본 내용은 Building Knowledge Graph chapter 6를 참고하였습니다.
그래프 알고리즘의 카테고리
1. Statistical (통계적)
그래프 노드, 관계의 수나, 관계의 차수, 노드 레이블 유형 등 그래프에 대한 지표.
2. Analytical (분석적)
전체 지식그래프나 하위 구성요소에서 나타나는 중요한 패턴이나 잠재적 지식을 다룸.
3. Machine Learning (기계 학습)
그래프 알고리즘의 결과를 ML 모델의 속성(feature)로 사용하는 방식, 또는 머신러닝을 통해 그래프 스스로 진화하도록 함.
대표적인 그래프 활용 사례
- Network Propagation (네트워크 전파) : 깊은 경로 계산을 통해 신호가 어떻게 그래프를 통해 전파되는지를 이해함. 중요한 경로를 찾아내고, 해당 경로의 안정성을 최적화 하거나 여분의 경로를 추가하는데 활용할 수 있음. e.g. 커뮤니티 내의 질병 확산 경로 분석, 공급망 약점 분석
- Influence (영향력 분석) : 영향력있는 노드에 대한 분석. 노드의 영향력 분석 방법으로는 중앙성(centrality) 분석이 있음. e.g. 소셜 미디어에서의 인플루언서 영향력 분석
- community detection (군집 탐지) : 그래프 알고리즘은 약한 연결고리들(상호간의 연결 링크가 많지 않고, 드문드문 보이는 연결관계)을 찾고, 이를 제거함으로써 그룹을 나누는 경향이 있음. e.g. 금융 사기 범죄 탐지, 병원체 탐지
- similarity (유사성) : 그래프에서 반복되는 유사한 패턴을 탐지. 노드간의 알려진 관계나 위계, 또는 공통 속성을 검색함. e.g. 구매이력 기반 상품 추천
- link prediction (링크 예측) : 지식 그래프의 형상, 그리고 휴리스틱하게 몇 개의 예시를 활용해 지식 그래프에서 누락된 간선을 예측하여 풍부하게 함. e.g. SNS 추천 친구
이러한 분석을 위해 WCC(Weakly Connected Components), Louvain 알고리즘 등 다양한 그래프 알고리즘을 적용할 수 있으며, 알고리즘에 따라 동일한 그래프에 대해 상이한 결과가 도출될 수 있음. 따라서 자신의 상황과 그래프의 특성을 고려해 다양한 알고리즘을 실험해보고, 가장 적합한 알고리즘을 선택하는 것이 중요함.
Neo4J Graph Data Science
Neo4j Graph Data Science는 Neo4J 그래프 데이터베이스에서 그래프 알고리즘을 적용시켜볼 수 있도록 하는 플러그인이다. Neo4J Graph Data Science는 CPU와 RAM 에 최적화 되어 있으며, GPU 기반의 솔루션들을 상회하는 성능을 가졌다고 한다.
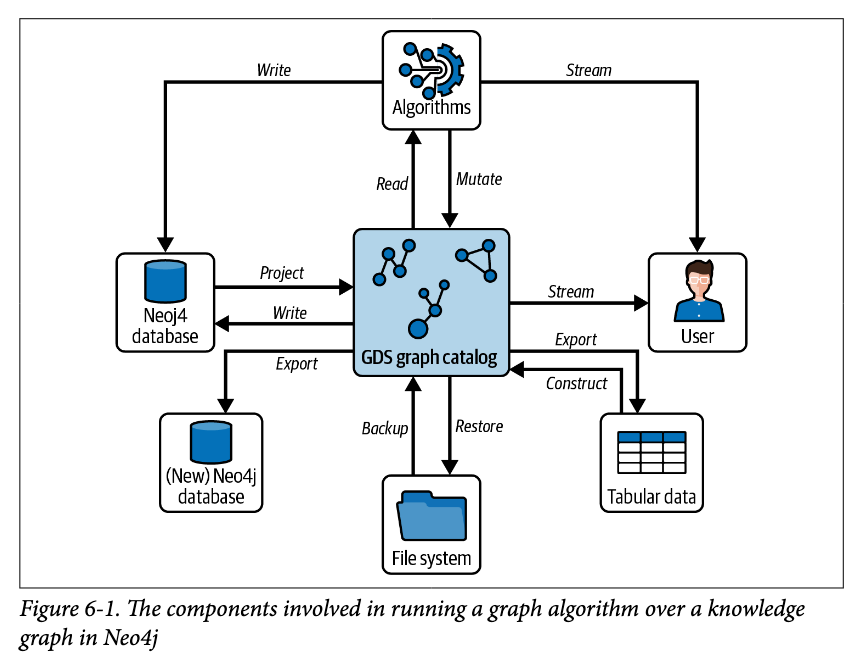
위 그림은 Neo4j GDS가 실제로 Neo4J 데이터베이스에 그래프 알고리즘을 동작시키는 모습을 나타낸 그림이다. 다음의 4가지 단계에 거쳐 그래프 알고리즘이 실행된다.
- Read Projected Graph : 그래프에서 그래프 알고리즘을 적용하고자 하는 부분을 선택하여 프로젝션(projection)을 만든다.
- Load Projected Graph : 프로젝션 된 그래프를 병렬 처리에 적합하도록 인메모리 형식으로 로드해온다.
- Execute Algorithm : 선택한 매개변수로 알고리즘을 실행시킨다.
- Store Result : 계산된 결과를 지식그래프에 다시 저장할 수 있고. downstream system으로 전달하거나 유저에게 전달할 수 있다.
Graph Data Science는 APOC 플러그인과 같은 방식으로 설치할 수 있다.
Graph Data Science 사용해보기
실습을 위한 데이터는 여기에서 다운받을 수 있다.
실습에 앞서, 실습에 필요한 데이터를 그래프로 불러와야 한다. gds.run_cypher()로 neo4j 그래프 데이터 베이스에 직접 질의할 수 있다.
step 1. 역 정보 로드하기
우선 영국의 역에 대한 데이터nr-stations-all.csv 를 불러오고, 이를 Station 노드로 정의한다.
# 데이터베이스 연결하기
host = "bolt://127.0.0.1:7687"
user = "neo4j"
password= "yolo"
# gds object 정의
gds = GraphDataScience(host, auth=(user, password), database="neo4j")
# Load stations as nodes
gds.run_cypher( """
LOAD CSV WITH HEADERS FROM "nr-stations-all.csv" AS station
CREATE (:Station {name: station.name, crs: station.crs})
""" )
그 다음, 역별 연결(트랙) 정보에 대한 데이터 nr-station-links.csv를 불러온다. track의 거리 정보는 :TRACK 레이블의 distance 속성으로 부여한다.
# 역 간의 연결 정보를 TRACK 레이블 간선으로 불러오기
gds.run_cypher( """
LOAD CSV WITH HEADERS FROM "nr-station-links.csv" AS track
MATCH (from:Station {crs: track.from})
MATCH (to:Station {crs: track.to})
MERGE (from)-[:TRACK {distance: round( toFloat(track.distance), 2 )}]->(to)
""" )
gds.close()
step 2. projection 생성하기
지금부터 그래프 알고리즘을 이용해 해결할 문제는 두 역 간의 최단 거리를 구하는 것이다. 그 전에, 그래프 알고리즘 연산에 적합하도록 도메인 인메모리 그래프를 생성하도록 프로젝션을 생성한다. 프로젝션 된 그래프는 형태적으로 원 그래프와 동일하지만, 이름과 거리 값만이 속성으로 들어가게 된다. (이 예시에서는 노드와 엣지가 갖는 속성이 한 개 뿐이므로 사실상 프로젝션 된 그래프가 원본 그래프와 동일하다.)
프로젝션 그래프를 생성할 때는 gds.graph.project.cypher() 메서드를 사용하며, 매개변수로 프로젝트 그래프의 이름과 노드 스펙, 관계 스펙에 대한 cypher 쿼리를 전달한다.
host = "bolt://127.0.0.1:7687"
user = "neo4j"
password= "yolo"
gds = GraphDataScience(host, auth=(user, password), database="neo4j")
gds.graph.project.cypher(
graph_name='trains',
node_spec='MATCH (s:Station) RETURN id(s) AS id',
relationship_spec= """
MATCH (s1:Station)-[t:TRACK]->(s2:Station)
RETURN id(s1) AS source, id(s2) AS target, t.distance AS distance
""" )
gds.close()step 3. 다익스트라 알고리즘 적용해서 최단 거리 탐색
다익스트라 알고리즘을 사용해, Birmingham New Street 역과 Edinburgh역 사이의 최단 거리를 구해보도록 하겠다. gds.shortestPath.dijkstra.stream으로 다익스트라 알고리즘을 사용해볼 수 있다. 매개변수로는 프로젝트 그래프와 소스 노드 ID(SourceNode), 타겟 노드 ID(TargetNode), 그리고 가중치로 적용할 속성 명칭(relationshipWeightProperty)을 전달한다.
host = "bolt://127.0.0.1:7687"
user = "neo4j"
password= "yolo"
gds = GraphDataScience(host, auth=(user, password), database="neo4j")
# Brimingham New Street 노드와 Edinburgh 노드 ID 변수에 정의하기
bham = gds.find_node_id(["Station"], {"name": "Birmingham New Street"})
eboro = gds.find_node_id(["Station"], {"name": "Edinburgh"})
# 최단거리 탐색
shortest_path = gds.shortestPath.dijkstra.stream(
gds.graph.get("trains"),
sourceNode=bham,
targetNode=eboro,
relationshipWeightProperty="distance" )
# 결과 출력
print("Shortest distance: %s" % shortest_path.get('costs').get(0)[-1])
gds.close()
프린트 된 결과는 Shortest distance: 298.0.일 것이다. 실제로, 어떤 경로를 그래프 상에서 갖는지 확인하고자 한다면 Neo4J 브라우저/데스크탑 쿼리 창에 다음의 쿼리를 입력하면 된다.
step 4. 노드의 중심성 분석하기
이번에는 영국에 있는 모든 역의 중심성에 대해 분석한다. 중심성(Centrality)란 그래프에서 노드가 갖는 중요도에 대해 나타내며, 근접중심성, 매개중심성, 고유 벡터 중심성 등의 지표가 있다. 여기서는 매개중심성을 기준으로 분석하도록 한다. 매개중심성은 노드가 얼마나 자주 다른 노드들이 중간 노드가 되는지를 기준으로 중심성을 평가한다.
gds = GraphDataScience(host, auth=(user, password), database="neo4j")
# 프로젝트 그래프 가져오기
graph = gds.graph.get("trains")
# 매개중심성 구하기
result = gds.betweenness.stream(graph)
# 가장 높은 매개중심성을 갖는 노드의 ID 가저오기
highest_score = result.sort_values(by="score", ascending=False).iloc[0:1].get('nodeId')
# 가장 높은 매개중심성을 갖는 노드의 이름과 중심성 가져오기
n = gds.run_cypher(f"MATCH (s:Station) WHERE ID(s) = {int(highest_score)} RETURN s.name")
print("Station with highest centrality: %s" % n["s.name"][0])
gds.close()알고리즘을 실행시키면 Tamworth라는 역의 매개중심성이 가장 높게 나타나는 것을 확인할 수 있다.
매개중심성은 오직 노드가 다른 두 노드가 연결될 때 얼마나 그 노드를 자주 지나는지에 대한 값이므로, 엣지에 가중치가 있는 경우 이를 고려할 수 없다는 한계가 있다.
step 6. 계산된 결과를 반영하기
stream을 mutate으로 바꾼다면, 프로젝션된 그래프에 결과를 반영시켜, 다른 분석을 할 때 해당 이전에 분석한 값을 이용할 수 있다. write를 사용하면 지식그래프에 결과를 반영시킬 수 있다.
gds = GraphDataScience(host, auth=(user, password), database="neo4j")
graph = gds.graph.get("trains")
# 계산된 매개중심성을 betweness 속성으로 부여하기
result = gds.betweenness.write(gds.graph.get("trains"), writeProperty="betweenness" )
total_stations = gds.run_cypher("MATCH (s:Station) RETURN count(s) AS total_stations")
print(f'Total number of stations: {total_stations.iloc[0][0]}')
# 매개중심성이 계산되어 반영된 노드의 개수
processed_stations = gds.run_cypher( """
MATCH (s:Station) WHERE s.betweenness IS NOT NULL
RETURN count(s) AS stations_processed """)
print(f'Number of stations with betweenness score: {processed_stations.iloc[0][0]}')
gds.close()
