본 내용은 Building Knowledge Graph Chapter 12를 참고합니다.
비구조화 된 데이터에서 그래프 기반 검색의 이점?
지식그래프를 사용해서 인덱스 기반 검색 엔진을 보완하는 것은 지식그래프의 '지능(intelligence)를 활용할 수 있다는 점에서 강점을 갖는다. 여기서 언급되는 지능이란, 동의어, 유의어, 그리고 연관된 키워드를 이해할 수 있고, 도메인과 연관된 개념을 추론할 수 있고, 이를 바탕으로 자연어 질의에 대해 보다 섬세한 답변을 제공할 수 있는 능력이다.
자연어 텍스트에서 개체 추출하기
문서에서 나타나는 자연어 텍스트는 사람이 현실의 객체와, 그 객체가 다른 객체와 갖는 관계를 설명함으로써 다른 사람에게 정보를 전달한다. 하지만, 사람이 어떤 객체를 텍스트로 표현하는 방식은 너무나 다양하고, 때로는 모호하기도 하다. 사람이 사용하는 언어, 외국어까지 나가지 않아도 사투리만 생각해봐도 그러하다.
만약 사투리를 사용하는 이용자가 "고무다라이"를 쿠팡에서 검색한다고 생각해보자. 원시적인 인덱스 기반의 검색엔진에서는 이용자가 원하는 빨간색의 고무 재질인 대야를 찾아내지 못할 것이다.
이번엔 다른 예를 생각해보자. "나는 오늘 친구를 만나기 위해, 삼성역 근처 카페로 갔다.", "삼성의 3분기 실적이 증가했다." 라는 문장들에서 "삼성"이라는 단어가 모두 등장하지만, 각각의 단어가 의미하는 바는 다르다. 단순한 텍스트 매칭 기반 검색 엔진에서는 이 두 "삼성"의 의미를 고려하여 검색 결과를 도출하지는 못할 것이다.
이처럼 오로지 텍스트 기반의 문서를 기반으로 한 자동 자연어 처리는 동일한 엔티티에 대해 다르게 표현되는 명칭을 처리하기엔 한계가 있으며, 비효율적이다.
그렇다면, 전세계의 모든 이용자가 어떤식으로 표현하든 소위 '알잘딱'하게 그들이 원하는 검색 결과를 제시해줄 수 있을까? 어쩌면 이를 위해선 단순히 '텍스트' 중에서 이를 찾는 것이 아닌 '개념'을 찾는 과정이 필요할 것이다.
Step1. Named Entity Resolution
huggingface의 transformer에서 pipeline을 이용해 NER을 진행해보자. 모델을 재정의 하지 않은 경우, BERT 기반의 모델을 사용하게 된다. 기본적으로 제공하는 모델은 영어에 적합한 모델이므로, 한국어 문장에서 NER을 진행해보고 싶다면 Hugging Face 직접 모델을 찾아보도록 하자.
from transformers import pipeline
# ner pipeline 정의
ner_pipe = pipeline("ner", aggregation_strategy="simple")
# 예시 텍스트 (영어)
title = """Twitter chair Patrick Pichette joins graph data \ platform Neo4j board of directors."""
for entity in ner_pipe(title):
print(entity)이번에는 한국어 특화 모델을 사용해보겠다. monologg/koelectra-base-v3-naver-ner를 사용했다.
from transformers import pipeline
kor_class_pipe = pipeline("token-classification", model="monologg/koelectra-base-v3-naver-ner")
example1= "나는 친구를 만나기 위해 삼성역으로 갔다."
example2 = "삼성의 3분기 실적이 발표되었다"
# example 1 ner
for entity in kor_class_pipe(example1):
print(entity)
# example 2 ner
for entity in kor_class_pipe(example2):
print(entity)실행 결과는 아래와 같이 나올 것이다.
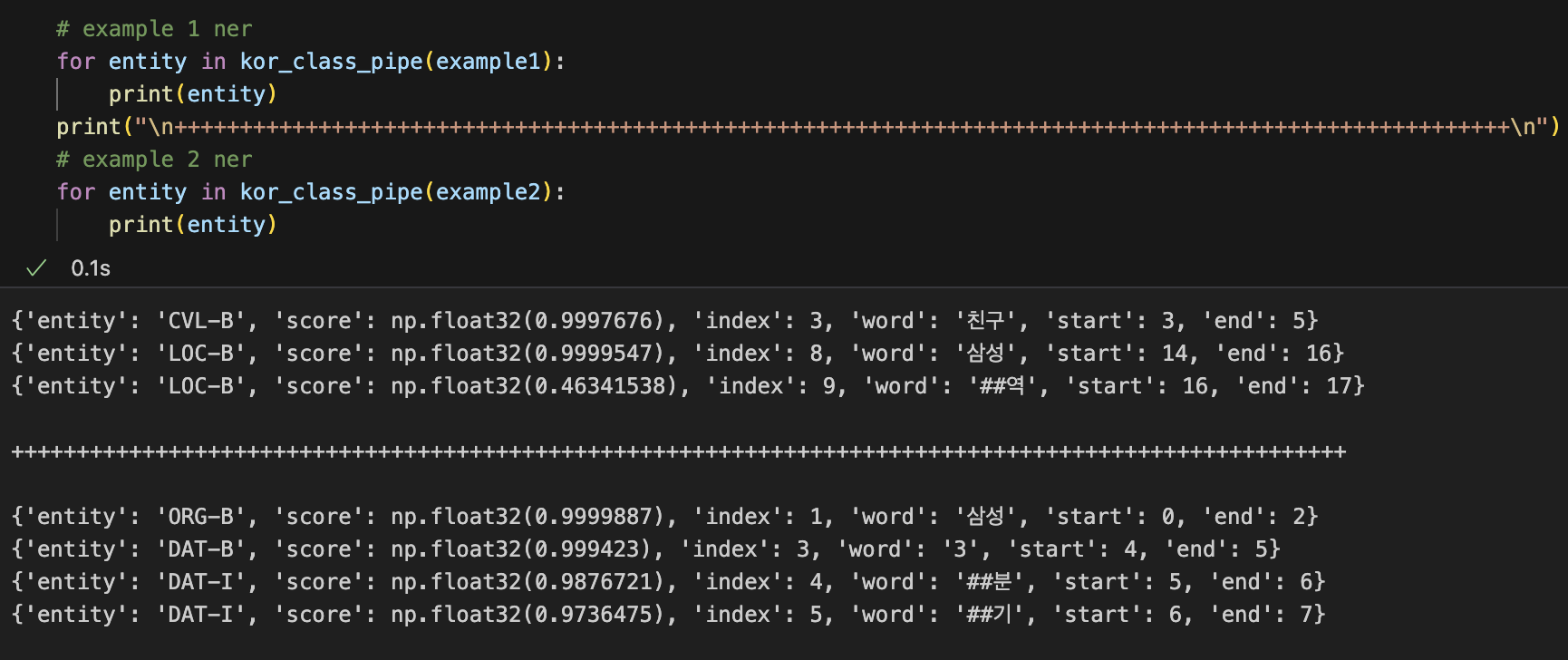
사진을 보면 알 수 있듯이, "삼성" 이라는 단어가 각각 "LOC-B"(장소)와 "OGR-B"(기관/조직)로 분류된 것을 확인할 수 있다.
Step 2. 그래프에 쓰기
이번에는 직접 예시 기사를 가져와서 생성해보도록 하자. 작업상의 편리함을 위해, neo4j 드라이버와 NER Pipe를 속성으로 갖는 클래스 neo4j_graph_creator를 정의하였다.
class neo4j_graph_creator:
# 클래스 생성자 정의
def __init__(self, uri, user, password):
# 드라이버 정의
self.driver = GraphDatabase.driver(uri, auth=(user, password))
# NER 파이프라인 정의 --> 한글 NER 추출 모델 사용
self.ner_pipe = pipeline("token-classification", model="monologg/koelectra-base-v3-naver-ner")
# 드라이버를 닫는 함수
def close(self):
self.driver.close()
# 텍스트로부터 엔티티 추출 ==> 그래프로 생성하는 함수
def create_graph_from_text(self, title, fragment, author, url):
title = title
fragment = fragment
author = author
url= url
# 문자열로부터 엔티티를 추출 -> 추출 결과를 entity_list에 저장
entity_list = []
for entity in self.ner_pipe(title + fragment):
entity_list.append(entity)
# 추출 결과로부터 그래프 생성하는 Cypher 쿼리
cypher_query = '''
MERGE (a:Article { url:$url })
ON CREATE SET a.title = $title, a.text = $frg
MERGE (p:Person { name: $author })
MERGE (a)-[:has_author]->(p)
WITH a, $entityList AS entities
UNWIND entities AS entity
MERGE (e:Entity { name: entity.word, type: entity.type })
MERGE (a)-[:references { salience: entity.score }]->(e)
'''
with self.driver.session(database="neo4j") as session:
session.write_transaction(
lambda tx: tx.run(cypher_query, url=url, author=author, title=title, frg=fragment,
# 엔티티 타입의 경우, 한글 버전은 ORG-B 등으로 세분되어 있으나 편의상 ORG만 떼어 사용
entityList=[{"word": x["word"], "type":x["entity"].split("-")[0], "score": x["score"] } for x in entity_list]))
self.close()사이퍼 쿼리를 조금 더 자세히 보도록 하자.
MERGE (a:Article { url:$url })
ON CREATE SET a.title = $title, a.text = $frg 이 부분은 Article노드를 생성한다. Article노드는 title과 text의 세트로서 하나의 엔티티로 식별이 되고, url 속성을 갖는다.
MERGE (p:Person { name: $author })
MERGE (a)-[:has_author]->(p) 위의 쿼리는 작성자를 표현하는 Person 노드를 생성한다. Article 노드는 [:has_author] 관계로 Person 노드와 연결된다.
WITH a, $entityList AS entities
UNWIND entities AS entity
MERGE (e:Entity { name: entity.word, type: entity.type })
MERGE (a)-[:references { salience: entity.score }]->(e)마지막으로, 위의 쿼리는 엔티티 리스트로부터 엔티티를 가져오고, Article노드와 Entity 노드를 [:references] 관계로 연결한다. $entityList는 실제로 {'entity': 'ORG-B', 'score': np.float32(0.9999887), 'index': 1, 'word': '삼성', 'start': 0, 'end': 2}와 같은 엔티티 정보를 담고 있는 딕셔너리 자료를 여러개 가지고 있는 리스트이다. UNWIND 키워드로 리스트를 개별 행으, 즉 개별 엔티티 딕셔너리로 풀어내고, 각각의 엔티티 딕셔너리로부터 속성값을 추출하여 사용한다.
이때 [:references]가 갖는 속성인 salience는 보통 텍스트 안에서 그 엔티티가 갖는 중요도를 나타내는데, 여기서는 엔티티명의 타입 매칭에 대한 신뢰도를 사용했다.#
이렇게 neo4j_graph_creator를 정의한 뒤, 실제 기사문들을 넣어 그래프를 생성해보도록 하자.
# 예시 기사문 1
title_1 = "코스피, 1.33% 상승 마감…네이버 '불기둥'"
fragment_1 = '''
코스피가 1%대 강세 마감했다. 낙폭 과대 인식에 따른 반발매수세가 대거 유입되면서 상승폭이 컸다.
외국인은 코스피200 선물 시장에서 1조 넘게 사들였다. 특히, 대형반도체주를 중심으로 다시금 투심이 개선되는 흐름을 보였다.
이날 코스피지수는 전거래일대비 45.16포인트(1.33%) 오른 3,431.21로 거래를 마쳤다. 외국인이 현물시장에서 4,400억원을, 코스피200 선물시장에서 1조1,000억원 어치를 사담았다.
기관 역시도 3,000억원 매수 우위.
개인은 현물시장에서 7,400억원, 선물시장에서 2,700억원 어치를 쏟아냈다.
시가총액 상위종목별로는 대부분의 종목이 강세 마감했다.
삼성전자(1.08%), SK하이닉스(3.71%), KB금융(2.66%), 신한지주(2.46%) 등의 상승폭이 상대적으로 컸다.
특히, 네이버는 7.02% 상승 마감했는데, 장중 8.58%까지 치솟기도 했다.
반면, 두산에너빌리티(-0.32%)는 소폭 하락 마감했다.
코스닥지수는 전거래일대비 11.52포인트(1.38%) 오른 846.71로 거래를 마쳤다.
'''
author_1 = "정경준"
url_1 = "https://the.url.of.the.article"
# 예시 기사문 2
title_2 = "NAVER, 두나무 계열사 편입에 사흘째 강세…7% 상승"
fragment_2 = '''
NAVER가 두나무를 계열사로 편입한다는 소식에 사흘째 강세를 나타냈다.
29일 한국거래소에 따르면 NAVER는 이날 1만8000원(7.02%) 오른 27만4500원에 거래를 마쳤다. 장중에는 9% 가까이 뛰기도 했다.
네이버가 국내 가상자산 거래소 1위 업비트 운영사인 두나무를 계열사로 편입한다는 소식이 전해지면서 지난 25일 이후 3거래일 연속 상승세가 이어지고 있다.
가상자산업계에 따르면 네이버와 두나무 양사는 현재 비상장사인 자회사 네이버파이낸셜과 두나무 주식 교환비율 산정 등 세부 논의를 진행 중이다.
거래 방식으로는 '포괄적 주식교환' 방식이 유력하다. 이는 한 회사가 다른 회사의 주식 전부를 취득해 100% 지분을 확보하는 방식이다. 합병과 달리 법인 자체를 그대로 유지하며 지배구조만 모회사-자회사 형태로 재편된다. 이사회 승인 후 거래가 성사된다면 네이버-네이버파이낸셜-두나무로 이어지는 수직계열화가 완성된다.
증권가에서는 이번 제휴에 따라 강력한 시너지가 발생할 것으로 예상하고 있다. 이준호 하나증권 연구원은 "네이버-두나무가 강한 제휴로 신사업을 추진한다는 분명한 사실만으로도 기존 목표주가 32만원까지 안정적인 매수 기회라는 판단"이라며 "실제 합병 및 신사업 가시화에 따라 추정치, 목표주가 상향 예정"이라고 전망했다.
'''
author_2 = "김경택"
url_2 = "https://n.news.naver.com/mnews/article/003/0013512839"
# neo4j_graph_creator 객체 생성
pw = "" # 자신이 설정한 인스턴스 비밀번호
driver_obj = neo4j_graph_creator("neo4j://127.0.0.1:7687", "neo4j", pw)
# 기사문으로 그래프 생성하기
driver_obj.create_graph_from_text(title_1, fragment_1, author_1, url_1)
driver_obj.create_graph_from_text(title_2, fragment_2, author_2, url_2)코드를 실행시킨 뒤, 다시 neo4j desktop으로 돌아가서 그래프를 확인해보면 아래와 같은 모습을 보이는 것을 알 수 있다.
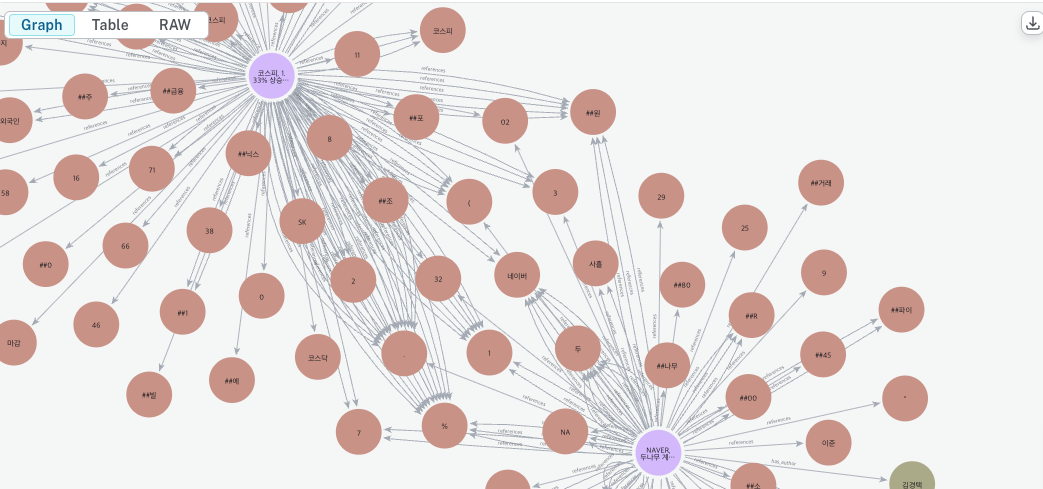
코드에서 사용한 한국어 NER 추출 모델은 엄밀히 따지면 토크나이저에 가까워서, 어근/어미도 다 떼어서 제공하고, 숫자나 보통명사들도 추출하기 때문에 위 사진과 같이 의미없는 엔티티값이 많이 생성된다. 게다가 업데이트가 조금 덜 된 것인지, "두나무" 라는 회사 이름도 "두" + "나무"로 분석하는 오류를 확인할 수 있다.
하지만, 두 개의 기사문이 "네이버" 라는 엔티티를 중간 매개 노드로 하여 연결되어 있는 모습을 볼 수 있다.
Step 3. 쿼리해보기
예제(1) 기사에서 언급된 엔티티 확인하기
아래 쿼리문은 특정 기사에서 언급된 엔티티들에 대해 확인한다. 기사 제목이 길기 때문에, 여기서는 URL으로 기사를 찾고, 해당 기사에서 등장한 엔티티를 확인하도록 한다.
MATCH (a1:Article)-[:references]->(e:Entity)
WHERE a1.url = "https://n.news.naver.com/mnews/article/003/0013512839"
RETURN e.name AS entityName, e.type AS entityType실행 결과는 아래 사진과 같다. 어근, 어미가 분리되어 나타난 경우가 대다수인 것을 확인할 수 있다.

예제(2) 특정 엔티티가 언급된 기사 찾기
이번에는 기사를 검색하는 것과 같이, 특정한 엔티티가 언급되는 기사를 찾는다. 찾아낸 기사의 제목과, URL을 확인할 수 있도록 return 값을 설정한다.
MATCH (a:Article)-[:references]->(e:Entity)
WHERE e.name = "네이버" AND e.type = "ORG"
RETURN a.url AS articleLink, a.title AS articleTitle쿼리를 실행시키면 아래의 사진과 같은 결과를 얻을 수 있는데..

기사에서 해당 키워드가 등장한 횟수만큼의 엔티티 노드가 생성되어서 그런지, 기사 링크와 타이틀이 중복되어 나온다. 유니크한 결과값만 확인하고 싶다면 리턴 시킬 때 DISTINCT 키워드를 추가하면 된다.
MATCH (a:Article)-[:references]->(e:Entity)
WHERE e.name = "네이버" AND e.type = "ORG"
RETURN DISTINCT a.url AS articleLink, a.title AS articleTitle