본 내용은 Building Knowledge graph - chapter 9 의 내용에 기반합니다.
시작에 앞서, 이 링크에 들어가서 ds1.csv, ds2.csv, ds3.csv 파일을 다운받아 준다. 인스턴스도 새로 생성하여 진행하면 좋다. 다운받은 파일은 인스턴스의 로컬 경로 > import 폴더에 저장한다.
이름으로 동일 엔티티 식별하기
Step1. 데이터를 지식그래프로 모델링하여 Graph DB에 저장
고객 정보를 담은 세 개의 데이터를 그래프로 저장하기 위해, 각 데이터의 행을Person 노드에, 그리고 각 열의 값은 노드의 속성값을 반영하도록 지식그래프를 모델링한다. 각 컬럼의 명칭을 보면 나이, 생일, 출생 연도 등 유사한 컬럼을 갖는 경우가 있는데, 우선 이 경우도 그대로 그래프 속성으로 반영한다.
우선 먼저 csv 파일을 읽어온다. 각 행을 속성값으로 그대로 반영할 수 있도록, p += properties(row);를 입력한다.
LOAD CSV WITH HEADERS FROM "file:///ds1.csv" AS row
CREATE (p:Person) set p.source = "ds1", p += properties(row) ;
LOAD CSV WITH HEADERS FROM "file:///ds2.csv" AS row
CREATE (p:Person) set p.source = "ds2", p += properties(row) ;
LOAD CSV WITH HEADERS FROM "file:///ds3.csv" AS row
CREATE (p:Person) set p.source = "ds3", p += properties(row) ;Step 2. 엔티티 매칭하기
ds1이 출처인 노드는 생년(yob;Year Of Birth)정보를, ds2 출처 데이터는 나이 정보(age)를, ds3 출처 데이터는 생일(dob; Date Of Birth)를 갖고 있을 것이다. 각각의 소스에 1980년 5월 12일생인 michael이 존재한다면, 각 노드에 존재하는 Michael이 한 엔티티로 매칭 될 수 있도록 하는 과정이 필요하다.
MATCH (p1:Person), (p2:Person)
WHERE p1.source <> p2.source
AND (p1.ssn = p2.ssn OR p1.passport_no = p2.passport_no)
AND id(p1) > id(p2)
CREATE (p1)-[:SAME_AS { ssn_match : p1.ssn = p2.ssn, passport_match : p1.passport_no = p2.passport_no}]->(p2)Step3. 이름의 유사도 계산하기
하지만, 이름이 일치한다고 해서 두 사람이 반드시 일치한다고 할 수 없으므로, 우선은 보조 식별자로 처리하고, Jaro-Winkler 유사도 거리가 0.2 미만일 때만 관계가 생성되도록 한다. 아래의 쿼리는 두 노드의 소스가 다르고, ID 값이 다를 경우에 한하여, Jaro-Winkler 거리가 0.2 미만인 경우에 SIMILAR 관계를 부여하도록 한다. 이때 관계의 속성값은 1-유사도 거리로 부여한다.
MATCH (p1:Person), (p2:Person)
WHERE NOT (p1)-[:SAME_AS]-(p2)
AND p1.source <> p2.source
AND id(p1) > id(p2)
AND apoc.text.jaroWinklerDistance(p1.m_fullname, p2.m_fullname) < 0.2
CREATE (p1)-[:SIMILAR { sim_score : 1-apoc.text.jaroWinklerDistance(p1.m_fullname, p2.m_fullname)}]->(p2)이제 SIMILAR 관계의 속성값을 바탕으로 높은 유사도를 갖는 이름을 필터링한다. 그 전에, 사회보장번호가 다르거나, 여권 번호가 다른 경우에 대해서는 미리 삭제해준다.
MATCH (p1:Person)-[sim:SIMILAR]->(p2:Person)
WHERE p1.ssn <> p2.ssn OR p1.passport_no <> p2.passport_no
DELETE simStep 4. SIMILAR 관계에 가중치 부여하기
출생 연도가 동일한 경우에 대해서는 SIMILAR 관계의 속성값에 가중치를 부여한다. 반대로, 다른 경우에 대해서는 유사도 값을 줄이도록 한다.
threshold 값은 :param yob_threshold => 5;로 설정하고 아래의 쿼리를 입력한다.
MATCH (p1:Person)-[sim:SIMILAR]->(p2:Person)
WITH sim, abs(p1.m_yob - p2.m_yob) AS yob_diff SET sim.sim_score = sim.sim_score * CASE WHEN yob_diff > $yob_threshold THEN .9 ELSE 1.1 ENDStep 5. 속성값으로 필터링하기
필터링할 threshold를 :param sim_score_threshold => .95로 설정한다. 그 다음 아래의 쿼리를 입력해 임계치에 미치지 못하는 관계를 삭제한다.
MATCH (p1:Person)-[sim:SIMILAR]->(p2:Person)
WHERE sim.sim_score < $sim_score_threshold
DELETE simMaster Entity 빌드/업데이트
위의 단계를 거쳐 이제 유사하거나, 동일한 엔티티 노드에 대해서 관계를 생성하였다. 마지막 단계는 Master Entity에 대한 영속적인 표현을 생성하는 것이다. 그러기 위해서는, SAME_AS나 SIMILAR 관계로 연결된 노드의 집합을 식별해야 한다. 그래프의 집합을 감지하기 위해서, Weakly Connected Components(WCC) 알고리즘을 적용한다.
Step 1. 알고리즘 적용을 위한 프로젝션 생성
알고리즘을 적용할 프로젝션 그래프를 생성한다. 프로젝션 그래프는 GDS 카탈로그에 'identity-wcc'로 저장될 것이다.
CALL gds.graph.project(
'identity-wcc',
'Person',
['SAME_AS','SIMILAR'] )Step 2. WCC 알고리즘으로 노드 그룹 식별
WCC 알고리즘을 stream 모드로 실행시켜준다. 식별된 그룹의 각 노드에는 그룹에 대한 ID인 golden_id 속성을 부여한다.
CALL gds.wcc.stream('identity-wcc')
YIELD nodeId, componentId
WITH gds.util.asNode(nodeId) AS person, componentId AS golden_id
RETURN golden_id, person.m_fullname, person.passport_no, person.ssn
ORDER BY golden_id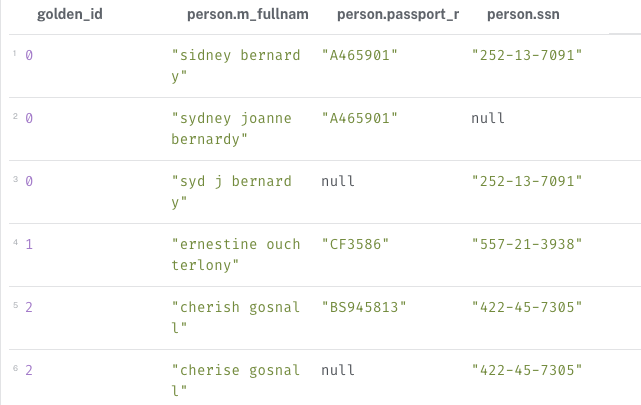
그러면 이렇게 동일하다고 식별되는 엔티티 노드 그룹들에 대해 아이디가 부여된 것을 확인할 수 있다. 이 노드는 :HAS_REFERENCE 관계로 Person 노드와 연결된다.
Step 3. 마스터 엔티티 노드 생성
이제 식별된 golden_id를 갖는 마스터 엔티티 노드(golden record)를 생성한다. 마스터 엔티티 노드의 레이블은 PersonMaster로 부여한다.
CALL gds.wcc.stream('identity-wcc')
YIELD nodeId, componentId WITH gds.util.asNode(nodeId) AS person, componentId AS golden_id
MERGE (pg:PersonMaster { uid: golden_id })
ON CREATE SET pg.fullname = person.m_fullname,
pg.ssn = person.ssn,
pg.passport_no = person.passport_no
ON MATCH SET pg.ssn = coalesce(pg.ssn,person.ssn),
pg.passport_no = coalesce(pg.passport_no, person.passport_no)
MERGE (pg)-[:HAS_REFERENCE]->(person)쿼리를 실행시키면 Person 노드들이 PersonMaster 노드에 참조되는 것을 확인할 수 있다.
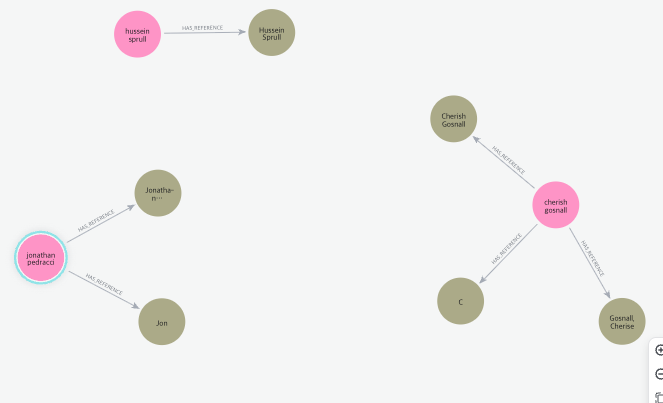
여권 번호로 마스터 엔티티를 조회하고, 마스터 엔티티 노드가 참조하고 있는 다른 노드들의 속성정보를 확인해보자. collect로 노드 집합에 대한 정보들을 한번에 받아올 수 있다.
MATCH (p:PersonMaster)-[:HAS_REFERENCE]->(ref)
WHERE p.passport_no = 'A465901'
WITH p, collect( { source: ref.source , details : properties(ref)}) AS refs
RETURN { master_entity_id : p.uid, references: refs }쿼리를 실행시키면 아래와 같은 JSON 형식의 결과를 확인할 수 있다.

이 과정은 대체로 반복되어야 하는 작업이고, 데이터베이스의 규모가 클 경우에는 변동분에 대해서만 정기적으로 갱신하는 것이 일반적이다. 이러한 일련의 과정을 Entity Resolution이라고 하는데, Entity Resolution은 WCC 외에도, 연결 깊이(degree), 중심성 등 다른 지표를 활용할 수 있고, 이런 지표를 계산 하기 위한 자동 알고리즘은 대체로 Neo4j에 탑재되어 있다.
실습 - Amazon-Google Product Catalog Data
이번에는 타이틀명이 복잡한 실제 제품 카탈로그 데이터로 실습을 진행한다. 이 링크에서 'Aamazon-Google Product' 데이터를 다운받고, 다운받은 데이터를 로컬인스턴스 디렉토리의 import 폴더로 옮긴다.
LOAD CSV WITH HEADERS FROM "file:///Amazon.csv" AS row
CREATE (p:Product { sid: row.id }) SET p.source = "AMZ", p += properties(row) ;
LOAD CSV WITH HEADERS FROM "file:///GoogleProducts.csv" AS row
CREATE (p:Product { sid: row.id }) SET p.source = "GGL", p += properties(row) ;Amazon.csv 파일을 열어 보면 실제로 title 컬럼의 값들이 매우 자유분방한 것을 확인할 수 있다.

이러한 상태의 데이터를 바로 사용하기 전에, 매칭을 위한 Word 노드를 생성한다. Word 노드는 파싱된 제품명만을 다룬다. 아래의 쿼리는 Product 노드의 제품명으로부터 파싱된 Word 노드를 생성하고, 두 노드를 :includes 관계로 연결시킨다.
// 인덱스 부여
CREATE INDEX FOR (w:Word) ON w.txt ;
MATCH (p:Product { source : "GGL" })
UNWIND [x in split(apoc.text.replace(tolower(p.name),"[^a-zA-Z0-9]", " ")," ")
WHERE x <> "" ] AS txt
MERGE ( w:Word { txt: txt }) merge (p)-[:includes]->(w) ;
MATCH (p:Product { source : "AMZ" })
UNWIND [x in split(apoc.text.replace(tolower(p.title),"[^a-zA-Z0-9]", " ")," ") WHERE x <> "" ] AS txt
MERGE ( w:Word { txt: txt }) merge (p)-[:includes]->(w) ;
그러면 위 사진과 같이 Product 노드의 제품명에 포함된 단어들이 :includes 노드로 연결된 모습을 확인할 수 있다.
이제 Entity Resolution을 위한 그래프 알고리즘 적용을 위해, 프로젝션 그래프를 GDS 카탈로그에 추가하도록 한다.
CALL gds.graph.project(
'identity-sim',
['Product', 'Word'],
['includes']
);이제 nodeSimilarity 알고리즘을 적용해 노드의 유사도를 구하도록 한다. 이때 제품명에 대해서도 Jaro-winkler 알고리즘을 적용하여, 두 유사도를 비교해보겠다. jaroWinklerDistance의 경우, 값이 작을수록 유사도가 높다는 의미이므로, 직관적으로 파악하기 쉽게 1-apoc.text.jaroWinklerDistance(node1.name, node2.title)로 구한다.
CALL gds.nodeSimilarity.stream('identity-sim', { similarityCutoff: 0.8 })
YIELD node1, node2, similarity
WITH similarity, gds.util.asNode(node1) AS node1, gds.util.asNode(node2) AS node2
WHERE node1.source = "GGL" AND node2.source = "AMZ"
RETURN similarity AS tk_sim,
// jaroWinklerDistance는 값이 작을수록 유사도가 높다
1-apoc.text.jaroWinklerDistance(node1.name, node2.title) AS str_sim,
node1.name AS Prod1,
node2.title AS Prod2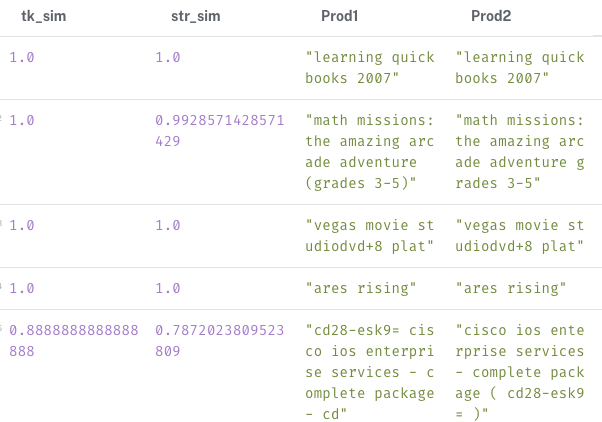
토큰 기반의 유사도 비교 방식이 문자열 기반 방식보다 조금 더 강력하다는 것을 확인할 수 있다.
이제 원본 그래프에 SIMILAR 관계를 생성하고, 속성으로 앞서 구한 유사도를 부여한다.
CALL gds.nodeSimilarity.stream('identity-sim', { similarityCutoff: 0.8 })
YIELD node1, node2, similarity
WITH similarity, gds.util.asNode(node1) AS node1, gds.util.asNode(node2) AS node2
WHERE node1.source = "GGL" AND node2.source = "AMZ"
MERGE (node1)-[:SIMILAR { sim_score : similarity }]->(node2)