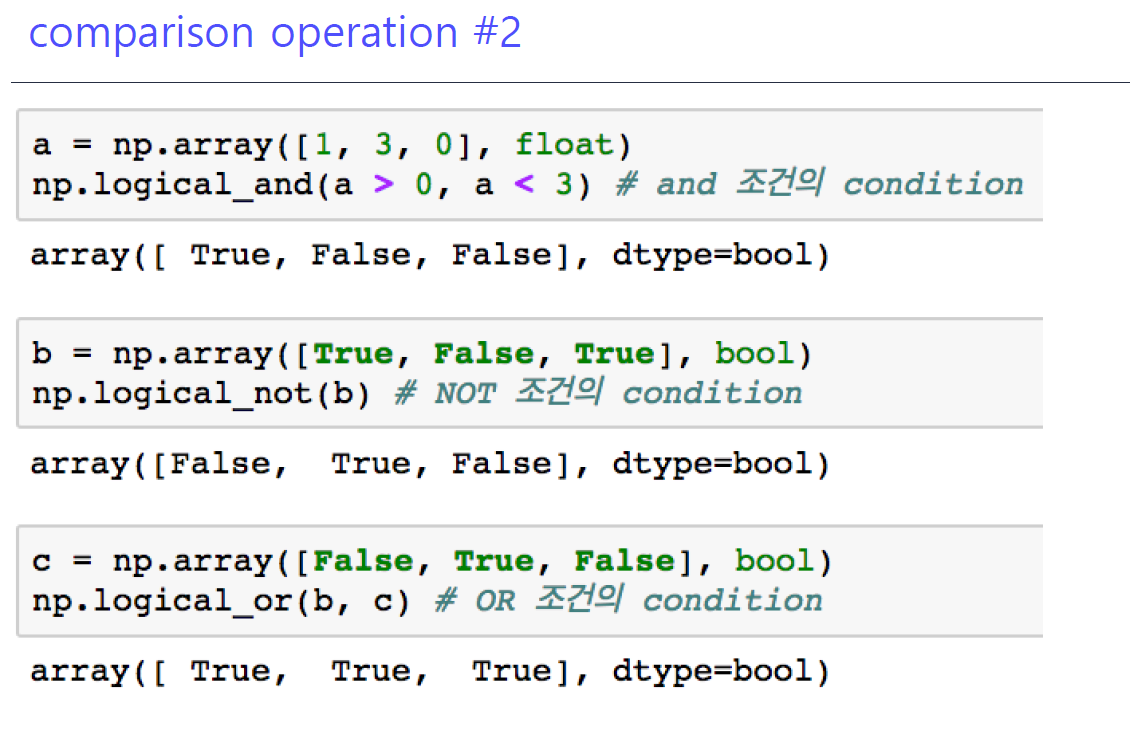
8-3. comparison operation #2
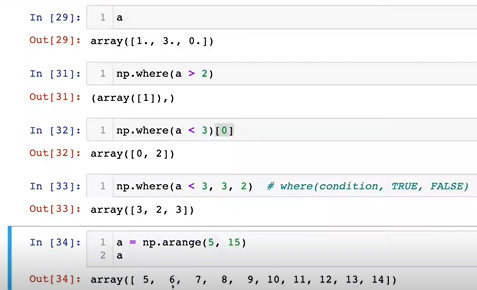
8-4. np.where
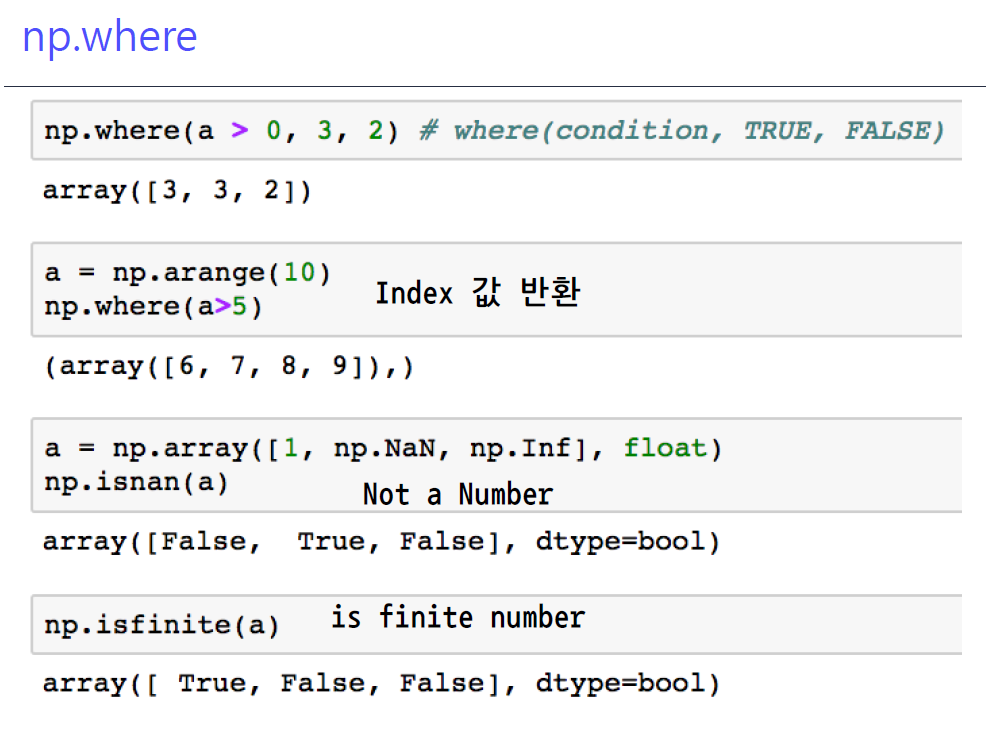
- 첫번째는 안에 불린인덱스가 들어가 데이터 개수만큼 True or False가 나오는데 , True 영역엔 True값이 False 영역에는 False 값이 출력
- 두번째는 a>5에 만족하는 True의 값의
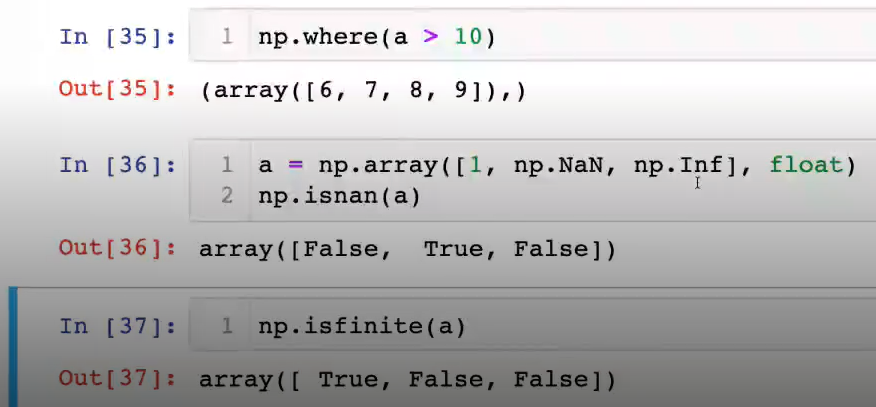
인덱스 반환isnan: not a number라고 해서 메모리 값이 존재하지 않는 경우isfinite: 한정되지 않는 값으로 학습하게 되면 수렴하게되지 않는 경우, in infinite number를 찾는 것
- 예시
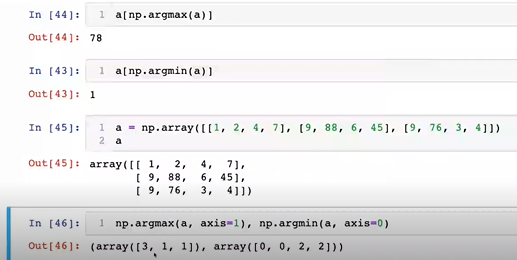
8-5. argmax & argmin

- 가장 큰 값, 가장 작은 값의 인덱스를 반환

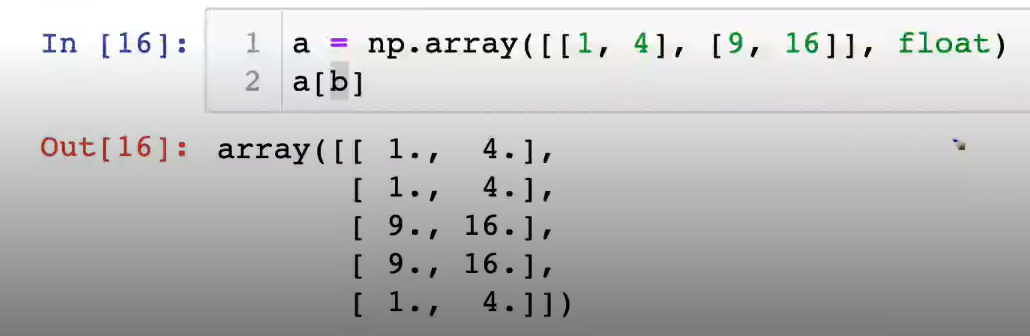
8-6. boolean & fancy index
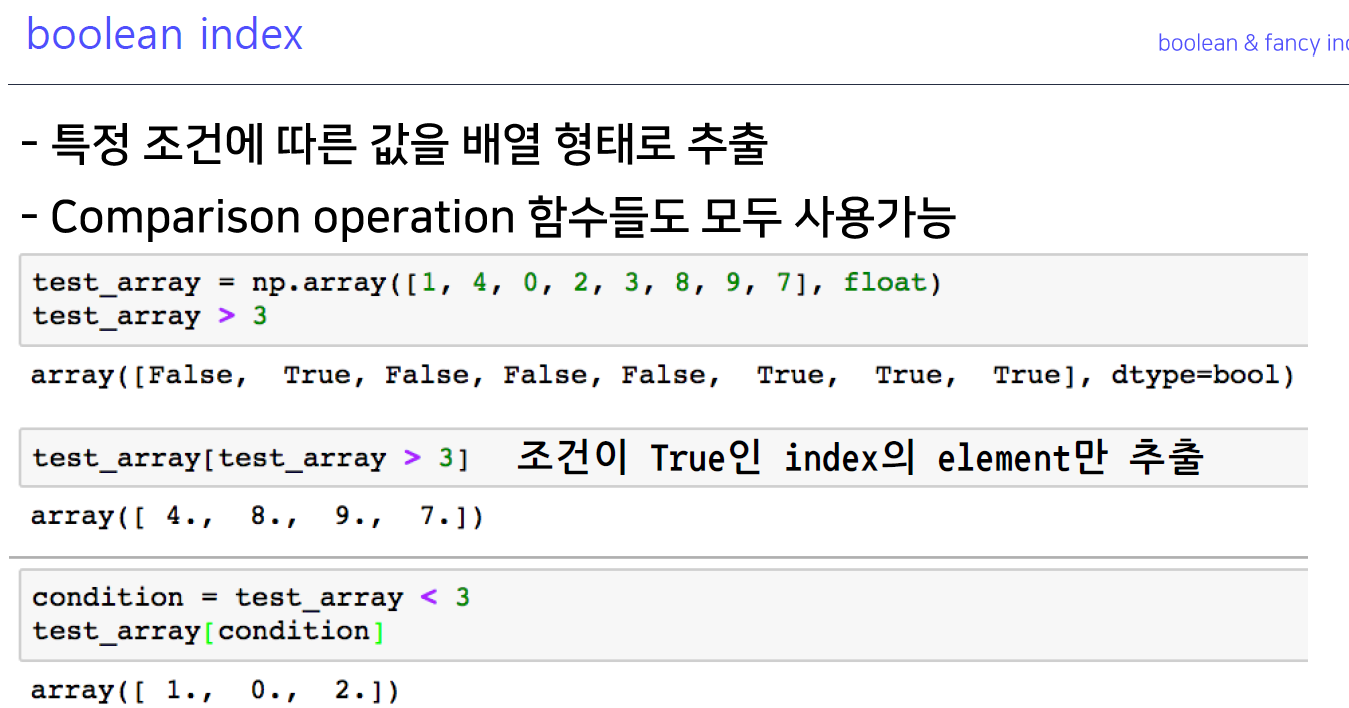
- 불린 리스트의 값을 커리해오는 것( 뽑아오는 것)
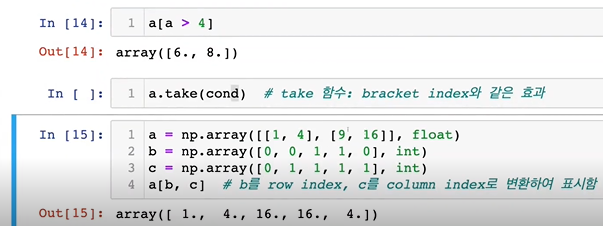
8-7. fancy index

인덱스 값을 넣어주는 것에서 차이가 있음- 0의 값은 2, 1의 값은 4, 3의 값은 8, 2의 값은 6
- take 함수를 써도 동일하기는 함

- 0,0 → 1 | 1,1, → 16 등과 같이 출력

9. numpy data i/o
9-1. loadtxt & save txt
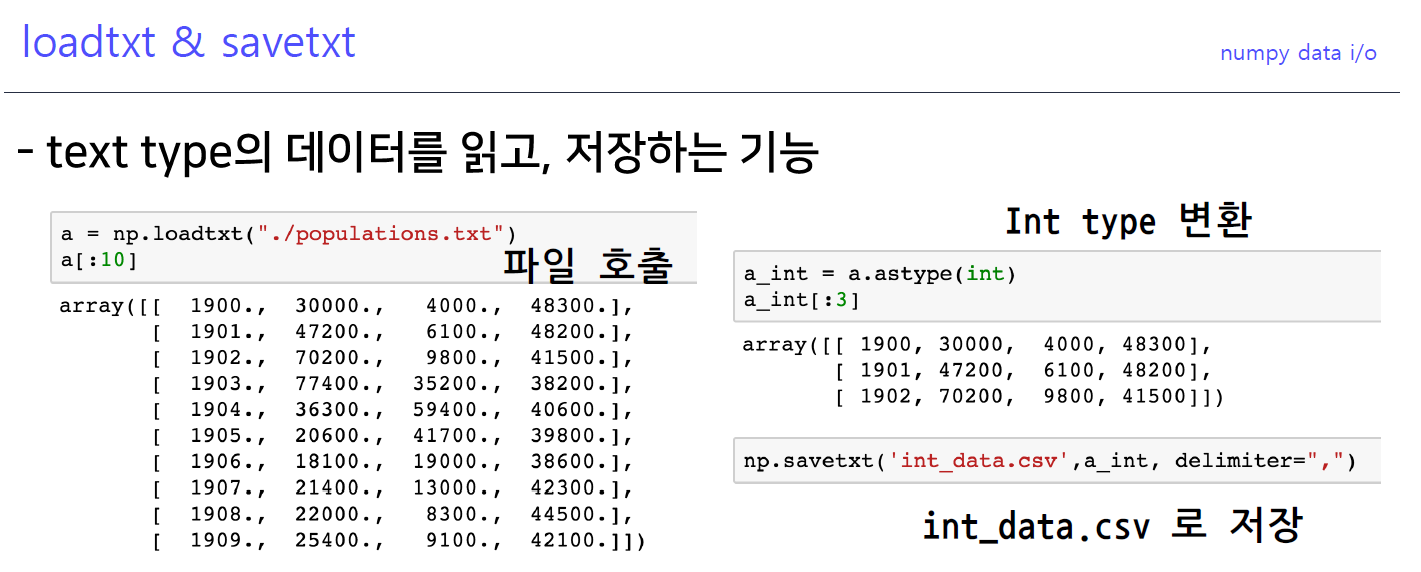
delimiter는 저장하는 기준값

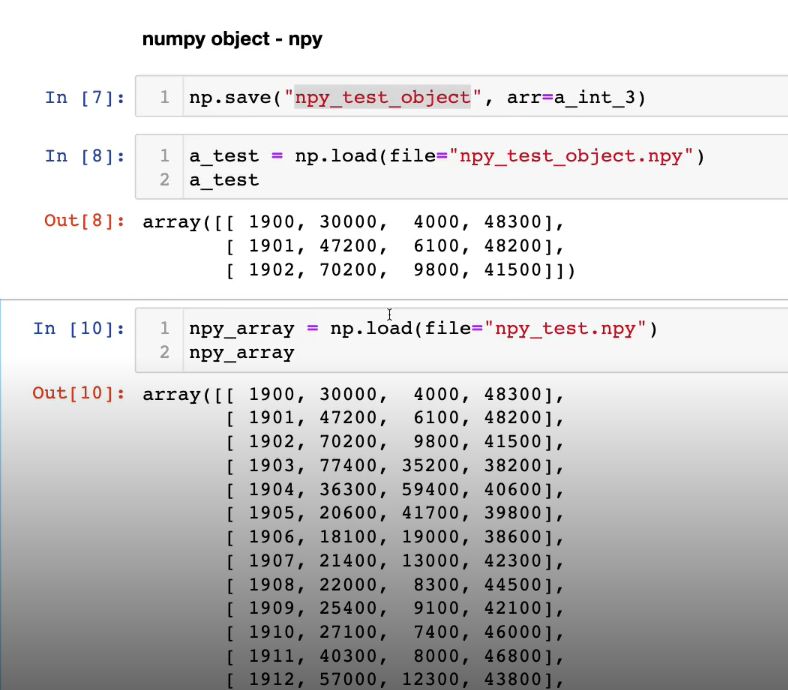
- npy파일

세상을 이롭게하는 AI Engineer