Grafana에서 대시보드를 구성하기 위해서는 다음 과정을 거친다. 매뉴얼
1. Datasource 추가하기
2. Create Dashboard
3. Create Panel in Dashboard
Alert 받기 위해서는 다음 과정이 필요하다. 매뉴얼
이거는 이메일을 설정해서 이메일 기반으로 contact point를 설정하고 alert 를 써서 오게 할 것.
- Create contact point
- Create policy
- Create alert rule (from panel)
ps -ef | grep grafanagrafana 잘 떠있는지 확인하고.

웹 환경에서 진행하도록 할 것임.
처음 우선 데이터를 확인하려면 데이터가 어디있는지 알아야함. 그게 data source 라고 함.
왼쪽 아래 설정에 메뉴 보면 data sources 가 있음
다른 옵션들도 있으니 확인 한 번씩 해보고
고도화된 회사나 팀들에서도 쓰고 있기 때문에 이런 Access Control도 옵션이 많이 있다. 보안 설동도 가능.
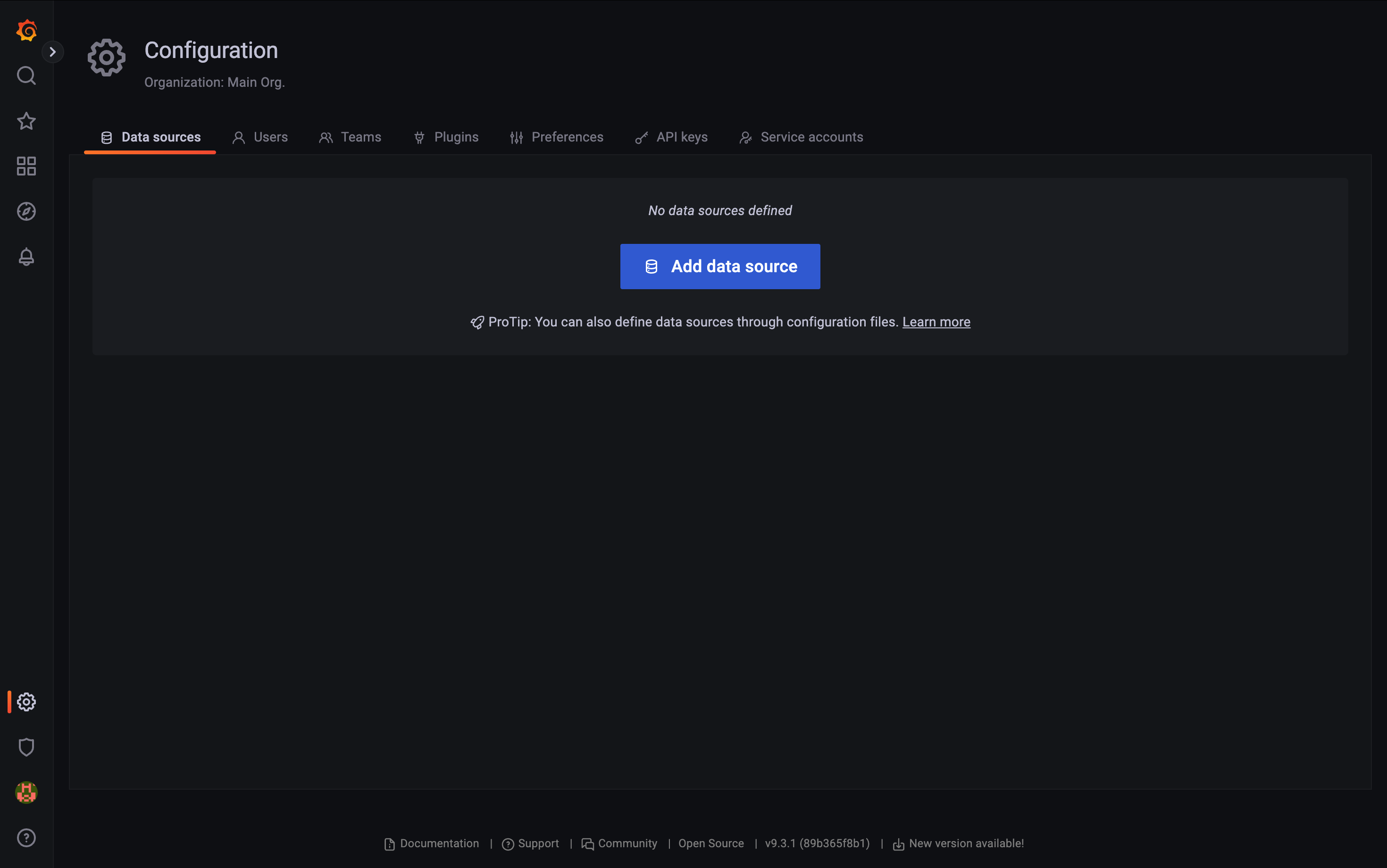
처음엔 아무 것도 없을 텐데
Add Data source눌러주자.
쓸 수 있는 데이터베이스 종류가 여러가지고 나온다.
여기서 여러가지 선택할 수 있는 옵션들이 있다는 건
얘네들의 프로토콜을 Grafana가 알고 있다는 것.
프로토콜에 맞춰서 할 수 있고
특히 CloudWatch, AWS나 Azure 모니터링, 그리고 구글 클라우드 모니터링 들도 다 붙일 수 있다.
여기에 없는 것들은 API call 이나 HTTP, TCP 기반 프로토콜로 따로 설정할 수 있다.
prometheus 선택.
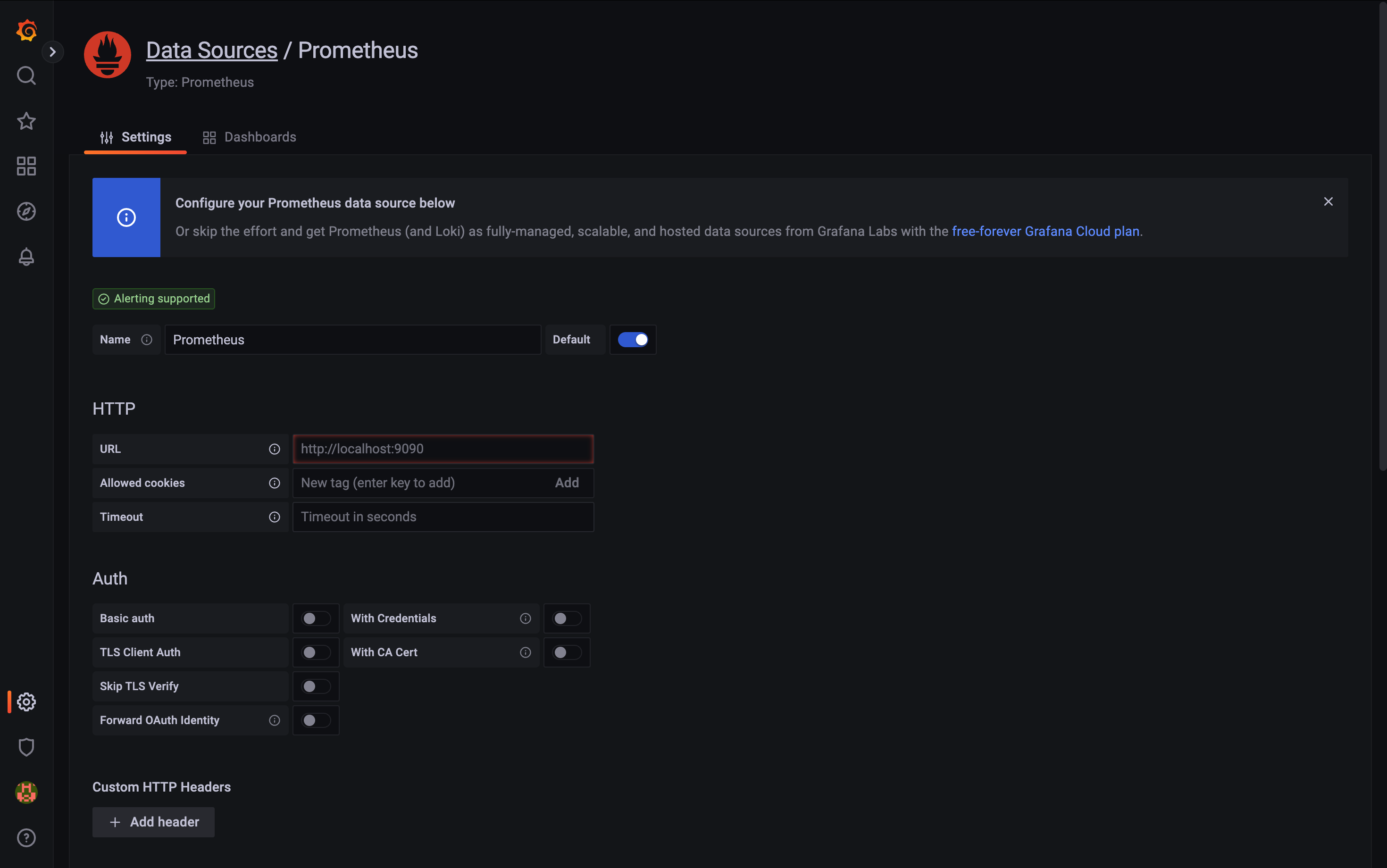
여기서 쓰는 주소는 도메인 주소도 좋고,
Grafana 서버 입장에서 접속할 수 있는 주소여야 한다.
내가 웹 화면을 보는 클라이언트랑은 다르다는 것을 꼭 이해를 해줘야 함.
URL : http://localhost:9090
https 등 다른 옵션들은 안 쓰기 때문에 기본으로 놔둔다.
맨 아래 페이지 내려보면 Save & test
버튼 클릭해서 초록색 버튼 나와야 제대로 되는 것인데, 접속이 안되는 주소를 하면
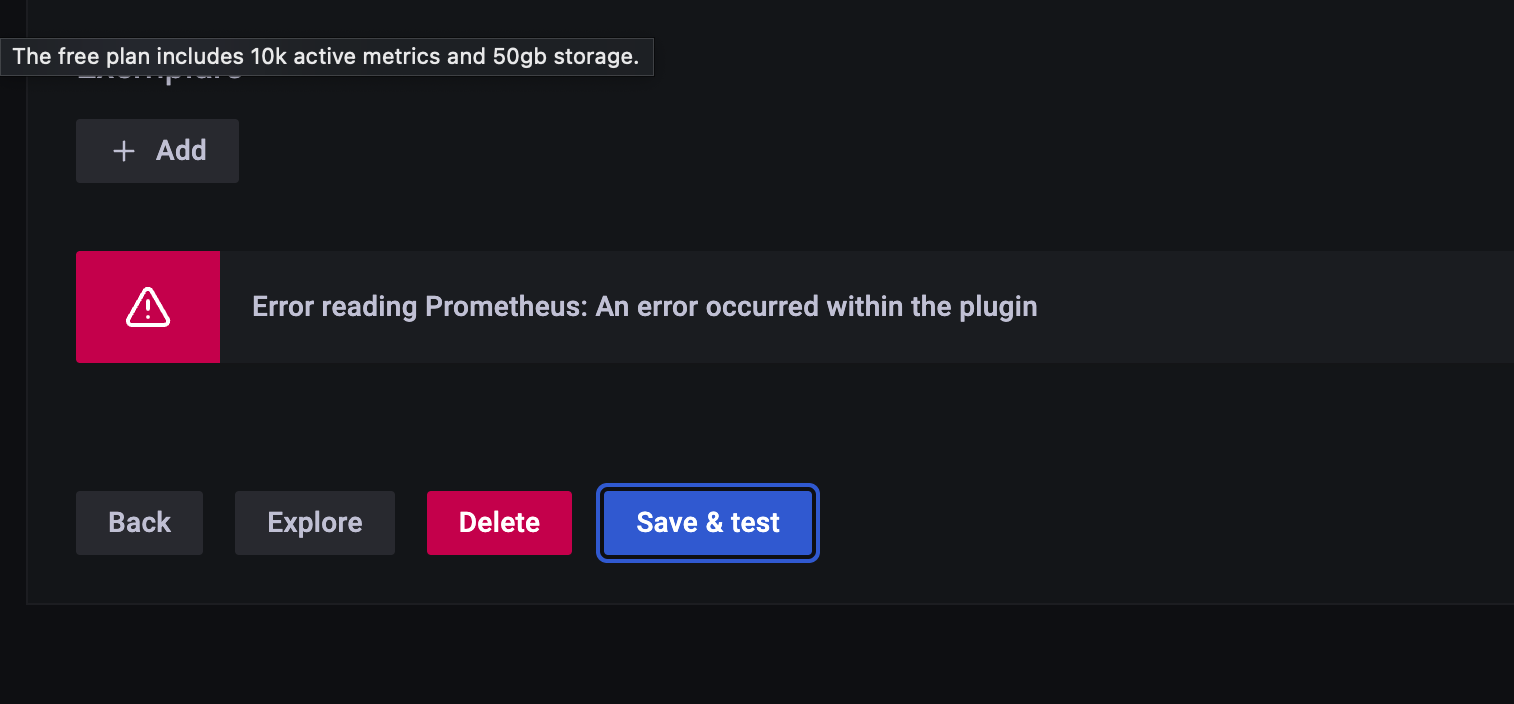
이런 에러가 올라온다.
맨 위에 올려보면
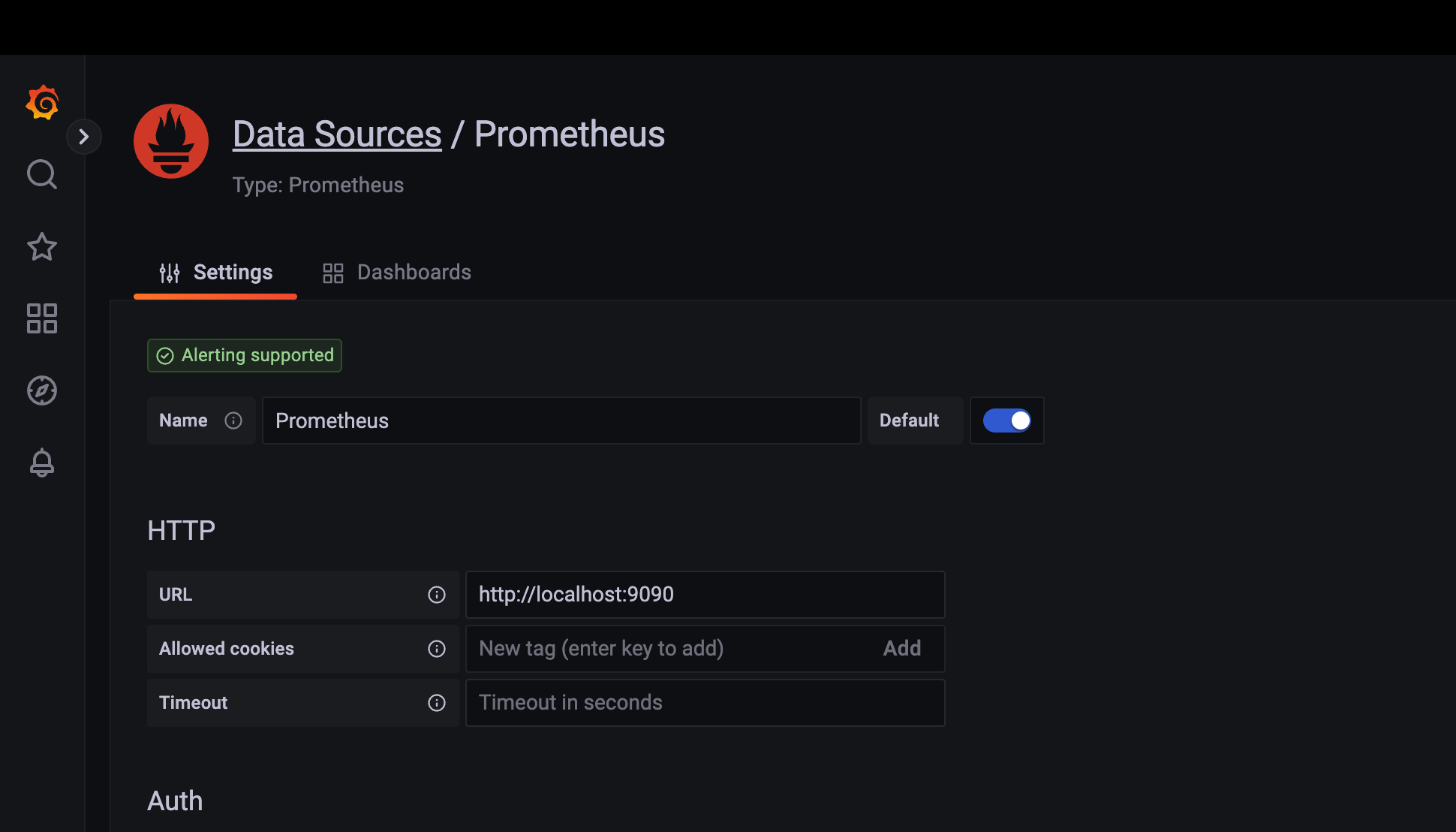
이 해당 데이터 소스가Alerting supported 라고 체킹이 돼야
Grafana가 아하 이 데이터 소스는 alerting 기능을 지원하는 애야~ 라고 해서
자신의 서버에서 판단하는 게 아니라 해당 데이터 소스에서 쿼리로 alert를 판단해서 오게 해서 조금 더 alert 시스템에 대한 부하를 낮출 수 있다.
back 버튼으로 다시 돌아가서
설정을 눌러보면
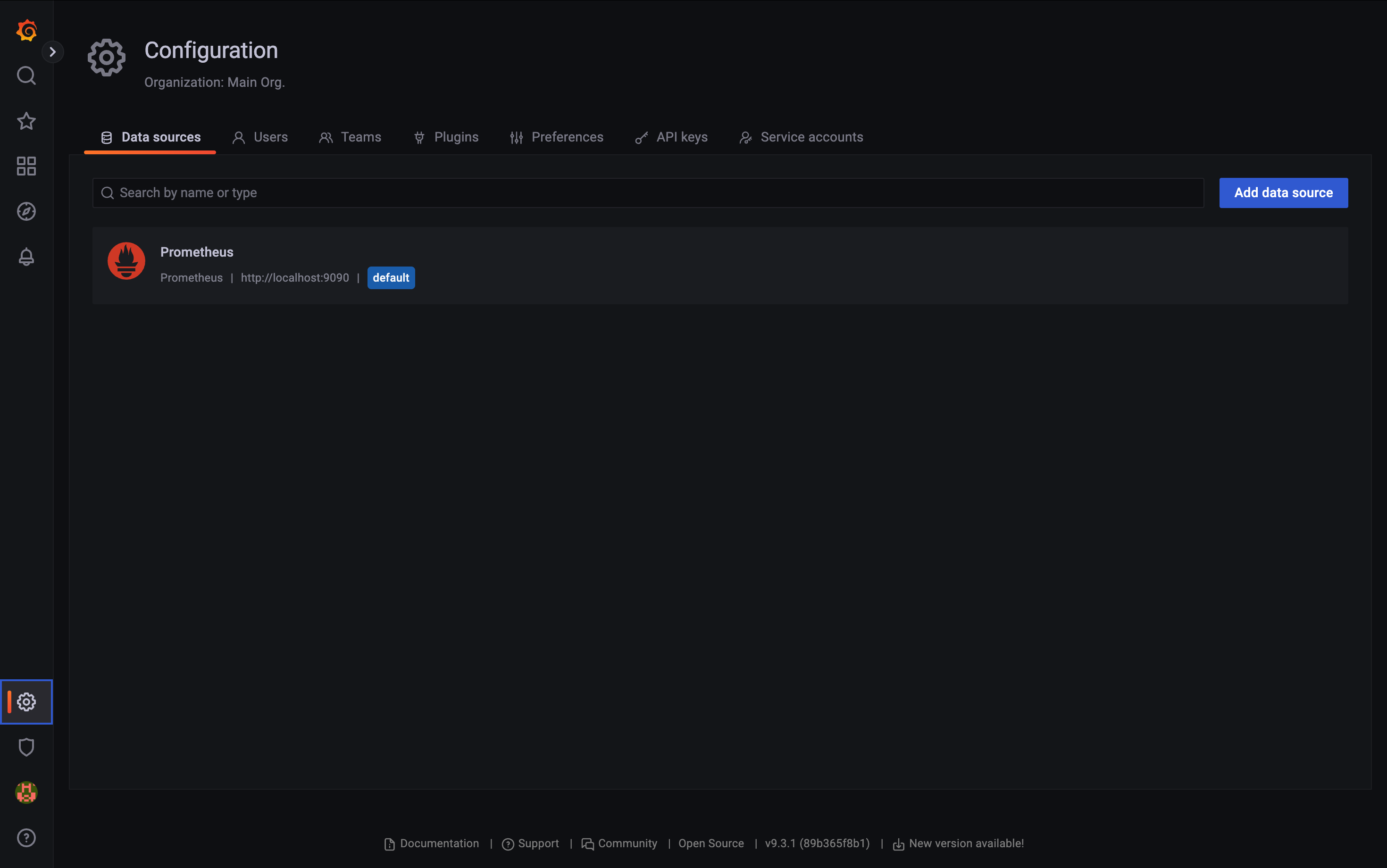
이렇게 Prometheus라는 데이터 소스가 추가된 것을 볼 수 있다.
이제 대시보드를 만들어 보자.
Dashboards > Browse
들어가보자
아직 들어온 게 없어서 아무것도 없고
지금 General 이라는 폴더가 기본으로 만들어져 있다.
New > New Dashboard 클릭
Add a new panel 클릭
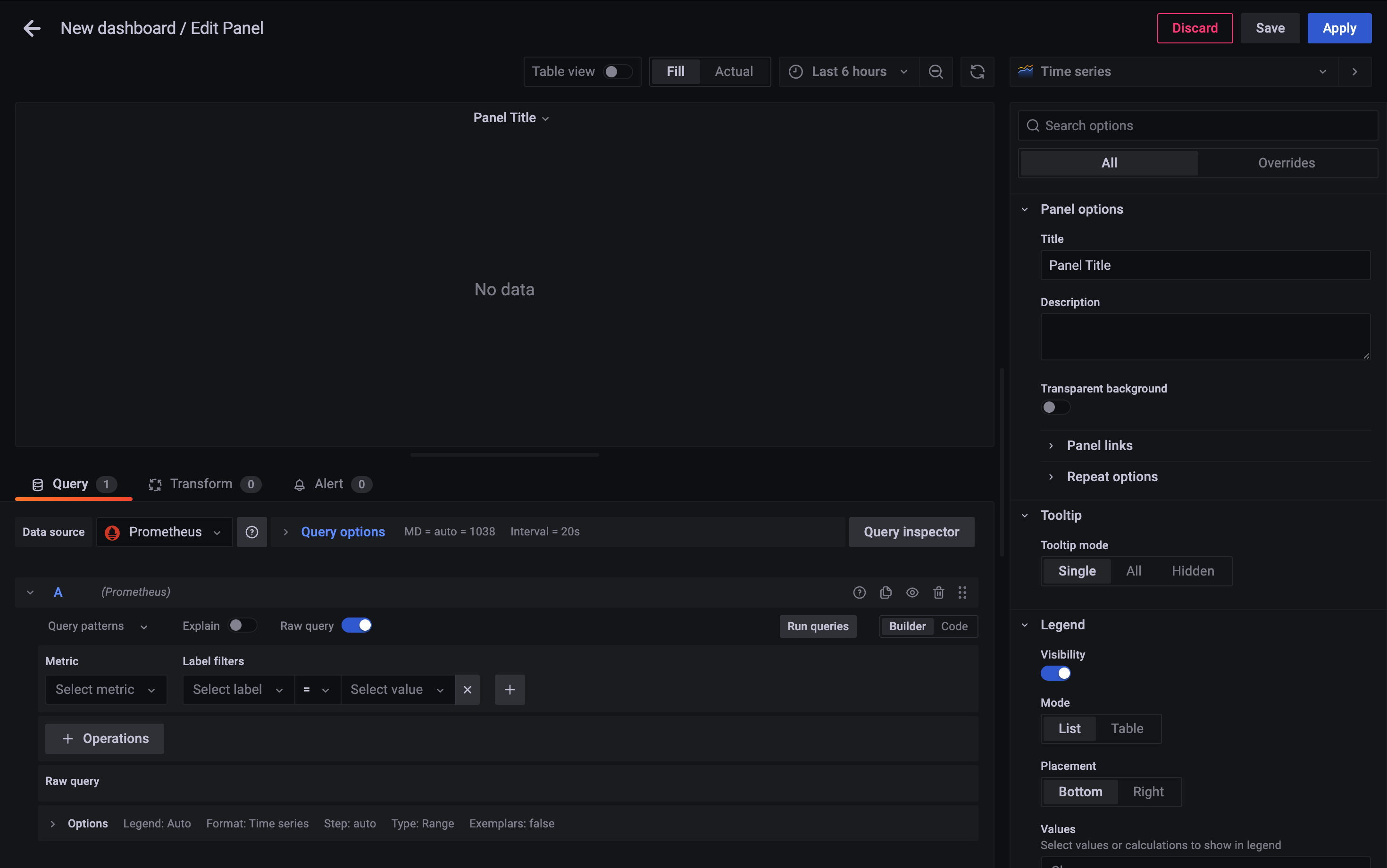
이런 화면이 나온다.
여기서 꼭 설정해야될 게 Data source를 꼭 설정해줘야 한다.
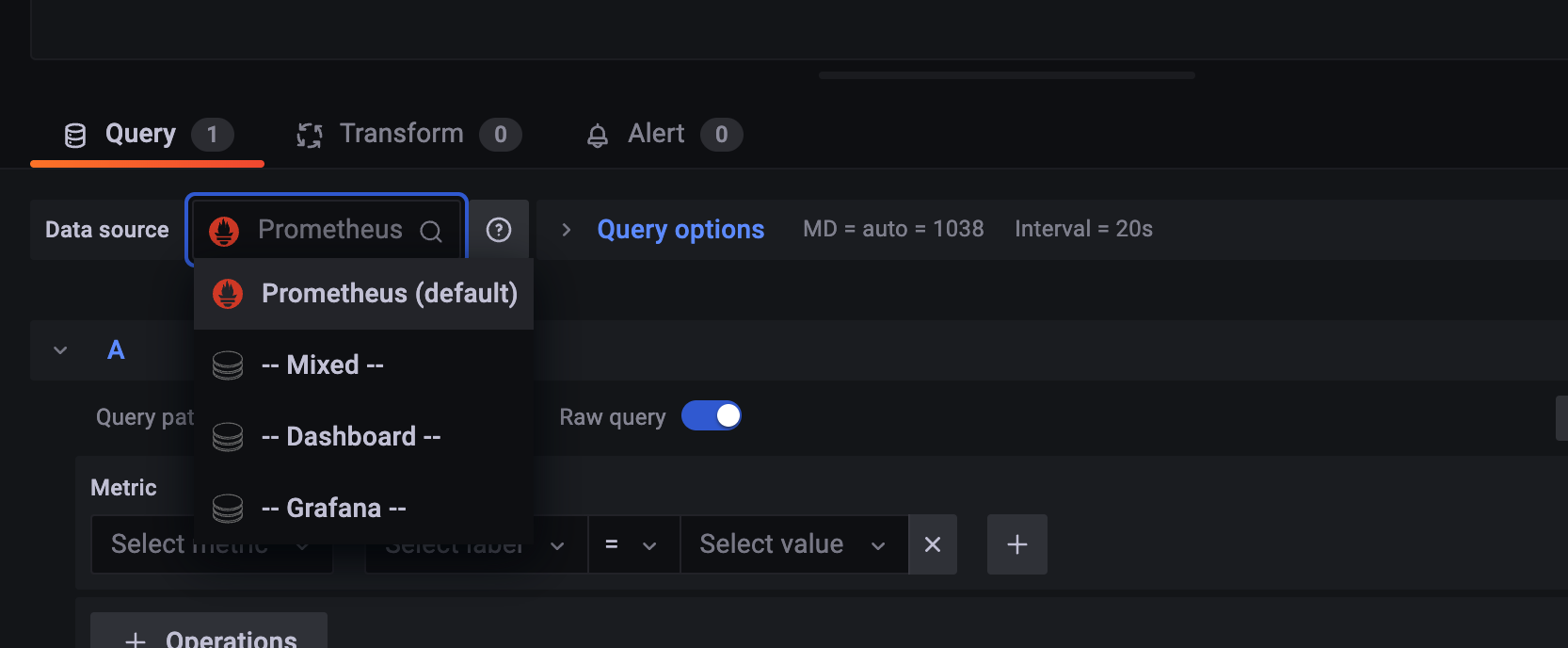
Prometheus로 설정.
--Mixed: 각 쿼리 별로 데이터 소스를 설정할 수 있다
아래 A 라고 되어 있는 곳에다가 내가 쓸 쿼리들을 여러 개 쓸 수 있다.
Metric 을 눌러보면 현재 내가 Prometheus에서 쓸 수 있는 metric들이 나온다.
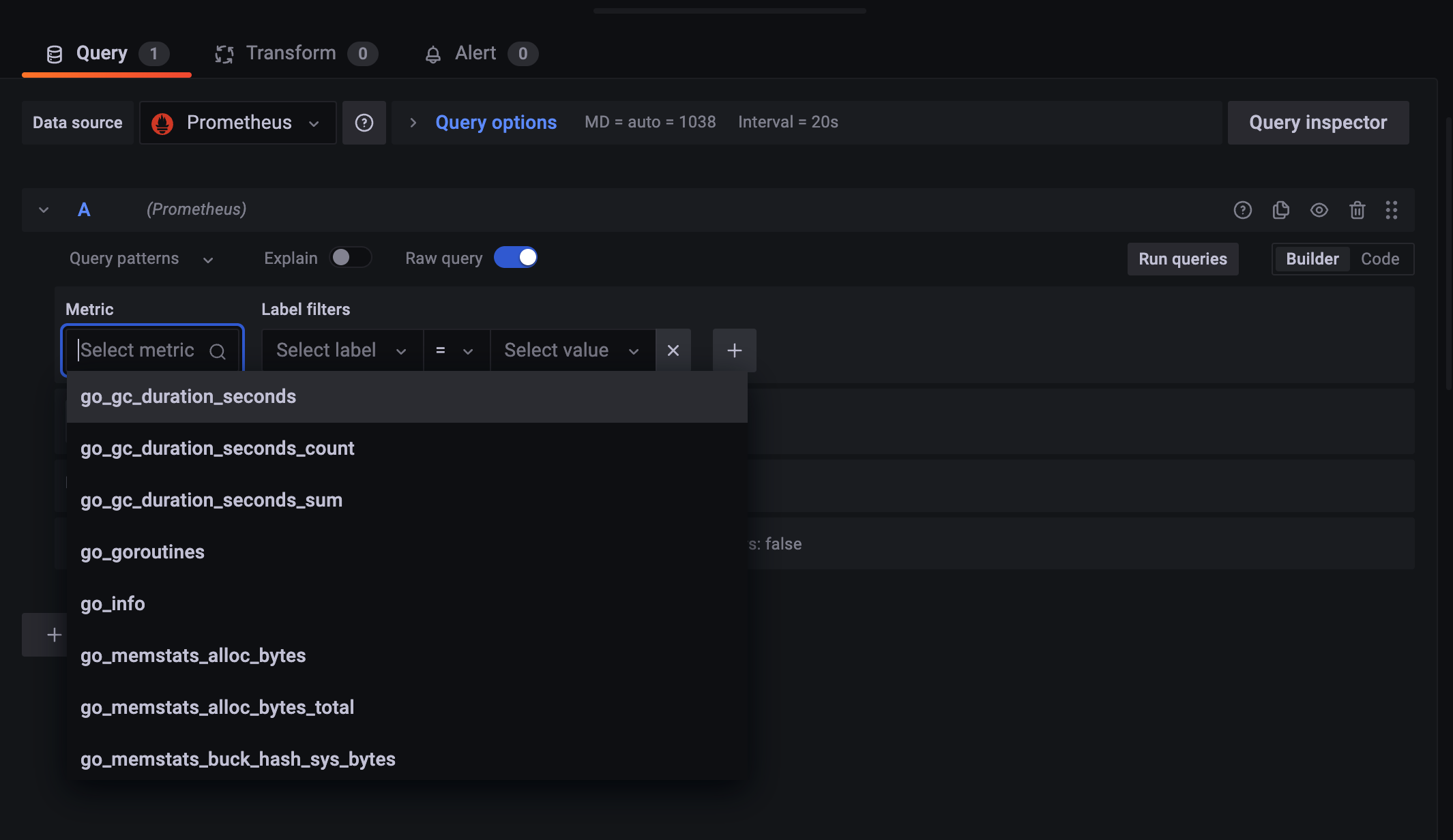
오른쪽 위에 Code 를 클릭해서
직접 입력할 수 있다.
Prometheus/metric 화면을 봐 보자.
프로메테우스 서버가 자기자신이 남기는 매트릭들이 수집이 되고 있다.
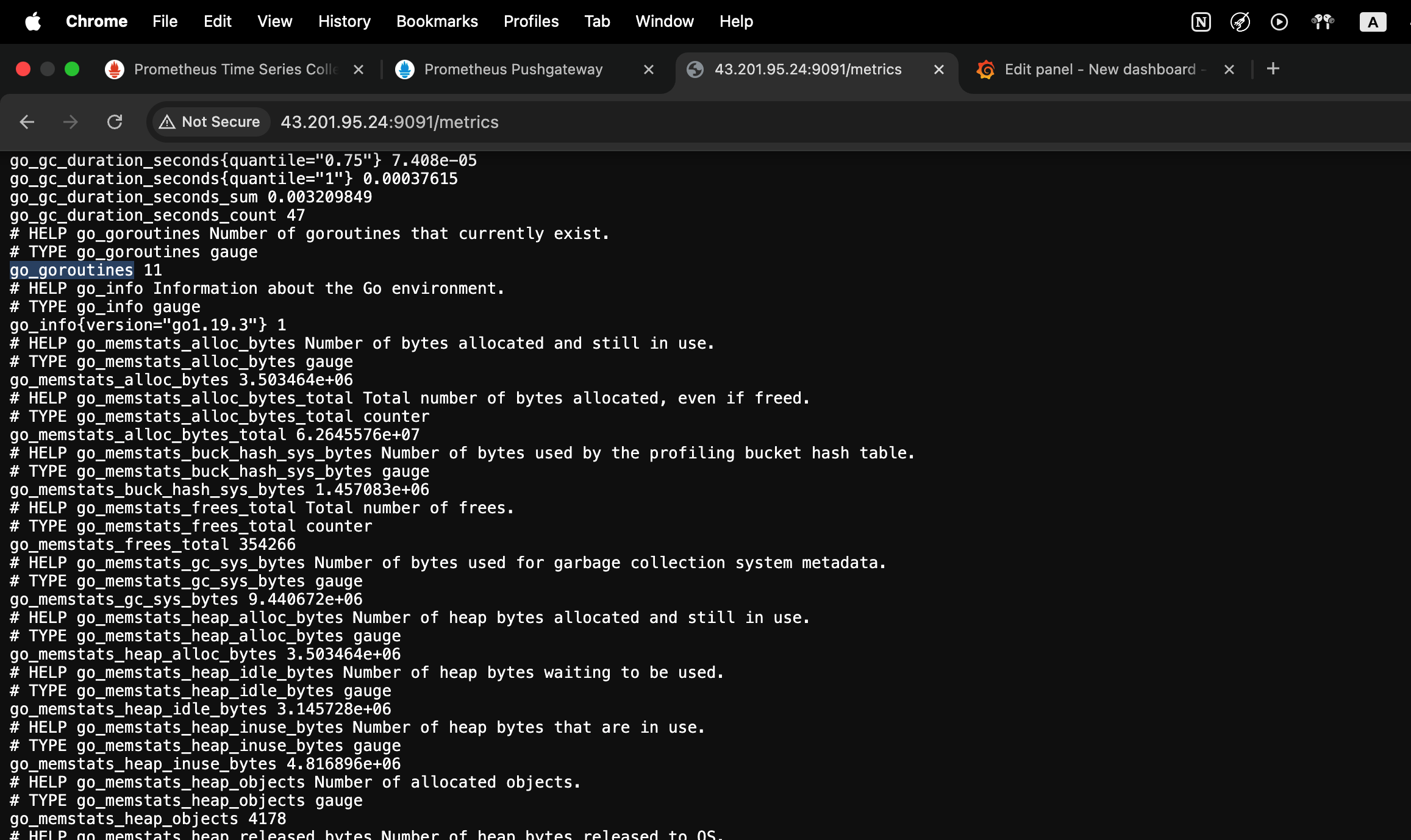
go_goroutines 라는 데이터가 있는데.
type이 늘어날 수도, 줄어들 수도 있는 gauge 다.
현재 11개다.
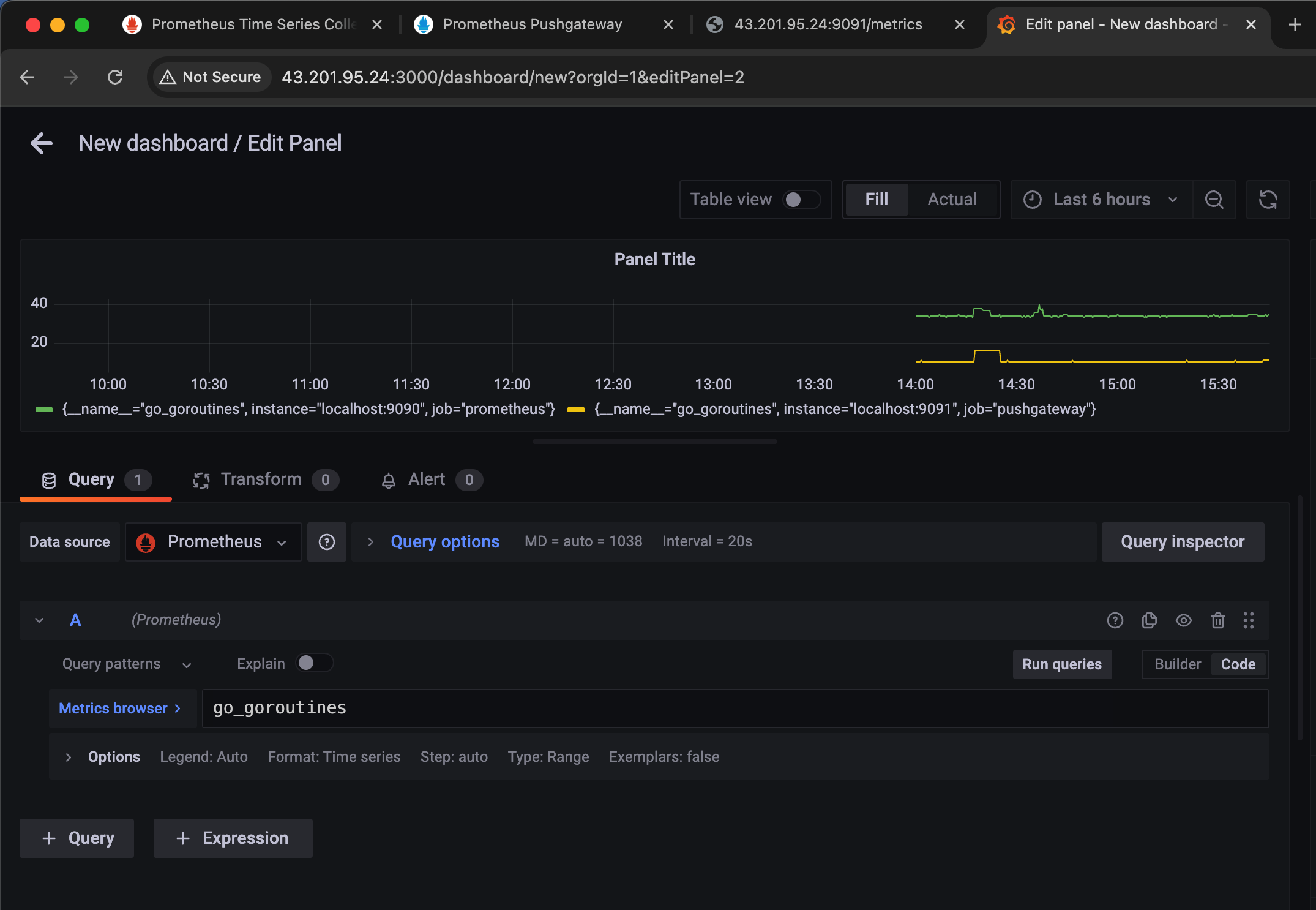
쿼리에 go_goroutines 를 입력해보면 위에처럼 그래프가 나오게 된다.
그래서 실제 GO_Routines 인스턴스가 Localhost 9090:9090, Job = Prometheus인 친구는 34개에서 35개 이렇게 쓰고 있고
Push Gateway 는 10개 정도를 쓰고 있다고 나온다.
metric 을 추가했다면 가장 먼저 해야될 게, panel의 이름을 지어주는 것이다.
단위를 써주는 게 좋다.
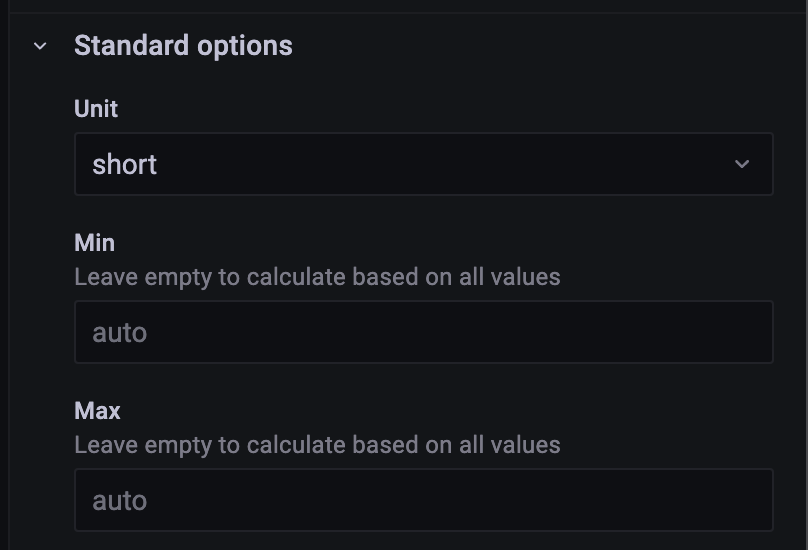
Standard options > Unit 을
Misc > short 로 설정을 해주자.
(short 는 숫자가 많아지면 축약해주는 게 short 다.)
오른쪽 맨 위에
Apply 눌러서 적용.
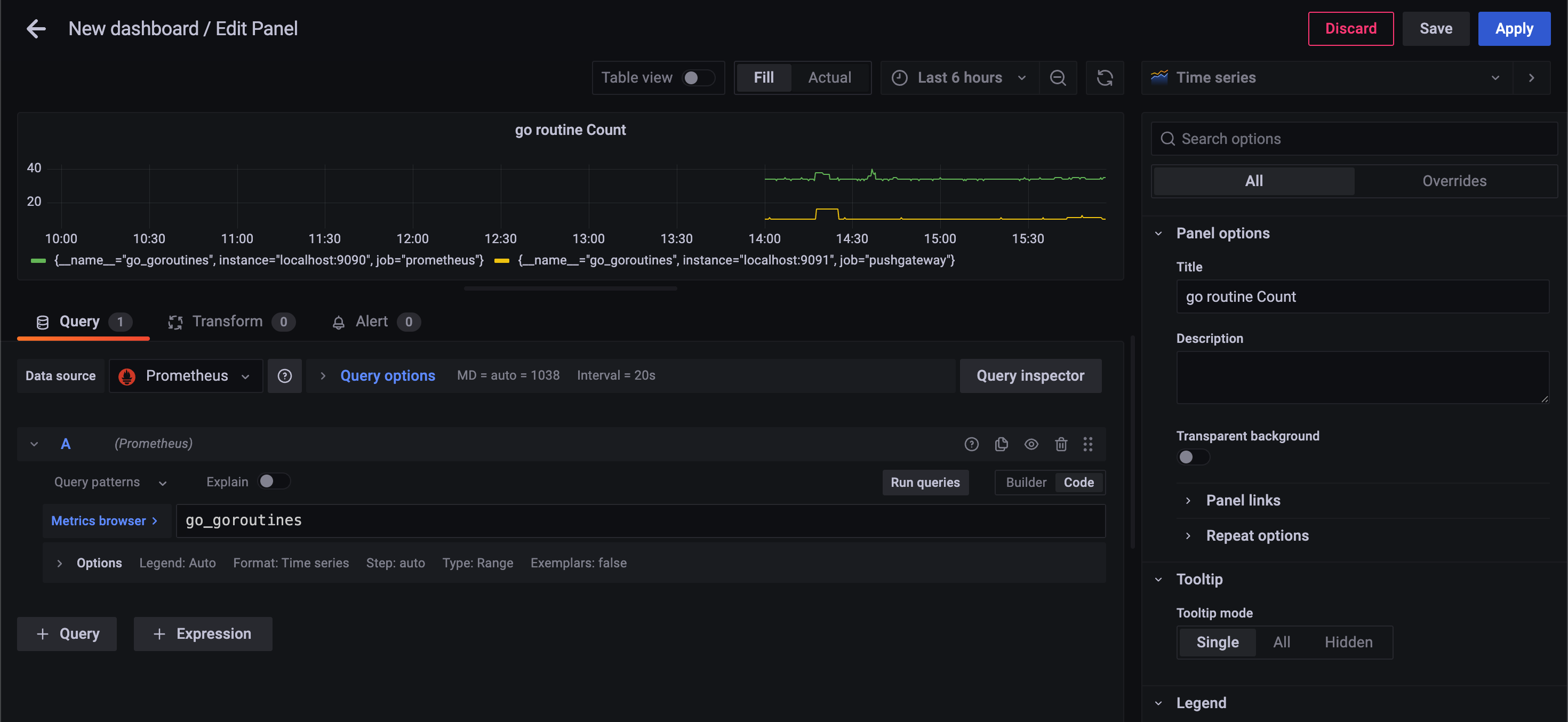
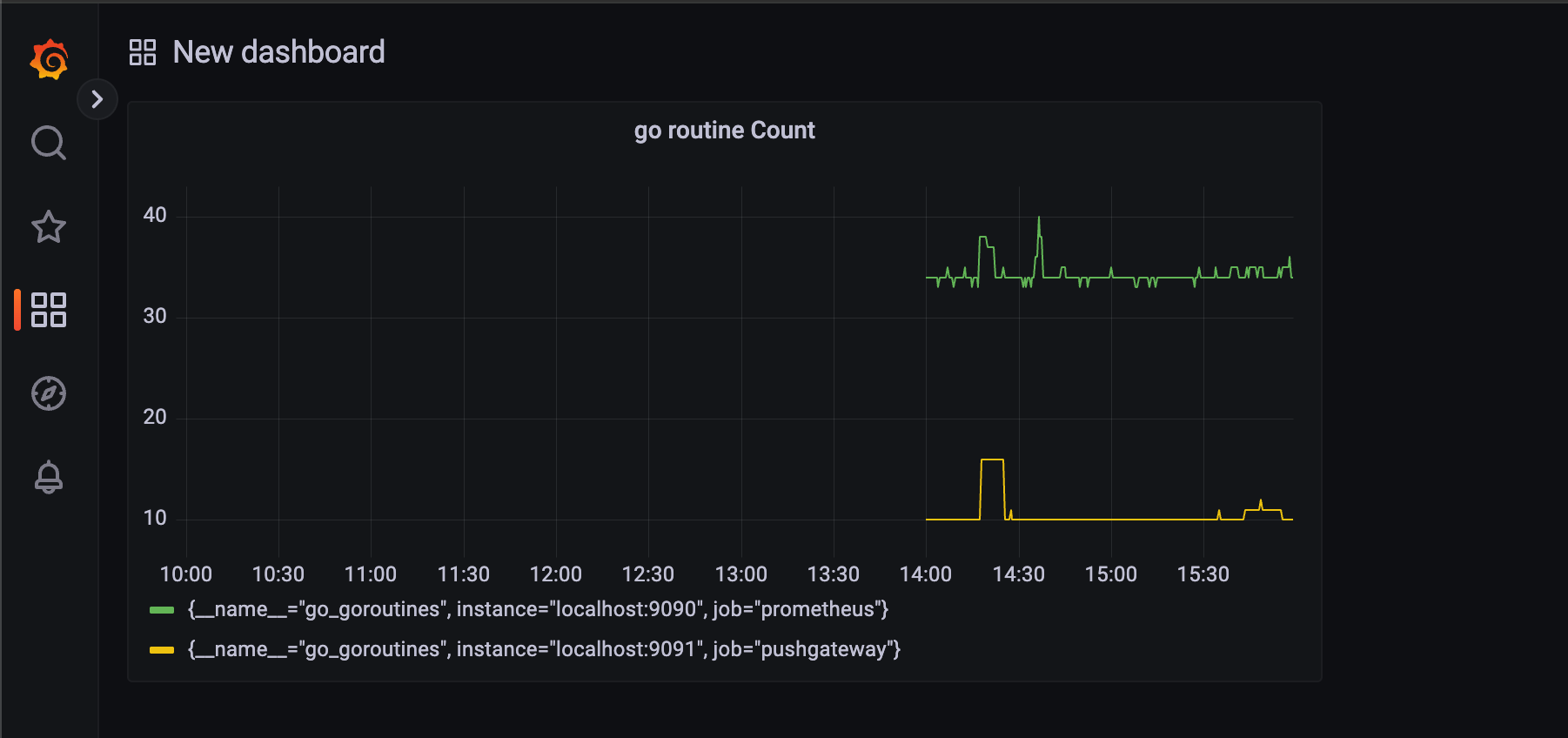
그러면 이렇게 대시보드가 완성된다.
한 번 대시보드가 완성되었다면
오른쪽 위에 save dashboard 를 꼭 눌러서 저장을 해줘야 한다.
저장하지 않으면 현재 화면에서만 적용이 된 것이기 때문에 사라진다.
이렇게 하면 GoRoutines Count 판넬이 만들어진 걸 확인할 수 있다.
대시보드를 보면 각 색깔에 대한 이름이 나오는데 이걸 Legend라고 한다.
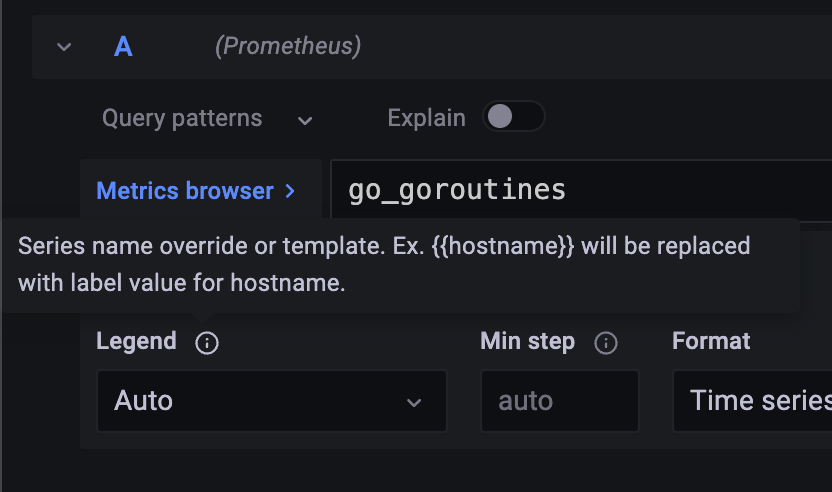
Legend라고 보면 Series Name Overide or Template 이렇게 돼 있어서
중괄호 두 개로 씌우면 Label Name으로 Replace 할 수 있다고나와 있다.
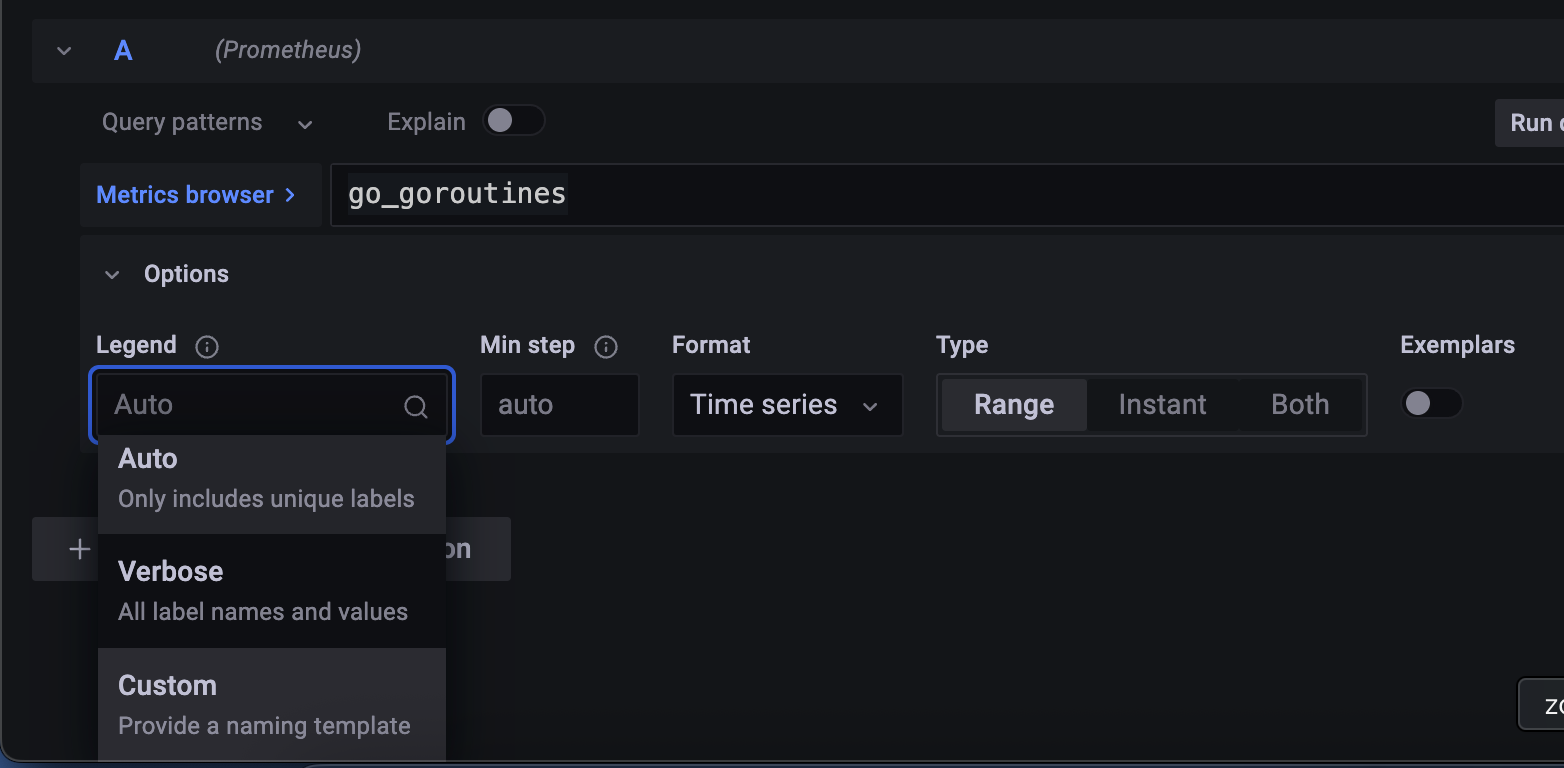
legend 를 custom 으로 바꾸고
{{job}} 이라고 적으면
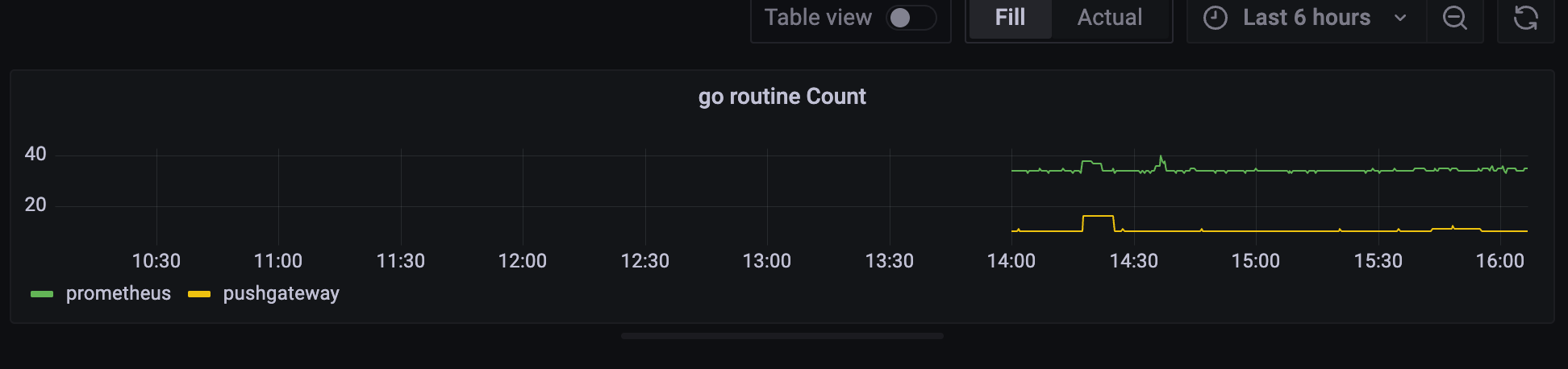
이렇게 legend 의 이름이 job 이름만 나오도록 커스터마이징 할 수 있다.
go_goroutines 은 하나의 서버 안에서만 의미가 있는 것이기 때문에 Instance까지 추가해서
job name, instance name 으로 출력될 수 있도록 설정해두자.
{{job}} {{instance}}
threshold 로 line 표시 가능.
아래 show 옵션 선택을 해 주어야 한다.
다른 사람이 동시에 수정하면 conflict 이런 것들 때문에 오버라이드가 가끔씩 될 수가 있어서 협의해야 함.
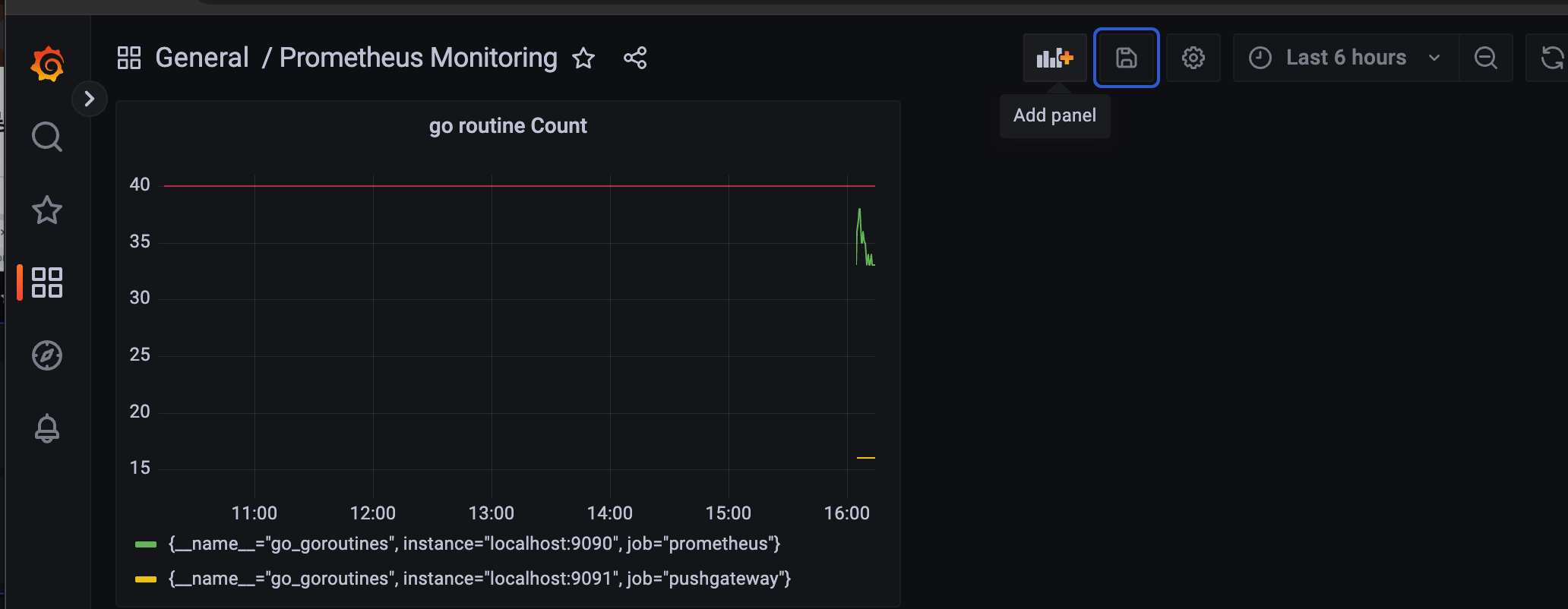
저장 바로 왼쪽 add panel
add a new panel
9091/metric
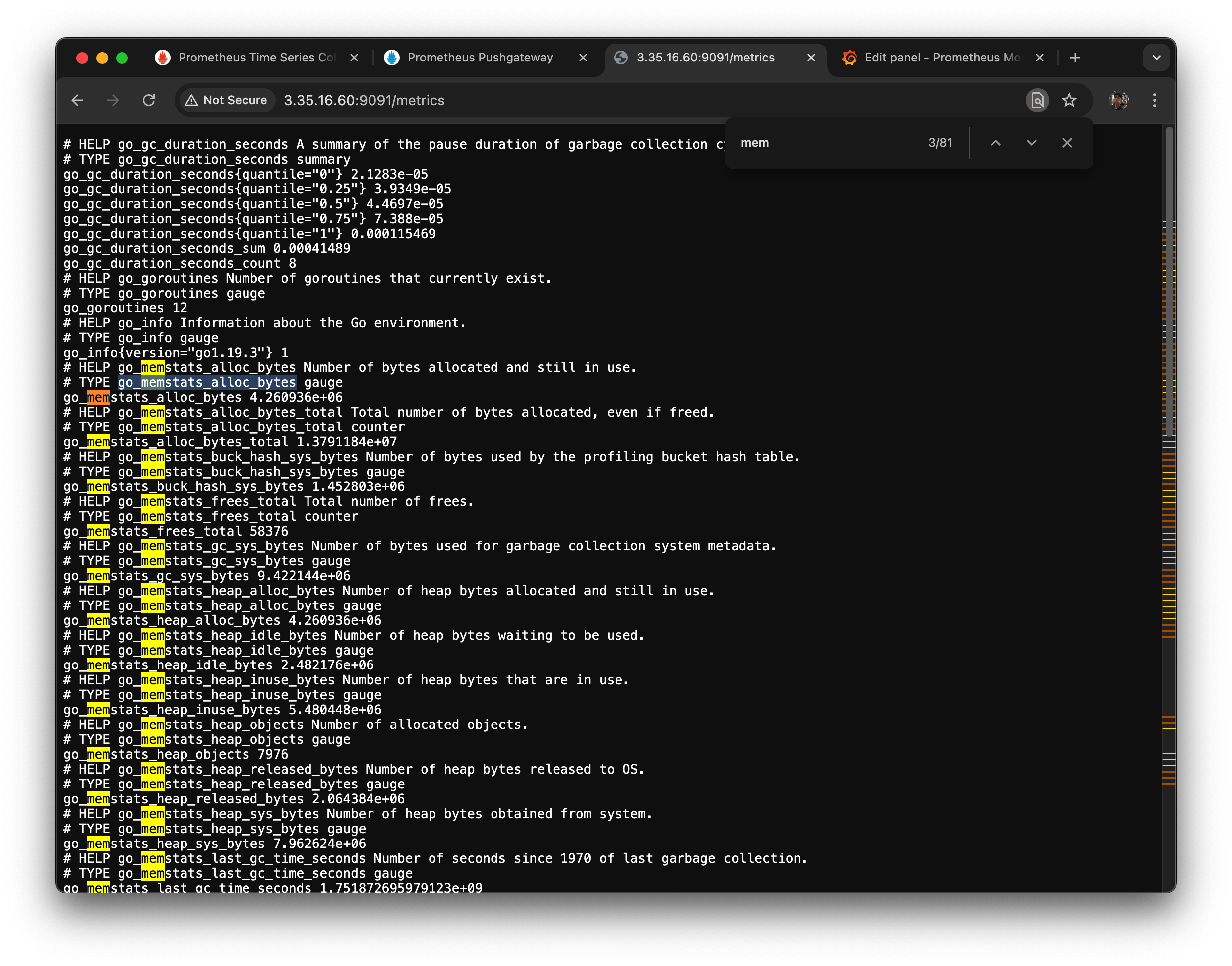
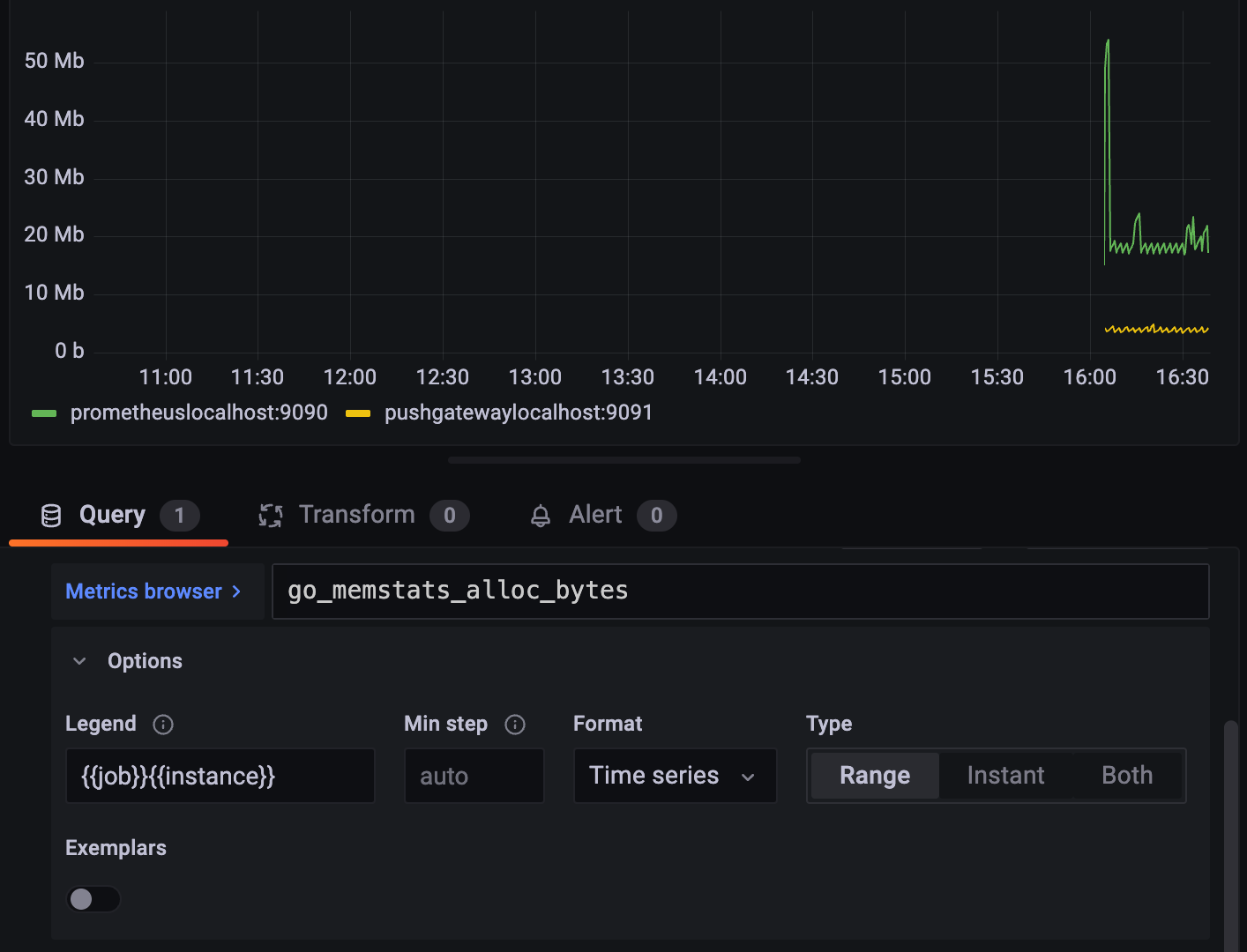
go_memstats_alloc_bytes (gauge) : 프로그램 해당 운영체제에서 받아서 쓰고 있는 값이다. Prometheus 자기 자신의 메모리 사용량 (Go runtime 기준)
node_memory_*: 서버 전체 메모리 상황
서버 모니터링이 목적이라면 nodememory 계열 메트릭을 사용
Prometheus 인스턴스 자체의 성능 측정이 목적이라면 gomemstats 계열이 유용하다.
Metric 이름 설명 node_memory_MemTotal_bytes전체 메모리 node_memory_MemFree_bytes사용 가능한 메모리 (완전히 비어 있는 영역) node_memory_Buffers_bytes커널 버퍼에 사용된 메모리 node_memory_Cached_bytes디스크 캐시로 사용된 메모리 node_memory_MemAvailable_bytes애플리케이션이 자유롭게 쓸 수 있는 메모리 (가장 중요) node_memory_SwapTotal_bytes스왑 총량 node_memory_SwapFree_bytes사용 가능한 스왑 영역
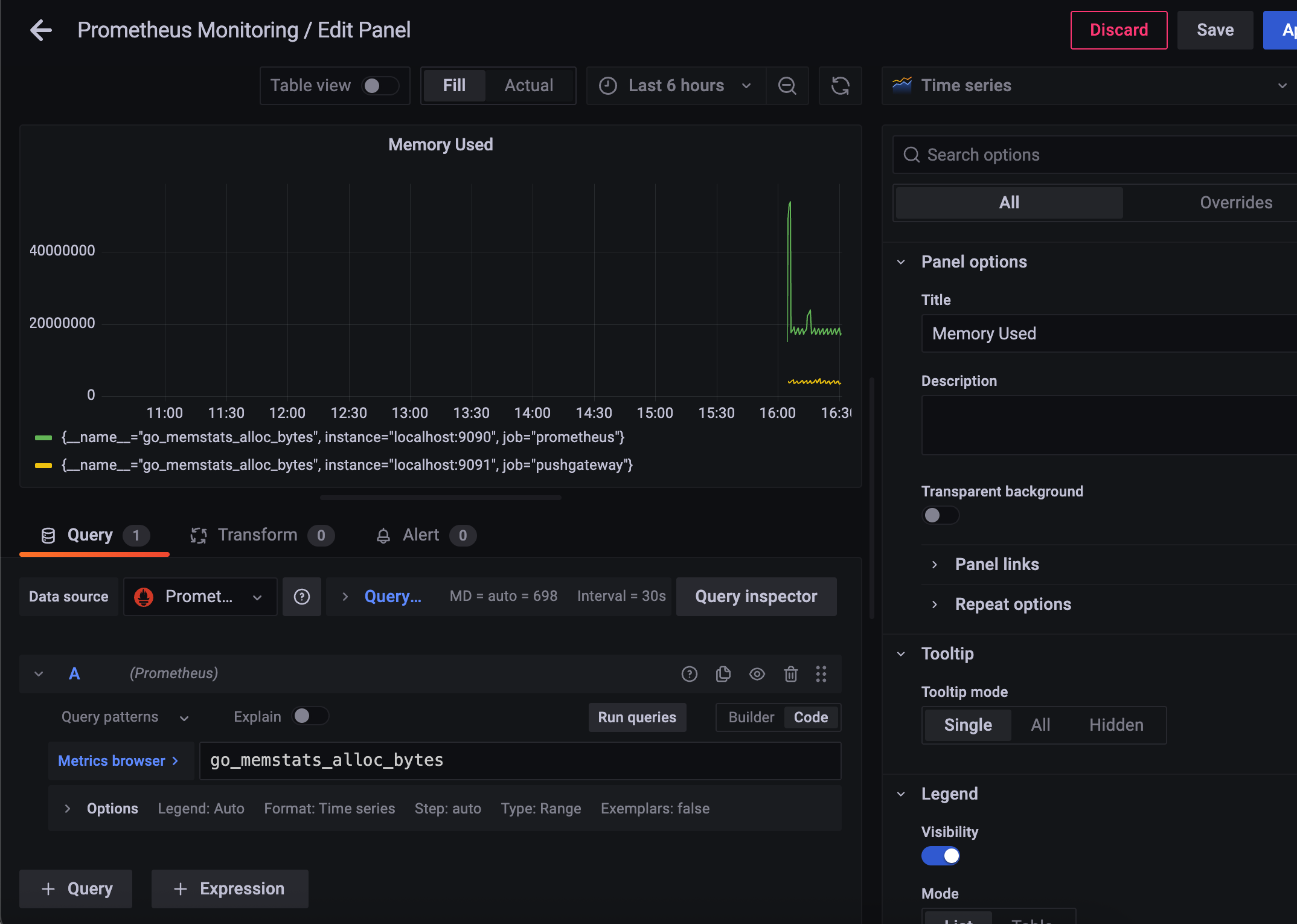
code 로 바꿔서
go_memstats_alloc_bytes 입력,
run Queries
Title 은
Memory Used 로 변경
왼쪽에 단위를 보면 메가바이트 단위로 쓰는 것 같으니
Unit > Data > bytes(SI)
로 설정해서 축약된 상태로 볼 수 있도록 한다
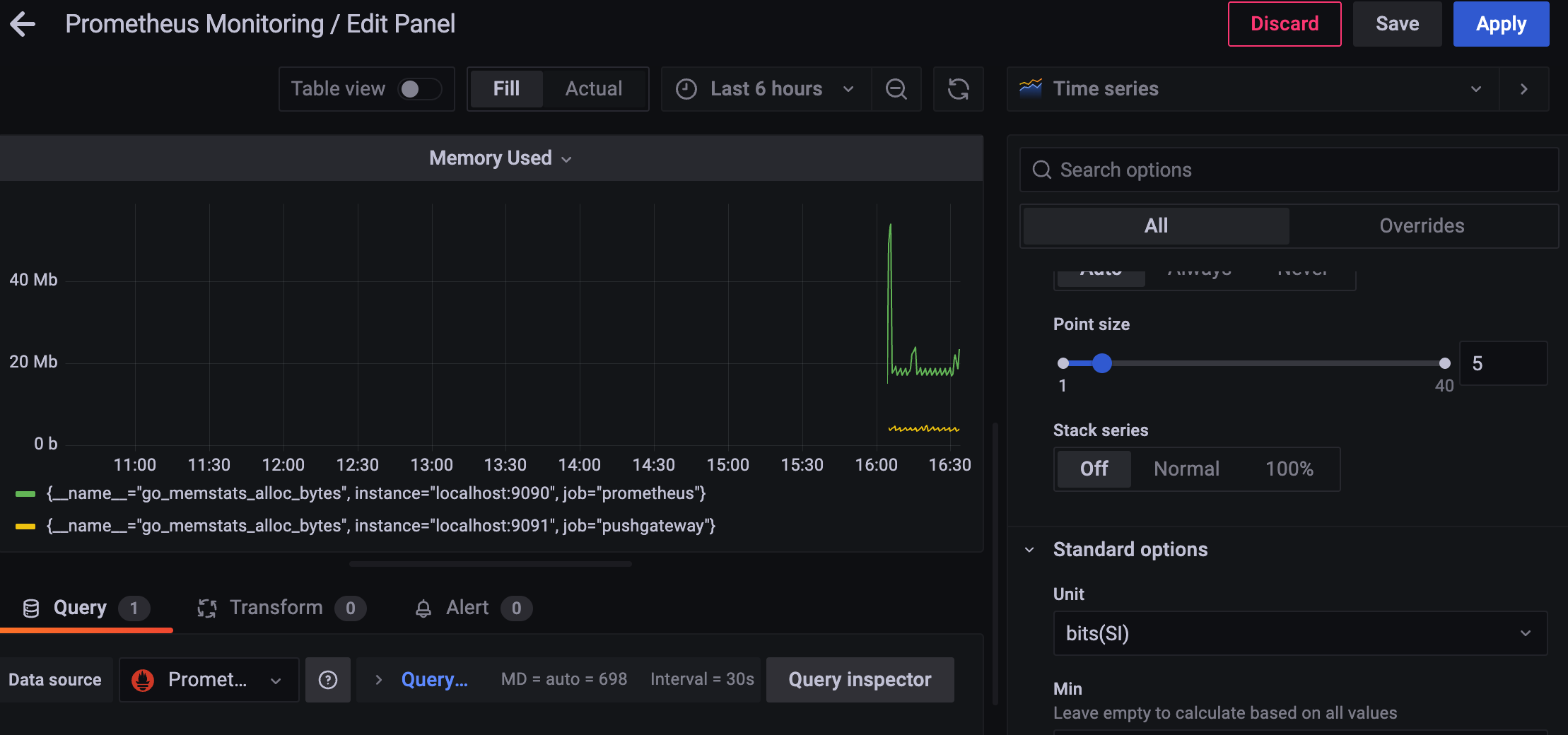
프로메테우스가 20MB 정도, PushGateway가 6MB 정도 쓰고 있다고 나온다.
메모리 사용량도 인스턴스 별로 의미가 있으니
레전드도 변경을 해보자.
만약 인스턴스가 많다면. 인스턴스 하나하나 다 그리는 건 보기에 좋지 않다. 그리고 메모리 사용량이 굳이 높지 않은 건 관심을 안 가져도 되지 않을까?
이런 걸 할 때 쿼리를 추가해주면 된다.
- 간단한 쿼리 사용법
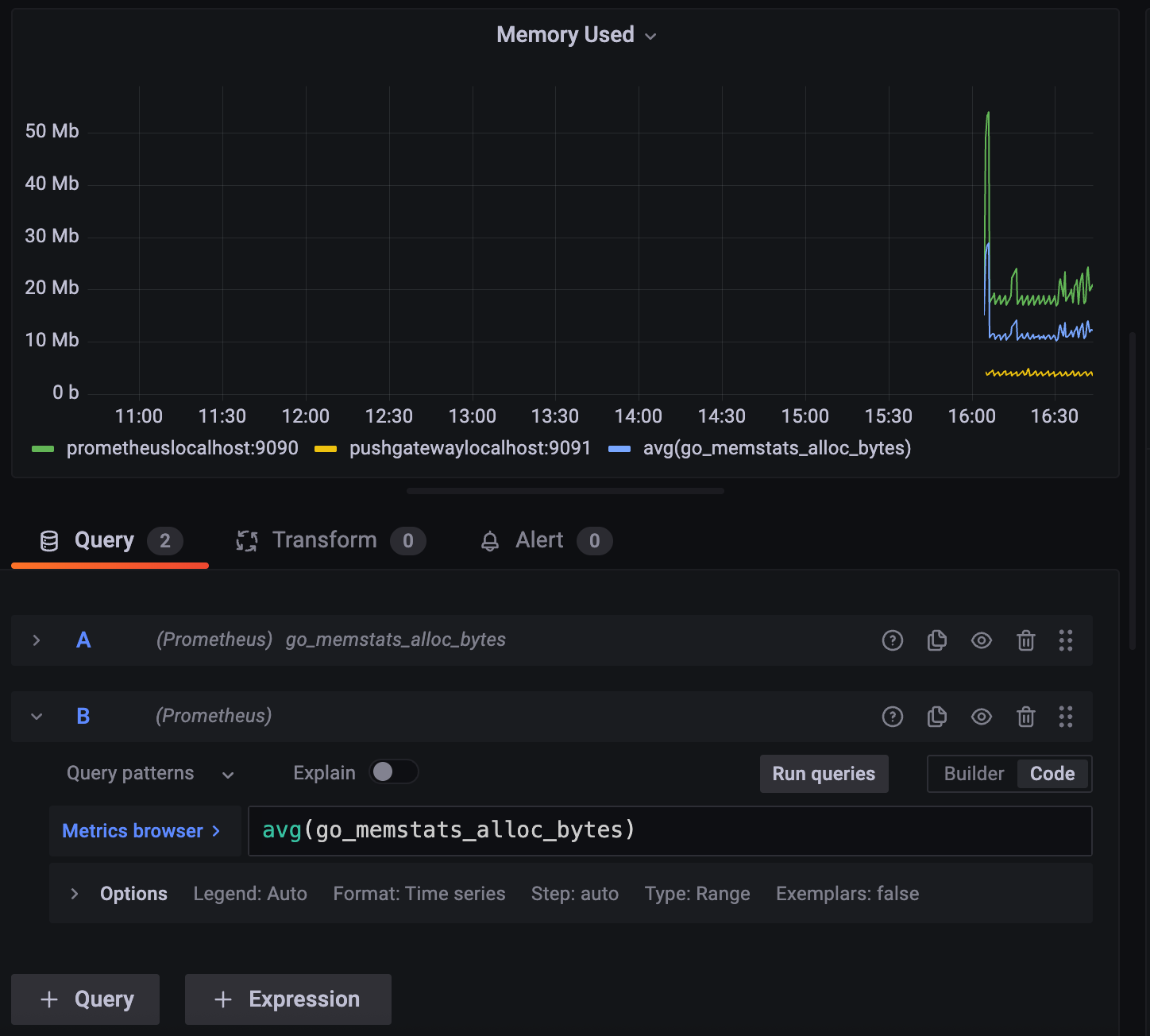
prometheuslocalhost:9090 와
pushgatewaylocalhost:9091 의 평균 값을 보 여주는 avg()
Title 옆에 단위 까지 적어주고
저장하면 완료
이제 단순한 사용량은 알겠는데
이게 위험한 건지? 를 보려면 %로 보면 좋다.
시스템이 제공하는 거에 비해서 얼마만큼 쓰고 있냐.
go_memstats_sys_bytes : system이 제공하는 byte. 운영체제한테 내가 쓰겠다고 할당 받음
go_memstats_alloc_bytes : 그 중에 내가 지금 쓰는 byte
두 개를 나눠주면 됨.
go_memstats_alloc_bytes/go_memstats_sys_bytes
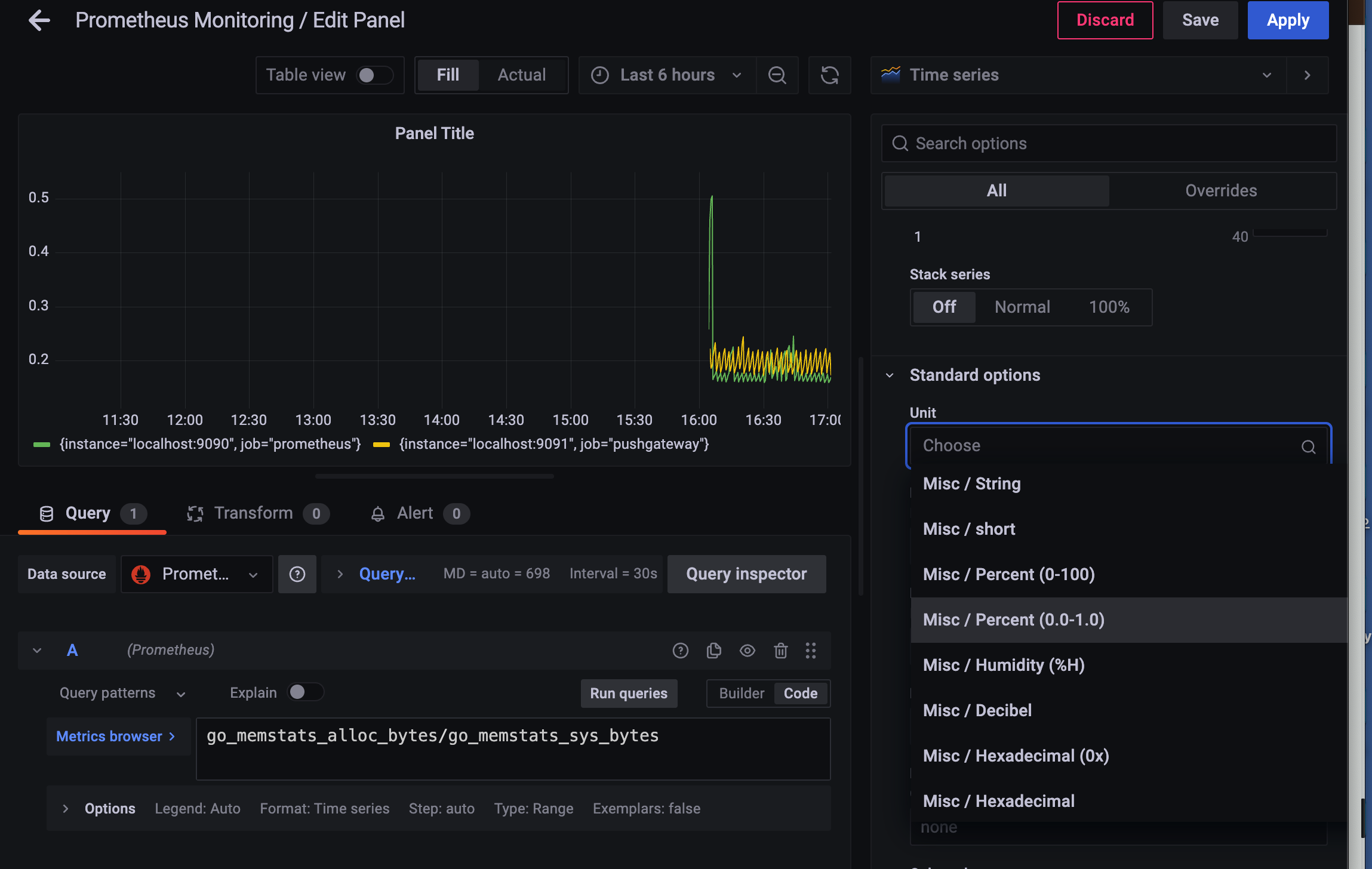
misc > Percent (0.0~1.0) 선택.
이름 수정
레전드 수정
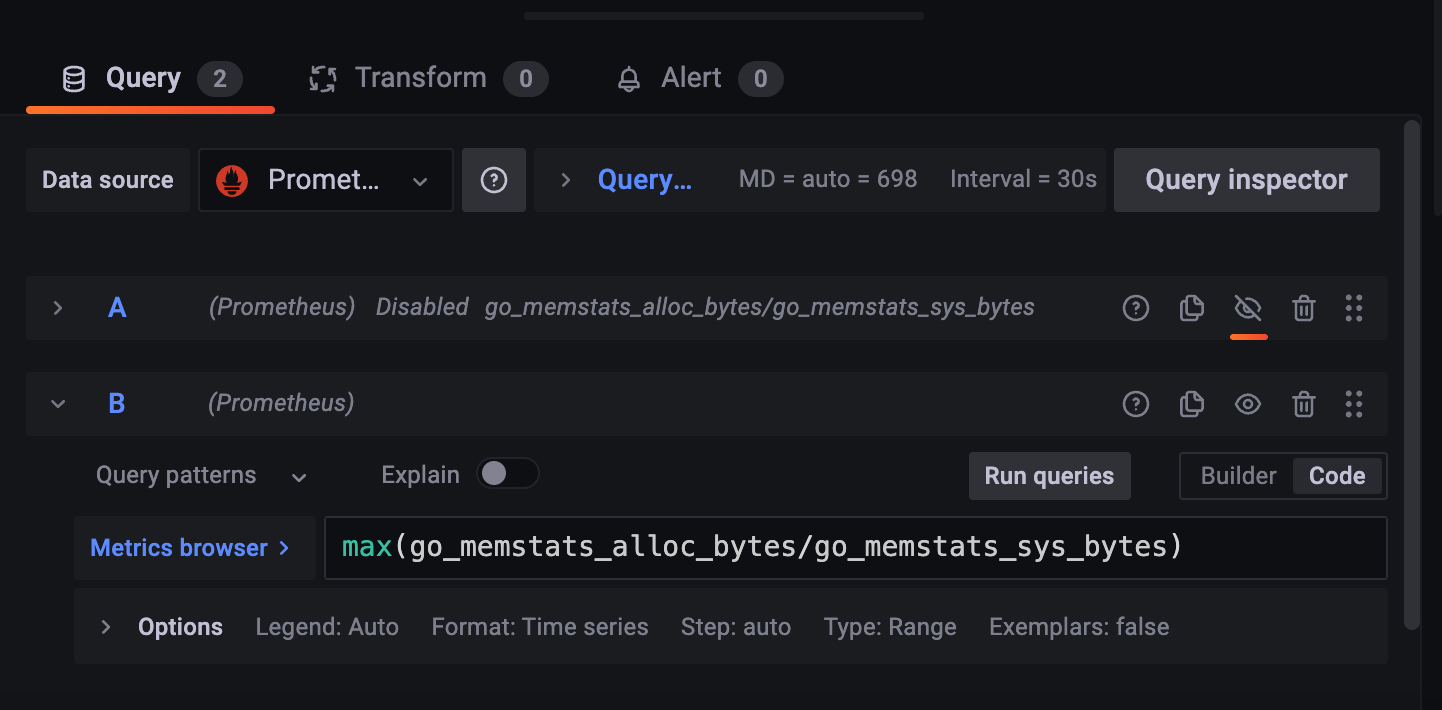
이런 식으로 필요한 것만 보여주고, 필요 없는 것은 보이지 않게 처리할 수도 있다.
이번에는 GC time을 해보자

GC duration이라고 summary 타입으로 되어 있고 퀀터타일 별로 되어 있는데 우선 총 합만 가져와서 그려보자.
go_gc_duration_seconds_sum 을 입력하면 아래 처럼 나온다.
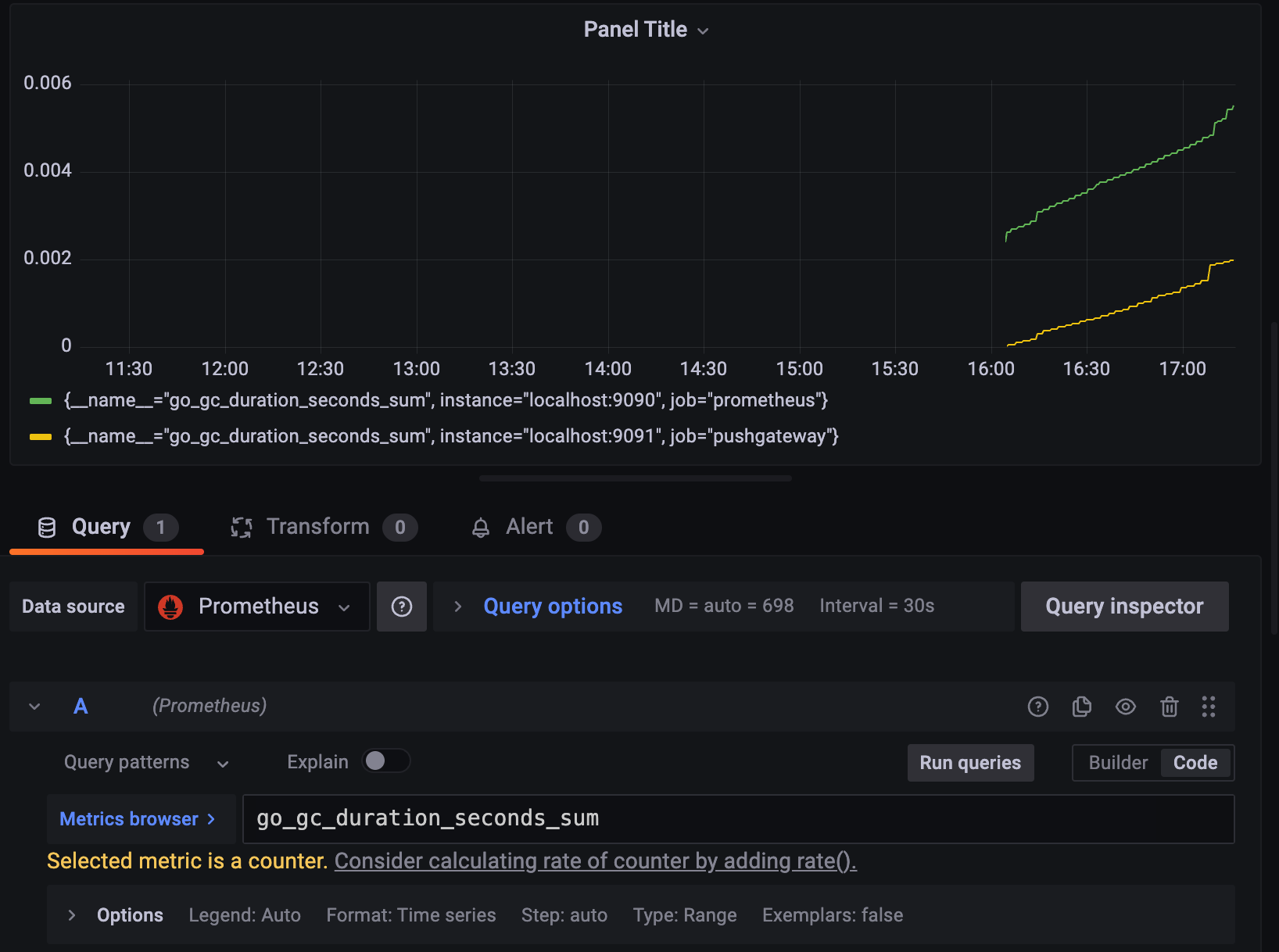
계속 증가하는 양상을 보이는데, 지금까지 걸린 GC duration 이니까. 근데 얘는 counter 다.
그래서 아래에 보면 해당 매트릭의 타입별로 적절한 함수를 쓰라고 추천을 해준다.
counter는 rate() 를 쓰라고 메세지가 나온다.
애초부터 이렇게 볼 일이 없음 ㅋㅋ
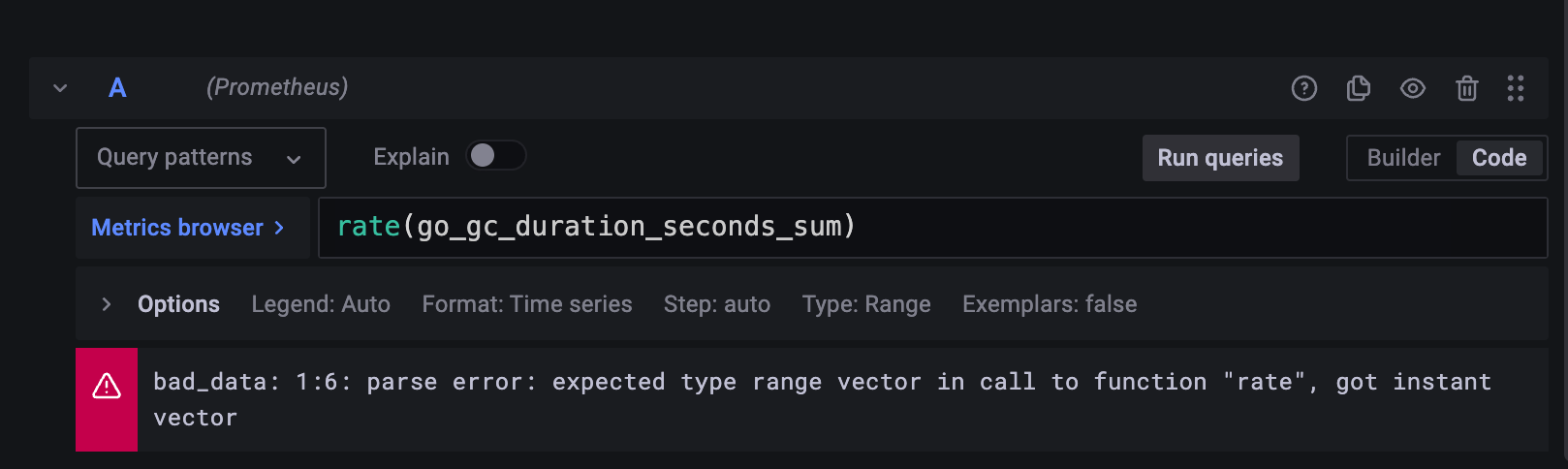
rate()로 묶어줘도 오류 메세지가 나온다.
rate 는 range vector 에 쓸 수 있는데?
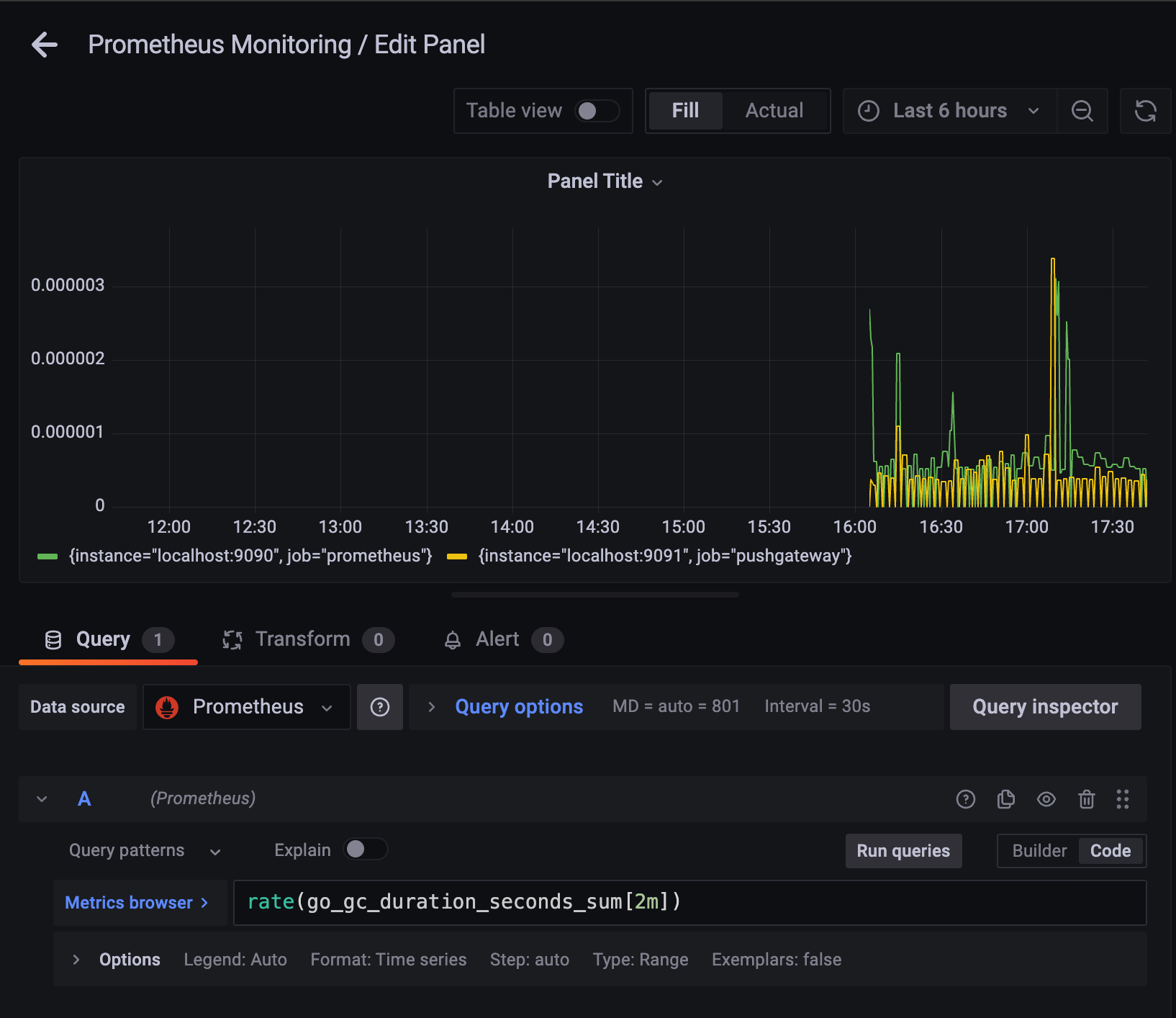
sum 옆에 [2m] 를 붙여 적어주면 해결된다.
지금 실습 세팅에서는 polling이 15초로 되어 있지만 대용량 시스템 같은 경우엔 15초로하는 경우는 별로 없다.
30초 ~ 아니면 부하가 심하고 매트릭 시스템에 대해 잘 준비가 안 돼 있다, 아니면 그런 부분에 계산이 필요하다 이런 경우 1분 까지 설정 하기도 한다.
보통 Range()가 있는 경우 2분을 많이 설정 함.
1분으로 하면 1 분마다 한 번 설정한 걸 rate 같은 비율을 계산한다.? 오차가 많이 날 수 있다. 그래서 최소 2분 이상을 설정해주자.
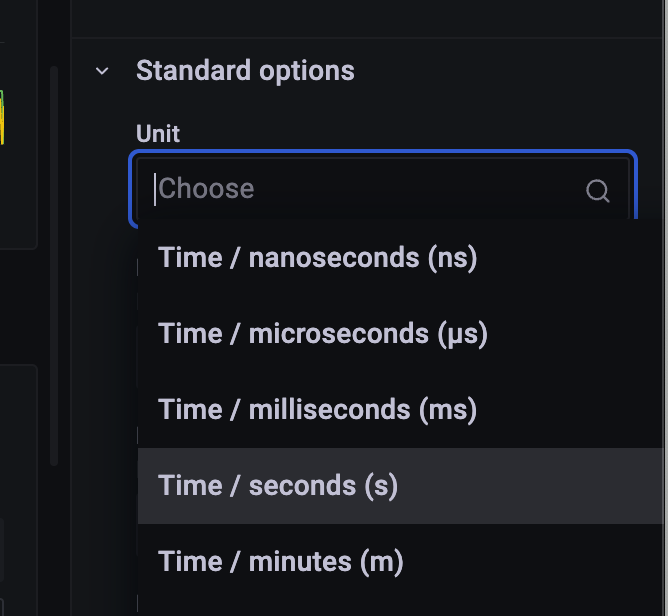
단위도 바꿔주고.
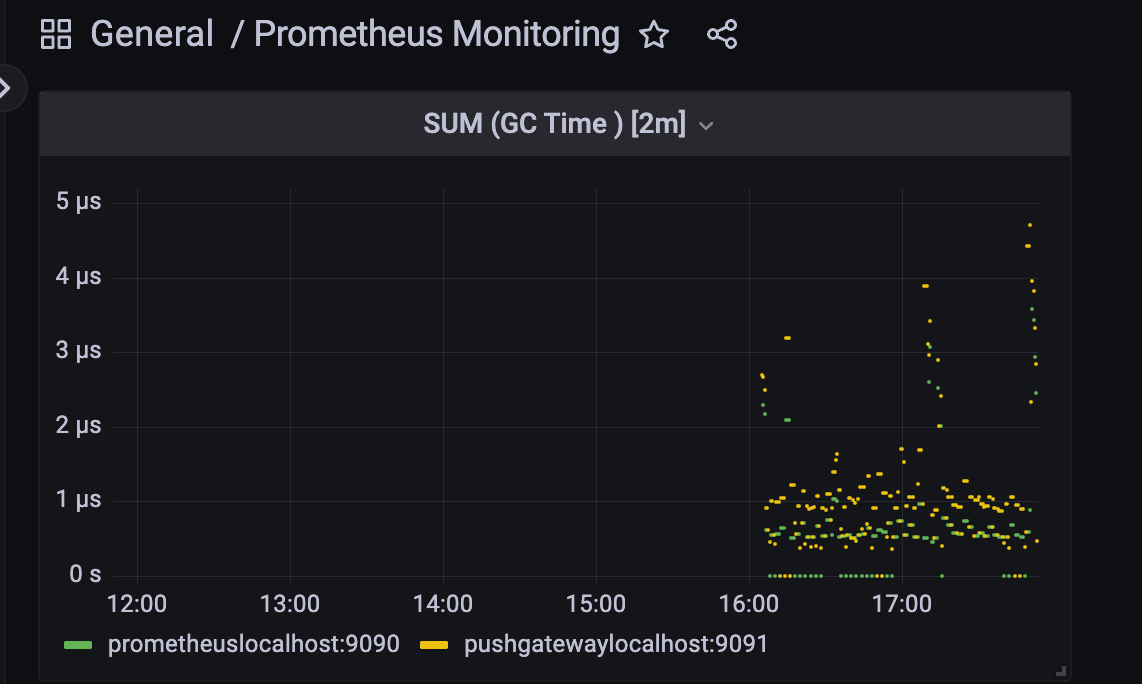
이렇게 해서 2분동안 이 seconds가 증가한 비율을 계산해주는 함수다.
Alerting 설정하기
우선은 알러팅을 받기 전에 알러팅을 받을 contanct point를 설정해 줘야 함.
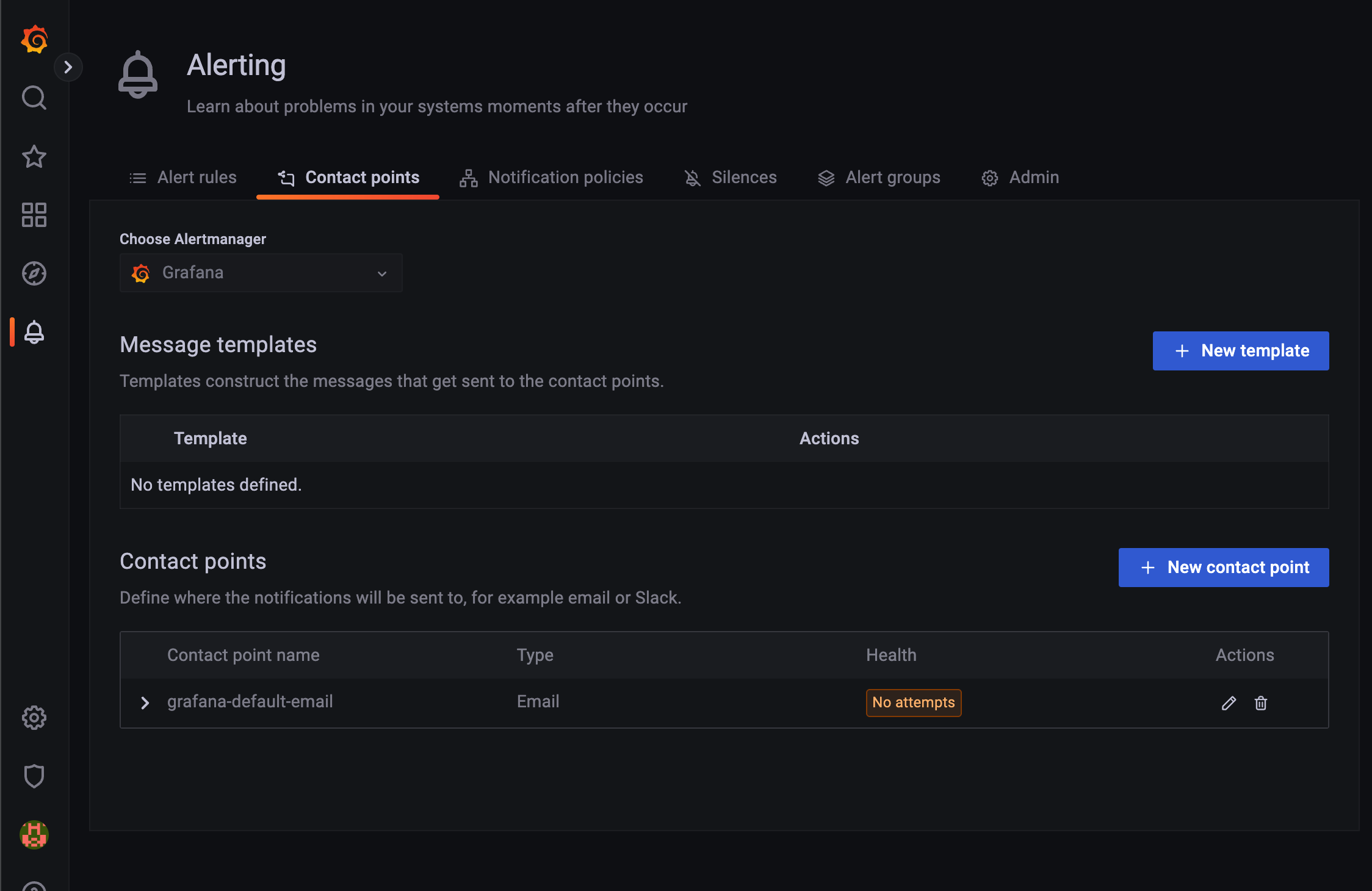
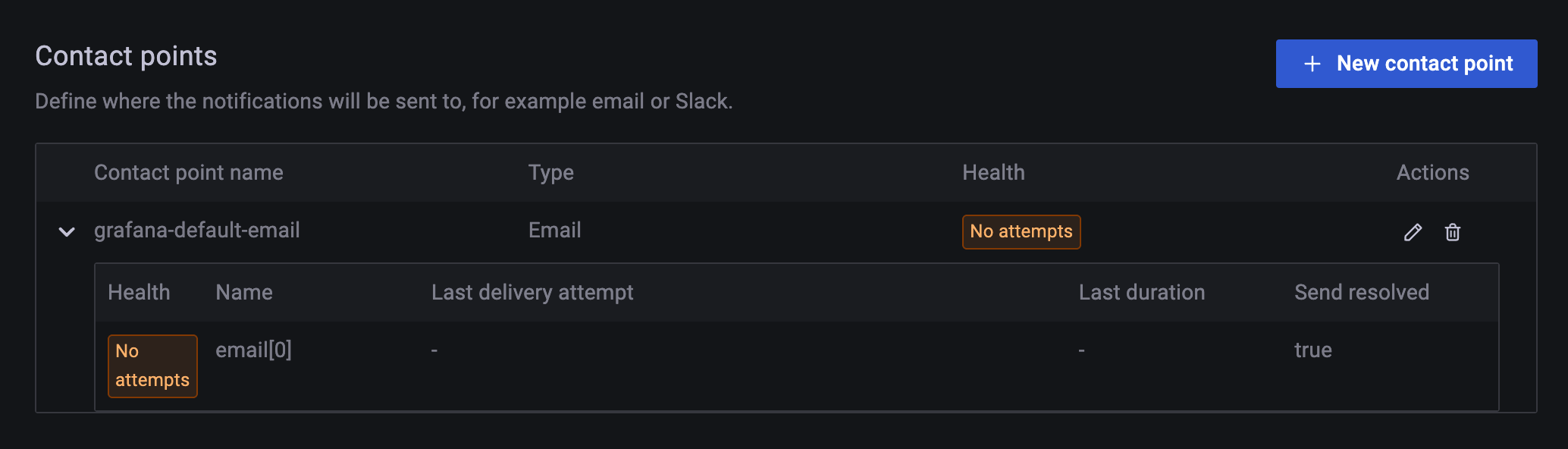
여기 보면 default email이라고 이렇게 돼있는데 연필모양 edit contanct point 버튼 눌러서 수정 페이지로 이동.
SMTP 구성한 사람들은
Address 에 메일을 보낼 주소를 쓰면 그 메일 주소로 notification message 를 보낼 수 있다
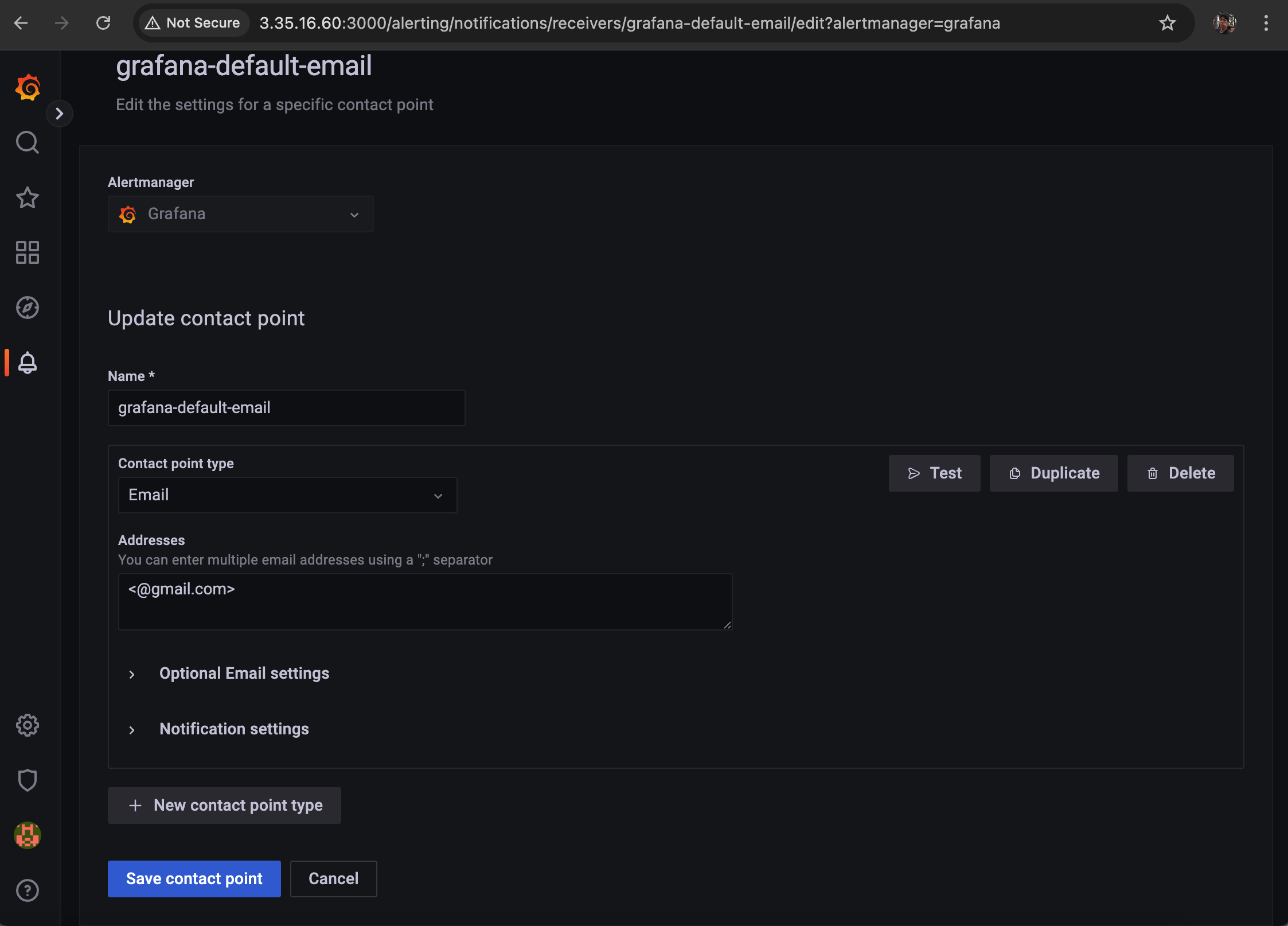
메일 주소 입력 완료 하고
Test 버튼 클릭
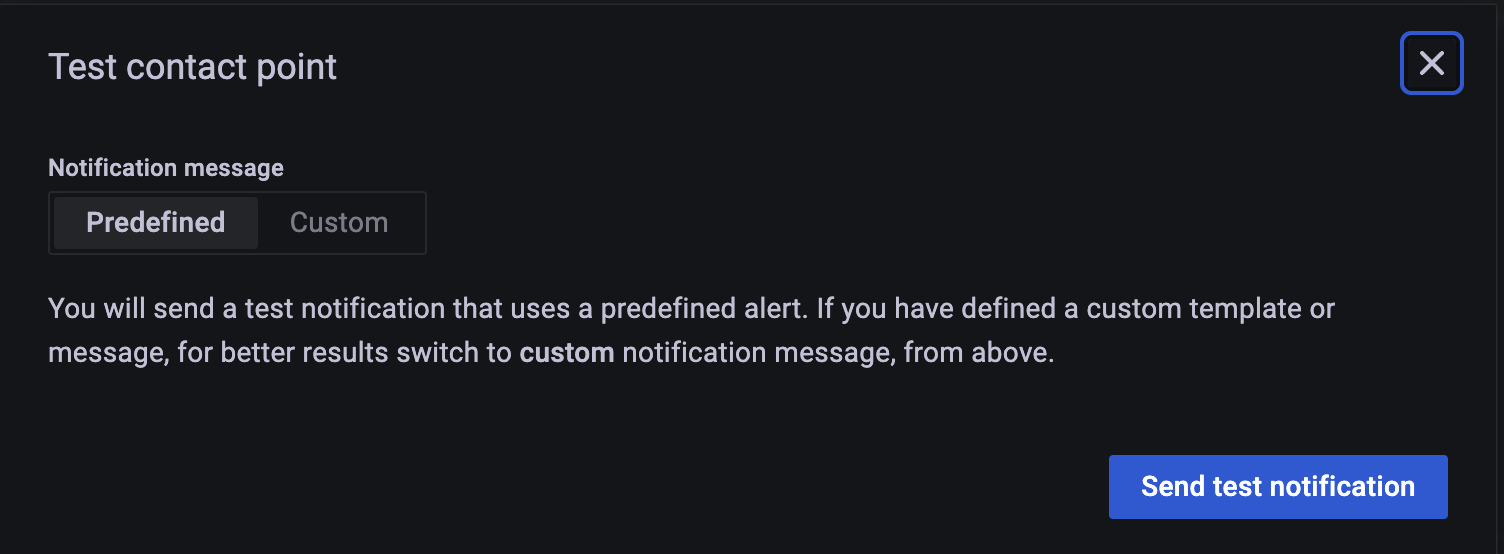
미리 설정된 테스트 notification 할 수도 있고
custom 해서 내용을 보낼 수도 있다.
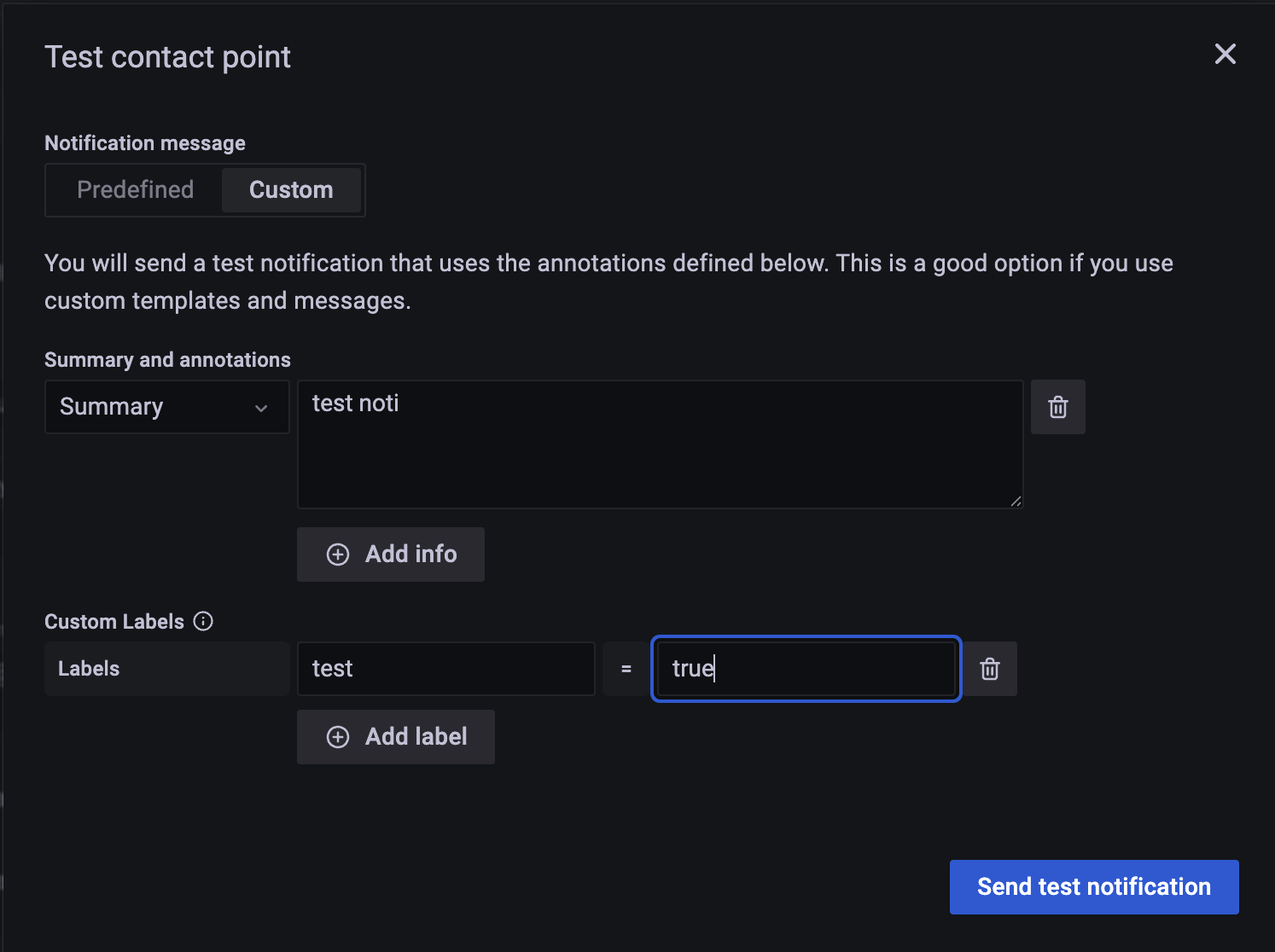
test noti,
test = true 레이블을 넣어서 테스트 해보자
이런 메세지 뜨고 메일 확인해보면
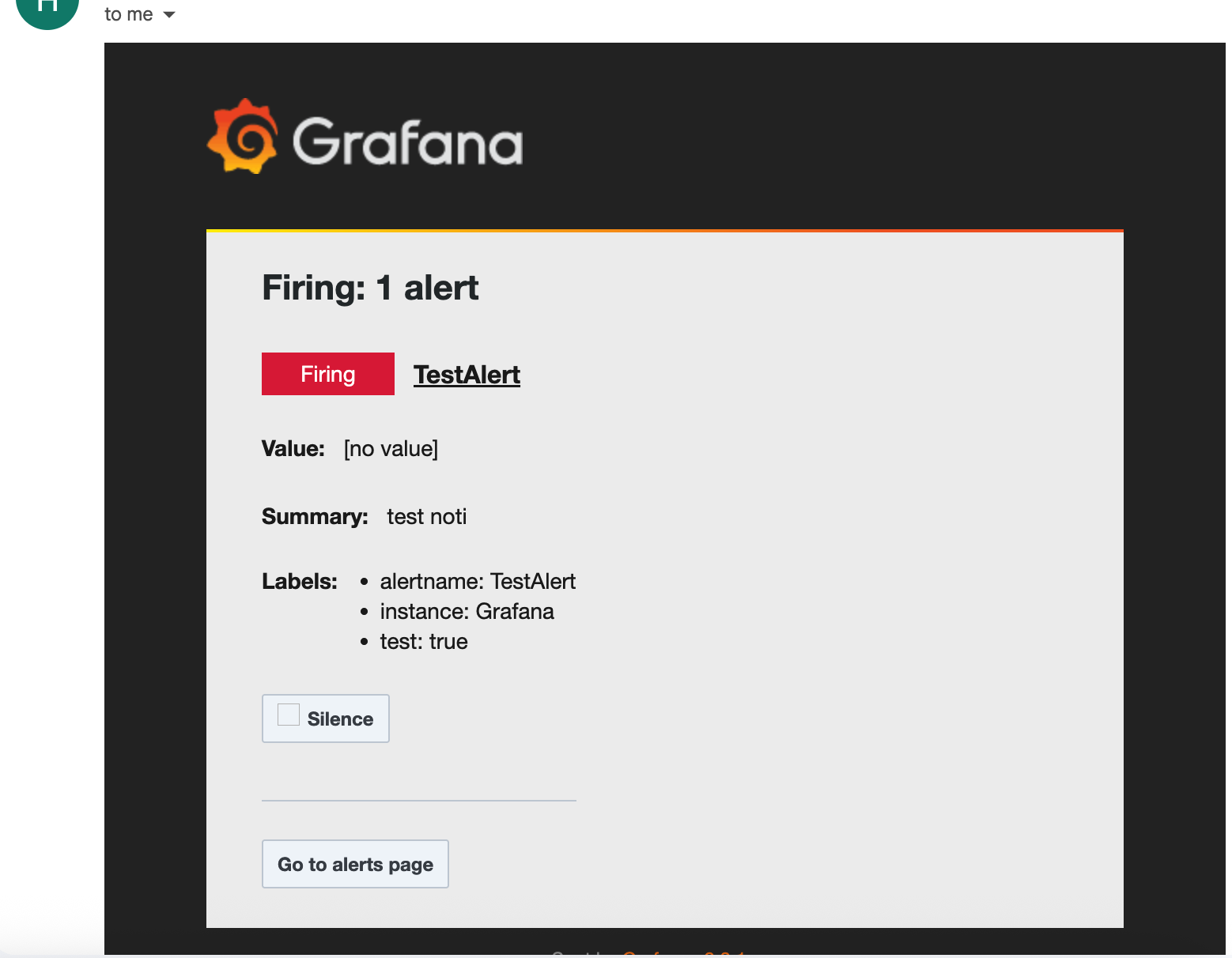
이렇게 메일이 와 있을 것.
go to alerts page 은 페이지가 열리지 않을 텐데,
http://localhost:3000/alerting/list?alertState=firing&view=state
로컬호스트에서 주소를 바꿔주면 잘 될 것.
Save Contanct Point 클릭
이렇게 설정한 뒤 앞으로 notification에 사용할 것이다.
우선 그 전에
alerting > notification policies 로 들어가서
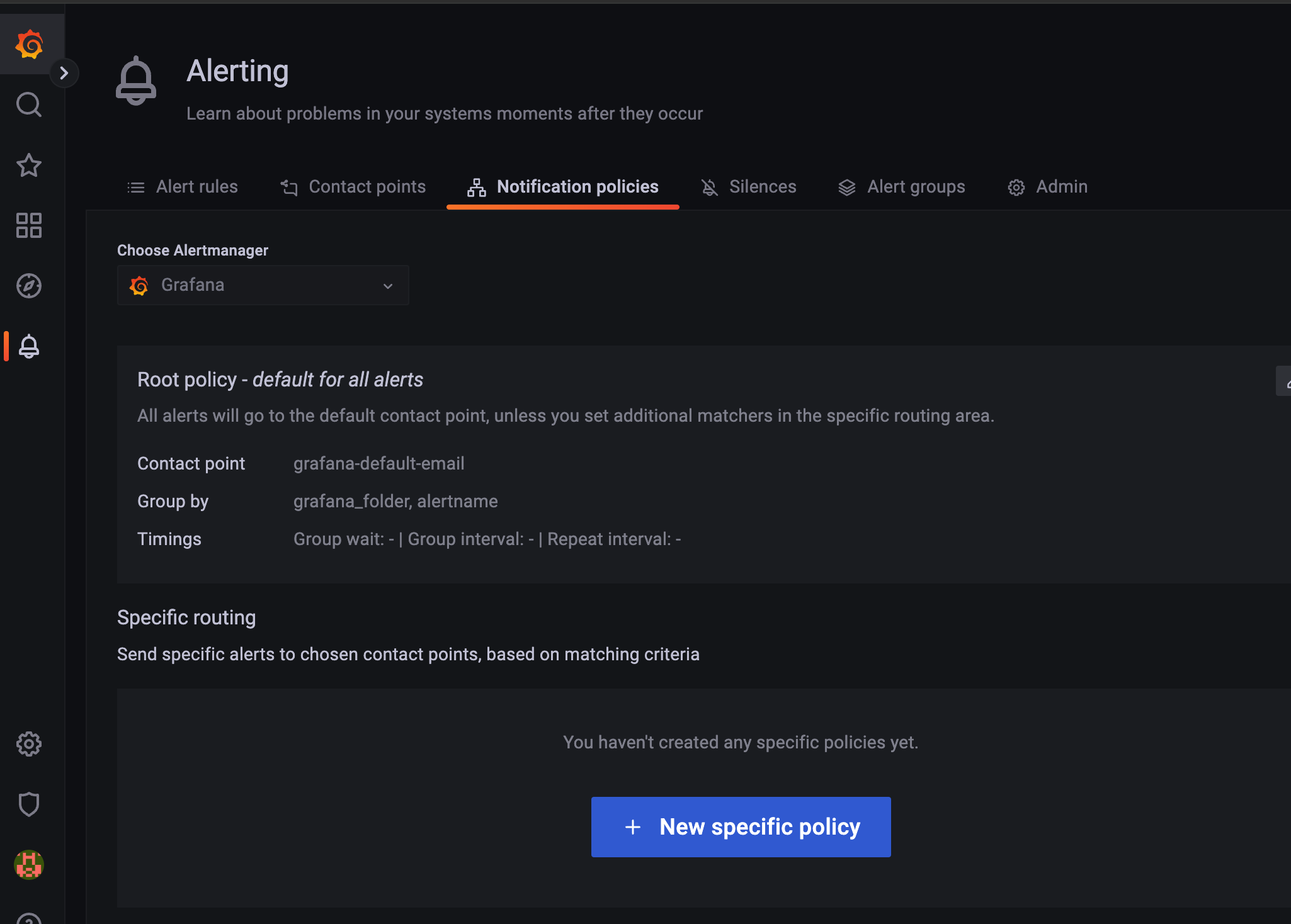
New specific policy 클릭.
add matcher 클릭
어떤 라벨이 들어오면 누구한테 노티를 보내겠다 이런 방식.
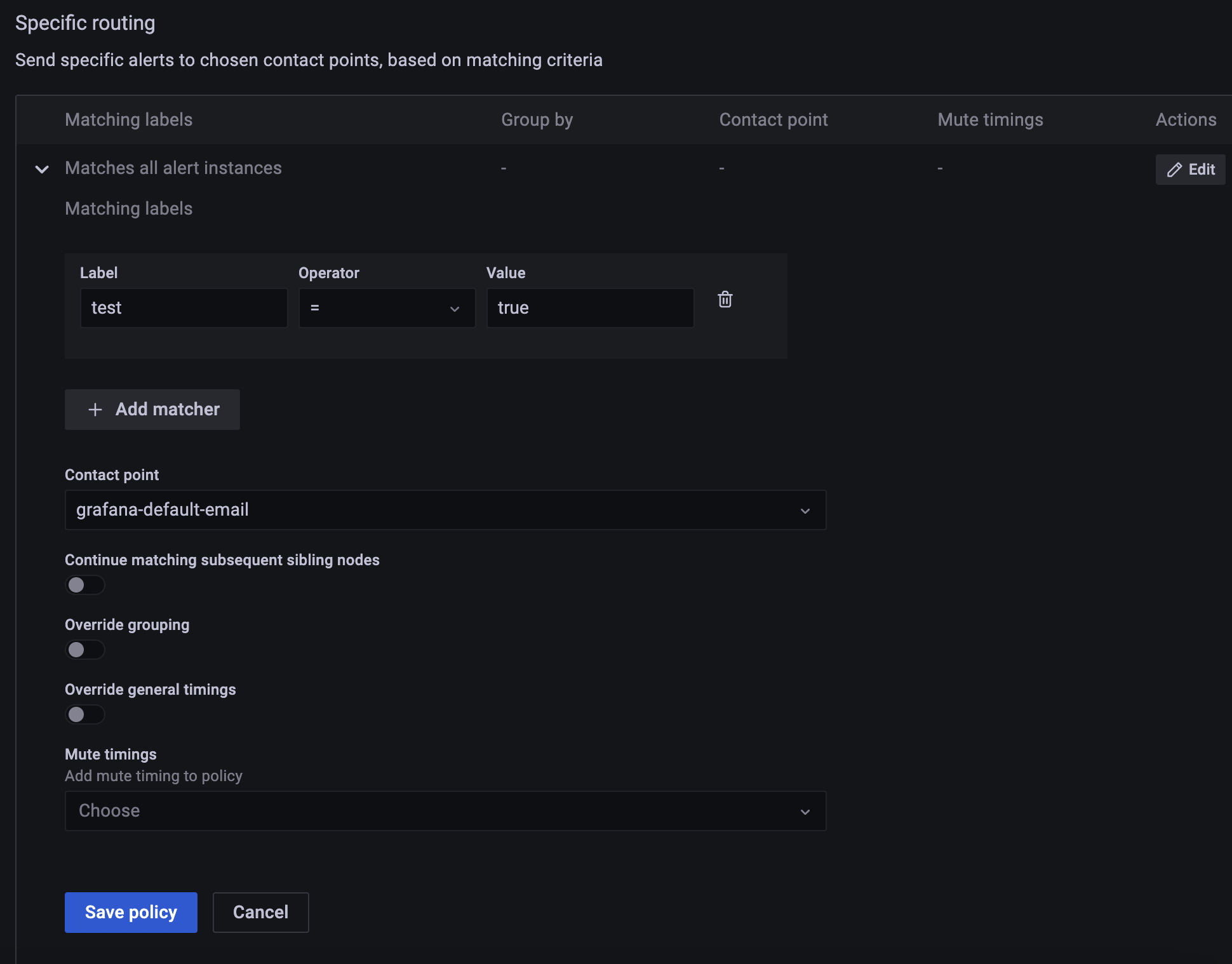
test라는 값이 true가 들어오면 하겠다.
contact point는 아까 설정한 이메일로 하겠다.
mute는 안 하고
Save Policy 클릭

이렇게 policy 가 만들어진 다음 alert를 걸면 된다.
Dashboards 로 들어가서
General 폴더에 아까 만든 모니터링 대시보드로 이동
Memory used % 에서 alert를 보내려고 하는데
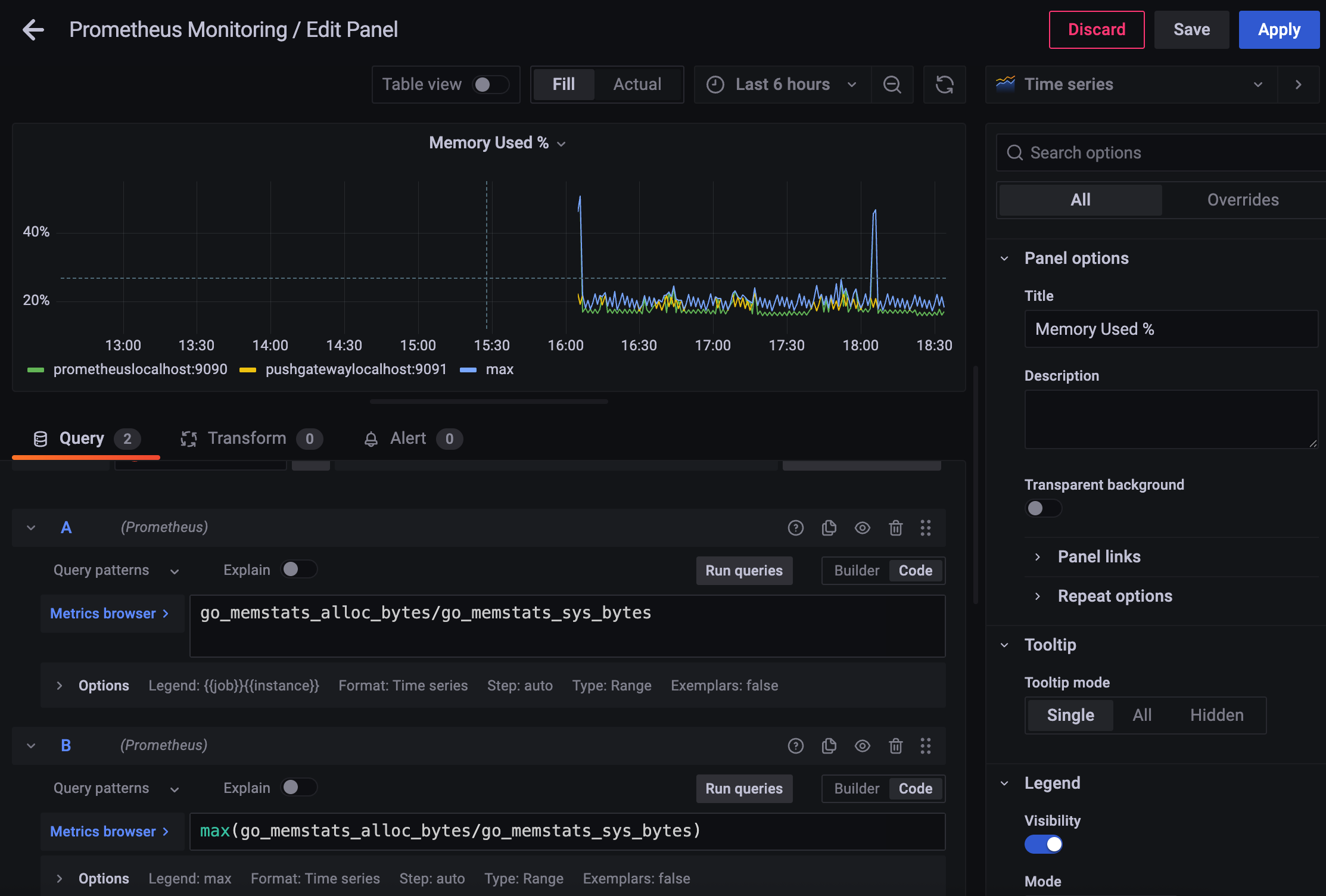
숨김 기능이 켜져 있으면 버그가 좀 있는 것 같으니
Query A, Query B 둘 다 보이게 설정해주고 apply, save 해주고
다시 들어가서 alert 설정을 해준다..
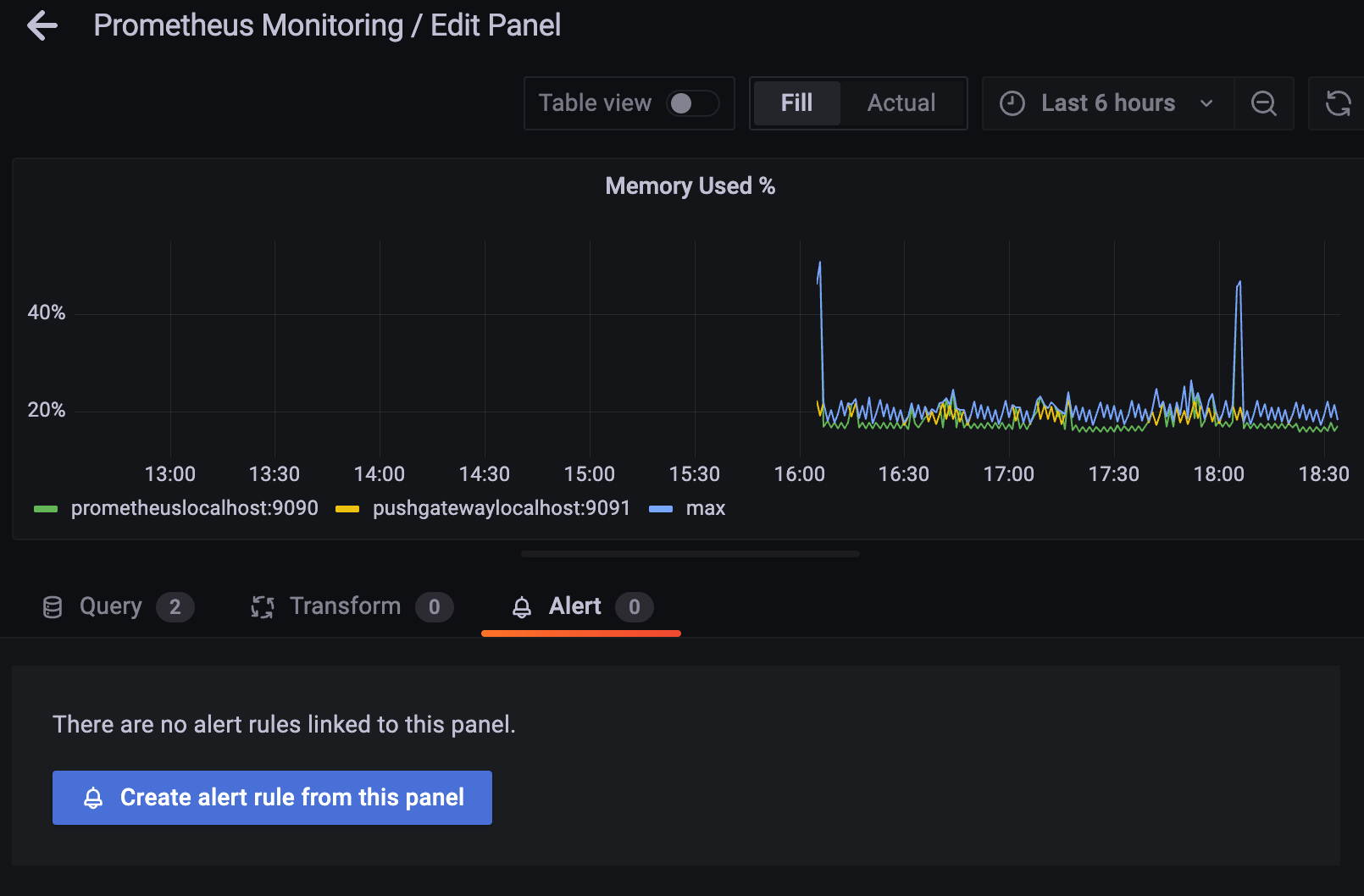
create alert rule from this panel 클릭
30 분으로 설정하고
preview 버튼 클릭하면
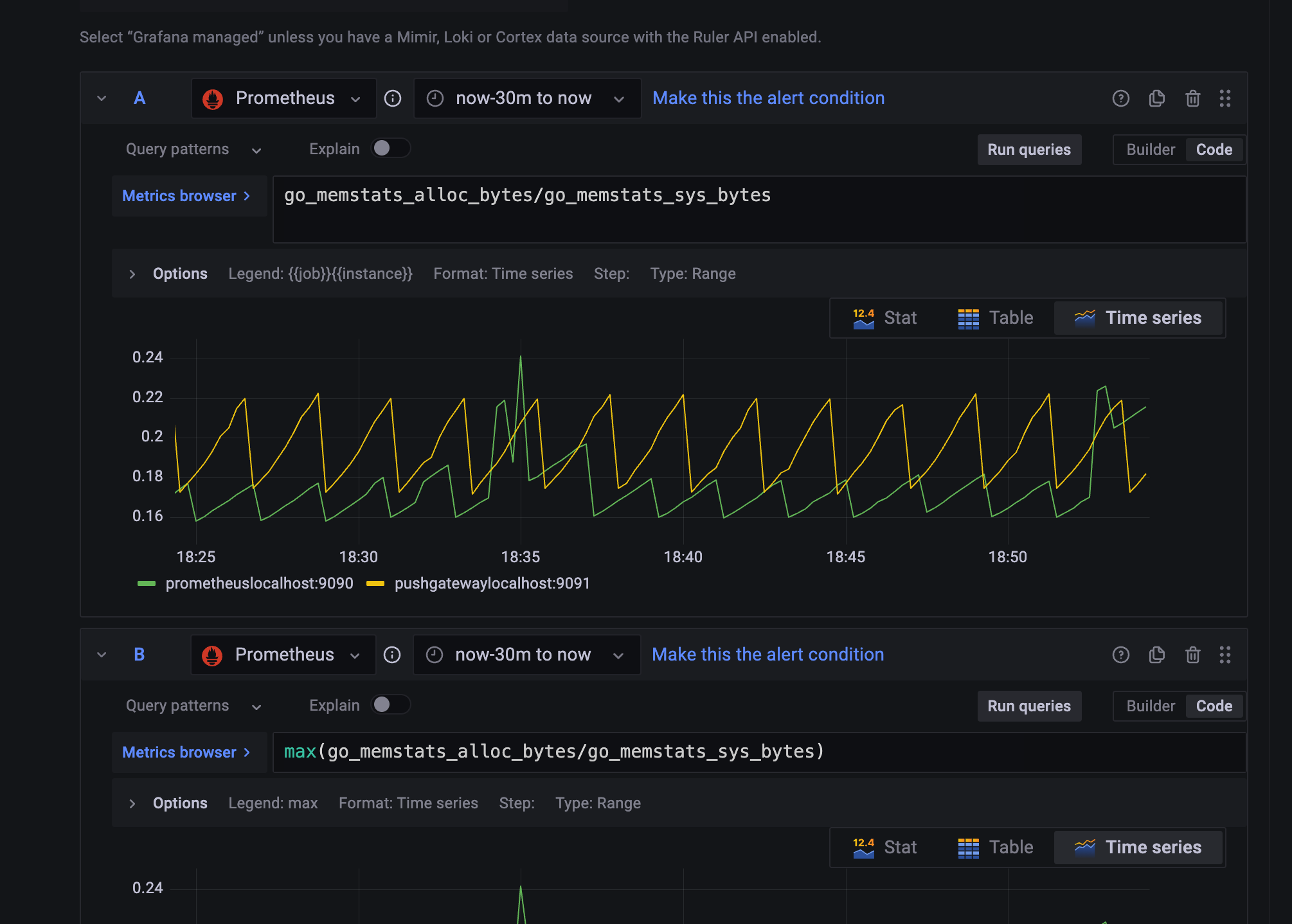
이런 모습으로 그래프 모습이 보이게 된다.
Query C 설정
아래로 내려와서 query c를 설정하자.
input B의 Last 값,
Drop Non-numeric values 로 설정을 해주자.
이래야 값이 없을 때나 이상한 값에 대한 이상한 알람을 줄일 수 있음.
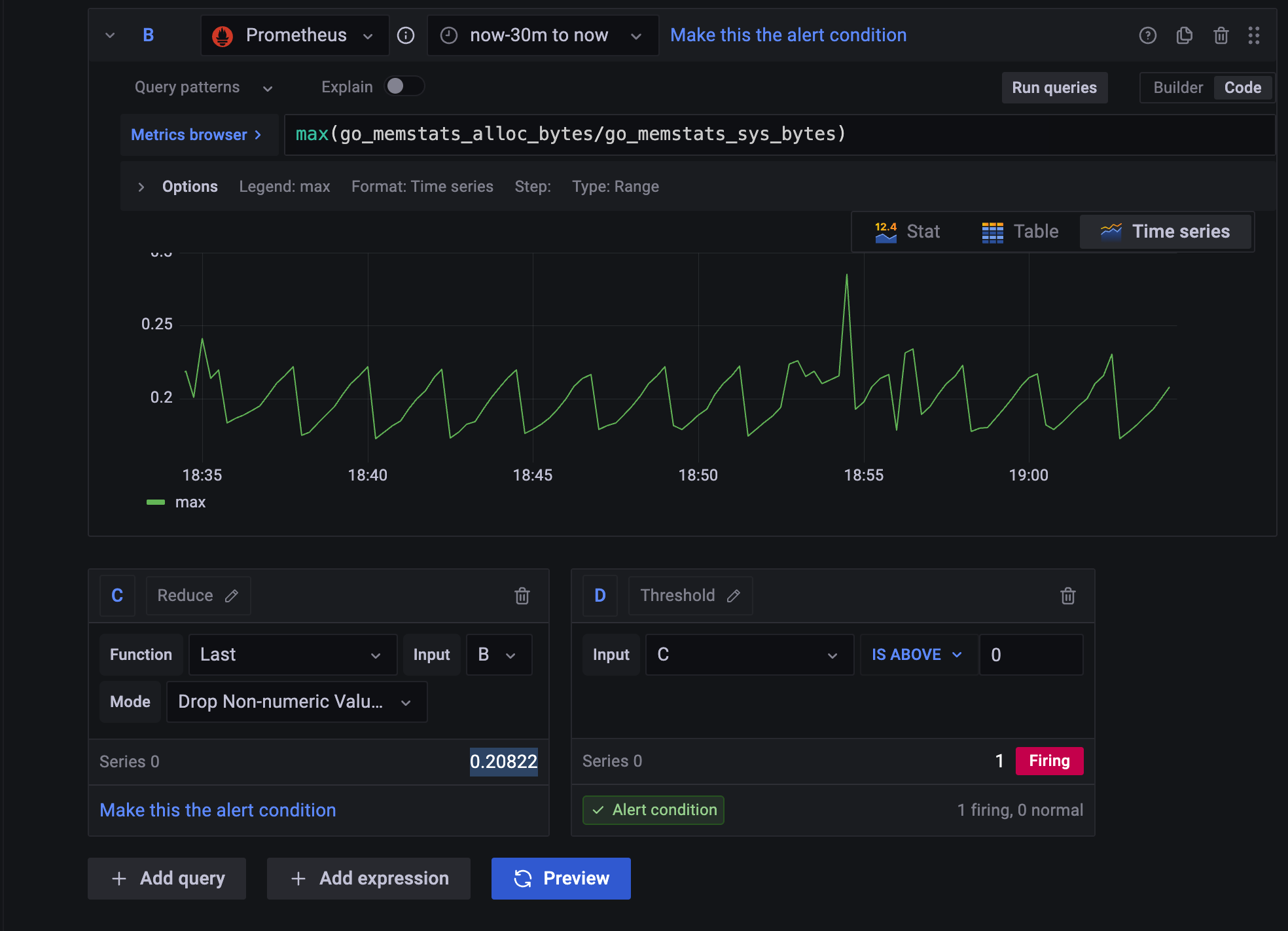
query D
query D는
query C의 값, query B의 last 값을 non-numeric value로 drop한 그 값이
0보다 크면 알람을 주는 조건이니까
지금 0.20822로 firing되는 조건이다 라고 되어 있다.
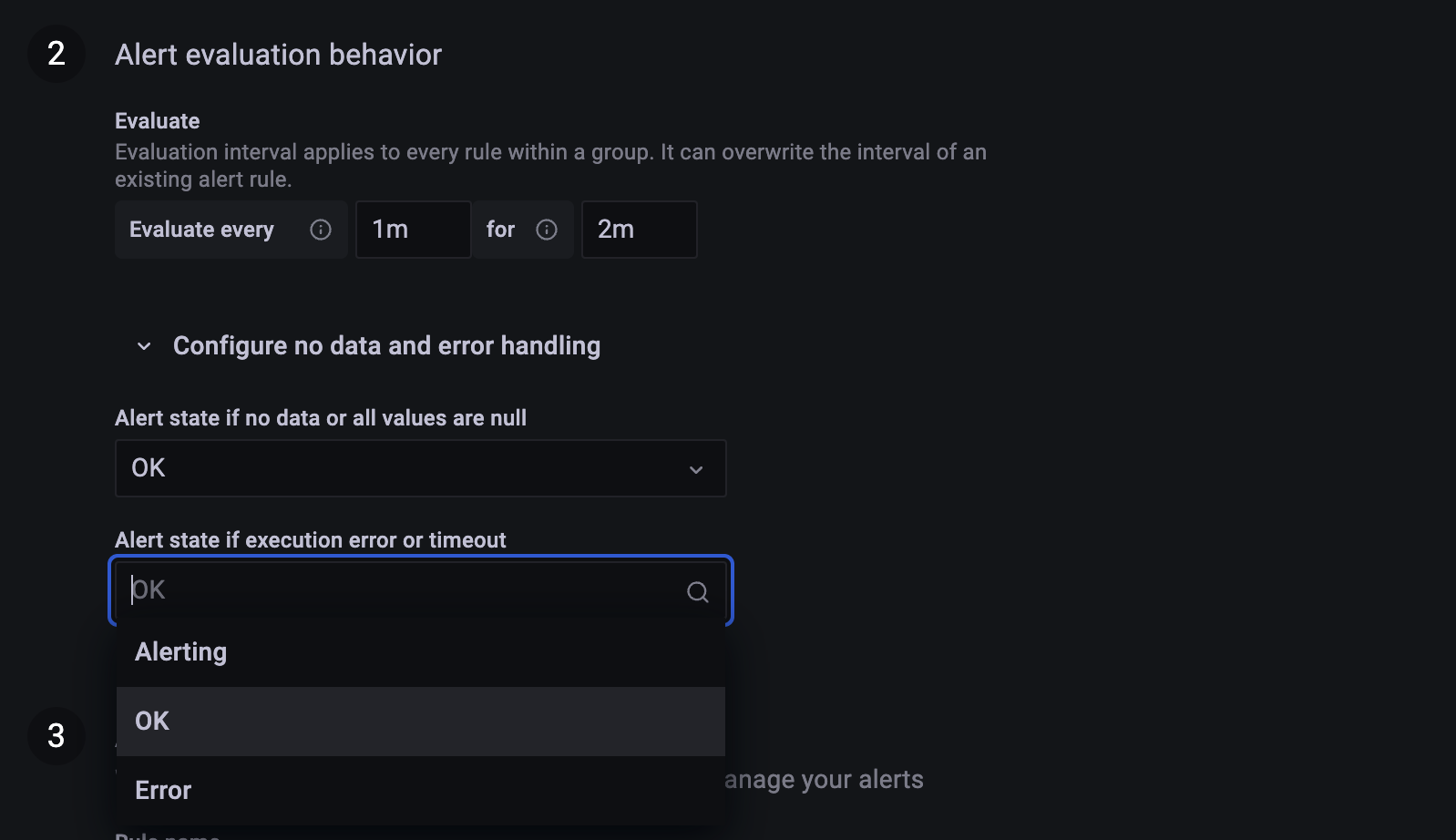
Evaluate every 1m for 2m 으로 설정.
위에 그래프에서 나온 30분은 preview 하기 위해서 설정한 값이고
evaluate 하는 기간은 여기서 설정한다.
1분마다 조건을 확인하는데
기간 2분에 대해서 조건을 확인한다.는 뜻이고
위에 Query C 에서 설정한
Last 의 B, B값의 마지막 값을 확인한다는 뜻.
last가 아닌 sum(), max(), min() 등으로 하면
기간에 영향을 더 많이 받음.
보통은 evaluate을 짧게, 그리고 기간을 좀 길게 둔다.
보통 매트릭 수집하는 게 30초나 1분 정도 걸린다고 했었는데
기간은 최소한 2분 이상은 돼야 한다.
evaluate도 자주 하면 할수록 grafana 서버에 부담이 되는 거기 때문에 꼭 필요한 게 아니면 1분도 잦은 것일 수도 있다.
알람을 최소화 하기 위해서
데이터가 없을 때, null 일 때, 알람 말고 ok 로 설정,
execution error or timeout 나도 ok 로 설정.
초기에 우리 시스템이 세팅이 불안정할 때, alert 받으면서 시스템을 고도화 할 때 사용하고 ok 로 설정해두면 불필요한 알람을 안 받을 수 있다.
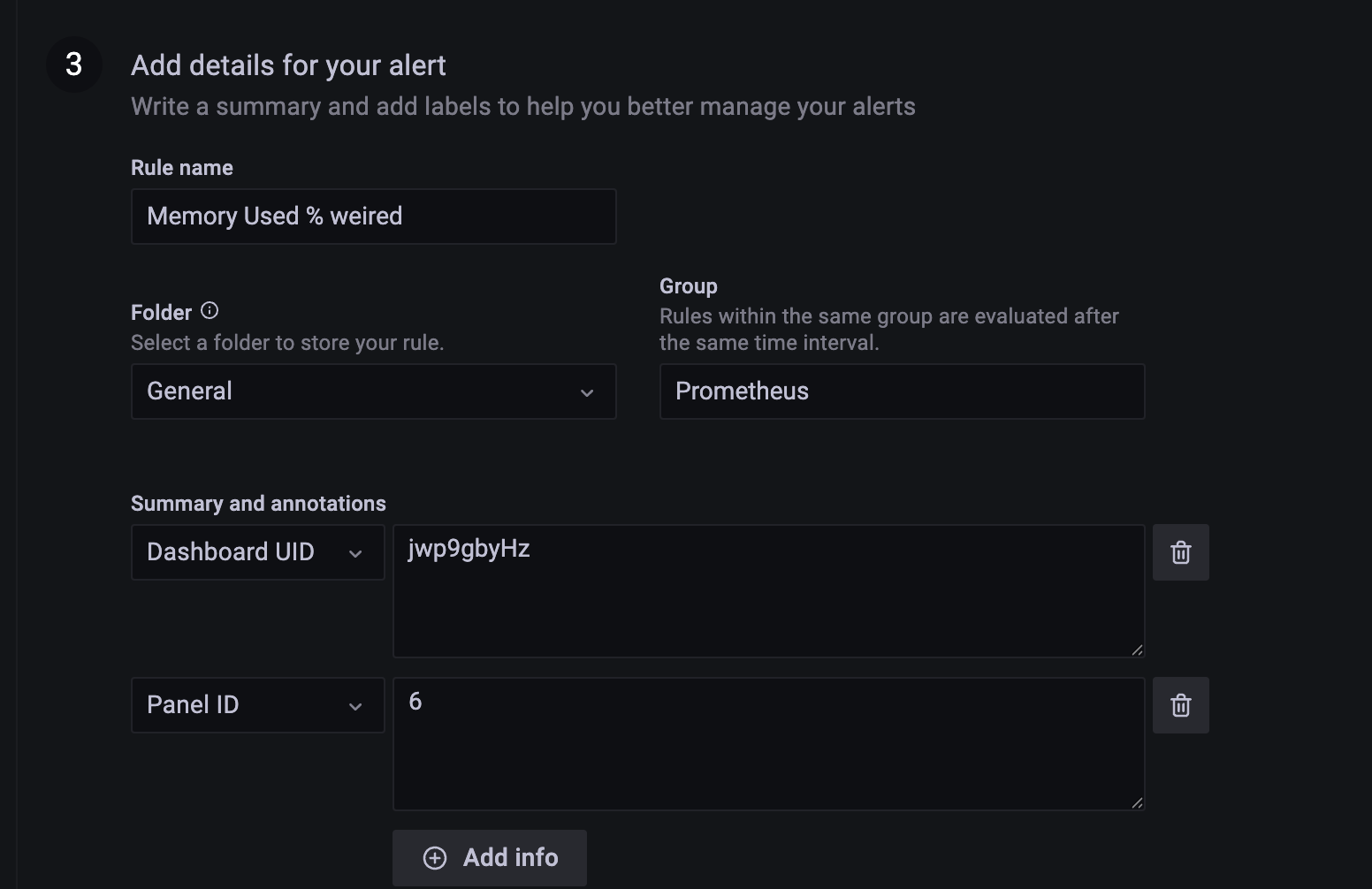
Rule name : 맘대로
폴더 : General,
Group : Prometheus
아래 add info 로 alert에 info 내용 추가할 수 있음
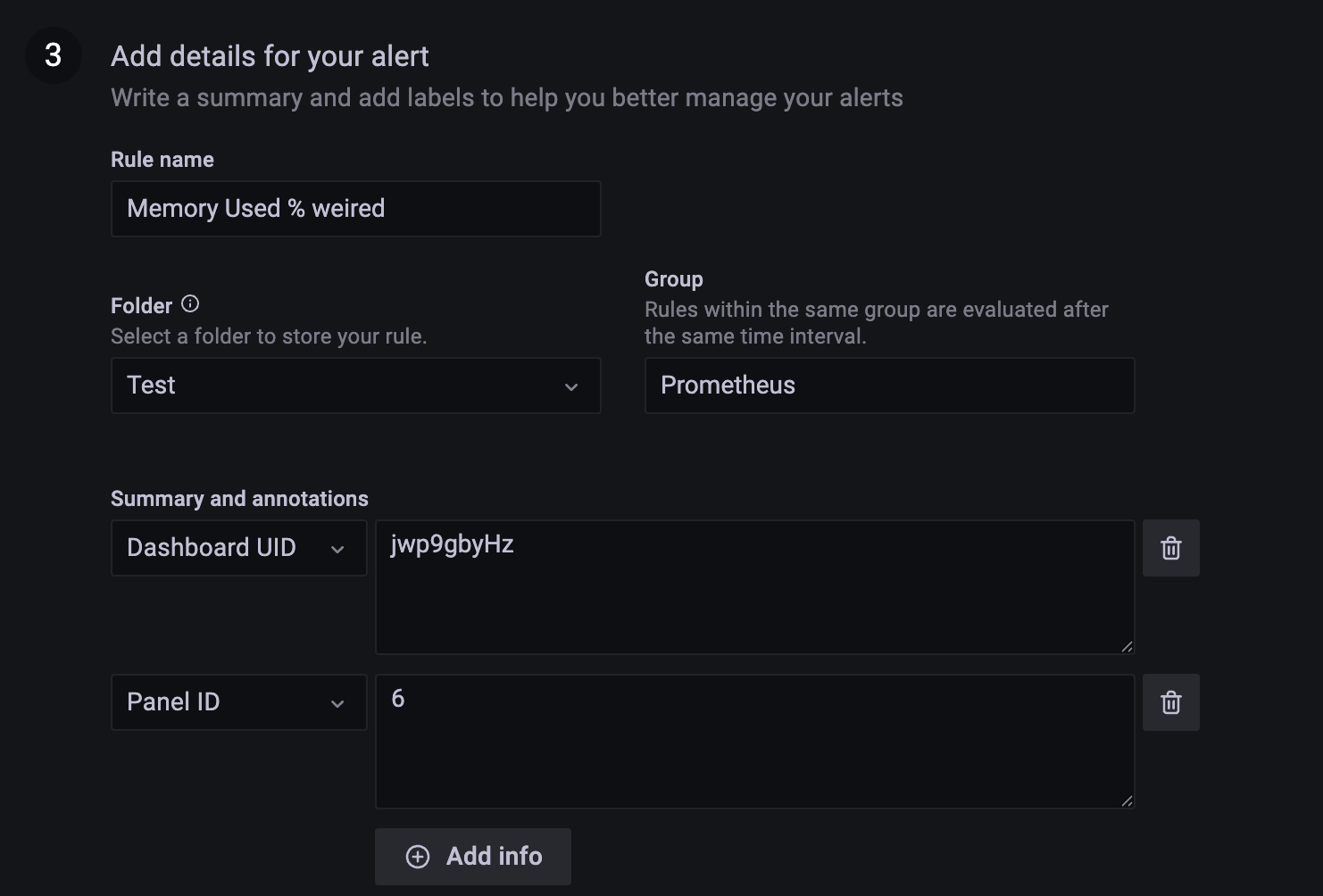
폴더 이름을 General 로 하면 이미 있는 폴더라고 생성이 되지 않는다.
수정해놓자.
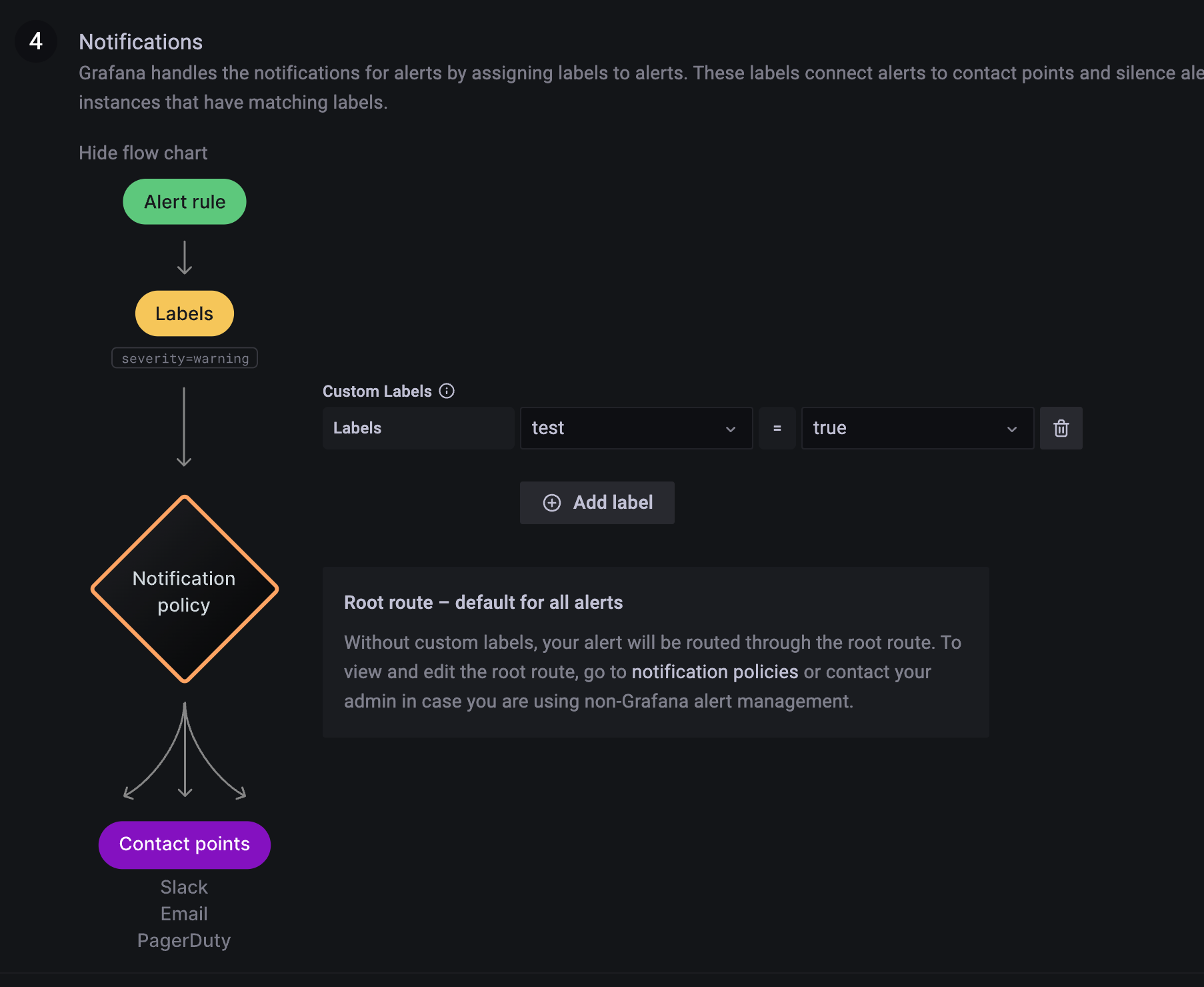
아까 test = true 면 이메일을 보내기로 했고 그렇게 policy 를 만들어놨으니 이렇게 입력을 해주자.
설정이 완료되면 맨 위로 올라가서 Save and exit 클릭.
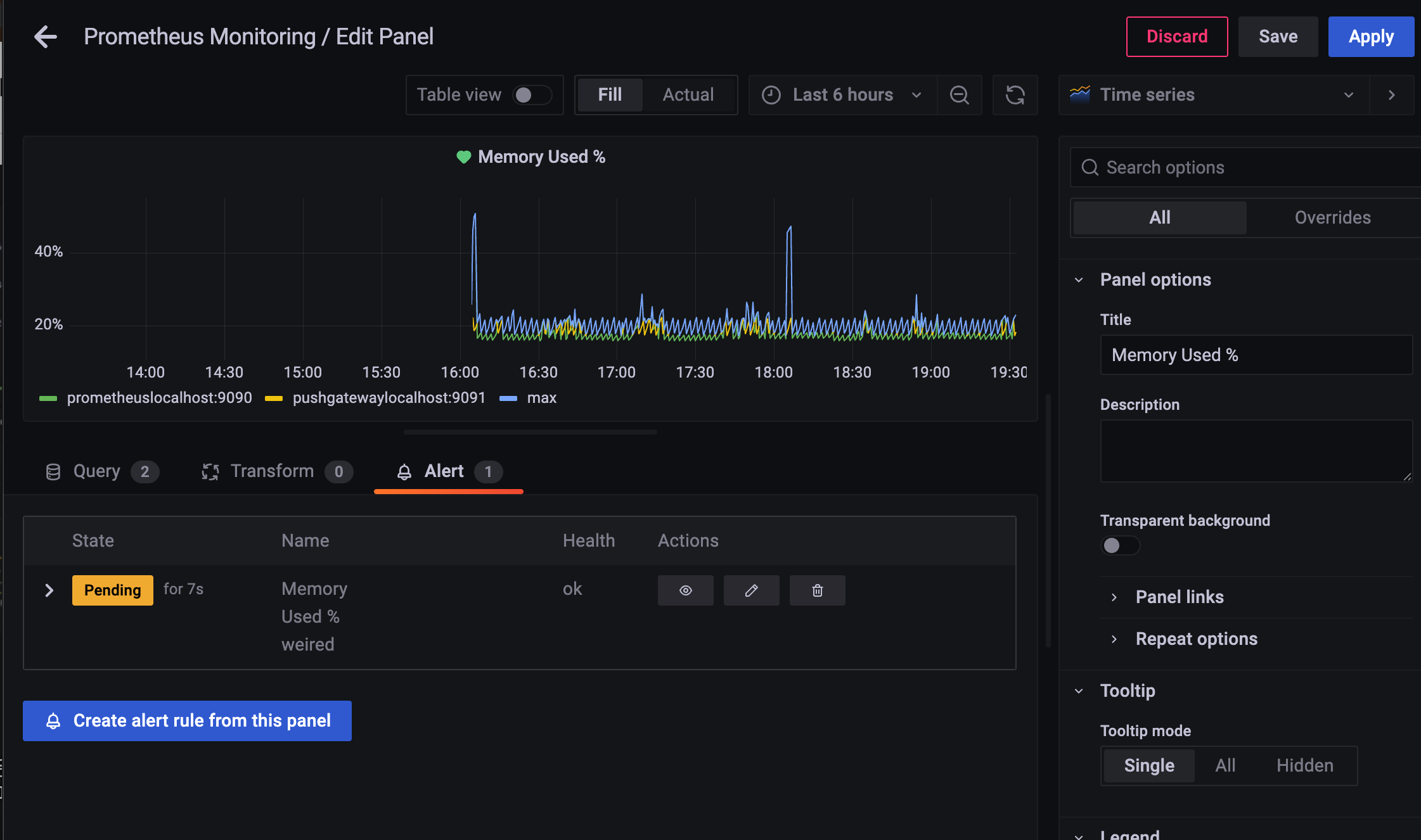
alert 가 생겼고
우측 상단 apply 클릭
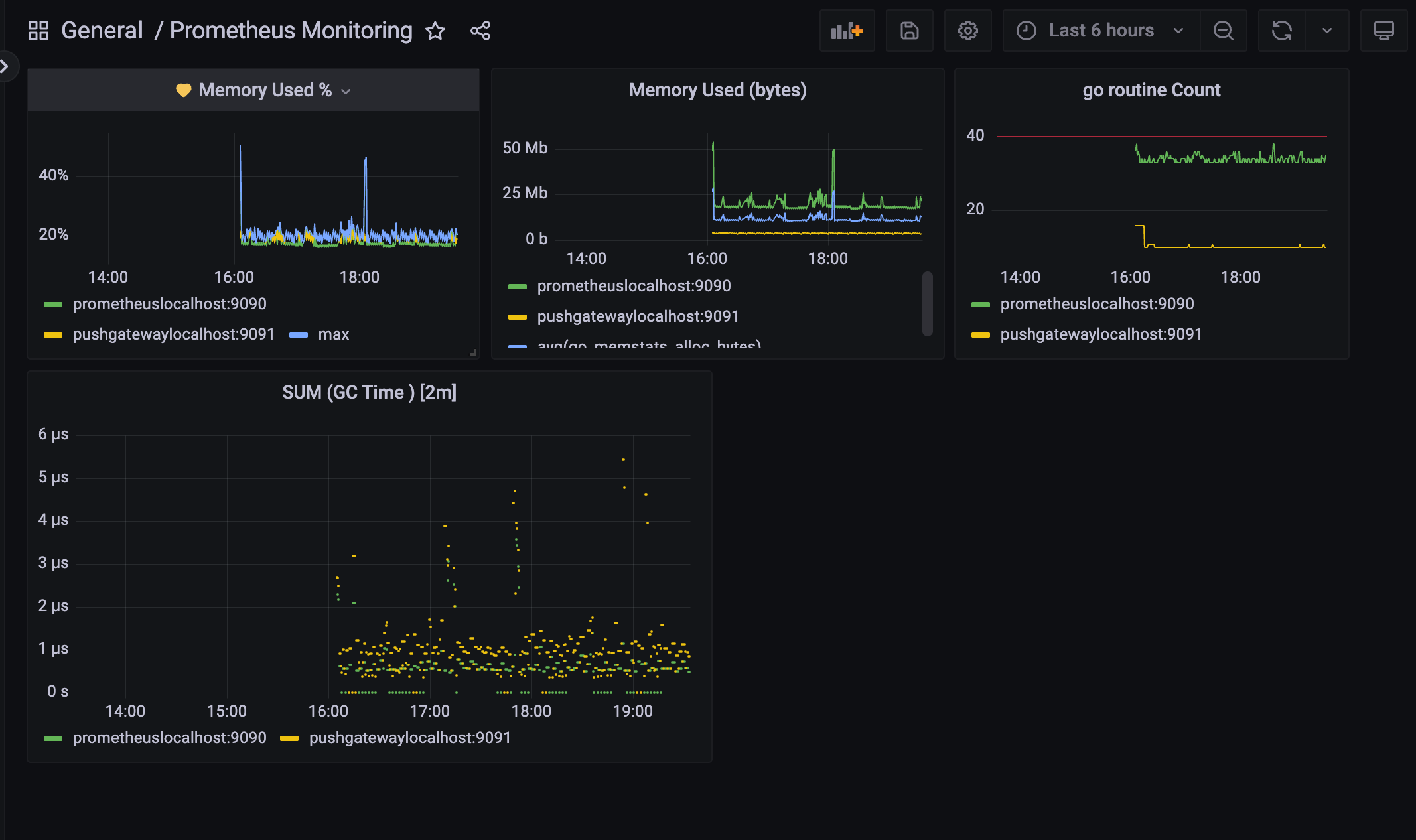
아까 alert 설정해두었던 대시보드에 하트가 생겼다.
해당 panel에 alert가 걸려 있다는 뜻.
초록색은 아직 alert 규칙에 해당되지 않았다는 뜻.
어? 아까 Max가 0 이상이면 alert 하기로 했었는데?
아까 평가하는 기간은 1분동안 평가하고 지난 2분을 평가한다고 했으니까
이 친구가 평가하는 데 시간이 좀 걸린다.
alert rules 에 들어가면 한 눈에 볼 수 있다.
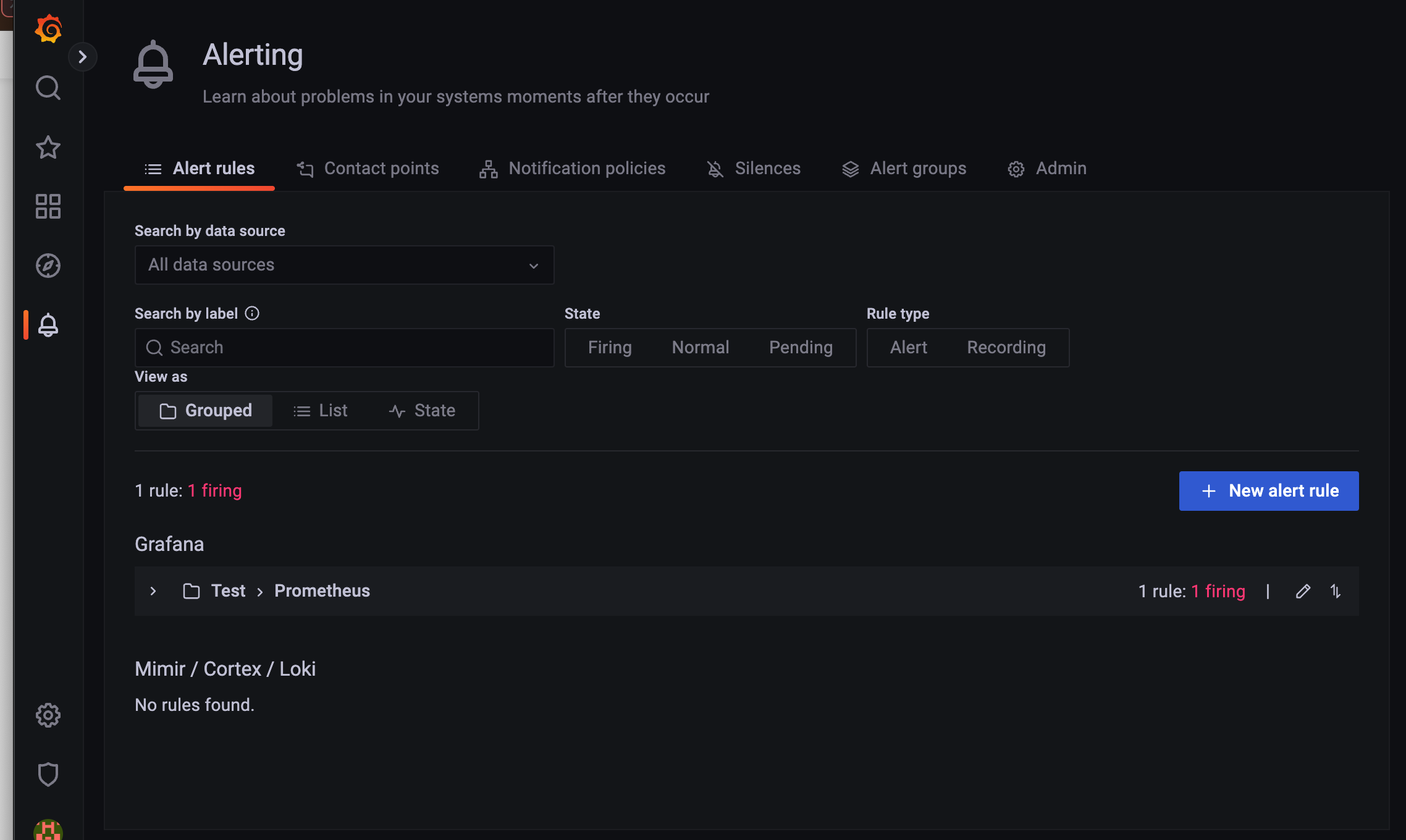
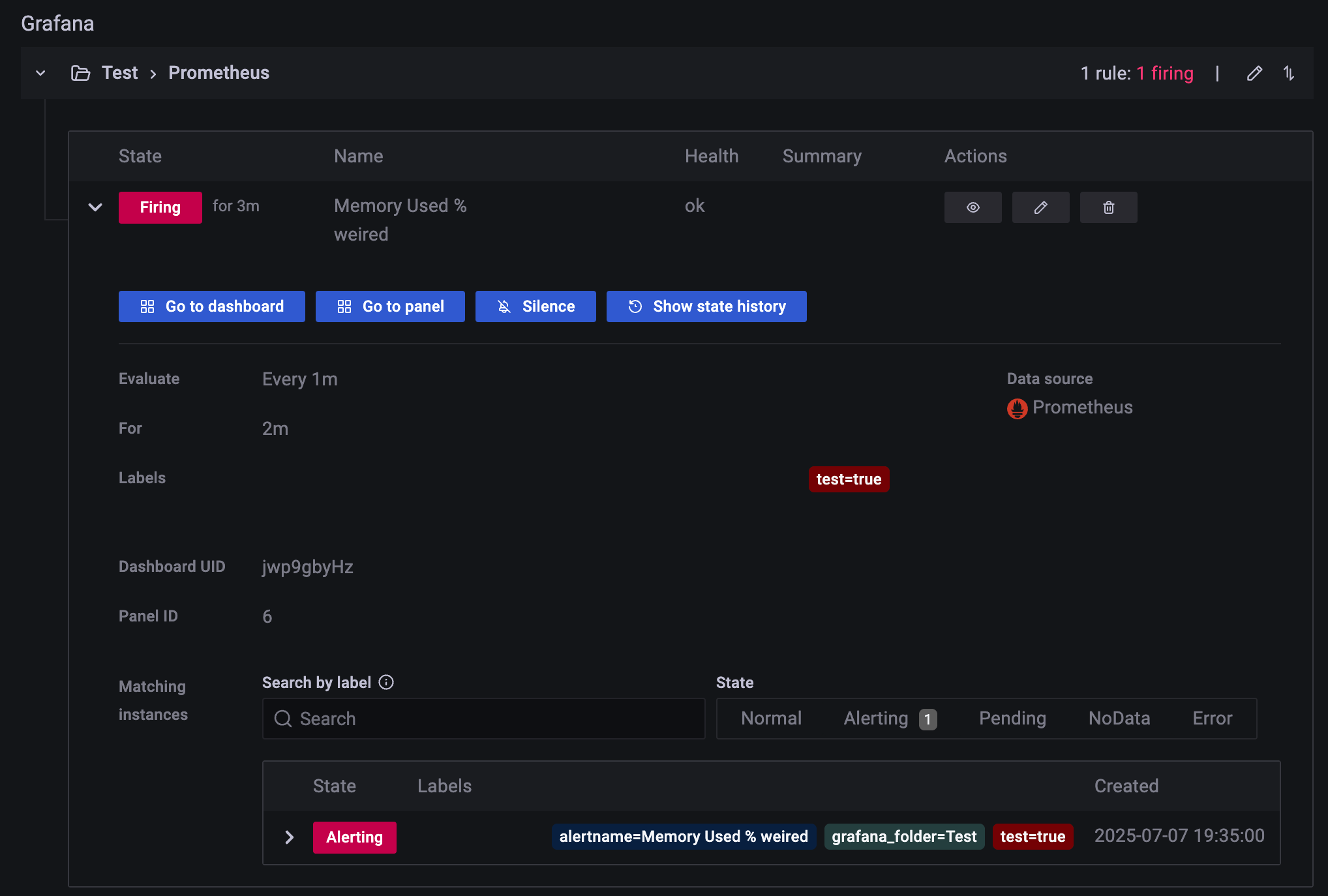
1분이 지나고 last 값이 0 이상인지 지정기간(2분) 에 대해 판단한다.
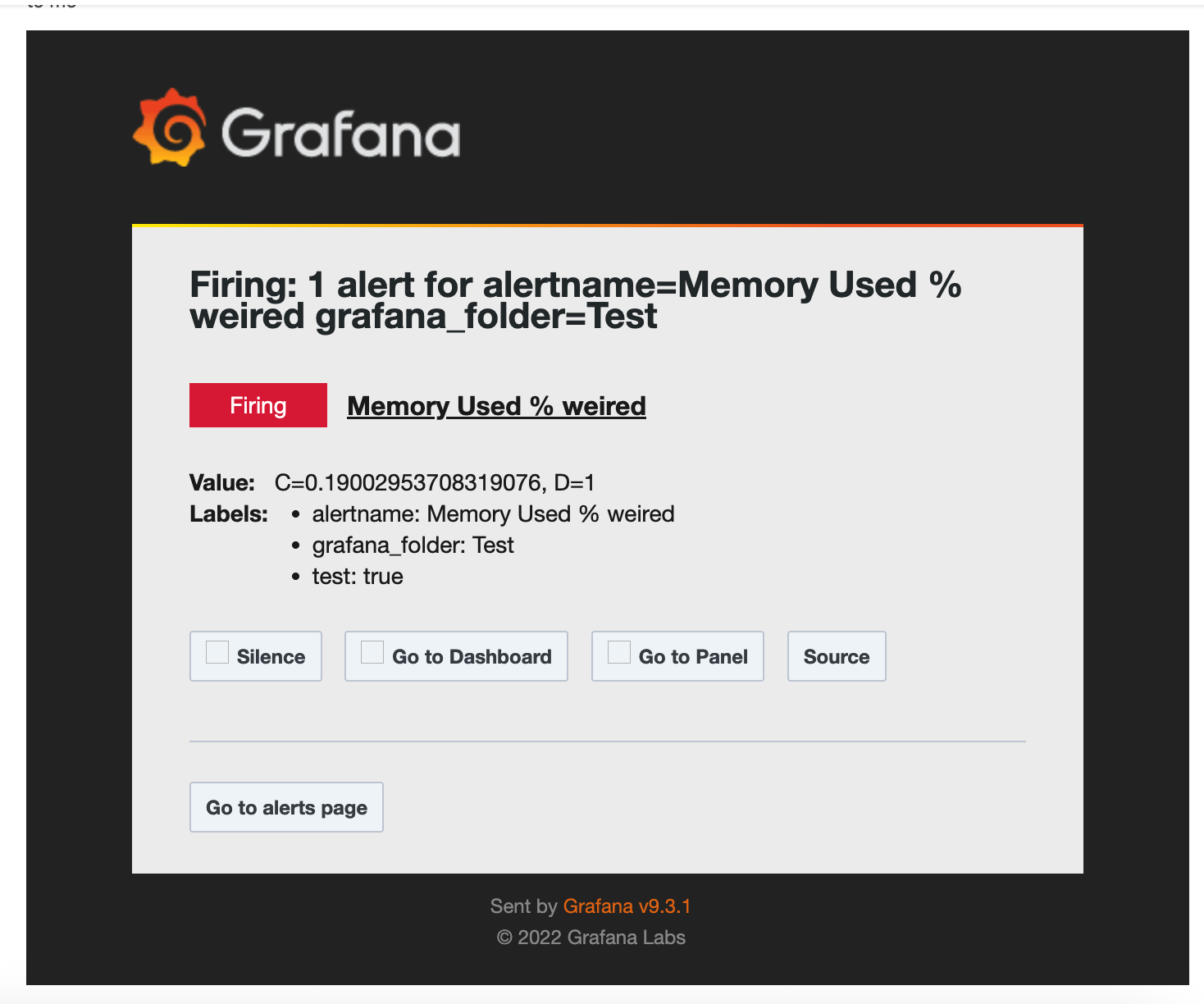
이메일 설정을 잘 해 두었다면 이렇게 메일이 온다.
설정해두었던 라벨 test:true 도 잘 들어가 있다.
3.1 예제 panel
3.1.1 go_routine
go_goroutines
unit: short
Legend: {{job}} {{instance}}
3.1.2 memory used
go_memstats_alloc_bytes
unit: bytes
Legend: {{job}} {{instance}}
3.1.3 memory usage
go_memstats_alloc_bytes/go_memstats_sys_bytes
unit: percent
Legend: {{job}} {{instance}}
3.1.4 sum(gc time) [2m]
rate(go_gc_duration_seconds_sum[2m])
unit: seconds
Legend: {{job}} {{instance}}
