
1. GAN의 개요
적대적 생성망(GAN, Generative Adversarial Networks)은 머신러닝에서 생성 모델링을 위한 강력한 접근 방법이다. GAN은 실제와 구분하기 어려운 가짜 데이터를 생성하는 것을 목표로 하는 모델이다. 간단하게 설명하면, GAN은 두 개의 주요 구성 요소로 이루어져 있다: 생성자(Generator)와 판별자(Discriminator). 이 두 신경망이 경쟁하게 해서 이미지 등의 데이터를 생성해낸다.
1-1. GAN이란?
GAN(Generative Adversarial Networks)은 2개의 모델을 서로 경쟁하도록 하여 훈련하는 생성모델이다. 그 2개의 모델은 생성자(Generator)와 판별자(Discriminator)이다. Discriminator 쪽은 이미지 등의 진짜 데이터와 Generator가 생성한 데이터를 올바르게 식별할 수 있도록 학습한다. Generator 쪽은 랜덤한 노이즈를 입력으로 해서 가짜 데이터를 출력한다. Generator는 Discriminator가 진짜 데이터라고 착각할만한 데이터를 생성하도록 학습한다.
이 과정에서 Generator와 Discriminator는 서로의 능력을 강화하며, 최종적으로 생성자는 실제와 거의 구분할 수 없는 품질의 이미지를 생성할 수 있게 되고, 판별자는 보다 정확하게 이미지를 구별할 수 있게 된다.
1-2. GAN의 구성
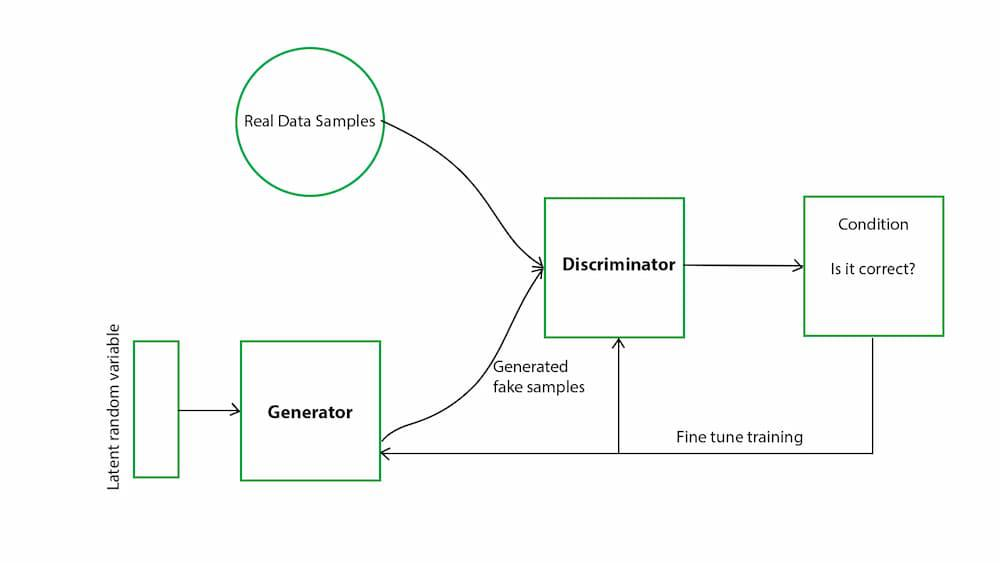
출처 https://www.geeksforgeeks.org/generative-adversarial-network-gan/
Generator는 랜덤 노이즈를 입력으로 해서 가짜 데이터를 생성한다. Discriminator는 가짜 데이터에는 0, 진짜 데이터에는 1의 라벨을 붙인다. Generator는 처음에는 랜덤한 노이즈로부터 시작하지만, 훈련을 반복함에 따라 실제 데이터와 비슷한 분포를 학습하게 된다. 초기에는 Discriminator는 임의로 생성된 이미지와 실제 이미지를 잘 구분하지 못하지만, 훈련을 반복하면서 점점 더 정확하게 구별할 수 있게 된다.
2. GAN의 평가 함수
GAN은 일반적인 지도 학습과는 다르게 명시적인 손실 함수(loss function)를 사용하지 않는다. 대신, 생성된 이미지의 품질을 평가하고 개선하기 위해 다양한 평가 기준을 사용한다. 이러한 평가 기준은 명확히 한 가지로 정해진 것이 아니라, 매우 다양하고 문제에 따라 다를 수 있기 때문에, 연구자나 개발자가 설정하고 실험적으로 결정할 수 있다.
https://arxiv.org/abs/1406.2661
GAN 에 대하여 2014년에 처음으로 발표된 논문 Generative Adversarial Networks에서는 평가 함수를 다음과 같이 정의하였다.
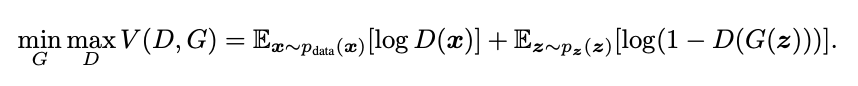
- : 이는 GAN의 핵심 학습 목표를 나타낸다. 생성자 𝐺와 판별자 𝐷사이의 미니맥스(minimax) 게임을 의미한다. 즉, 생성자는 𝐺를 최소화하려고 하고, 판별자는 𝐷를 최대화하려고 한다.
- : 판별자 𝐷와 생성자 𝐺 사이의 목적 함수(Objective Function)
- : 실제 데이터 𝑥가 주어졌을 때, 판별자 𝐷가 𝑥를 실제 데이터로 판별할 확률의 로그를 나타낸다. 즉, 판별자가 실제 데이터를 실제로 인식하는 정도를 측정한다.
- : 잠재 공간의 랜덤 벡터 𝑧가 주어졌을 때, 생성자 𝐺가 𝑧를 가짜 데이터로 생성하고, 판별자 𝐷가 이를 가짜로 판별할 확률의 로그를 나타낸다. 즉, 판별자가 생성된 가짜 데이터를 가짜로 인식하는 정도를 측정한다.
이렇게 Discriminator의 식별 결과는 우변 제 1항, 2항 양쪽에 영향을 주고, Generator의 식별 결과는 우변의 제 2항에만 영향을 준다. Generator와 Discriminator는 각각 반대 방향으로 를 움직이려고 한다. 학습이 제대로 진행되고 있을 때는 어떤 균형점에서 Nash 균형이 된다.
Nash 균형은 게임 이론에서 중요한 개념으로, 모든 플레이어가 다른 플레이어의 전략을 고려하여 자신의 전략을 선택할 때, 어떤 플레이어도 현재 전략을 변경할 이유가 없는 상태를 의미한다. 즉, 각 플레이어가 자신의 전략을 고정시켰을 때 모두에게 최선의 선택이 되는 상태인 것이다.
3. GAN의 구현
3-1. 훈련용 데이터 준비
GAN에 사용하는 훈련용의 데이터를 준비한다. 여기서 각 픽셀의 값은 Generator의 활성화 함수에 맞춰서 의 범위에 들어가도록 조정한다.
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from keras.datasets import mnist
(x_train, t_train), (x_test, t_test) = mnist.load_data()
print(x_train.shape, x_test.shape)
# 각 픽셀의 값을 -1에서 1 사이의 범위에 넣는다.
x_train = x_train/255*2-1
x_test = x_test/255*2-1
# 손으로 쓴 문자 이미지의 표시
plt.imshow(x_train[0].reshape(28,28), cmap="gray")
plt.title(t_train[0])
plt.show()
# 1차원으로 변환한다
x_train = x_train.reshape(x_train.shape[0], -1)
x_test = x_test.reshape(x_test.shape[0], -1)
print(x_train.shape, x_test.shape)
3-2. GAN의 각 설정
GAN에 필요한 각 설정을 실시한다. 여기서는 epoch 수 대신 학습 횟수를 설정한다. 훈련 데이터를 전부 사용해서 학습하는 것이 아니라, 훈련 데이터에서 매번 랜덤으로 미니 배치를 꺼내서 학습한다. 이것을 변수 n_learn 으로 작성하였다.
n_learn = 20001 # 학습 횟수
interval = 2000 # 이미지 생성 간격
batch_size = 32
n_noise = 128 # 노이즈의 수 (Generator에 입력)
img_size = 28
alpha = 0.2 # Leaky ReLU의 음의 영역에서의 기울기기본 ReLU는 입력 값이 0보다 작으면 출력을 0으로 하고, 0보다 크면 그 값을 그대로 출력하는 함수이므로 음수 입력에 대해 기울기가 0이 되므로, 역전파 과정에서 가중치가 업데이트되지 않기 때문에 작은 기울기를 주는 Leaky ReLU를 사용한다.
3-3. Generator 구축
Keras로 Generator 모델을 구축한다. 위에서 설명한 Leaky ReLU를 중간층의 활성화 함수로 사용한다.
에는 보통 0.01 등 작은 값이 사용된다. GAN에서는 Generator에서 경사가 소실되기 쉽고 학습이 정체되므로 값을 약간 크게 한 Leaky ReLU를 주로 사용한다.
또한 출력층의 활성화 함수에는 Discriminator로의 입력을 -1에서 1의 범위로 하기 위해서 를 사용한다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LeakyReLU
# Generator의 망 구축
generator = Sequential()
generator.add(Dense(256, input_shape=(n_noise,)))
generator.add(LeakyReLU(alpha=alpha))
generator.add(Dense(512))
generator.add(LeakyReLU(alpha=alpha))
generator.add(Dense(1024))
generator.add(LeakyReLU(alpha=alpha))
generator.add(Dense(img_size*img_size, activation="tanh"))
generator.summary()실행 결과
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 256) 33024
leaky_re_lu (LeakyReLU) (None, 256) 0
dense_1 (Dense) (None, 512) 131584
leaky_re_lu_1 (LeakyReLU) (None, 512) 0
dense_2 (Dense) (None, 1024) 525312
leaky_re_lu_2 (LeakyReLU) (None, 1024) 0
dense_3 (Dense) (None, 784) 803600
=================================================================
Total params: 1493520 (5.70 MB)
Trainable params: 1493520 (5.70 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________3-4. Discriminator 구축
Keras로 Discriminator 모델을 구축한다. 중간층 활성화 함수로는 마찬가지로 Leaky ReLU를 사용하고, 출력층의 활성화 함수에는 0에서 1의 값에서 진짜인지 여부를 식별하기 위해서 시그모이드 함수를 사용한다. 손실함수에는 교차 엔트로피를 사용한다. (binary_crossentropy)
https://www.tensorflow.org/api_docs/python/tf/keras/losses/binary_crossentropy
# Discriminator 망 구축
discriminator = Sequential()
discriminator.add(Dense(512, input_shape=(img_size*img_size,)))
discriminator.add(LeakyReLU(alpha=alpha))
discriminator.add(Dense(256))
discriminator.add(LeakyReLU(alpha=alpha))
discriminator.add(Dense(1, activation="sigmoid"))
discriminator.compile(loss="binary_crossentropy", optimizer=optimizer, metrics=["accuracy"])
print(discriminator.summary())실행 결과
# Discriminator 망 구축
discriminator = Sequential()
discriminator.add(Dense(512, input_shape=(img_size*img_size,)))
discriminator.add(LeakyReLU(alpha=alpha))
discriminator.add(Dense(256))
discriminator.add(LeakyReLU(alpha=alpha))
discriminator.add(Dense(1, activation="sigmoid"))
discriminator.compile(loss="binary_crossentropy", optimizer=optimizer, metrics=["accuracy"])
print(discriminator.summary())
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_6 (Dense) (None, 512) 401920
leaky_re_lu_4 (LeakyReLU) (None, 512) 0
dense_7 (Dense) (None, 256) 131328
leaky_re_lu_5 (LeakyReLU) (None, 256) 0
dense_8 (Dense) (None, 1) 257
=================================================================
Total params: 533505 (2.04 MB)
Trainable params: 533505 (2.04 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
None3-5. 모델의 결합
Generator와 Discriminator를 결합한 모델을 만든다. 노이즈로부터 Generator에 의해 이미지를 생성하고, Discriminator에 의해 그것이 진짜 이미지인지 여부를 판정하도록 결합한다. 결합 모델에서는 Generator만 훈련하므로 Discriminator는 훈련하지 않도록 설정한다.
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input
# 결합 시에는 Generator만 훈련한다
discriminator.trainable = False
# Generator에 의해 노이즈로부터 생성된 이미지를 Discriminator가 판정한다
noise = Input(shape=(n_noise,))
img = generator(noise)
reality = discriminator(img)
# Generator와 Discriminator의 결합
combined = Model(noise, reality)
combined.compile(loss='binary_crossentropy', optimizer=optimizer)
print(combined.summary())실행 결과
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 128)] 0
sequential (Sequential) (None, 784) 1493520
sequential_2 (Sequential) (None, 1) 533505
=================================================================
Total params: 2027025 (7.73 MB)
Trainable params: 1493520 (5.70 MB)
Non-trainable params: 533505 (2.04 MB)
_________________________________________________________________
None3-6. 이미지를 생성하는 함수
Generator를 사용하여 노이즈로부터 이미지를 생성하고 표시하기 위한 함수를 정의한다. 훈련된 Generator에 노이즈를 입력하면 이미지가 생성된다. 이미지는 5x5장 생성되는데, 일반적으로 1장의 이미지로 만든 후 다음에 표시한다.
def generate_images(i):
n_rows = 5
n_cols = 5
noise = np.random.normal(0, 1, (n_rows * n_cols, n_noise))
g_imgs = generator.predict(noise)
g_imgs = (g_imgs + 1) / 2 # 0~1의 범위로 한다
matrix_image = np.zeros((img_size*n_rows, img_size*n_cols)) # 전체 이미지
# 생성된 이미지를 나열하여 1장의 이미지로 한다.
for r in range(n_rows):
for c in range(n_cols):
g_img = g_imgs[r*n_cols + c].reshape(img_size, img_size)
matrix_image[r*img_size:(r+1)*img_size, c*img_size:(c+1)*img_size] = g_img
plt.figure(figsize=(10,10))
plt.imshow(matrix_image, cmap="Greys_r")3-7. 학습
구축된 GAN 모델을 사용해 학습한다.
Generator가 생성한 이미지에는 정답 라벨 0, 진짜 이미지에는 정답 라벨 1을 주어서 Determinator를 훈련시킨다. 그다음에 결합된 모델을 사용해 Generator를 훈련시키는데, 이 경우의 정답 라벨은 1이 된다.이러한 훈련을 반복함으로써 진짜와 분간할 수 없는 이미지가 생성된다. (GPU 사용을 권장한다)
batch_half = batch_size // 2
loss_record = np.zeros((n_learn, 3))
acc_record = np.zeros((n_learn, 2))
for i in range(n_learn):
# 노이즈로부터 이미지를 생성해 Discriminator를 훈련
g_noise = np.random.normal(0, 1, (batch_half, n_noise))
g_imgs = generator.predict(g_noise)
loss_fake, acc_fake = discriminator.train_on_batch(g_imgs, np.zeros((batch_half, 1)))
loss_record[i][0] = loss_fake
acc_record[i][0] = acc_fake
# 진짜 이미지를 사용해서 Discriminator를 훈련
rand_ids = np.random.randint(len(x_train), size=batch_half)
real_imgs = x_train[rand_ids, :]
loss_real, acc_real = discriminator.train_on_batch(real_imgs, np.ones((batch_half, 1)))
loss_record[i][1] = loss_real
acc_record[i][1] = acc_real
# 결합한 모델에 의해 Generator를 훈련
c_noise = np.random.normal(0, 1, (batch_size, n_noise))
loss_comb = combined.train_on_batch(c_noise, np.ones((batch_size, 1)))
loss_record[i][2] = loss_comb
generate_images(i)실행 결과
3-8. 오차 및 정밀도의 추이
학습 중에서의 오차와 정밀도의 추이를 확인한다. Discriminator에 진짜 이미지를 대입시켰을 때 오차 추이와 가짜 이미지를 대입시켰을 때 오차 추이를 그래프로 표시한다. 또한 정밀도의 추이도 표시한다.
batch_half = batch_size // 2
loss_record = np.zeros((n_learn, 3))
acc_record = np.zeros((n_learn, 2))
for i in range(n_learn):
# 노이즈로부터 이미지를 생성해 Discriminator를 훈련
g_noise = np.random.normal(0, 1, (batch_half, n_noise))
g_imgs = generator.predict(g_noise)
loss_fake, acc_fake = discriminator.train_on_batch(g_imgs, np.zeros((batch_half, 1)))
loss_record[i][0] = loss_fake
acc_record[i][0] = acc_fake
# 진짜 이미지를 사용해서 Discriminator를 훈련
rand_ids = np.random.randint(len(x_train), size=batch_half)
real_imgs = x_train[rand_ids, :]
loss_real, acc_real = discriminator.train_on_batch(real_imgs, np.ones((batch_half, 1)))
loss_record[i][1] = loss_real
acc_record[i][1] = acc_real
# 결합한 모델에 의해 Generator를 훈련
c_noise = np.random.normal(0, 1, (batch_size, n_noise))
loss_comb = combined.train_on_batch(c_noise, np.ones((batch_size, 1)))
loss_record[i][2] = loss_comb
if i % interval == 0:
print("n_learn:", i)
print("loss_fake: ", loss_fake, "acc_fake: ", acc_fake)
print("loss_real: ", loss_real, "acc_real: ", acc_real)
print("loss_comb: ", loss_comb)
generate_images(i)실행 결과
-
학습 횟수 step 0

-
학습 횟수 step 2000

-
학습 횟수 step 4000
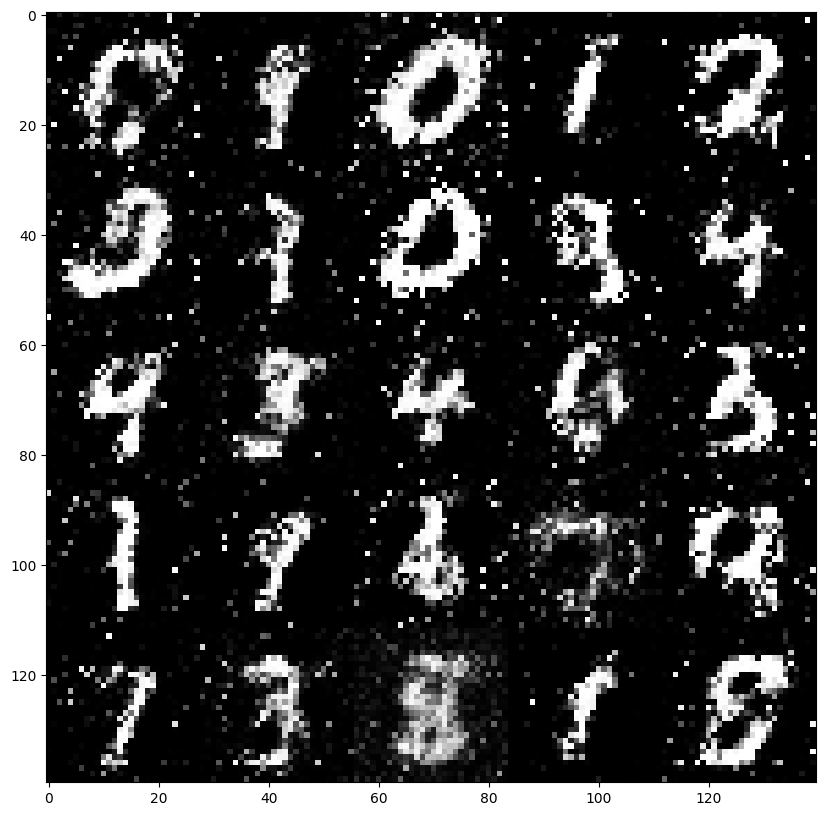
-
학습 횟수 step 6000

-
학습 횟수 step 8000

-
학습 횟수 step 10000

-
학습 횟수 step 12000

-
학습 횟수 step 14000

-
학습 횟수 step 16000

-
학습 횟수 step 18000

-
학습 횟수 step 20000

학습이 진행됨에 따라 점차 명료한 이미지가 형성되는 과정을 볼 수 있다.
3-8. 오차와 정밀도의 추이
# 오차의 추이
n_plt_loss = 1000 # 오차의 범위 표시
plt.plot(np.arange(n_plt_loss), loss_record[:n_plt_loss, 0], label="loss_fake")
plt.plot(np.arange(n_plt_loss), loss_record[:n_plt_loss, 1], label="loss_real")
plt.plot(np.arange(n_plt_loss), loss_record[:n_plt_loss, 2], label="loss_comb")
plt.legend()
plt.title("Loss")
plt.show()
# 정밀도의 추이
n_plt_acc = 1000 # 정밀도의 표시 범위
plt.plot(np.arange(n_plt_acc), acc_record[:n_plt_acc, 0], label="acc_fake")
plt.plot(np.arange(n_plt_acc), acc_record[:n_plt_acc, 1], label="acc_real")
plt.legend()
plt.title("Accuracy")
plt.show()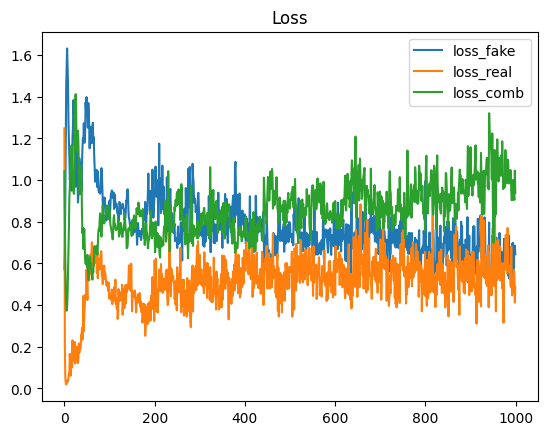
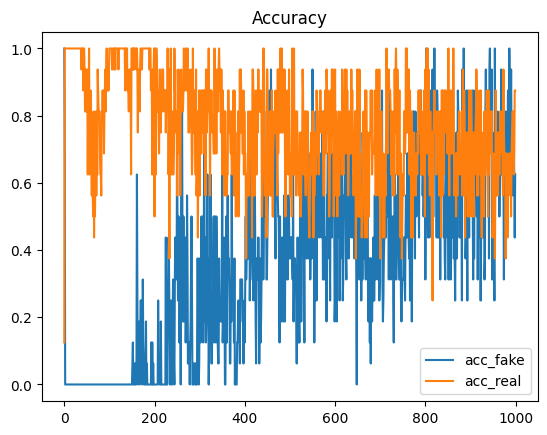
흠.. 일정 범위에서 오차와 정확도가 진동하고 있다. 정확도의 경우 Generator가 완벽한 이미지를 생성하면 정답률은 0.5가 되고 Discriminator가 완벽하다면 정답률은 1.0이 된다. 그러므로 학습 진행중에는 정확도는 0.5~1.0 사이에서 진동할 것으로 예상했는데, step 1000까지는 그 범위를 많이 넘어가고 있다.
