수학적인 베이스는 한양대학교에서 오픈강의로 열린 곳을 참고 했습니다 링크텍스트
혹시나 질문이 있으시다면 dsd0919@naver.com 으로 메일 보내주시면
최대한 답변 드리겠습니다
Random Walk란?
시계열 데이터 가 아래와 같은 모형을 따른다고 해보자
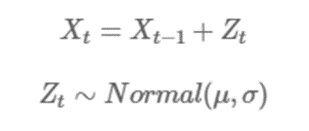
는 평균이 이고 분산은 인 정규 분포를 따른다고 가정하자 는 실수값으로 간주하자
위 모델을 Random Walk 모형이라고 한다. 이유는 가 대칭 분포인 경우 이전 데이터 값인 이 주어졌다고 할 때 그 다음 데이터 값이 를 기준으로 앞으로 가거나 뒤로 갈 확률이 각각 50대 50이기 때문이다
이때 다음 시점값이 이전시점과의 상관관계가 확실히 있으므로 는 Stationary하지 않는다
시계열의 정상성(Stationary)란?
시계열의 정상성이란 시계열 데이터가 시간에 흐름과 무관한 특징을 가지고 있다 따라서 시간에 따라서 변하는 추세와 계절성이 없어야 하고 시간과 상관없는 주기는 있어도 괜찮다 white noise시계열은 정상성을 나타내는 시계열이다 white noise에 대해 리뷰 해보자면 평균이 0이고 분산이 상수이며 자기상관관계가 없는 데이터를 white noise라고 한다.
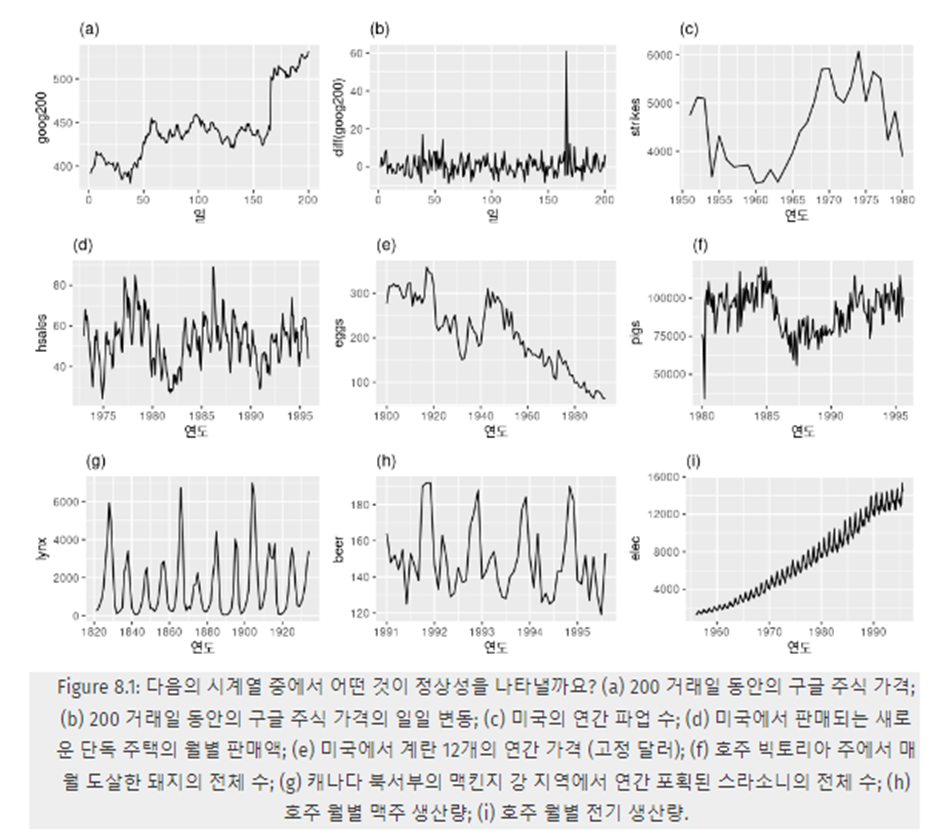
a) 추세가 있고 수준이 변함
b) 정상성을 나타내는 시계열 후보
c) 추세가 있고 수준이 변함
d) 계절성이 보임
e) 추세가 있고 수준이 변함
f) 추세가 있고 수준이 변함
g) 언뜻 보면 계절성이 보이는거 같지만 날짜와 상관없이 스라소니의 먹이가 구하기 힘들어져서 개체수가 줄고 줄어들면 먹이 구하기가 용이해져서 개체수가 다시 늘어나는 식이다 따라서 정상 시계열 후보
h) 연말에 맥주생산량이 급격하게 늘어나는 계절성을 보인다
i) 분산이 늘어나고 추세가 있으며 수준이 변한다
약한 정상성을 수학적으로 더 엄밀하게 정의한다면 다음의 세 가지 조건을 만족해야 한다
임의의 t에 대해서
임의의 t에 대해서
임의의 t, h에 대하여
3번에서 γ(h)는 자기공분산 함수 (Autocovariance Function, ACVF)라 불리우는데, 공분산이 시점 t에 의존하지 않고, 시간의 차이인 h에만 의존함을 의미한다.
[] <- Correlation 공식
예를 들어, A 주식이 정상성을 띤다고 가정합시다. 이 주가의 평균이 3천원이고, 임의의 시점을 t = 2020년 1월 3일이라 치면
2020년 1월 3일의 주가의 평균이 μ=3천원
2020년 1월 3일의 주가의 분산이 유한하며 (= 극단치로 터지지 않고)
2020년 1월 3일의 주가와, 그로부터 5일 뒤인 2020년 1월 8일의 주가 간의 공분산이 γ(5)임을 의미한다.
**정상성이 중요한 이유** **시계열의 평균과 분산이 일정해야 시계열 값을 예측할 수 있다.** 시계열 분석에서는 “우리가 구한 시계열 자료”가 어떤 시간에 따른 확률과정(stochastic process)[확률공간에서 정의되는 확률변수들의 모임]에서 실현된 값이라고 본다. 확률과정은 시간별로 표시된 확률 변수의 집합으로 정의가 되는데 각 시점 t에서의 값이 확률분포를 따른다고 보고, 이를 종합적으로 고려했을 때 시간 t에서의 값들이 어떤 확률 분포를 따를 때 확률 과정이라고 부를 수 있다 따라서 우리가 얻은 시계열 자료가 일정한 평균과 분산을 가진 확률 과정을 따른다고 가정해야만 시계열 예측을 할 수 있다.
예를 들어보자 만약에 우리가 예측을 하려고 하는 시점에서의 확률변수가 갑자기 평균과 분산이 다른 분포를 따른다고 가정해보자 그러면 이는 예측하기 쉬울까? 물론 아닐 것이다 따라서 예측을 수행함에 있어 정상성은 필수인 조건이다.
NonStationary인 데이터를 Stationary하게 만들기
차분(differencing)
우리는 정상성을 나타내지 않는 시계열을 정상성이 나타나게 할 수 있는데 그 방법이 바로 차분(differencing)이다 차분은 바로 옆에 있는 데이터와의 차이를 계산하는 것으로 시계열의 수준을 제거 함으로써 시계열의 변화를 일정하게 만드는데 도움이 된다
-> 계절성 차분 1차 2차... 차분이 존재하지만 보통 1차 차분 이내에 해결 된다.
로그변환
우리는 로그변환을 통해 값의 변동이 큰경우(분산이 큰경우) 이런 지수적인 그래프를 선형적인 값으로 바꿔준다
따라서 로그변환을 통해 값의 분산을 일정하게 만든 후 차분을 통해 정상성을 만족시키도록 해서 정상성이 만족되게 한다
이때, 로그의 차분값이 증가율의 근사값으로 알려져 있는데
이렇게 쓰면 해석상 이점이 있다
가령 GDP같은 지수적인 그래프에서
“GDP의 로그의 차분값이 AR(1)과정을 따릅니다” 라는 말보다
“GDP의 증가율이 AR(1) 과정을 따릅니다 가 더 잘 와닿는다
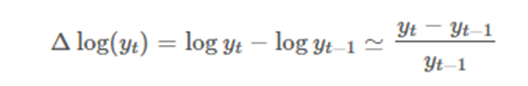
시계열 데이터가 Stationary한지 확인하는 방법
- ACF 그래프를 활용하는 법
정상성을 나타내지 않는 데이터는 ACF가 느리게 감소하지만, 정상성을 나타내는 시계열은 ACF가 비교적 빠르게 0으로 떨어질 것이다(Sharp drop off) - 통계적 가설 검정을 이용하는 법(Augmented Dickey-Fuller(ADF test) / KPSS test)
ADF 검정은 시계열에 단위근(unit root)이 존재하는지의 여부를 검정함으로써 정상 시계열인지 여부를 판단한다.단위근이 존재하면 정상 시계열이 아니다단위근이란
AR(p) 모형이 정상성을 띠기 위한 조건은 특성 방정식의 모든 근의 절대값이 1보다 커야한다는 것이다 특성 방정식은 다음과 같이 쓸 수 있다
여기서 B는 후방이동 기호를 의미하고 By_t = y_t-1 이다 따라서 위의 식은
를 y_t로 정리해서 얻어낸 식이다
만약 이 특성방정식의 근이 1인 것을 가지고 있다면 이때 단위근을 가지고 있다고 말한다
단위근을 갖으면 시계열은 Non-Stationary하게 되는데 이를 AR(1)모형에 대해 설명해보겠다.
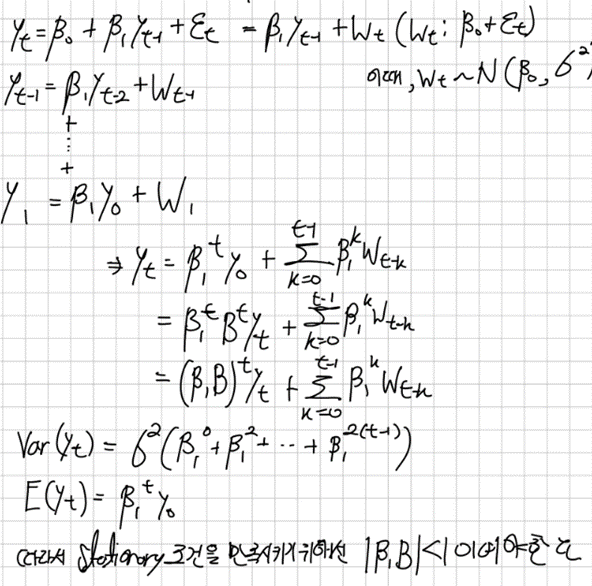
단위근 검정방법
(1)ADF(Augumented Dickey Fuller test)
Augmented Dickey-Fuller (ADF) Test - Must Read Guide - ML+ (machinelearningplus.com)
ADF는 AR(p) 모형에서의 단위근 검정으로써 귀무가설은 단위근을 가진다는 것이고(Not stationary) 대립가설은 단위근을 가지지 않는다는 것이다 이때 검정통계량과 ADF의 디키-풀러 분포의 Critical Value를 이용해서 검정통계량과 CV를 비교해 귀무가설을 기각한다
파이썬에서는 from statsmodels.tsa.stattools import adfuller 로 구현 돼 있다
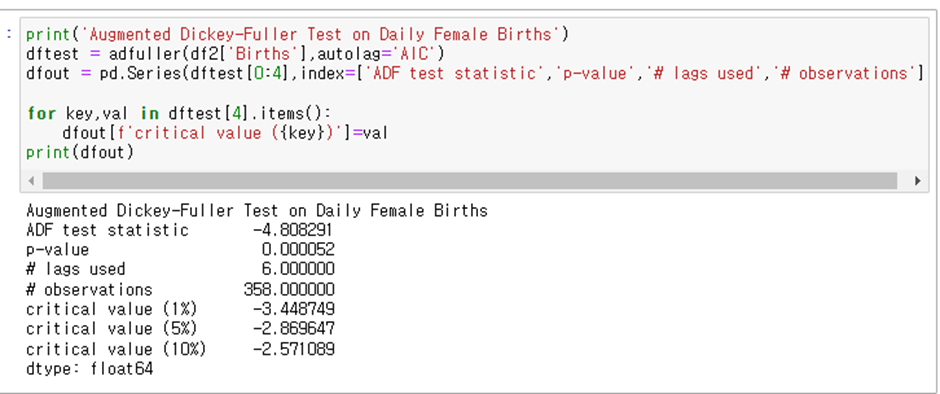
Adf의 regression 파라미터는 4가지 옵션이 존재하는데 c, ct, ctt, n으로 구성돼있고 각각은 다음을 의미한다
c : constant (상수항만 존재)
ct: constant and trend(상수항과 추세 존재)
ctt: constant and linear and quardratic trend (상수항과 1차 2차 추세가 존재)
n: no constant, no trend (상수항과 추세가 둘다 존재하지 않음)
또한 adf는 AIC의 값을 최소로 하는 AR(p)값을 선택하고 위 예제에서는 p=6이다 또 p-value가 0.05 보다 작음을 확인 할 수 있지만 통계량이 크리티컬 발류보다 작은것을 확인해도 위의 예제는 귀무가설을 기각하고 정상 시계열임을 알 수 있다.
(2) KPSS Test
KPSS Test는 ADF Test와 가설이 다르다
KPSS의 귀무가설은 시계열이 정상시계열이다(stationary) 는 것이고 대립가설은 시계열이 정상시계열이지 않다는 것이다
우리는 KPSS test와 ADF test를 혼용해서 쓰면 안된다 KPSS test는 확정적 추세를 갖는 데이터에서의 stationarity를 확인하는 것이다 KPSS test에서 regression = ct로 설정해준다면 우리는 데이터가 trend 주변에서 stationary함을 볼 수 있다
KPSS Test for Stationarity - Machine Learning Plus
파이썬에서 KPSS를 사용하면 P값이 출력될 때 최대 10%에서 최소 1%로 출력이된다 그렇기 때문에 warning 메시지가 뜨고 실제 P값은 출력된 P값보다 더 큰 값이다라는 정보를 주게된다
[확실한 추세가 있는 데이터에 대해 log 변환으로 분산 조정후 kpss trend 주변에서 stationary인지 확인]
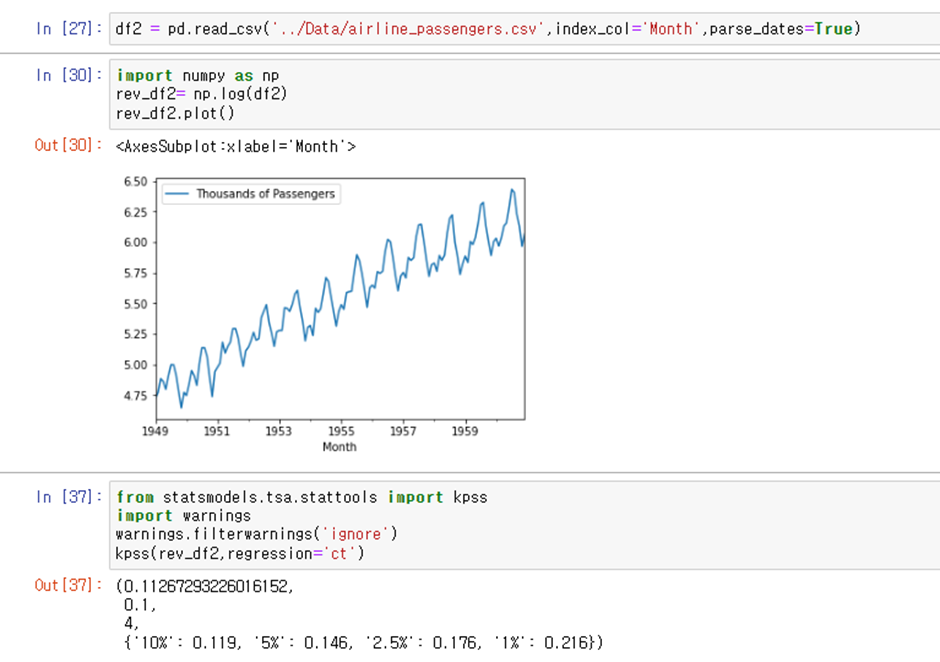
통계량이 CV보다 작으므로 귀무가설 기각 불가
Kpss trend 주변에서는 stationary하다
반대로 평균 근처에서 stationary인지 확인
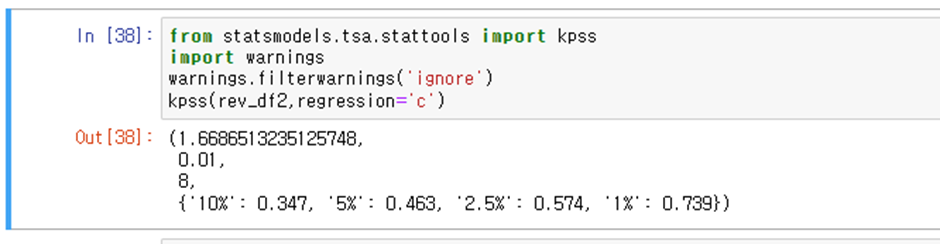
통계량이 CV보다 크므로 귀무가설 기각
일정한 상수에 대해서는 stationary하지 않는다.
AR모델(Auto Regressive Model) 과 MA모델 (Moving Average Model)
자기회귀 모델에서는, 변수의 과거 값의 선형 조합을 이용해 관심 있는 변수를 예측한다 자기회귀라는 단어에는 자기 자신에 대한 변수의 회귀라는 의미가 있다
따라서 차수 p의 자기회귀 모델(autoregressive model)은 다음과 같이 쓸 수 있다.
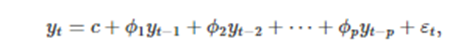
a.AR모델과 MA모델의 상호변환
우리는 위의 AR모델을 변형할 수 있는데
AR(1)모델부터 변형해보겠다
먼저 우리는 단위근을 갖지 않는다고 가정하자
아래의

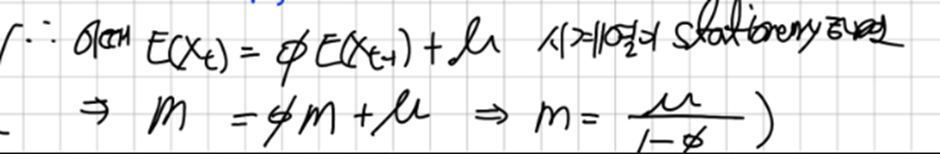
따라서 우리는 t에서의 관측값을 이전시점들의 오차의 선형결합으로 표현할 수 있게 됐다
우리는 Causal 한 시스템에 대해 정의 할 수 있는데

우리는 오차가 White noise임을 알기에 미래시점의 관측값과 현재시점 이전의 오차로 표현되는 X_t의 공분산이 0임을 알 수 있다 이렇게 미래의 시스템에 의존하지 않는 시스템을 Causal(인과성이 있는)한 시스템이라고 한다.
우린 이렇게 | pi |<1 이면 AR(1) 모델이 Causal한 모델 즉 X_t가
이렇게 바뀜을 알 수 있다 이렇게 이전시점의 오차를 이용해서 목표 예상변수를 표현하는 모델을 이동평균모델 MA(q)라고 한다.
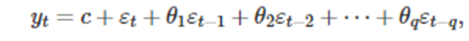
따라서 우린 방금 AR(1) 모델을 MA(inf)모델로 바꾼 것이고 이를 반대로 MA(q)모델을 AR(inf) 모델로 바꿀 수 있다
MA(1)을 생각해보자
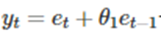
이때 e_t = y_t-y_t-1 이고 이를 재귀적으로 전개하면 우리는 e_t를 다음과 같이 쓸 수 있다
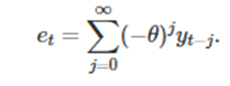
마찬가지로 |Theta|<1의 조건을 만족해야 한다
b.AR모델과 MA모델을 상호변환 할 수 있는 매개변수의 계수조건 찾기
위에선 | Pi |<1 이었고 아래에선 |Theta| < 1이다 이 조건에 대해서 자세히 알아보고자 AR(1)을 후방연산자를 사용해서 전개해보고 AR(2)에 대해서도 전개해보겠다
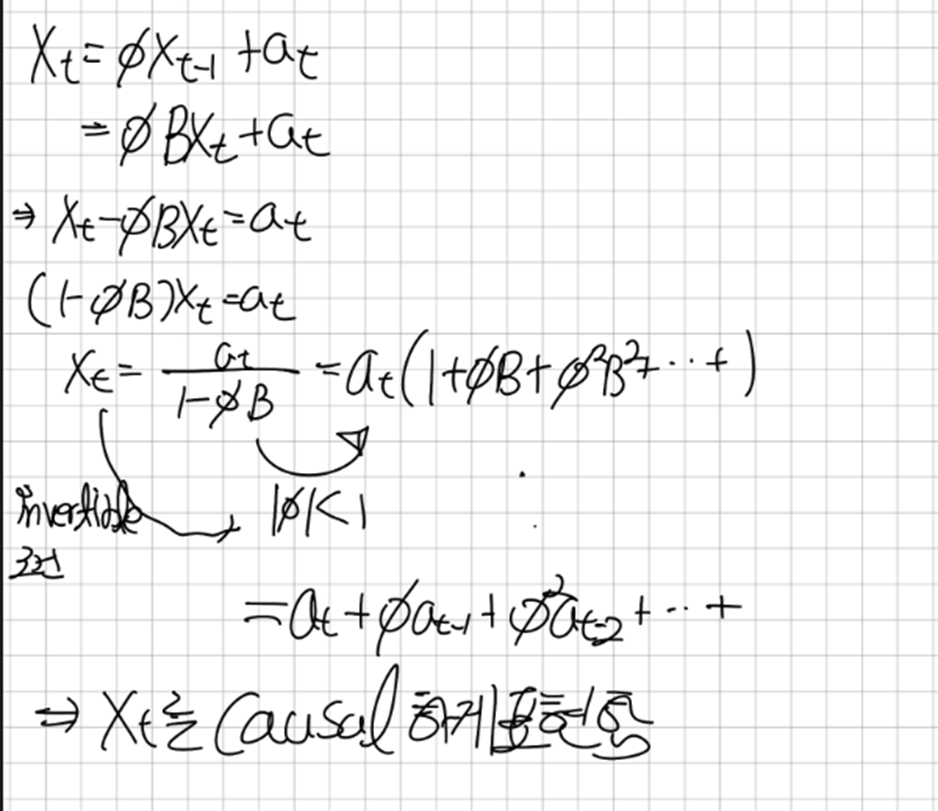
1/1-(pi*B) -> piB 가 공비로 갖고있는 무한등비급수라고 생각 할 수 있다
이점을 이용해서 AR(2)를 전개해 보겠다
AR(2)
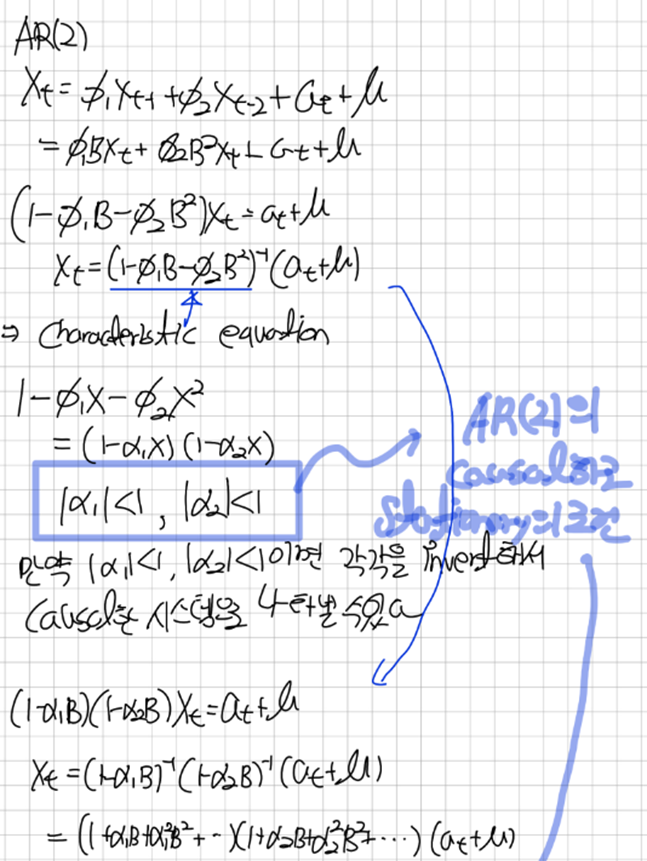

이런식으로 매개변수의 계수에 대한 조건을 세울 수 있고 조건을 만족하면 AR(p)모델이 Causal하게 표현됨을 알 수 있다 또한 X_t가 Causal함이 밝혀지면 우리는 이를 통해 MA모델의 매개변수를 찾아 낼 수 있다 예를 들어보자
c. AR(p) 모델이 Causal 함이 밝혀졌을 때 MA(inf) 모델의 매개변수의 계수 찾기
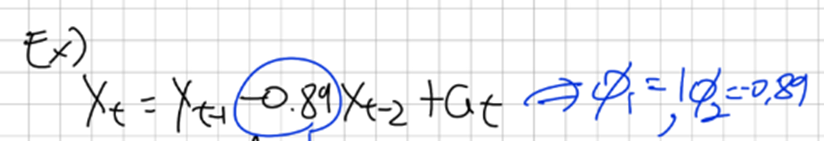
물론 AR모델의 계수는 우리가 갖고 있는 시계열의 회귀분석으로부터 예측 할 것이다
위 모델의 특성 방정식을 구하고 AR(2) 조건을 확인하면 X_t가 Causal하다는걸 알 수 있고
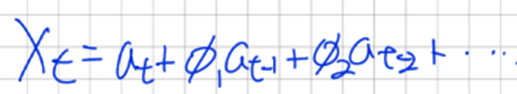
이렇게 작성 할 수있고 이를

이 방정식에 대입하고
곱해서 a_t가 되도록하는 pi_1,pi_2, .. 을 구할 수 있다
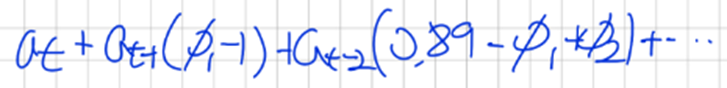
pi_1 = 1 , 이를 0.89-pi_1+pi_2에 대입해서 pi_2를 찾을 수있다
우리는 AR(2)의 조건을 살펴보았는데 MA(2) 조건에 대해서도 알아보자
MA(2)

이를 정리하면
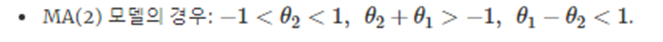
위와 같은 조건이 나온다
P와 q가 커질수록 더 복잡한 조건이 생긴다.
d.AR모델의 매개변수를 찾기 위한 Yuler-Walker Equation
이는 word파일을 참고하자.
f. ARIMA(AutoRegressive Integrated Moving Average)
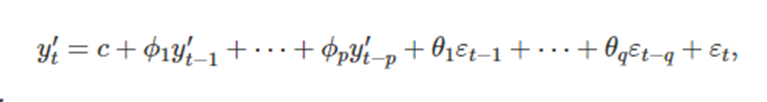
y’_t는 차분을 구한 시계열이고 우변은 AR모델과 MA모델의 합으로 적혀 있다 이것을 ARIMA(p,d,q)모델 이라고 하는데 p는 AR의 차수 d는 1차차분이 포함된 정도 q는 이동평균의 차수를 의미한다
ARIMA 모델의 d로인해 우리는 추세가 있는 데이터를 다룰 수 있다
우리는 위에서 자기회귀와 이동 평균 모델에서 invertibility조건을 알아봤는데 이는 ARIMA 모델에서도 똑같이 적용된다
지금까지 알아본 많은 모델은 ARIMA모델의 특수한 경우이다

우리는 위의 식을 후방이동연산자를 사용해서 바꿔서 쓸 수 있는데 다음과 같이 쓸 수 있다
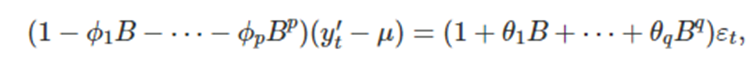
여기서
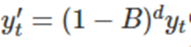
이고 μ는 의 평균이다 [d는 differential 차수]
여기서 c는
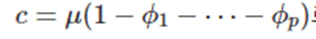
로 정의한다.
우리는 ARIMA가 정확히 어떤 수학적인 기준으로 모델의 차수를 고르는지 이해할 필요가 있지만 이는 소프트웨어에게 맡기도록 하자
우리는 이와 관련해서 쓸 수 있는 모델이 2가지가 있는데 auto_arima와 ARIMA이다
호출방법은 다음과 같다
from pmdarima import auto_arima
pmdarima의 auto_arima는 information criterion 값을 사용해서 모델의 AIC 값이 가장 작은 모델 모델을 선택한다 모델의 d값을 선택하기 위해 KPSS ADF test등을 사용하고
auto_arima는 ARIMA모델을 얻기위해 Hyndman-Khandakar(힌드만-칸다카르) 알고리즘을 사용한다
Hyndman-Khandakar
- KPSS 검정을 반복해 차분횟수 d를 결정한다
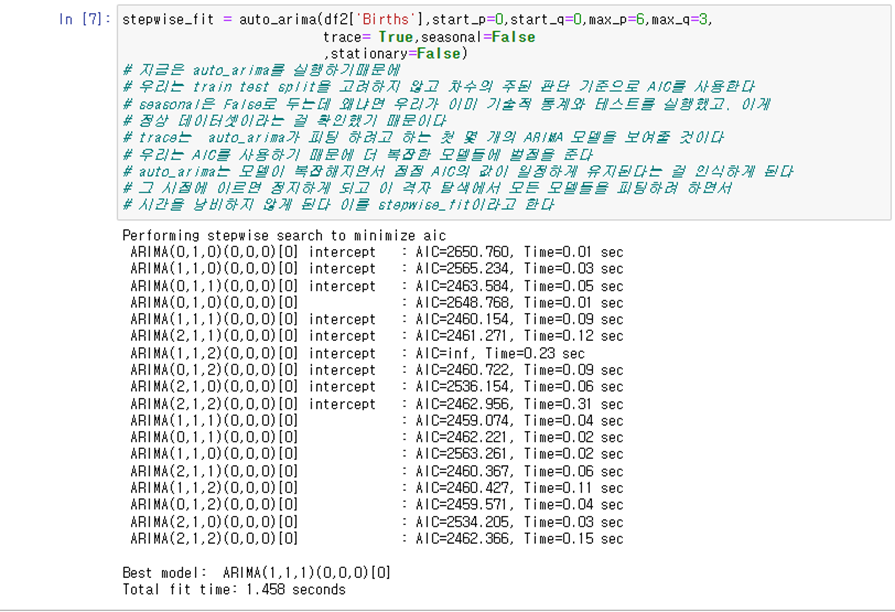
- 데이터를 d번 차분한후에 AIC를 최소화하는 p와 q를 고른다 이때 p와 q의 모든 가능한 조합을 살펴보는 것이 아니라, 모델 공간을 탐색하기 위해 단계적(stepwise) 탐색을 사용한다
기본모델 4가지를 맞춘다.

d>=1이면 상수는 제거된다
여기서 맞춘 AIC 값이 가장 좋은 기본모델을 현재모델로 둔다
현재모델에서 p와 q를 +-1로 바꾸거나 상수를 넣거나 빼서 가장 좋은 모델을 현재모델로 채택한다
더 작은 AIC가 나오지 않을 때까지 반복한다
g. 수동모델링 과정
c,d값
우리는 Auto Arima를 통해 모델을 자동 선택할 수 있지만 모델이 대략적으로 작동하는 방식은 공부해볼만 하다 상수 c와 차분의 정도 d는 장기 예측값에 중요한 영향을 준다

d 는 예측구간에도 영향을 주는데 d값이 클수록 예측구간의 크기가 급격하게 늘어나고 d=0에서 장기 예측 표준 편차가 과거 데이터의 표준편차에 가까워질 것이다 따라서 모든 예측구간은 실제적으로 같게 될 것이다.
process
1. 데이터를 그래프로 나타내고, 특이한 관측값을 찾는다
2. 분산을 안정화하기위해 박스-칵스 변환을 사용해 데이터를 변환한다
3. 데이터가 정상성을 나타내지 않는다면, 데이터가 정상성을 나타낼 때까지 데이터를 가지고 1차차분을 계산한다
4. ACF/PACF 를 살펴보고 ARIMA(p,d,0)가 적당할지 ARIMA(0,d,q)가 적당한지 살펴본다
5. 우리가 고른 모델을 사용해보고 더 나은 모델을 위해 AIC를 사용한다
6. 잔차의 ACF를 고려하고 융-박스검정과 같은 포트맨토 검정을 하여 잔차가 White Noise인지 확인한다
7. 잔차가 백색잡음이면 예측값을 계산한다
힌드만-칸다카르 알고리즘은 3~5단계만을 처리해준다
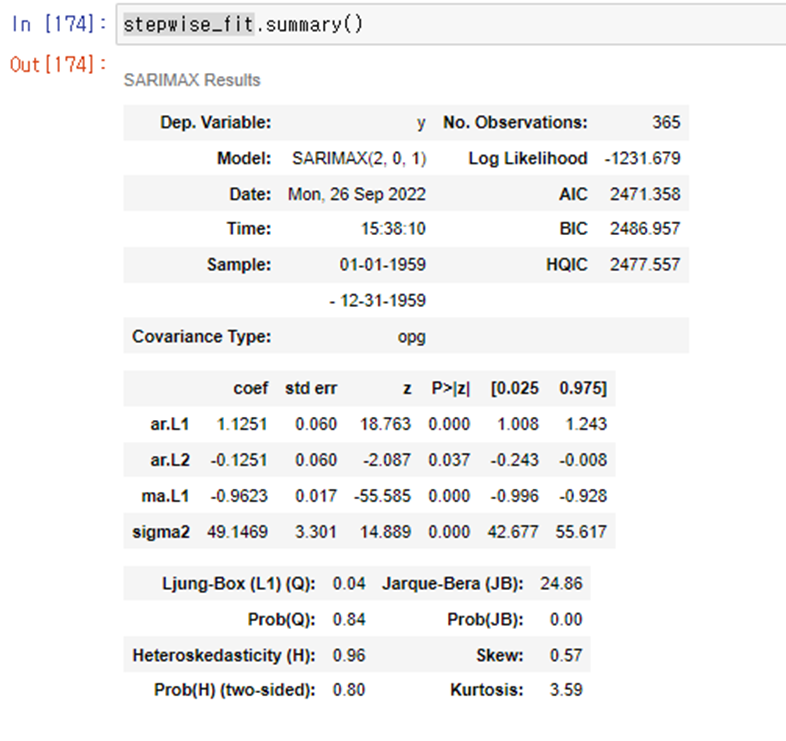
잔차의 acf와 pacf를 그린후 ljung-Box test까지 해보기
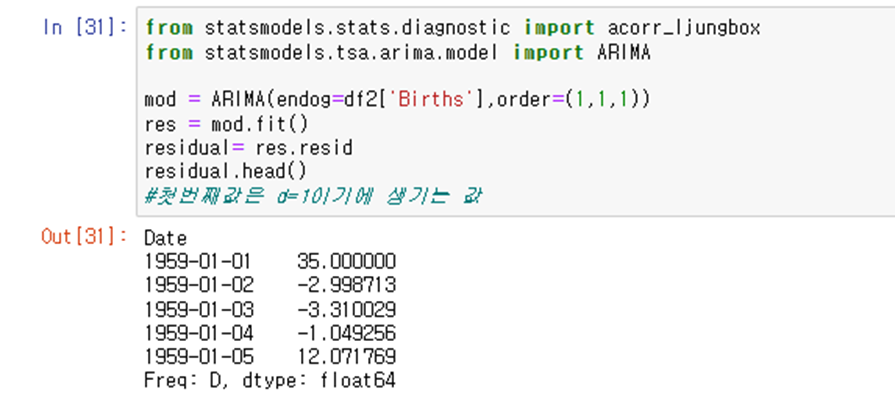
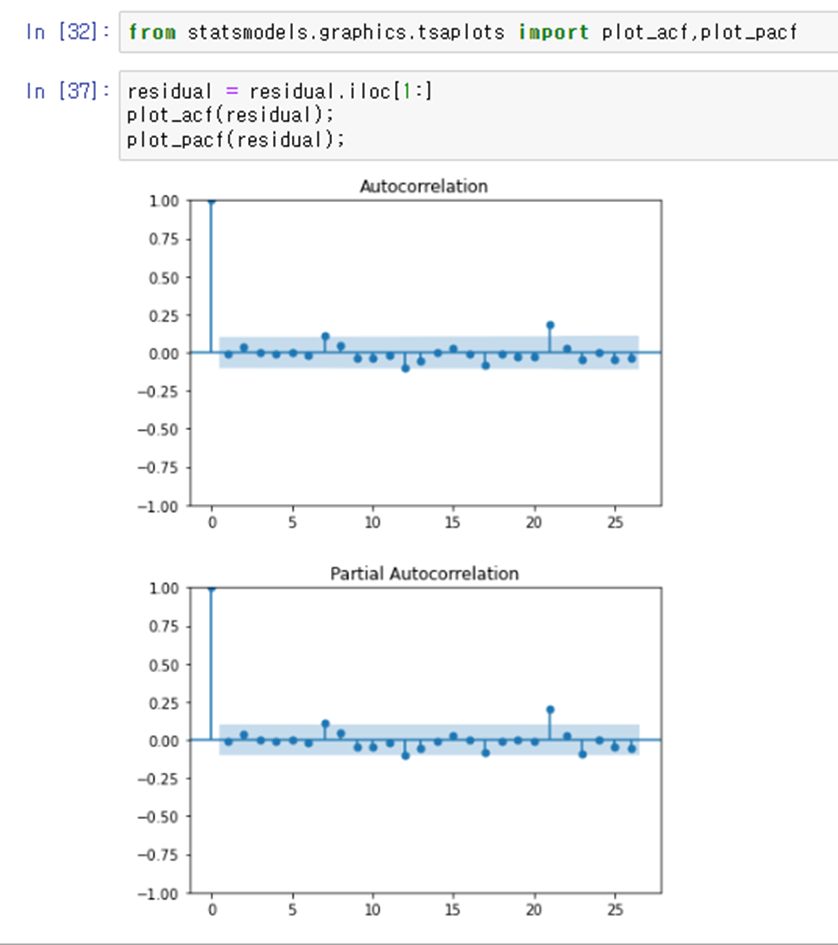
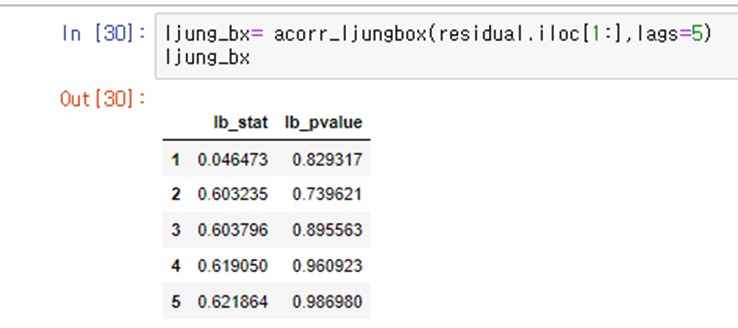
인덱스는 lag값 / lb_stat =통계량 , lb_pvalue는 p_value를 의미
h. 점예측하기
점예측은

위와 같은 과정을 거치는데
ARIMA(3,1,1)에대해 작성하면 다음과 같다

ARIMA의 예측구간은 더 복잡한 과정을 다루므로
따라서 Python에서 구현해봤는데
정상시계열에선
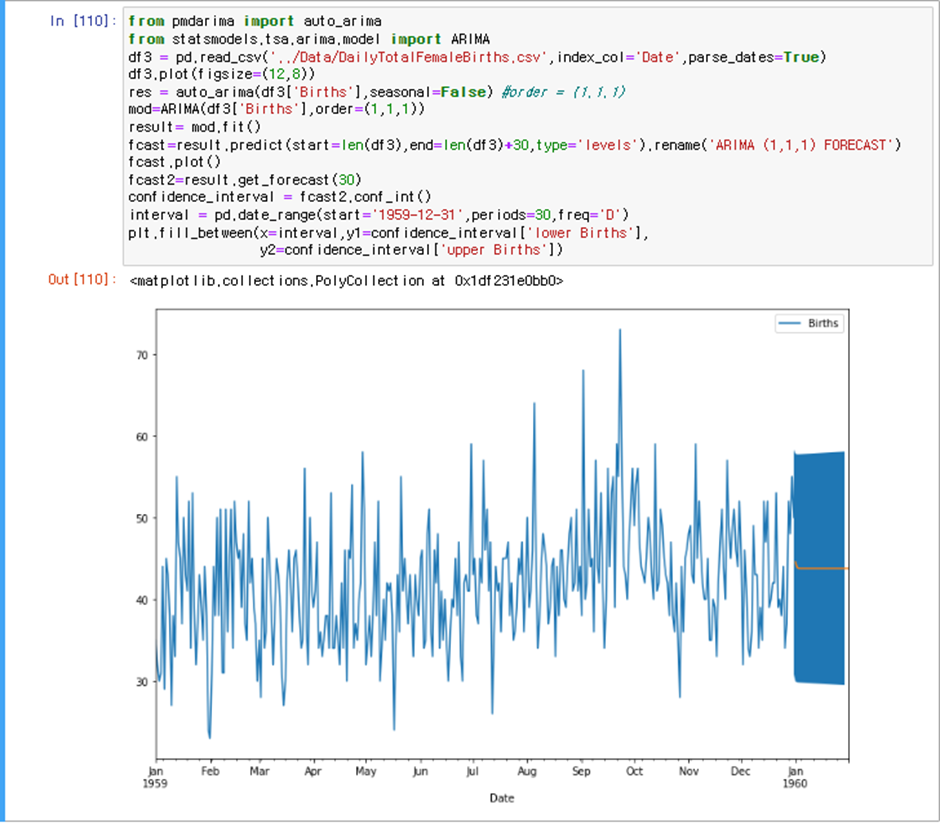
PI가 일정하게 나왔고
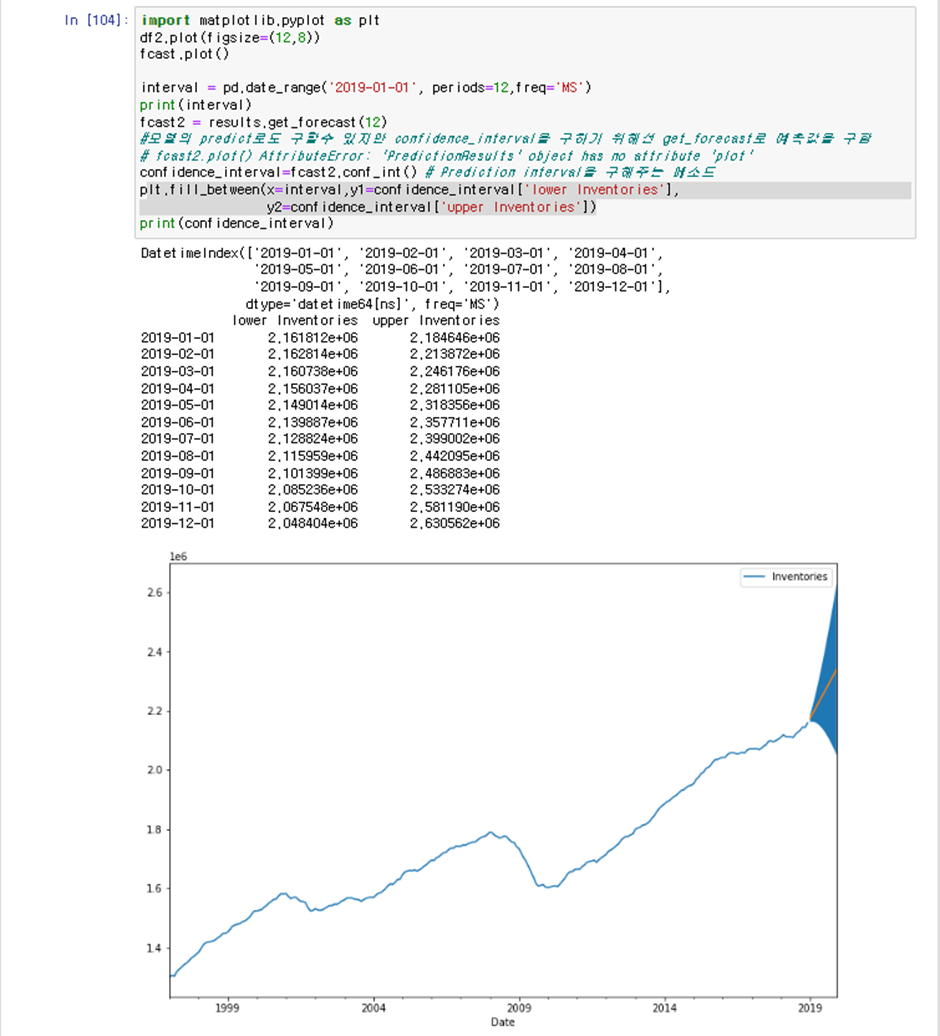
비정상 시계열에선 PI가 퍼지듯이 나왔다

i. SARIMA
우리는 ARIMA를 진행하다보면 Seasonality가 들어있는 데이터는 처리할 수 없다는 사실을 알 것 이다 따라서 계절성을 지원하는 ARIMA라는 뜻에서 SARIMA가 나오게 됐다 SARIMA는 기존의ARIMA에서 P,D,Q가 새로 추가가 됐는데
P,D,Q가 의미하는 바는 다음과 같다


SARIMA(1,1,1)(1,1,1) Formula
ARIMA Formula 에서 계절성 요소들을 추가한것과 같다
S는 계절성 주기를 의미한다
우리는 ARIMA와 같이 ACF와 PACF를 보고 이 데이터가 어떤 모델을 써야할지 대략적으로 유추 할 수 있는데 다음과같다


우리는 계절성 데이터를 계절성 차분을 2회 구해서 plot을 그려보았다
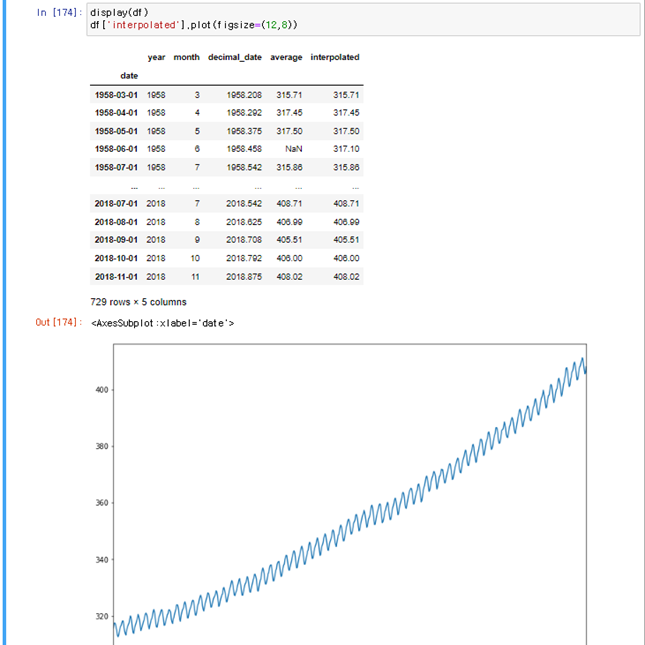
미국의 CO2 배출량을 ppm단위로 만든 데이터는 계절성 데이터 인데 이것의 ACF,PACF를 그려보겠다
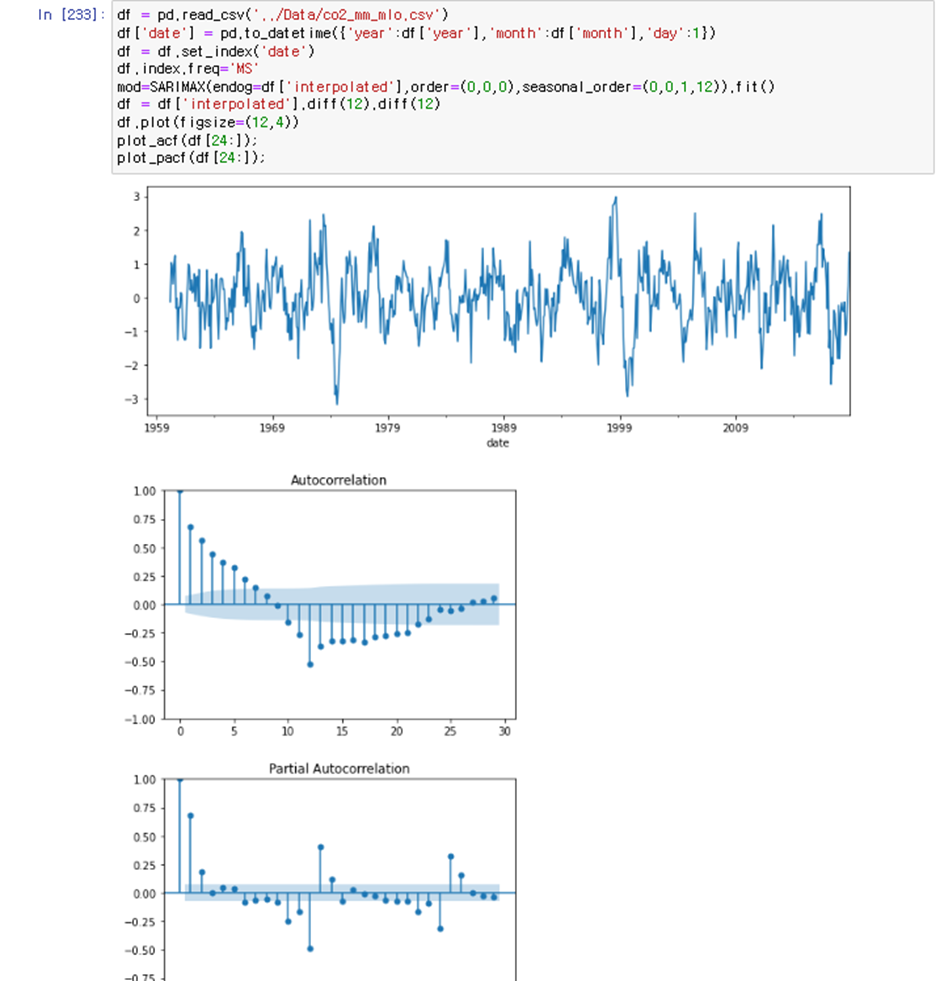
이는 위에서 ARIMA(0,0,0)(1,2,0)[계절성 2회차분]모델에 더 가까움을 알 수 있고 AR(1)모델을 사용한다고 봐야한다
따라서 우리는 기본모델을 ARIMA(1,0,0)(1,2,0) 이라고 볼 수 있다
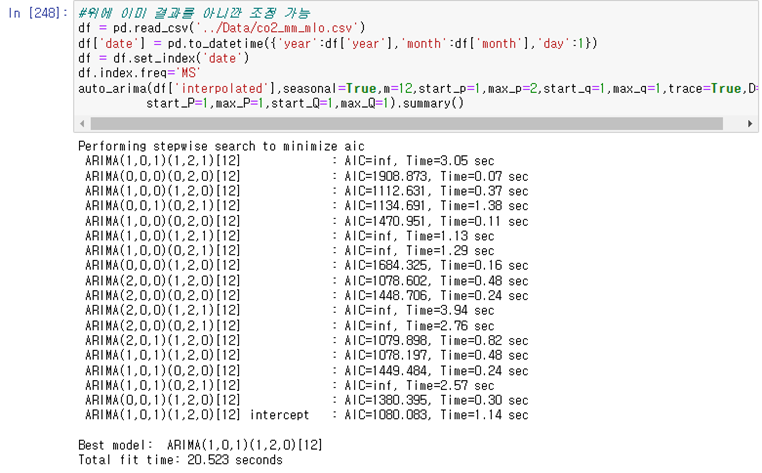
Auto_arima로 수행했을 때 거의 비슷함을 알 수 있다
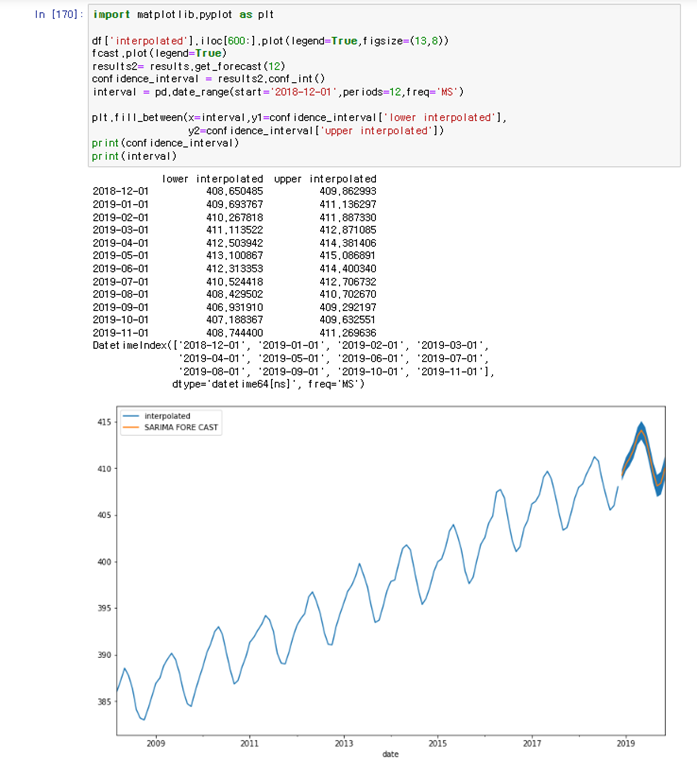
j. SARIMAX
SARIMA의 외생적 회귀 변수도 지원한다는 의미이다
예를 들어보자 우리가 레스토랑에 방문하는 방문자 수를 예측하고자 하고 이전에 방문객수의 데이터를 갖고 있다고 해보자 우리는 이전에 해왔던 것처럼 예측을 수행할 수 있다 하지만 휴일정보를 포함하고 싶을 땐 어떻게 해야할까?
우리는 휴일 정보를 Dummy Variable로 만들어 적용할 수 있을 것이다
( pd.get_dummies( ) )
우리가 직접 외생변수(exogeneous variable)를 넣을 수 있는데 여기에는 약간의 직관이 필요하다 우리가 예측에 관련이 있다고 생각하는 것들을 외생변수로써 넣는 것이다
하나 중요한점은 우리는 외생변수를 예측하는 것이 아니고 그저 미래시점에 대해 우리가 알고 있는 외생변수를 제공하는 것이다 다시 말하면 우리는 미래의 외생변수 까지 알고 있어야 하며 실제로 외생변수는 휴일과 같은 단순한 것들이다 혹은 우리가 어떤 근거로 미래의 외생변수에 대해 강한 확신이 있어야 한다
[일자별 레스토랑 방문객수에 대한 데이터 SARIMA &SARIMAX][미래시점의 총방문객수 예측]
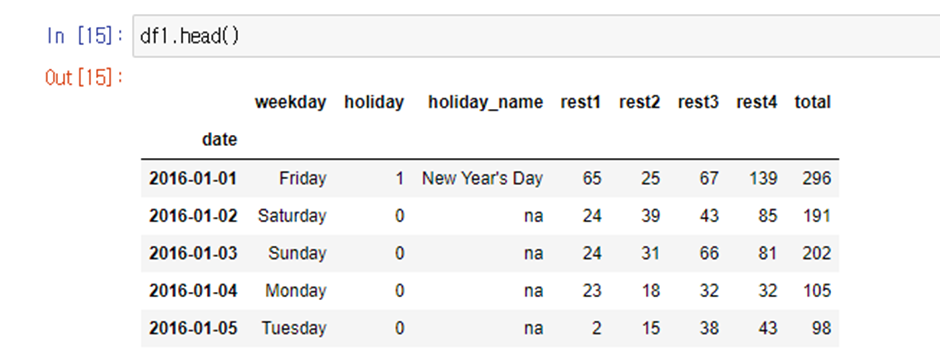
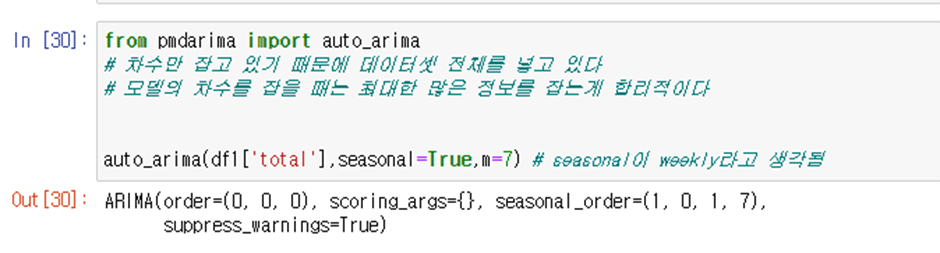
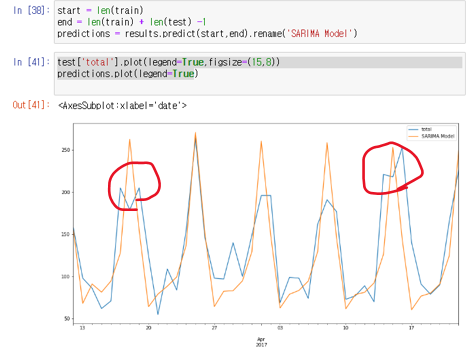
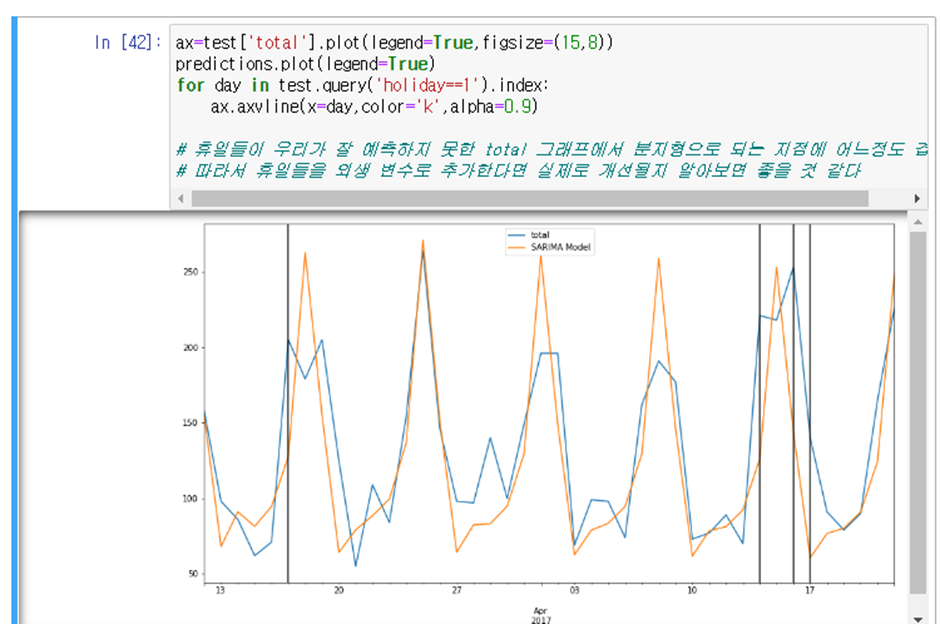
분지형으로 된 곳이 잘 예측되지 않았다고 볼 수 있는데 이것이 휴일의 영향일 것이라고 예측할 수 있다

SARIMAX 구축
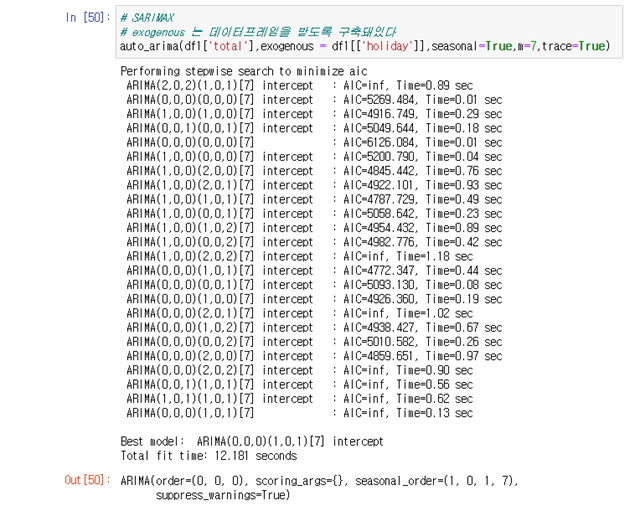

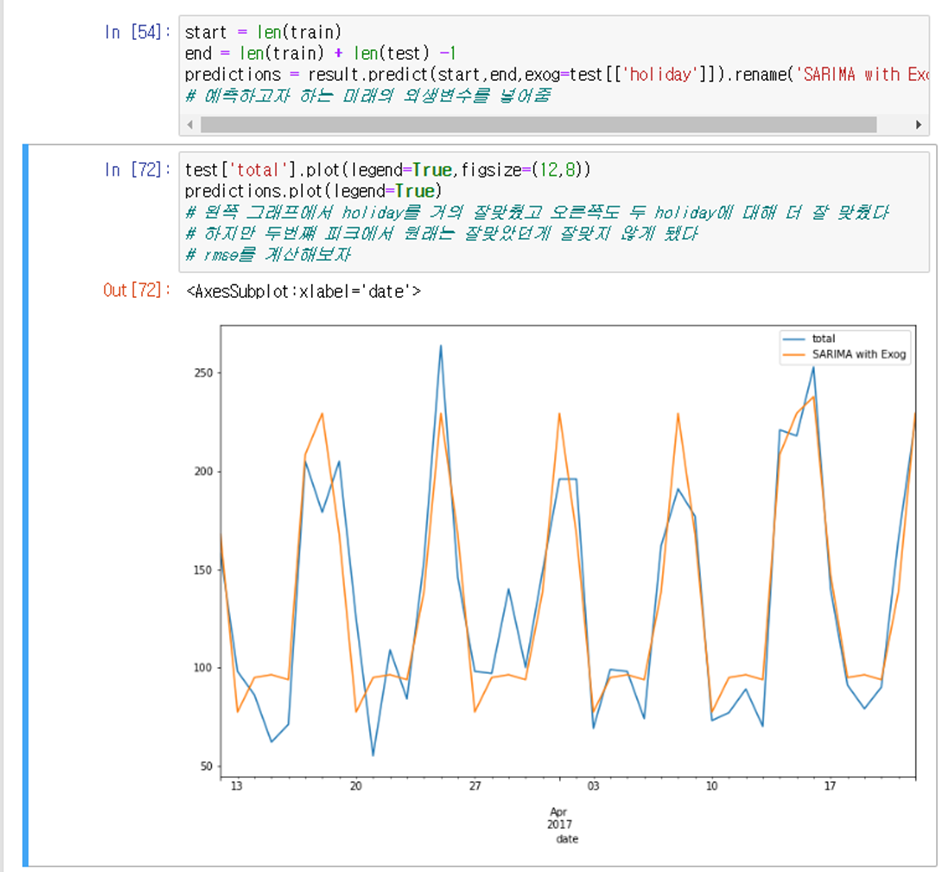
SARIMAX가 더 적당하다고 판단 가능하다
따라서 SARIMAX에 대해 모든 데이터로 다시 학습을 하고 실제 미래에 대한 예측을 진행하면 된다
