
1. VAE의 개요
VAE는 일종의 '생성기'라고 할 수 있다. 생성기, 즉 생성 모델은 어떤 데이터(그림, 목소리 등)를 보고 비슷한 데이터를 만들어낼 수 있는 모델이라는 뜻이다. 예를 들어, 많은 고양이 사진을 보여주면 새로운 고양이 사진을 만들어낼 수 있다는 것이다!
VAE가 주로 사용되는 분야는 다음과 같다.
- 그림 그리기: 새로운 그림을 만들어낼 수 있다. 예를 들어, 새로운 캐릭터나 배경을 생성할 때 사용할 수 있다.
- 음악 작곡: 새로운 음악이나 음향을 만들어낼 수 있다.
- 데이터 압축: 큰 데이터를 작은 숫자 묶음으로 압축해서 저장 공간을 절약할 수 있다.
1-1. 생성 모델이란?
생성 모델이란?
생성 모델이란 데이터를 학습해서 그와 비슷한 새로운 데이터를 만들어내는 모델이다. 즉, 훈련 데이터의 분포와 생성 데이터의 분포가 일치하도록 학습하는 모델이라고 할 수있다.
생성 모델의 종류
생성 모델에는 대표적으로 두 가지 종류가 있다.
(1) 변분 오토인코더 (VAE)
데이터를 작은 숫자 묶음(잠재 변수)으로 바꿨다가 다시 원래 데이터로 복원하는 방식이다.
예를 들어, 고양이 사진을 작은 숫자 묶음으로 바꿨다가, 그 숫자 묶음으로 새로운 고양이 사진을 만들 수 있다.
(2) 생성적 적대 신경망 (GAN)
두 개의 신경망이 서로 경쟁하는 방식으로, 하나는 새로운 데이터를 만들고(생성자), 다른 하나는 그 데이터를 진짜인지 가짜인지 판별한다(판별자).
예를 들어, 하나는 가짜 고양이 사진을 만들고, 다른 하나는 그 사진이 진짜 고양이 사진인지 아닌지 맞추려고 한다. 둘이 경쟁하면서 점점 더 진짜 같은 고양이 사진을 만들게 되는 것이다.
이 포스트에서는 둘 중 VAE에 대하여 다루려고 한다.
1-2. 오토 인코더
오토인코더는 비지도학습 인공신경망의 한 종류로, 데이터를 입력받아 이를 압축한 다음 다시 원래의 데이터로 복원하는 과정을 학습한다. 주로 데이터의 중요한 특징을 뽑아내고, 불필요한 정보를 제거하는 데 사용된다. 데이터 차원 축소, 노이즈 제거, 이상 탐지 등에 활용될 수 있다.
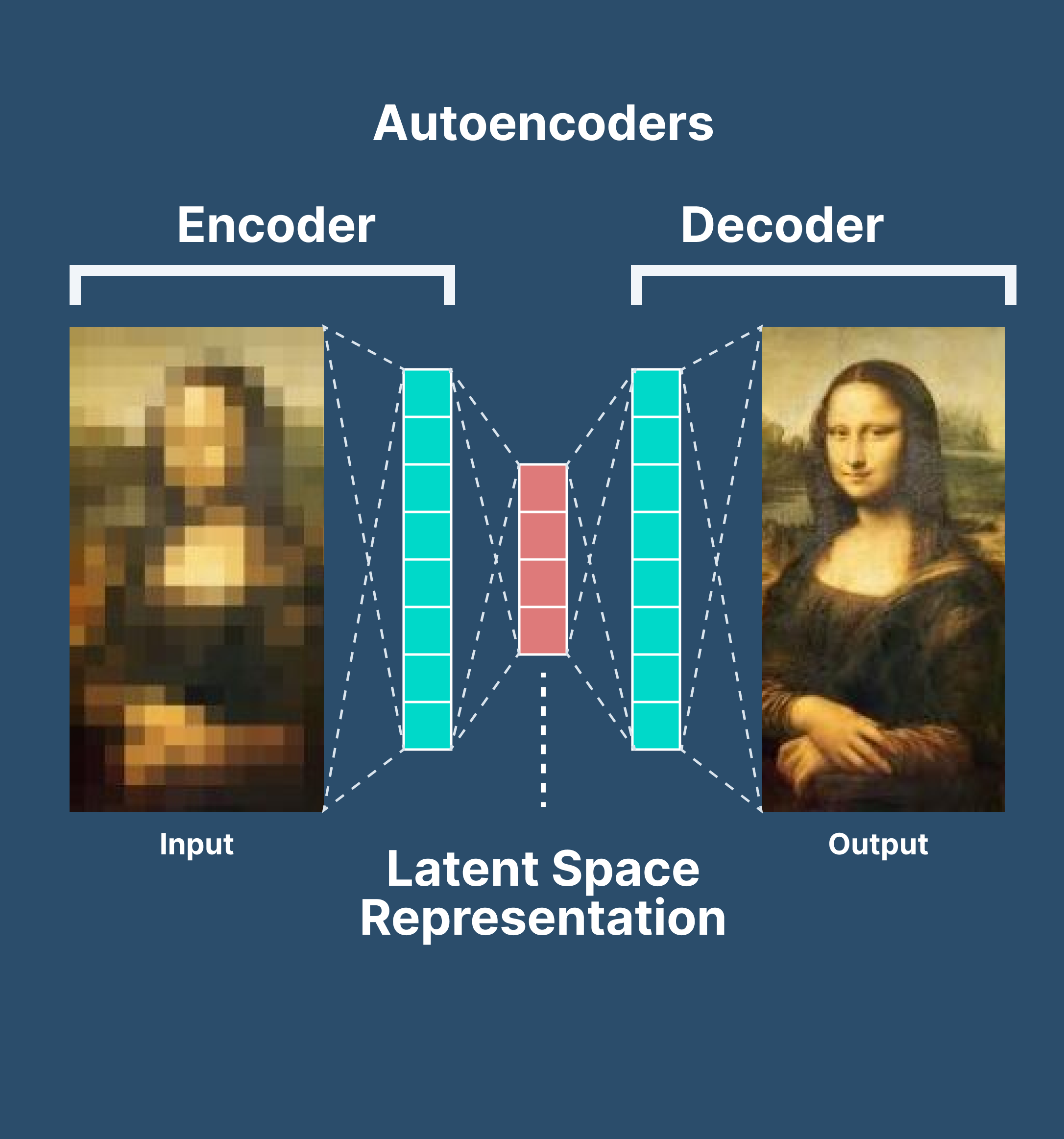
오토인코더는 Encoder와 Decoder로 구성되어 있다.
- 인코더 (Encoder): 입력 데이터를 작은 숫자 묶음으로 압축한다. 이 숫자 묶음을 '잠재 표현' 또는 '잠재 공간'이라고 한다.
- 디코더 (Decoder): 압축된 숫자 묶음을 다시 원래 데이터로 복원한다.
그림에서 볼 수 있듯이, 입력과 출력의 크기는 같고, 중간층의 크기는 그보다 작다. 출력이 입력을 재현하도록 학습하지만, 중간층의 크기는 입력보다 작기 때문에 데이터가 압축된다. 이미지를 다루는 경우, 중간층은 원본 이미지보다 적은 데이터양으로 이미지를 보유할 수 있게 된다. 지도 데이터가 필요하지 않으므로 비지도 학습으로 분류된다.
1-3. VAE
오토인코더는 단순히 데이터의 압축 및 복원을 목표로 하는 반면, 변분 오토인코더는 데이터 분포를 모델링하고 새로운 데이터를 생성하는 능력을 갖는다. VAE는 특히 생성 모델로서의 활용도가 높으며, 고차원 데이터의 잠재 구조를 보다 잘 학습할 수 있도록 설계되었다.
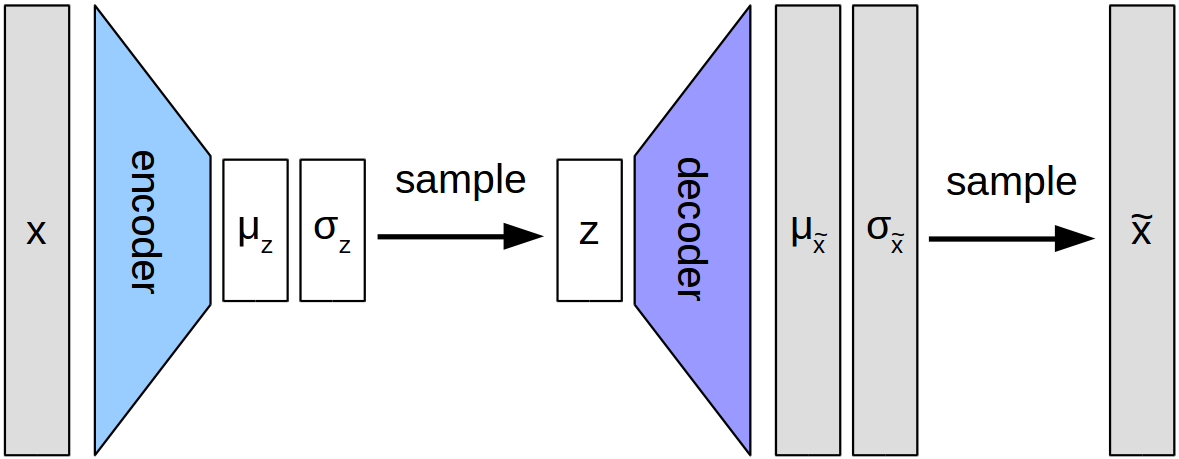
VAE에서는 먼저 Encoder에 의해 평균 벡터 와 분산 벡터 를 구한다. 이들을 바탕으로 잠재 변수 가 확률적으로 샘플링되고, 로부터 Decoder에 의해 원본 데이터가 재현된다. VAE는 이 잠재변수 를 조정함으로써 연속적으로 변화하는 데이터를 생성할 수 있게 된다.
VAE의 잠재 공간에서 연속적인 변화란, 잠재 변수 𝑧의 값을 조금씩 조정함에 따라 원래 데이터 공간에서의 데이터가 부드럽게 변한다는 것을 의미한다.

위는 연속적으로 변화하는 손으로 쓴 숫자 이미지의 예시이다.

사람의 표정을 연속적으로 생성할 수도 있다.
VAE는 오토인코더와 달리 잠재변수의 부분이 확률 분포가 되는 특징이 있다. 그래서 같은 입력이라도 매번 다른 출력을 생성해낼 수 있다. 그래서, 노이즈에 대해서 견고해지며, 본질적인 특징을 추출하는 능력이 향상된다. 잠재 변수가 연속적인 분포이므로 잠재 변수를 조정함으로써 출력의 특징을 조정할 수도 있다. 위와 같은 이미지는 잠재 변수를 통해 얼굴의 특징이 연속적으로 변화되는 것을 볼 수 있다.
VAE는 유연성이 높고 연속성을 표현할 수 있기 때문에 현재 주목받고 있는 생성모델이다.
2. VAE의 구조
2-1. Reparametrization Trick
Reparametrization Trick 또는 재매개변수 트릭은 모델이 잠재 변수 𝑧의 분포를 학습할 수 있도록 도와주는 중요한 기법이다. 이 트릭을 사용하면 잠재 변수 𝑧를 확률적 분포로부터 샘플링하면서도 모델을 효과적으로 학습할 수 있다.
VAE의 학습 과정에서 잠재 변수 를 정규분포 로부터 샘플링해야 한다. 그러나 샘플링 과정은 비결정론적이어서, 역전파를 통해 손실을 최소화하는 과정에서 문제가 발생한다(확률 분포에 의한 샘플링이 중간에 있기 때문에 그대로 역전파에 의한 학습을 할 수 없다). 즉, 샘플링 자체가 미분 가능하지 않기 때문에 학습이 어려워진다.
그래서, 여기에 Reparametrization Trick을 사용해서 샘플링 과정을 분리하여 이를 미분 가능하게 만들어버리는 것이다. 샘플링 과정을 표준 정규 분포 에서 샘플링하는 것으로 분리하고, 이후 평균 𝜇와 표준 편차 𝜎를 적용하는 방식으로 재구성한다.
Reparametrization Trick은 평균값 0, 표준 편차 1인 노이즈 을 발생시켜서 확률분포에 따른 샘플링을 피해 VAE를 구축한다.
Reparametrization Trick은 다음 식으로 쓸 수 있다.
연산을 곱과 합으로 나타낼 수 있기 때문에 확률에 의한 샘플링이 없어진다.
이로써, 편미분을 할 수 있게 되므로, 각 파라미터의 gradient를 역전파로부터 구할 수 있다.
2-2. 오차
VAE 모델을 학습하기 위해서는 오차를 정의해야 한다. VAE의 오차는 '입력에 대한 재구축이 얼마나 입력과 차이가 나는가'를 나타내면서, 동시에 '잠재변수 가 얼마나 발산하고 있는가'를 나타내야 한다.
잠재변수는 학습을 진행하면 0으로부터 떨어져 발산하는 성질이 있다. 이러한 발산을 방지하기 위해서 VAE의 오차에는 정칙화 항 를 더한다.
출력이 입력으로부터 얼마나 어긋나있는지를 나타내는 재구성 오차 와 잠재변수가 얼마나 발산하고 있는지를 나타내는 정칙화 항 을 더해서 VAE의 오차를 다음과 같이 나타낼 수 있다.
VAE는 이 오차 E를 최소화하도록 학습한다. 학습이 적절하게 진행되고 있을 때는 와 이 균형이 잡혀있다.
(1) 재구성 오차
출력이 입력으로부터 얼마나 어긋나있는지를 나타내는 재구성 오차 는 다음 식으로 나타낸다.
여기에서 는 VAE의 입력이고 는 출력, 는 배치 크기, 은 입력층과 출력층의 뉴런 수를 의미한다. 모든 입출력에서 총합을 취하고, 배치 내에서 평균을 취한다.
안의 식은 와 가 같을 때 최솟값을 취하므로 와 2개 값의 간격의 크기를 나타낸다.
이 재구성오차를 사용할 수 있는 것은 일 때만 가능하다.
(2) 정칙화 항
VAE의 정칙화 항 는 다음 식으로 나타낸다.
이 식에서 는 배치 크기, 은 잠재 변수의 수, 는 표준 편차, 는 평균값이다. 모든 잠재변수에 대하여 총합을 취하고, 배치 내에서 평균을 취한다.
안의 식은 표준 편차 , 일때 최솟값 0이다. 그리고 가 1을 벗어나거나 가 0을 벗어나면 커진다. 와 로 잠재변수가 샘플링되므로 '잠재변수가 얼마나 표준편차 1, 평균값 0과 떨어져 있는지'를 나타내게 된다.
모든 잠재변수에서 총합을 취하고 배치 내에서 평균을 취하면 위의 식은 잠재변수 전체의 발산 정도를 나타내는 정칙화 항으로서 사용될 수 있다!
2-3. 구현 기법
로 나타내기로 한다. 이 식을 사용하면 정칙화 항 는 다음과 같이 된다.
여기서 는 음의 값을 취할 수 있어 값의 범위에 제한이 없다. 즉, 𝜙는 실수 전체 범위에서 값을 가질 수 있다. 𝜙가 음수가 될 수 있다는 것은 모델이 𝜙를 예측할 때 특정한 활성화 함수를 사용하지 않아도 된다는 것을 의미한다.
즉, 활성화 함수에 항등함수를 사용할 수 있게 되어 구현이 간단해진다는 뜻이다!
이때 항등함수(identity function)는 입력을 그대로 출력으로 반환하는 함수 이다.항등함수를 사용한다는 것은 𝜙에 대해 추가적인 변환을 하지 않겠다는 의미이다. 이는 모델의 구현을 단순화시키고, 𝜙값이 자연스럽게 모든 실수 범위를 커버할 수 있게 한다. 따라서 를 예측할 때 별도의 제한이나 추가 변환을 하지 않아도 되므로, 구현이 더 간단해진다.
3. 오토인코더 구현하기
3-1. 훈련용 데이터
tensorflow.keras.datasets에서 MNIST 데이터를 불러들여서 사용한다. MNIST 데이터셋의 이미지들은 0부터 255까지의 정수 값으로 표현된 28x28 픽셀의 흑백 이미지이다.
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.datasets import mnist
(x_train, t_train), (x_test, t_test) = mnist.load_data()
print(x_train.shape, x_test.shape)
x_train = x_train/255
x_test = x_test/255
plt.imshow(x_train[0].reshape(28, 28), cmap="gray")
plt.title(t_train[0])
plt.show()
255로 나누는 것은 이 픽셀 값을 0과 1 사이의 실수 값으로 정규화(normalization)하기 위함이다.
현재 데이터는 이미 2차원 배열 형태이므로 reshape(28, 28)은 필요하지 않다.
# x_train의 원래 형태는 (60000, 28, 28)
# 이를 (60000, 784)로 변환
x_train = x_train.reshape(x_train.shape[0], -1)
x_test = x_test.reshape(x_test.shape[0], -1)
print("훈련용 데이터의 형태 : ", x_train.shape, "테스트용 데이터의 형태 : ", x_test.shape)실행 결과
훈련용 데이터의 형태 : (60000, 784) 테스트용 데이터의 형태 : (10000, 784)3-2. 오토인코더의 각 설정
오토인코더에 필요한 각 설정을 실시한다. 이미지의 폭과 높이가 28픽셀이므로 입력층에 필요한 뉴런의 개수는 개가 된다. 또한 출력이 입력을 재현하도록 학습하므로 출력층의 뉴런 수는 입력층과 같게 된다. 중간층은 뉴런 수를 이보다는 적게 설정한다.
epochs = 20
batch_size = 128
n_in_out = 784
n_mid = 643-3. 모델의 구축
Keras로 오토인코더 모델을 구축한다. 입력, Encoder, Decoder 순으로 층을 쌓는다. Model 클래스를 사용해 모델을 구축한다. Model 클래스는 다음과 같이 설정한다.
Model(입력, 출력)
Model 클래스를 사용하면 오토인코더, 인코더, 디코더의 모델을 각각 설정할 수 있다. 이 단계에서 학습은 오토인코더로만 실시하기 때문에 Encoder, Decoder는 개별적으로 컴파일하지는 않는다.
from json import decoder
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
# 각 층
x = Input(shape=(n_in_out,)) # 입력
encoder = Dense(n_mid, activation="relu") # Encoder
decoder = Dense(n_in_out, activation = "sigmoid") # Decoder
# 망
h = encoder(x)
y = decoder(h)
# 오토인코더의 모델
model_autoencoder = Model(x,y)
model_autoencoder.compile(optimizer="adam", loss="binary_crossentropy")
model_autoencoder.summary()
print()
# Encoder의 모델
model_encoder = Model(x,h)
model_encoder.summary()
print()
# Decoder의 모델
input_decoder = Input(shape=(n_mid,))
model_decoder = Model(input_decoder, decoder(input_decoder))
model_decoder.summary()실행결과
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 784)] 0
_________________________________________________________________
dense_2 (Dense) (None, 64) 50240
_________________________________________________________________
dense_3 (Dense) (None, 784) 50960
=================================================================
Total params: 101,200
Trainable params: 101,200
Non-trainable params: 0
_________________________________________________________________
Model: "model_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 784)] 0
_________________________________________________________________
dense_2 (Dense) (None, 64) 50240
=================================================================
Total params: 50,240
Trainable params: 50,240
Non-trainable params: 0
_________________________________________________________________
Model: "model_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_3 (InputLayer) [(None, 64)] 0
_________________________________________________________________
dense_3 (Dense) (None, 784) 50960
=================================================================
Total params: 50,960
Trainable params: 50,960
Non-trainable params: 0
_________________________________________________________________3-4. 학습
model_autoencoder.fit(x_train, x_train, shuffle=True, epochs=epocks, batch_size=batch_size, validation_data=(x_test, x_test))- x_train, x_train: 학습 시 입력 데이터와 목표 출력 데이터 모두 x_train을 사용한다.
- shuffle=True: 각 에포크(epoch)마다 데이터를 섞어서 학습한다.
- epochs=epochs: 전체 데이터셋을 몇 번 반복해서 학습할지 설정한다.
- batch_size=batch_size: 한 번의 업데이트에 사용될 데이터 샘플의 수를 설정한다.
- validation_data=(x_test, x_test): 검증 데이터로 x_test를 사용한다. 입력과 출력 모두 x_test로 설정하여 모델의 성능을 검증한다.
Epoch 1/20
469/469 [==============================] - 4s 4ms/step - loss: 0.2003 - val_loss: -10574.8477
Epoch 2/20
469/469 [==============================] - 2s 3ms/step - loss: 0.1166 - val_loss: -21333.8008
Epoch 3/20
469/469 [==============================] - 2s 3ms/step - loss: 0.0961 - val_loss: -33922.8984
Epoch 4/20
469/469 [==============================] - 2s 3ms/step - loss: 0.0861 - val_loss: -45903.6562
...
Epoch 19/20
469/469 [==============================] - 2s 4ms/step - loss: 0.0733 - val_loss: -71739.6406
Epoch 20/20
469/469 [==============================] - 2s 4ms/step - loss: 0.0733 - val_loss: -72050.2188
<keras.src.callbacks.History at 0x7fade0097d90>3-5. 생성 결과
이미지가 적절하게 재구축되어있는지 여부, 중간층이 어떠한 상태에 있는지를 확인한다. 입력 이미지와 재구축된 이미지를 나열하여 표시하고, Encoder의 출력도 8x8의 이미지로 표시한다.
encoded = model_encoder.predict(x_test)
decoded = model_decoder.predict(encoded)
n = 8 # 표시할 이미지 수
plt.figure(figsize=(16,4))
for i in range(n):
ax = plt.subplot(3, n, i+1)
plt.imshow(x_test[i].reshape(28, 28), cmap="Greys_r")
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 중간층의 출력
ax = plt.subplot(3, n, i+1+n)
plt.imshow(encoded[i].reshape(8,8), cmap="Greys_r")
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 출력 이미지
ax = plt.subplot(3, n, i+1+2*n)
plt.imshow(decoded[i].reshape(28, 28), cmap="Greys_r")
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
28x28의 이미지가 encoder에 의해 8x8로 압축된 후 Decoder에 의해 전개되어 원본 이미지가 재구축되었다(완전히 일치하지는 않지만).
4. VAE의 구현
VAE를 구현한다. Encoder로 이미지를 잠재변수로 압축한 후 Decoder로 원본 이미지를 복원한다. 또 잠재변수가 넓어지는 잠재공간을 가시화하여, 잠재변수가 생성 이미지에 미치는 영향을 확인한다.
4-1. 훈련용 데이터 준비하기
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow as tf
from tensorflow.keras.datasets import mnist
(x_train, t_train), (x_test, t_test) = mnist.load_data()
print(x_train.shape, x_test.shape)
x_train = x_train / 255
x_test = x_test / 255
plt.imshow(x_train[0].reshape(28, 28), cmap="gray")
plt.title(t_train[0])
plt.show()
# x_train의 원래 형태는 (60000, 28, 28)
# 이를 (60000, 784)로 변환
x_train = x_train.reshape(x_train.shape[0], -1)
x_test = x_test.reshape(x_test.shape[0], -1)
print("훈련용 데이터의 형태 : ", x_train.shape, "테스트용 데이터의 형태 : ", x_test.shape)
epochs = 10
batch_size = 128
n_in_out = 784 # 입출력층의 뉴런 수
n_z = 2 # 잠재변수의 수 (차원 수)
n_mid = 256 # 중간층의 뉴런 수4-2. VAE의 각 설정
epochs = 10
batch_size = 128
n_in_out = 784 # 입출력층의 뉴런 수
n_z = 2 # 잠재변수의 수 (차원 수)
n_mid = 256 # 중간층의 뉴런 수4-3. 모델의 구축
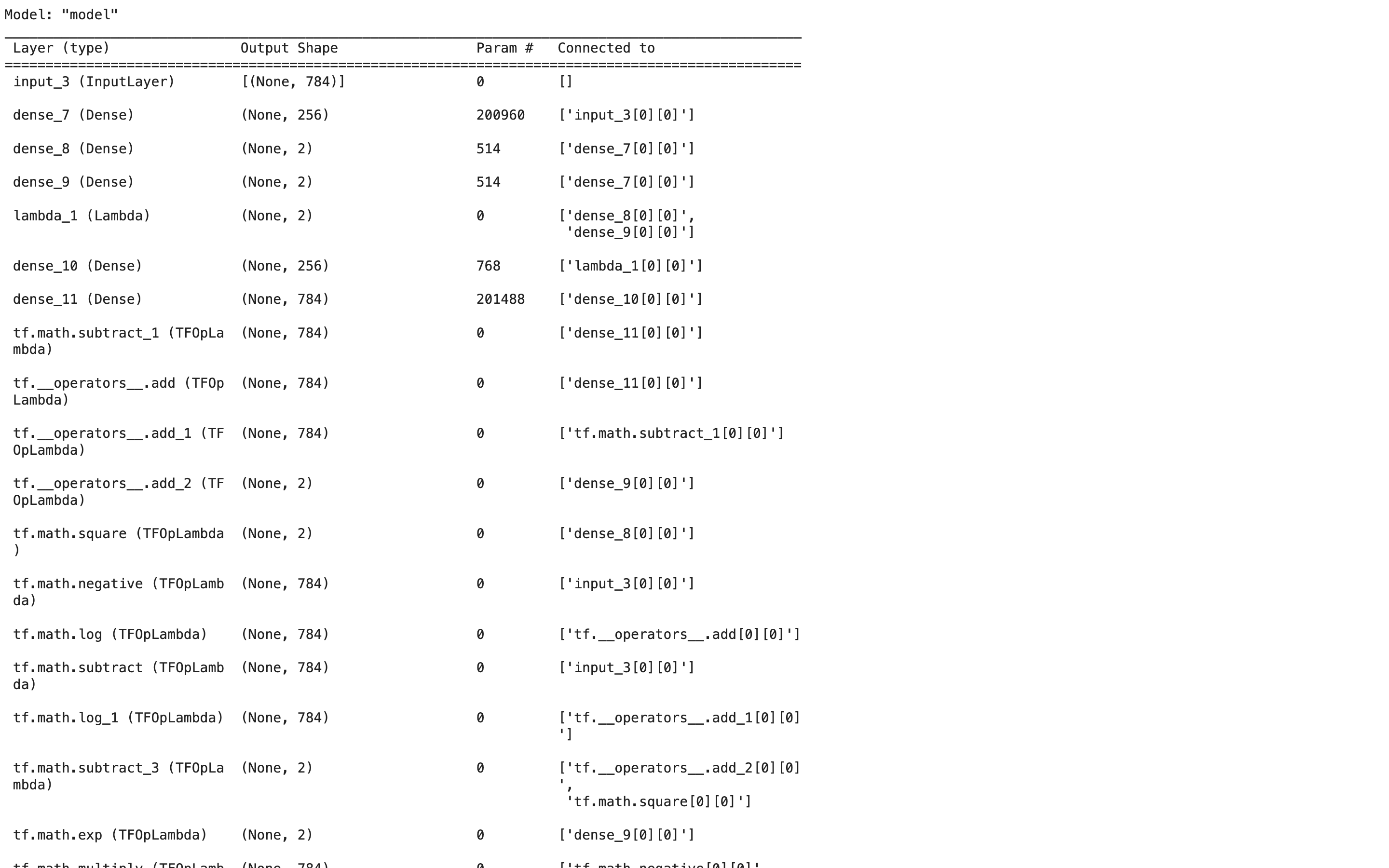
Keras로 VAE모델을 구축한다. Encoder의 출력은 잠재 변수의 평균값 및 표준편차 의 거듭제곱(=분산)의 대수()로 한다.
VAE의 코드에서는 역전파에 의한 학습을 위해 Reparametrization Trick을 사용한다. 평균값 0, 표준편차 1인 노이즈 을 발생시켜서 표준 편차와 곱하고 평균값에 더해 잠재변수 로 한다.
손실함수는 위에서 설명했던 것처럼 다음으로 나타낸다.
여기에서 우변 제1항의 재구성 오차 는 출력과 입력의 편차를 나타낸다.
- : 배치 크기, : 입출력층의 뉴런 수, : VAE입력, : VAE의 출력
또한, 우변 제 2항의 정칙화 항 는 평균값이 0, 표준 편차가 1에 가까워지도록 기능한다.
- : 배치 크기, : 잠재변수의 수, : 평균값, : 분산의 대수()
from tensorflow.keras.models import Model
from tensorflow.keras import metrics # 평가함수
from tensorflow.keras.layers import Input, Dense, Lambda
from tensorflow.keras import backend as K # 난수 발생에 사용
# 잠재 변수를 샘플링하기 위한 함수
def z_sample(args):
mu, log_var = args # 잠재변수의 mu, phi
epsilon = K.random_normal(shape=K.shape(log_var), mean=0, stddev=1)
return mu + epsilon * K.exp(log_var / 2) # Reparameterization Trick에 의해 잠재변수를 구한다.
# Encoder
x = Input(shape=(n_in_out,))
h_encoder = Dense(n_mid, activation="relu")(x) # Keras에서 Layer 객체를 생성하고, 그 객체에 입력 데이터 x를 전달하여 출력을 계산함
mu = Dense(n_z)(h_encoder)
log_var = Dense(n_z)(h_encoder)
z = Lambda(z_sample, output_shape=(n_z,))([mu, log_var])
# Decoder
mid_decoder = Dense(n_mid, activation="relu")
h_decoder = mid_decoder(z)
out_decoder = Dense(n_in_out, activation="sigmoid")
y = out_decoder(h_decoder)
# VAE의 모델을 생성
model_vae = Model(x, y)
# 손실 함수
eps = 1e-7 # log 안이 0이 되는 것을 막는다
rec_loss = K.sum(-x*K.log(y+eps) - (1-x)*K.log(1-y+eps)) / batch_size # 한 배치의 모든 샘플에 대한 평균 재구성 오차
reg_loss = -0.5 * K.sum(1+log_var - K.square(mu) - K.exp(log_var)) /batch_size # 평균 정칙화 항
vae_loss = rec_loss + reg_loss
model_vae.add_loss(vae_loss)
model_vae.compile(optimizer="adam")
model_vae.summary()실행 결과
4-4. 학습
구축한 VAE의 모델을 훈련한다. 입력을 재현하도록 학습하므로 정답은 입력 그 자체가 된다. VAE에서는 목표 데이터(타겟)를 명시적으로 정의할 필요가 없다. 입력 데이터만으로도 재구성 오차를 계산하고, 이를 통해 모델의 성능을 평가할 수 있기 때문이다. 따라서 validation_data에 None을 전달하여 목표 데이터를 지정하지 않는 것이 합리적이다.
model_vae.fit(x_train, x_train, epochs=epochs, batch_size=batch_size, validation_data=(x_test, None))실행결과
Epoch 1/10
469/469 [==============================] - 11s 20ms/step - loss: 204.2548 - val_loss: 172.1148
Epoch 2/10
469/469 [==============================] - 10s 22ms/step - loss: 170.3284 - val_loss: 166.2809
Epoch 3/10
469/469 [==============================] - 7s 15ms/step - loss: 166.8137 - val_loss: 164.3773
Epoch 4/10
469/469 [==============================] - 9s 19ms/step - loss: 164.9091 - val_loss: 162.6355
Epoch 5/10
469/469 [==============================] - 7s 15ms/step - loss: 163.3998 - val_loss: 161.3455
Epoch 6/10
469/469 [==============================] - 8s 18ms/step - loss: 162.1556 - val_loss: 160.2570
Epoch 7/10
469/469 [==============================] - 8s 17ms/step - loss: 160.9701 - val_loss: 159.0706
Epoch 8/10
469/469 [==============================] - 8s 17ms/step - loss: 159.8663 - val_loss: 158.1292
Epoch 9/10
469/469 [==============================] - 9s 19ms/step - loss: 158.8449 - val_loss: 157.0773
Epoch 10/10
469/469 [==============================] - 7s 15ms/step - loss: 157.9377 - val_loss: 156.2512
<keras.src.callbacks.History at 0x7ba31c494ca0>4-5. 잠재공간의 가시화
2개의 잠재변수를 각각 가로축, 세로축으로 평면에 플롯하여 가시화한다. 잠재 변수는 훈련이 끝난 VAE의 모델을 사용하여 작성한다.
다음 코드를 실행하면, 잠재변수가 라벨별로 분류되어 산포도로 표시된다.
# 잠재변수를 얻기 위한 모델
encoder = Model(x,z)
# 훈련 데이터로부터 만든 잠재변수를 2차원 플롯한다
z_train = encoder.predict(x_train, batch_size = batch_size)
plt.figure(figsize=(6,6))
plt.scatter(z_train[:, 0], z_train[:, 1], c=t_train)
plt.title("Train")
plt.colorbar()
plt.show()
z_test = encoder.predict(x_test, batch_size = batch_size)
plt.figure(figsize=(6,6))
plt.scatter(z_test[:, 0], z_test[:, 1], c=t_test)
plt.title("Test")
plt.colorbar()
plt.show()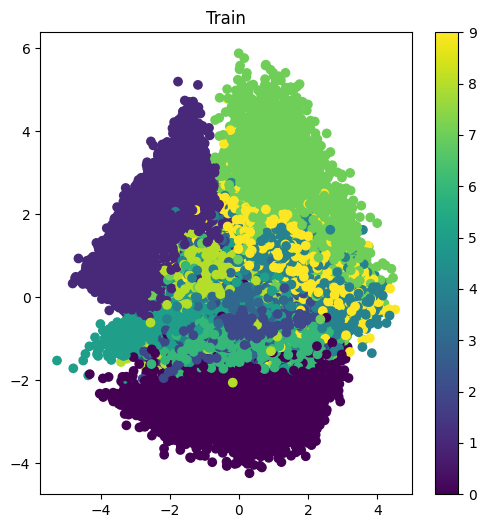
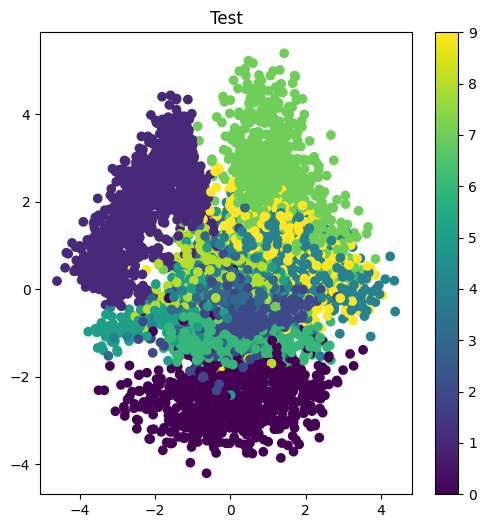
각 라벨별로 다른 잠재공간의 영역이 차지하고 있다. 단일 라벨로 차지한 영역도 있으면, 여러 개의 라벨이 겹쳐져 있는 영역도 있다.
이렇게 VAE는 입력을 잠재공간에 할당하도록 학습한다. 명확하게 잠재변수가 분포하는 영역이 형성되므로 잠재변수가 Decoder에 의해 생성하는 데이터에 어떻게 영향을 미치는지 직감적으로 파악하기 용이하다.
4-6. 이미지의 생성
잠재변수가 생성할 이미지에 주는 영향을 확인한다. 훈련한 VAE의 Decoder를 사용해 2개의 연속적으로 변화하는 잠재변수에서 이미지를 16x16장 생성한다.
# 이미지 생성기
input_decoder = Input(shape=(n_z,))
h_decoder = mid_decoder(input_decoder)
y = out_decoder(h_decoder)
generator = Model(input_decoder, y)
# 이미지를 나열하는 설정
n = 16
image_size = 28
matrix_image = np.zeros((image_size*n, image_size*n)) # 전체 이미지
# 잠재 변수
z_1 = np.linspace(2, -2, n) # 각 행
z_2 = np.linspace(-2, 2, n) # 각 열
# 잠재 변수를 변화시켜서 이미지를 생성
for i, z1 in enumerate(z_1):
for j, z2 in enumerate(z_2):
decoded = generator.predict(np.array([[z2, z1]])) # x축, y축의 순서로 넣는다.
image = decoded[0].reshape(image_size, image_size)
matrix_image[i*image_size:(i+1)*image_size, j*image_size:(j+1)*image_size] = image
plt.figure(figsize=(10,10))
plt.imshow(matrix_image, cmap="Greys_r")
plt.tick_params(labelbottom=False, labelleft=False, bottom=False, left=False) # 축 눈금의 라벨과 선을 지운다
plt.show()
잠재변수로부터 16x16장의 이미지가 생성되었다. 잠재변수의 변화에 따른 이미지의 변화를 확인할 수 있다. VAE에 의해 단 2개의 잠재변수에 이미지가 압축되었다.
