
안녕하세요, AI 엔지니어입니다
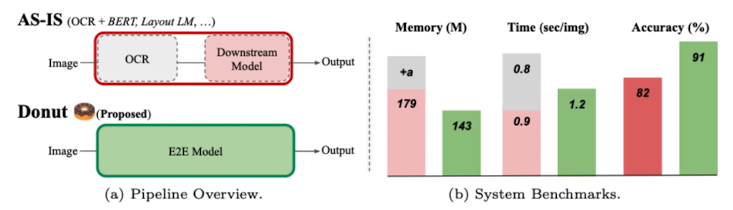
[논문 정리] OCR-free Document Understanding Transformer (WIP)
Abstract 현재의 Visual Document Understanding (VDU) 기법은 텍스트 추출을 OCR 엔진에 맡기고, OCR이 반환한 텍스트를 이해하는 방식에 집중해왔다. 하지만 OCR을 활용하는 것에는 다음의 3가지 문제가 존재한다. OCR을 사용하기
2024년 7월 8일
·
0개의 댓글·
0
[논문 정리] ConvNeXt(2022)
레퍼런스: "ConvNext: A ConvNet for the 2020s" Liu, Z., et al. (2022)
2023년 11월 8일
·
0개의 댓글·
0
[논문 구현] AlexNet
레퍼런스: <ImageNet Classification with Deep Convolutional Neural Networks(2021)>Tensorflow 구현싱글 GPU 기준으로 수정Summary 확인 plot_modelModel: "sequential" La
2023년 11월 3일
·
0개의 댓글·
0