
학습목표
pandas I 강의에 이어서 pandas 라이브러리의 다음과 같은 기능에 대해 학습
이후 사전처럼 해당 강의내용을 사용하자!
- groupby
- pivot_table
- joint method (merge / concat)
- Database connection
- XLS persistence
1. Groupby I
1-1. Groupby
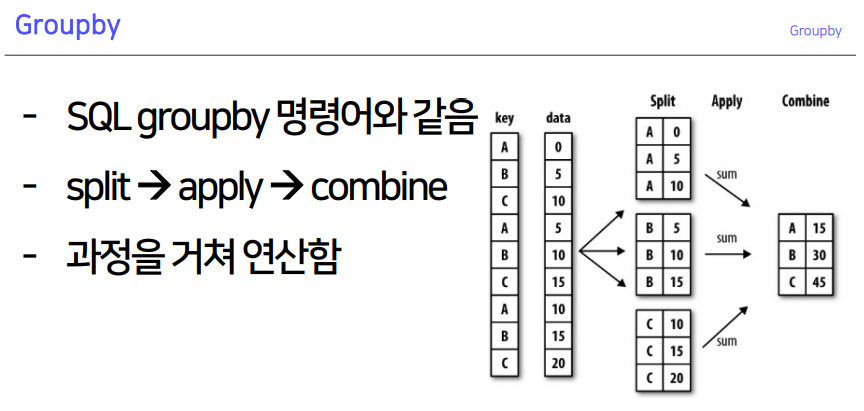
split: 인덱스가 같은 것끼리 묶은 것- 엑셀 피벗테이블과 비슷함
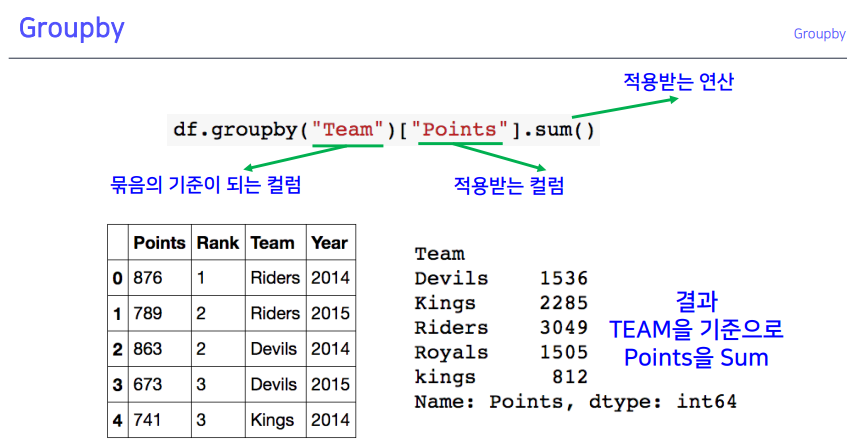
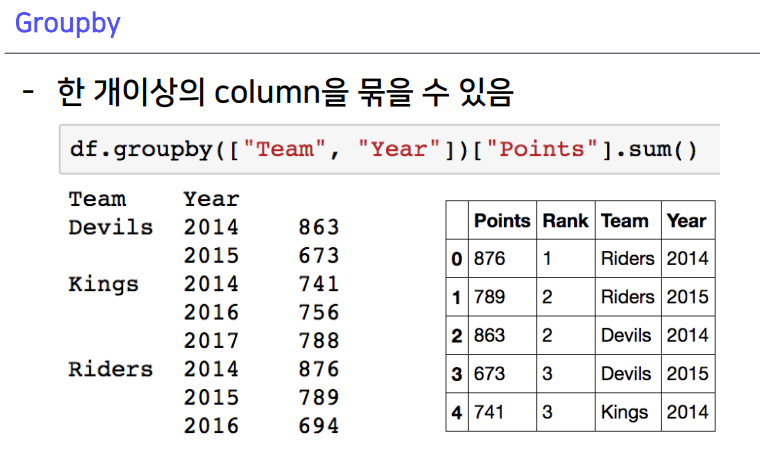
- mean : 평균
1-2. Hierarchical index
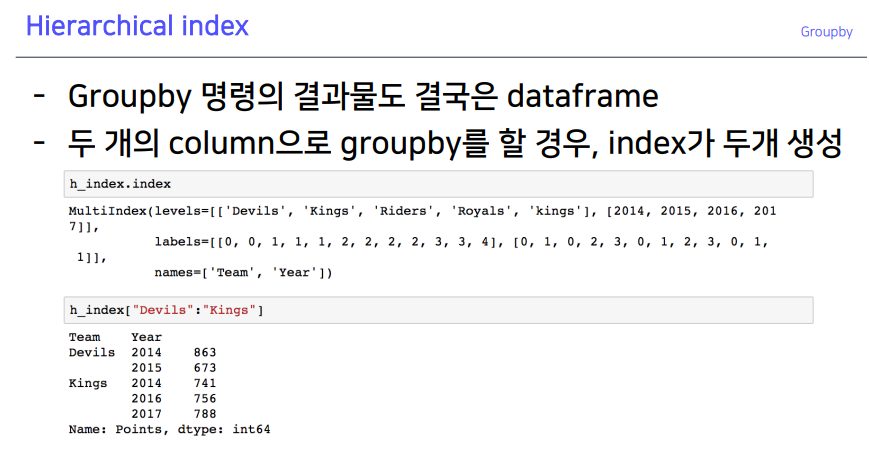
Hierarchical index: 2칸의 인덱스로 구성 할 수 있는 것
1-3. Hierarchical index - unstack()
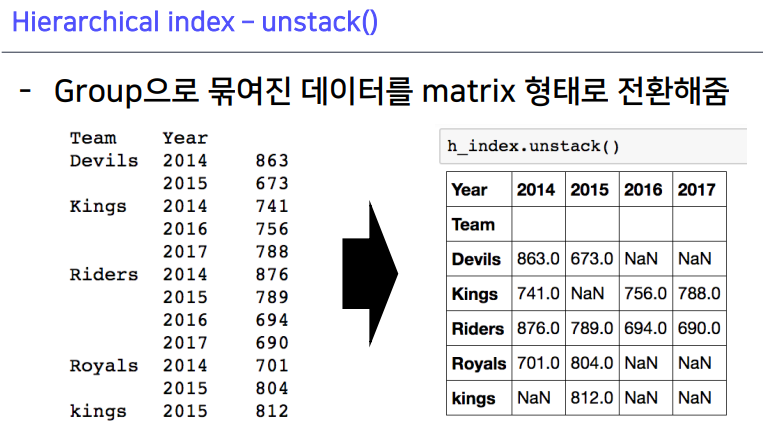
- reset_index()로 풀 수도 있음
1-4. Hierarchical index - swaplevel
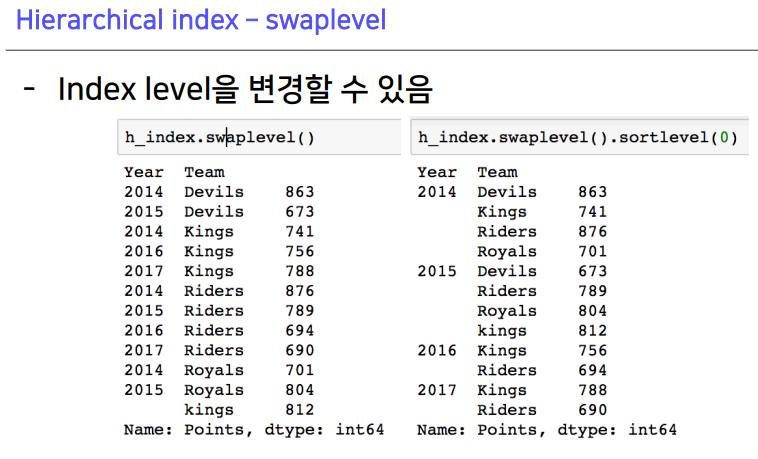
swaplevel(): 결과물만 바뀌어 출력sortlevel(): 정렬하여 출력
1-5. Hierarchical index - operations
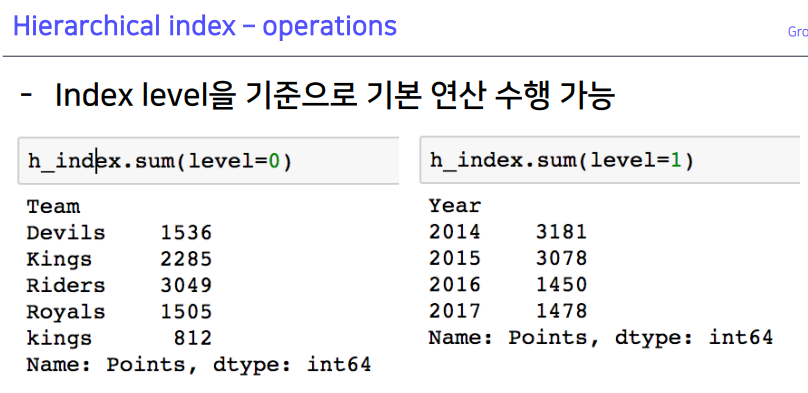
2. Groupby II
2-1. Groupby - gropued
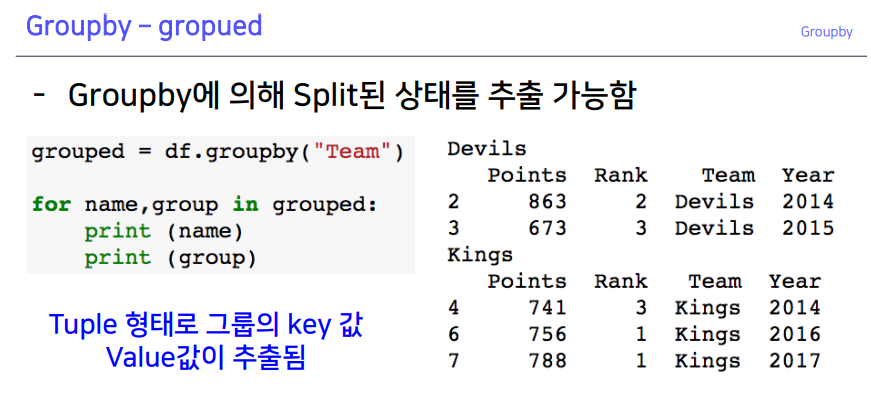
key value형태로 데이터 출력 가능
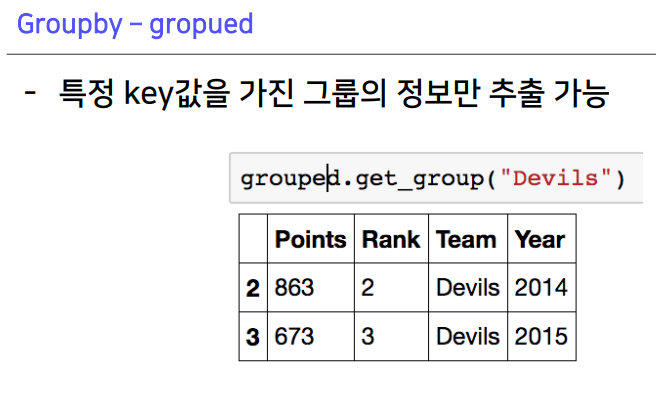
get_group()

- lamda 함수를 통해 transformation 가능
2-2. Groupby - aggregation
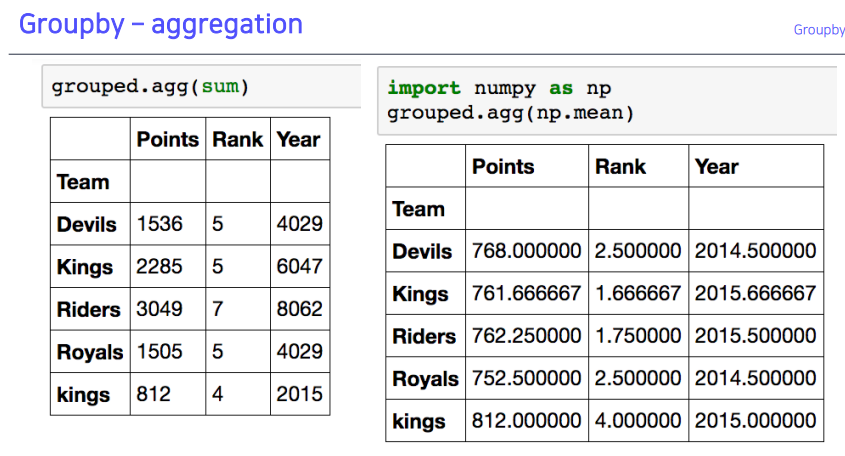
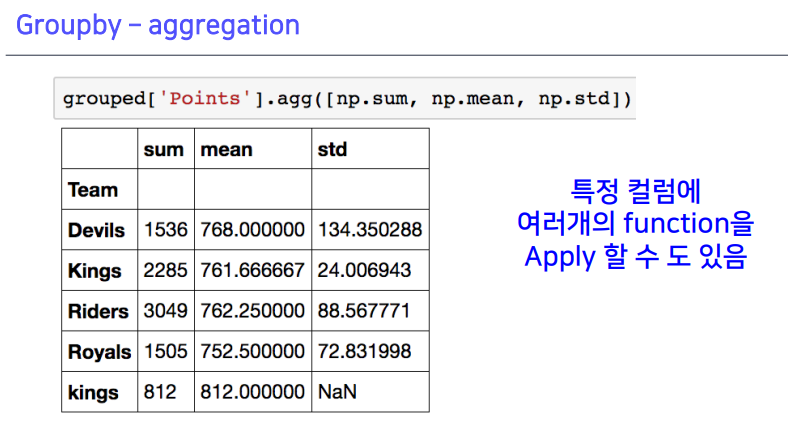
- 여러 함수 사용 가능 (sum, mean, std)
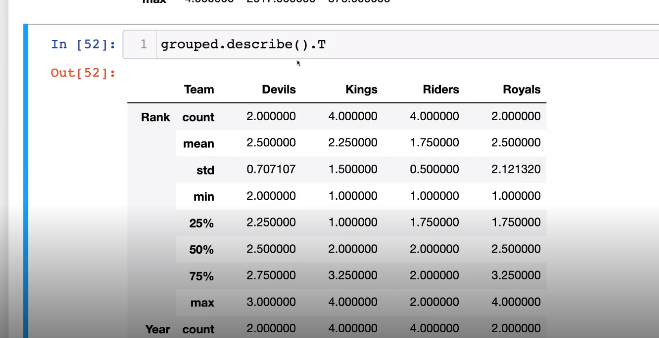
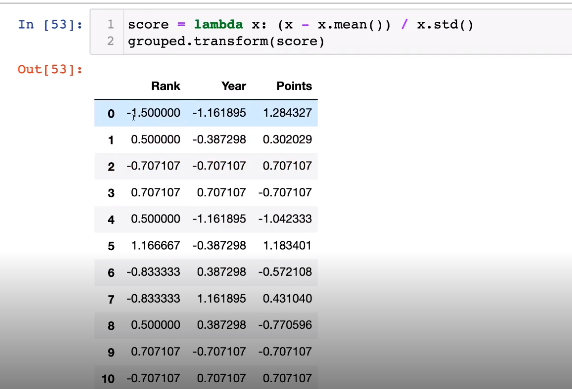
2-3. Groupby - transformation
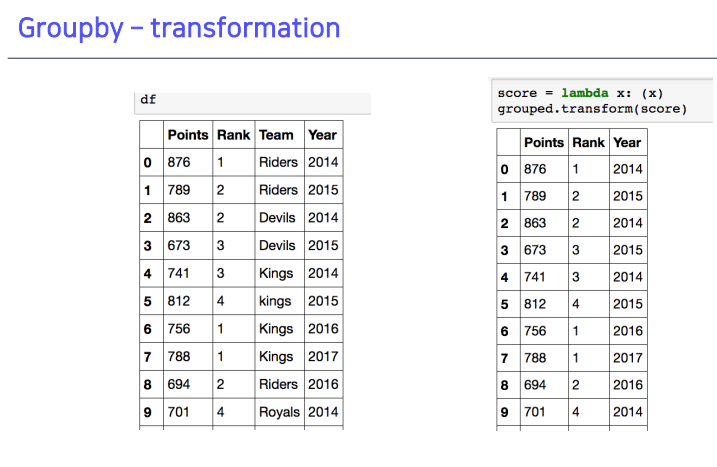
- 개별 데이터 변환

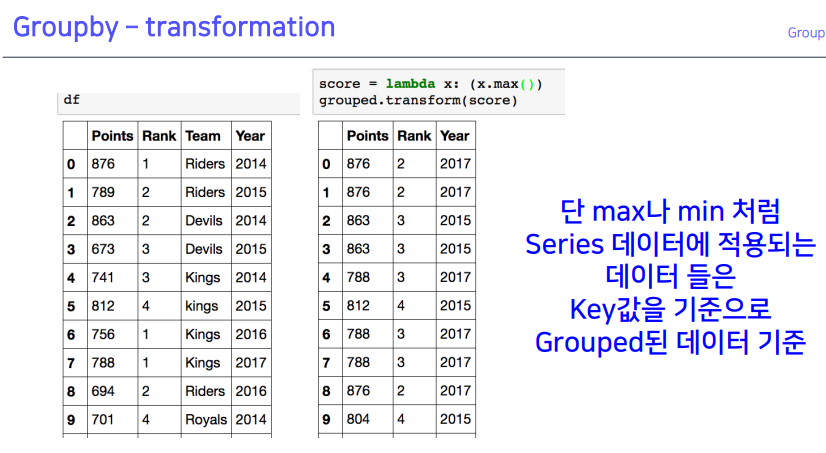
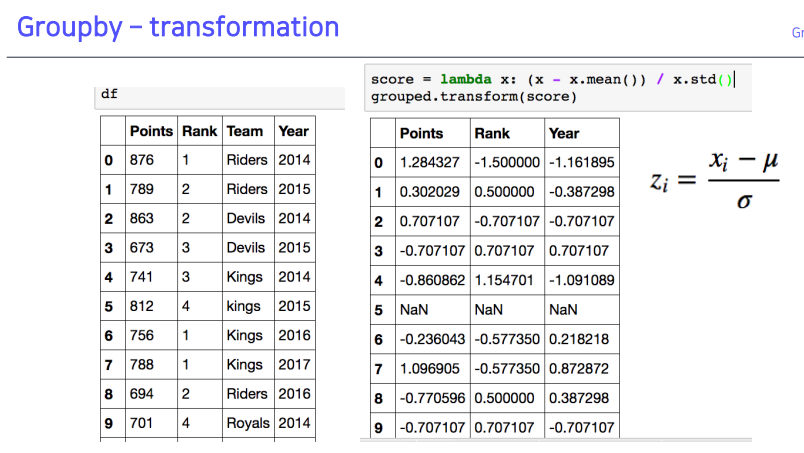
- Normalization(
정교화) 시키는 것 → 개별데이터에 적용- 그룹 상태에서 그룹 별로 연산을 할 수 있도록 하며, 그룹 별 연산을 해줄 때 각각 값들에 영향을 줄 수 있도록 해줌
2-4. Groupby - filter
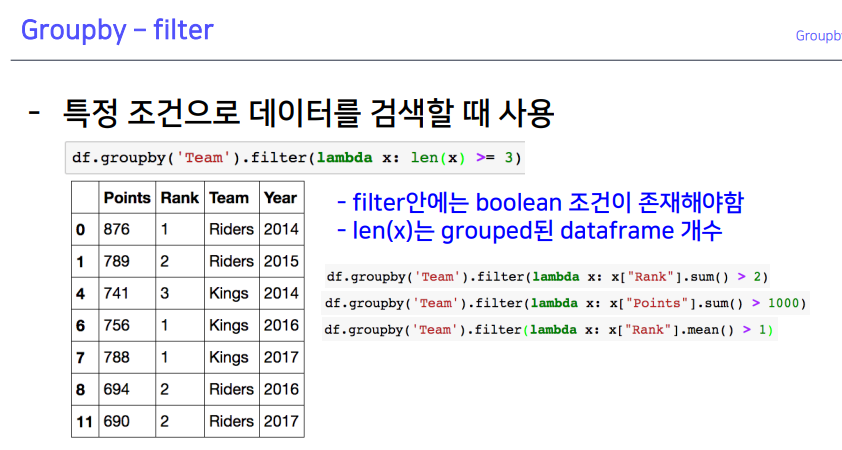
- 람다에 조건을 넣어주면, 그룹바이 된 상태에서 조건에 만족한 값만 뽑을 수 있음
- 그룹 바이 된 상태이다 보니, 랭크라는 값이 그룹별로 모아져 있을 텐데 그 sum 이 이보다 클 때
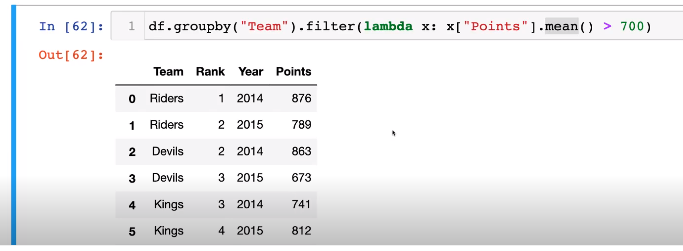
3. Case study
3-1. Data
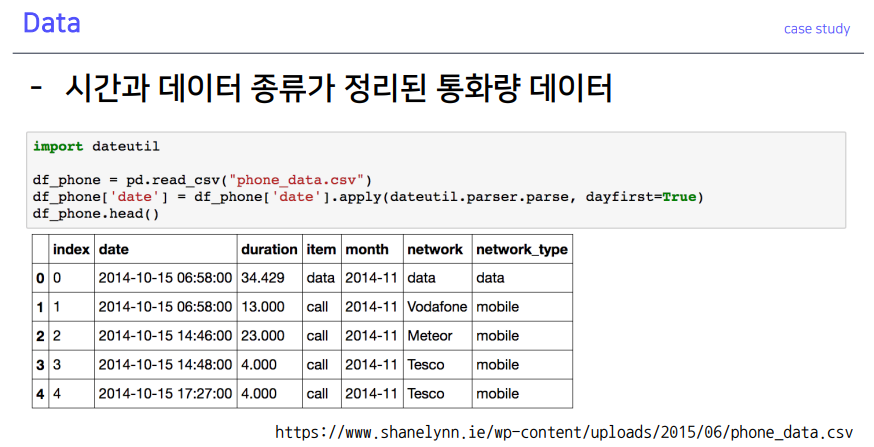
wget함수로 데이터 다운로드- 데이트 타입을 datetype으로 바꿔주어야 함
**dateutil.parser.parse**
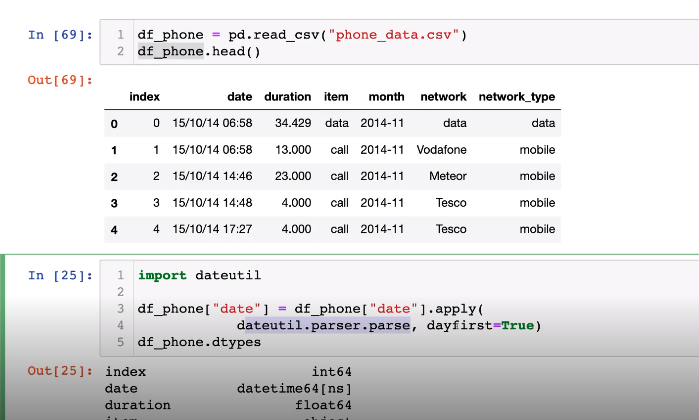
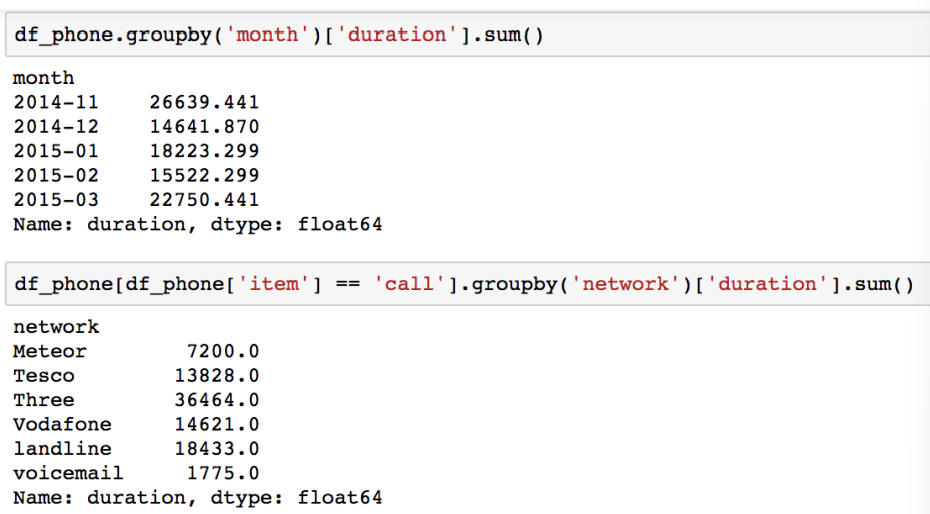
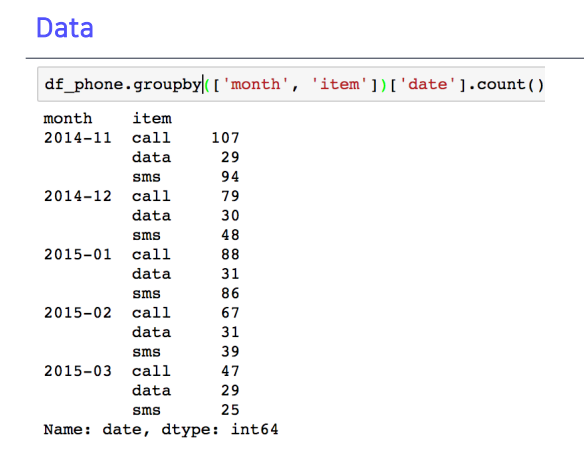
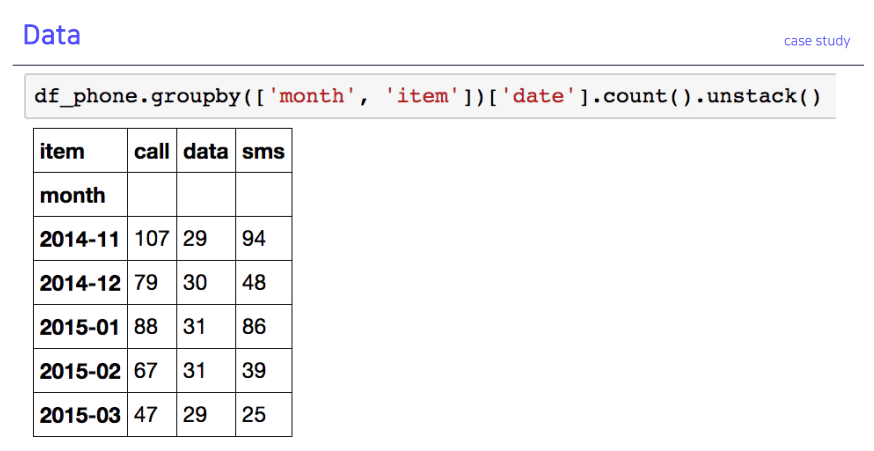
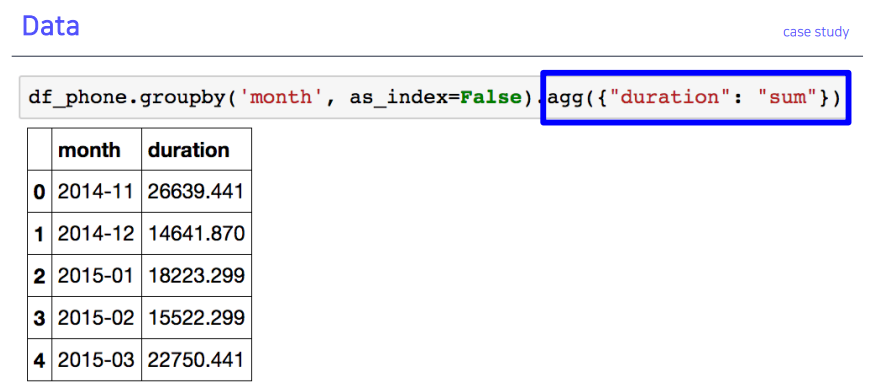
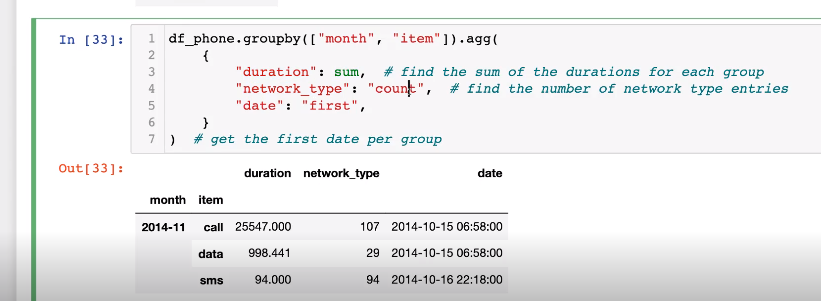
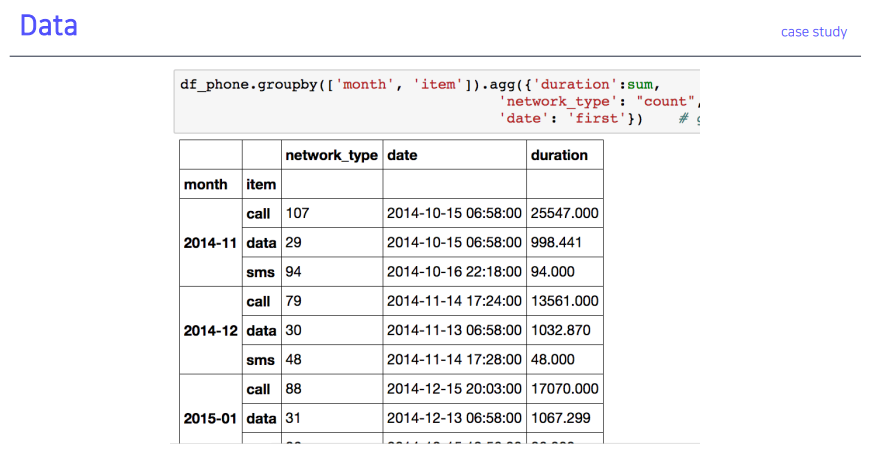
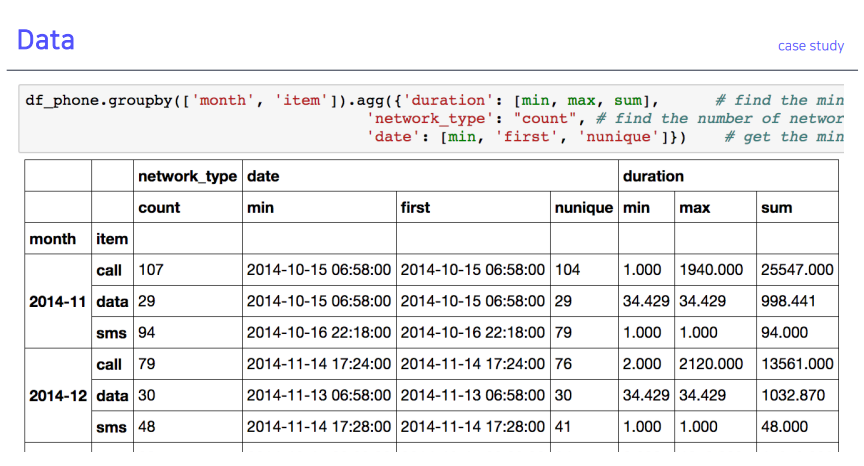
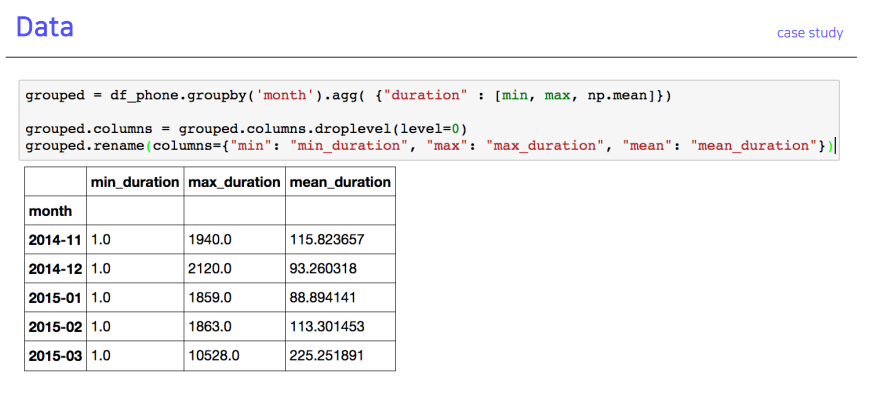
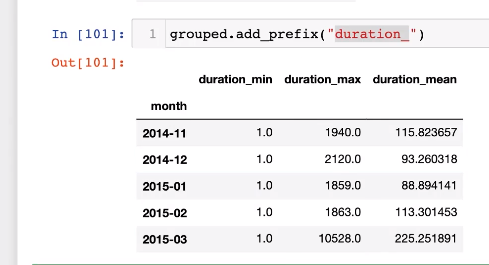
prefix함수 출력 결과
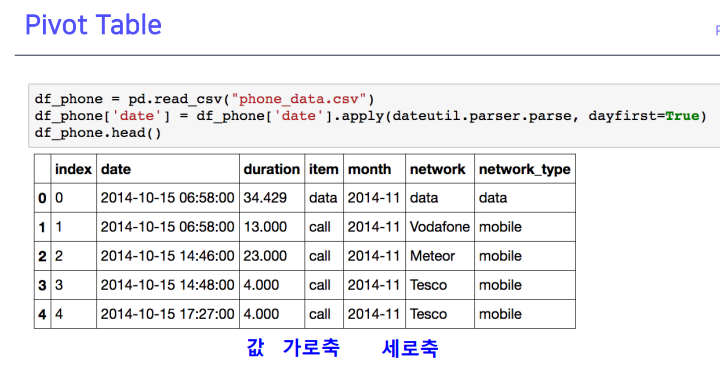
4. Pivot table Crosstab
4-1. Pivot Table
- index 축은 groupby와 동일
- column에 추가로 라벨링 값을 추가해서, value에 numeric type 값을 aggregation 하는 형태
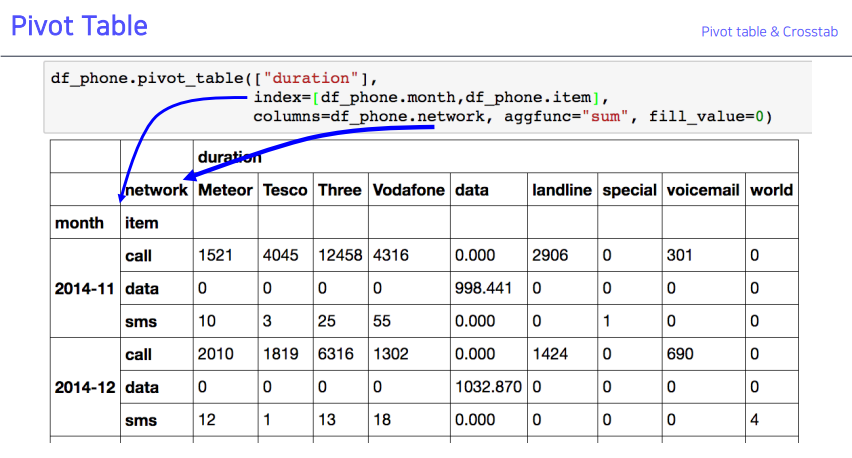
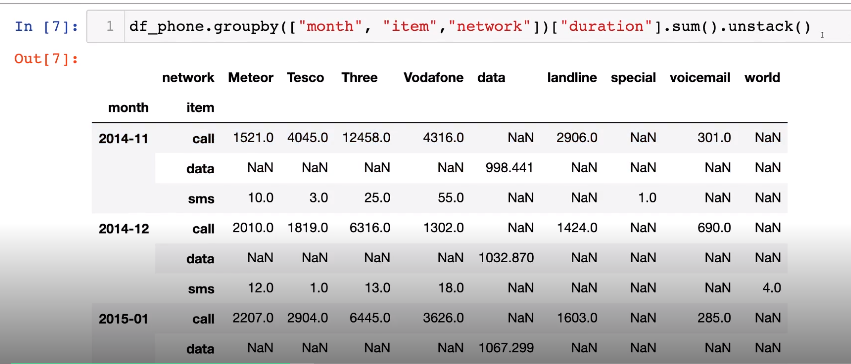
- group by로 비슷하게 출력하는 예시
4-2. Crosstab
- 특히 두 칼럼에 교차빈도, 비율, 덧셈 등을 구할 때 사용
- pivot table의 특수한 형태
- user- item rating matrix 등을 만들 때 사용 가능
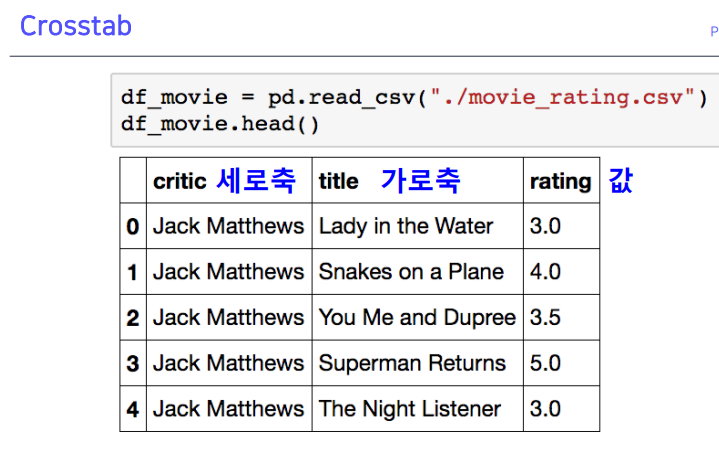
영화평점과 비슷
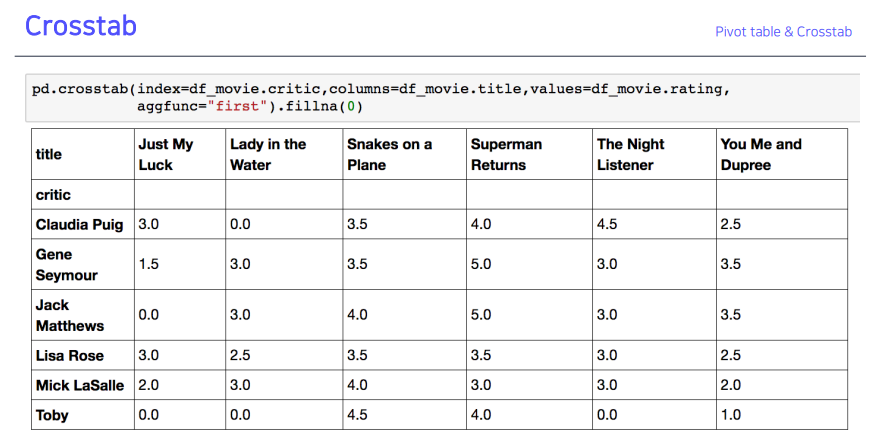
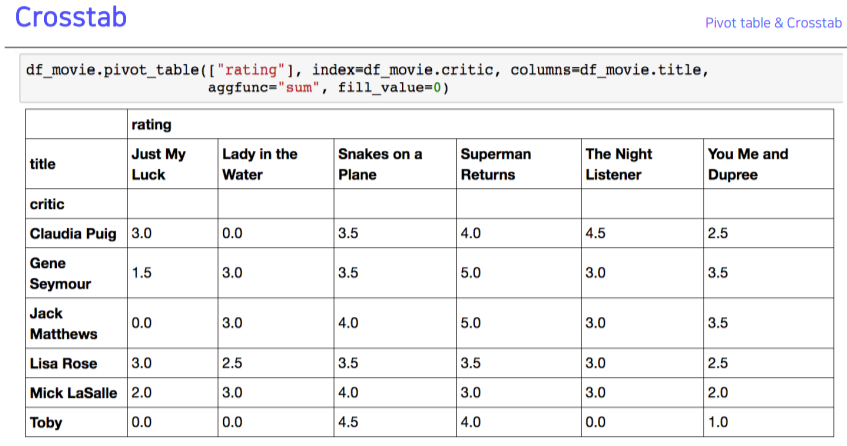
- Groupby, pivot table, crosstab 모두 비슷하기에 가장 편한 걸 쓰면 됨
5. Merge & Concat
5-1. merge
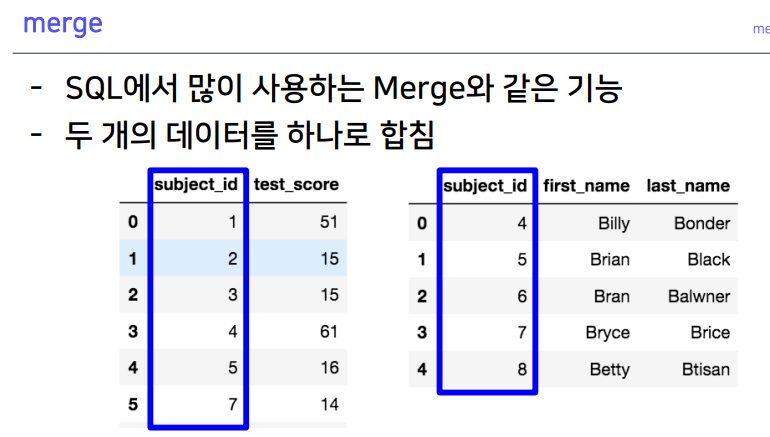
- subject_id 기준으로 merge
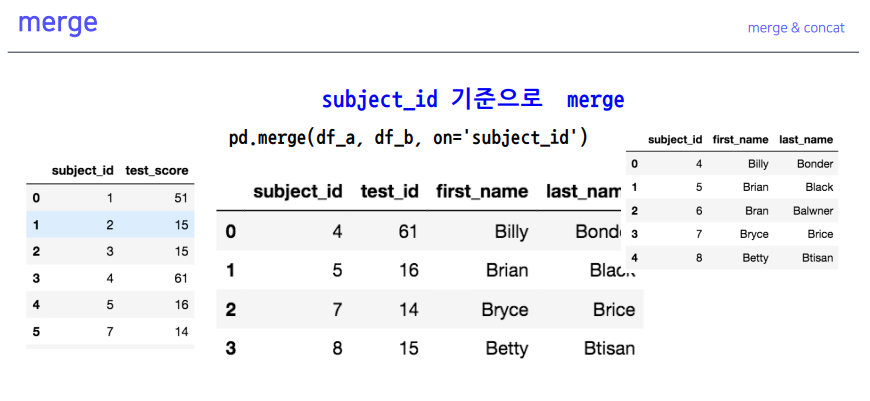
- 양쪽에 다 같은 컬럼이 있어야
on사용 가능
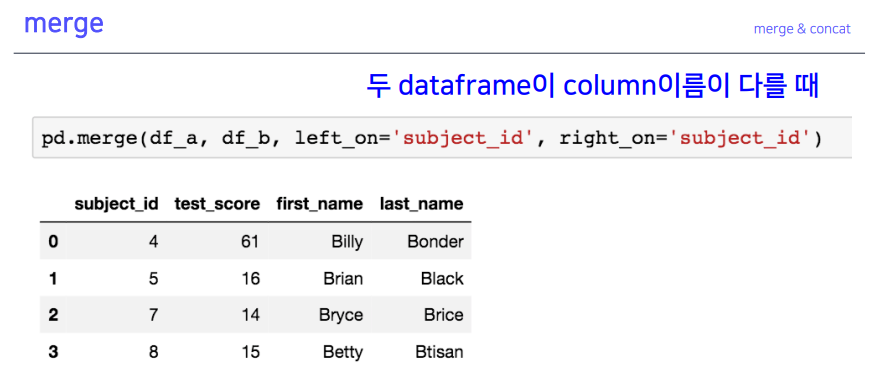
- 두 컬럼 이름이 다르면
left on,right on을 통해 merge 가능
5-2. join method
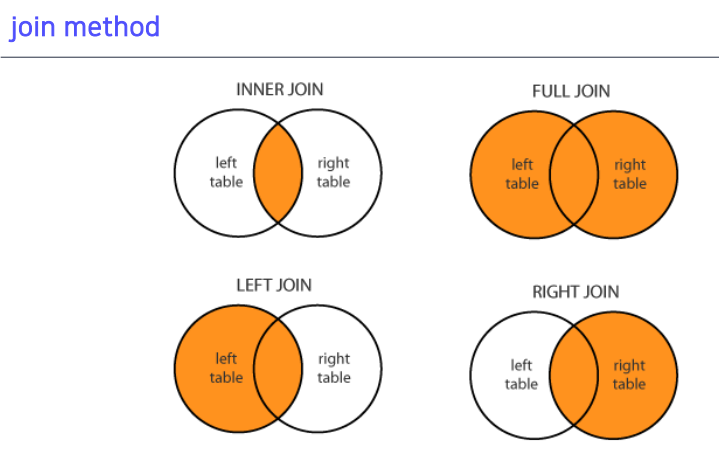
- join 규칙
inner join은 양쪽 다 같은 값이 있어야함left는 왼쪽 것만 보여주고 없는 것은non값 (right동일)
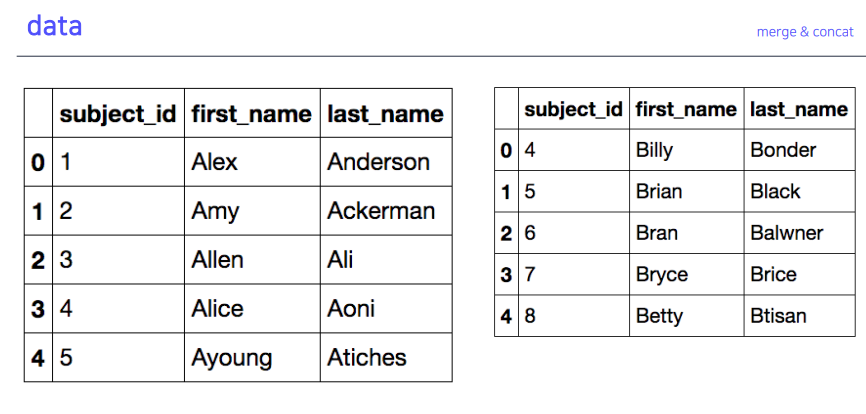
5-3. data
5-4. left join
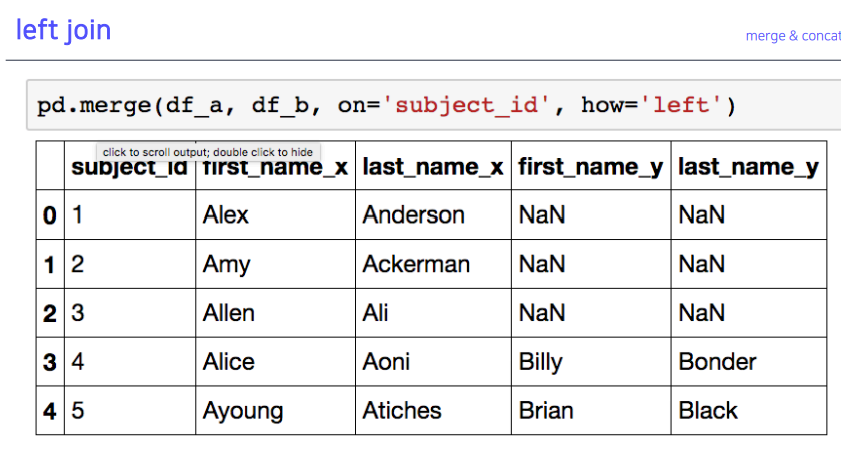
- 왼쪽에 있는 건 다 나오고, 오른쪽에 없으면 nan
5-5. right join
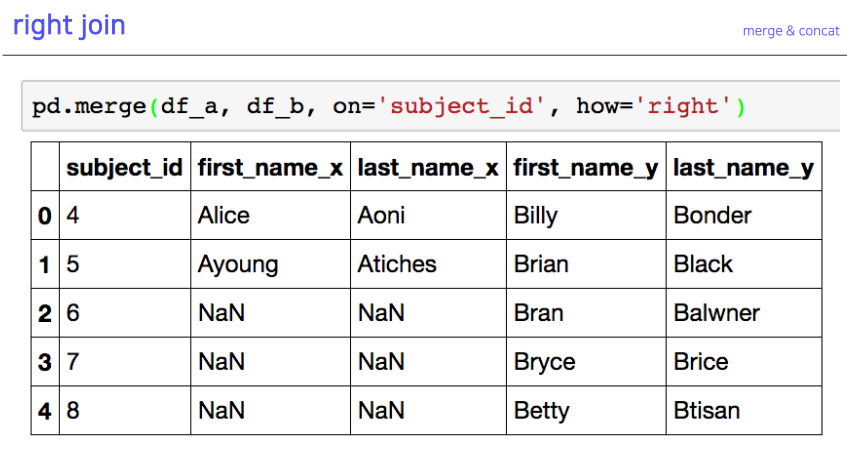
- 오른쪽에 있는 건 다 나오고, 왼쪽에 없으면 nan
5-6. full(outer) join
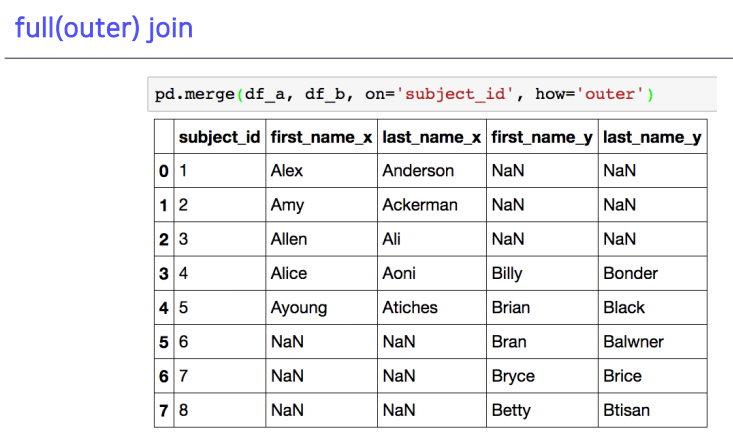
5-7. inner join
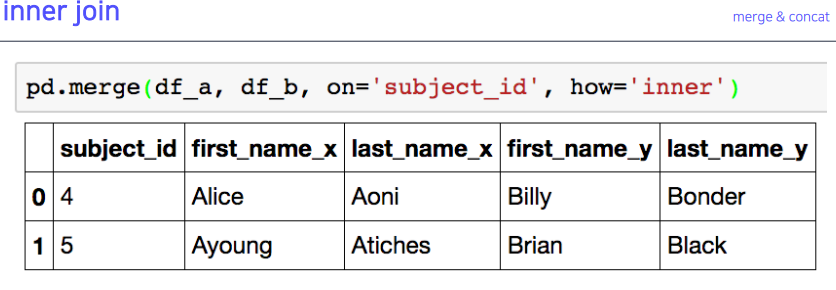
5-8. index based join
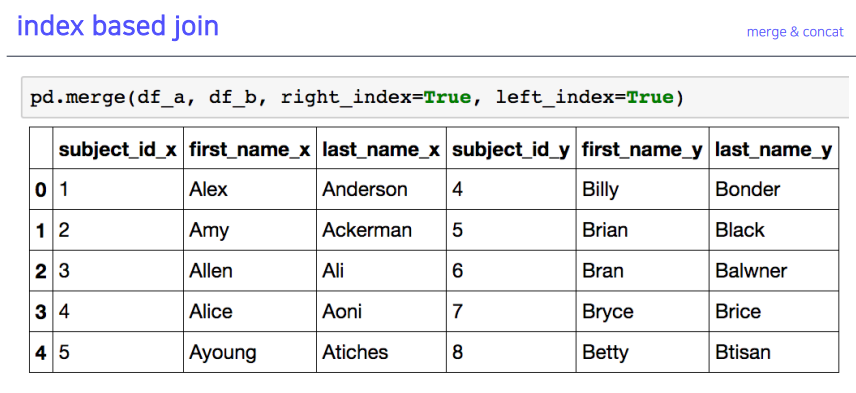
- 인덱스 값을 기준으로 합칠 때, 인덱스 값을 기준으로 합침
5-9. concat
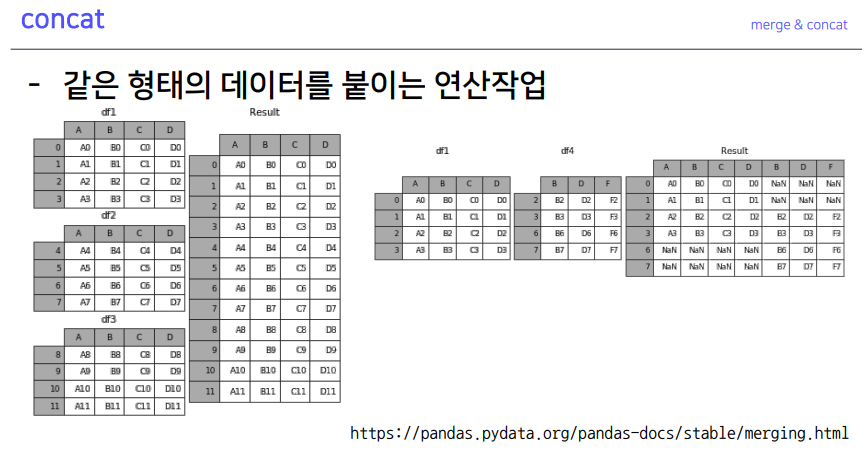
- 밑 혹은 옆으로 붙일 수 있음
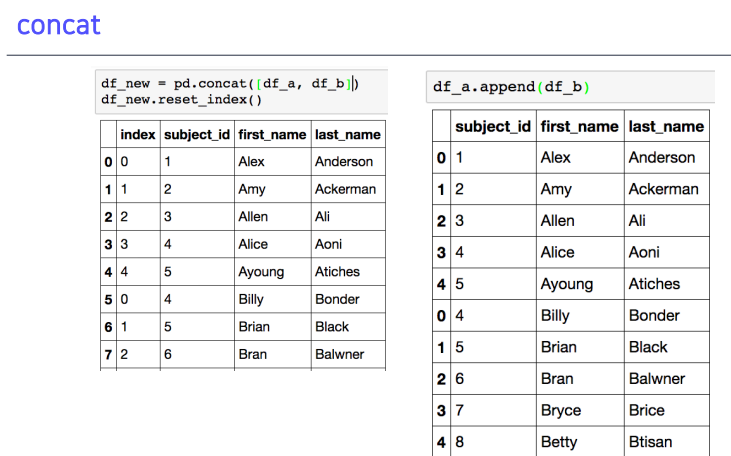

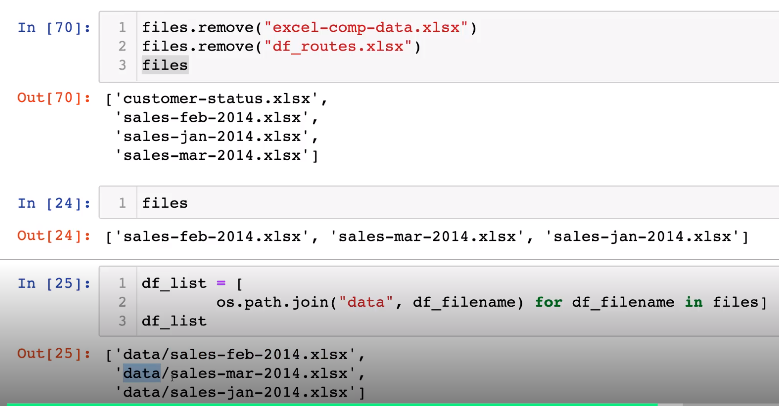
axis =1은 옆으로 붙음- 월별 실적 엑셀파일들을 concat으로 합칠 수도 있음
- 엑셀파일 불러오는 방법
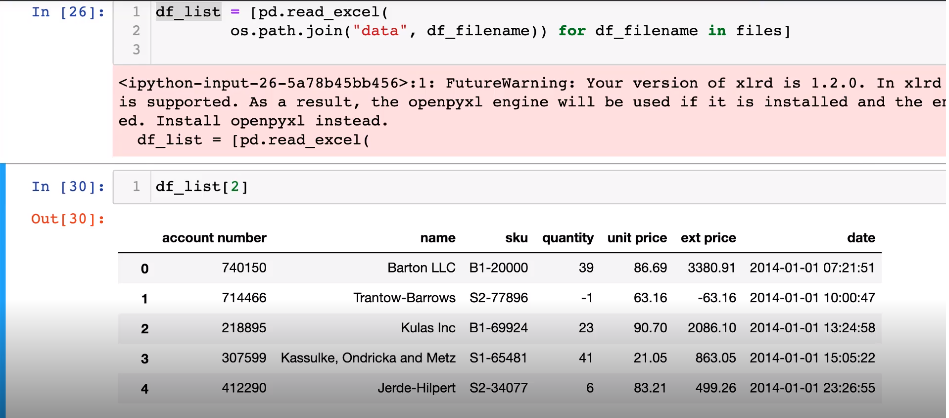
6. persistence
6-1. Database connection
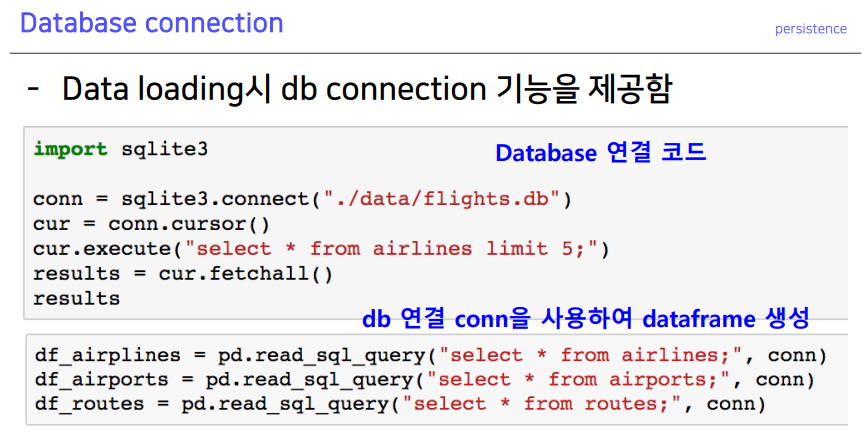
select문으로 데이터문을 뽑을 수 있음
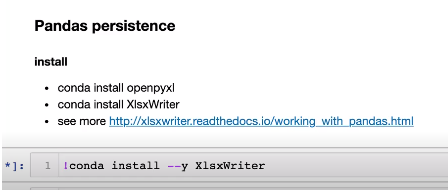
6-2. XLS persistence

- 설치해야 사용 가능하며, 하기와 같이 설치하면 됨
6-3. Pickle persistence


세상을 이롭게하는 AI Engineer