
학습목표
- 최적화와 관련된 주요한 용어와 다양한 Gradient Descent (경사하강법) 기법
- 먼저, 최적화에는 Generalization, Overfitting, Cross-validation 등 다양한 용어가 있으며, 각 용어들의 의미에 대해 학습
- Further Questions
- 올바르게(?) cross-validation을 하기 위해서는 어떤 방법들이 존재할까?
- Time series의 경우 일반적인 k-fold cv를 사용해도 될까?
1. Gradient Descent (경사하강법)
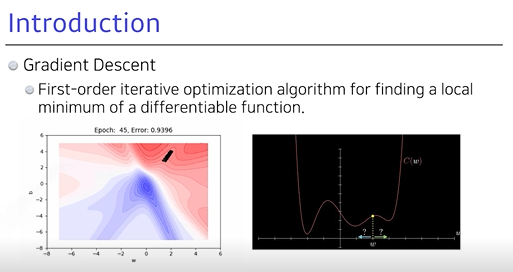
- Loss function가 줄었을 때,
최적화에 도달- 찾고자하는 파라미터에 대해 Loss function을 미분한 편미분 값으로 학습 목표
- 1차 미분 값 사용 → 지속적 반복으로 최적화 →
local min을 찾는게 목적
2. 최적화에서의 중요한 컨셉

3. Generalization (일반화)
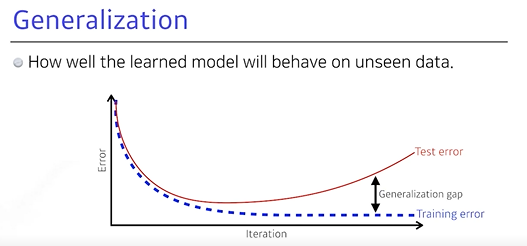
💡 일반화 성능을 높이는 것이 목표이지만, 높이게 되면 무조건 좋을까?
일반화 (Generalization): 학습을 시키면 iteration (반복)이 지나감에 따라, Training data에 대한Training error가 줄어듦- 그러나, Training error가 0에 가까워졌다고 해도, 항상 원하는 최적값에 도달했다는 보장은 없음
- 어느 정도 시간이 지나면,
Test error가 일어나고 성능이 떨어짐
- Training error와 Test error 간 차이와 Generalization이 좋다고 해서 Training data가 좋다고 설명 할 수 없음
- Generalization이 좋다라는 것은 이 네트워크의 성능이 Training data와 비슷하게 나오는 것
💡 하지만 Training data가 성능 자체가 안 좋다면?
- Generalization이 좋다고 해서 Test data의 성능이 좋다고 할 수 없음
- 그 이유는 Generalization은
Training data와 Test data 간 차이가 얼마나 나는지, 그리고일반화 성능만을 말하기 때문
4. Underfitting vs Overfitting
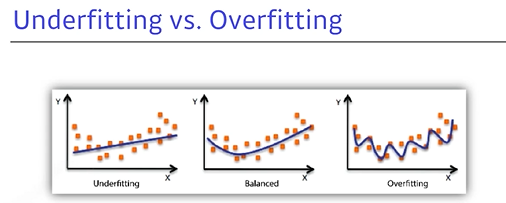
Overfitting: Training data에서 잘 동작하지만Test data에서 잘 작동하지 않는 것Underfitting: 네트워크가 너무 간단하거나 학습 데이터도 잘 맞추지 못하는 것Ballanced: Best
5. Cross-validation

- Training data와 Test data를 나누어 주어지며, 이는 Training data와 Validation data (검증 데이터)를 나눠서 Training data를 주고 학습시키려는 것이 목적
- Training data로 학습시킨 모델이
학습에 사용되지 않은 Validation data를 기준으로 얼마나 잘 되는 것을 보는 것
💡 Training data, Validation data를 얼마만큼 나누는 것이 좋을까?
반반? → Training data가 적기 때문에 성능이 덜 나올 수도 있음 → 이를 해결하려는 것이 Cross-validation
- Training data와 Validation data를 K개로 나누는 것
- 일반적으로, NN을 학습하는데 있어 많은 Hyper parameter가 존재
- 어떤게 좋은지 모르므로 일반적으로 Cross-validation을 활용해, 최적의 Hyper parameter set을 찾고 이를 고정한 상태에서 학습시킬 때 모든 데이터를 사용하며, 그래야 더 많은 데이터를 가지고 모델을 학습할 수 있음
test data는 학습의 어떤 방법으로든 사용해서는 안 됨
- test data로 Cross-validation를 하거나 Hyper parameter를 서칭(x)은 Cheating!
- 즉, 학습에서는 training data와 validation data를 활용하고, test data는 활용하면 안 됨
💡
Hyper parameter: 사용자가 직접 세팅해주는 값
- Hyper parameter는 모델링할 때 사용자가 직접 세팅해주는 값으로,
learning rate나 서포트 벡터 머신에서의 C, sigma 값, KNN에서의 K값 등 굉장히 많으며, 머신러닝 모델을 쓸 때 사용자가 직접 세팅해야 하는 값은 상당히 많음.- Hyper parameter는 정해진 최적의 값이 없음. 휴리스틱한 방법이나 경험 법칙(rules of thumb)에 의해 결정하는 경우가 많으며, 베이지안 옵티미제이션과 같이 자동으로 하이퍼 파라미터를 선택해주는 라이브러리도 있긴 함.
- parameter와 Hyper parameter를 구분하는 기준은 사용자가 직접 설정하느냐 아니냐로,
사용자가 직접 설정하면 Hyper parameter,모델 혹은 데이터에 의해 결정되면 parameter
💡
parameter: 최적화에서 찾고 싶은 값으로 모델 내부에서 결정
- parameter는 모델 내부에서 결정되는 변수로, 또한 그 값은 데이터로부터 결정됨. 예를 들면, 한 클래스에 속해 있는 학생들의 키에 대한 정규분포를 그린다고 하면, 정규분포를 그리면 평균(μ)과 표준편차(σ) 값이 구해짐. 여기서 평균과 표준편차는 parameter이며, 이 때 parameter는 데이터를 통해 구해지며 모델 내부적으로 결정되는 값으로, 사용자에 의해 조정되지 않음. (They are often not set manually by the practitioner)
- 선형 회귀의 계수도 마찬가지로, 수많은 데이터가 있고 그 데이터에 대해 선형 회귀를 했을 때 계수가 결정되며, 이 계수는 사용자가 직접 설정하는 것이 아니라 모델링에 의해 자동으로 결정되는 값(They are required by the model when making predictions)
6. Bias and Variance
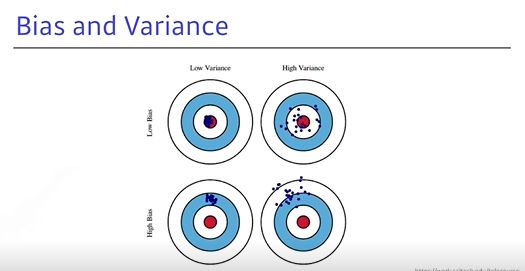
- Underfitting과 Overfitting에 이어지는 것으로, 활을 쐈을 때 같은 위치를 맞추면 좋은 것과 유사 개념
Low Variance: 입력했을 때 일관적으로 출력되는 좋은 경우High Variance: 비슷한 값을 입력해도 출력이 많이 달라지며, Overfitting될 가능성이 높아짐- 평균적으로, 같은 입력에 대해 출력이 많이 분산되더라도 타겟에 접근하게 되면 variance가 낮다고 보고 높은 건 많이 벗어난 것으로 볼 수 있음
7. Bias and Variance Tradeoff

- 학습 데이터에 noise가 있다고 가정했을 때, 이러한 noise가 있는 타겟 데이터를 최소화하는 것은 3가지 파트로 나눌 수 있음
Tradeoff (균형): 최소화하려는 것은 1개의 값인데, 1개가 줄어들면 나머지 1개가 커지는 것- t는 target이고 은 NN 출력 값
- t라는 true target에 noise가 있다 가정하고, cost를 최소화하는 것은 bias, variance, noise로 나뉨
- 모델 특성이 bias를 많이 줄이면 variance가 높아질 가능성이 커지고, variance를 줄이면 bias가 높아질 가능성이 커짐
- 학습 데이터에
noise가 있을 경우,bias와 variance를 둘 다 줄일 수 있는 경우는얻기 힘듦
8. Bootstrapping
부츠의 끈: 신발끌을 위로 들어 하늘을 날겠다는 허망한 꿈- 통계학에서 어떤 test 혹은 metric을 한 번에 다 사용하는 것이 아니라 이 중 몇 개만 활용
- 80개씩 활용한 모델을 여러 개 만들 수 있는데, 이때 하나의 입력에 대해 각각의 모델이 같은 값을 예측할 수 있지만, 다른 값도 예측할 수 있음
- 이 모델들이 예측하는 값들이 얼마나 일치하는 지를 보거나, 전체적인 모델을 예측하고자 할 때 활용
- 학습 데이터가 고정 돼 있을 때, 그 안에서 샘플링을 통해 학습 데이터를 여러 개 만들고 이를 활용해 여러 모델을 만들어 무언가를 하기 위함
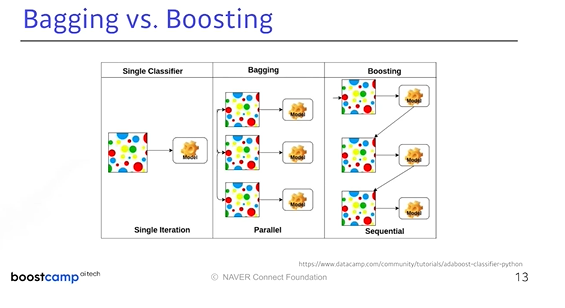
9. Bagging vs Boosting

Bagging(Bootstrapping aggregating의 약자)
- 학습 데이터가 고정 돼 있을 때, 그 안에서
샘플링을 통해학습 데이터를 여러 개만들고 이를 활용해여러 모델을 만들어 아웃풋을 내고평균을 내기 위함 (앙상블이라고도 함)- 테스트 명이 들어왔을 때 모두 돌려보고 그 값의 평균이 1개의 모델을 썼을 때보다 좋은 성능을 낼 때가 많으며, 캐글에서 앙상블로 많이 쓰고 이는 Bagging에 속할 때가 많음
Boosting
- sequencial하게 바라봐서 간단하게
1개의 모델만 만들고모델을 학습 데이터에 대해 돌려봄- 간단하기 때문에 80개에 대해 잘 예측했지만 20개는 예측을 잘 못할 수 있음
- 이 때
2번째로 모델을 만들어보고, 20개에 대해서만 잘 동작하는 모델을 만들어 봄- 그리고 이러한(
weak learner)을 합치고, 하나하나의 모델들을 sequencial하게 합쳐서strong learner로 만듦- 각각 weak learner들의 웨이크를 찾는 식으로 정보를 취합
💡 위 그림이 잘 설명해주고 있음
Single Classifier: 데이터 1개가 있을 때, 1개의 모델을 만듦Bagging: 여러 개 모델을 만들고 독립적으로 이 모델들을 돌려 결과를 출력Sequential: 독립적으로 모델을 돌리는 것이 아닌, weak learner들이 하나의 strong learner로 만들어서 결과적으로 한 개의 모델을 만듦

세상을 이롭게하는 AI Engineer