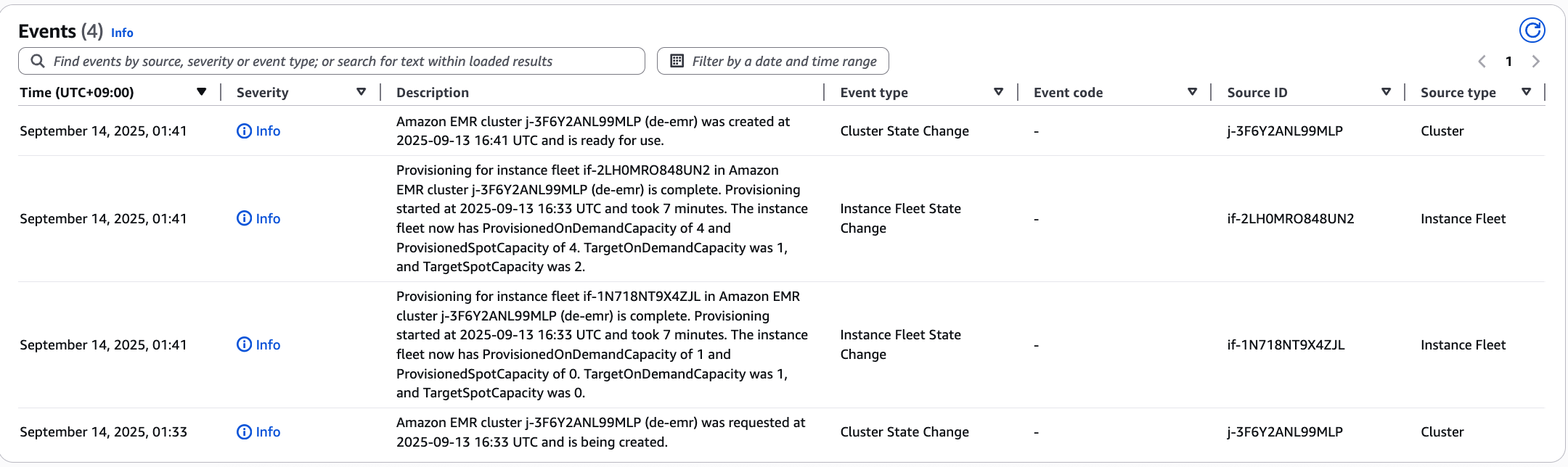
요금을 적게 만드려고 노력 중인데
요금 줄이는 게 문제가 아니게 되었다.
Spot instance 쓰기가 왜 이렇게 힘든 게야...
Instance Fleet 설정
EMR 실습 중에 http://localhost:9870/dfshealth.html#tab-over 포트 포워딩으로 HDFS health check를 하던 도중 노드들의 상태를 확인했다. 그런데 Core 노드들이 모두 죽어있었다. 마스터 노드에서만 실습을 하고 있었기 때문에 클러스터는 정상 동작 중이었고, 나머지 노드들이 죽어 있는 사실을 몰랐던 상황이다.
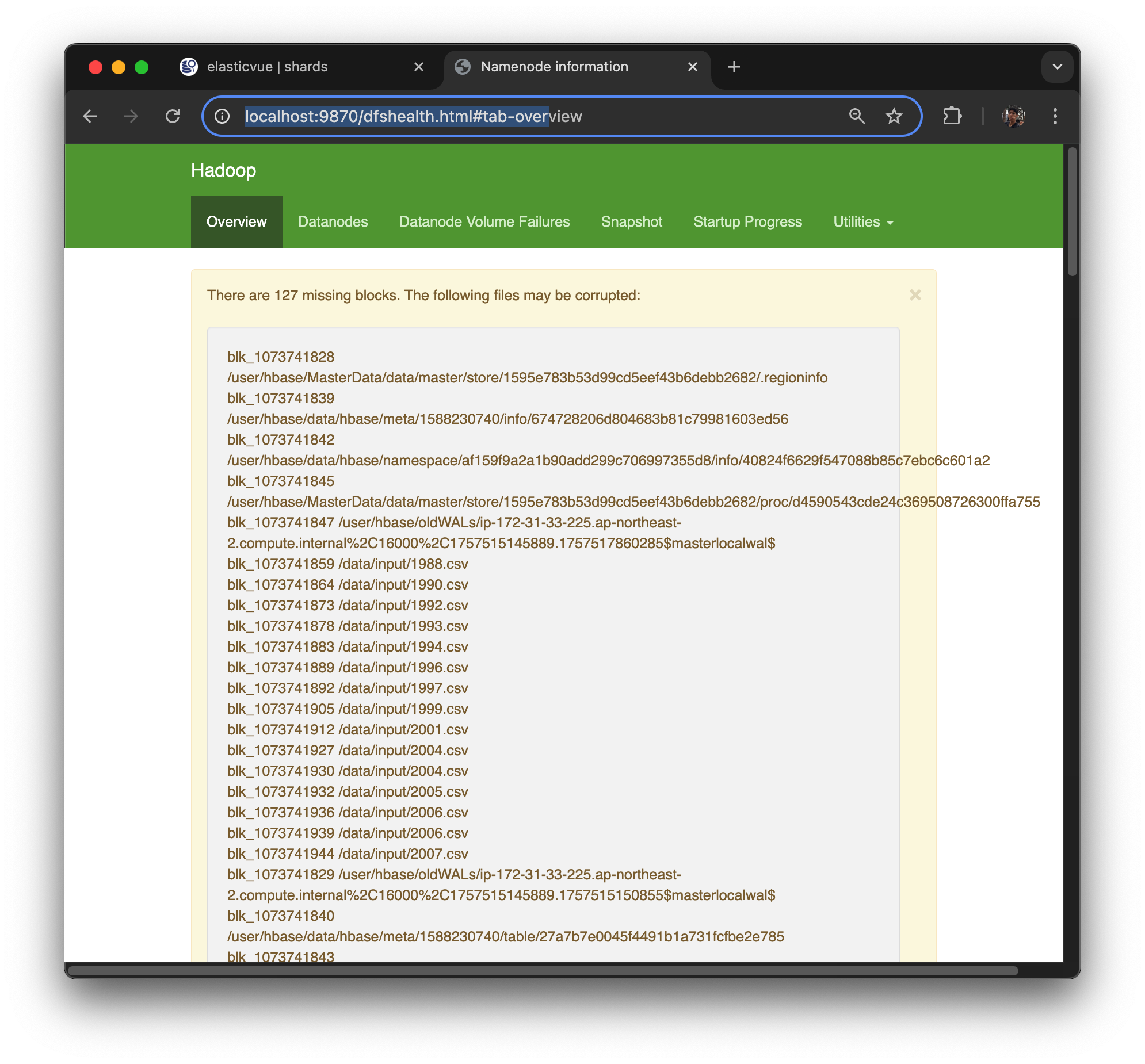
결론적으로, Spot 인스턴스를 사용했기 때문에 노드가 종료되면 자동으로 On-Demand로 넘어가 복구될 것으로 기대했으나, 실제로는 종료된 노드는 그대로 죽어 있었다. 따라서 EMR 클러스터를 다시 만들고, Instance Fleet 기능을 적용하여 자동으로 On-Demand 전환이 가능하도록 설정해야 했다.
1️⃣ InstanceGroup 기반 문제
현재 로그를 보면 Core 노드가 Spot으로만 요청되어 있고, 특정 타입만 고정해서 요청한 상태였다. InstanceGroup 기반에서는 해당 타입에 용량이 없으면 자동 복구가 불가능하다.
직접 수동으로 다른 타입으로 변경하거나 새로 추가해야 한다.
aws emr modify-instance-groups --cluster-id <cluster-id> --instance-groups InstanceGroupType=CORE,InstanceCount=3,InstanceType=m5.xlarge즉, InstanceGroup 기반에서는 Spot 부족 시 실패하며, 자동 복구가 되지 않는다.
2️⃣ InstanceFleet 기반 해결 방법
InstanceFleet을 사용하면 여러 타입을 동시에 정의할 수 있고, Spot과 On-Demand를 섞어서 설정할 수 있다.
"InstanceFleets": [
{
"Name": "CoreFleet",
"TargetOnDemandCapacity": 0,
"TargetSpotCapacity": 3,
"InstanceTypeConfigs": [
{ "InstanceType": "r6g.xlarge" },
{ "InstanceType": "m5.xlarge" },
{ "InstanceType": "c5.xlarge" }
],
"LaunchSpecifications": {
"SpotSpecification": {
"TimeoutAction": "SWITCH_TO_ON_DEMAND",
"AllocationStrategy": "capacity-optimized"
}
}
}
]- r6g.xlarge Spot이 없을 때 → 자동으로 다른 Spot 타입으로 대체하거나 On-Demand로 fallback
- 즉, Spot 종료 시에도 자동 복구 가능
3️⃣ InstanceFleet 설정 예시 화면
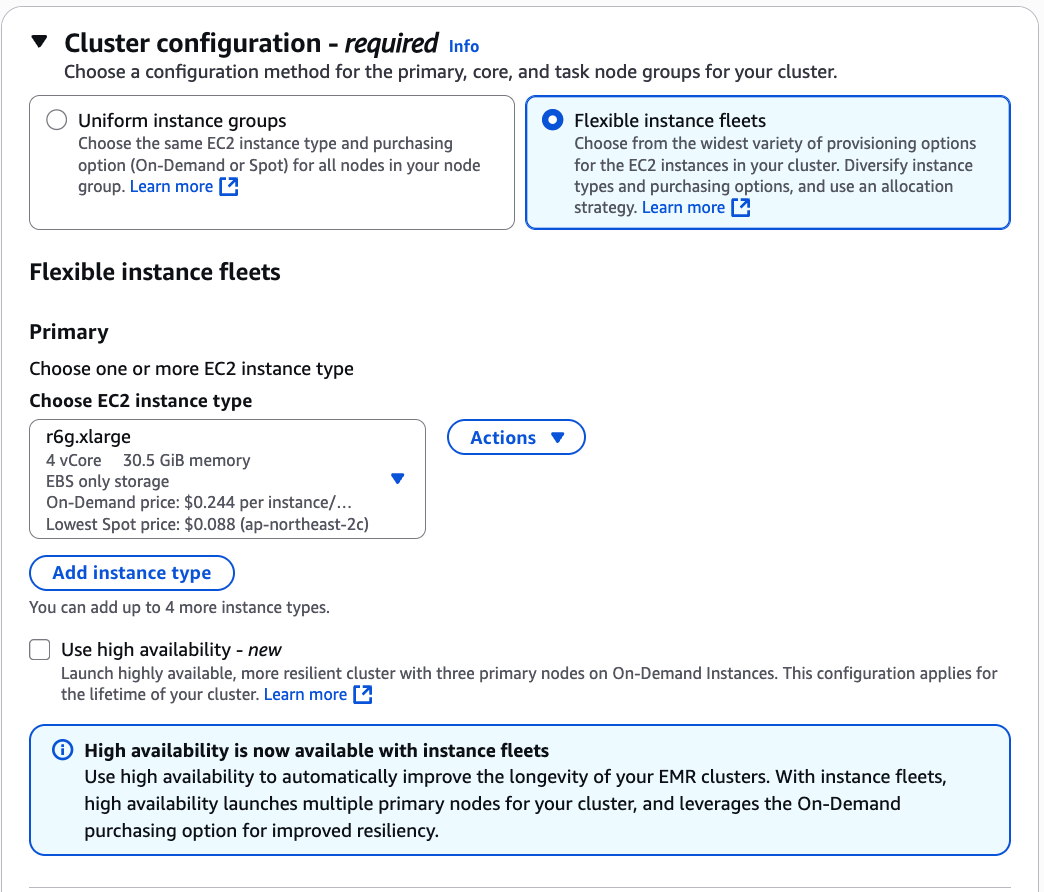
Flexible instance fleets 선택, EC2 r6g.xlarge 선택, High Availability 선택
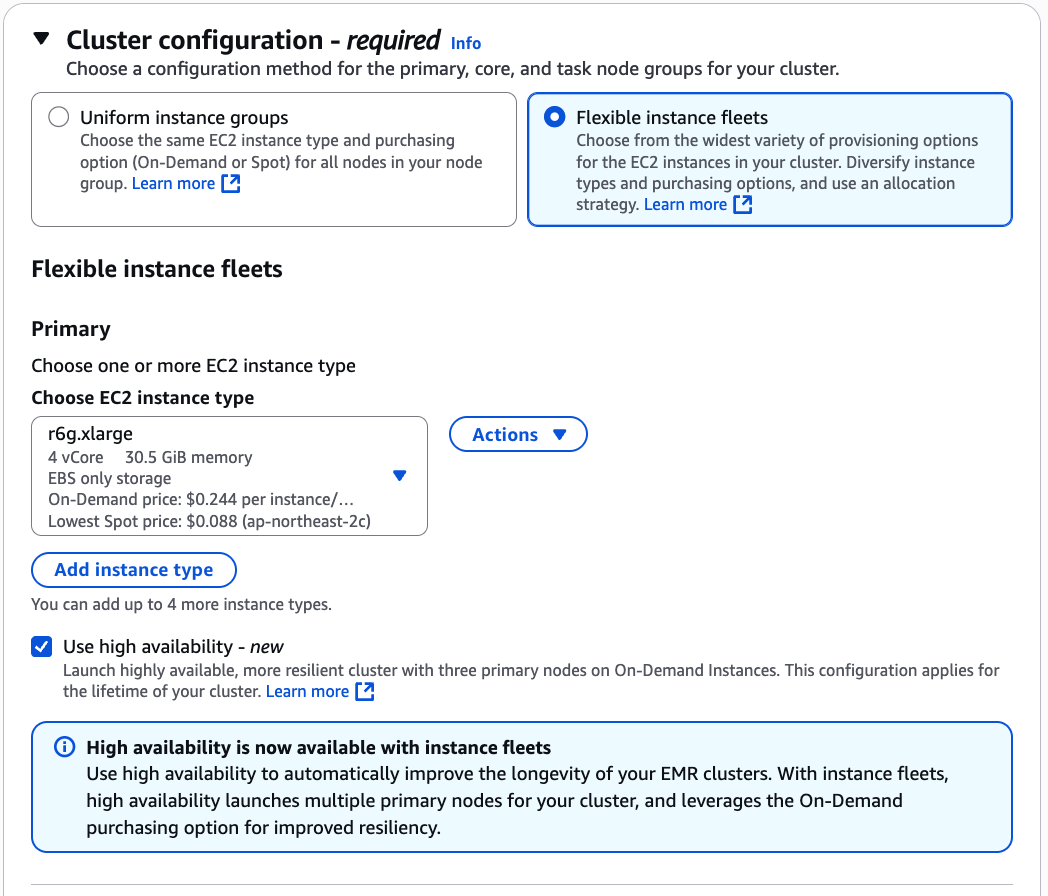
Core 노드에 r6g.xlarge와 m6g.xlarge 두 가지를 넣음
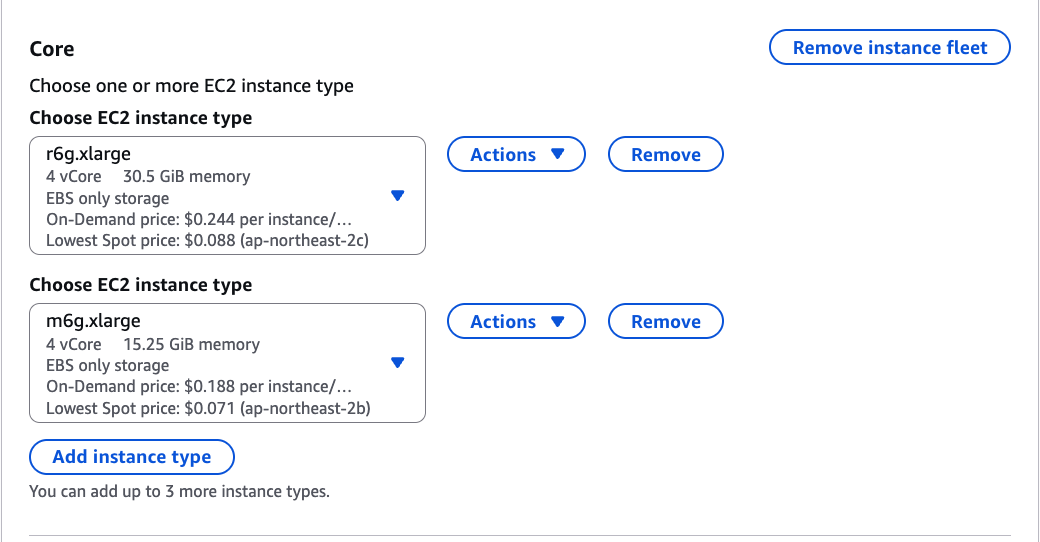
Allocation strategy 설정: On-Demand 전략은 lowest price, Spot 전략은 capacity-optimized

Cluster scaling 및 provisioning: Core 3, On-Demand 0, Launch timeout 후 On-Demand 전환, Timeout 10분, Resize timeout 10분
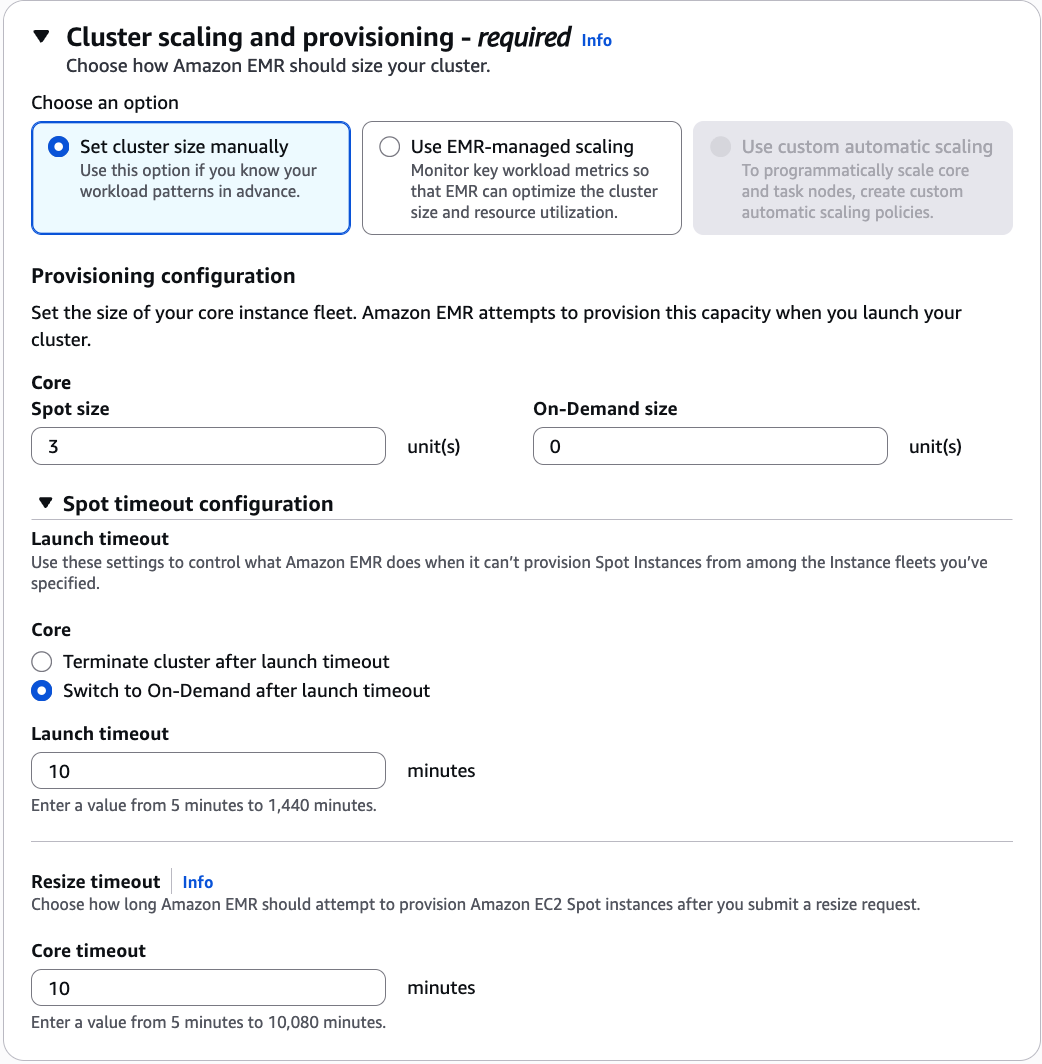
4️⃣ HA(Multi-Master)와 Instance Fleet 호환 문제
아래와 같은 에러가 발생할 수 있다.
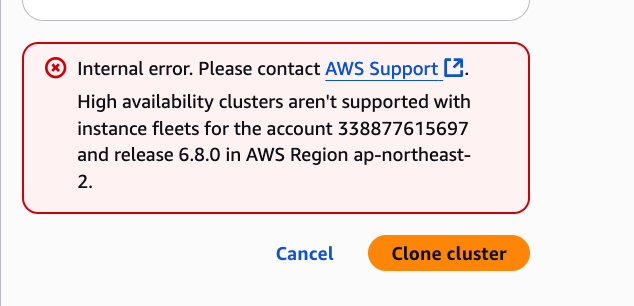
Internal error. Please contact AWS Support.
High availability clusters aren't supported with instance fleets for the account 338877615697 and release 6.8.0 in AWS Region ap-northeast-2.
- EMR 6.8.0에서는 일부 계정/리전에서 Multi-Master + Instance Fleet 조합이 지원되지 않는다.
- Multi-Master 클러스터는 EC2 Instance Group 기반만 지원될 수 있으며, Spot/On-Demand 혼합 설정 시 에러가 발생할 수 있다.
5️⃣ Spot 인스턴스 종료 시 EMR 동작
- Spot(Core 노드) 종료 시 EMR은 노드가 없어졌다고 판단한다.
- Allocation strategy에 따라 새 노드를 채우려고 시도한다.
- Spot 우선 → 다른 Spot 풀에서 먼저 시도
- 모든 Spot 풀 실패 → 설정에서 “Switch to On-Demand after launch timeout” 옵션이 켜져 있으면 On-Demand로 대체
- Launch timeout 동안 Spot 확보 실패 → Cluster terminate 가능
6️⃣ 요금과 우선 순위
EMR은 Spot → On-Demand 순서로 시도한다.
- Spot 풀에서 찾다가 실패 → launch timeout 후 On-Demand 시도
- 여전히 실패하면 다른 인스턴스 타입(예: m6g.xlarge)으로 대체
- On-Demand는 고정 요금이므로 단순히 다른 타입/풀에서 시도하는 과정이다.
결론
- InstanceGroup 기반 Spot-only 구성 → 자동 복구 불가
- InstanceFleet 기반 Spot + On-Demand → 자동 복구 가능
- Spot 종료 대비, 핵심 클러스터는 On-Demand 혹은 Fleet 기능 활용 필요
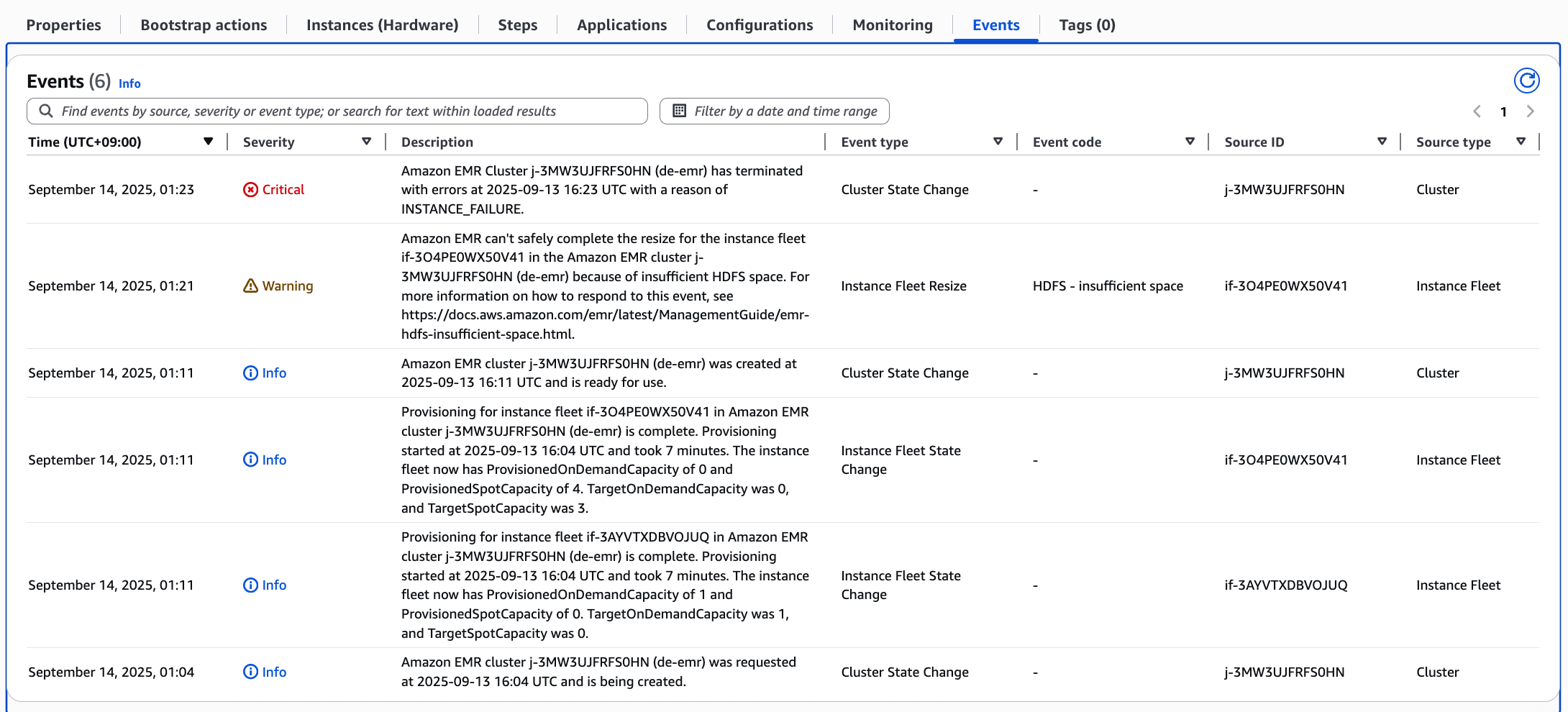
1️⃣ 로그 핵심 포인트
Cluster 생성 완료
2025-09-14 01:11 UTC
Provisioning complete
ProvisionedOnDemandCapacity=0
ProvisionedSpotCapacity=4
TargetOnDemandCapacity=0
TargetSpotCapacity=3
Core Fleet은 Spot 4개 Provisioned, On-Demand 0
Target Spot 3, Target On-Demand 0 → Spot 우선으로 설정됨
Resize 실패
2025-09-14 01:21 UTC
Amazon EMR can't safely complete the resize ... because of insufficient HDFS space
EMR에서 Spot 인스턴스가 종료되거나 용량을 늘리려고 할 때, HDFS 공간 부족 때문에 새로운 노드를 안전하게 추가할 수 없음
즉, EMR이 Spot → On-Demand로 자동 전환하려고 해도, HDFS가 용량 부족이면 추가 Provisioning 자체가 막힘
Cluster 종료
2025-09-14 01:23 UTC
Cluster terminated with INSTANCE_FAILURE
HDFS 공간 부족으로 인해 Fleet resize 실패 → 클러스터 종료(INSTANCE_FAILURE)
2️⃣ 이유 요약
Spot 종료 → On-Demand fallback 원칙은 맞음
하지만 HDFS 안전성 체크 때문에 On-Demand 노드가 추가되지 않은 상태
EMR은 HDFS에 데이터 블록을 안전하게 복제할 수 없는 경우 노드 추가를 막음 → 결국 On-Demand 전환이 안 됨
결과적으로 Spot 부족이나 종료 상황에서도 자동 복구 실패
3️⃣ 해결 방안
HDFS 용량 확보
기존 Core 노드에 충분한 디스크 공간 확보
EBS 볼륨 크기 늘리기 또는 Core 노드 수를 늘려 HDFS replication 공간 확보
Fleet 설정 조정
Launch timeout과 Switch to On-Demand 옵션 확인
TargetOnDemandCapacity를 1 이상으로 두어 Spot 실패 시 즉시 On-Demand provisioning 가능
Auto Scaling 고려
HDFS 공간을 기준으로 Scaling Policy 설정 가능
예: Disk Utilization ≥ 80% → On-Demand 추가
즉, 지금 상황에서는 “Spot 종료 → On-Demand fallback”이 동작하지 않은 이유는 HDFS 공간 부족 때문에 EMR이 노드 추가를 안전하게 할 수 없어서이다.
먼저 HDFS 용량 문제를 해결해야 On-Demand fallback이 정상적으로 동작한다.
원하면 제가 HDFS 공간 부족 상황에서 안전하게 Instance Fleet을 설정하는 JSON 예시까지 만들어 드릴 수 있다.
aws emr create-cluster \
--name "de-emr" \
--log-uri "s3://leo4study/emr-log" \
--release-label "emr-6.8.0" \
--service-role "arn:aws:iam::338877615697:role/EMR_DefaultRole" \
--ec2-attributes '{"InstanceProfile":"EMR_EC2_DefaultRole","EmrManagedMasterSecurityGroup":"sg-01c243fb29396806b","EmrManagedSlaveSecurityGroup":"sg-09a6a122fee935214","KeyName":"fastcampus_de","AdditionalMasterSecurityGroups":[],"AdditionalSlaveSecurityGroups":[],"SubnetIds":["subnet-072c02c56337d15ad"]}' \
--applications Name=Flink Name=Ganglia Name=Hadoop Name=HBase Name=HCatalog Name=Hive Name=JupyterHub Name=Livy Name=Spark Name=Tez Name=Trino Name=ZooKeeper \
--configurations '[{"Classification":"hive-site","Properties":{"javax.jdo.option.ConnectionDriverName":"org.mariadb.jdbc.Driver","javax.jdo.option.ConnectionPassword":null,"javax.jdo.option.ConnectionURL":"jdbc:mysql://de-emr.c928wie02lla.ap-northeast-2.rds.amazonaws.com:3306/hive?createDatabaseIfNotExist=true","javax.jdo.option.ConnectionUserName":"hive"}},{"Classification":"jupyter-sparkmagic-conf","Properties":{"kernel_python_credentials":null}}]' \
--instance-fleets '[{"Name":"Core","InstanceFleetType":"CORE","TargetSpotCapacity":2,"TargetOnDemandCapacity":1,"LaunchSpecifications":{"SpotSpecification":{"TimeoutDurationMinutes":15,"TimeoutAction":"TERMINATE_CLUSTER","AllocationStrategy":"PRICE_CAPACITY_OPTIMIZED"},"OnDemandSpecification":{"AllocationStrategy":"LOWEST_PRICE"}},"InstanceTypeConfigs":[{"WeightedCapacity":4,"EbsConfiguration":{"EbsBlockDeviceConfigs":[{"VolumeSpecification":{"VolumeType":"gp2","SizeInGB":32}},{"VolumeSpecification":{"VolumeType":"gp2","SizeInGB":32}}]},"BidPriceAsPercentageOfOnDemandPrice":100,"InstanceType":"r6g.xlarge"},{"WeightedCapacity":4,"EbsConfiguration":{"EbsBlockDeviceConfigs":[{"VolumeSpecification":{"VolumeType":"gp2","SizeInGB":32}},{"VolumeSpecification":{"VolumeType":"gp2","SizeInGB":32}}]},"BidPriceAsPercentageOfOnDemandPrice":100,"InstanceType":"m6g.xlarge"}]},{"Name":"Primary","InstanceFleetType":"MASTER","TargetSpotCapacity":0,"TargetOnDemandCapacity":1,"LaunchSpecifications":{"OnDemandSpecification":{"AllocationStrategy":"LOWEST_PRICE"}},"InstanceTypeConfigs":[{"WeightedCapacity":1,"EbsConfiguration":{"EbsBlockDeviceConfigs":[{"VolumeSpecification":{"VolumeType":"gp2","SizeInGB":32}},{"VolumeSpecification":{"VolumeType":"gp2","SizeInGB":32}}]},"BidPriceAsPercentageOfOnDemandPrice":100,"InstanceType":"r6g.xlarge"}]}]' \
--scale-down-behavior "TERMINATE_AT_TASK_COMPLETION" \
--ebs-root-volume-size "50" \
--step-concurrency-level "256" \
--region "ap-northeast-2"이렇게 합의를 보았다.