2 Application Metric 대시보드 만들기
2.1 Memory 지표
새 대시보드 만들기
2.1.1 JVM heap usage
jvm 검색하면 나오는 매트릭들.
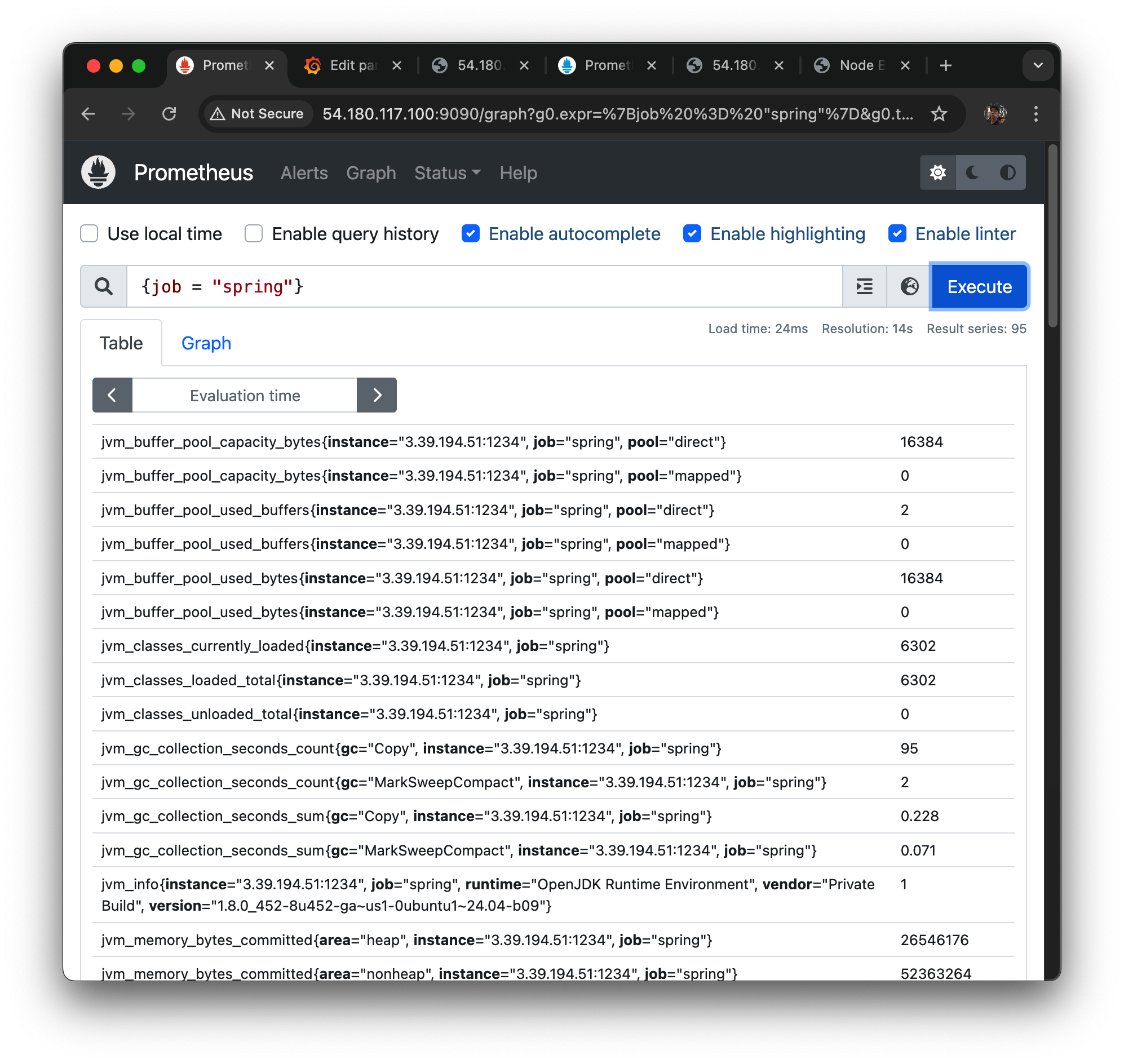
이런 식으로 검색해서 job 별 매트릭들을 가져올 수 있다
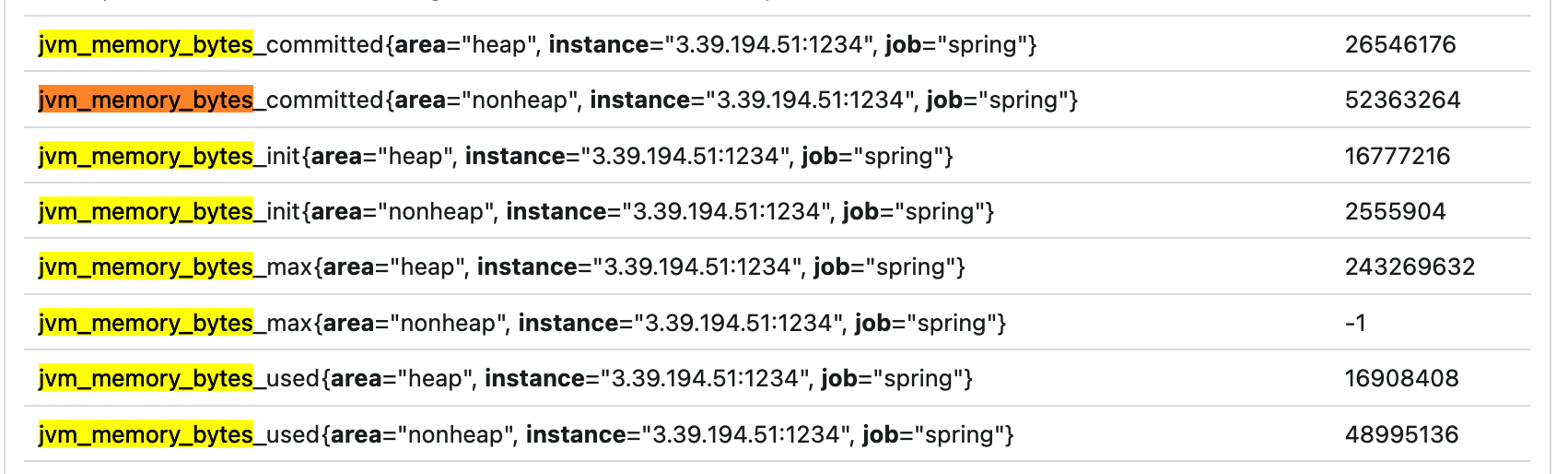
jvm_memory_bytes
관련된 매트릭들을 검색해보았을 때 나오는 녀석들인데
used가 heap, nonheap 있고
max가 heap, nonheap 있고.
max,nonheap의 value가 -1로 안잡히고 있다.
nonheap은 offheap이라고도 하는데 java 메모리가 아니라 네이티에 있는 메모리를 쓰는 건데,
사용량을 보면 used도 nonheap 이 잡히는데..
init 때 처음 잡힌 메모리랑 그리고
커밋된 메모리 이렇게 되어 있는데 그러면 내가 heap 사용량을 보고
싶다면
heap 영역의 사용량/메모리 바이트 max
를 보면 된다.
jvm_memory_bytes_used{area="heap"} / jvm_memory_bytes_max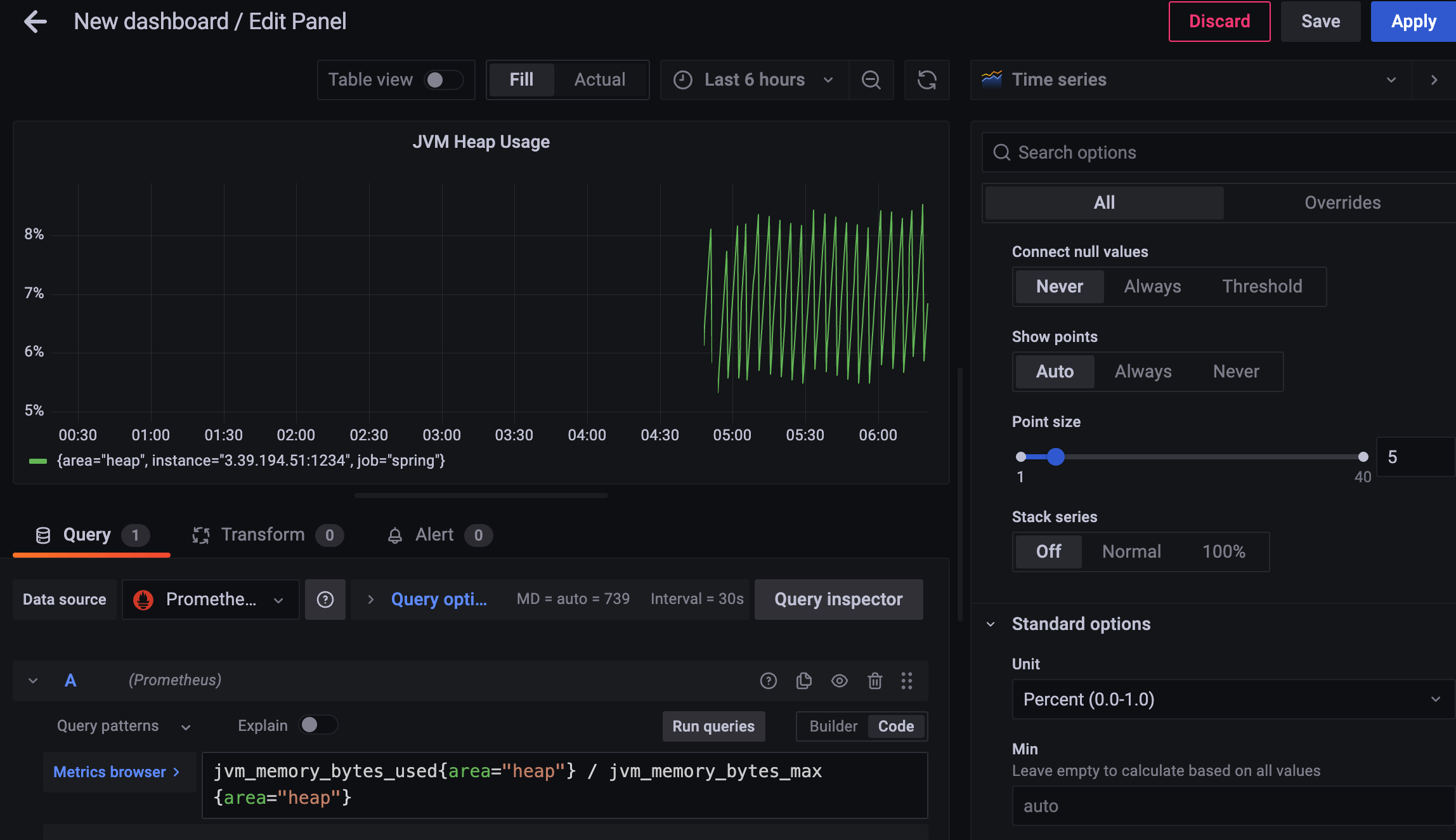
apply + save
그러면 heap 말고 이 인스턴스가 쓰고있는 메모리 usage 알고 싶다면?
2.1.2 App memory usage (amount)
사용량(heap + offheap)
sum by (instance) (jvm_memory_bytes_used{job="spring"})area가 heap,nonheap 있었는데, 다 합쳐서 보고싶은 것.
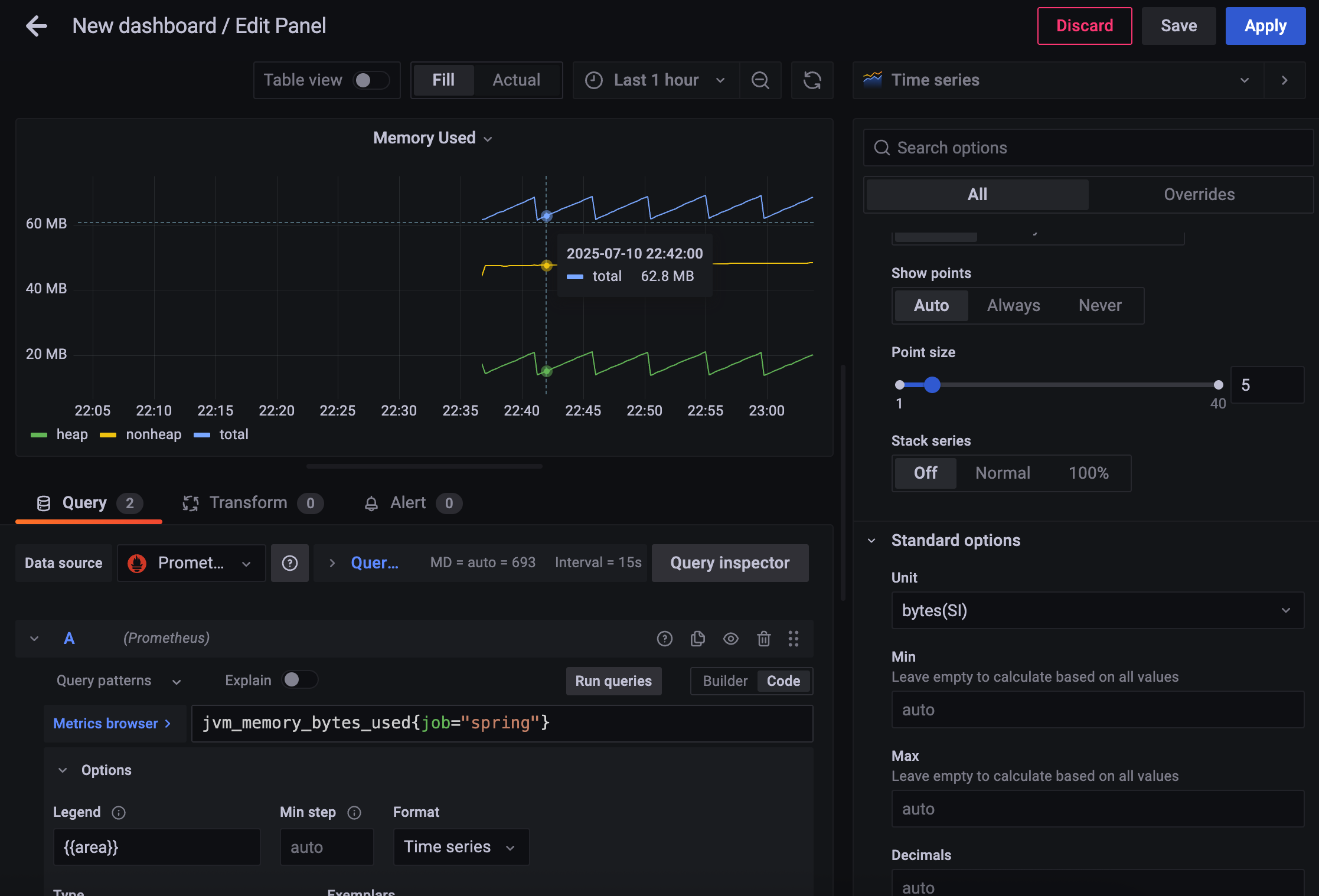
노란색 + 초록색 이 A 의 결과
B 의 결과가 파란색.
2.1.3 App memory usage (%)
그럼 이친구가 해당 컴퓨터에서 사용하고 있는 메모리의 퍼센트는?
사용량 % (node의 memory 대비) 를 구해보자.
전체 사용량, 노드의 사용량 알아야 하는데
노드가 가지고 있는 메모리는
{job="node"} 로 검색, node_memory 로 시작하는 녀석들을 찾아보자.
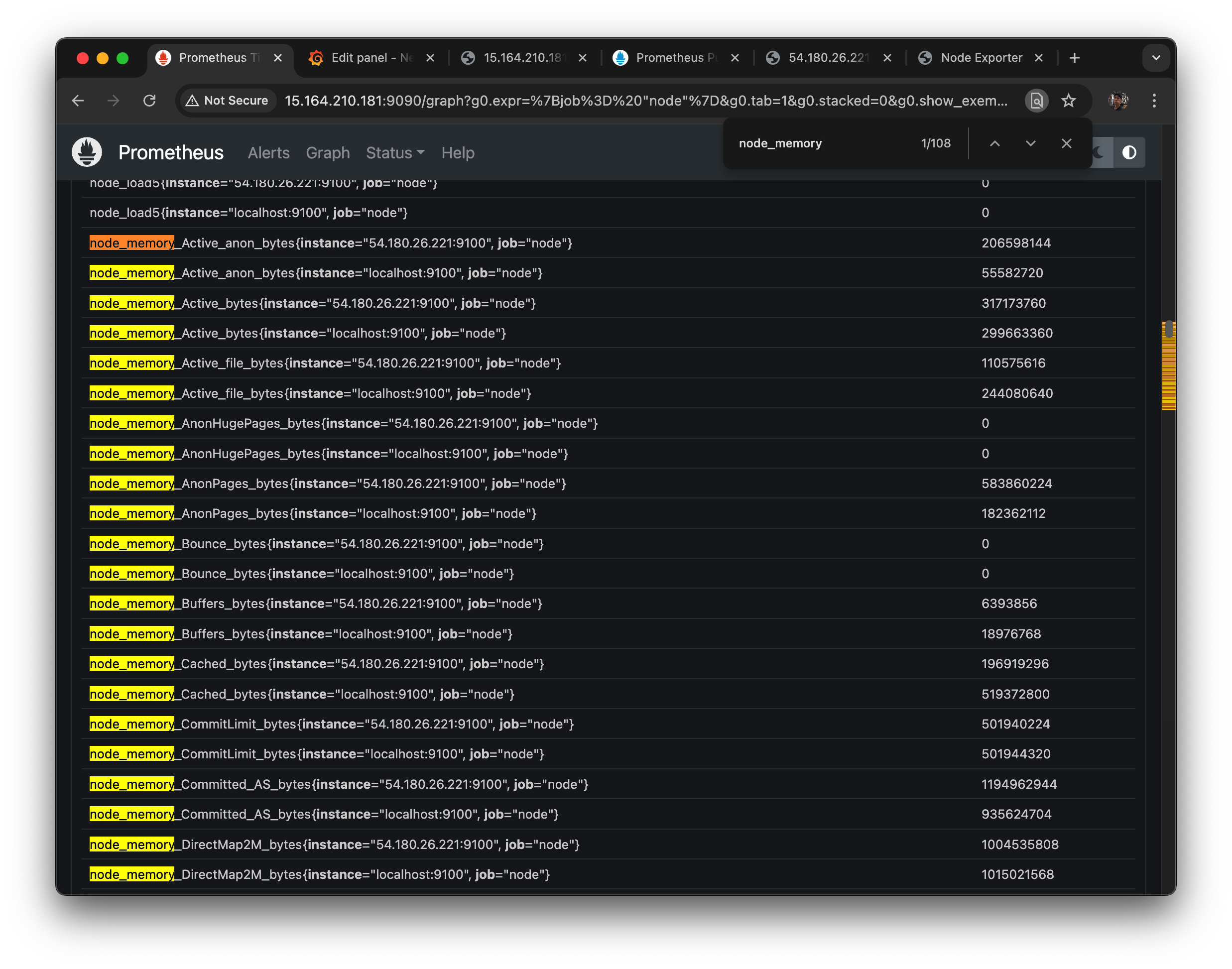
node_memory_MemTotal_bytes 가 사실상 총 메모리 양이니 사용한다.
단위는 bytes(SI)
인스턴스는 내가 app을 띄운 인스턴스를 선택.
node_memory_MemTotal_bytes{job="node", instance="$your_instance"}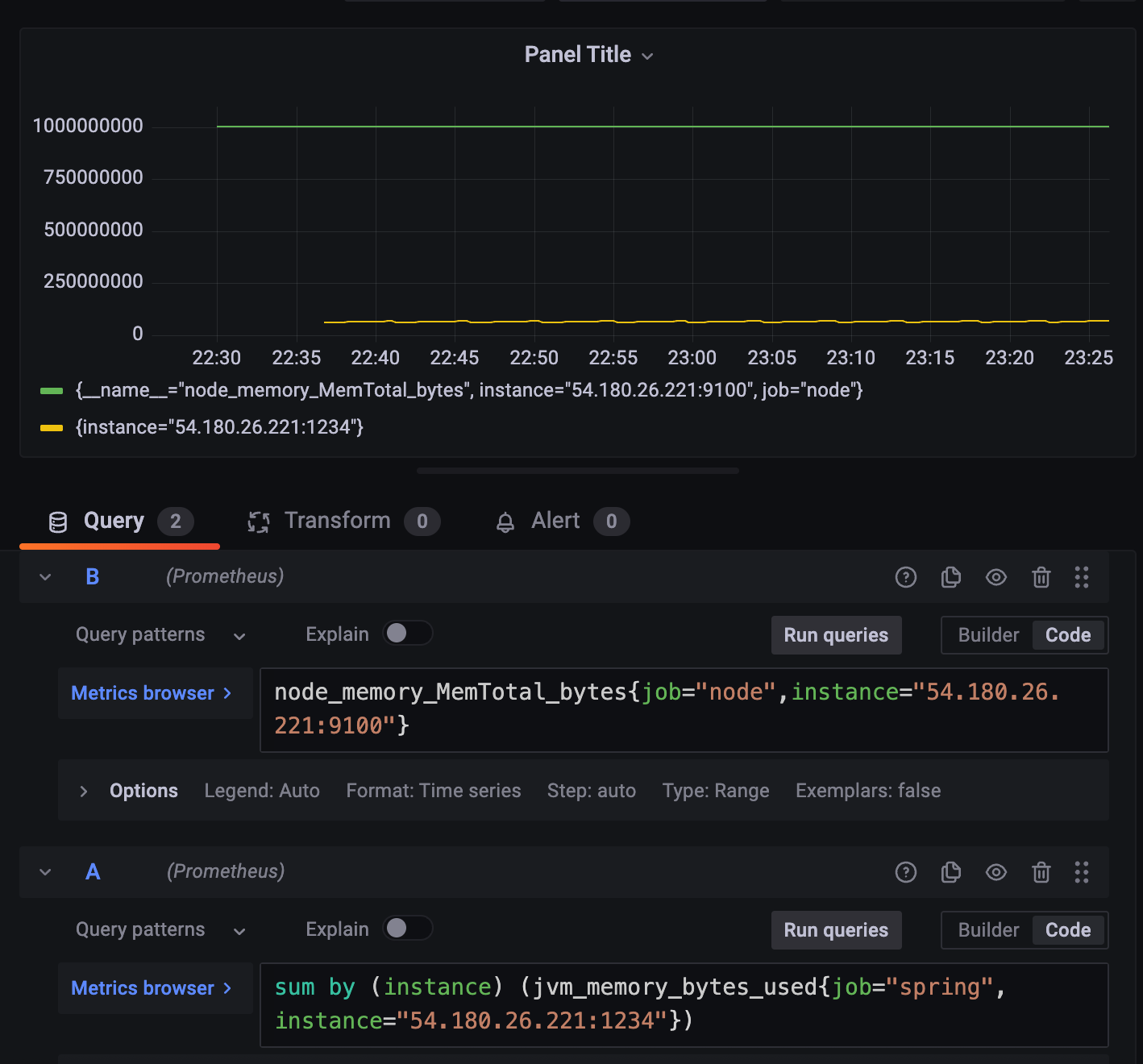
그리고 아까 앱서버에서 사용 중인 메모리량을 추가한다
이제 두 개의 값을 나눠서 %로 나타내면 됨.

이런 식으로 하면 계산이 되지 않는다.
계산이 될 법도 한데 왜 안되지? 하는 경우엔
Query 가 아닌 Expression 으로 추가해보자.
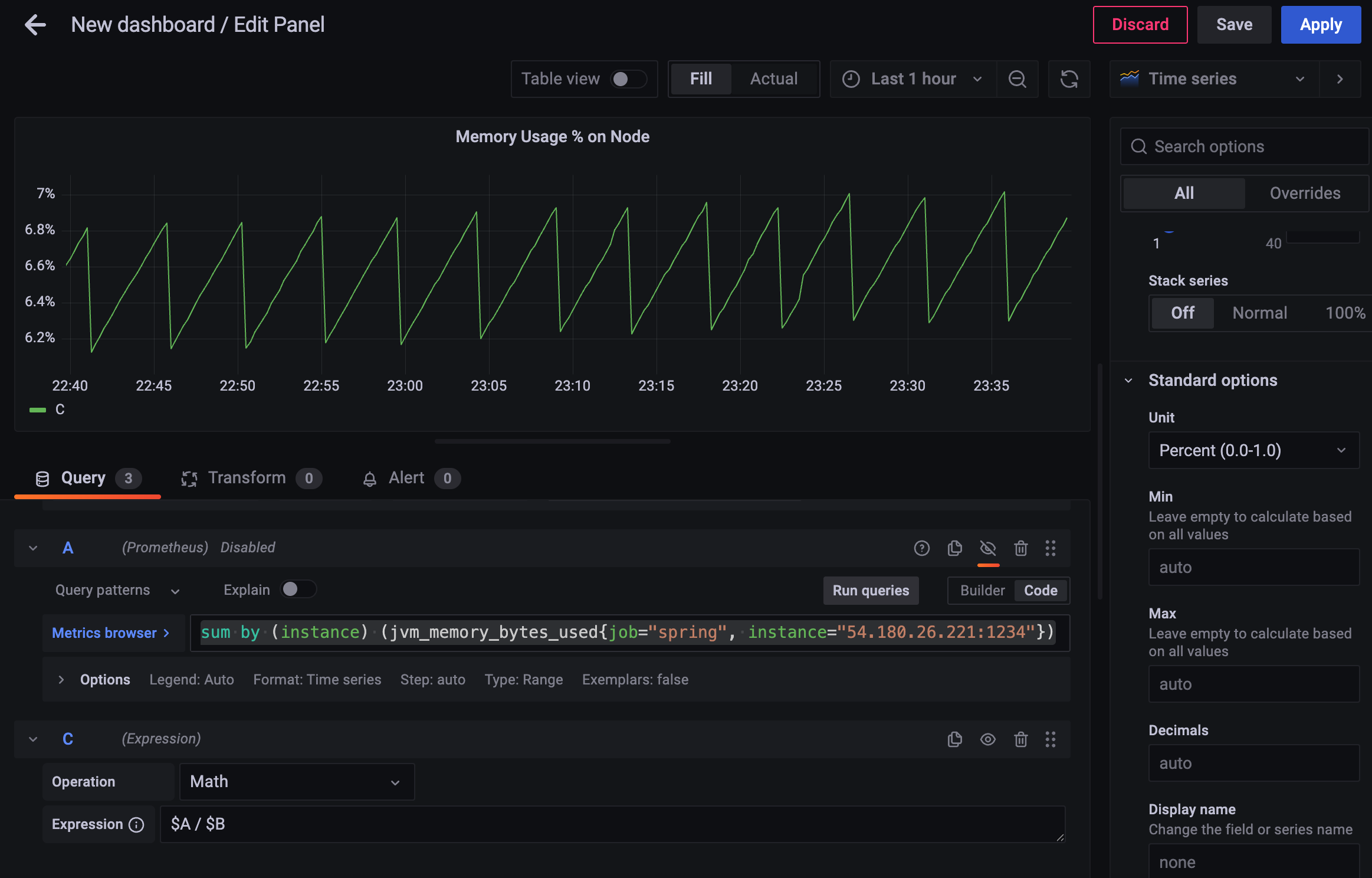
2.1.2 의 쿼리를 A, 2.1.3 의 쿼리를 B라고 했을때,
expression 을 추가하고 Math로 표현식
$A/$B- unit: percentile(0~1)
2.1.4 GC time
{job = "Spring"} , gc를 검색해서 찾아보자

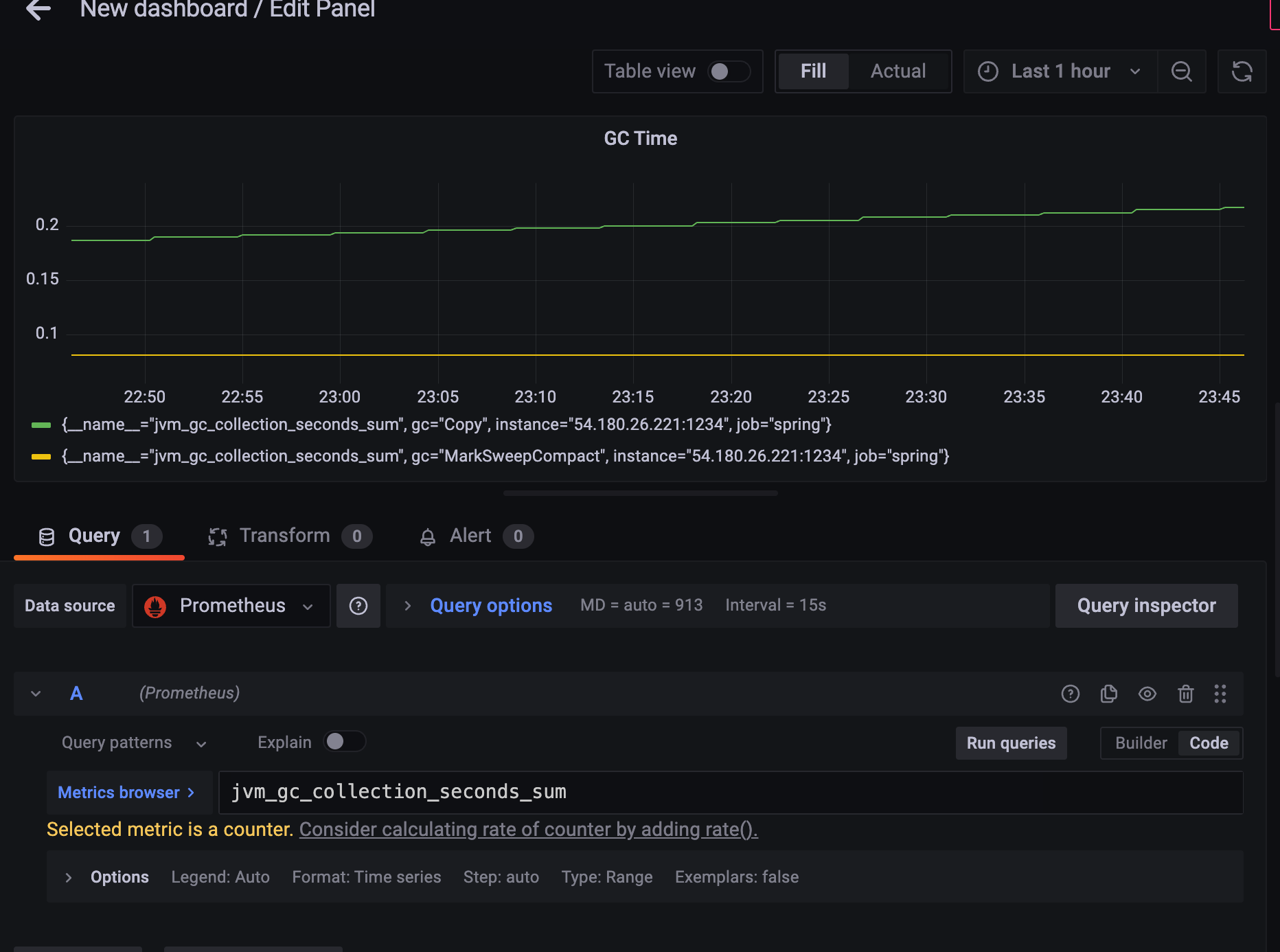
새로운 대시보드를 만들어서
Metrics browser 에서 jvm_gc_collection_seconds_sum 를 검색해보자.
gc가
- Copy
- MarkSweepCompact
두 단계로 나뉘는 것을 확인할 수 있다.
MarkSweepCompact 나눠서 확인하면 좋겠지만
총 GC에 걸린 시간을 알고싶은 것..
jvm_gc_collection_seconds_sum 은 counter 니까
rate() 를 쓰도록 하자
rate는 벡터에다가 쓸 수 있는데, $__rate_interval 예약변수를 쓰면 된다.
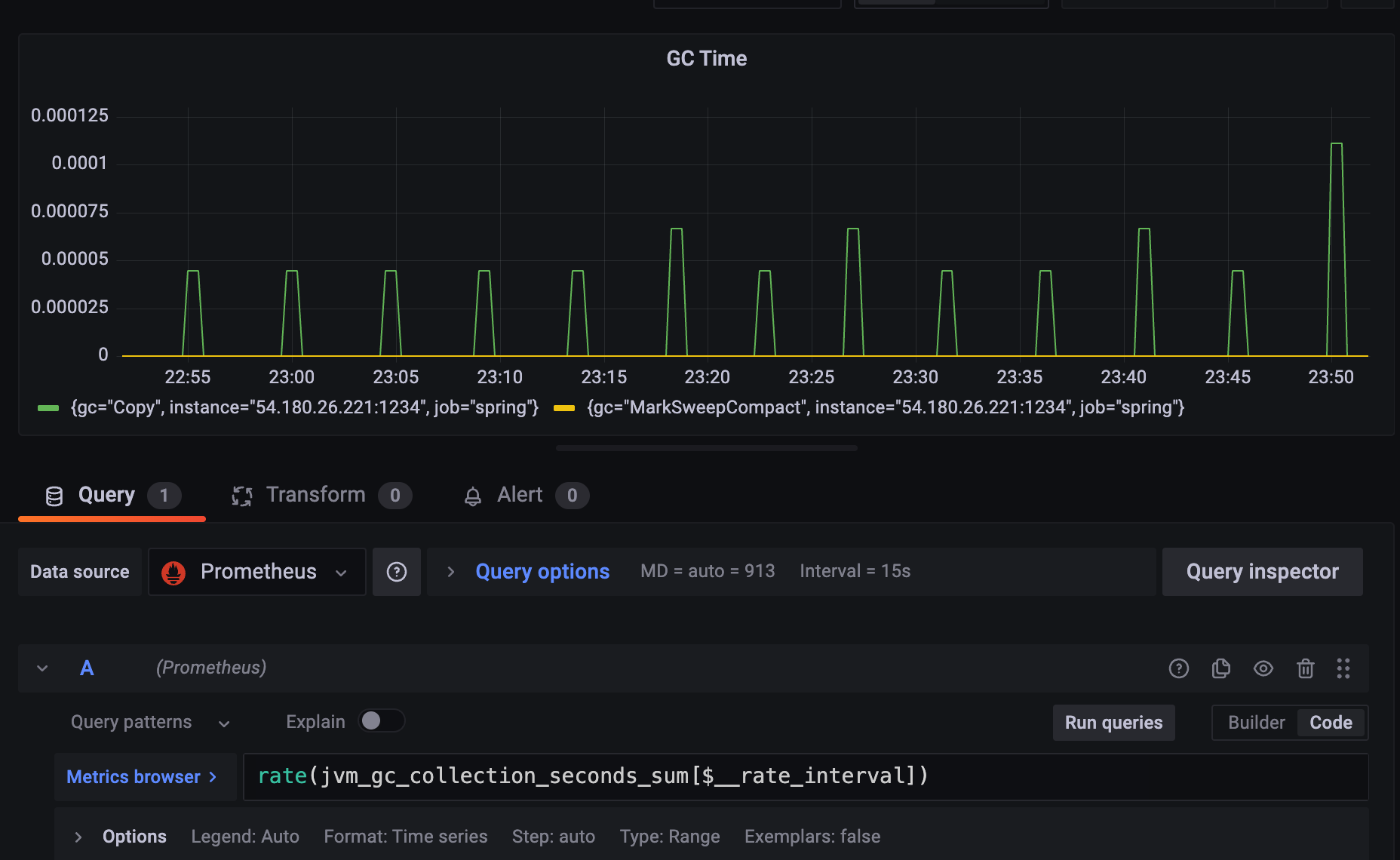
Copy, MarkSweepCompact 합치고 싶다면
sum by (job, instance) (rate(jvm_gc_collection_seconds_sum[$__rate_interval]))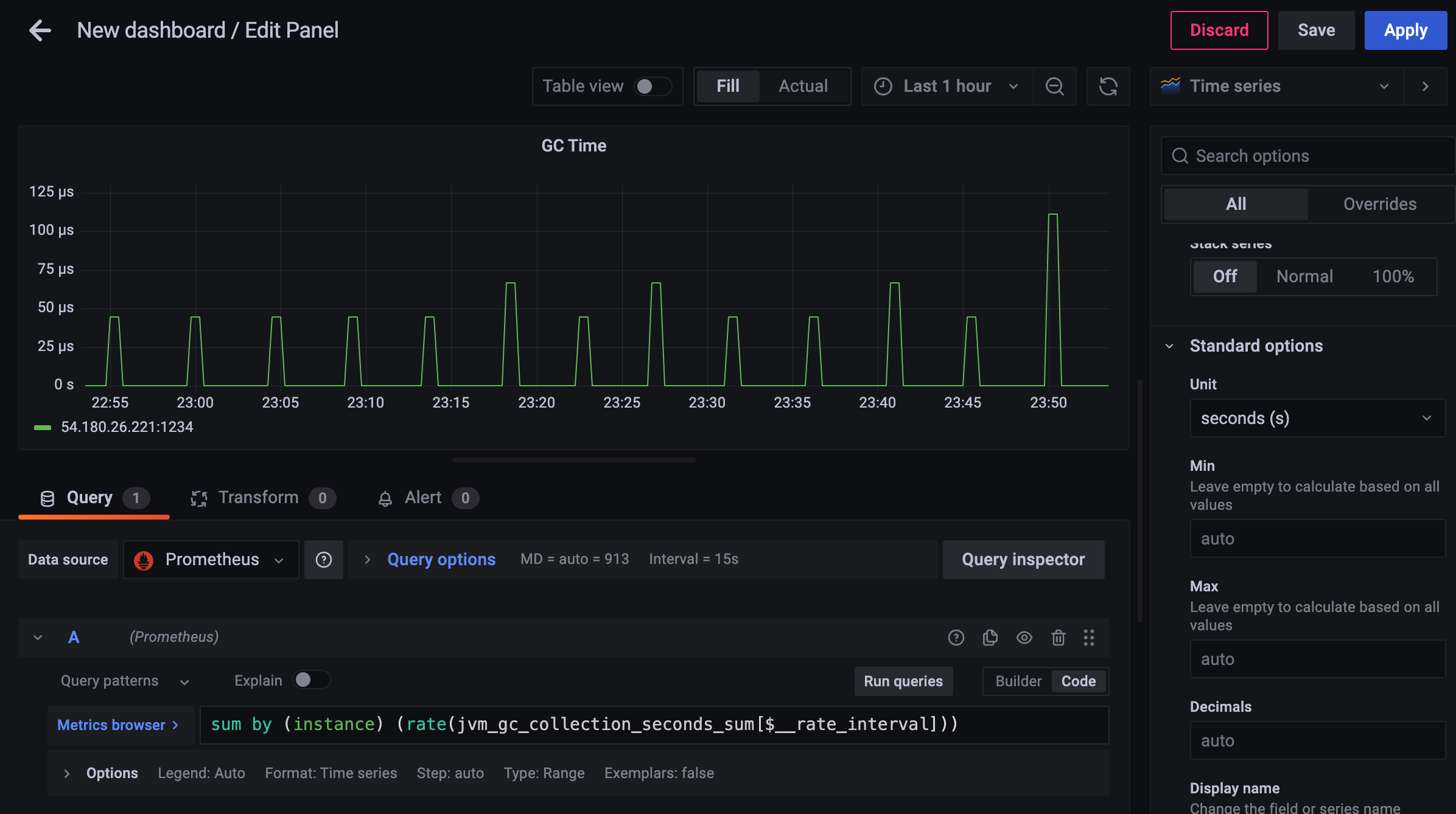
대부분은 0초고, 40 마이크로세컨드 ~ 110 마이크로세컨드 왔다갔다 하고 있어서
GC time은 안정적이라고 볼 수 있다.
2.2 CPU 지표
CPU 지표 구할때 어려운 점 :
현재 prometheus simple client java 에서는 자기 자신의 process_cpu_seconds_total 만 구할 수 있다.
이 값만으로는 cpu usage % 를 구할 수 없다.
cpu는 전체 시스템이 점유한 시간 대비 이 프로세스가 점유한 시간 해야 사용률을 구할 수가 있다.
그래서 node 에 있는 모니터링 정보랑 같이 조합해야됨.
2.2.1 node exporter 의 값으로 기간의 cpu seconds total 구하기
우선 node 에 대한 cpu 지표를 뽑아야 하는데,
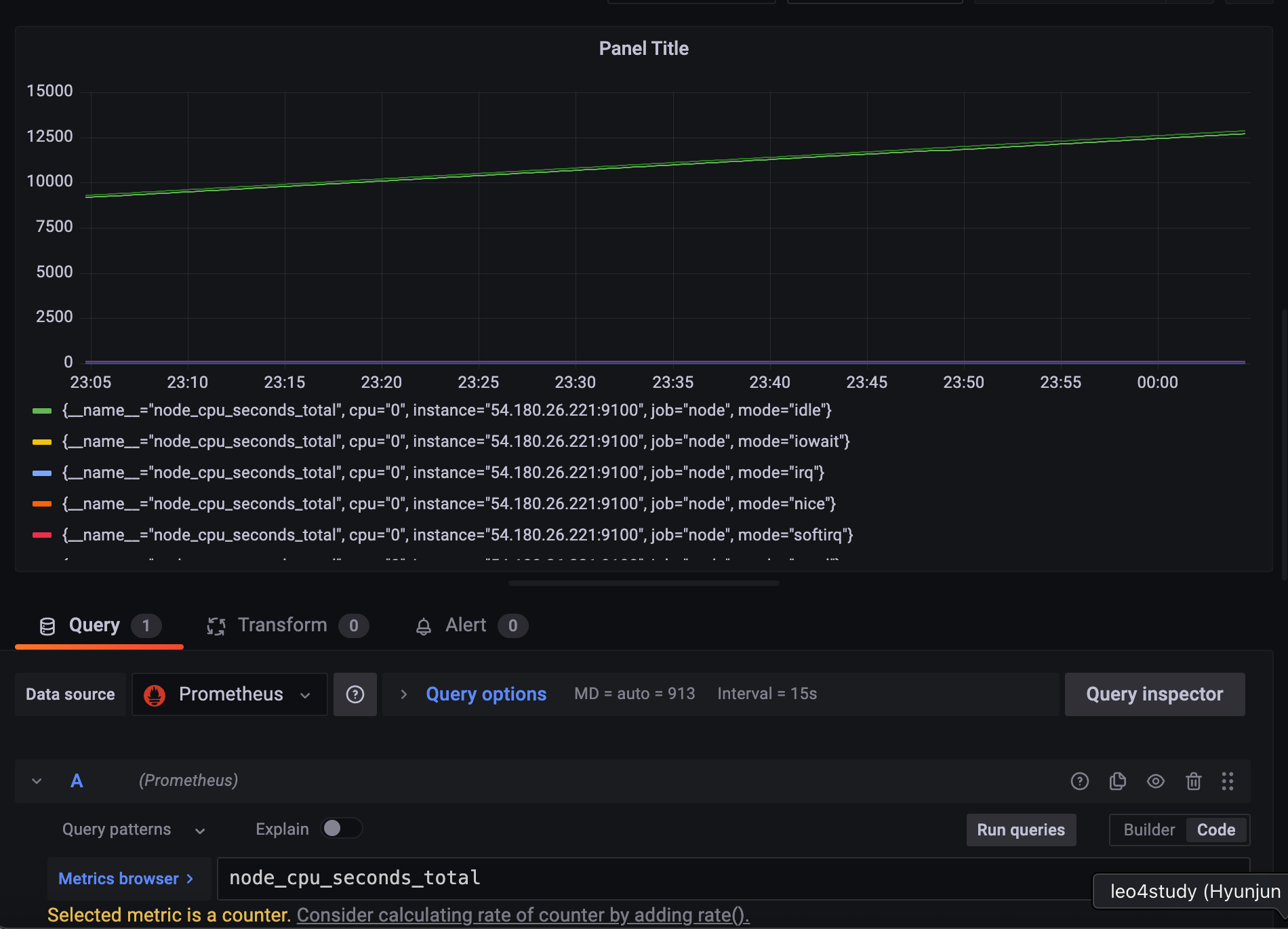
종류가 꽤 많다.
스프링이 뜬 어플리케이션만 보기 위해 인스턴스 설정을 하고
counter 니까 rate() 함수를 사용해주자.
cpu_time을 얼마나 썼는지가
각 노드에 mode단위로 나눠서 나오고 있다.
전체 CPU time을 구하고 싶다면 더해줘야 함.
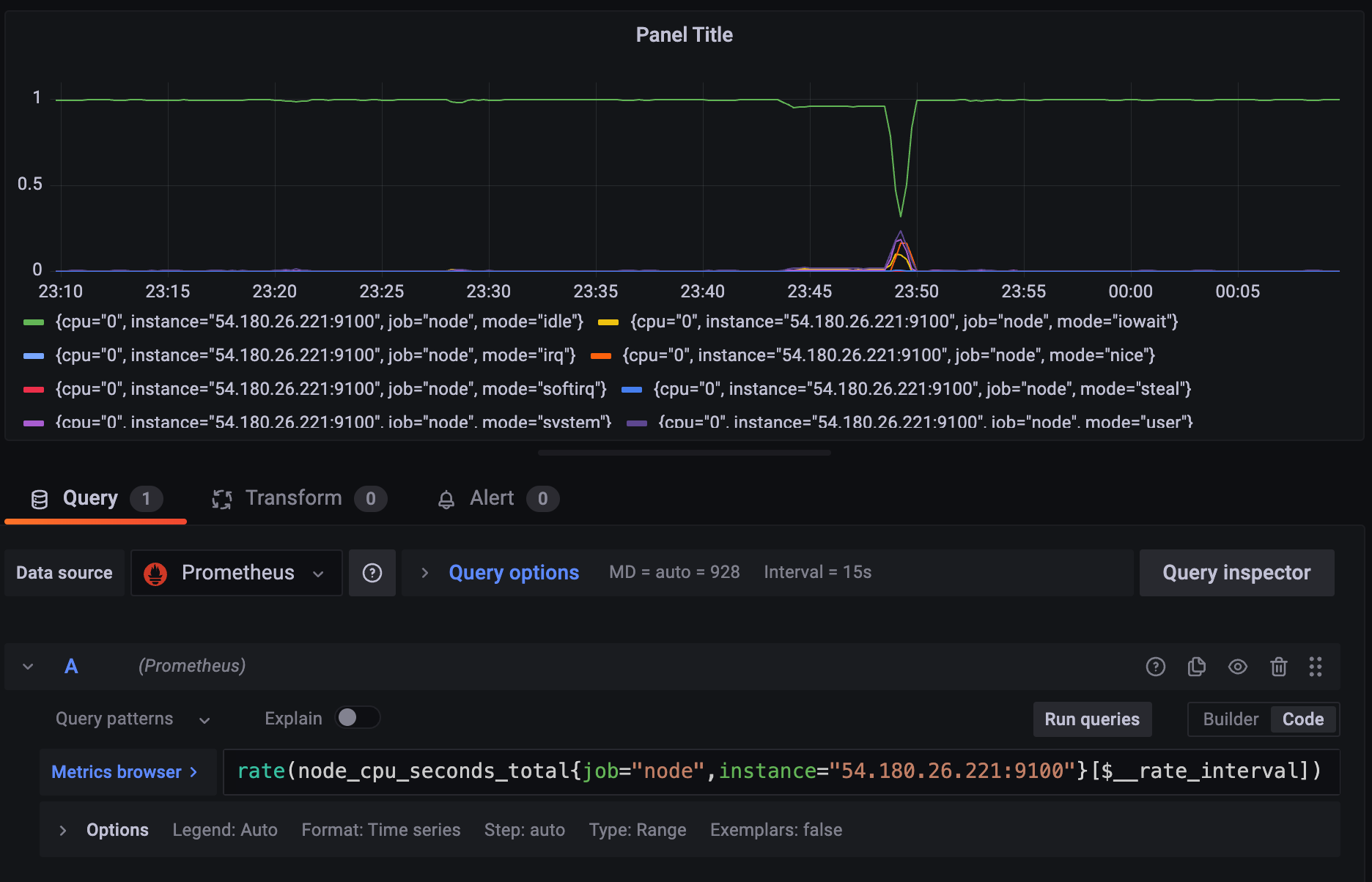
sum by (instance) (rate(node_cpu_seconds_total{job="node",instance="54.180.26.221:9100"}[$__rate_interval]))위 공식으로 node_cpu_seconds_total 을 type과 관련없이, instance 별로 구할 수 있다.
당연히, 전체 CPU time은 1이 되어야 하는데, 약간의 오차가 있을 수 있다.
2.2.2 rate 로 단위 구간당 cpu seconds total
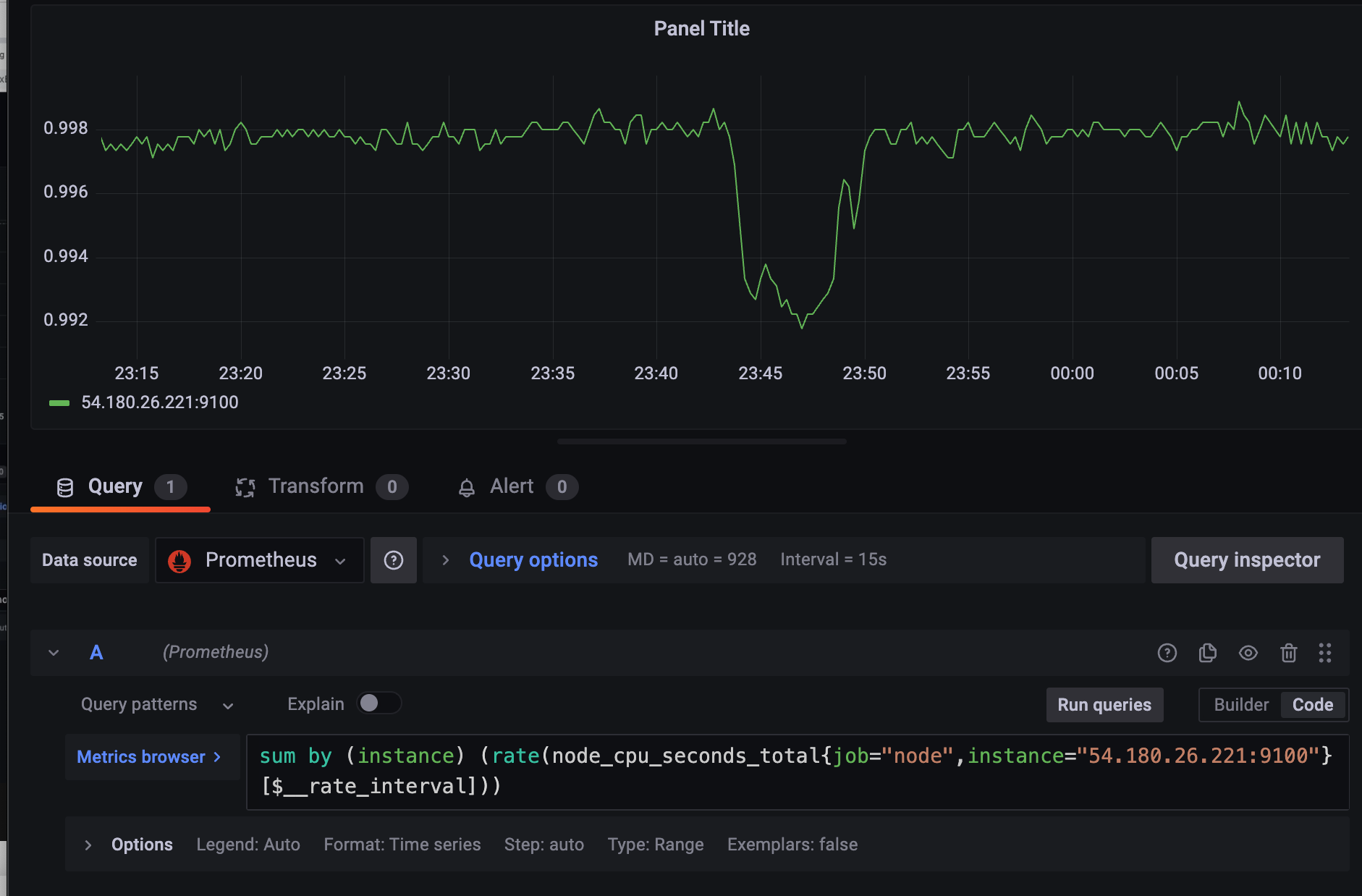
rate(process_cpu_seconds_total{job="spring", instance="$your_instance"}[$__rate_interval]) >= 02.2.3 별도의 두개의 query 결과를 이용하는 Math 수식 활용하기
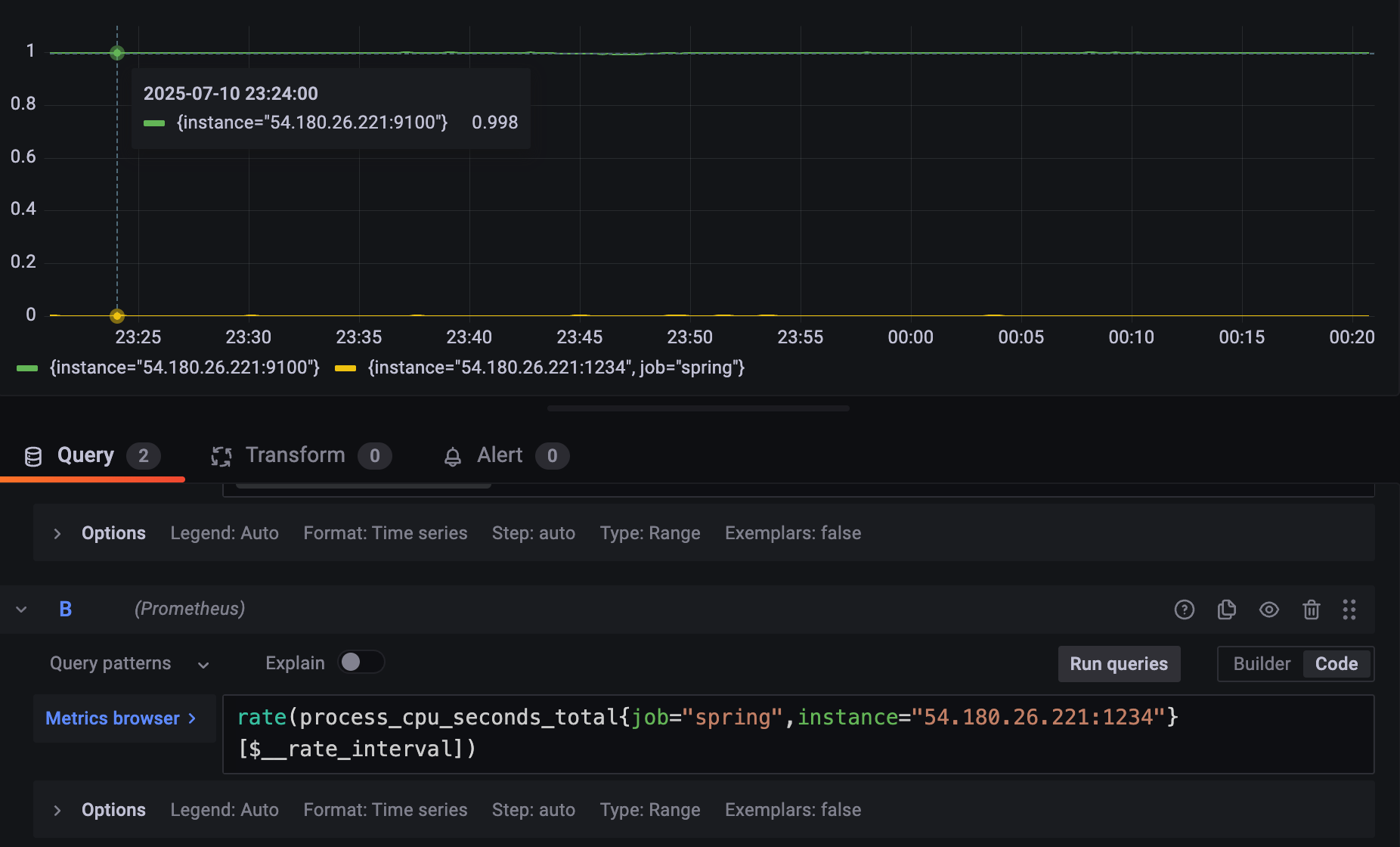
2.2.1의 쿼리를 A
2.2.2의 쿼리를 B 로 했을때,
C query 를 만들고, operation을 Math 로 한다.
다음 수식으로 비율%를 구할 수 있다.
$B / $A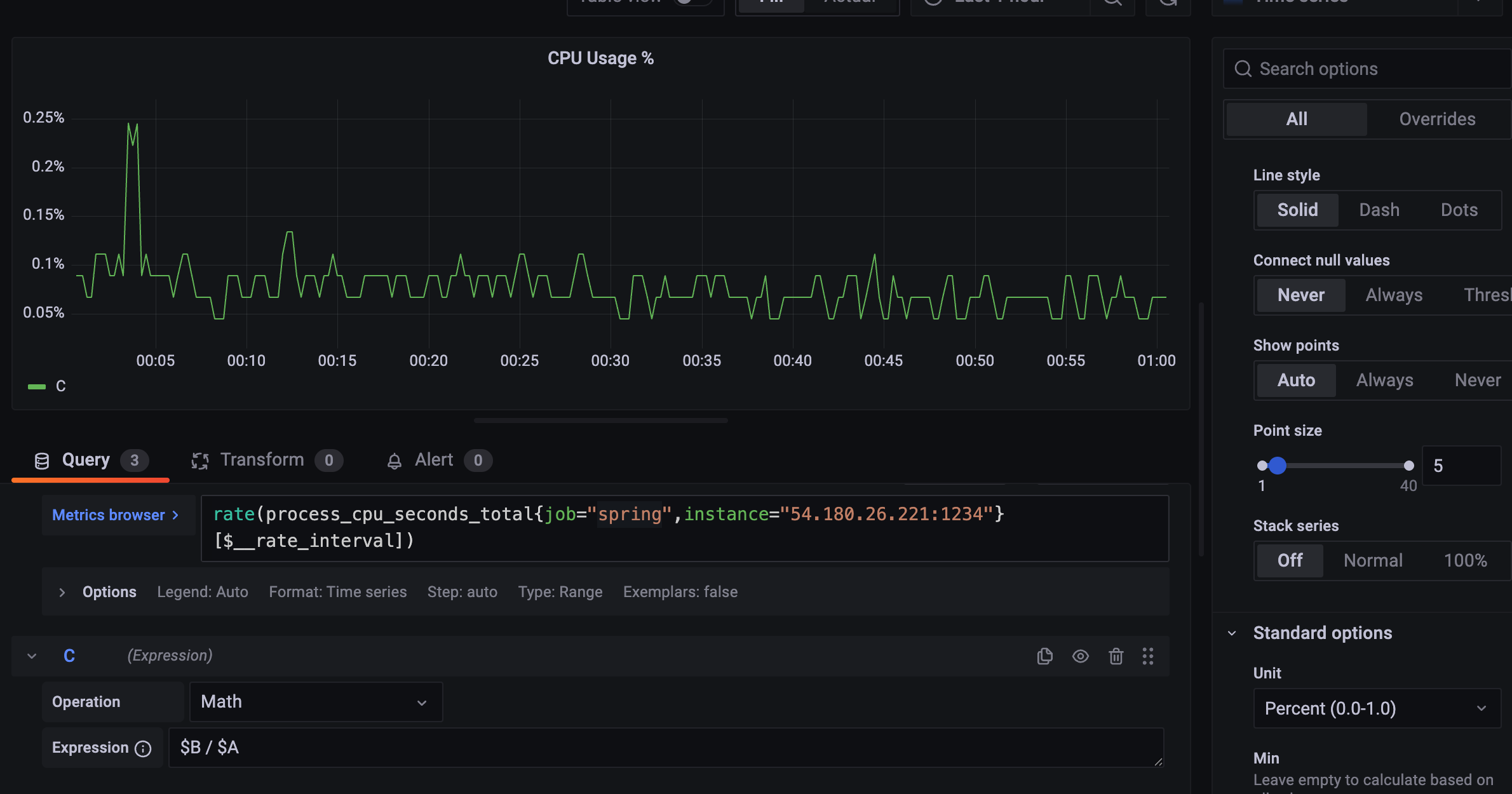
CPU를 0.05%~0.2% 로 1%도 안 쓰는 것을 확인할 수 있다.
2.2.4 확인
CPU사용율이 낮다면, 예제에 있는 /cpurun API를 호출하면 무한루프를 돌면서 cpu 사용율이 치솟는다.
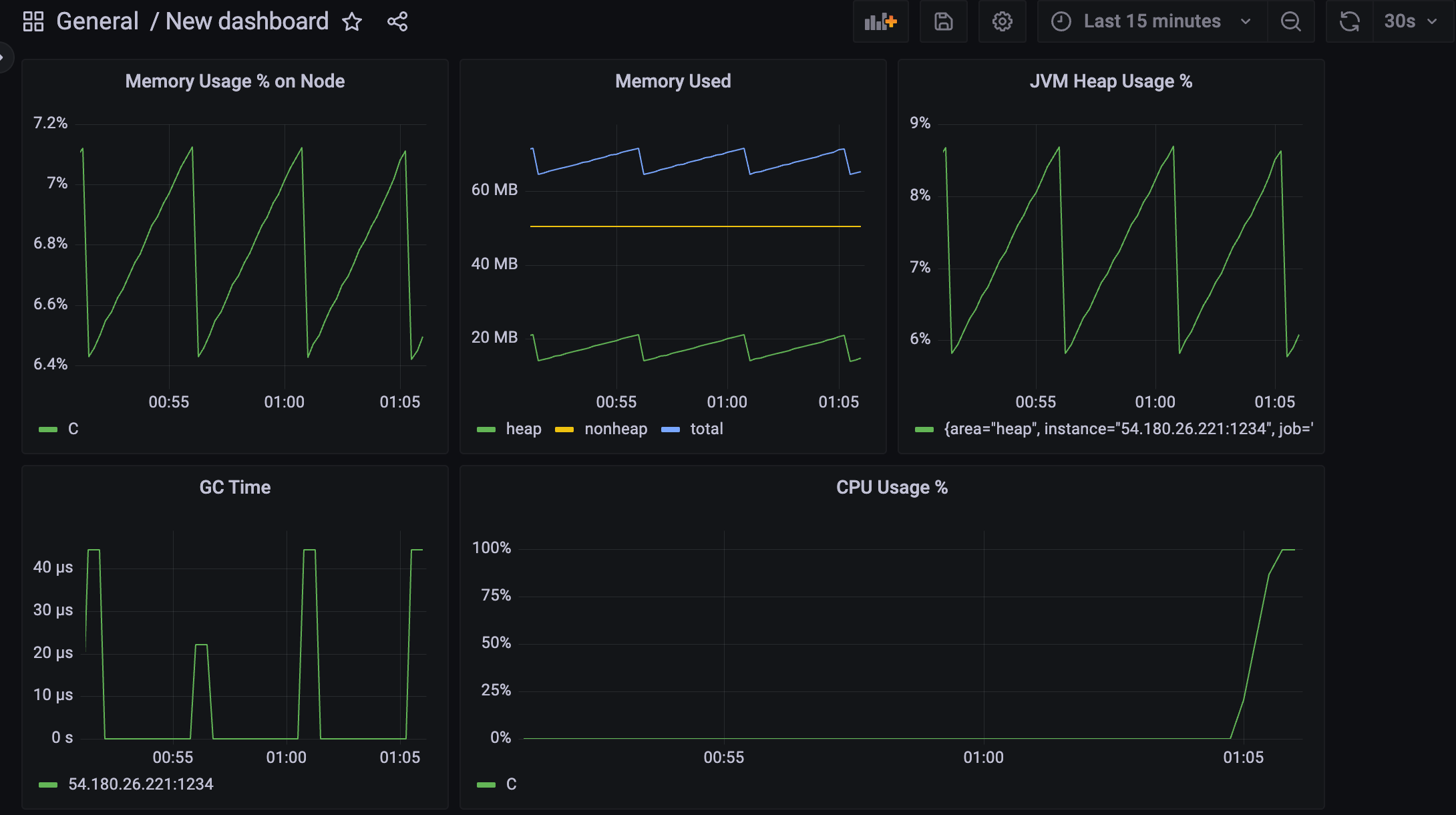
단순히 while만 도는 거니까 memory 사용률은 변하지 않는 것을 알 수 있다.
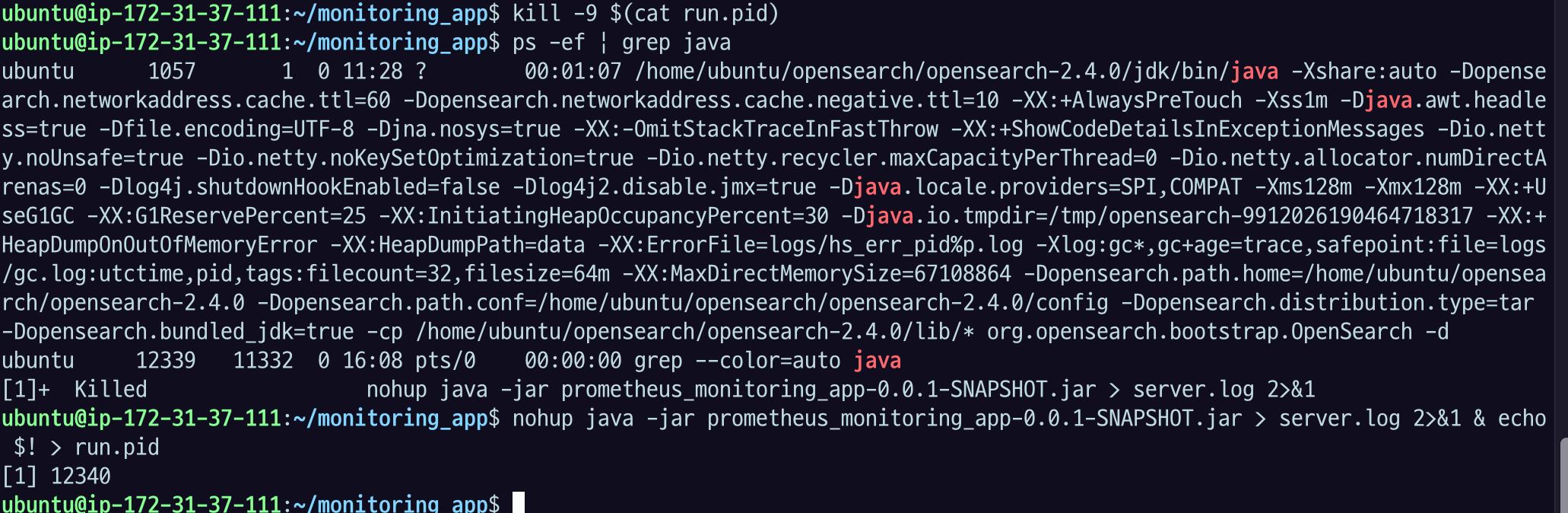
kill -9 으로 종료시켜주고 다시 실행시켜 주자
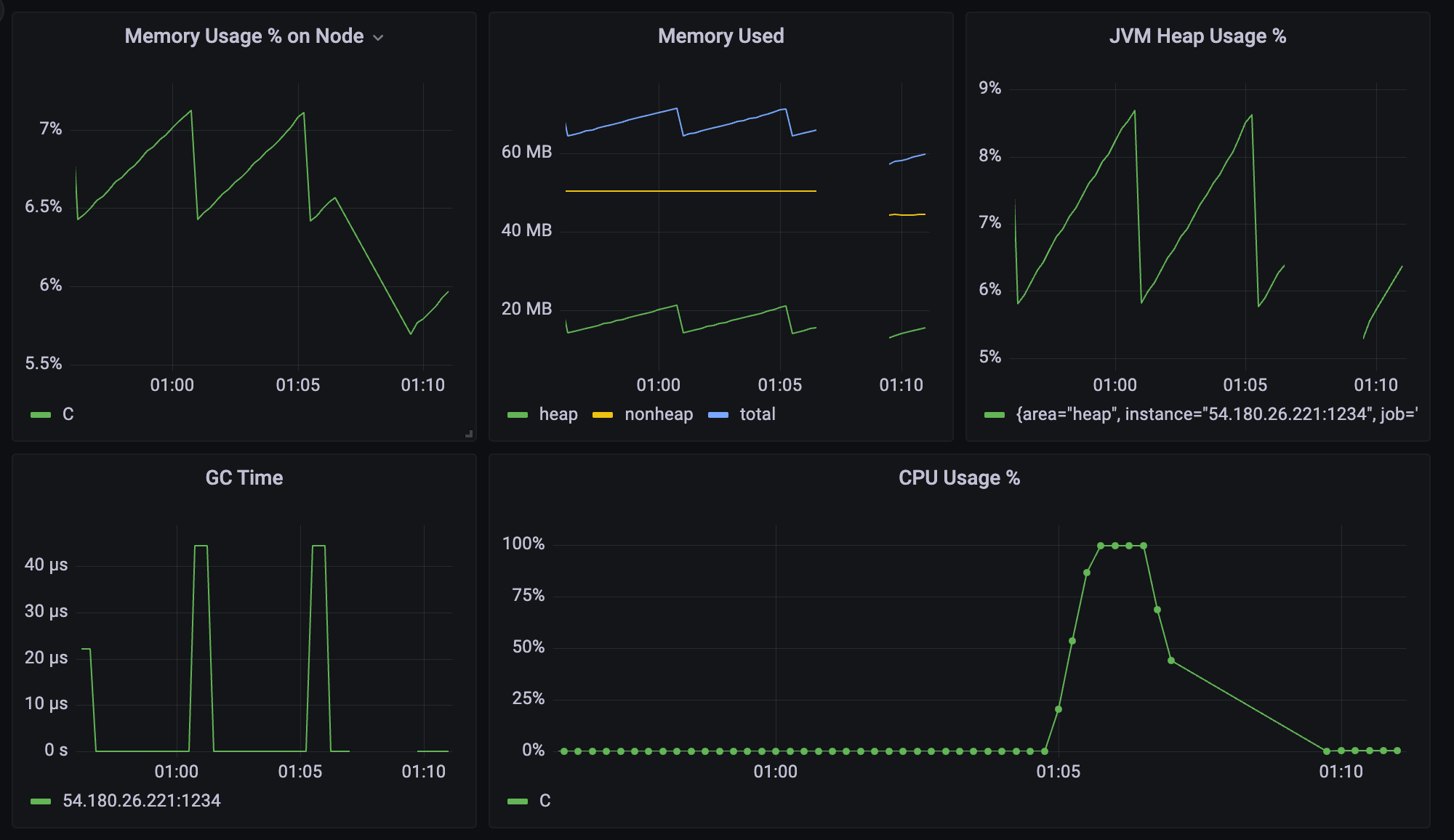
cpu 사용률이 줄어드는 모습.
실제로는 바로 0로 떨어져야 하는데, rate함수를 썼기 때문에 천천히 줄어드는 것 처럼 보인다.
2.2.5 대안
가장 좋은 것은, app에서 node(system)의 cpu_seconds_total 을 제공해서 하나의 대상에 대해서 계산을 하면 좋다. (한 번에 계산하거나), 아예 usage % 를 제공하는 것이다.
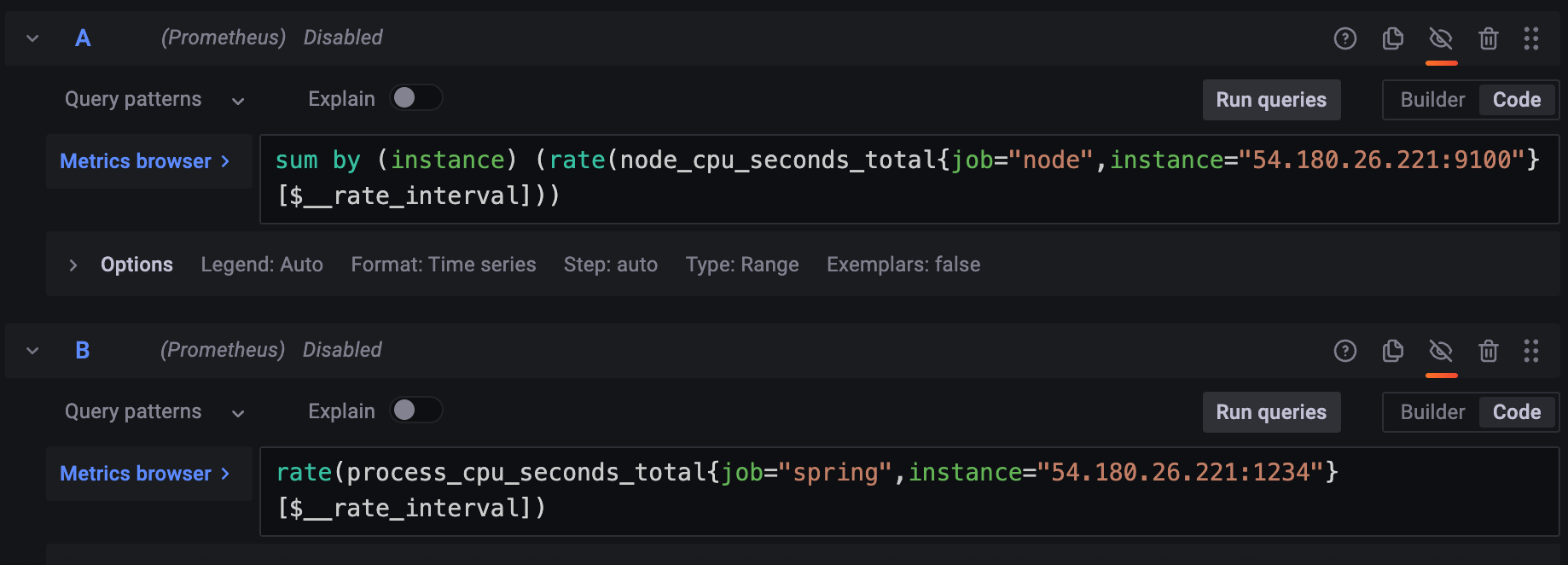 이 수식은 별로 좋지 않은 게, A인스턴스랑 B인스턴스가 명확히 다르다. port번호가 다르니까. 수집하는 대상이 달라서 rate를 이용해 계산을 할 수는 있지만 아예 같은 대상의 CPU시스템의 total 을 제공하거나 아예 퍼센트를 제공하는 게 좋다.
이 수식은 별로 좋지 않은 게, A인스턴스랑 B인스턴스가 명확히 다르다. port번호가 다르니까. 수집하는 대상이 달라서 rate를 이용해 계산을 할 수는 있지만 아예 같은 대상의 CPU시스템의 total 을 제공하거나 아예 퍼센트를 제공하는 게 좋다.
- Spring Framework 자체 메트릭 시스템은 이것을 제공한다.
2.3 Filesystem
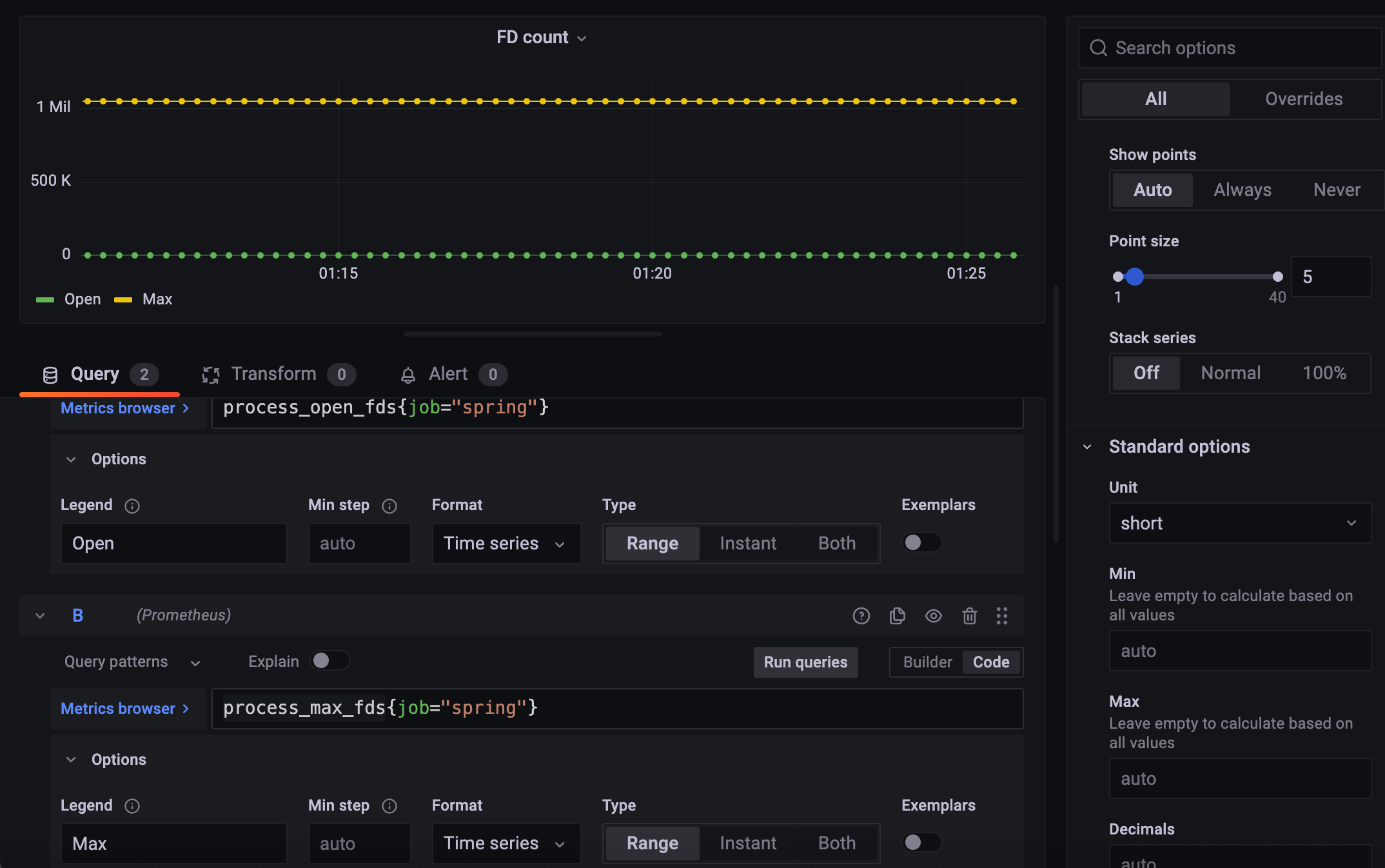
리눅스에서는 FD는 중요한 요소다.

프로세스당 할당할 수 있는 최대 FD랑 현재 열고 있는 FD
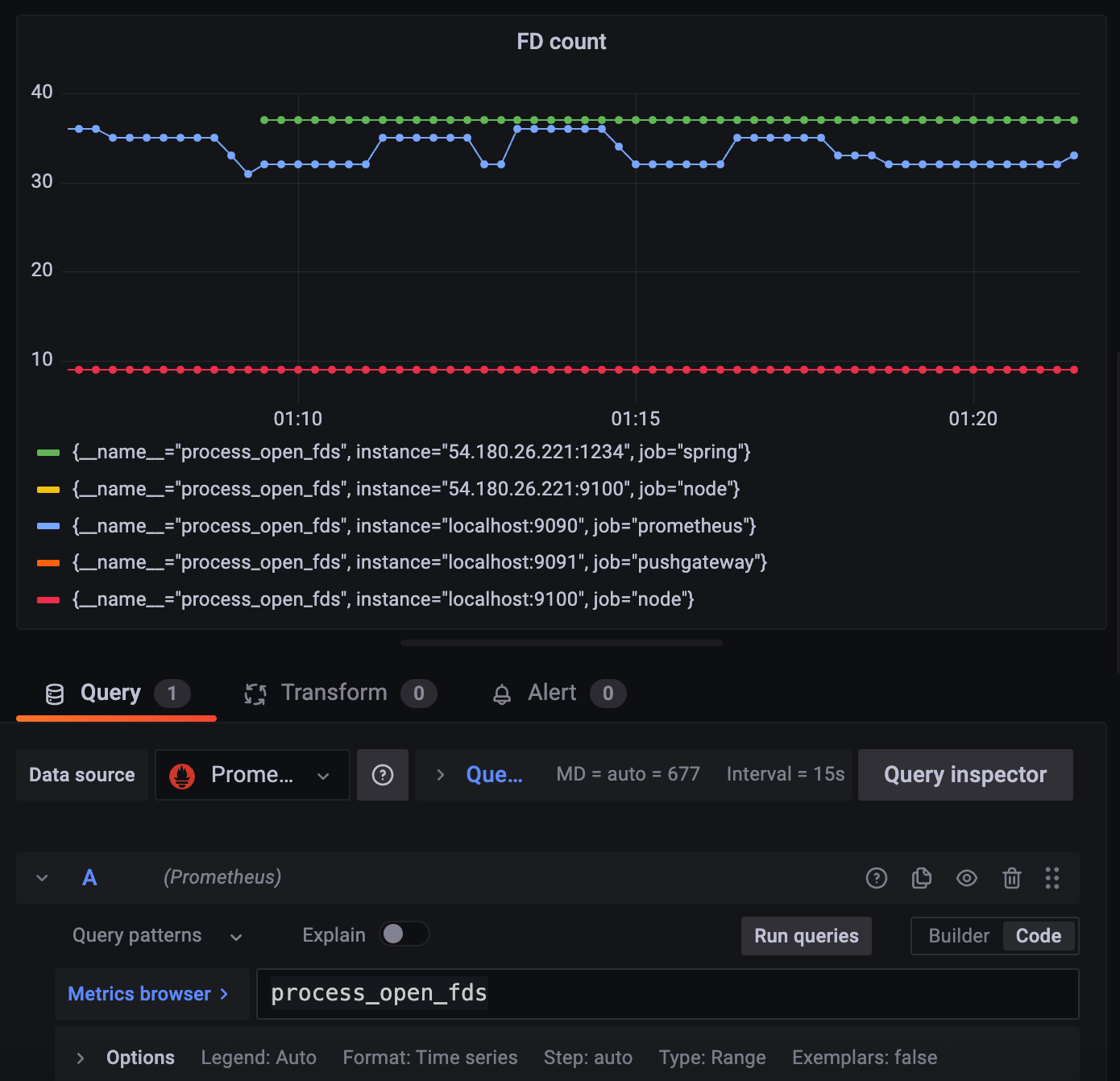
현재 쓰고 있는 FD들이 나온다.
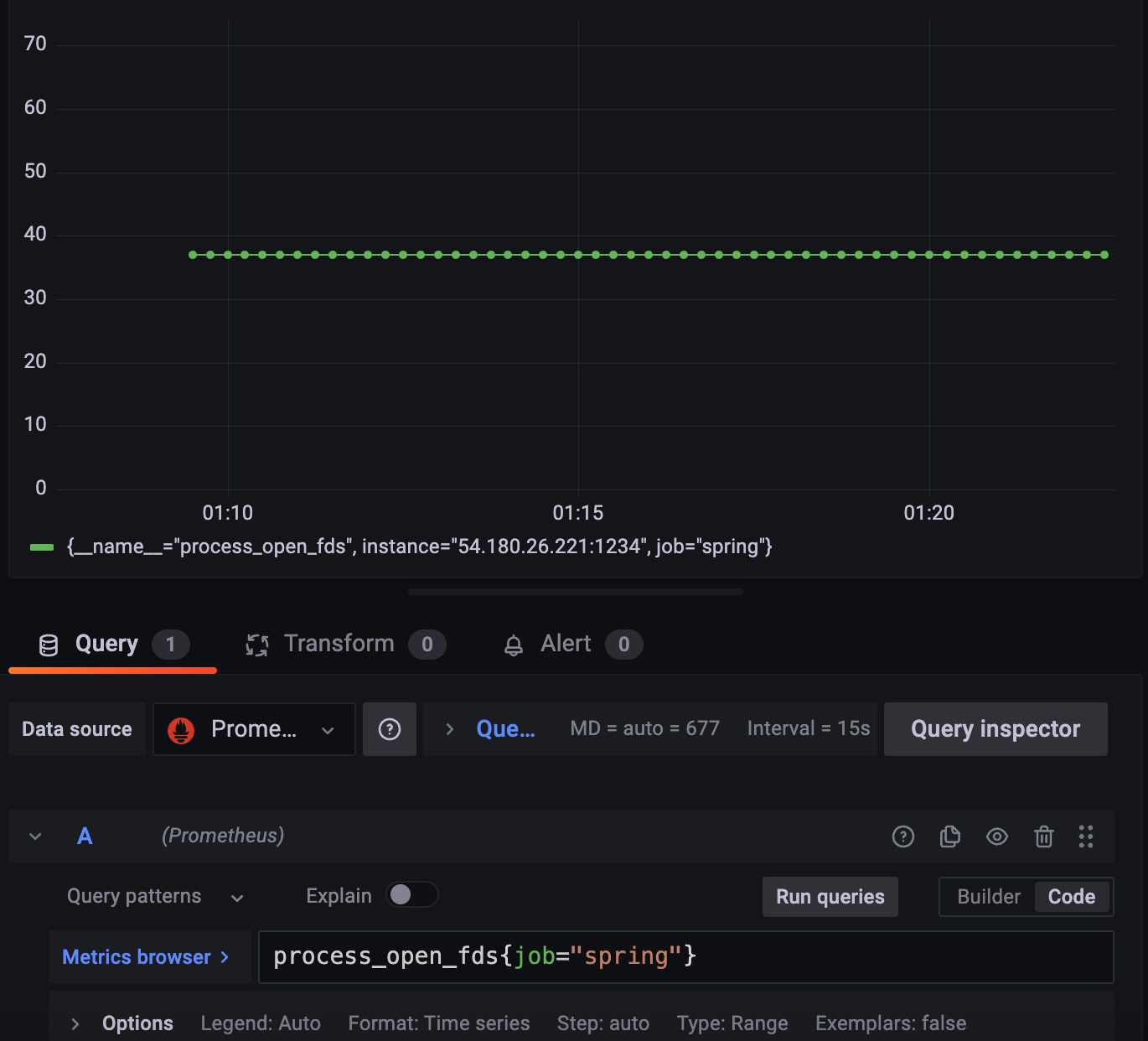
FD는 숫자 자체만으로도 의미가 있다.
2.3.1 FD count