Pagination이란?
전체 데이터에서 지정된 갯수의 데이터만 전달받는 방법입니다.
Pagination의 방법
1. 오프셋 기반 (Offset-based Pagination) : "몇 번째에 있다" 중점
보통 offset, limit을 이용하여 쿼리 처리합니다.
예시
-- PAGE_SIZE = 가져올 묶음 크기 (10, 20, ...)
-- PAGE_NO = 가져올 묶음 번호 (0, 1, 2, ...)
SELECT * FROM items
ORDER BY id DESC
LIMIT PAGE_SIZE
OFFSET (PAGE_NO * PAGE_SIZE)OFFSET만큼의 데이터를 읽은 뒤 LIMIT만큼 데이터를 읽어서 반환합니다.
오프셋 기반 단점 (1) - 데이터의 중복과 누락
데이터의 갯수가 중점이 되므로, 데이터 수량에 변화가 생기면 가져온 데이터의 중복과 누락이 발생할 수 있습니다.
- 중복 : 다음 페이지를 가져왔음에도, 이전 페이지의 데이터가 밀려서 함께 반환합니다.
- 누락 : 이전 페이지와 다음 페이지 사이에 조회하지 못한 데이터가 숨어있습니다.
오프셋 기반 단점 (2) - 성능 저하
위의 예시쿼리를 보면, 뒷 페이지를 조회할 수록 OFFSET의 크기가 증가합니다.
OFFSET 값이 커질 수록 원하는 순서의 데이터를 얻기 위해 조회하는 데이터가 커집니다.
- 검색 엔진이 색인을 생성하기 위해 뒷 페이지의 데이터를 조회할 수 있습니다.
- 사용자에 의해 뒷 페이지의 데이터를 조회할 수 있습니다.
2. 커서 기반 (Cursor-based Pagination) : "어떤 데이터의 다음" 중점
where와 limit을 활용하여, 이전에 조회한 데이터 이후 몇 개를 요청하는 방식입니다.
정확한 위치에서 필요한만큼만 데이터를 조회하므로 오프셋 기반의 단점을 해결할 수 있습니다.
여기서 말하는 CURSOR은 사용자에게 응답해준 마지막 데이터의 식별자 값입니다.
이 값을 기준으로 n개를 요청합니다.
예시
-- CURSOR_VALUE = 마지막 데이터의 식별자
SELECT *
FROM items
WHERE id < CURSOR_ID
ORDER BY id DESC커서 기반 단점 (1) - 유니크한 커서 필요
커서 기반 페이지네이션이 정확하게 동작하기 위해서는, 유니크한 커서가 필요합니다. 중복되는 값을 커서 기준으로 잡을 경우 누락되는 데이터가 발생할 수 있습니다.
커서 기반 단점 (2) - 구현의 어려움
예시와 같이 단순하게 처리할 수 있으나, 데이터와 커서의 형태에 따라 구현이 복잡해질 수 있습니다. 특히 Cursor 값을 기준으로 조회하는 만큼, 특정 기준을 위한 정렬이 어려워 질 수 있습니다.
두 방법의 비교
비교
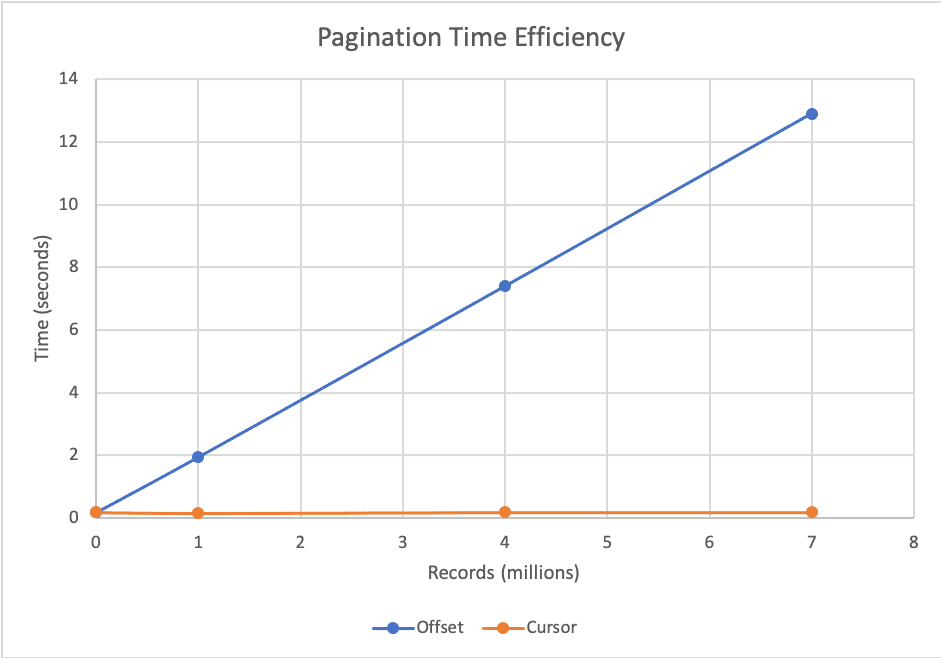
OFFSET의 크기가 늘어날 수록 오랜 시간이 걸리는 오프셋 기반과 커서 기반을 비교한 그래프입니다.
커서 기반은 일정한 데이터만 조회하므로 완만한 그래프를 사용하나, 오프셋 기반은 시간이 점점 길어지고 있습니다.
단순 테스트
테스트 쿼리
-- 오프셋 기반 (PAGE_NO에 따라 OFFSET 값 변경)
explain analyze select * from did_info
order by id desc
limit 10
offset (PAGE_NO * 10)
-- 커서 기반 (PAGE_NO에 맞는 CURSOR 계산 필요)
explain analyze select * from did_info
where id < CURSOR
order by id desc
limit 10데이터가 319개 있는 테이블을 조회하여 비교했습니다. 사용한 DB는 PostgreSQL 12.7입니다. postgreSQL에서는 explain analyze를 쿼리 앞에 붙여주면 시간을 비교할 수 있었습니다.
PAGE_SIZE는 10으로 고정한 뒤, PAGE_NO를 조정하며 비교했습니다.
대상 테이블의 id는 auto_increment로 1부터 1씩 증가하는 값입니다. (id = 1 ~ 319)
신규 데이터의 id는 점점 늘어나는 구조로, 앞 페이지는 최신 데이터부터 보여주는 형태로 정의하겠습니다.
테스트 1 (PAGE_NO=1, CURSOR = 310)
아예 첫 페이지는 건너 뛰고, 2번째 페이지(PAGE_NO=1)을 시도했습니다. 첫 페이지에서 319 ~ 310까지의 데이터를 조회했으므로, CURSOR=310입니다.
-
오프셋 기반
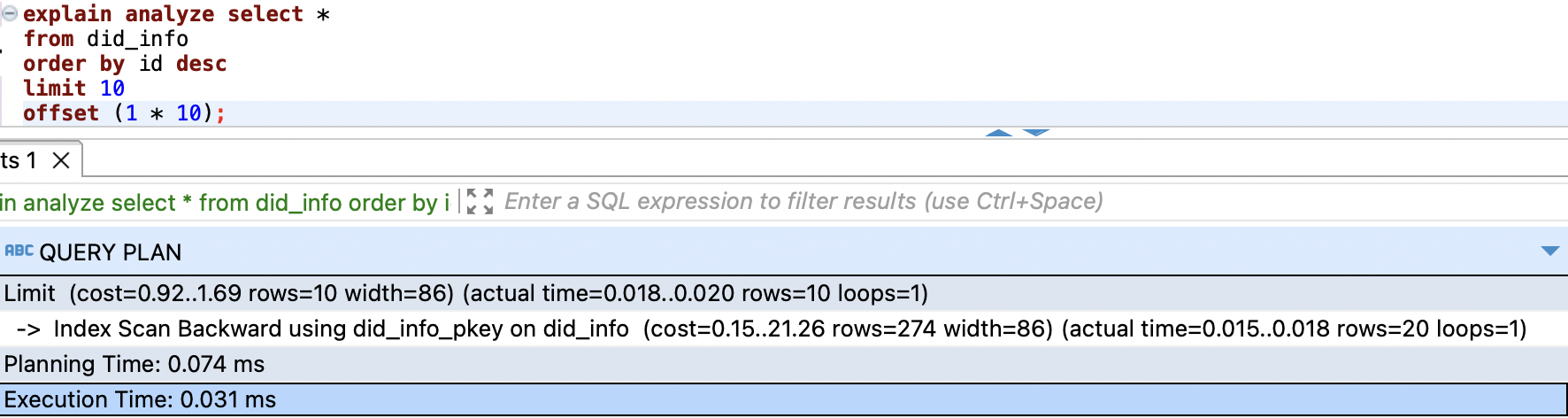
정렬이 일어난 후 10개의OFFSET을 지나 10개의 데이터를 지났습니다. (rows=20)개를 탐색했고, 시간은 0.031 ms가 소요됐습니다. -
커서 기반
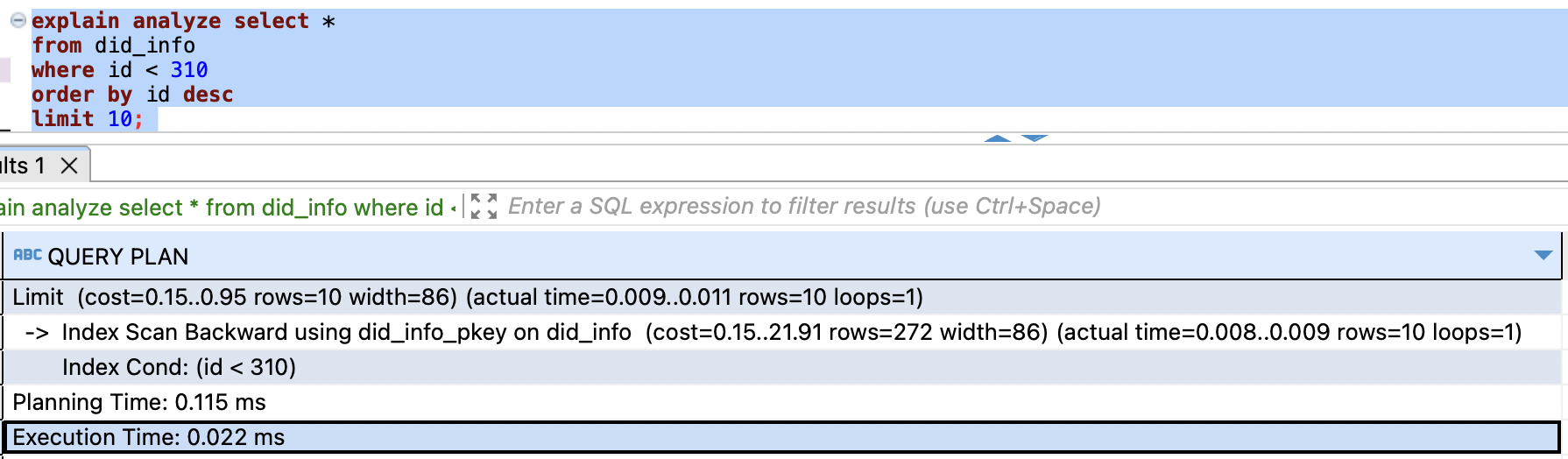
커서 기반과 같은 결과를 반환했으나, (rows=10)개를 탐색했고, 시간은 0.022 ms가 소요됐습니다.
테스트 2 (PAGE_NO=30, CURSOR = 20)
이번엔 뒤에서 2번째 페이지(PAGE_NO=30)을 시도했습니다. OFFSET=300, CURSOR=20입니다.
-
오프셋 기반
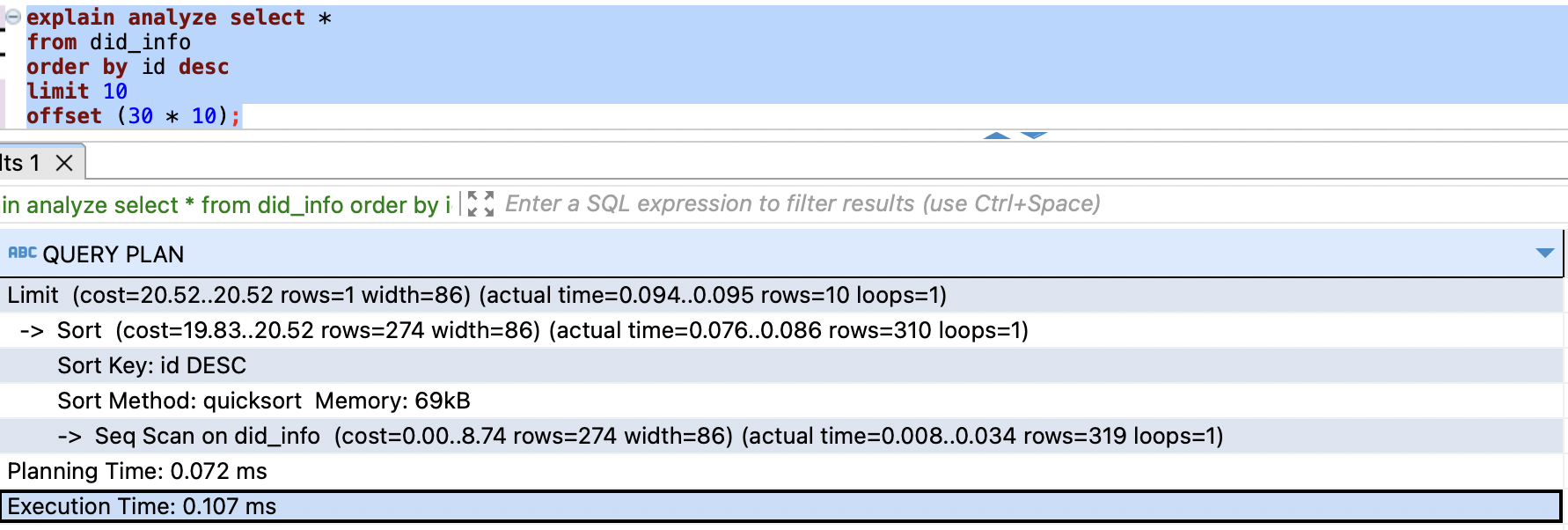
OFFSET이 커지면서 내부적으로 전체 데이터도 조회를 하긴 했으나, 예상했던 (rows=310)도 함께 보입니다. 시간은 0.107 ms가 소요됐습니다. -
커서 기반
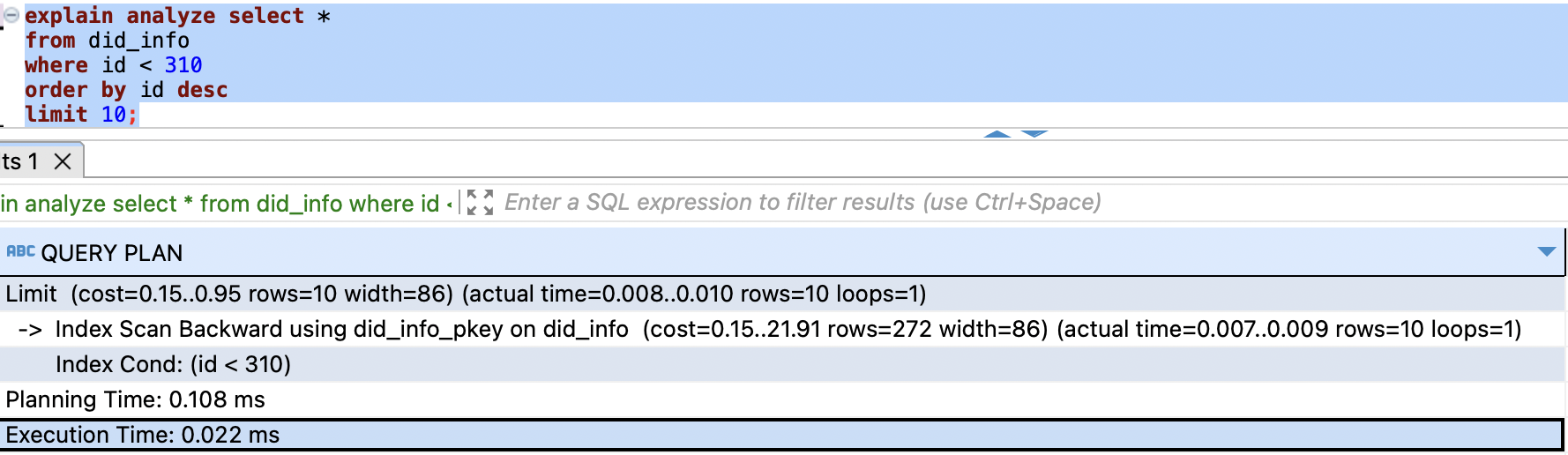
커서 기반은 여전히 (rows=10)을 동일하게 확인했고, 시간은 0.022 ms가 소요됐습니다.
어떨 때 쓰는 게 좋을까?
- 중복 데이터를 노출해도 상관 없을 때
- 데이터에 빈번한 추가, 수정, 삭제가 없을 때
- OFFSET이 커지는 데이터는 조회할 일이 적을 때 (예: 오래된 데이터는 조회하는 일이 적을 때)
와 같은 경우, 오프셋 기반의 페이지네이션을 사용해도 좋다고 생각합니다.
다만 위 예시처럼 커서와 정렬 기준이 단순한 케이스에서는 커서 기반을 쉽게 적용할 수 있으나, 실 업무 환경에서는 다를 수 있습니다.
충분한 고민 후 적절한 방법을 찾기를 바랍니다.
참고 사이트
왜 오프셋 페이징보다 커서 페이징일까?
두 페이지네이션을 이해하기 위해 좋습니다. 쉬운 설명과 시각자료를 갖고 있습니다.
Cursor based Pagination이란? - Querydsl로 무한스크롤 구현하기)
직접 구현한 경험을 바탕으로 작성되어 좋은 내용이었습니다.
커서 기반 페이지네이션 구현하기
offset, limit 외에 페이지네이션을 구현하는 방법에 대한 설명이 있어 좋았습니다.
Cursor-based pagination vs Offset-based pagination
다른 글들이 참고한 그래프의 출처입니다. (영문)
