최근에 연구 실험을 진행을 하는데 이전까지는 Optimizer를 그저 gradient를 최적화 해주는 도구로써 여겼었다. 하지만 torch에 optimizer.load_state_dict()가 있어서 Optimizer에도 업데이트 되는 부분이 있는건가 싶어서 연구미팅에서 교수님께 여쭤보니 Optimizer에 대해서 알아보면 좋을 것 같다는 말씀을 하셔서 이번기회에 알아보기로 했다.
Optimizer를 load하고 하지 않고에 따라 Transfer learning에서 성능차이가 생기는 것처럼 보여서 여쭤보게 된 실질적인 이유가 있다.
우선 이전에 미팅에서 Optimizer에 대해 언급했던 부분을 Recall 해보자.
일단 위에서 말한 Optimizer의 역할을 조금 더 자세히
Recall
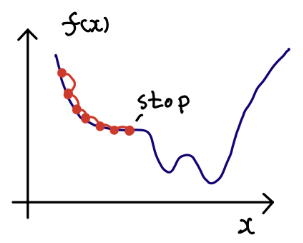
딥러닝 학습시 최대한 틀리지 않는 방향으로 학습해야 한다(->loss를 줄이는 방향으로)
이때 loss의 최솟값을 찾아가는 것을 최적화(Optimization)이라고 하고 이를 수행하는 알고리즘이
최적화 알고리즘(=Optimizer)라고 한다.
Optimizer의 종류는 다음과 같다
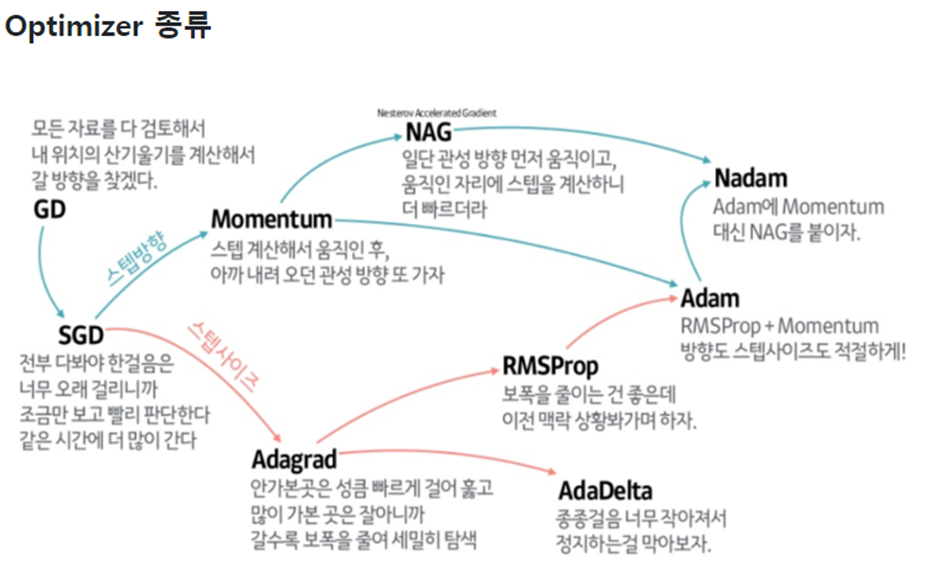
먼저 목표를 확실하게 하고 가겠다.
우리의 최종목표는 일반적으로 성능이 좋다고 여겨지고 빈번하게 사용하는 Adam이다.
이를 위해서 Momentum과 Adagrad RMSProp을 공부하고 마지막으로 Adam에 대해 서술할 것이다.
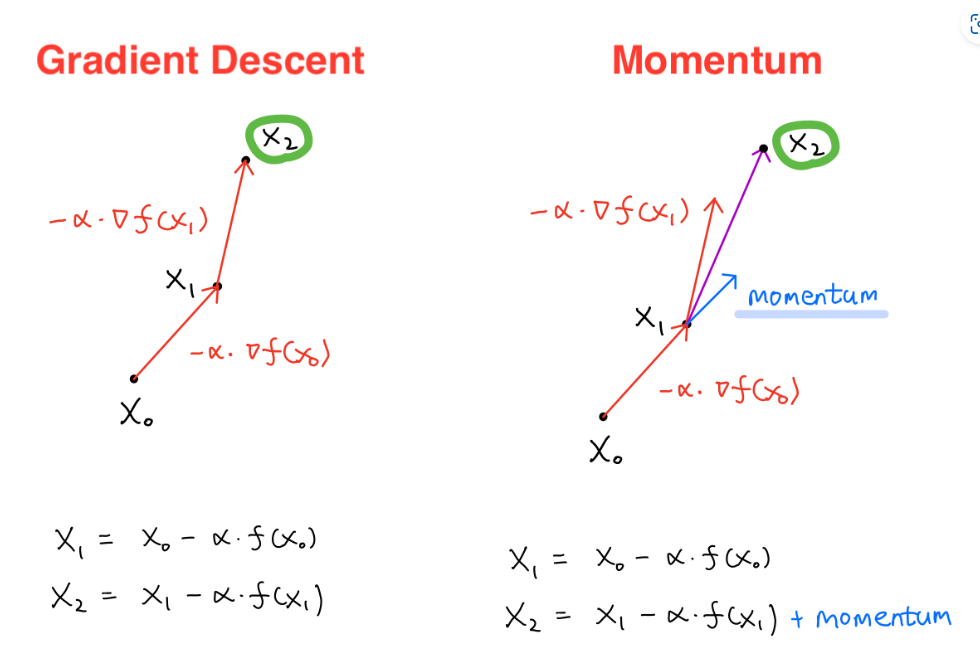
Momentum
Momentum은 물리의 관성개념을 Optimizer에 적용한 것이다. γ라는 Parameter를 사용해서
해당 step에서의 gradient에 이제까지(과거의) 모멘텀을 얼마나 반영할지 정해준다.
바로아래의 식을 정리하면 그 아래의 식이 나오게 된다.
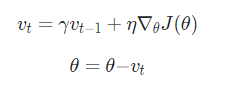
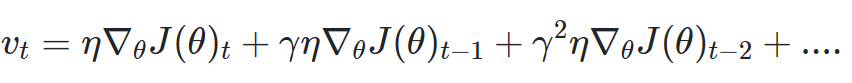
Momentum은 위와 같은 식으로 볼 수 있다.
혹시나 위의 식이 거북하고 읽기 싫은 사람들이 있을 것 같아 이야기를 해두는 건데
위는 시간 t에서의 목적함수의 미분 즉 gradient를 의미한다
η는 stepsize(=learning rate)라고 생각하면 된다.
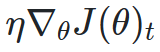
우리는 Momentum을 사용함으로써 기존에 SGD에서 속도가 0이되면 더이상 움직이지 않는 부분을 관성으로써 움직일 수 있게 됐다.
[출처] https://icim.nims.re.kr/post/easyMath/428
위와 같이 gradient에 learning_rate를 곱해서 더한후 momentum을 추가로 더해준다.
Pytorch torch.optim 패키지에 SGD의 momentum hyperparamer로써 구성할 수 있다.
→optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
Adagrad
Adagrad와 RMSProp 모두 결국에는 자동차의 브레이크를 어떻게 밟을 것인가에 대한 논의로 생각해보면 이해가 쉽다!
우리는 Learningrate Scheduler를 사용해서 학습을 시행함에 따라서 점점 Learning rate를 줄여서 최적값에 수렴할 수 있도록 할 수 있다.
우리가 하나 유념하고 있어야 하는 사실은 일반적인 gradient descent에 경우에는 모든 변수들이 업데이트 할때 gradient에 같은 학습률(Learning rate)이 곱해져서 업데이트 한다
Adagrad는 위의 scheduler에서 조금 더 발전한 형태로 "변수별로 적용된(Adaptive) 학습률"을 주는 방식이다.
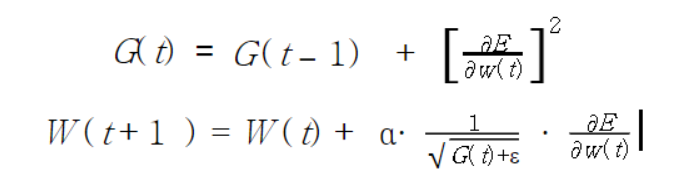
위의 식에서 보면 LossFunction을 E라고 표현했고 가 의미하는 것이 Gradient이다.
이때 알아야할것이 G와 W는 벡터로써 업데이트 되는 파라미터의 개수만큼 존재해야 업데이트를 할 수 있을것이다.
alpha는 Momentum에서 Eta의 역할을 하는 기준 Learning rate이다.
사실 구글링을 통해서 찾아보면 자주 변화한 변수들의 경우에는 Optimum에 가까이 있을 확률이 높기 때문에 작은 크기로 이동하면서 세밀한 값을 조정한다라고 돼있는데,이를 내 방식대로 이해하면 다음과 같다.
→ 위의 두식을 바라보면 시간이지날수록 값이 G(t)값이 커지는 구조인데 단, 여기서 G(t)는 벡터이므로 커지는 정도가 다를 것이다.
여전히 optimum과 거리가 있는 인자는 아직 커지는 정도가 클 것이고 optimum과 거리가 짧은 인자는 커지는 정도가 짧을것이다.
그러면 기준 learning rate인 alpha뒤에서 사실상의 Adaptive를 진행해주는 인자는 시간에 따라 작아지게 될 것인데 이것이 바로위의 이유에 의해 더 작게작아지냐 크게 작아지냐로 나뉠 것이다.
아직 optimum과 거리가 있는 인자의 경우에는 G(t)의 값이 비교적 작아서 크게크게 step을 밟게 할 것이고, 이미 충분히 학습을 한 인자는 G(t)의 값이 커서 세밀하게 step을 밟게 할 것이다.
이러한 방식을 통해서 우리는 weight마다 step을 다르게 밟게 할 수 있는 것이다.
RMSProp
자, 그렇다면 Adagrad는 시간이 극도로 많이 흐르게 되면 0으로 수렴한다는 문제가 생긴다. 따라서 학습이 더이상 진행되지 않는데, 이러한 문제점을 해결한 것이 바로 RMSProp이다.
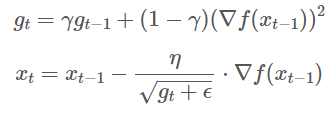
RMSProp은 이전까지의 LearningRate를 보정해주는 인자()와 이전의 gradient의 제곱을 가중평균을 해서 인자의 size를 조절한다.
이름 그림으로 이해하면 다음과 같다.
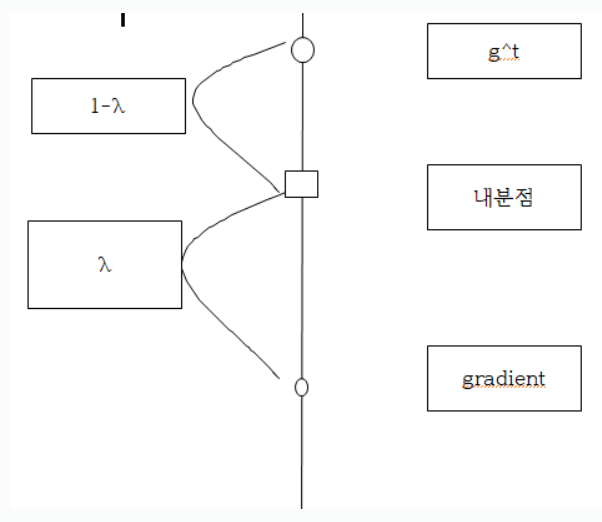
내분점을 사용함으로써 gradient와 g^t를 그냥 더하는 것을 조절해서 사용을 한다.
이렇게 사용함으로써 AdaGrad보다 학습을 더 오래함으로써 중간에 덜 최적화 되는 상황을 방지할 수 있다.
Adam
Adaptive Moment Estimation(Adam)은 딥러닝 최적화 기법으로 Momentum과 RMSProp의 장점을 결합한 알고리즘이다. 즉, 학습의 방향(Momentum)과 속도를 개선했다.

[출처]https://wikidocs.net/152765
위의 를 입실론이라고 생각할 수 있다.
분자에 있는 입실론을 로 생각할 수 있다.
Momentum은 에 γ를 계속해서 곱해서 합하는 것이 아닌 이전 Momentum과 를 가중평균하여서 RMSProp와 마찬가지의 논리로써 가중평균을 진행했다.
우리는 Momentum을 이용하고 가중평균을 통해서 방향을 "적절하게" 조절하고 RMSProp의 가중평균을 통해서 속도를 "적절하게" 조절한 것이다.
이전과 차이점은 가중치를 업데이트를 할때 Momentum Optimizer의 경우에는 gradient와 Momentum을 따로 더하고 RMSProp의 같은경우에는 Gradient를 적절하게 바꿔서 더했다면, Adam 같은 경우에는 gradient로 "적절히" 계산된 momentum을 "적절하게" 바꿔서 더한다. 이때 이 벡터로써 원소마다 다른값을 갖는다.
Pytorch Model에서 optimizer.load_state_dict()?
사실 이번 포스팅을 쓰게된 이유는 "Optimizer의 업데이트되는 부분이 무엇인가?"에서 부터 시작됐다.
우리는 Adam을 사용하였는데 Adam을 사용하는 이상 Parameter별로의 learningrate를 조절하는 인자와 momentum이 계속해서 변하게 된다. 따라서 optimizer의 state는 이러한 것들이 있을 것이다. 즉 learningrate를 조절하는 인자와 momentum이 인자로써 존재 할 것이다.
Transfer Learning은 Pre-training된 모델을 이용하는데 데이터가 달라진 것이기 때문에 결과적으로 Loss Function자체가 달라져있을 것이다. 최적화를 하는 과정 자체가 하나의 모델을 어떠한 데이터에 대해서 최적화 하는 과정으로 이해할 수 있기 때문에 우리는 새로운 Optimizer를 사용해야 할 것이라고 생각된다.
