본 내용은 building knowledge graph - a practitioner guide chapter 11의 내용을 참고합니다.
의존성 모델링(dependency modeling)
의존성 문제가 발생하는 상황을 생각해보자. 예를 들어, 어떤 프로그램을 개발할 때, 보안 취약성이 발견된 소프트웨어 라이브러리가 보고된다면 개발 중인 프로그램에서 해당 부분을 사용하는 곳을 찾고, 대체 시켜야 한다. 그렇지 않으면 나중에 그 부분에서 보안 문제가 발생할 것이기 때문이다. 이러한 상황을 그래프로 표현한다면, 프로그램 -[:의존하다]-> 라이브러리로 나타낼 수 있을 것이다. 이처럼 다른 요소에 의해 영향을 받는 네트워크 모형을 '의존성 모델' 이라고 한다. 앞선 사례와 같은, 의존성 모델에서 발생하는 문제는 그래프 패턴 매칭이나 그래프 알고리즘으로 풀어 나갈 수도 있다.
숨겨진 의존성 탐색
아래와 같은 테이블이 있다고 생각해보자.
| Element | Depends On |
|---|---|
| A | B |
| A | C |
| A | D |
| C | H |
| D | J |
| E | F |
| E | G |
| F | J |
| G | L |
| H | I |
| J | N |
| J | M |
| L | M |
이 테이블을 그래프로 도식화 하면 아래와 같은 그림을 얻을 수 있다. A->D와 같이 테이블 상에 명시적으로 표현되는 의존성 관계도 존재하는 한편, A->I 같이, 여러 개의 요소에 걸쳐 숨겨진 의존성을 갖는 의존성 관계도 존재한다.
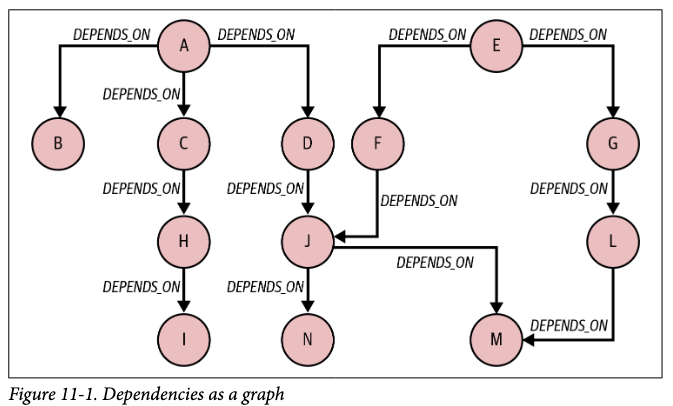
만일, 이러한 테이블이 존재하는 관계형 데이터베이스에서 "A와 I 사이에 숨겨진 의존성이 존재하는가?"라는 답변을 얻기 위한 탐색하는 쿼리를 입력하면 아마 다음과 같은 SQL문을 작성할 수 있을 것이다.
SELECT count(*) >0 dependency_exists
FROM dependencies d
INNER JOIN dependencies d1
ON d.depends_on = d1.elem
INNER JOIN dependencies d2
ON d1.depends_on = d2.elem
[...]
WHERE d.elem = 'A' AND d2.elem = 'I'쿼리문이 매우 길고 복잡할 뿐더러, 이런 구문은 작은 규모의 데이터베이스에서도 잘 동작하지 않을 것이다. 기본적으로 관계형 데이터베이스는 이런 재귀적 경로 분석을 위해 설계되지 않았기 때문이다.
이번에는 neo4j에서 같은 질문에 대한 답을 찾아보자. 우선 테이블 데이터를 그래프로 생성해야 한다.
LOAD CSV WITH HEADERS FROM "file:///dependencies.csv" AS row
MERGE (a:Element { id: row.element })
MERGE (b:Element { id: row.depends_on})
MERGE (a)-[:DEPENDS_ON]->(b)쿼리를 실행하고 전체 노드와 링크를 확인하면 아래와 같은 그래프를 볼 수 있을 것이다.
이제 우리는 눈으로도 직관적으로도 숨겨진 의존성 관계를 파악할 수 있다. 쿼리를 통해 그래프에서 숨겨진 의존성 관계를 찾는 것은 더 쉬운 작업이 되는데, 이는 숨겨진 의존성 관계도 명시적으로 표현되었기 때문이다.
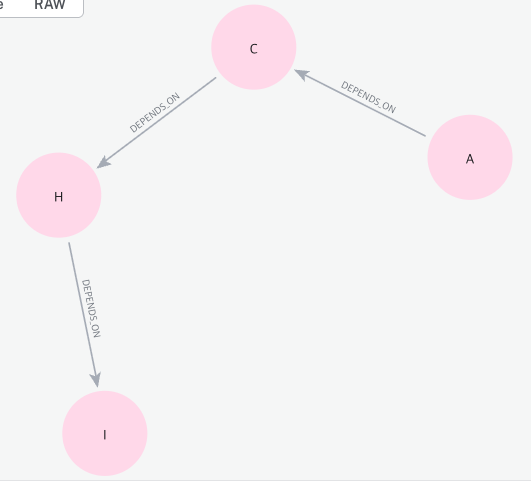
MATCH path = (:Element { id: 'A'})-[:DEPENDS_ON*]->(:Element { id: 'I'})
RETURN path쿼리를 입력하면 아래와 같이 A노드와 I노드 사이의 관계를 나타내는 서브 그래프를 확인할 수 있다.
다른 의존성 모델 알아보기
1. 자격이 있는 의존성 모델 (qualified dependencies)
자격이 있는 의존성 모델은 의존성 관계에 속성값이 부여된 모델을 의미한다. 예를 들어, 회사의 오너쉽 관계에 대한 그래프를 생성할 때, 오너쉽 관계를 단순히 -[:OWNS]->로만 표현할 수는 없다. 지분 비율에 따라 미치는 영향력이 다르기 때문이다. 따라서, 오너 별 지분도 함께 표현하여, -[:OWNS {PART : .1}]-> 과 같은 형태가 적합할 것이다.
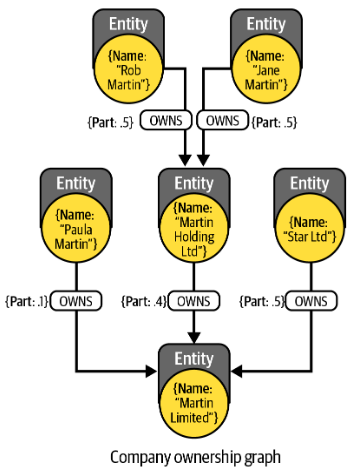
자격이 있는 의존성 모델에서 속성 값은 항상 수치여야 하며, 최소한 열거 리스트 형태여야 한다. 왜냐하면 이 속성값들로 말미암아 복잡한 영향 전파를 계산하거나 의존성 모델의 정확성을 검증할 수 있기 때문이다.
2. 시간적 유효성 (temporal validity) 자격을 갖는 의존성 모델
시간적 유효성을 자격으로 갖는 의존성 모델은 속성값으로 시간을 갖는다. 시간 값은 의존성이 유효할 때를 나타낸다. 따라서 특정 날짜나 시간이 주어졌을 때, 의존성이 활성화되어 있는지 여부를 판단하는 것이 가능하다.
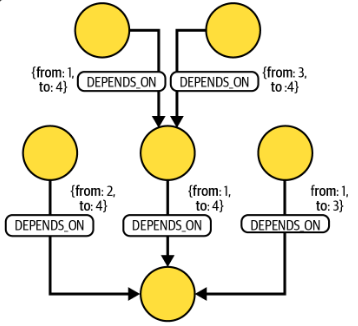
위의 그림을 보면, 각 -[:DEPENDS_ON]에서 유효한 시간 t를 나타내고 있다.
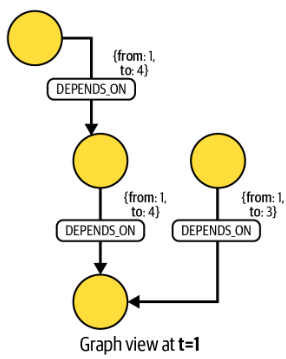
예를 들어, t=1인 상황에서, 의존성이 유효한 부분만 나타내면 아래와 같다. {from:3}, {from:2} 인 의존성 관계는 성립되지 않는 것을 확인할 수 있다.
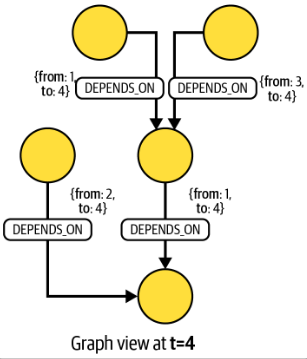
이번에는 t=4 상황에서 의존성이 유효한 부분만 나타낸다. 이 경우 {to:3} 속성을 갖는 의존성 관계는 더이상 성립되지 않는다.
이런 그래프를 쿼리할 때에는 매개변수 t를 주어야 하며, 그렇게 되면 t 일 때 가능한 패턴만을 탐색하게 된다.
3. 다중 의존(multidependency)의 의미론
앞선 그래프들은 모두 하나의 노드에서 한 개의 관계를 갖는 형식이었다. 하지만 현실세계에서는, 하나의 노드가 여러 개의 관계를 갖는 경우가 대부분이다. 예를 들어, 주식투자자의 경우, 하나의 기업에만 투자하기보다는 여러 개의 기업에 분산하여 투자할 것이다.
한편, 다중 의존성에는 두 가지 종류의 해석이 있다. 부가적 vs 중복적,
1. 복합적 의존성(additive dependency)
복합적 종속성이란, 의존성이 종속된 엔터티들에 분산된다는 것을 의미한다. 즉, 어떤 요소 A가 다른 요소 B에 의존할 때, B가 A에 기여하는 비중만큼 가중되어 의존하게 된다.
이처럼 부모노드가 갖는 영향력이 자식노드가 갖는 영향력과 가중치 곱의 총합이 되는 경우를 부가적 종속성이라고 한다. 의존성 분제에서 주로 다뤄지는 부정적 영향에서는, 전파되는 피해가 그 기여 비율로 제한되며,종속된 요소들의 용량이 너무 많이 상실되면 상위 요소가 제공 기능을 완전히 잃는 전환점(tipping point)에 이를 수도 있다.
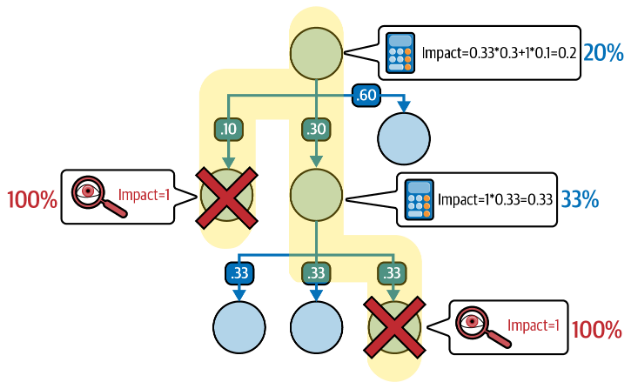
위 그림은 복합적 의존성을 갖는 그래프를 나타낸다. 돋보기는 실제 관측/발생한 영향도이고, 계산기는 계산되거나 도출된 영향도이다. 노란색으로 하이라이트 된 부분은 영향력의 전파 경로이다. 그림을 보면 알 수 있다시피, 최상단 노드는 최하단 노드로부터의 영향력이 가중되어 합하여지므로, 20%의 영향을 받을 수 밖에 없다. 만일 최상단의 노드가 의존하고 있는 노드로부터 어떠한 영향도 받지 않아야 한다면, 위와 같은 형태의 복합적 의존성 그래프는 적합하지 않을 것이다.
2. 중복 의존성 (redundant dependency)
한편, 중복 의존성은 fault tolorence를 제공할 수 있다. 모든 종속 엔티티가 포함된 중복 세트에서, 한 시점에서 한 개의 관계만 활성화 시키기 때문이다.
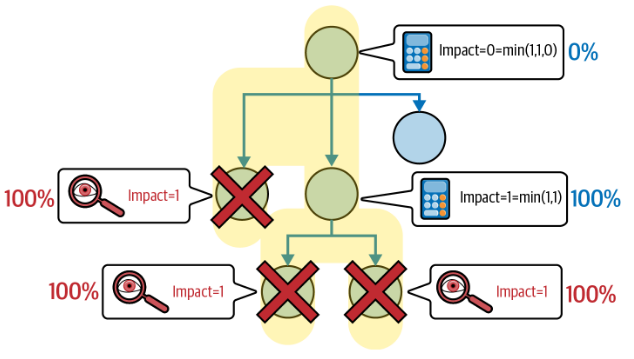
위의 그래프는 중복 의존성을 갖는다. 최하단의 노드 모두에서 failure가 떴고, 이로 인해 상위 노드는 100%의 영향을 받게 된다. 상위 노드의 형제 노드 중 하나도 똑같이 failure가 뜬 상황이다. 하지만 나머지 한 개의 노드에서 failure가 뜨지 않은 상태이므로 영향력의 최소값만 택하는 최상단 노드에서는 0의 영향을 받게 된다. 즉, 대부분의 시스템 노드에서 failure가 발생했지만, 남아있는 한 개의 노드 덕분에 최상단의 노드마저 failure가 되는 일이 발생하지 않았다.
즉, 결과적으로 보호노드를 설정함으로써 특정 부분에서의 실패가 더이상 다른 노드로 전파되지 않게 할 수 있다.
이러한 유형의 상황은 상시운영이 필요한 핵심 서버가 실패할 경우, 서버에 의해 보호되는 소프트웨어 시스템의 고가용성 아키텍처에서 일반적으로 나타난다.
보다 복잡한 시스템에서는 상위 개체가 제대로 작동하기 위해 최소한의 하위 개체 수가 필요할 수도 있다. 임계값 이상의 하위 개체가 정상적으로 작동하면 상위 개체는 영향을 받지 않고(고장률 0%) 계속 작동하지만, 임계값보다 적은 수의 하위 개체가 작동하면 상위 개체는 고장(고장률 100%)이 발생하는 상황이 존재할 수도 있다는 것이다. 이런 상황에서는 아래의 식과 같이 중복의존성 수식을 살짝 변형하여 적용할 수도 있다. 는 임계치로, 최소한으로 구동되어야 할 노드(시스템)의 개수이다.
의 총합이 이상이라면 0을, 아니라면 1을 부여하는 방식이다.
예시로 다룬 두 사례는 각각 별도의 유형만 존재했지만, 실제 환경에서는 두 유형의 다중의존성이 한 시스템 내에서 공존할 수도 ㅇ닜다.
Cypher로 영향력 전파 확인하기
여기에서 예제 실행을 위한 csv 파일을 다운받고, import 폴더에 넣는다.
▶️ 예제 (1) I, K, J 노드와 의존관계 갖는 노드 탐색
❗️변수 선언과 쿼리 실행문은 각각 분리하여 실행 -그렇게 안하면 쿼리 결과 값이 안 뜸❗️
- 변수
declared선언 (한 번만 실행해도 됨)
:param declared => ["I", "K", "J"];- 선언된 변수들에 의존 관계를 갖는 노드 리스트 확인하기
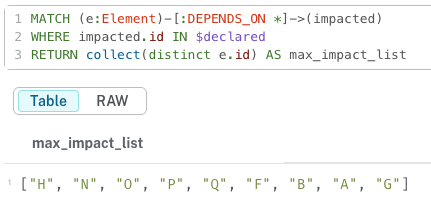
MATCH (e:Element)-[:DEPENDS_ON*]->(impacted)
WHERE impacted.id IN $declared
RETURN collect(distinct e.id) AS max_impact_list;collect()는 리스트 형태로 값을 리턴하는 메서드임.
실제로 그래프에서 확인해보면, 아래 사진에서 노란색으로 표시한 노드들이 리스트업 된 것을 확인할 수 있다.
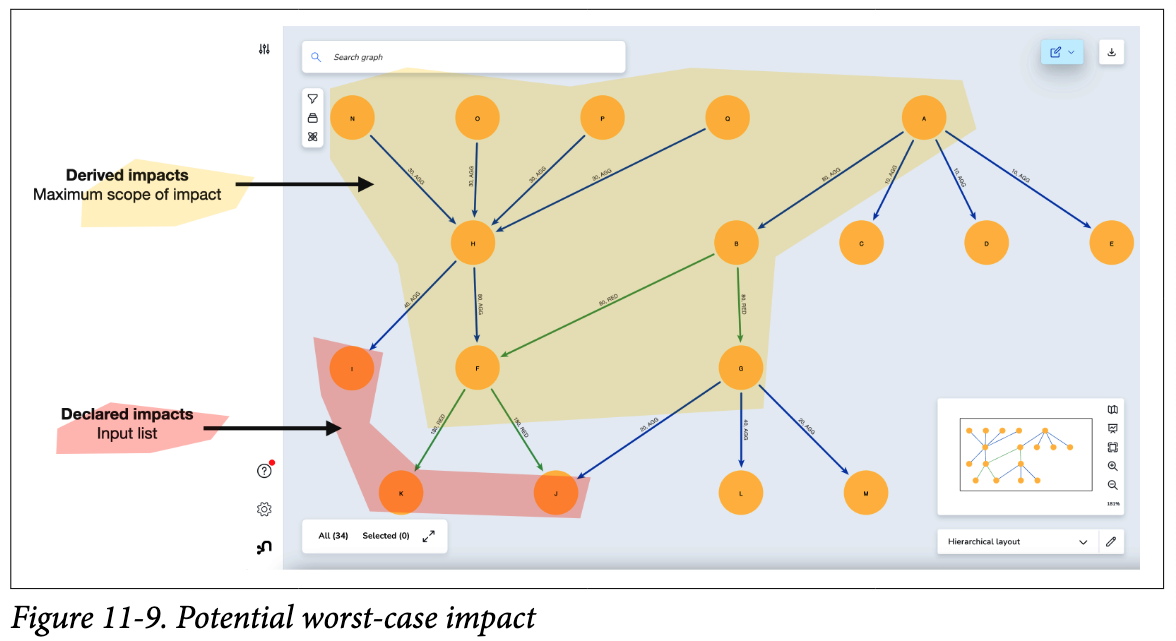
이는 [DEPENDS_ON*] 패턴으로 mode 속성이나 abs 속성값과 상관 없이, 그리고 거쳐가는 노드의 갯수와 관계 없이impacted 패턴에 해당하는 노드의 id가 declared 에 선언된 리스트에 포함되었는지에 대한 여부로만 필터링 했기 때문이다.
▶️ 예제 (2) 중복 의존성 영향력 전파 계산하기
current변수 선언하기
:param current => "F";- 중복의존성 영향력 전파 계산하기
MATCH (e:Element { id: $current })-[d:DEPENDS_ON {mode:"RED"}]->(dependee)
WITH e.id AS element, dependee.id AS dependee,
CASE WHEN dependee.id IN $declared THEN 1 ELSE 0 END AS partial_impact
RETURN element, min(partial_impact) AS derived_impact;F 노드와 중복 의존 관계를 갖는 경우, F 노드의 영향력은 여러개의 중복의존 관계들 중 임계값을 갖는 유효 관계에서의 영향력만을 고려한다. 여기서 F노드가 중복 의존 관계를 갖는 노드 J, K 모두 declared 변수 리스트에 포함된 노드들이므로, partial_impact는 아래와 같은 값을 갖는다.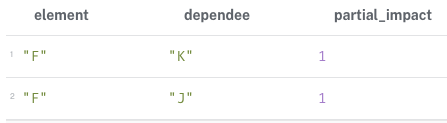
중복의존 관계에서 영향력의 계산은 유효 관계의 영향력 지수만을 고려하며, 예제에서는 최소값으로 유효 관계를 설정하도록 했다. 따라서 위 쿼리의 결과값은 아래와 같이 도출된다.
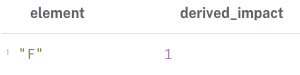
이런 상황은 통신 네트워크에서 고장 기지국이 I, K, G일때 F의 통신 가능 여부에 대해 구할 때로 생각해볼 수 있다. F가 통신하는 기지국 중 하나라도 정상(0)이라면 F가 통신이 가능한 상태(0)라고 할 수 있지만, 모두 고장난 기지국인 경우에는 F가 통신이 불가능한 상태(1)라고 해석할 수 있다.
▶️ 예제 (3) 복합 의존성 영향력 전파 계산하기
이번에는 노드 G가 갖는 복합의존성 영향력을 계산해보도록 한다. I, K, J의 비율은 각각 0.5, 1, 0.33으로 설정한다.
declared,current변수 재정의
:param declared=> { I : 0.5, K: 1, J: 0.33 } ;
:param current => "G";[d:DEPENDS_ON]의 끝 노드가 declared에 포함된 id를 제외하고, 나머지 노드에 대해서는 모두 0을 곱하고, declared에 정의된 id의 경우엔 정의한 비율만큼을 곱한다.
2.
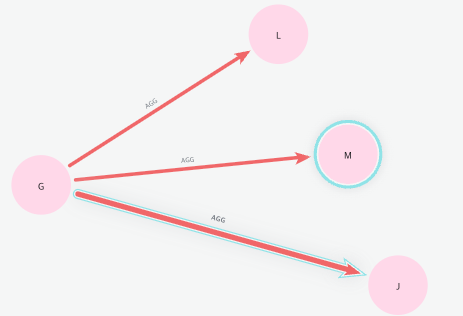
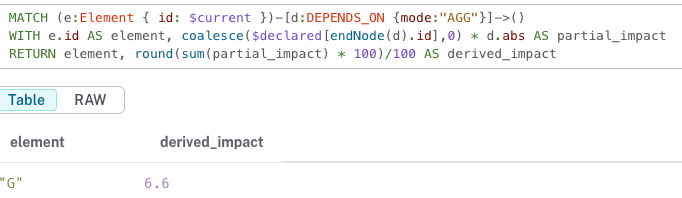
MATCH (e:Element { id: $current })-[d:DEPENDS_ON {mode:"AGG"}]->()
WITH e.id AS element, coalesce($declared[endNode(d).id],0) * d.abs AS partial_impact
RETURN element, sum(partial_impact) AS derived_impactcoalesce:coalesce는 리스트에서 왼쪽->오른쪽 순서로 인자를 검사하며, 첫 번째로 NULL이 아닌 값을 반환하는 역할을 한다.
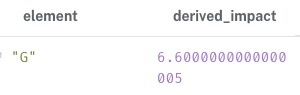
G 노드는 L, M, J노드와 AGG 모드 관계를 가지며, 이중 declared에 있 는 노드는 J뿐이다. 따라서, 나머지 L, M과 연결된 링크의 영향력에는 0이 곱해지고, J와 연결된 링크의 영향력 20에는 J의 비중인 0.33이 곱해져, 결과적으로 대략 6.6의 값을 가지게 된다.
20 * 0.33의 값이 6.60000000005로 지저분하게 나오는 이유는 부동소수점 0.33이 컴퓨터 내부에서 이진수로 표현하는 과정에서 0.33333333과 같이 변환되기 때문이다. 정 거슬린다면 round를 사용해 0.33 * 20 * 100 을 계산하여 소수점 첫째자리 이하의 수들을 제거하고, 다시 100으로 나누어 6.6만 나오게 하는 방법이 있다.
지식그래프에서 의존성의 유효성 확인하기
의존성 그래프가 가져야할 중요한 특징은 정확성을 쉽게 검증할 수 있다는 것이다. 따라서, 잘 형성된 의존성 그래프는 상황에 따라 여러 특정한 조건을 검증해야 한다. 일반적으로 후술할 3가지의 조건을 충족하는지의 여부로 의존성 그래프가 잘 형성되었는지 검증할 수 있다.
1️⃣ Cycle 유무 검증
방향 그래프 구조에서 cycle이란, 그래프가 순환하여 자기자신으로 돌아오는 구조를 의미한다. 이는 궁극적으로 일부 구성요소가 궁극적으로는 자기 자신에게 의존한다는 것을 의미하므로, 의미 자체는 성립할 수 있겠으나 계산적인 측면에서 무한루프에 빠지게 하여 버그를 발생시킬 가능성이 있다.
그래프 구조에서 사이클을 탐색하는 것은 매우 쉽다. 단순히 자기 자신 노드로부터 출발하여 자기 자신에게 돌아오는 패턴을 쿼리하기만 하면 된다. 아래의 쿼리를 입력하면 쉽게 Cycle 유무를 확인할 수 있다.
MATCH cycle = (e:Element)-[d:DEPENDS_ON*]->(e)
RETURN cycle다만, 대규모 그래프의 경우, 사이클 유무를 검색하는 것만으로도 비용이 매우 많이 드는 쿼리가 될 수 있으므로 유의하여야 한다. 우회적인 방법으로는, 1. 검사할 노드들의 서브셋을 설정 (e.g. WHRER e.id IN $node_subset 필터 적용), 2. 참조 경로의 길이 제한(e.g. ()-[:DEPENDS_ON*3..45]->())이 있다.
2️⃣ 복합 의존성 가중치 총합이 기댓값에 미치는지 확인
예를 들어 개별 주주의 소유 비율을 적용하는 경우, 비율의 총합이 100인지 확인하는 과정이 필요하다. 그렇지 않으면 총합이 100%를 넘어가는 비정상적인 상황이 발생할 수도 있기 때문이다. 검사 방법은 간단하다. 각 노드별로, 해당 노드가 갖는 가중치의 총합을 구하여 그것이 1인지 (또는 100% 인지), 혹은 사전 정의된 총합 값과 동일한지 확인하기만 하면 된다.
- 비율 가중치인 경우
노드의 각 관계에 정의된 비율 가중치 총합이 1인지 체크한다.
MATCH (e:Element)-[d:DEPENDS_ON { mode:'AGG'}]->()
WITH e, sum(d.rel) AS agg_sum
RETURN e.id AS element_id, agg_sum = 1 AS valid- 절댓값 가중치인 경우
노드의 각 관계에 정의된 가중치의 총합이e.total과 동일하면 유효로 체크한다.
MATCH (e:Element)-[d:DEPENDS_ON { mode:'AGG'}]->()
WITH e, sum(d.abs) AS agg_sum
RETURN e.id AS element_id, agg_sum = e.total AS valid3️⃣ 소비가 생산을 초과하는지 확인
일부 동적 시나리오에서는 의존성이 빈번히 추가되거나 삭제될 수 있다. 노드에 '총 소비량', '총 생산량' 같은 속성이 존재하는 경우, 관계가 추가, 제거되거나 용량의 업데이트가 별도의 트랜잭션에서 수행될 때 불일치가 발생할 수도 있다. 또한 매번 노드와 관계의 추가, 삭제가 발생할 때마다 전체를 갱신하는 계산을 수행하도록 하면 계산 비용이 많이 든다는 문제도 있다.
이때 적용해 볼 수 있는 유효성 검증 방안은 들어오는 관계의 값(생산)과 나가는 관계의 값(소비)의 균형을 실시간으로 확인하는 것이다. 들어오는 관계의 값 총합과 나가는 관계의 값 총합을 비교해, 들어오는 관계 값보다 나가는 값 관계가 더 크진 않은지 확인한다.
MATCH (e:Element)
OPTIONAL MATCH ()<-[dependee:DEPENDS_ON { mode:'AGG'}]-(e)
WITH e, sum(dependee.abs) AS agg_sum
OPTIONAL MATCH ()<-[dependee:DEPENDS_ON { mode:'RED'}]-(e)
WITH e, agg_sum, coalesce(min(dependee.abs),0) AS red_sum
WITH e, agg_sum, red_sum, agg_sum + red_sum AS total_cap WHERE total_cap > 0
MATCH (e)<-[dependent:DEPENDS_ON]-()
WITH e.id AS elem, agg_sum, red_sum, total_cap, sum(dependent.abs) AS used
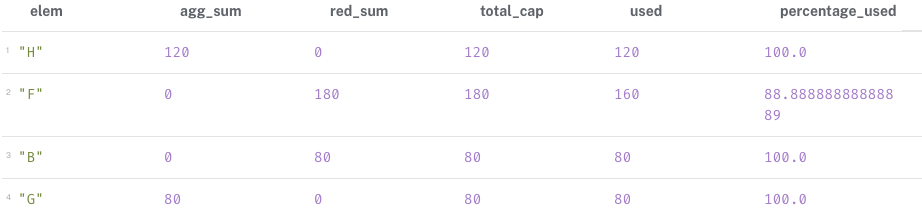
RETURN elem, agg_sum, red_sum, total_cap, used, used *100.0 / total_cap AS percentage_used위의 쿼리를 입력하면 아래의 표를 확인할 수 있다. agg_sum, red_sum은 각각 다른 모드의 들어오는 관계를 의미하고, total_cap은 생산/소비총량이며 used는 나가는 관계로서 소비된 양을 의미한다.
4️⃣ 중복의존성 구성이 임계값의 정의와 일치하는지 확인
중복 의존성과 함께 임계값이 정의된 경우, 중복 집합의 구성 개수가 최소한 임계값과 같아야 한다. 만일 않으면 의존성이 충족되지 않는다. 예를 들어, 어떤 서비스를 가동하기 위해 최소 2개의 서버가 구동중이어야 하는데, 정작 오직 한 개의 서버만 존재하는 상황과 같이, 적어도 중복 의존성의 구성요소 개수가 최소 임계치 개수보다 많거나 같은지 확인하는 과정이다.
MATCH (e:Element)-[d:DEPENDS_ON { mode:'RED'}]->()
WITH e, count(d) AS available_redundant_elements
RETURN e.id AS element_id, available_redundant_elements > e.threshold AS valid위의 쿼리는 연결된 노드의 개수가 설정된 임계 노드의 개수보다 많은지 확인하고, 이를 기준으로 임계치의 유효성을 체크한다.
복잡한 의존성 처리
복잡한 시스템에서 대량의 이벤트를 필터링 하거나 우선순위를 결정하는 것은 매우 유용하다. 특히 IT 인프라에서 어떤 프로세스가 중요한 시스템에 영향을 미치는지를 파악하고, 주요 시스템의 동작에 영향을 주지 않도록 우선순위를 조정하는 것은 매우 중요한 일이다. 여기서 중요한 시스템이란 곧, 운영체제와 같이 여러 개의 프로세스, 프로그램에 영향을 주는 시스템을 의미한다.
의존성 그래프는 이러한 의존성에 따른 우선순위 배치 문제를 해결하는데 도움을 줄 수 있다.
Single-Point-of-Failure Analysis (SPOF)
단일 실패 지점 (Single Point Of Failure)란 시스템의 전 구성요소가 의존하는 단일 요소로, 그 요소의 실패가 전체 시스템의 실패로 이어진다.
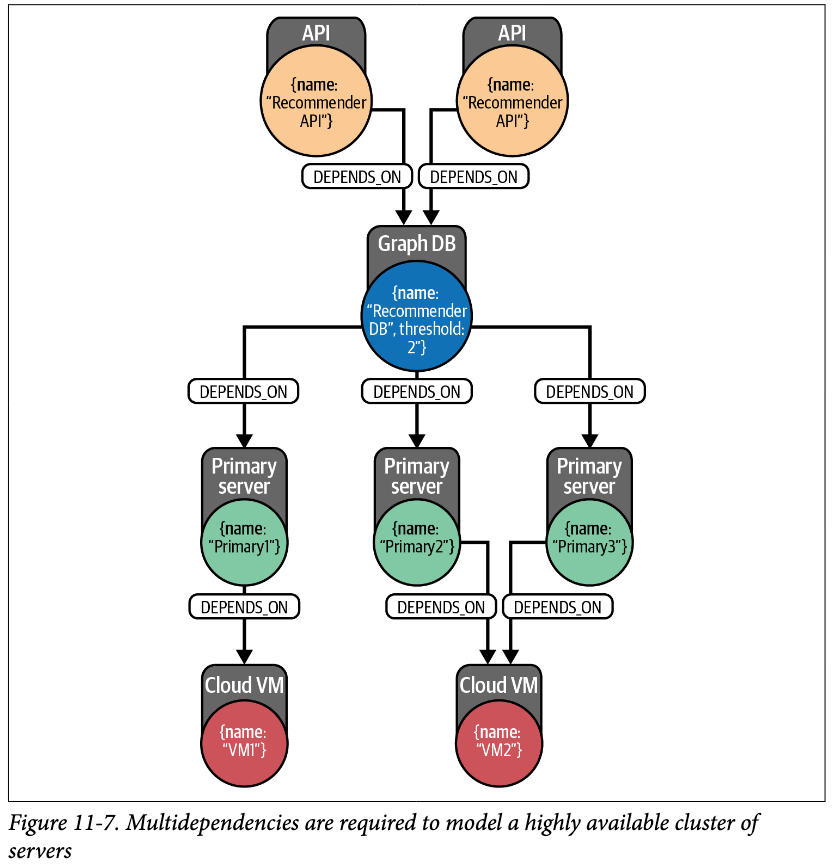
예를 들어 위 사진과 같은 시스템이 있다고 생각해보자. 주요 서버 2개가 Colud VM 2에 의존하고 있는 상황이고, 최소 가동 임계치가 2개인 Graph DB는 VM2에 의존하는 주요 서버 2개에 의존한다. 따라서, 만약 VM2가 고장나게 된다면, VM2에 의존하는 서버 2개도 죽는 것이고, 최소 가동 임계 서버거 2개인 Graph DB도 작동하지 못하게 되는 것이다. 그러면 Graph DB에 모두 의존하고 있는 두개의 서비스 API도 사용하지 못하는 것이다.
이 상황에서 SPOF는 VM2이다. VM2의 마비로 인해 전체 시스템이 다운된 상황이기 때문이다. 이처럼 시스템 아키텍쳐를 설계할 때, SPOF를 잘 분석하는 것이 무엇보다 중요하다.
지식그래프에서 SPOF는 단순한 Cypher 쿼리로 표현될 수 있다. 다운되지 말아야 할 서비스에 대한 노드로부터 의존성 관계를 거슬러 올라가는 식으로 SPOF 노드를 발견할 수 있다.
MATCH alertPath = (spof)<-[:DEPENDS_ON*]-(e:Element)-[:DEPENDS_ON*]->(spof)
WHERE e.id = $selected_node_id
RETURN alertPath위의 쿼리는 선택된 노드의 SPOF를 탐색하도록 하는 쿼리이다. e에서 시작해서 :DEPENDS_ON 관계를 역방향(<-) 으로 여러 번(*) 따라갔을 때 도달하는 노드와, e에서 시작해서 :DEPENDS_ON 관계를 정방향(->) 으로 여러 번(*) 따라갔을 때 나오는 동일한 노드, 즉 중간 연결점 역할을 수행하여 위아래의 의존 관계가 spof로 수렴하는 구조를 찾는다.
모든 SPOF가 치명적인 것은 아닐 수도 있다. 하지만 SPOF는 위상학적으로 데이터/에너지의 병목이 발생할 수 있는 지점이고, 따라서 이를 잘 분산시킬 수 있도록 해야 한다. 만일 해당 SPOF가 완전히 해결될 수 없다면, 문제가 발생했을 때의 백업 방법에 대해 마련해두어야 한다.
Root Cause Analysis
근본 원인 분석은 영향 전파 분석의 반대 개념으로, 여러 개의 영향(impacts)이 주어졌을 때, 이 모든 것이 단일한 요소에 의존하는지 확인하는 것이 목표다.
만약 그것이 증명된다면, 그 공통 조상(common ancestor)이 관측된 영향들의 근본 원인(root cause) 이 된다.
이런 분석은 서비스 보증 시스템(service assurance systems) 에서 흔히 나타난다. 서비스 보증 시스템은 복잡한 시스템을 모니터링하면서 시스템 내 구성 요소들로부터 지속적으로 알람, 이벤트, 메트릭을 수집한다.
통신망, 공급망, IT 인프라처럼 복잡한 시스템에서는 각 구성 요소가 서로 복잡하게 의존하며 알람은 어떤 요소에서의 오작동을 의미한다. 해당 요소 자체 문제일 수도 있지만, 다른 의존 요소의 실패가 연쇄적으로 영향을 미쳐 발생한 것일 수도 있다.
따라서 모니터링 시스템은 알람의 양을 줄여서 “고신호/저잡음” 상태를 만들고, 정확한 개입이 가능하도록 해야 한다.
이를 위해 사용하는 방법 중 하나가 모든 파생 알람을 그 근본 원인과 묶어서 근본 원인만 보여주는 것이다.
step 1. 원인 후보 식별
근본 원인 분석 패턴을 만들기 위한 첫 단계는 원인 후보를 식별하는 것으로 여러 개의 영향을 받은 노드(symptoms)들이 주어졌을 때, 그래프에서 그 의존 관계를 탐색하여 그 증상들을 설명할 수 있는 leaf node를 찾는다.
이 과정에서 노드들은 서로 분리된 그룹(disjoint groups)으로 나타난다. 실제로는 동시에 발생했지만 독립적인 결함들이 감지되는 경우가 자주 있는데, 이 탐색 과정을 통해 독립적인 증상들을 즉시 서로 다른 클러스터로 묶을 수 있다.
- 문제 노드(symptoms) 정의
:param symptoms=> ["N","O","P","H","I","A","E"] ;- 원인 노드 찾기
MATCH (e:Element)-[:DEPENDS_ON*0..]->(x)
WHERE e.id in $symptoms
AND NOT (x)-[:DEPENDS_ON]->()
WITH x, collect(distinct e.id) AS explains_faults
WHERE size(explains_faults) > 1
RETURN x.id AS candidate_root, explains_faults
ORDER BY size(explains_faults) desc위의 쿼리는 NOT (x)-[:DEPENDS_ON]->() 구문으로 서로 의존하지 않는 리프노드를 탐색하여 모든 증상 노드의 의존성 체인의 근본 원인이 될 수 있는 노드를 찾는다.

그리고 각각 collect(distinct e.id)로 집계되는 과정에서 후보 근본 원인들에 의해 설명되는 증상이 식별된다.
step 2. 원인 노드가 될 가능성이 높은 노드 결정
이 단계에서는 정확도나 재현율, F-Score와 같은 일반적인 정보검색 메트릭을 사용해 순위를 매겨, 어떤 것이 근본 원인 노드가 될 가능성이 높은지 결정한다.
- 정확도 : 후보 노드의 근본 원인이 증상 요소 목록 중 몇 퍼센트를 설명하는가?
- 재현율 : 이 노드가 문제의 실제 근본 원인 노드라면, 최대 영향은 무엇이며, 실제 관찰(초기 실패 노드 목록)과 얼마나 일치하는가?
- f-score : 재현율과 정확도를 이용하여 계산되는 수치로 정확도와 재현율의 조화평균
MATCH (e:Element)-[:DEPENDS_ON*0..]->(x)
WHERE e.id IN $symptoms
AND NOT (x)-[:DEPENDS_ON]->()
WITH x, collect(distinct e.id) AS explains_faults
WHERE size(explains_faults) > 1
WITH x AS candidate_root, explains_faults
MATCH (candidate_root)<-[:DEPENDS_ON*0..]-(x)
WITH candidate_root, explains_faults, collect(distinct x.id) AS potential_max_impact
WITH candidate_root, toFloat(size(explains_faults))/size($symptoms) AS precision, toFloat(size([x in potential_max_impact
WHERE x in $symptoms])) / size(potential_max_impact) AS recall
// candidate_root, precision, recall, fscore 리턴
RETURN candidate_root.id, precision, recall,
(2 * precision * recall) / (precision + recall ) AS fscore
ORDER BY fscore DESC
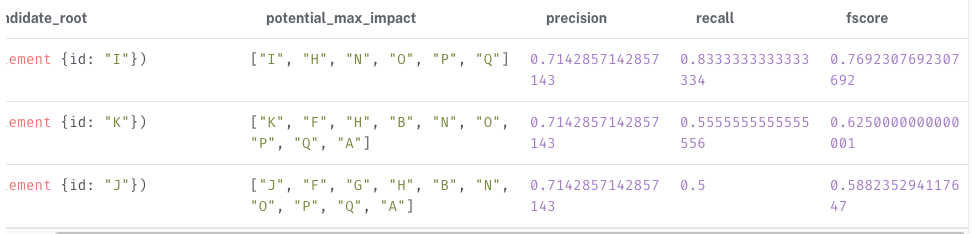
결과를 보면, I가 근본 원인 노드가 될 가능성이 가장 높음을 추측할 수 있다. 그러나, 만일 J가 근본 원인이라면 J에 간접적으로 의존하는 노드가 많으므로 증상 노드에 더 많은 실패 노드가 포함되어야 한다. 하지만 그랬다면 입력 노드에 J가 더 많이 포함되어 있어야만 했다.
이는 관찰된 증상 노드의 질에 따라 접근 방식이 달라진다는 것을 보여주며, 증상 노드 목록이 완전할수록 결과의 정확도가 상승한다. 하지만 실제 시나리오에서는 현재 상태에 대해서 완벽히 파악할 수가 없으므로, 이러한 유형의 분석은 항상 단일한 답변보다는 여러 개의 가능성이 높은 후보 목록을 제시한다. 이러한 결과에 시간, 각 전문 분야의 휴리스틱과 같은 다른 요소와 결합되어 근본 원인에 대한 올바른 진단을 내릴 수 있다.
