본 내용은 Building Knowledge Graph - chapter 7을 참고하여 작성됐습니다.
그래프와 머신러닝을 통합하는 2가지 방법이 있다.
1. in-graph machine learning
지식그래프가 시간에 따라 어떻게 발전할 것인지 예측.
2. graph feature engineering
고품질의 외부 예측 모델을 만들기 위해 지식그래프로부터 feature를 추출.
ML모델과 지식그래프를 동시에 활용하는 경우, 대부분의 시스템에서는 모델과 그래프 사이의 피드백 루프가 구현되어 있다.
Topological Machine Learning
in-graph machine learning 방식은 대체로 그래프 내부에서 스스로에 대한 계산이 진행되고, 이를 바탕으로 그래프를 더욱 풍부하게 하는 기술들로, 대체로 누락된 관계를 추가하거나, 노드에 레이블을 붙이거나, 속성값을 추가하는 프로세스가 진행된다. 이러한 예측을 위해 그래프의 위상적 성질(Topology)과 데이터가 사용된다.
👩🏫 example : 링크 출현 우도 계산하기
예제 실습에 앞서, 영화 지식그래프 데이터베이스를 준비한다. neo4j에 빌트인된 데이터를 활용한다. 새로운 인스턴스를 만들고 시작하는 것을 추천한다.
neo4j desktop을 이용할 경우, 쿼리 창에서 movie graph db를 사용해 볼 수 있도록 뜰 것이다.
클릭하면 좌측에 가이드같은 화면이 뜰 것인데, 여기서 가장 첫번째 사이퍼 쿼리문을 실행시켜주면 된다. Neo4j 브라우저를 사용하는 경우 :play movie graph를 쿼리 창에 입력하면 된다.
준비가 되었으면 다음 쿼리를 입력해서 'Keanu Reeves' 노드를 중심으로 하는 서브그래프를 확인해보자. 아래의 쿼리문은 키아누리브스가 나온 영화의 감독, 그리고 그 영화에 출연한 다른 배우들을 보여주는 쿼리이다.
MATCH (person:Person {name: 'Keanu Reeves'})
MATCH path = (person)-[:ACTED_IN]->(m)<-[:DIRECTED]-(d), (m)<-[:ACTED_IN]-(a)
RETURN path;쿼리를 실행하면 아래와 같은 그래프를 확인할 수 있다.
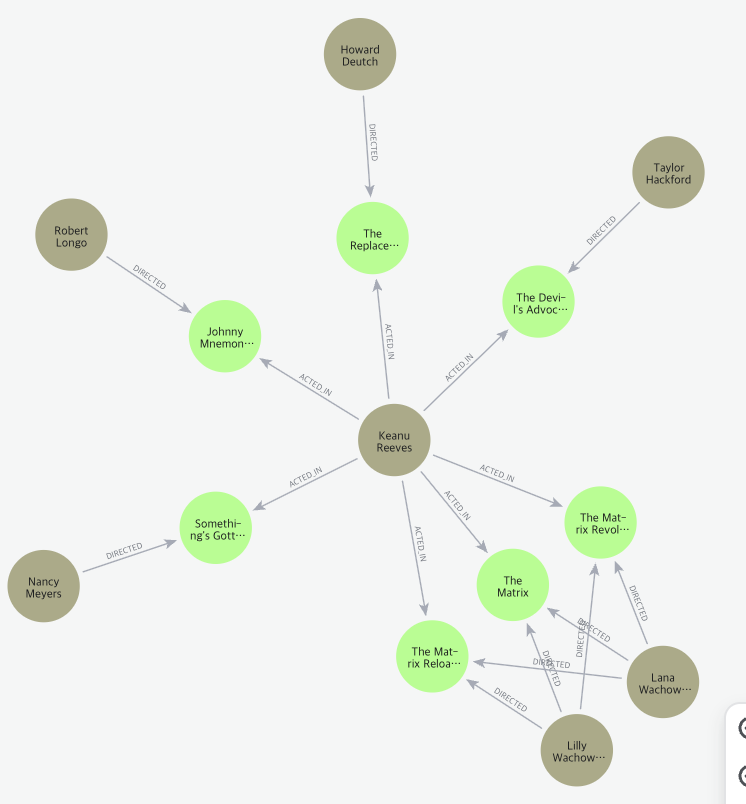
예제를 직접 실험해보기 위해, 키아누리브스가 'The Matrix'라는 영화에 출연하였다는 관계를 삭제한다.
MATCH (:Person {name:'Keanu Reeves'})-[r:ACTED_IN]->(:Movie {title:'The Matrix'})
DELETE r키아누 리브스가 매트릭스에 출연했다는 사실을 몰라도, 직감적으로 그가 릴리 와쇼스키, 루나 와쇼스키가 감독한 다른 두 편의 매트릭스에 출연하였다는 사실을 기반으로 하여 'The Matrix'에도 출연하였을 가능성이 매우 높을 것이라고 쉽게 예측할 수 있다.
이번에는 실제로 키아누 리브스 노드가 'the Matrix'와 ACTED_IN 관계로 연결될 우도(Liklihood)를 계산해보겠다.
MATCH (Keanu:Person {name:'Keanu Reeves'})
MATCH (TheMatrix:Movie {title:'The Matrix'})
RETURN gds.alpha.linkprediction.preferentialAttachment (Keanu,
TheMatrix,
{relationshipQuery: "ACTED_IN"}) AS score계산 결과 24.0이라는 수치를 얻을 수 있다. 우도는 관계가 존재할 수 있다는 것을 나타내는 하나의 지표가 될 수는 있지만, 우도만으로 그 관계가 존재할 것이라는 것을 확정하기는 어렵다.
머신러닝 파이프라인 훈련
링크 예측을 위한 머신러닝 파이프라인은 다음의 9가지 과정으로 구성된다.
- 기반 지식그래프로부터 프로젝션된 그래프 생성
- 파이프라인 선언
- 프로젝션 그래프의 노드에 그래프 알고리즘을 활용해 관계 정보를 기반으로 계산된 속성값 부여
- 노드 쌍에 대한 feature vector를 생성하기 위해 combiner를 사용하여 이전 단계에 계산된 노드 속성값을 계산하여 한 개 이상의 링크 속성값 생성.
- 그래프를 서로 겹치지 않는 훈련, 테스트, 속성 세트로 분리
- 로지스틱 회귀와 같은 모델 후보 추가
- 선택적으로 훈련 과정에서의 계산 요구량(메모리)에 대한 평가 진행
- 모델 훈련과 평가 반복
- 모델이 평가 지표 충족 시 프로덕션 환경에 배포
Neo4J에는 위의 과정들을 쉽게 진행시킬 수 있는 빌트인 기능이 존재하므로, 쉽게 머신러닝 파이프라인을 구현할 수 있다.
👩💻 실습 : Recommanding Complementary Actors
1. 데이터 정리하기 (data wranggling)
기존의 영화 그래프를 가져와서 배우들이 같은 영화에 출연한 곳을 매치한다. 그 다음 같은 영화에 출연했던 각 배우 쌍을 ACTED_WITH 관계로 연결한다. 이때 방향은 중요하게 보지 않아도 된다.
MATCH (a:Person)-[:ACTED_IN]->(:Movie)<-[:ACTED_IN]-(b:Person)
MERGE (a)-[:ACTED_WITH]->(b)아래의 쿼리를 입력하여ACTED_WITH 관계를 갖는 노드를 확인하면
MATCH path = (a:Person)-[:ACTED_WITH]->(b:Person)
RETURN path다음과 같은 그래프를 볼 수 있다.
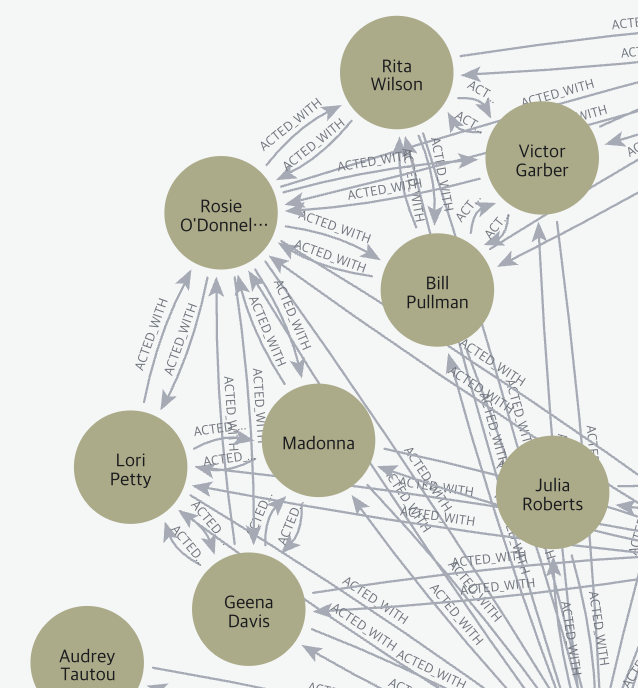
2. projection graph 생성하기
이제 GDS에서 활용할 프로젝션 그래프를 생성한다. 프로젝션된 그래프의 이름(actors-graph)을 전달하고,포함될 노드의 레이블(Person)과 해당 노드의 속성도 제공한다. 이 예제에서는 속성이 비어있으므로 {}으로 제공한다.마지막으로, 관계의 이름(ACTED_WITH)과 방향성(UNDIRECTED)을 전달한다.
CALL gds.graph.project( 'actors-graph',
{ Person: {} },
{ ACTED_WITH: { orientation: 'UNDIRECTED' } }
)3. pipeline 생성하기
이제 머신러닝 파이프라인을 생성한다. 아래의 쿼리만 입력하면 된다.
CALL gds.beta.pipeline.linkPrediction.create('actors-pipeline')4. 그래프 알고리즘으로 훈련시킬 node property 선택하기
여기서는 노드의 local topology를 숫자로 임베딩하는 그래프 알고리즘을 이용한다. GDS는 Node2Vec이나 FastRP 와 같이 노드 임베딩에 활용할 수 있는 알고리즘을 제공한다. 아래의 쿼리는 프로젝션의 각 노드에 embedding이라는 노드 속성을 계산하기 위해 FastRP 알고리즘을 구성하는 방법을 보여준다.
CALL gds.beta.pipeline.linkPrediction.addNodeProperty(
'actors-pipeline', // 프로젝션 이름
'fastRP', // 알고리즘명
// 알고리즘 수행 결과를 저장할 속성 명칭과 임베딩 차원 수, 랜덤 시드
{
mutateProperty: 'embedding',
embeddingDimension: 256,
randomSeed: 42
}
)파이프라인이 실행될 때, 각 노드의 embedding 속성은 그래프 위상에서 노드의 위치에 대한 숫자 인코딩으로 보강된다.
5. link feature를 처리하는 파이프라인 부분 구성하기
이제 노드의 embedding 속성을 바탕으로 링크의 속성을 갱신하는 부분을 구성한다. 링크 특성(link feature)는 쌍을 연결하는 단일 특성으로, topological ML에 필수적이며, 링크 특성(link feature) 단계는 파이프라인이 실행되는 훈련 시간과 모델이 예측을 수행하는 프로덕션에서 모두 실행된다.
특징 단계(feature step)는 addFeature 프로시저를 사용하는데, 이때 파이프라인의 이름과 노드 쌍을 결합해야 하는지를 결정하기 위한 알고리즘의 이름을 매개변수로 전달해야 한다. 여기서는 알고리즘으로 코사인 유사도를 적용한다. 각 노드의 embedding 속성 벡터를 사용해 코사인 유사도를 계산하고, 두 벡터의 유사도가 충분히 높으면 두 노드가 연결되었다고 판단한다. 코사인 유사도 외에 아다마르 곱과 L2 Norm을 사용할 수도 있지만, cosine 유사도가 가장 성능이 좋았다고 한다.
CALL gds.beta.pipeline.linkPrediction.addFeature(
'actors-pipeline',
'cosine',
{ nodeProperties: ['embedding'] }
)
YIELD featureSteps6. 학습데이터와 훈련데이터 분할하기
학습 데이터를 생성하기 위해서는 긍정 답(정답), 부정 답(오류)를 임의로 넣어줘야 한다. gds에서는 이를 자동으로 부여하는 기능이 있으며, 사용자는 정답과 오답의 비율만 설정하면 되며, 설정하지 않을 경우 기본값으로 세팅된다.
CALL gds.beta.pipeline.linkPrediction.configureSplit(
'actors-pipeline',
{
testFraction: 0.25,
trainFraction: 0.6,
validationFolds: 3
})7. 모델 후보군 추가하기
이제 학습시킬 모델을 추가한다. 추가할 모델은 Logistic Regression, Random Forest, 다층 퍼셉트론이다. 아래의 쿼리는 로지스틱 회귀 모델을 추가하는 구문이다.
CALL gds.beta.pipeline.linkPrediction.addLogisticRegression('actors-pipeline')모델이 등록되었으면, 학습을 위해 모델을 자동조정을 위해 준비시킨다. gds.alpha.pipeline.linkPrediction.configureAutoTuning()는 학습시킬 파이프라인의 이름과, 자동조정을 위해 시도할 최대 횟수를 적용한다.
CALL gds.alpha.pipeline.linkPrediction.configureAutoTuning(actorspipeline, {maxTrials: 100})8. 학습을 위한 메모리 리소스 확인하기
학습시킬 데이터가 많고, 모델 규모가 클 경우 메모리 자원이 매우 많이 요구된다. 따라서, 학습 이전에 학습에 필요한 메모리 리소스를 확인하는 과정이 필수적이다.
CALL gds.beta.pipeline.linkPrediction.train.estimate('actors-graph',
{ pipeline: 'actors-pipeline',
modelName: 'actors-model',
targetRelationshipType: 'ACTED_WITH' })
YIELD requiredMemory9. 모델 학습시키기
8단계에서 제공한 구성으로 파이프라인을 인스턴스화하고, 훈련 단계를 실행하여 actors-model이라는 모델을 출력한다. 또한 훈련 단계에 대한 몇 가지 메트릭을 생성하여 모델의 품질에 대해 추론하는 데 사용할 수 있도록 한다. 여기서는 "AUCPR" 을 사용한다.
CALL gds.beta.pipeline.linkPrediction.train('actors-graph',
{ pipeline: 'actors-pipeline',
modelName: 'actors-model',
metrics: ['AUCPR'],
targetRelationshipType:
'ACTED_WITH',
randomSeed: 73 })
YIELD modelInfo, modelSelectionStats
RETURN modelInfo.bestParameters AS winningModel,
modelInfo.metrics.AUCPR.train.avg AS avgTrainScore,
modelInfo.metrics.AUCPR.outerTrain AS outerTrainScore,
modelInfo.metrics.AUCPR.test AS testScore,
[cand IN modelSelectionStats.modelCandidates | cand.metrics.AUCPR.validation.avg] AS validationScores
그러면 결과로 이러한 테이블을 확인할 수 있을 것이다.
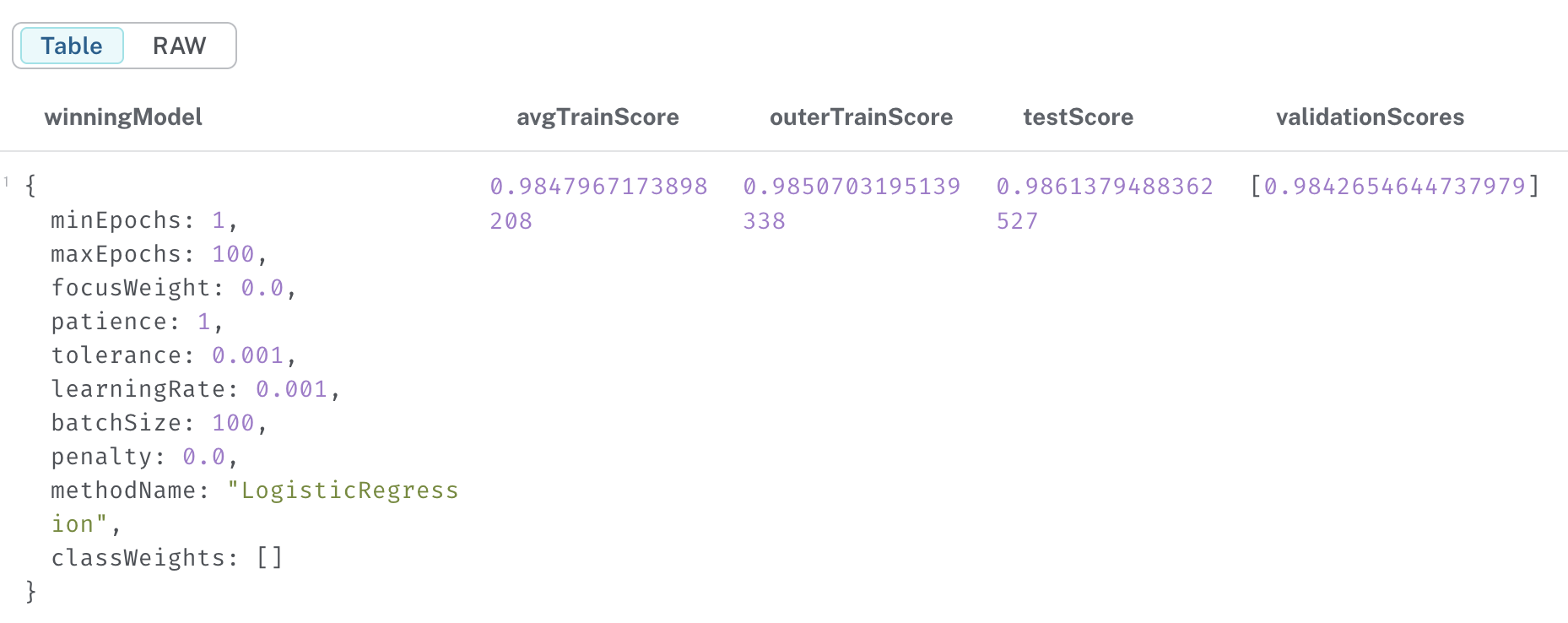
이렇게 훈련된 모델은 다른 그래프에서의 예측에서 사용가능하다.
10. 모델 사용해보기
모델을 실행시킬 때의 입력값은 그래프 프로젝션이다. 아래의 쿼리는 actors-input-graph-for-prediction는 모델에 입력될 그래프로, 원본 그래프와 동일한 그래프이나 몇 개의 합성 배우를 추가하거나 몇 개의 ACTED_IN 관계를 삭제하는 변형을 주도록 한다.
CALL gds.graph.project(
'actors-input-graph-for-prediction',
{ Person: {} },
{ ACTED_WITH: { orientation: 'UNDIRECTED' } } )아래의 쿼리는 프로젝션된 그래프를 모델에 입력하고, 예측 결과를 다시 프로젝션 그래프에 저장하도록 한다. 프로젝션 그래프의 이름, 그리고 모델의 명칭(actors-input-graph-for-prediction)과 예측할 관계(ACTED_WITH), 그리고 예측한 관계를 저장할 속성명(SHOULD_ACTED_WITH), 추천 세트의 개수 (topN), 그리고 추천 세트를 페기할 임계점(threshold)를 전달한다.
CALL gds.beta.pipeline.linkPrediction.predict.mutate( 'actors-input-graph-for-prediction',
{ modelName: 'actors-model',
relationshipTypes: ['ACTED_WITH'], mutateRelationshipType: 'SHOULD_ACT_WITH',
topN: 20,
threshold: 0.4 })
YIELD relationshipsWritten, samplingStats
위의 쿼리를 실행시키면 프로젝션된 그래프에는 SHOULD_ACTED_WITH가 존재하지만, 원본 그래프에는 존재하지 않는다. 원본그래프에도 결과를 반영하는 쿼리는 아래와 같다. 프로젝션 그래프에서 stream 된 SHOULD_ACT_WITH 를 갖는 노드 쌍의 ID를 추출하고, 이 ID로 하여금 SHOULD_ACT_WITH 관계를 다시 원 그래프에 merge 시킨다.
CALL gds.beta.graph.relationships.stream( 'actors-input-graph-for-prediction', ['SHOULD_ACT_WITH'] )
YIELD sourceNodeId, targetNodeId
WITH gds.util.asNode(sourceNodeId) AS source,
gds.util.asNode(targetNodeId) AS target
// 그래프 병합
MERGE(source)-[:SHOULD_ACT_WITH]->(target)11. 지식그래프 데이터 정리하기 (선택)
SHOULD_ACT_WITH 관계는 대칭성이 있어, 두 개의 관계를 배우(actors) 사이에 가질 필요가 없다. 즉, [:SHOULD_ACT_WITH]는(a)-[:SHOULD_ACT_WITH]->(b)면 충분하며, 역관계인 (b)-[:SHOULD_ACT_WITH]->(a)가 필요하지는 않다. 아래의 쿼리는 쌍방의 관계를 갖는 부분을 삭제한다.
MATCH (a:Person)-[:SHOULD_ACT_WITH]->(b:Person)-[d:SHOULD_ACT_WITH]->(a)
WHERE id(a) > id(b)
DELETE d12. 확인하기
이제 Cypher 쿼리만으로 추천 세트를 검색하는 데 필요한 모든 것이 준비됐다. 아래의 쿼리는 예측 모델을 그래프에서 실행하여 생성된 SHOULD_ACT_WITH 관계로 연결된 사람들을 찾아 해당 사람들의 이름을 반환한다.
MATCH (a:Person)-[:SHOULD_ACT_WITH]->(b:Person)
RETURN a.name, b.name쿼리를 실행하면 아래와 같은 테이블을 확인할 수 있다.
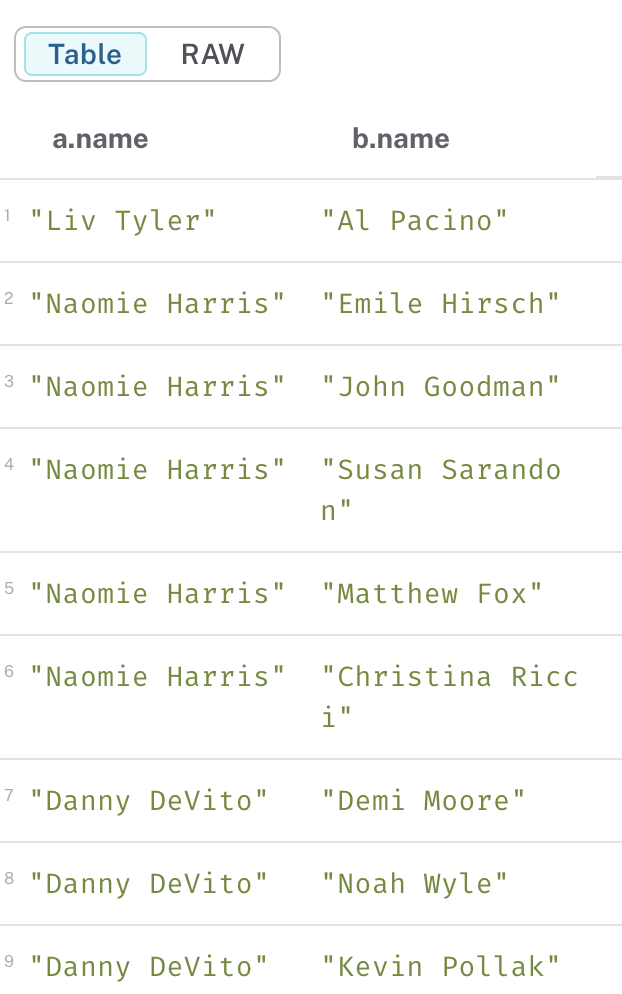
데이터가 갱신됨에 따라, 이 과정들은 주기적으로 반복되어야 한다. 또한 실제로는 모델의 매개변수를 최적화하는 데 더 많은 시간을 보내야 한다. 자동 ML이 도움을 줄 수 있지만, 인공 지능을 부트스트랩하는 데는 여전히 인간의 지능이 필요하다.
그래프 내 ML 파이프라인의 범위가 neo4j GDS가 제공하는 것만으로 충분하지 않은 경우, TensorFlow, PyTorch, scikit-learn, Google의 Vertex AI, Amazon SageMaker, Microsoft의 Azure Machine Learning과 같은 클라우드 호스팅 시스템을 사용할 수도 있으며, 이때 입력될 수 있는 값은 지식 그래프에서 추출된 특성 벡터 집합이다.
