Pytorch
1.내가보기위해 만든 torch 모델 Save와 loading

최근에 23학점을 듣게 되면서 정신없이 삶을 살던중에 연구실에서 Transfer Learning을 해야하는 상황이 생겼다 전체 데이터셋에 대해서 예측을 수행해야 했는데 그렇다보니 시간이 너무 오래걸렸다.. 이전에 10000개정도 되는 데이터를 예측할때는 시간이 2~3시
2.Optimizer
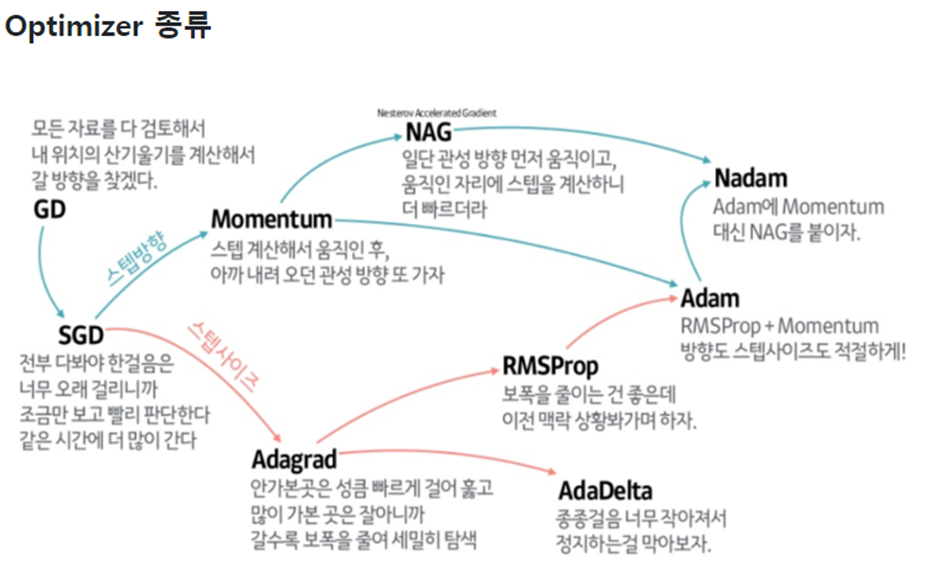
최근에 연구 실험을 진행을 하는데 이전까지는 Optimizer를 그저 gradient를 최적화 해주는 도구로써 여겼었다. 하지만 torch에 optimizer.load_state_dict()가 있어서 Optimizer에도 업데이트 되는 부분이 있는건가 싶어서 연구미팅에
3.Autograd
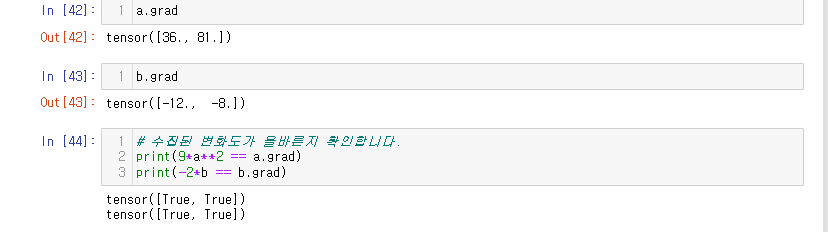
최근에 특정 layer층의 가중치를 Masking하는 방법에 대해서 알아보고 있던 도중에discussion을 확인하게 됐다. 이전에도 autograd가 gradient를 조정하는 역할을 하는 것을 알고는 있었는데, 정확히 알지는 못했기 때문에 이 기회에 정리해보고자 한
4.pytorch-lr-finder
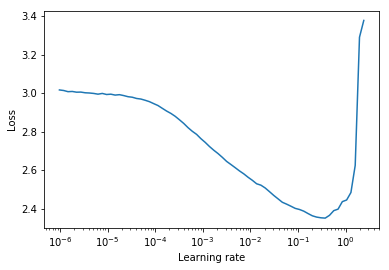
평소에 pytroch_forecasting Library를 쓰면 보통 pytorch_lightning과 결합하여서 써서, auto_lr_find를 이용해서 최적의 learning rate를 찾곤했다. 하지만 내가 직접 모델을 구현할때는 보통 pytorch_lightni
5.pytorch-forecasting SMAPE

최근에 다른 실험을 하던 도중에 결과가 내예상대로 안나오는 부분을 발견하고 코드를 유심히 살펴보았는데, 이전에 작성한 코드들에서도 똑같은 문제가 발생했을 거라는 생각이 들어서 해당 문법을 살펴본 결과 역시나 그랬다.. 이미 교수님께 결과 전송을 마치고 같이 분석도 한