MLOps 에 대한 개요
MLOps 란 무엇인가?
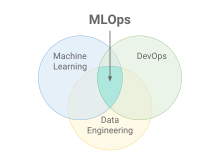
MLOps 는 프로덕션 환경에서 기계 학습 모델을 안정적이고 효율적으로 배포 및 유지 관리하는 것을 목표로 하는 문화/관행/시스템 구성 방식이라고 할 수 있다.
MLOps 위 도식에서 표시 된 것 처럼 Machine Learning, DevOps, Data(& SW) Engineering 을 모두 포함하며 교차하는 방식이라고 할 수 있다. 더불어 GPU 머신에 대한 컴퓨팅 파워 및 전체 인프라 관리를 위한 인프라 Engineering 까지 MLOps 의 범주에 속한다.
머신러닝의 구현 또한 전통적인 SW Engineering 요소와 동일하게 프로그램 Language(주로 python) 을 사용하여 구현되며, GPU 가 탐재된 머신에서의 동작, 시각화, 기존 애플리케이션으로의 배포 및 융합, 빅데이터 기술들을 사용하여 구현되기 때문에 대학의 연구실이나 개인 프로젝트가 아닌이상 기존 IT 서비스의 개발 프로세스를 따라 productization 되어야 한다.
이러한 관점에서 MLOps 는 연속성 있고 효율적인 ML 서비스를 위해 다음과 같은 영역을 고려하여 구축되어야 한다.
- 배포 및 자동화
- 모델 및 예측의 재현성
- 모델 테스트
- 거버넌스 및 규정의 준수
- 확장성
- 콜라보레이션
- 모니터링 및 관리
MLOps 가 필요한 이유는?
- DSML(Data Science & Machine Learning)
Data Science 및 Machine Learning 이 융합되는 프로젝트
MLOps 를 통해 DSML 프로젝트 진행, 플랫폼 구축, 조직문화를 정립하는 것의 필요성은 다양하다. 필요성에 대한 인지 이전에 DSML 프로젝트와 일반 애플리케이션의 차이점, DevOps 와 MLOps 의 차이점을 정리해 볼 필요가 있다.
DSML 프로젝트가 일반 애플리케이션 프로젝트와 다른점
MLOps 가 DevOps 와 다른점
DSML 시스템 또한 소프트웨어 시스템이므로 규모에 맞춰 시스템을 안정적으로 빌드하고 운영할 수 있도록 유사한 방식이 적용되지만 다음과 같은 부분들이 MLOps DevOps 와 다른 MLOps 의 특징으로 꼽힌다.
- 데이터 과학자 DSML 프로젝트는 EDA, 모델 개발, 실험에 중점을 두는 데이터 과학자 또는 ML 연구원을 포함한다.
- 실험적 DSML 의 기본은 실험적이다. 특성, 알고리즘, 모델링 기법, 매개변수 구성을 다양하게 시도하여 문제에 가장 적합한 것을 최대한 빨리 찾아야 한다.
- 검증 복잡성 DSML 시스템 테스트는 일반적인 단위 통합 테스트 외에도 데이터 검증, 학습된 모델 품질 평가, 모델 검증이 필요하며 다른 소프트웨어 테스트보다 더 복잡하다
- 배포 복잡성 DSML 시스템을 사용하면 모델을 재학습 시키고 배포하기 위해 다단계 파이프라인을 배포해야 할 수 있으며 데이터가 과학자가 배포하기 전 새 모델을 학습시키고 검증하기 위해 수동으로 수행되어야 하는 단계를 자동화해야 하는 복잡한 문제를 내포한다.
- 서비스 운영 ML 모델은 지속적으로 진화하는 데이터 프로필로 인해 성능이 저하될 가능성이 기존 SW 시스템보다 다양하다. 이런 저하를 고려해 요약 통계를 추적하고 모델이 성능을 모니터링 해 값이 기대치를 벗어나면 알림을 전송하거나 롤백해야 한다.
ML시스템의 구성요소
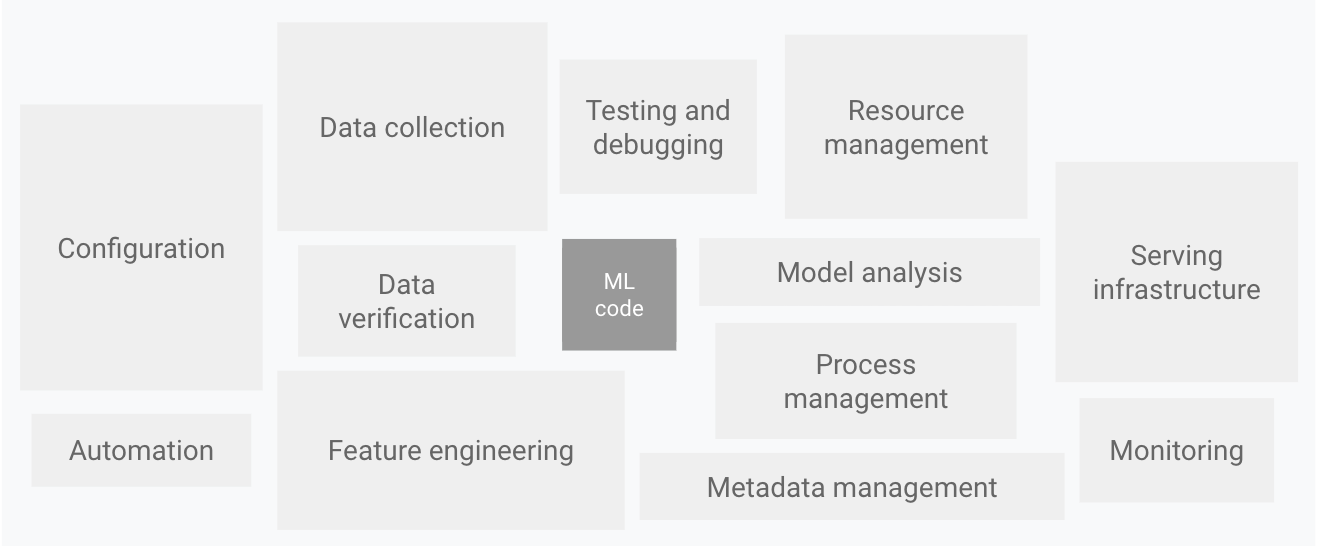
위 이미지의 ML 시스템의 구성요소에서도 볼 수 있듯이, ML 시스템에서 ML code 가 차지하는 부분은 아주 적은 비중을 차지한다.
ML code 외에 ML 모델을 실 서비스에 적용 및 Productization 하기 위해서는 CI, CD, CT 및 GPU 인프라 관리, 인프라 모니터링 등 엔지니어링 영역의 다양한 오픈소스와 퍼블릭 클라우드의 관리형 서비스가 이용 될 수 있다.
누가 MLOps 를 해야 하는가?
개인적인 생각으론, 머신러닝 개발의 기본 Flow 를 이해하고 동시에 Engineering 및 Infra 기본 개념을 갖춘 엔지니어와 데이터 사이언티스트, 모델 엔지니어 데이터 엔지니어등 ML 서비스를 구현하기 위해 협업하는 모든 구성원이 함께 MLOps 를 이해하고 내재화 해야 한다고 생각한다...
참고자료
