
학습목표
- panel data 의 줄임말인 pandas는 파이썬의 데이터 처리의 사실 상의
표준라이브러리pandas는 파이썬에서 일종의 엑셀과 같은 역할을 하여 데이터를 전처리하거나 통계 처리시 많이 활용하는 피봇 테이블 등의 기능을 사용할 때 쓸 수 있으며, pandas 역시 numpy를 기반으로 하여 개발되어 있으며,R의 데이터 처리 기법을 참고하여 많은 함수가 구성되어 있고, 기존 R 사용자들도 쉽게 해당 모듈을 사용할 수 있도록 지원
1. Pandas
1-1. pandas 설치 및 데이터로딩
- 구조화된 데이터의 처리를 지원하는 Python 라이브러리
- panel data → pandas
- 고성능 array 계산 라이브러리인 numpy와 통합하여, 강력한 “스프레드 시트” 처리기능을 제공
- 인덱싱, 연산용함수, 전처리 함수 등 제공
- 데이터처리 및 통계분석을 위해 사용
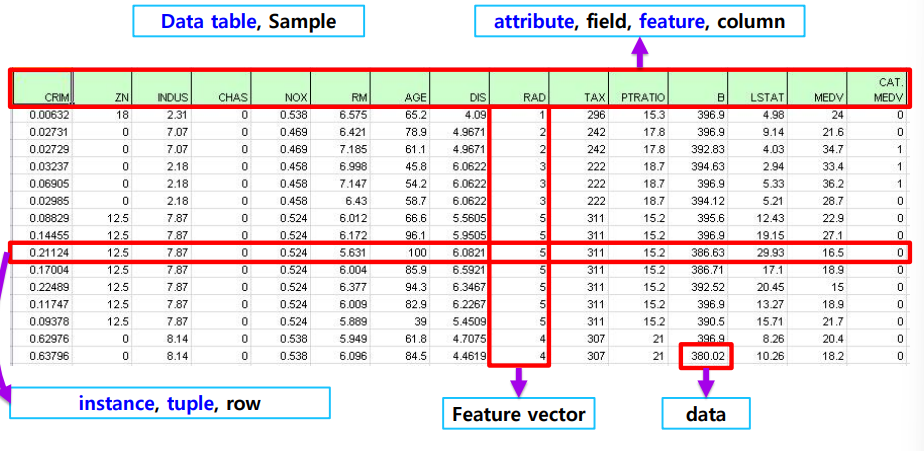
- 전체 데이터 : 데이터 테이블
- 머릿글 : 필드, attribute
- 한 행 : row, instance, tuple
- 한 열 : feature vector
- 한 데이터 : 값, value


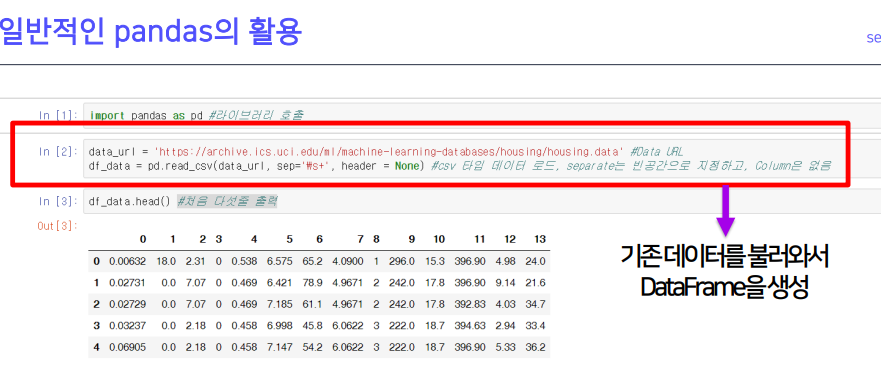
- read.csv(
위치 혹은 파일,\s(띄어쓰기)+(여러 개가 있다) →나누는 기준,헤더는 지정하지 않음)
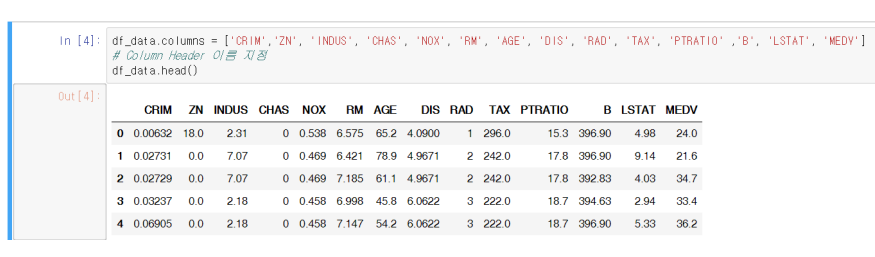
colums= 이름을 설정한 예시
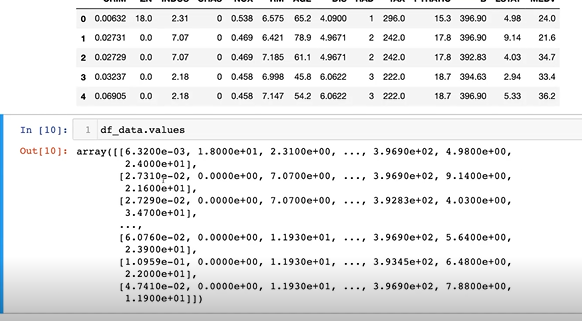
values= numpy 타입으로 활용하기 위한 변형 예시
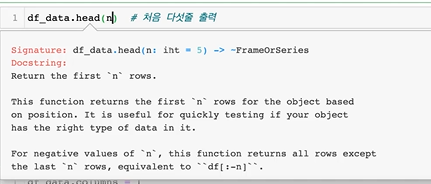
head→ shift+tab 눌러본 예시
2. Series (기초적인 객체의 개념)
2-1. pandas의 구성 및 활용
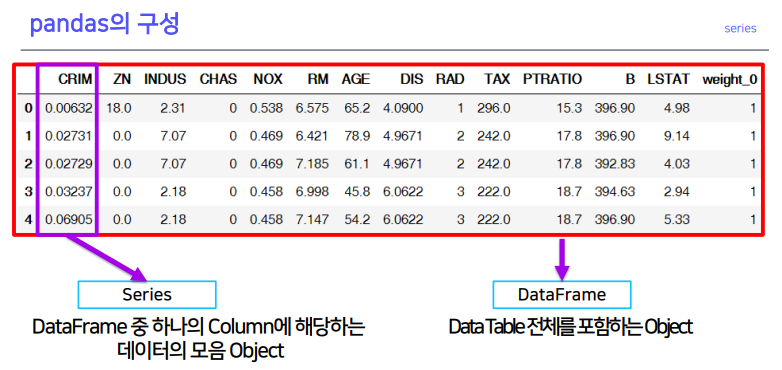
- 보라색 :
series- 전체 :
data frame
2-2. Series
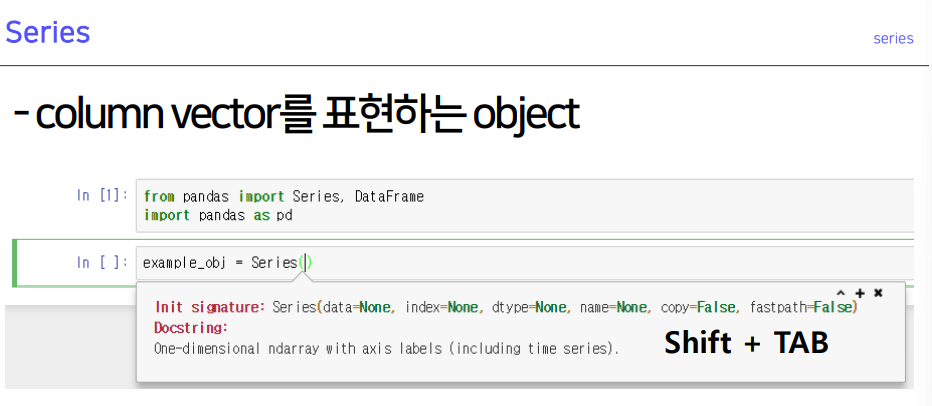
series: 컬럼 벡터를 표현하는 오브젝트
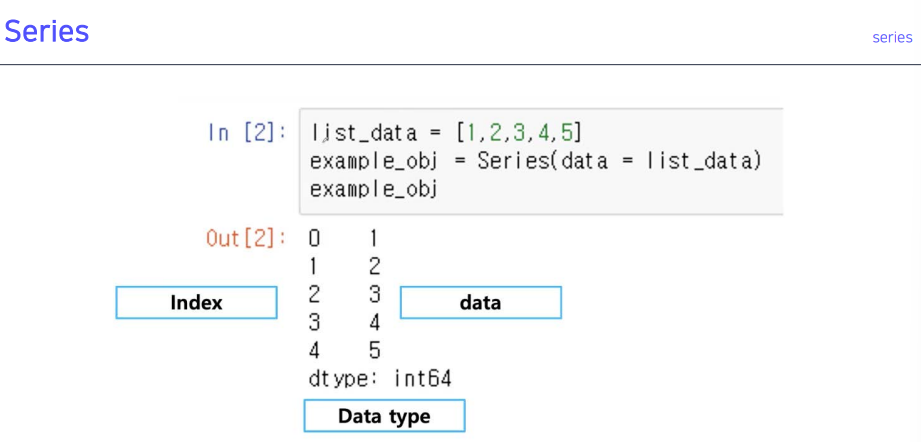
- numpy를 pandas로 쓰기 위해 시리즈 사용
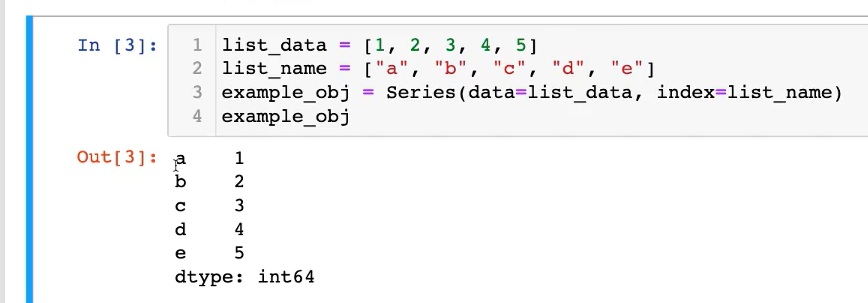
- 기존 데이터가 있고, 이 데이터를 접근하는 인덱싱이 숫자로 돼 있고, 문자로도 지정 가능

- ndarray의 서브클래스
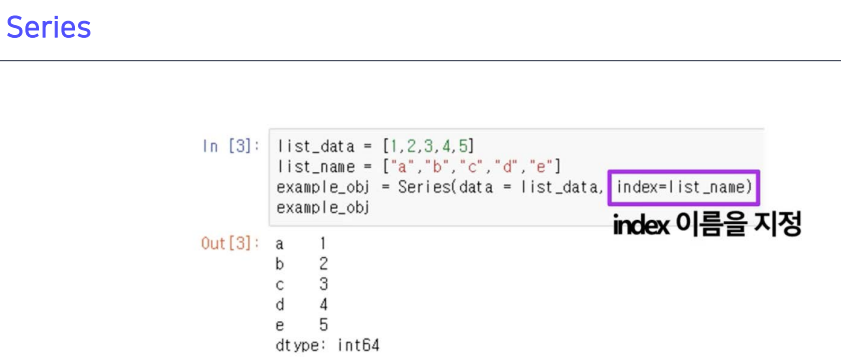
- 리스트 값과의 차이점
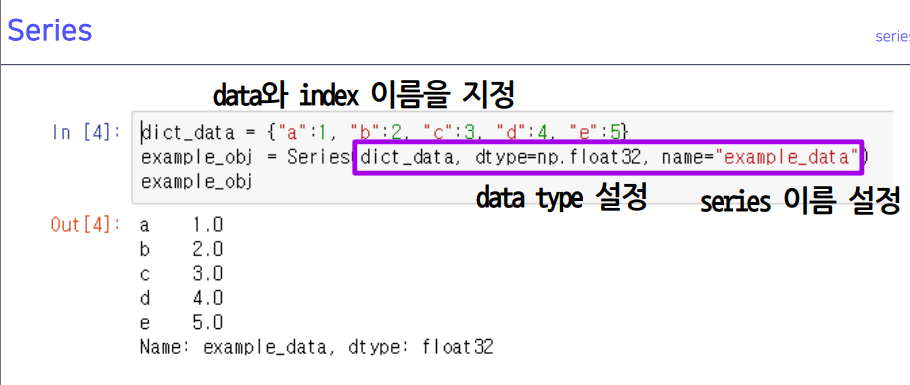
- 키값이 인덱스 값이 됨 + value값
- 예시



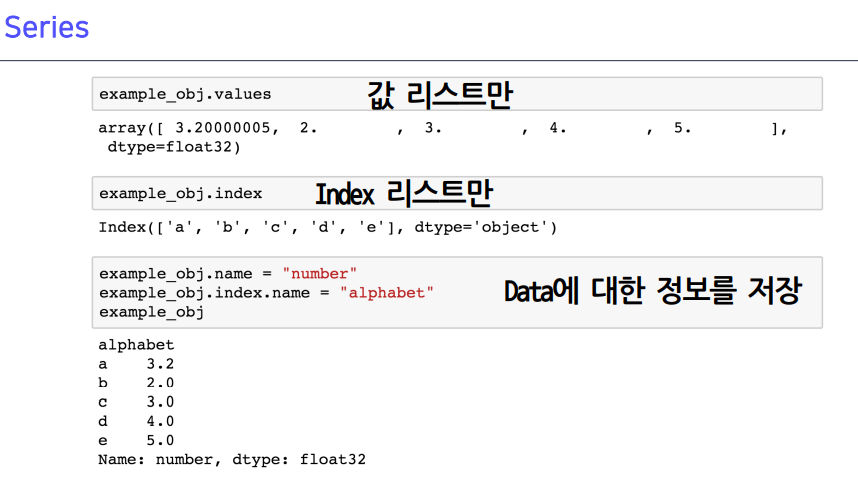
name은 이름을 지정해줄 수 있음 (보통 칼럼이름, 인덱스 이름 지정도 가능)
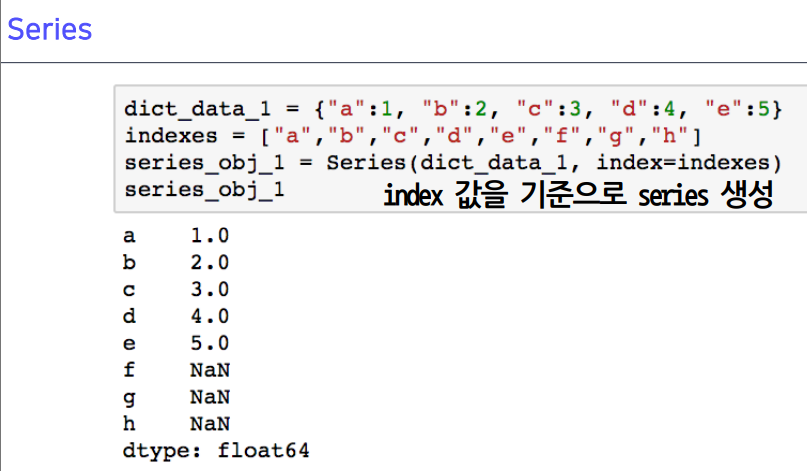
- 기본으로 시리즈 데이터 (데이터프레임)는 인덱스가 기준이 되기 때문에,
추가로 값을 생성해줌 (f~h)
3. dataframe

3-1. dataframe memory & overview

- 데이터 타입이 모두 다를 수 있음. (int, float, str 등)
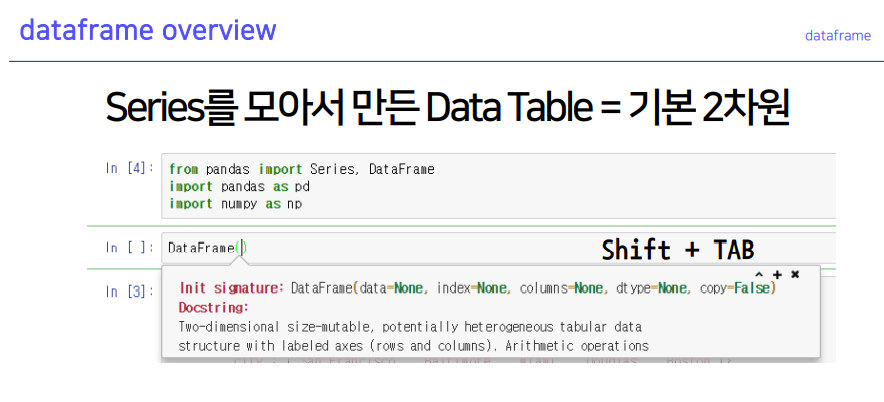
csv 형태로 주로 부름 (혹은 excel)
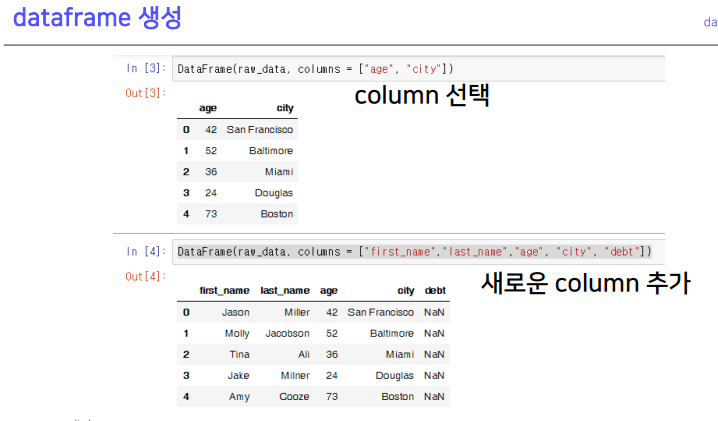
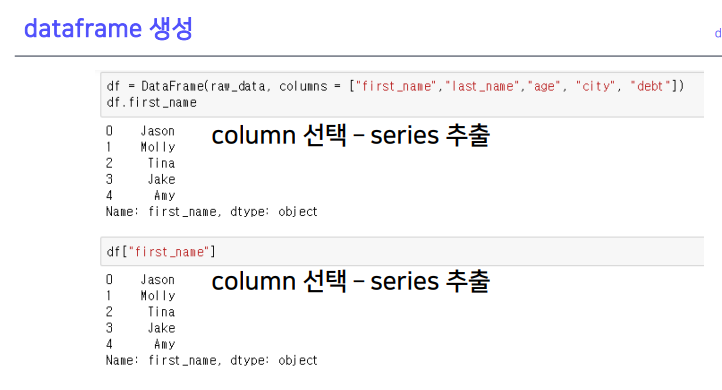
3-2. dataframe 생성
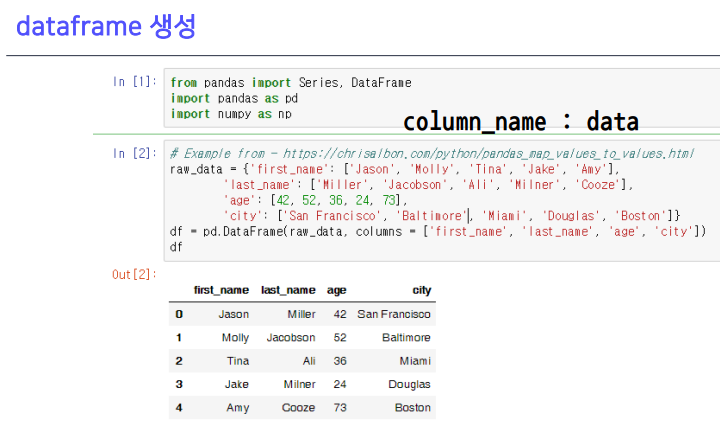
- 키값들이 칼럼의 이름으로 들어감
점 .작은따옴표 ‘’
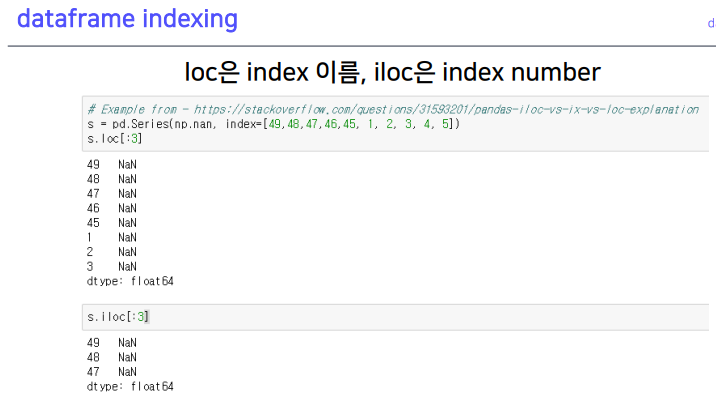
3-3. dataframe indexing

인덱싱= location + 인덱스의 값
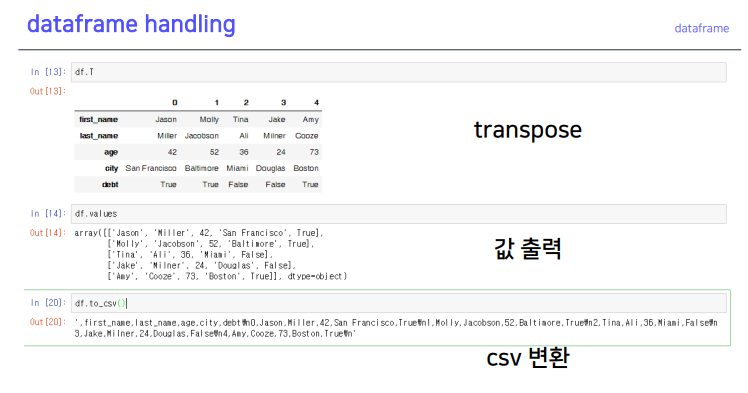
3-4. dataframe handling

불린 인덱스많이 사용, 이 값을 입력가능
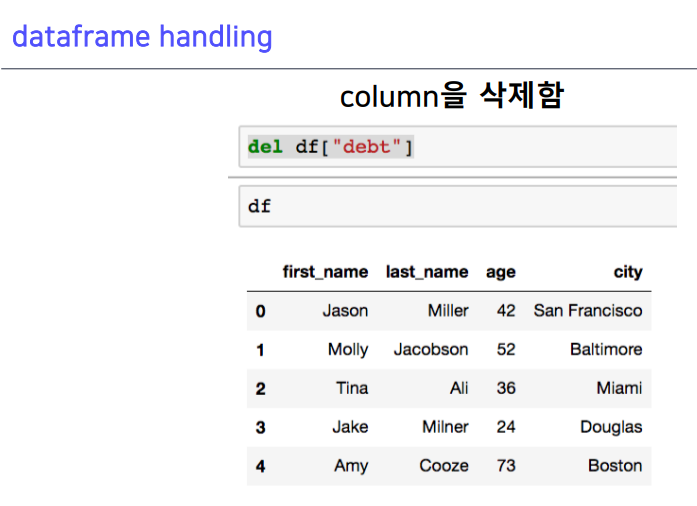
메모리 주소가 삭제됨
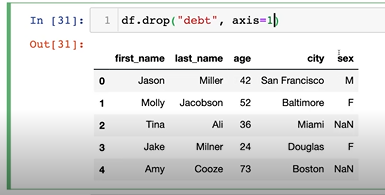
4. Selection & Drop
4-1. selection with column names
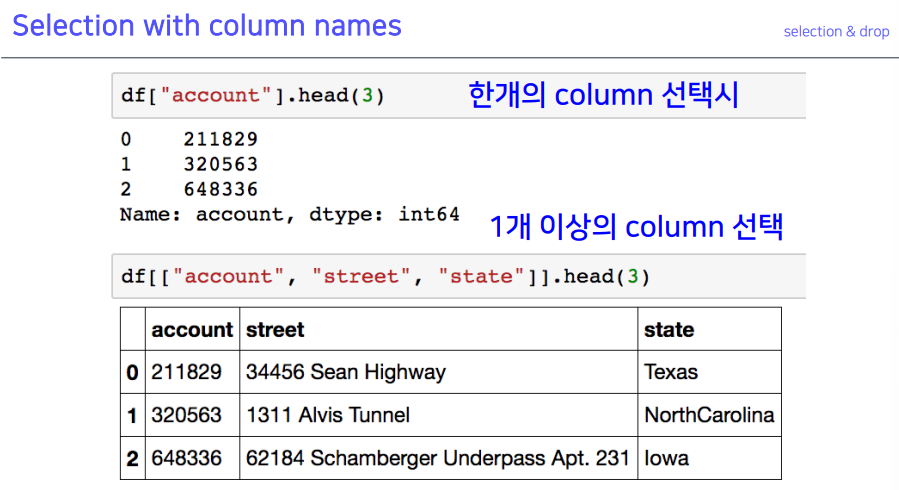
- 2번째 처럼 리스트를 만들어 컬럼 이름을 통해 여러 개 선택 가능
- 2개 뽑고
T를 하면 가독성이 좋아짐
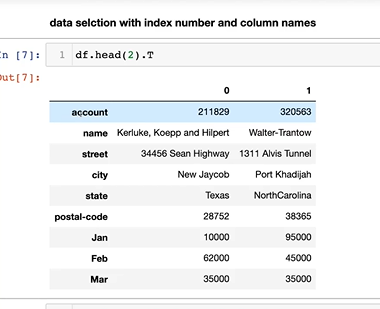
4-2. selection with index number


- 교수님은
컬럼은 str,index는 숫자로 지정해주시고 있다고 함
4-3. index 변경
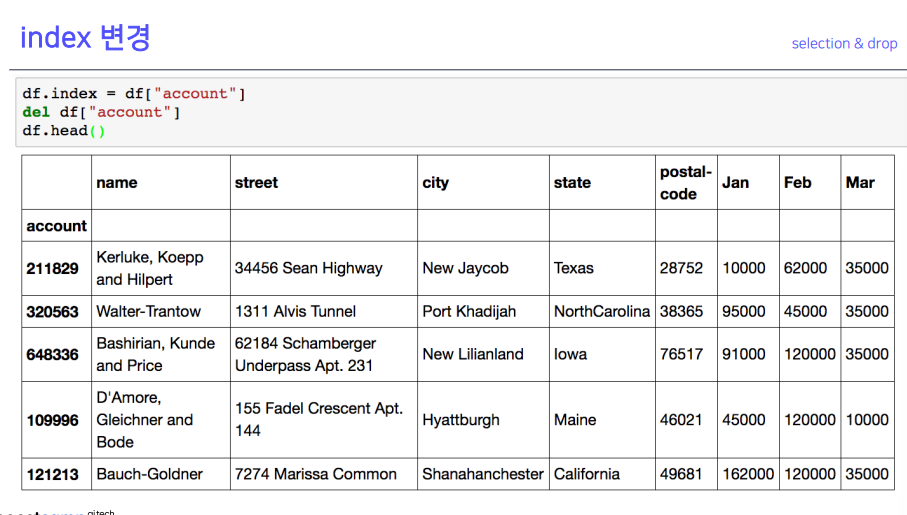
- 지울 수 있는 예시
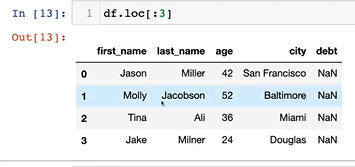
4-4. basic, loc, iloc selection
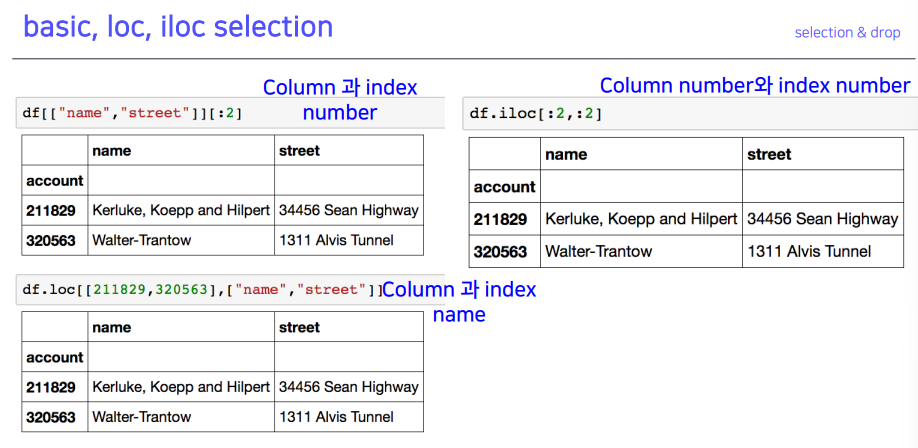
loc을 많이쓰심
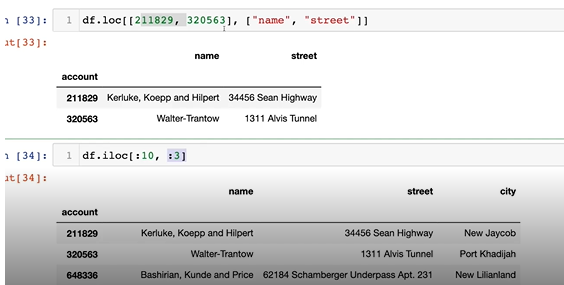
4-5. index 재설정

4-6. data drop
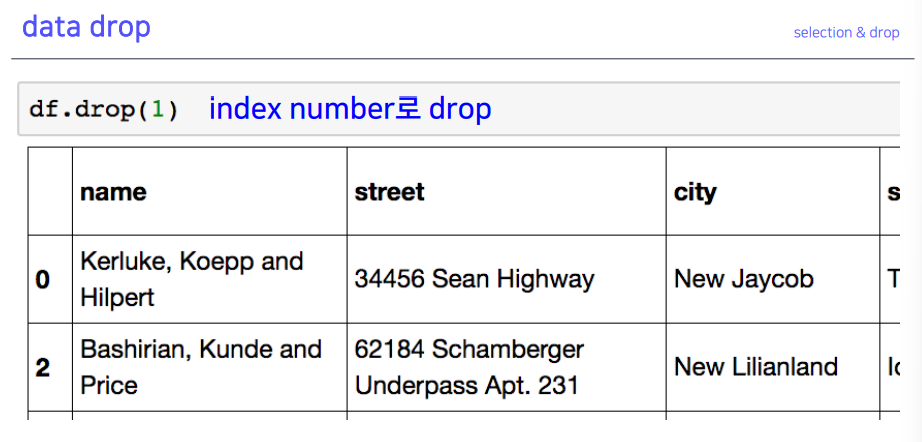
- 기존인덱스를 사라지게 함
(drop=True)→ 데이터프레임 변화 x

- 데이터프레임 값은 안 바꾸는 것을 권장하는데,
(inplace=True)를 하면 df 자체가 변하게 됨

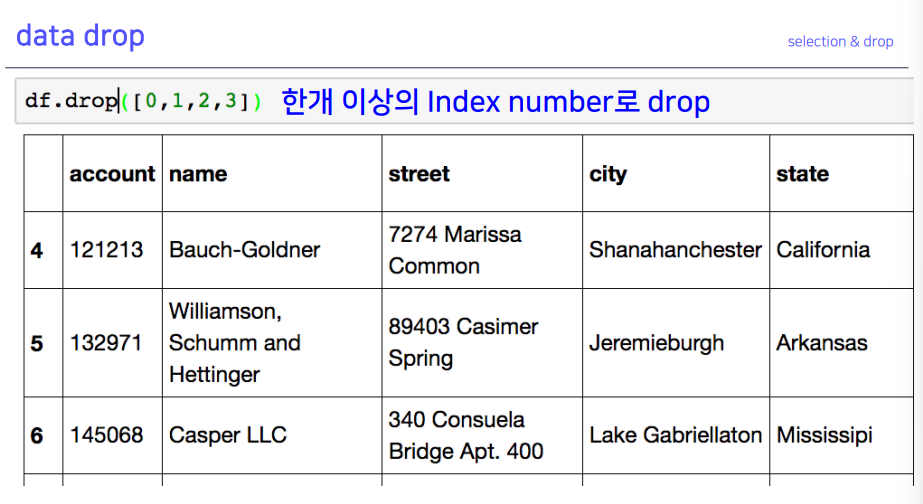

- 삭제는 아님! →
inplace를 해야 삭제 됨!
5. dataframe operations
5-1. series operation
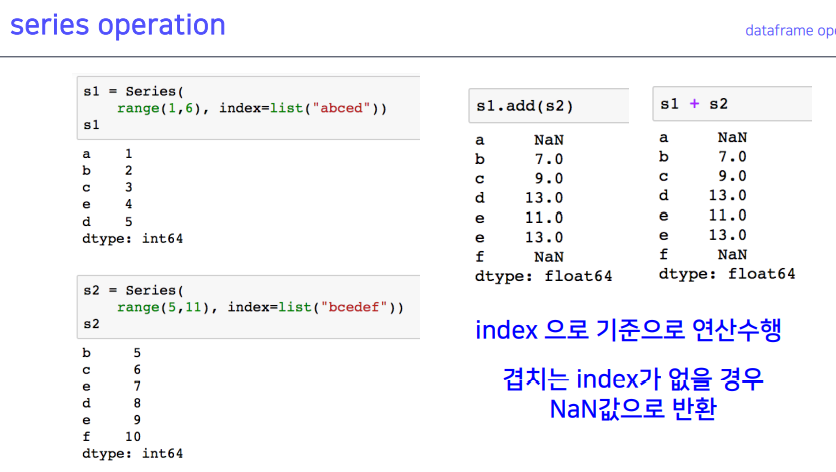
5-2. dataframe operation

- d랑 3이 없어 nan 값이 나옴 → fill value=0
5-3. series + dataframe
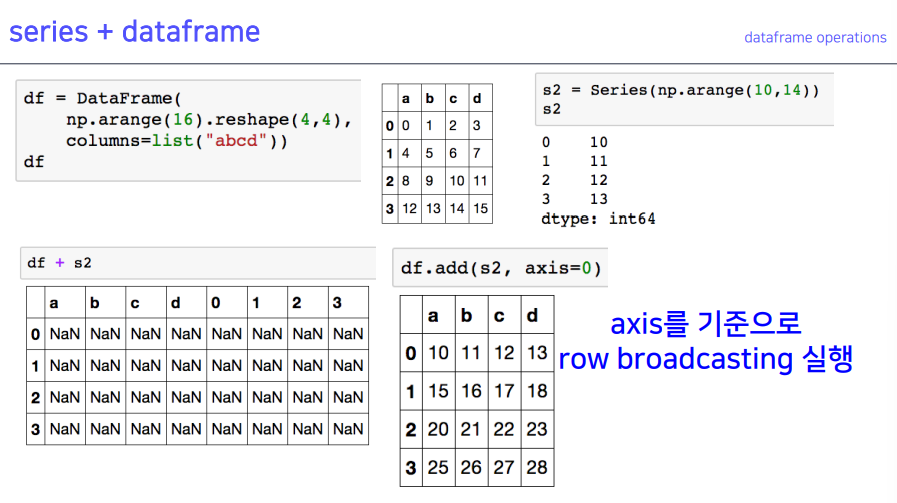
덧셈을 할 때 기준값axis를 늘 설정해줘야 함
6. lamda, map, apply
6-1. map for series

- 왼쪽 값에 제곱을 반환해 준 것이 우측
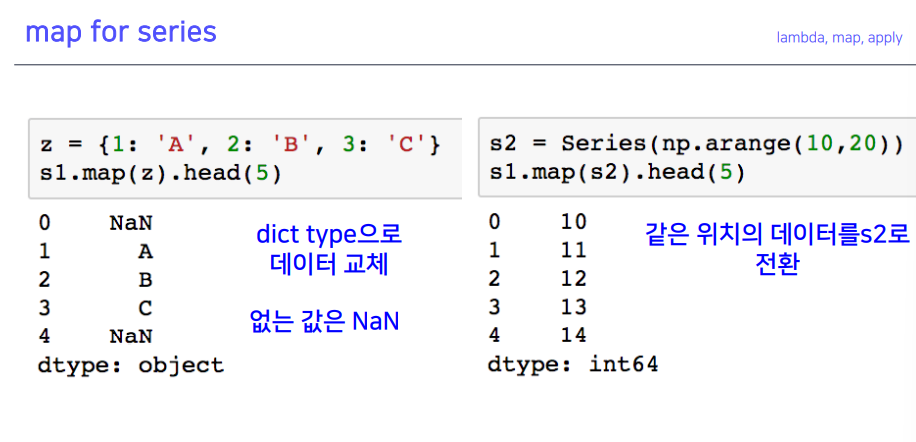
- 다른 시리즈 데이터도 들어갈 수 있음

- 성별 str → 성별 code
6-2. replace function

6-3. apply for dataframe
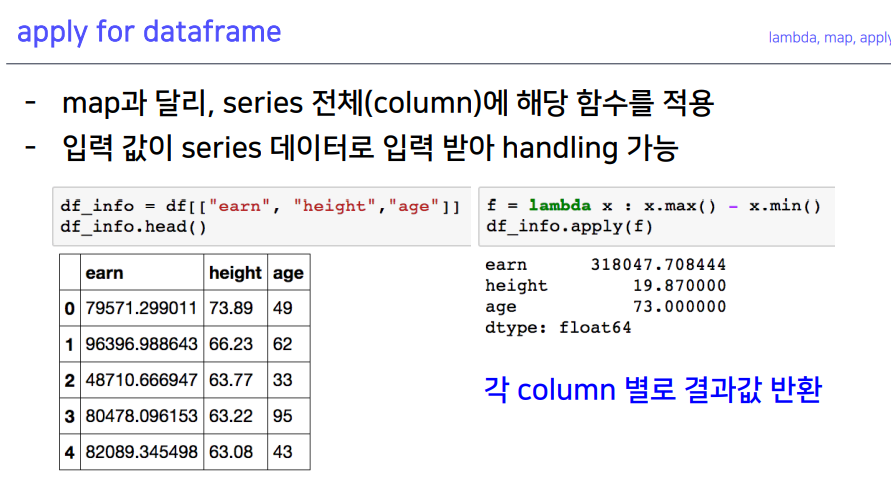
- 데이터프레임 전체에 적용됨


- 통계치 낼 때, apply 함수를 많이 씀
6-4. applymap for dataframe
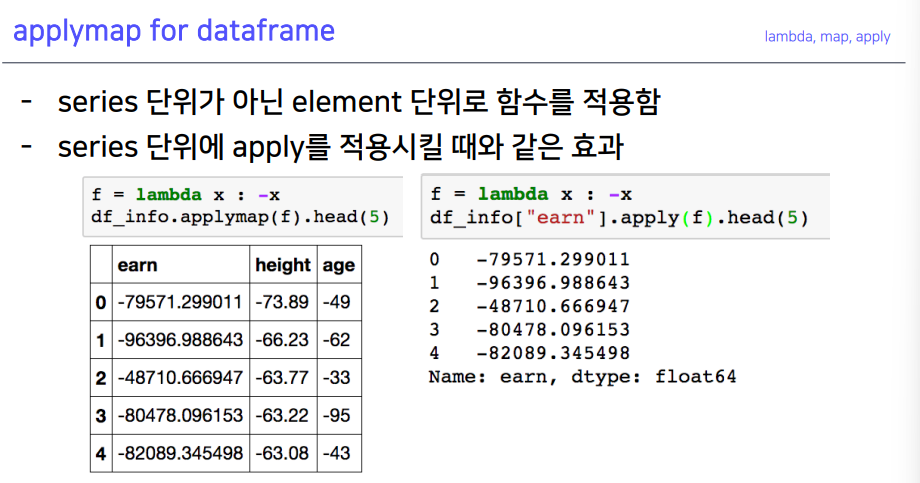
7. pandas built-in function
7-1. describe
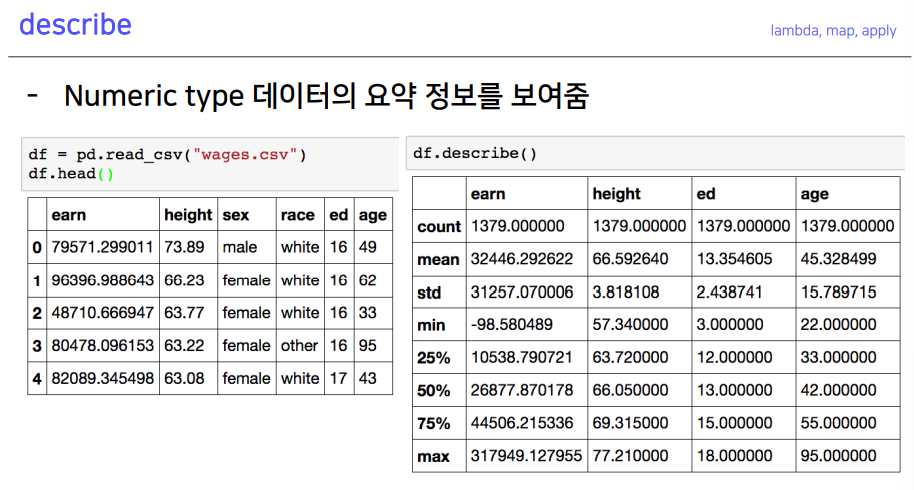
describe: 숫자형 값의 현황
7-2. unique

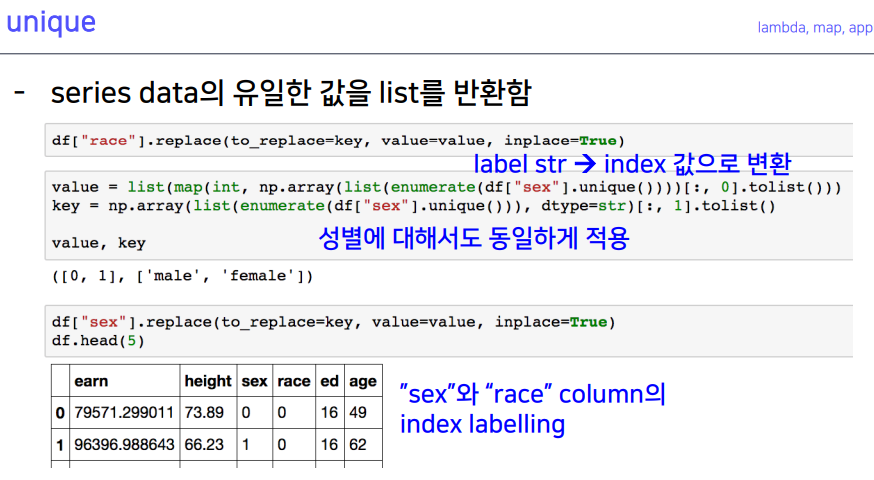
- 라벨 인코딩 시 많이 활용
7-3. sum

7-4. isnull

- null 값인지 아닌지
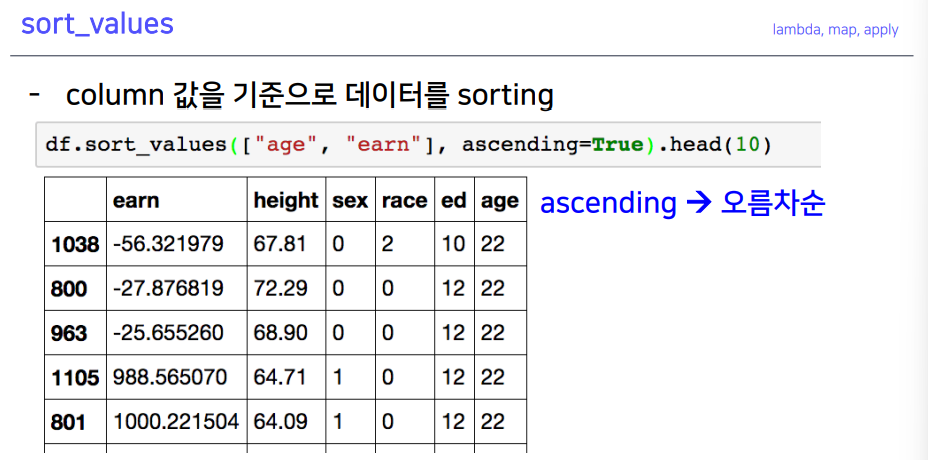
7-5. sort_value
7-6. Correlation & Convariance
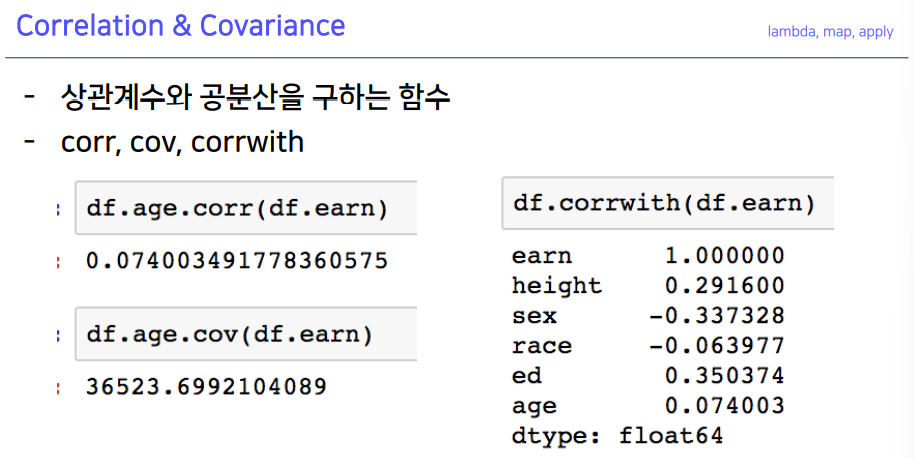
- age 값과 df.earn의 상관계수
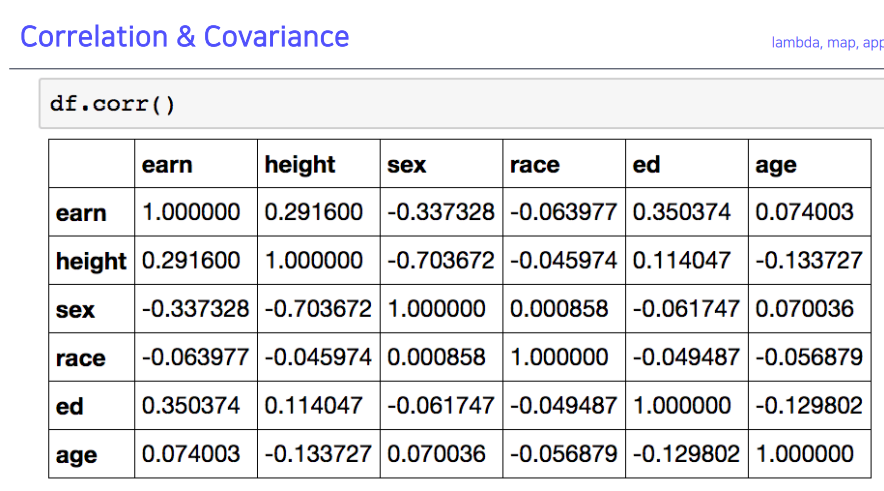
- 모든 값의 상관관계
- 데이터프레임의
출력 행 개수를조절할 수 있는 함수 (데이터사이언스 오픈채팅방에서 문의 나온 내용)

- 글자의 개수

세상을 이롭게하는 AI Engineer