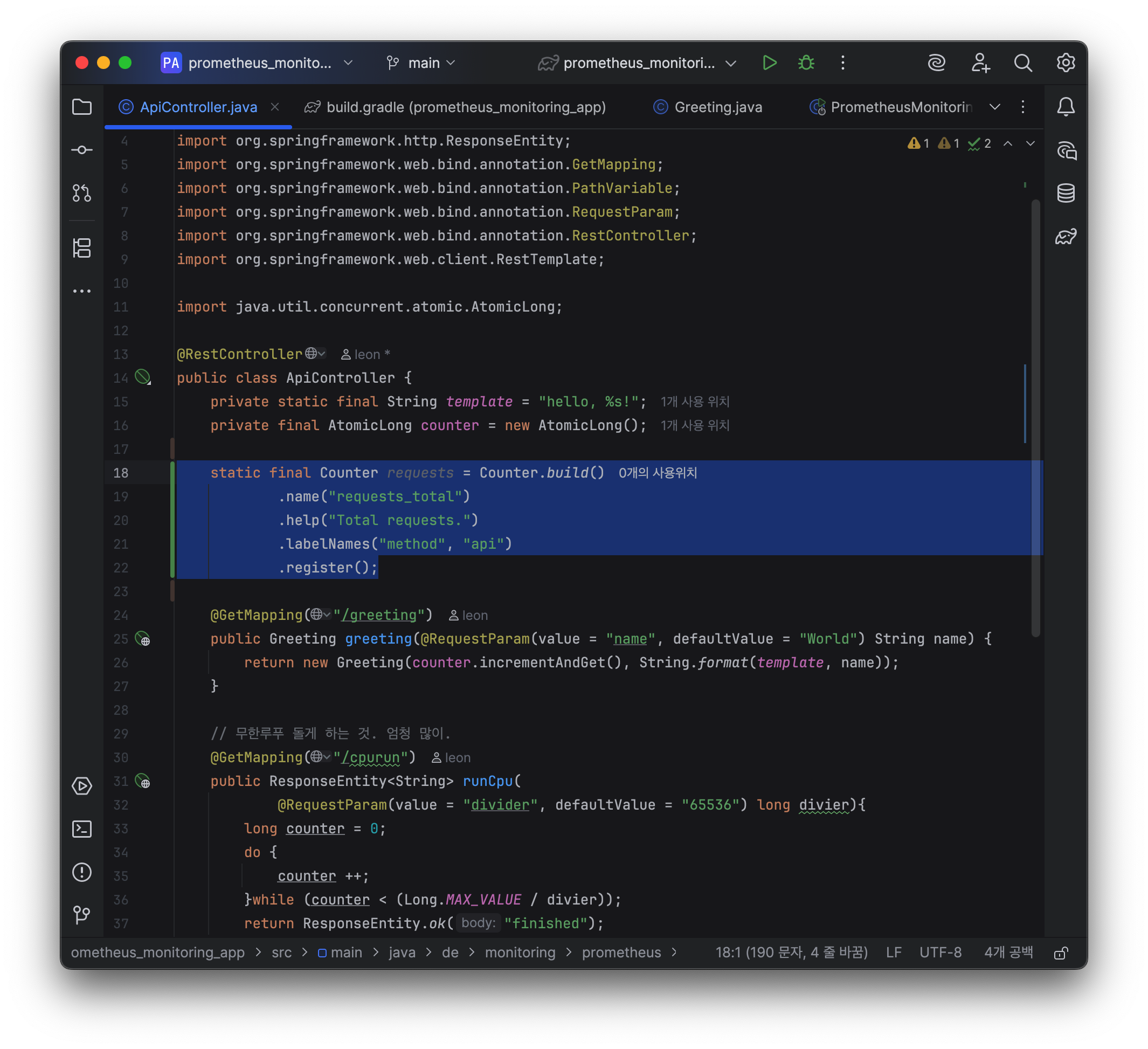
3.1 Metric 선언 및 정의 방법
(자바의 경우)
-
내가 원하는 매트릭 타입을 먼저 찾는다(counter, gauge, histogram, summary)
-
매트릭 빌더 부르고
-
name 설정하고
-
help설정하고
(각 metric마다 # 해서 위에 설명 써지는 거) -
label 있는 경우 labelNames를 파라미터 String의 멀티파라미터로, varargs로 넣는다. (필수는 아님, 라벨 넣을 때 순서 주의.)
-
register() 는 default Register가 되고 register 객체를 직접 사용하려면 여기에 파라미터를 넣으면 된다.
static final Counter requests = Counter.build()
.name("requests_total")
.help("Total requests.")
.labelNames("method", "api")
.register();- 한 번 선언된 메트릭은 static으로 JVM 내에서 global 영역에 존재해야 한다.
- builder pattern 으로 설정한다.
- label 이 있다면 string varags 로 세팅한다.
- label 은 사용할때 순서대로 맞춰넣어야 하므로 순서가 중요하다.
- register 에서
CollectorRegistry를 지정하지 않으면, default registry 를 사용한다.- 다른 framework 내장 registry 와 연동하려면 해당 객체를 등록해주던가, 아니면 default registry 를 역으로 해당 framework 에 등록해야한다.
3.2 Counter 사용하기
3.2.1 정의
API 호출 수를 count 하기 위한 counter 정의.
static final Counter requests = Counter.build()
.name("requests_total")
.help("Total requests.")
.labelNames("method", "api")
.register();requests_total 구할 건데, HTTP method랑 API path를 api path를 label로 받을 것.
- label 로 HTTP method 와 API 종류를 구분할 수 있게 한다.
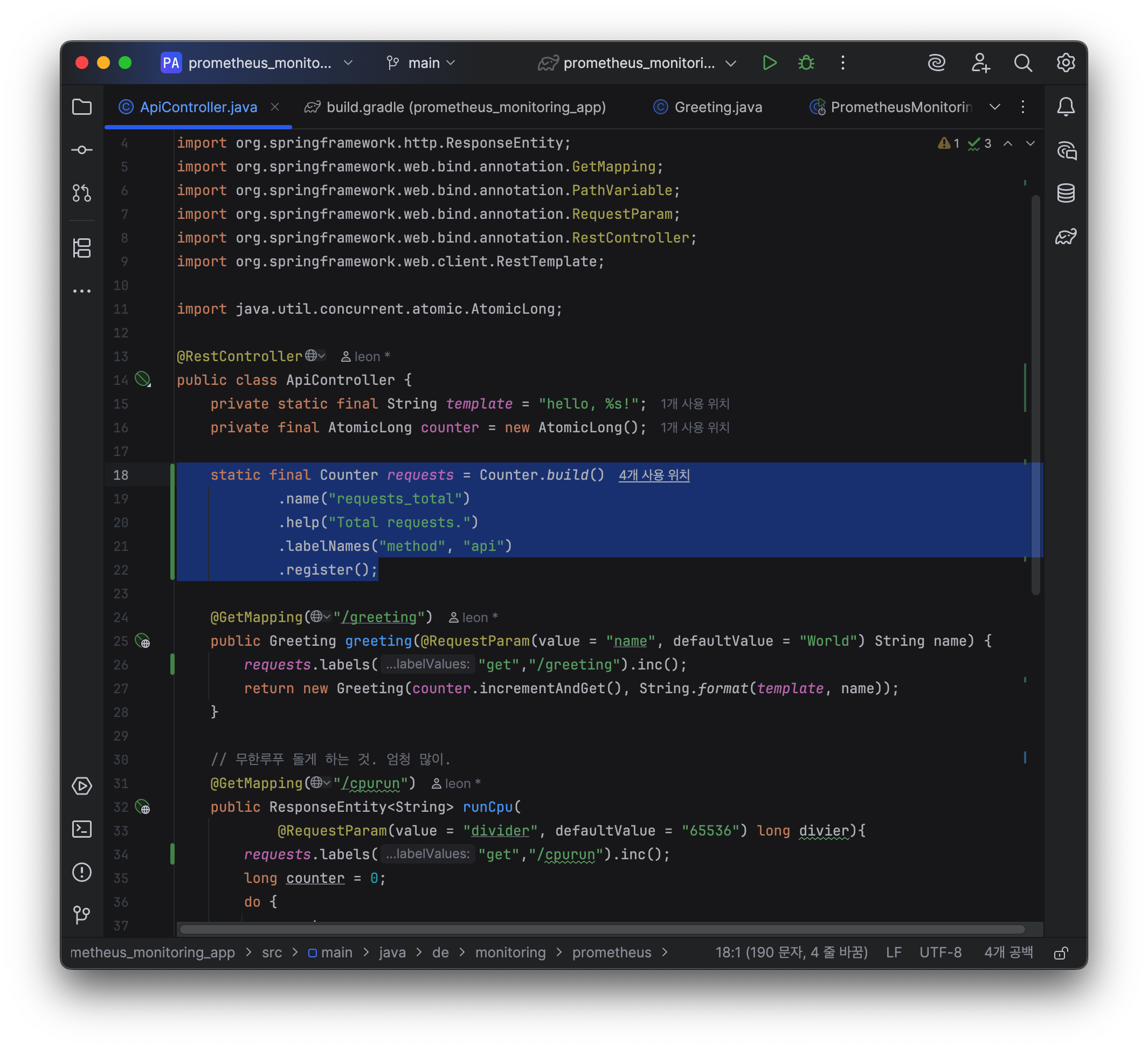
이렇게 넣어 주고 API의 각 메소드에 다음과 같이 api 별로 count를 할 수 있도록 한다.
requests.labels($http_method, $api).inc();- 각 메소드에 맞게 $http_method, $api 값을 넣는다.
- inc() 는 atomic 하게 해당하는 counter 를 increment ( = +1) 한다.
- inc(amount) 함수로 원하는 양만큼 증가시킬 수도 있다.
- 얘는 단방향 증가니까 감소하는 함수 자체가 없다.
각 메소드 별로 위에서 만든 requests 객체를 이용해서 남길 때,
아까 requests build 할 때,
.labelNames("method", "api") 이 있었다.
이렇게 라벨이 있는 친구는 무조건 꼭$http_method,$api라벨을 남겨줘야 함.
나는$api라는 라벨 값 안 넣을 건데? 그런 경우엔 null 이라도 넣어 줘야 함.
라벨 규칙을 꼭 맞춰서 넣어주자.
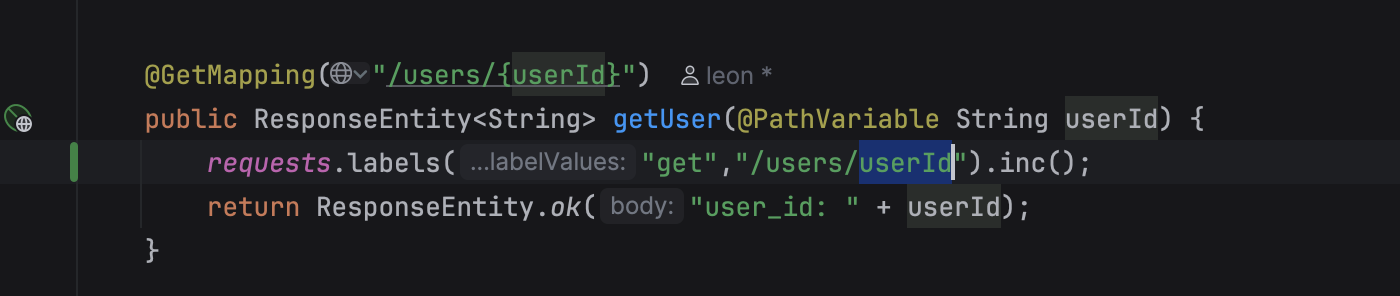
여기서는 userId 가 변수니까 하나하나 path니까 labels에 넣을 수도 있는데 그렇게 하진 않았다.
그렇게 하면 이 API 라는 Label에 붙는 Cardinality가 굉장히 많아진다. userId 카디널리티가 많은 게 문제가 되지는 않지만
타임시리즈가 , 시계열 데이터가 얼마나 많은 범위에 걸쳐 있는지가 집계에 좀 더 큰 영향을 미침 (그래서 한 달 이상을
저장하는 것을 지향)
하지만 Cardinality가 너무 많은 것도 데이터 집계할 떄 약간의 부하를 주기는 한다. (근데 필요하면 써야됨.)
그치만 userID를 개별로 남기는 것 자체는 그정도까지 metric으로는 필요가 없을 듯. 그거는 나중에 데이터베이스에서 분석가들이 조회해서 분석하는 식으로 해야 되지 매트릭 자체로 남길 필요는 x
자 이제 build 해서 배포해야 되는데, 이전 버전과 구분되어야 하니까,
version = '0.0.2-SNAPSHOT'
으로 수정하고 bootJar 실행해서 jar 파일 만들고
Appserver에 보내자.

문제없이 잘 되는 중!
이제 app server의 api 호출해보자.
새로고침 마구 누르는 중..
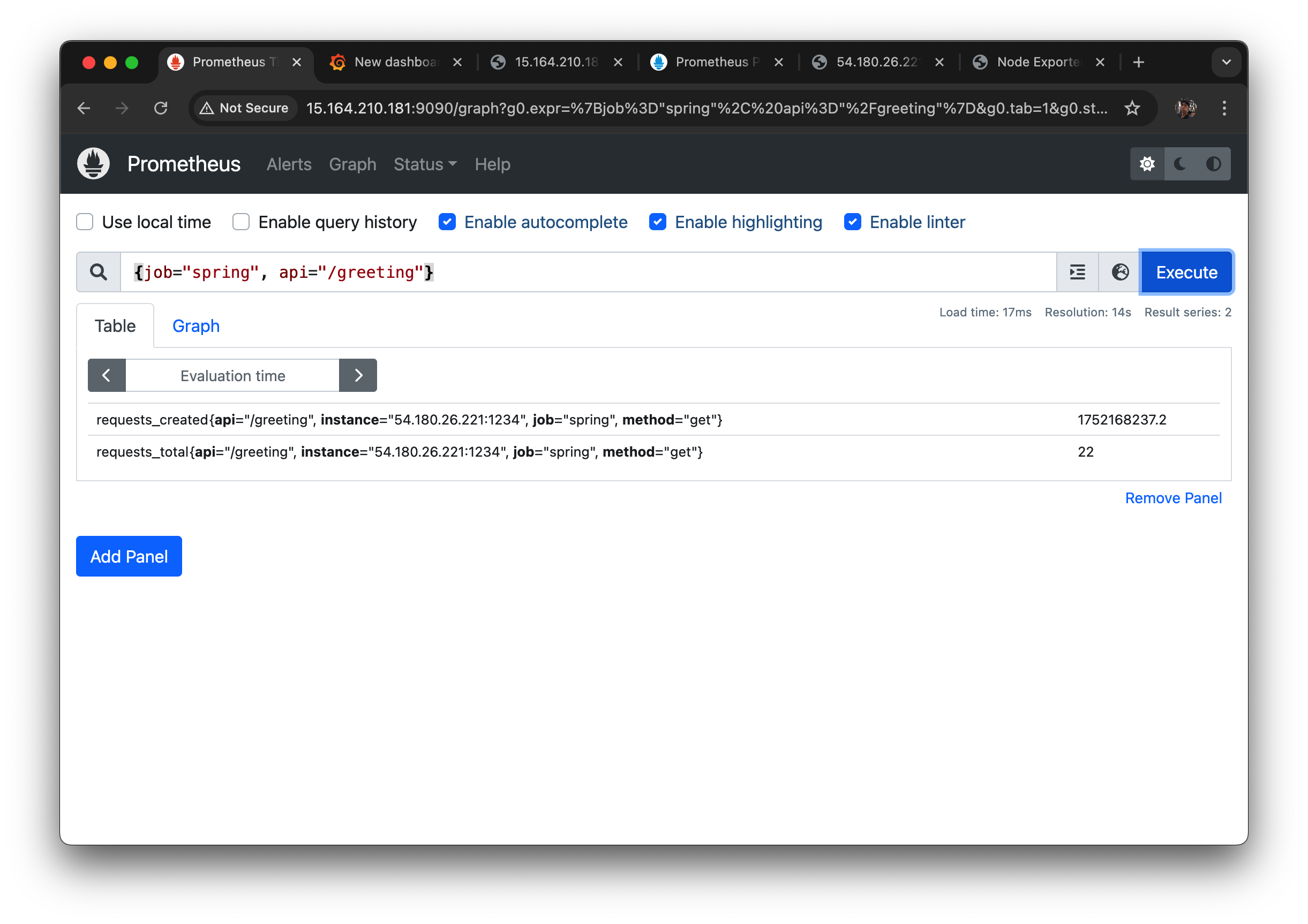
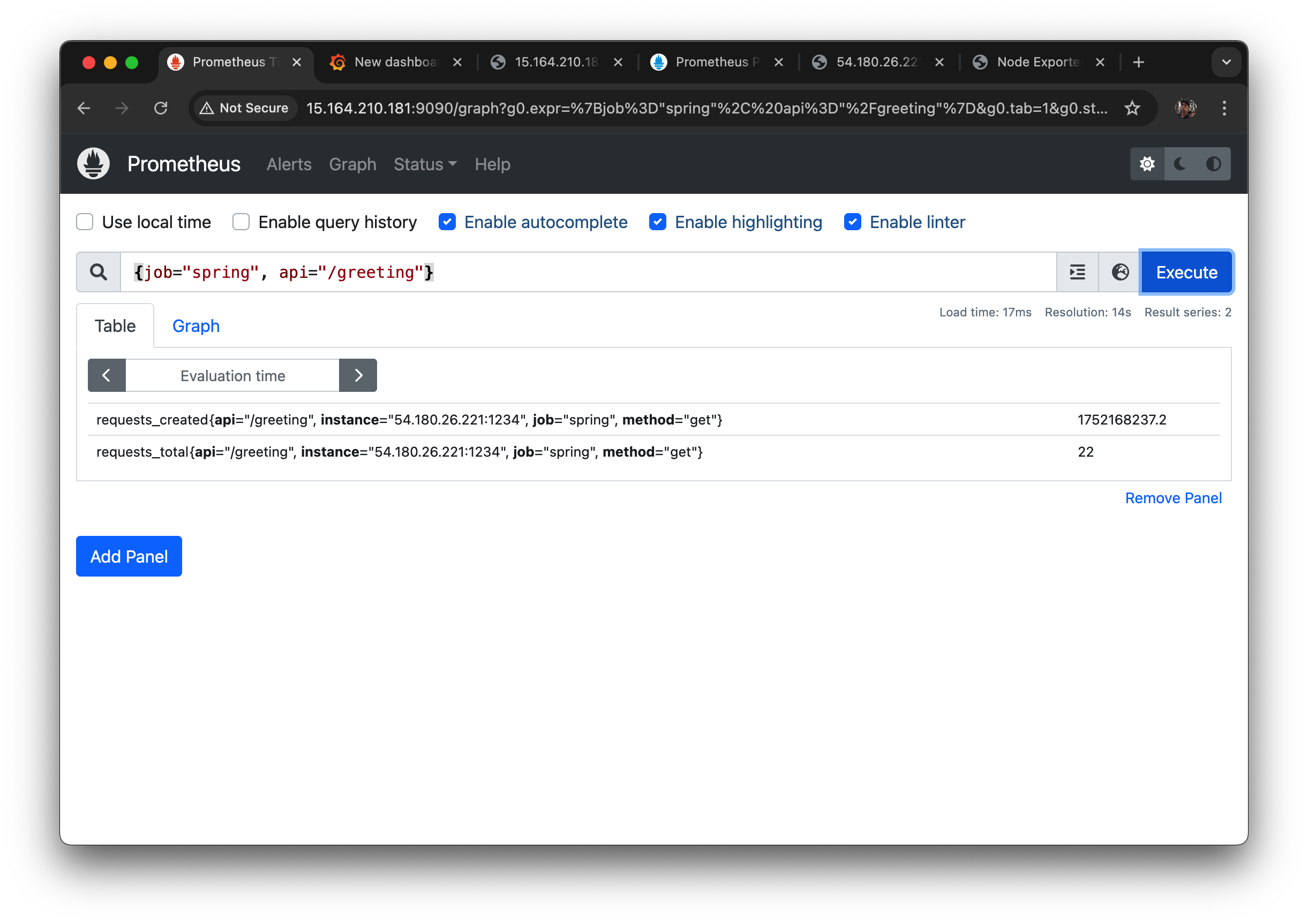
프로메테우스 매트릭에서 확인해보면
request total이 22개로 count가 잘 된 것을 확인할 수 있었다.
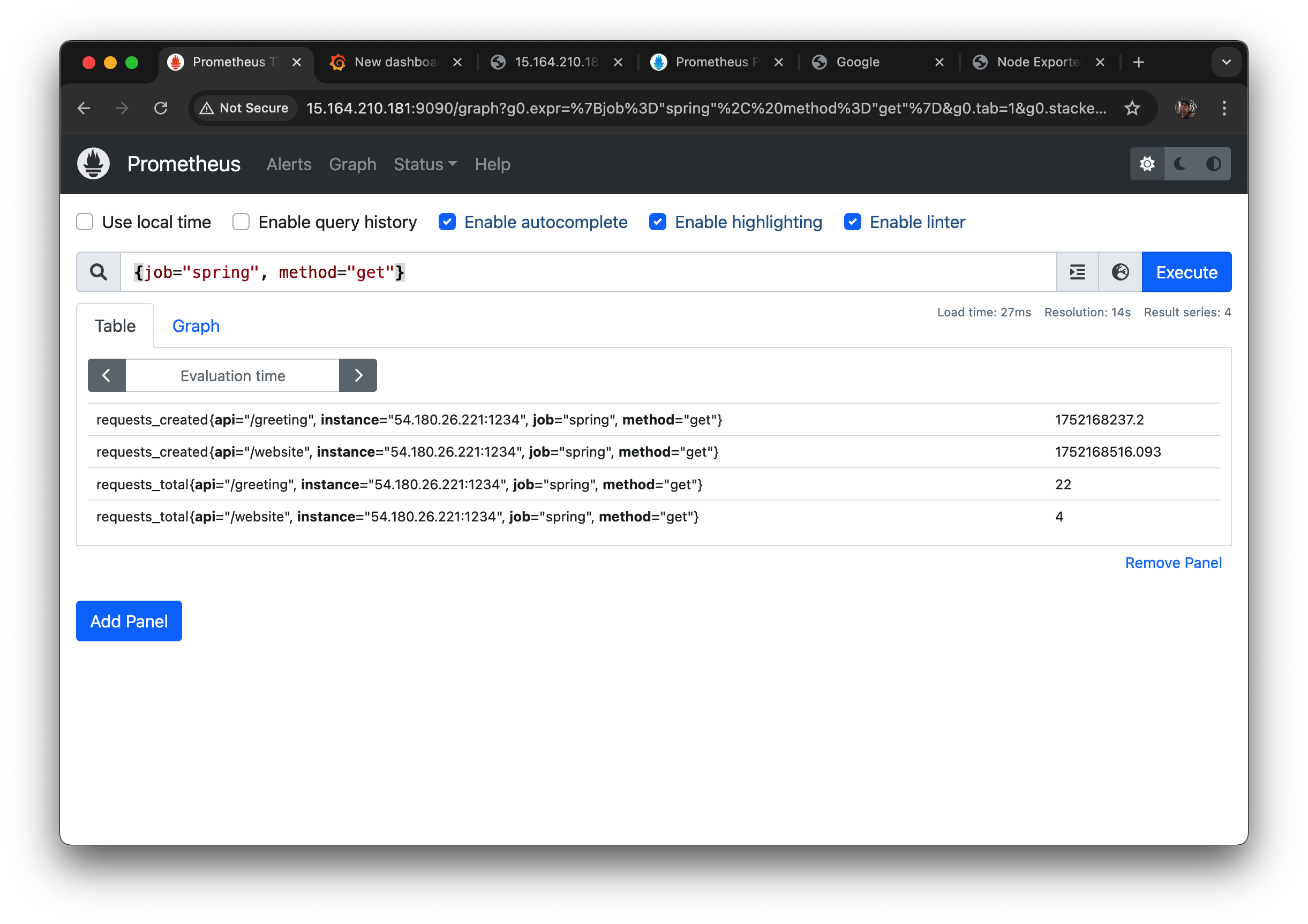
method = "get" 이용하는 다른 API도 잘 수집이 되는 것을 볼 수 있다.
이제 대시보드를 만들어 보자.
3.2.3 Counter Monitoring
리퀘스트는 초당 건수가 중요하니까
irate() 사용해서 나타낼 수 있다.
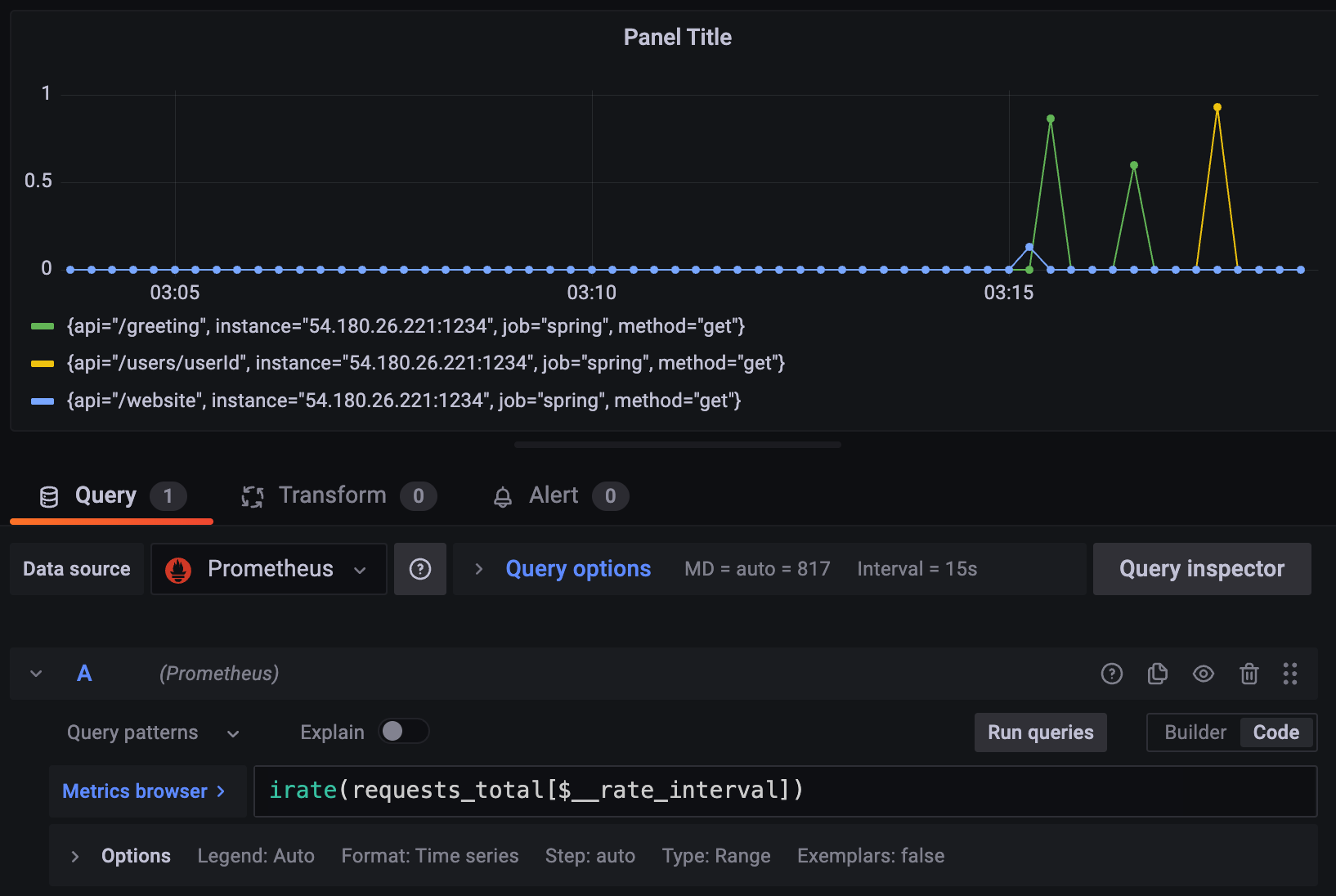
API별로, 서버가 여러 대 더라도 어떤 API가 많이 호출되었나
이런 걸 보고싶은 거니까 SUM by 로 묶어주자.
Req/s by API
sum by (method, api) (irate(requests_total[$__rate_interval]))이렇게 하면 API 종류 별로 묶인 걸 확인할 수 있다.
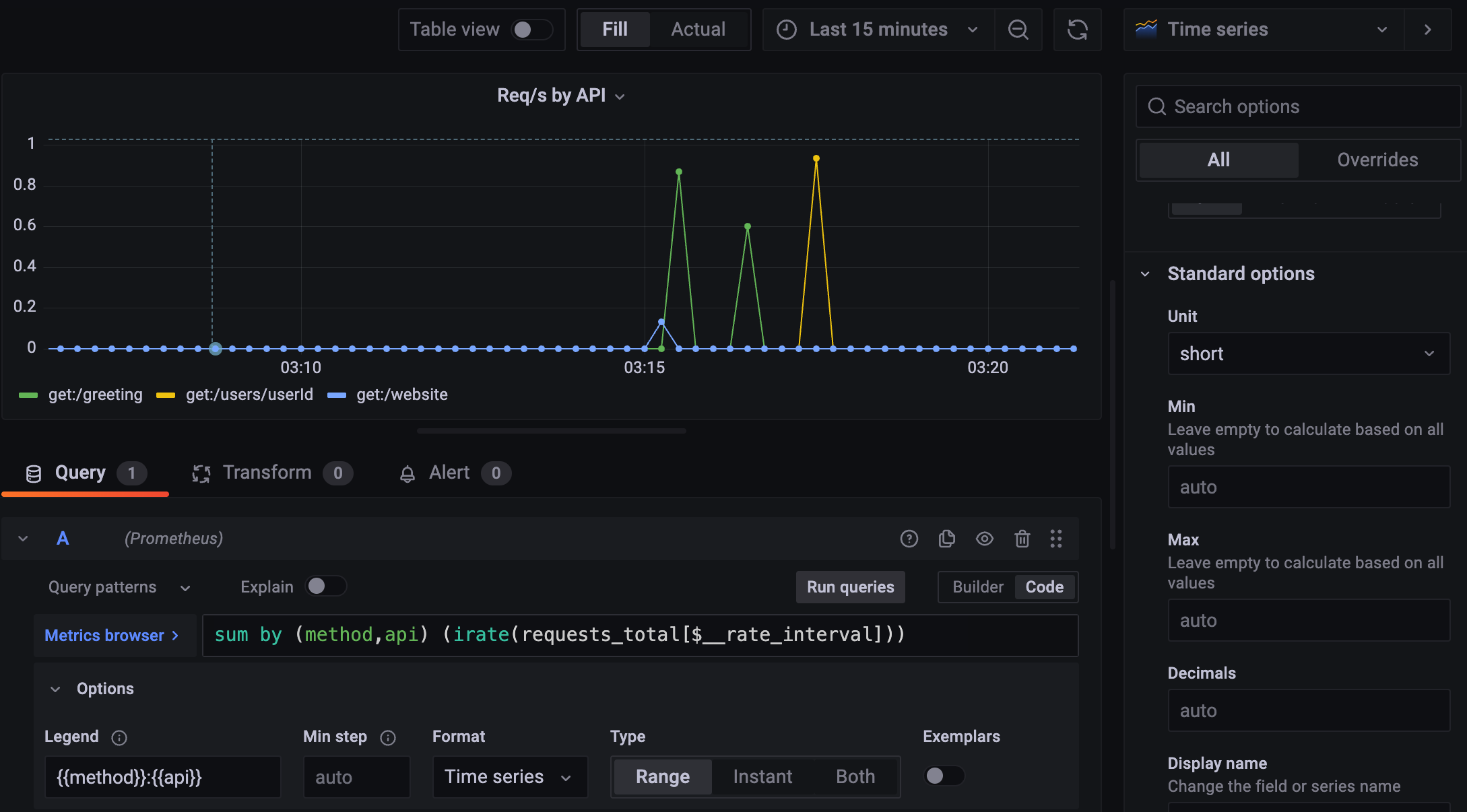
건 수니까, short로 표시.
3.3 Histogram 사용하기
remoteSiteLatency 를 쓸 수 있는 방법이 여러가지다.
3.3.1 정의
Website 호출 latency 를 측정하기위한 Histogram 정의
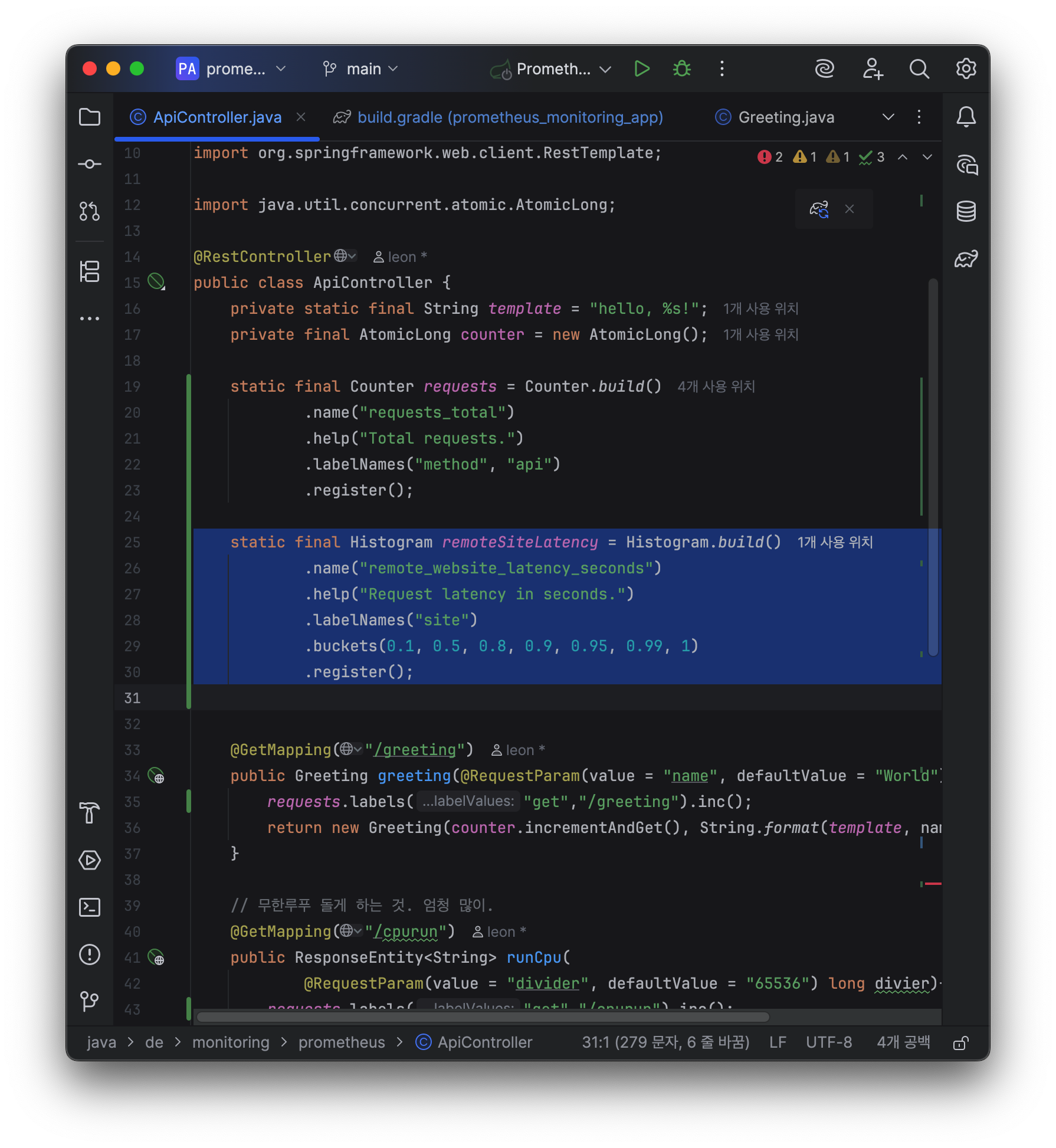
static final Histogram remoteSiteLatency = Histogram.build()
.name("remote_website_latency_seconds")
.help("Request latency in seconds.")
.labelNames("site")
.buckets(0.1, 0.5, 0.8, 0.9, 0.95, 0.99, 1)
.register();- label로 site 를 구분할 수 있게 했다.
- summary라면 Quantile이 온다.
3.3.2 명시적으로 timer 에 값 넣기
long startTime = System.currentTimeMillis();
String response = restTemplate.getForObject(site, String.class);
remoteSiteLatency.labels(site).observe((System.currentTimeMillis() - startTime) / 1000);원하는 함수를 수행하기 전에 currentTimeMillis 시작 시간 찍고,
System.currentTimeMillis() - startTime
현재 시간에서 시작 시간 빼서 밀리 세컨드 구하고
세컨드니까 나누기 1000.
그걸 observe 라는 함수를 써서 명시적으로 값 자체를 넘기는 것
3.3.3 timer 로 측정 끝 구간 알기
Histogram.Timer timer = remoteSiteLatency.labels(site).startTimer();
String response = restTemplate.getForObject(site, String.class);
timer.observeDuration();timer 제공하는데
labels(site). 라벨 넣어주고 startTimer(); 하면 스타트 객체가 떨어지는데 timer 객체가 이 시작 시간을 받아서 가지고 있는다.
그 다음 원하는 함수 response 실행하고
timer.observeDuration 하면 타이머가 자기 자신이 시간 구간을 기록하게 된다.
3.3.4 try-with-resource 구문에서 사용하기
try (Histogram.Timer requestTimer = remoteSiteLatency.labels(site).startTimer()) {
String response = restTemplate.getForObject(site, String.class);
return ResponseEntity.ok(response);
} catch (Exception e) {
return ResponseEntity.unprocessableEntity().body(e.getMessage() + e.getStackTrace());
}타이머가 try(try-with-resource) 구문안에 들어가면
labels(site) 라벨에 사이트 정보 넣어주고
startTimer() 로 requestTimer 객체를 만들면,
중간에 ovserve를 호출하지 않아도 되고,
리소스 구문이 끝날 때 암시적으로 호출하게 되어 있다. closeable.
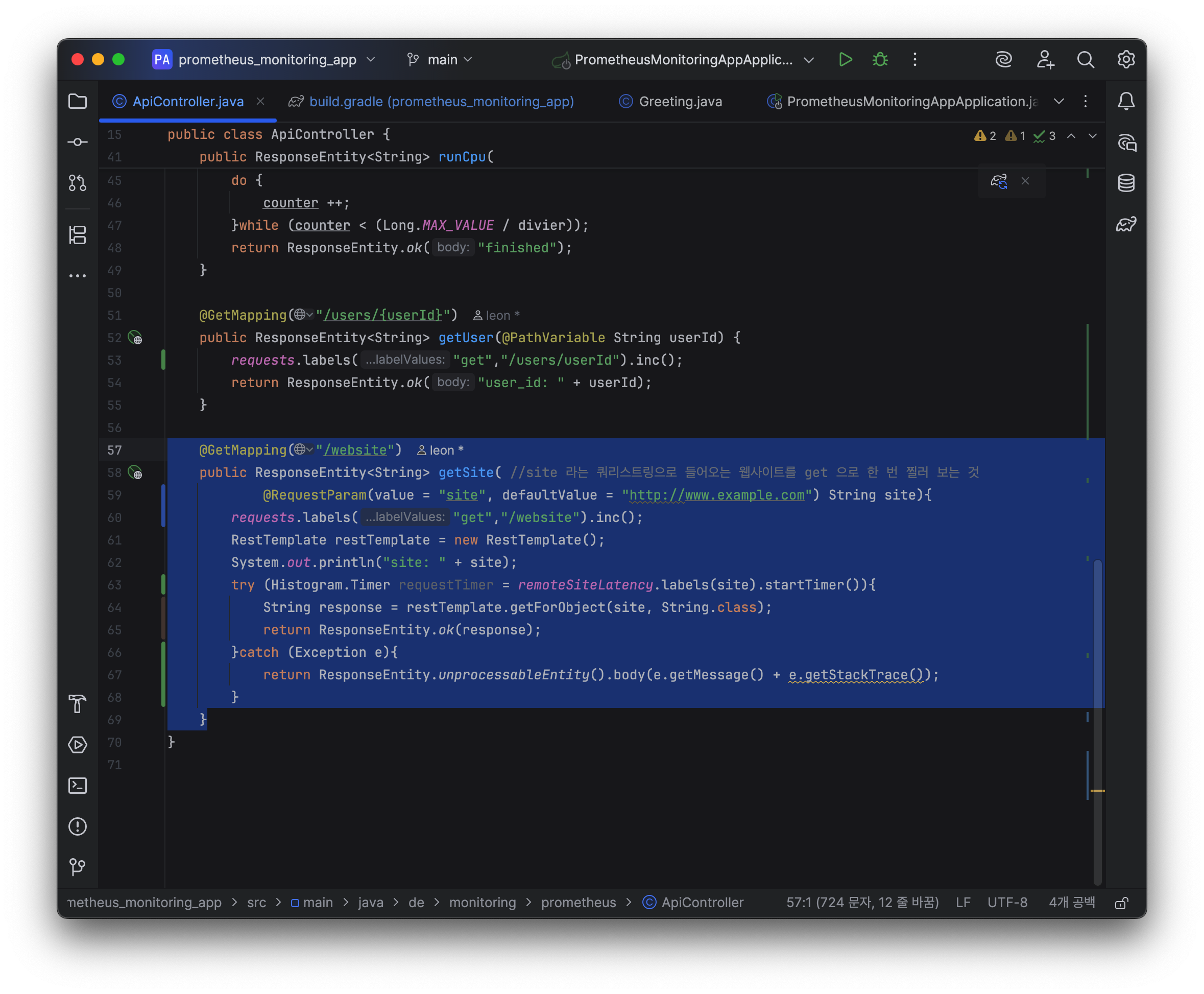
이제 다시 version = '0.0.3-SNAPSHOT' 배포를 해서 App server에 올려보자.

호출이 잘 되는 것으로 보아 배포가 잘 되었다
반복해서 여러 사이트들을 접속하고 리로드를 해 보겠다.
이제 프로메테우스에서
latency 를 검색해보자.
site라는 라벨을 가졌으니까
{site=~".+"} 로 검색을 해보자
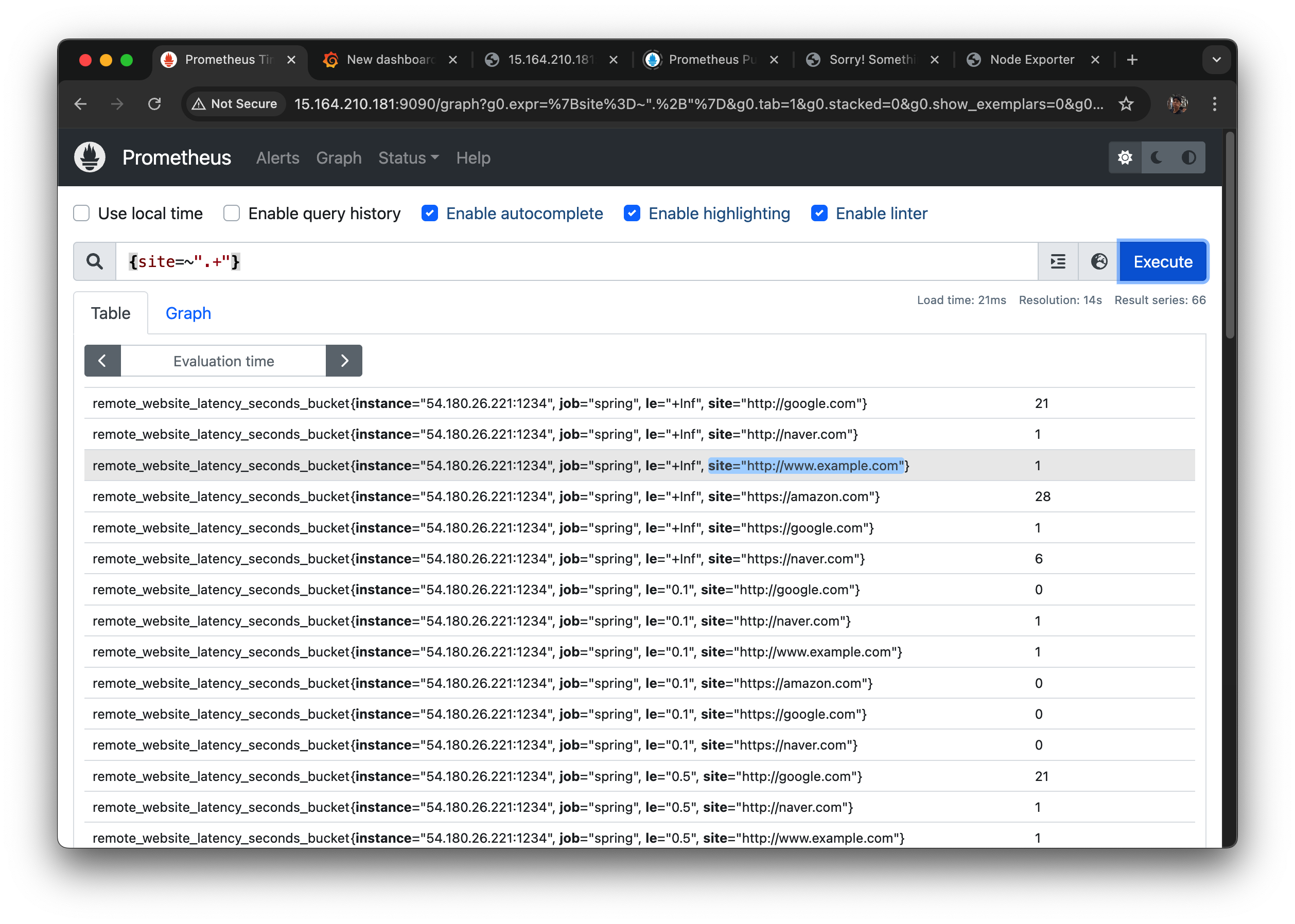
le="+Inf"인 것도 있고 le="0.1" 부터 le="1.0"까지 있다.
그리고
site="http://www.example.com" 이런 식으로 각 사이트가 라벨로 남는다.
www.example.com 만 확인을 해 보면
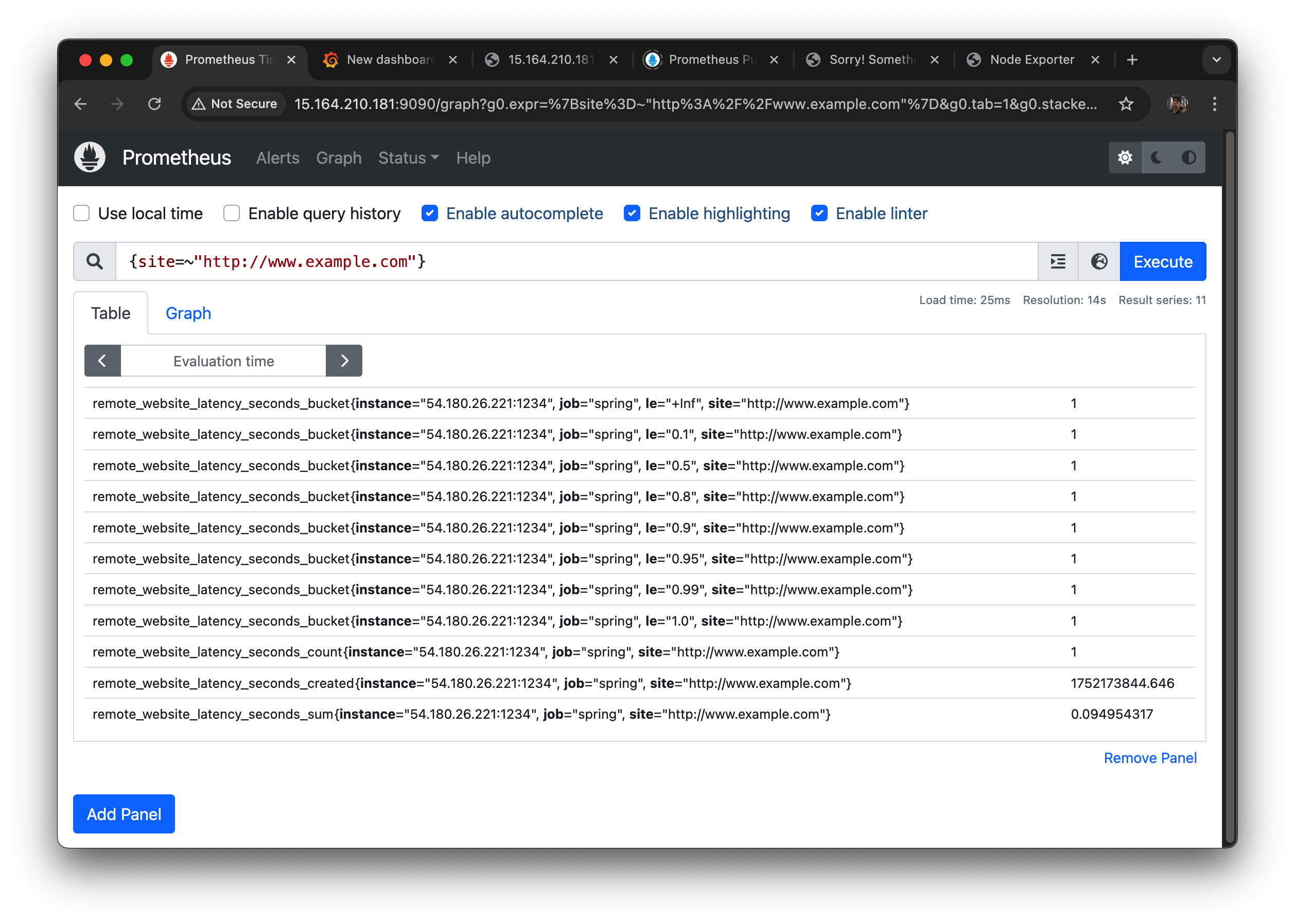
이렇게 나온다
이제 histogram 대시보드를 만들어 보자
3.3.5 Histogram Monitoring
0.95 0.99 등 worst 를 histogra_quantitile 함수로 aggregation 해서 집계한다.
histogra_quantitile을 쓰고 내가 몇 퍼센트 구간을 할 건지,
보통은 99% 또는 95% 정도를 많이 모니터링 한다.
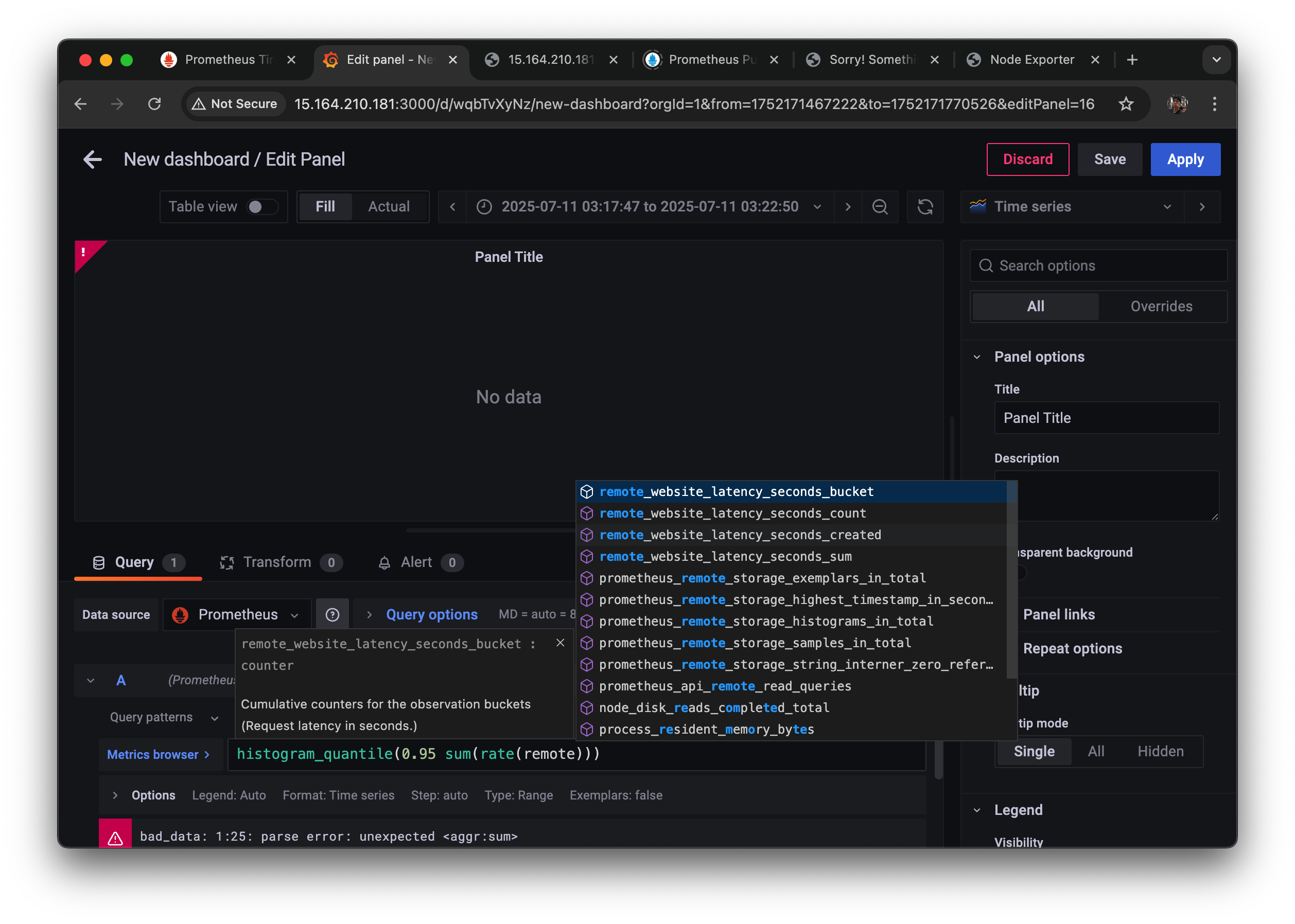
summary가 아니라 bucket으로 해야 한다.
Histogram latency .95 by site
histogram_quantile(0.95, sum(rate(remote_website_latency_seconds_bucket[5m])) by (le, site))- unit: seconds
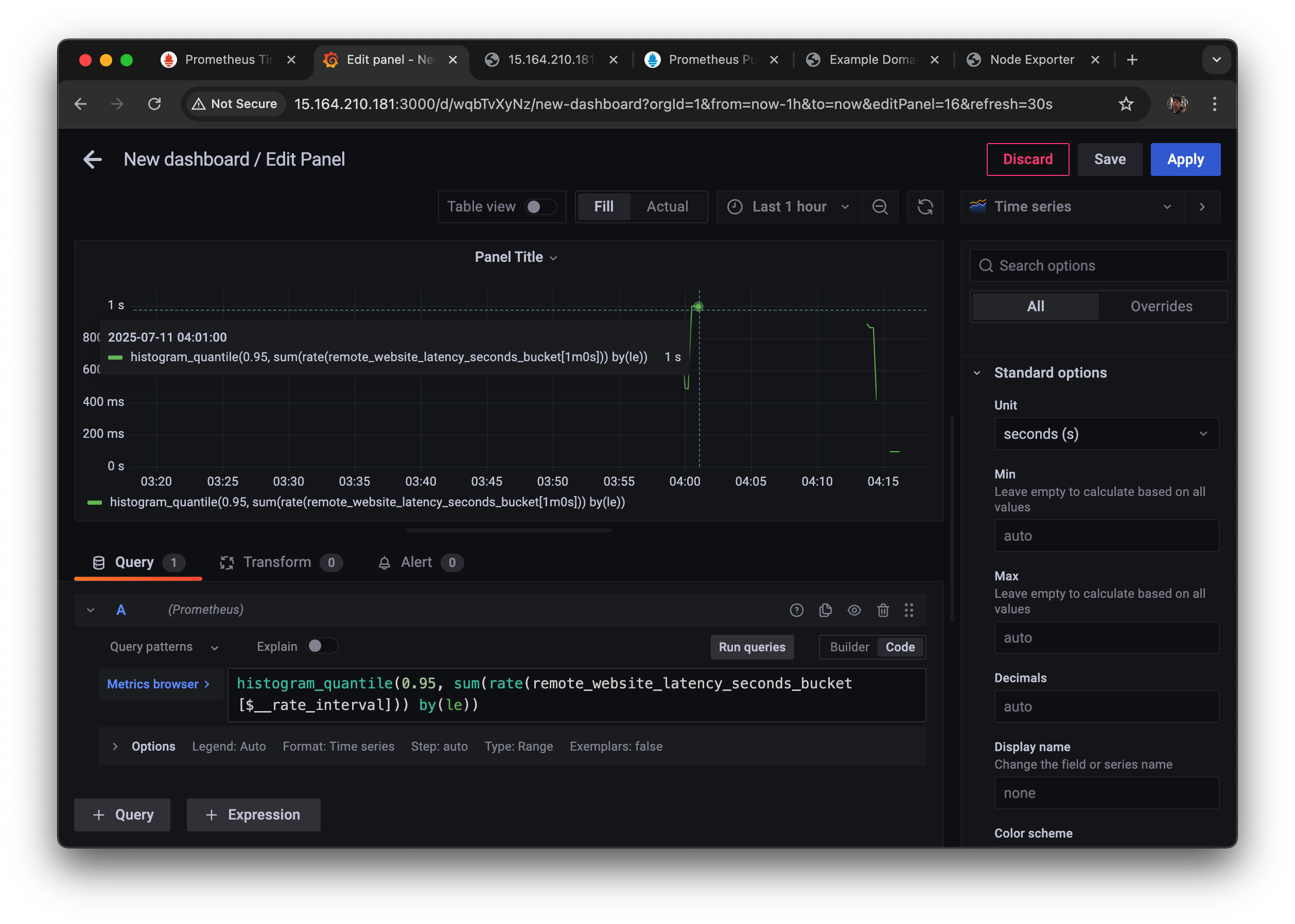
1 second 가 걸렸다가 800ms, 400ms로 95% 걸리고 있다.
site로 나눠서 조금 더 자세히 보면
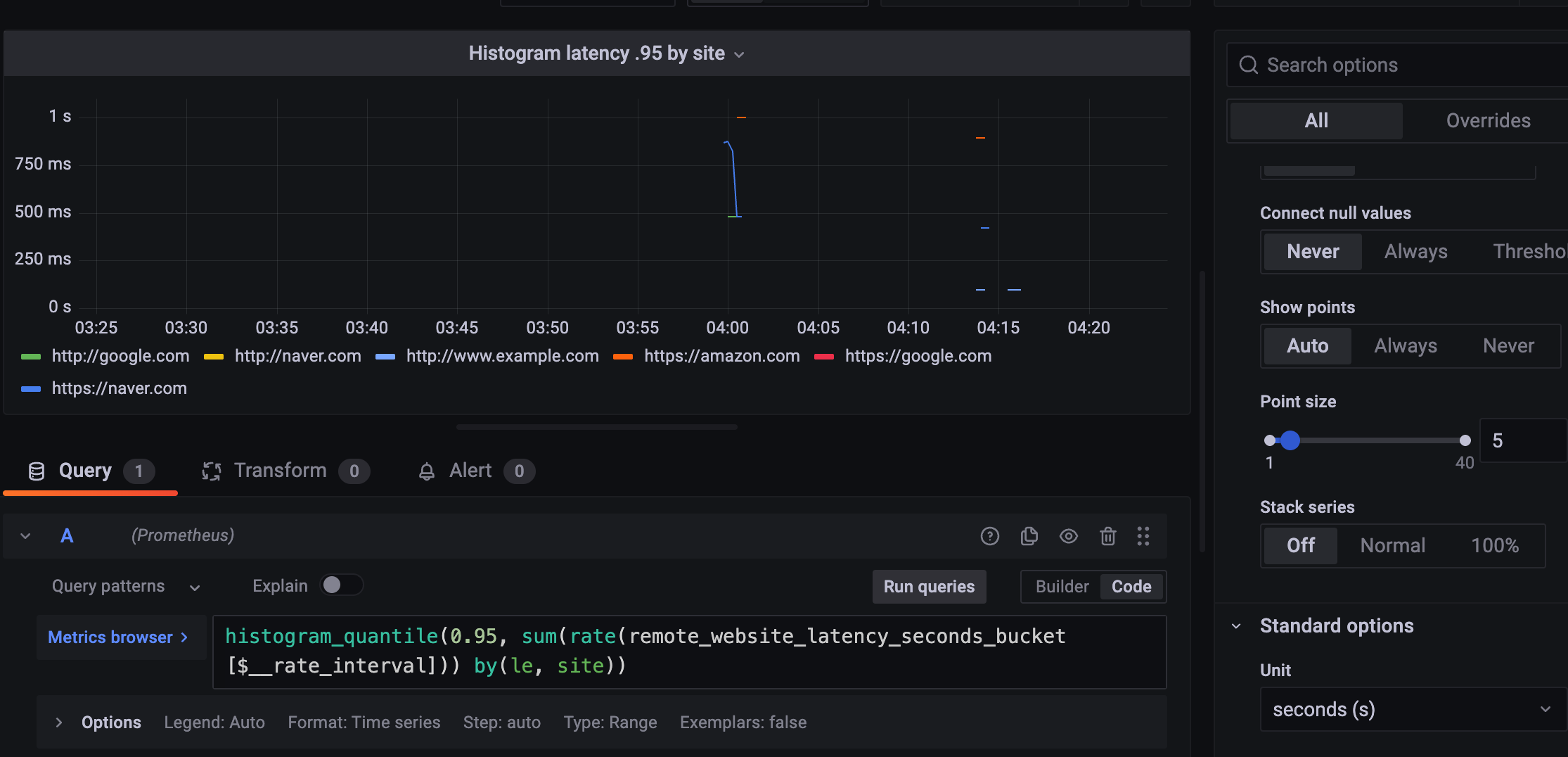
amazon : 1s > 제일 오래 걸림
naver : 800ms ~ 480ms
google : 480ms
각각 사이트 성능을 확인할 수 있었다.
만약에 사이트들이 완전히 프록시다. 이런 경우에는
라벨이 엄청 많이 나왔을 것.
사이트 개수가 얼마 안되고 성능 지표를 나눠서 보는 게 유의미하다
이런 경우엔 이렇게 보면 좋다.
데이터엔지니어링은 대량의 데이터를 확인해야 되기 때문에
로그로 직접 확인할 수는 없고 대부분 통계로 확인을 한다.
100%는 없고 몇 퍼센트의 어떤 영향이 있다 이런 것들을 조사할 일이 많은데 이런 상황에 이런 매트릭들을
잘 활용하는 게 정말 중요하다.
