1. 문제 개요: EMR 클러스터 BOOTSTRAP_FAILURE 반복
Amazon EMR 클러스터 생성 과정에서 OOM Error 및 BOOTSTRAP_FAILURE 문제가 반복적으로 발생해서
클러스터가 정상적인 워크로드 수행이 불가능했다.
특히, EMR 클러스터가 외부 Hive Metastore(Amazon RDS)와 연동을 시도하고 JDBC 드라이버를 설치하는 Bootstrap 단계에서 에러가 집중적으로 나타났다.
클러스터는 Hive Metastore 기동 단계에서 실패했으며, 로그에는 OutOfMemoryError 메세지가 포함되어 있었다.
2. 에러 로그를 통한 문제 추적 및 상세 분석
EMR은 Bootstrap → Puppet → Application 설치 → Steps의 순서로 클러스터를 구성함.
각 단계의 로그를 S3에 저장해서 어디서 문제가 생긴 것인지 확인했다.
(1) 프로비저닝 실패 (Puppet 로그 분석)
클러스터가 BOOTSTRAP_FAILURE 상태에 빠지자, 가장 먼저 프로비저닝 단계의 로그를 확인했다.
- 로그 위치:
s3://leo4study/emr-log/j-1AOA5XWEN90I3/node/i-09d9f7506d5e1fdc7/provision-node/apps-phase/0/00173010-5d11-45ac-ac02-f09cf20f51ba/stderr.gz
이 로그 파일은 Puppet이 애플리케이션 번들(Hive, Spark 등)을 설치하고 기본 설정을 적용하는 과정에서 발생한 에러를 담고 있다.
- 핵심 에러 메시지
Systemd start for hive-hcatalog-server failed!
Metastore startup failed, see /var/log/hive-hcatalog/hcat.err- 이 메시지는 Hive-HCatalog 서비스가
systemd를 통해 정상적으로 시작되지 못했음 나타낸다. Puppet은 클러스터의 애플리케이션을 프로비저닝하는 역할을 하는데, 이 단계에서 Hive Metastore 기동 실패가 프로비저닝 중단의 직접적인 원인이었음.
다음으로, Puppet의 상세 보고서를 통해 실패의 정확한 원인 파악해보자.
-
Puppet 보고서 분석:
/var/log/provision-node/reports/경로에 저장된202509091020.yaml파일을 분석함. -
보고서 내용:
status: failed와 함께 다음과 같은 메시지가 기록되어 있었음.
- level: err
message: |
change from 'stopped' to 'running' failed: Systemd start for hive-hcatalog-server failed!
...
Sep 09 10:20:13 hive-hcatalog-server[11218]: Metastore startup failed, see /var/log/hive-hcatalog/hcat.err
Sep 09 10:20:18 hive-hcatalog-server[11218]: Failed to start HCatalog server. Return value: 3[FAILED]- 이 로그는 Hive Metastore가 "stopped" 상태에서 "running" 상태로 전환하는 데 실패했고,
return value: 3은 서비스 실행 실패를 의미한다. - 문제의 원인을 Hive Metastore 기동 실패로 좁혔고, Hive Metastore 서비스가 실행되는 동안 발생한 내부 오류를 기록하는 전용 로그인
hcat.err파일을 찾아 보았다.
(2) 두 번째 단서: 근본적인 원인 (Hive Metastore 로그)
Hive Metastore가 왜 시작에 실패했는지 알아보기 위해 hcat.err 로그를 확인했다.
- 이 로그는 Hive Metastore 프로세스 내부에서 발생하는 에러를 기록함
핵심 에러 메시지:
java.lang.OutOfMemoryError: Java heap space-
이 에러는 Hive Metastore가 JDBC 연결을 통해 RDS에 접속하여 스키마를 초기화하는 과정에서 발생했다.
-
OutOfMemoryError는 일반적으로 JVM Heap 메모리가 부족할 때 발생한다. 하지만, EMR 노드는r6g.xlarge인스턴스로 32 GiB의 메모리를 가지고 있어 JVM 메모리가 부족할 가능성은 낮아 보였음. -
이 OOM이 왜 발생했는지에 대한 가설들을 세우고 하나씩 검증
3. 단계별 해결 시도 및 결과
문제의 원인을 파악하기 위해 여러 가설을 세우고, 각 가설에 대한 검증을 위해 단계적으로 접근했다.
시도 1: EMR 노드 JVM 옵션 및 Heap 크기 조정
-
가설: EMR 노드 자체의 메모리가 부족하여 Metastore 프로세스가 OOM으로 종료된다.
-
적용: EMR 클러스터 JSON 설정에
hadoop-env,yarn-env,spark-env설정을 추가하여 JVM 힙 크기를 늘림
[
{
"Classification": "hadoop-env", "Properties": {}, "Configurations": [
{"Classification": "export", "Properties": {"HADOOP_OPTS": "-server -XX:+ExitOnOutOfMemoryError"}}
]
},
{
"Classification": "yarn-env", "Properties": {}, "Configurations": [
{"Classification": "export", "Properties": {"YARN_HEAPSIZE": "2048"}}
]
}
]- 결과: 동일한 OOM 에러가 계속해서 발생함. EMR 노드 내부의 메모리 설정만으로는 해결할 수 없는 문제음
시도 2: 인스턴스 타입 변경 (아키텍처 가설)
- 가설: ARM 기반
r6g.xlarge인스턴스가 (Java <-> 네이티브) 라이브러리 호환성 문제를 일으킨다 - 적용: 실습 환경과 동일한 x86 기반
m5.xlarge인스턴스로 변경
두 인스턴스의 주요 사양을 비교해보자.
| 항목 | 기존 (r6g.xlarge) | 변경 (m5.xlarge) |
|---|---|---|
| vCPU | 4 | 4 |
| Memory | 32 GiB | 16 GiB |
| 아키텍처 | ARM (Graviton2) | x86 (Intel/AMD) |
- 결과:
m5.xlarge로 변경 후에도 동일한BOOTSTRAP_FAILURE가 발생함. 아키텍처 문제는 아니었고.
시도 3: JDBC 드라이버 재변경 및 불필요한 설정 제거
- 가설: JDBC 드라이버 버전이나 종류가 호환성 문제를 일으킨다
- 적용:
hive-site설정에서 JDBC 드라이버를org.mariadb.jdbc.Driver에서com.mysql.cj.jdbc.Driver로 변경하고,jupyter-sparkmagic-conf와 같은 불필요한 애플리케이션 설정을 제거함
[
{
"Classification": "hive-site",
"Properties": {
"javax.jdo.option.ConnectionDriverName": "org.mariadb.jdbc.Driver",
"javax.jdo.option.ConnectionPassword": "******",
"javax.jdo.option.ConnectionURL": "jdbc:mysql://de-emr.c928wie02lla.ap-northeast-2.rds.amazonaws.com:3306/hive?createDatabaseIfNotExist=true",
"javax.jdo.option.ConnectionUserName": "hive"
}
},
{
"Classification": "jupyter-sparkmagic-conf",
"Properties": {
"kernel_python_credentials": "{\"username\":\"jupyter\",\"base64_password\":\"anVweXRlcg==\",\"url\":\"http://localhost:8998\",\"auth\":\"None\"}"
}
}
]- 결과: 여전히
BOOTSTRAP_FAILURE가 발생했습니다
시도 4: Spot 인스턴스 수급 지연 문제 검토
-
가설1: Spot 인스턴스 켜지는 게 느려서 instance가 꺼진 상태에서 요청을 받아 OOM이 난다.
-
적용1: Steps 기능을 활용해 Spot 인스턴스 노드가 완전히 준비될 때까지 기다리도록 구성했다.
Step 1: s3://leo4study/bootstrap/wait-core-nodes.sh
Step 2: s3://leo4study/bootstrap/install-mariadb-driver.sh
Step 3: s3://leo4study/bootstrap/init-hive.sh
wait-core-nodes.sh: 모든 코어 노드가 Live datanodes 상태가 될 때까지 대기하는 스크립트.
init-hive.sh: schematool -dbType mysql -initSchema 명령어를 실행하여 Hive 스키마를 초기화하는 스크립트.
- 결과: 해당 스텝들을 적용했으나, 인스턴스 자체를 수급하지 못해
UNITS_AVAILABLE_TIMEOUT에러가 발생하며 클러스터가 무한 Starting 상태에 머물렀다. 이는 Spot 인스턴스의 가용량 문제였다.
- 가용량을 늘리고 다시 진행해 보았는데도 똑같은 에러 발생. (Steps 가 적용 되기 전부터 무한 Starting.)
- 가설2: AWS에서 Spot 인스턴스 수급이 원활하지 않아 프로비저닝이 지연되거나 타임아웃된다 (해당 AZ에 인스턴스가 모자란가?)
- 적용2: On-Demand 인스턴스만 사용하여 클러스터를 생성
- 결과: 이 단계에서도 OOM 에러는 계속 발생함. 이는 Spot/On-Demand 여부와 무관함을 확인.
4. 최종 원인 규명 및 해결: RDS DB 인스턴스 요금제
앞선 시도들이 실패하면서 EMR 클러스터의 OutOfMemoryError와 Too many connections 로그는 EMR 노드 자체의 문제가 아니라, 외부 의존성인 RDS DB의 성능 한계를 반영하는 현상이었다.
로그를 따라가며 다음과 같은 가설을 도출해 냈는데
PuppetException과Systemd start failed로그: Hive Metastore 서비스가 시작에 실패함.hcat.err로그의Too many connections: Metastore 서비스가 실패한 직접적인 원인이 RDS DB의 동시 연결 제한 때문임.JVM Heap size및Instance Type변경 시도 실패: 이 시도들은 EMR 노드 자체의 메모리 부족이나 아키텍처 호환성이 원인이 아니었음.RDS performance분석:db.t4g.micro인스턴스의 낮은max_connections설정과 Hive 스키마 초기화 시 발생하는 높은 CPU/I/O 부하를 확인했다. 이는 RDS 인스턴스가 Hive Metastore의 초기 요청을 감당하지 못해 연결을 거부하고, 이로 인해 EMR 노드에서 연쇄적으로 에러가 발생했다는 가설을 세울 수 있었다.
-
원인: 낮은 사양의 RDS는 Hive Metastore의 초기 부하를 처리하지 못했고, 이로 인해 JDBC 연결이 불안정해지면서 EMR 노드의 Hive Metastore 프로세스가 메모리를 소진하는 연쇄적인 오류를 일으킬 가능성이 있었음.
-
최종 해결 방안:
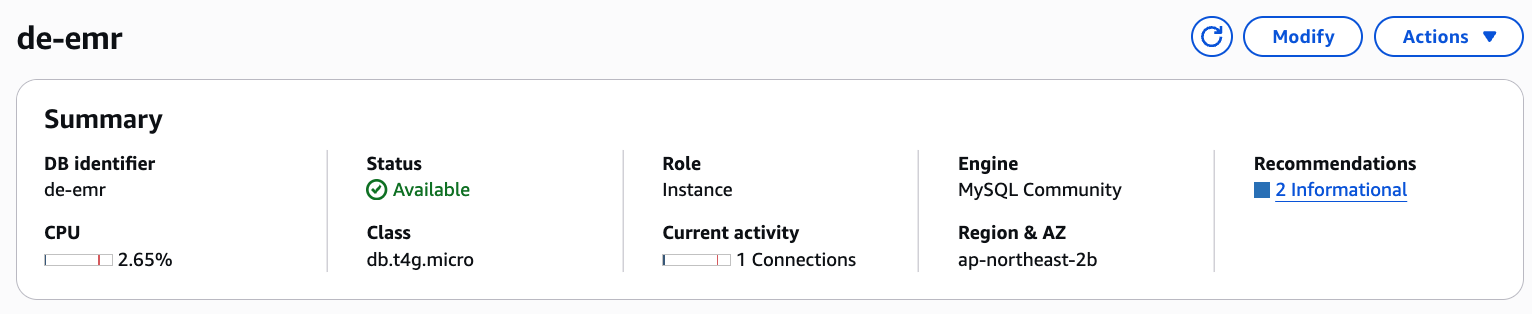
- RDS DB 인스턴스 요금제 상향: 기존
db.t4g.micro인스턴스를db.t4g.medium(RAM 4GB)으로 업그레이드했다.
max_connections를 크게 늘려 Hive Metastore의 초기 연결 요청을 충분히 처리할 수 있도록 함.
- EMR 클러스터 재구성 및 재실행: 변경된 RDS 설정과 함께 EMR 클러스터를 다시 생성함
- 결과: 클러스터가 정상적으로 Bootstrap 및 Provisioning 과정을 완료하고
WAITING상태로 전환됨.
- RDS DB 인스턴스 요금제 상향: 기존
RDS db.t4g.micro 에서 db.t4g.medium (RAM 4GB)으로 변경 + Hive 연결 풀 제한
[
{
"Classification": "hive-site",
"Properties": {
"javax.jdo.option.ConnectionDriverName": "org.mariadb.jdbc.Driver",
"javax.jdo.option.ConnectionPassword": "******",
"javax.jdo.option.ConnectionURL": "jdbc:mysql://de-emr.c928wie02lla.ap-northeast-2.rds.amazonaws.com:3306/hive?createDatabaseIfNotExist=true",
"javax.jdo.option.ConnectionUserName": "hive",
}
},
{
"Classification": "jupyter-sparkmagic-conf",
"Properties": {
"kernel_python_credentials": "{\"username\":\"jupyter\",\"base64_password\":\"anVweXRlcg==\",\"url\":\"http://localhost:8998\",\"auth\":\"None\"}"
}
}
]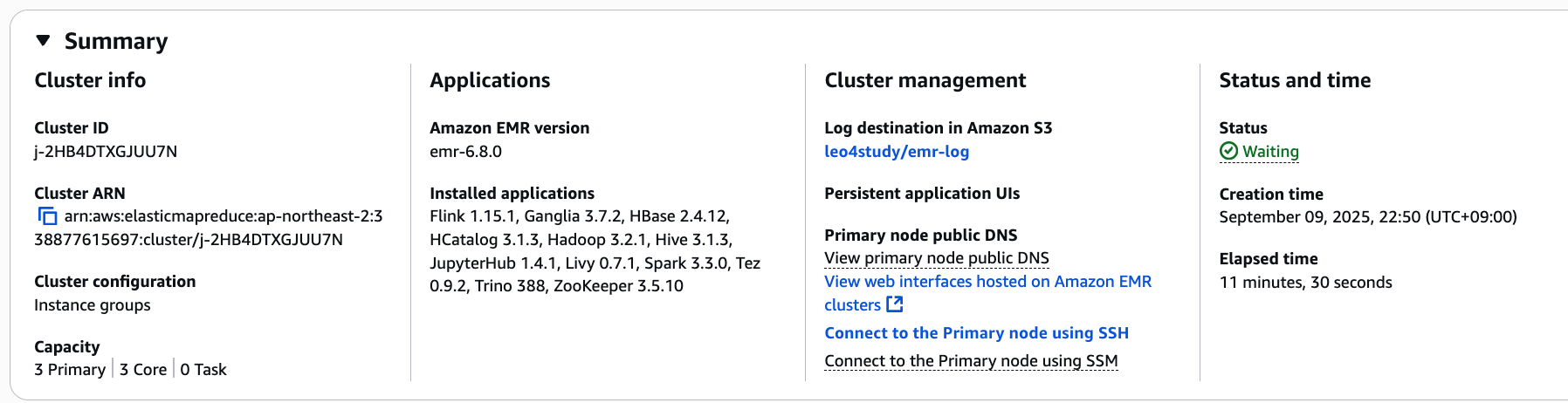
변경 후 해당 settings 로 성공한 모습..
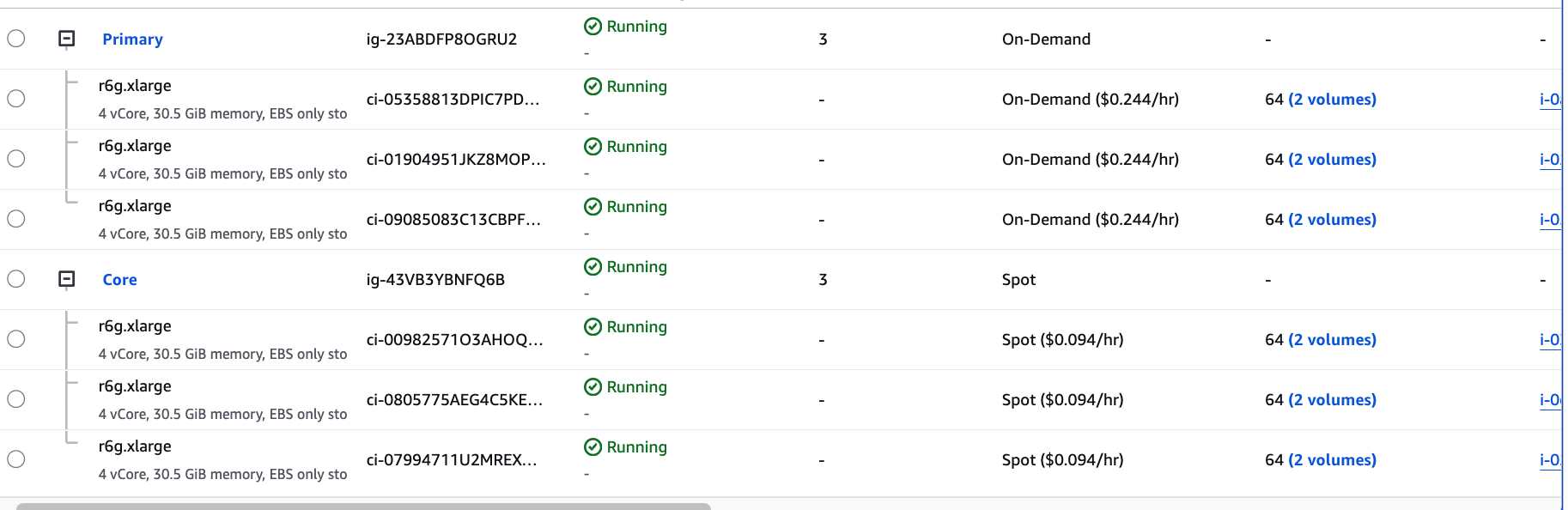
spot instance도 잘 적용이 된 모습이다.
후기.
EMR 클러스터의 OutOfMemoryError를 해결하면서, 단순히 노드 리소스 부족이 아닌 외부 시스템의 성능 한계가 근본 원인이 될 수 있다는 중요한 교훈을 얻었다. 이 경험을 통해 다음과 같은 로그 분석 및 문제 해결 접근법의 중요성을 깨달았다.
1. 로그 분석의 심층성 확보
수많은 로그 파일 속에서 error나 exception 같은 키워드만으로 문제를 찾는 것은 초기 단계에서 유용하지만, 핵심적인 단서를 놓칠 수 있다. 이번 문제의 경우, OutOfMemoryError는 EMR 노드 내부의 문제가 아닌, 외부 DB 연결 실패로 인해 발생한 연쇄적인 현상이었다.
문제점은 error 키워드 검색에만 의존할 경우, Too many connections와 같은 JDBC 드라이버의 세부적인 연결 실패 로그를 간과하기 쉬운 점이다. 이러한 로그는 WARN이나 INFO 레벨로 기록되거나, 일반적인 Exception 키워드와 함께 나타나지 않을 수 있기 때문이다.
개선 방안은 문제의 핵심 원인을 파악하기 위해 에러가 발생한 지점의 로그를 전체적인 맥락에서 직접 읽고 분석하는 노력이 필수적이라는 것이다. 에러 스택 트레이스의 상위 레벨에서 발견한 단서(예: Metastore startup failed)를 바탕으로 하위 레벨의 상세 로그(예: hcat.err)를 능동적으로 찾아 들어가야 한다.
2. EMR 클러스터 초기화 단계에 대한 이해
EMR 클러스터의 프로비저닝은 Bootstrap Actions → Puppet → Application 설치 → Steps의 명확한 단계별 프로세스를 따른다. 각 단계는 서로 다른 역할을 수행하며, 해당 단계에서 발생한 로그는 특정 경로에 저장된다.
단계별 로그 파악의 중요성은 이 문제에서 명확히 드러난다. 우리는 stderr.gz에서 Puppet의 Hive-HCatalog 기동 실패를 확인한 후, 더 깊은 원인을 찾기 위해 Hive-HCatalog 전용 로그 파일인 hcat.err를 추적했다. 이처럼 어떤 단계에서 어떤 애플리케이션 로그가 어디에 저장되는지를 파악하는 것이 문제 해결 시간을 대폭 단축시킨다.
적용은 향후 유사 문제 발생 시, EMR 클러스터의 초기화 흐름을 먼저 떠올리고, 실패가 발생한 단계에 해당하는 로그를 체계적으로 분석하는 것이다. (예: Bootstrap 실패 시 bootstrap-actions 로그, Provisioning 실패 시 provision-node 로그)
3. 결론
이번 경험은 분산 시스템에서 발생하는 복합적인 문제를 해결하는 데 있어 체계적인 로그 분석과 시스템 아키텍처에 대한 깊은 이해가 얼마나 중요한지 다시 한번 일깨워준다. 단순히 키워드로 로그를 검색하는 것을 넘어, 에러 로그가 가리키는 방향을 따라가며 원인과 결과를 연결하는 논리적 사고를 통해 근본 원인을 규명할 수 있었다.
