4.1 샤드 할당(Shard allocation)과 재배치(Rerouting)
엘라스틱뷰에서는 오픈서치 api를 통해서 명령어를 날릴 수 있다.
4.1.1 초기 샤드 할당
Elasticvue를 활용해서 진행할 것.
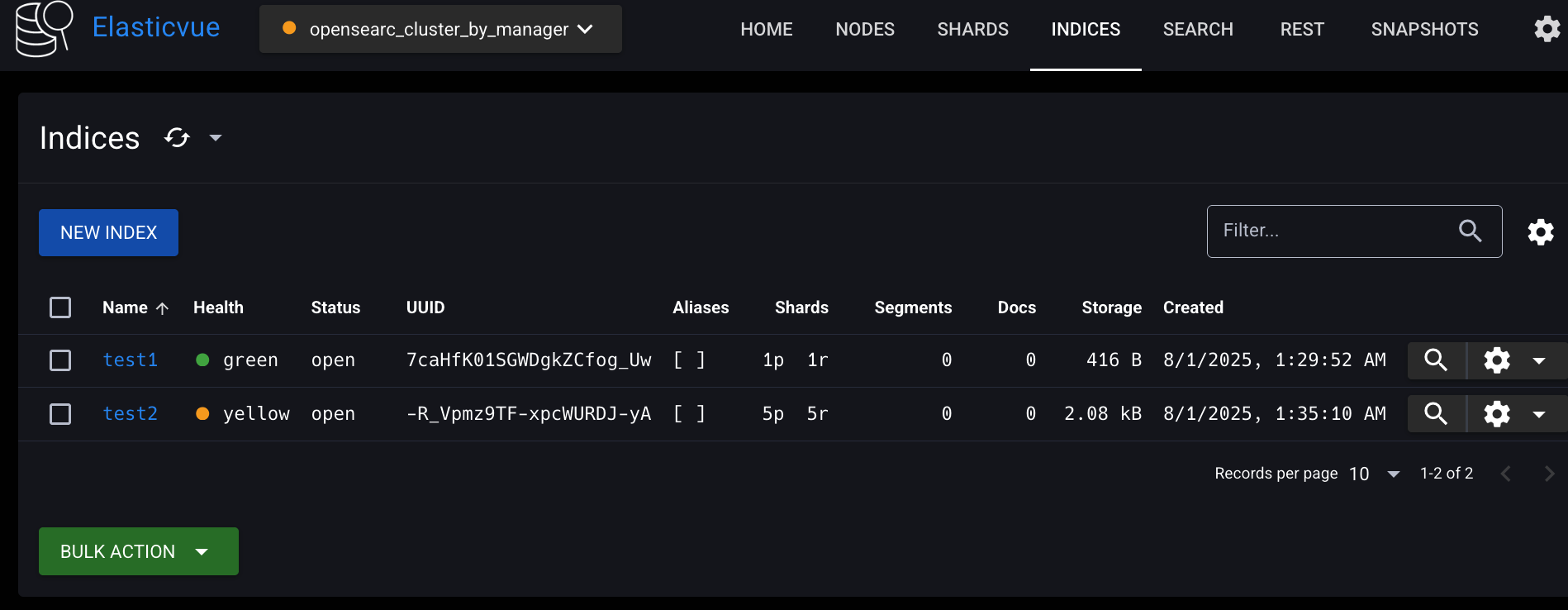
INDICES 탭에 들어가면 test1이라는 인덱스가 이미 하나 있는데 delete 해주고
NEW INDEX버튼 눌러서 test1 인덱스를 생성해보자.
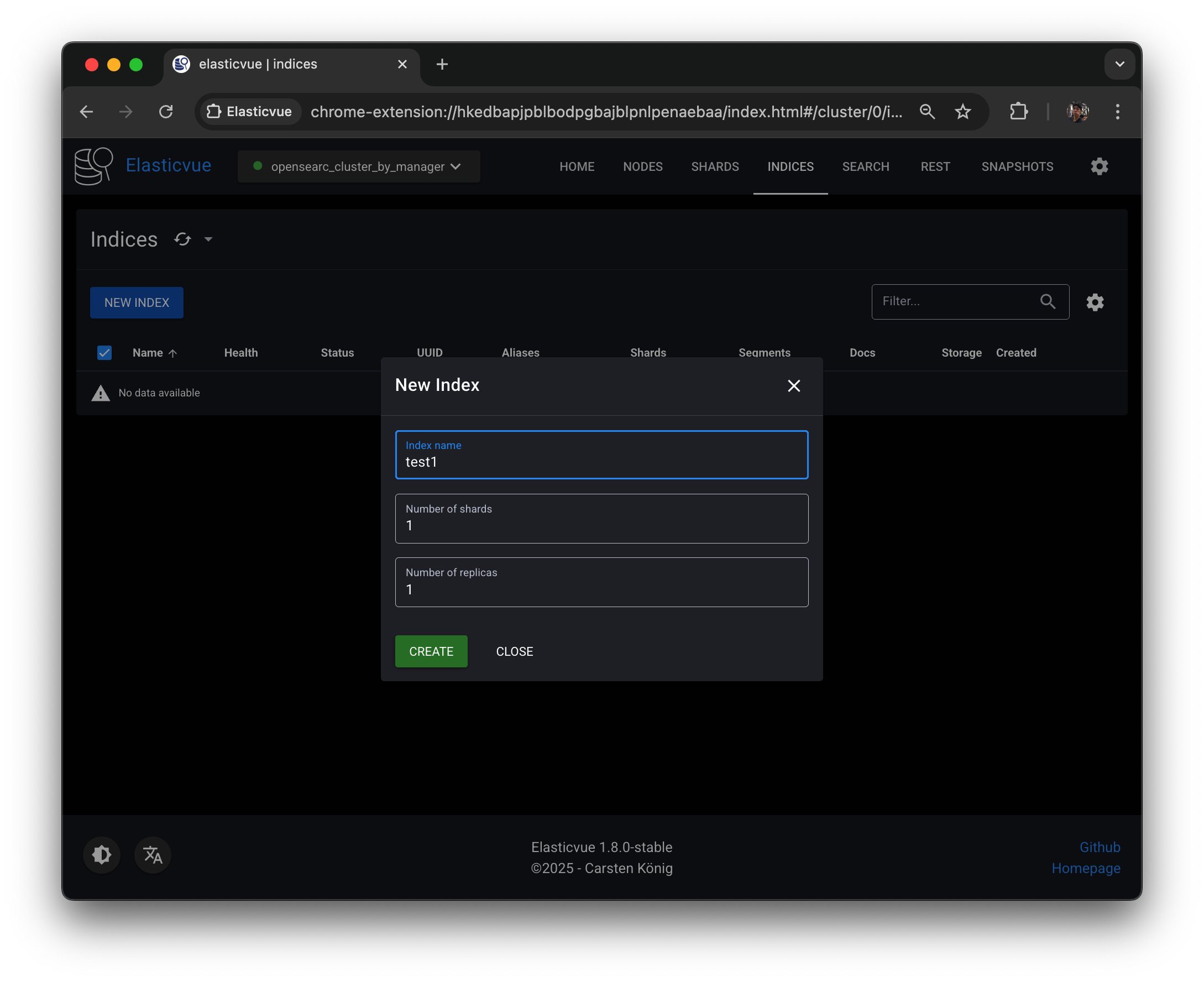
Elasticvue에서는 샤드 개수를 지정하지 않을 경우 기본적으로 프라이머리 샤드 1개, 프라이머리 샤드 당 레플리카 샤드 1개가 생성된다.
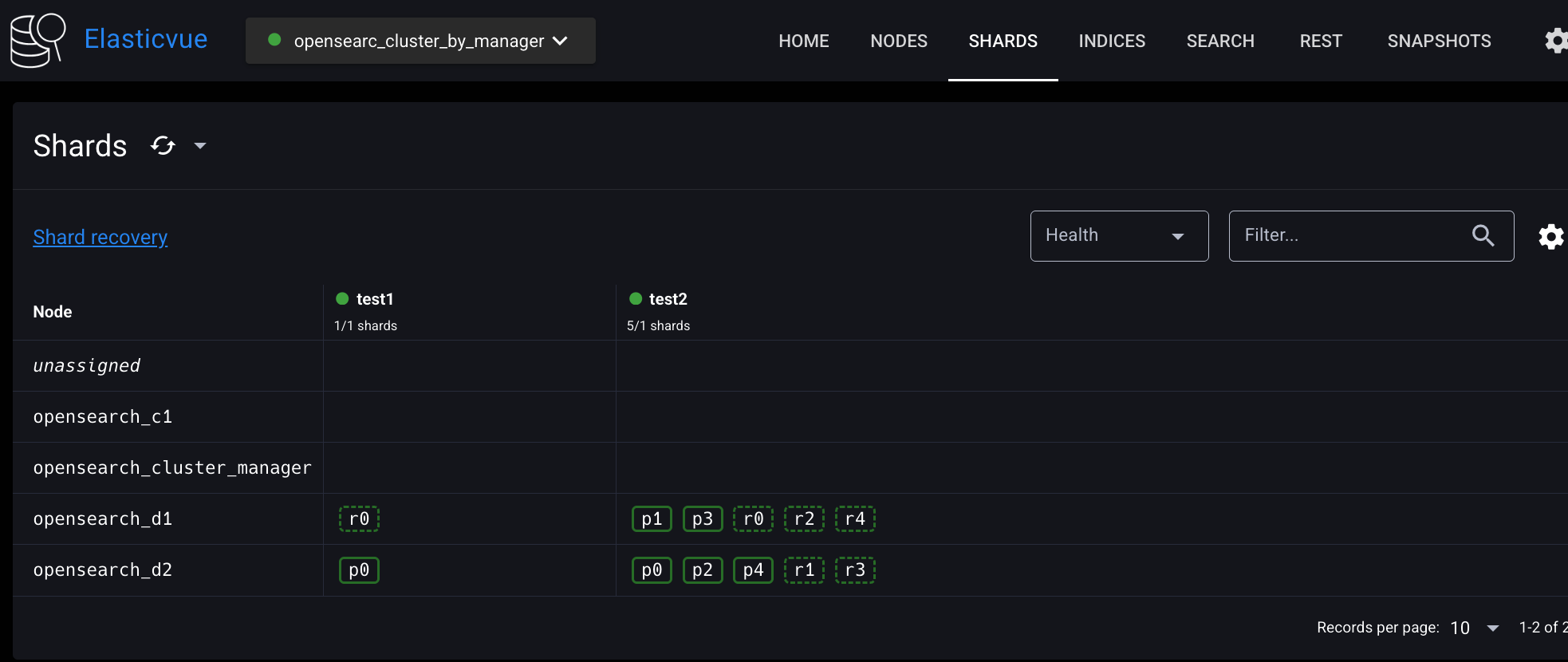
test1 인덱스는 데이터 노드 2개에 걸쳐 저장됐고, 프라이머리 샤드와 레플리카 샤드 쌍은 서로 다른 데이터 노드에 배치된 것을 확인할 수 있다.
4.1.2 인덱스와 샤드 상태 확인
상단에 SHARDS 탭으로 들어가보자.
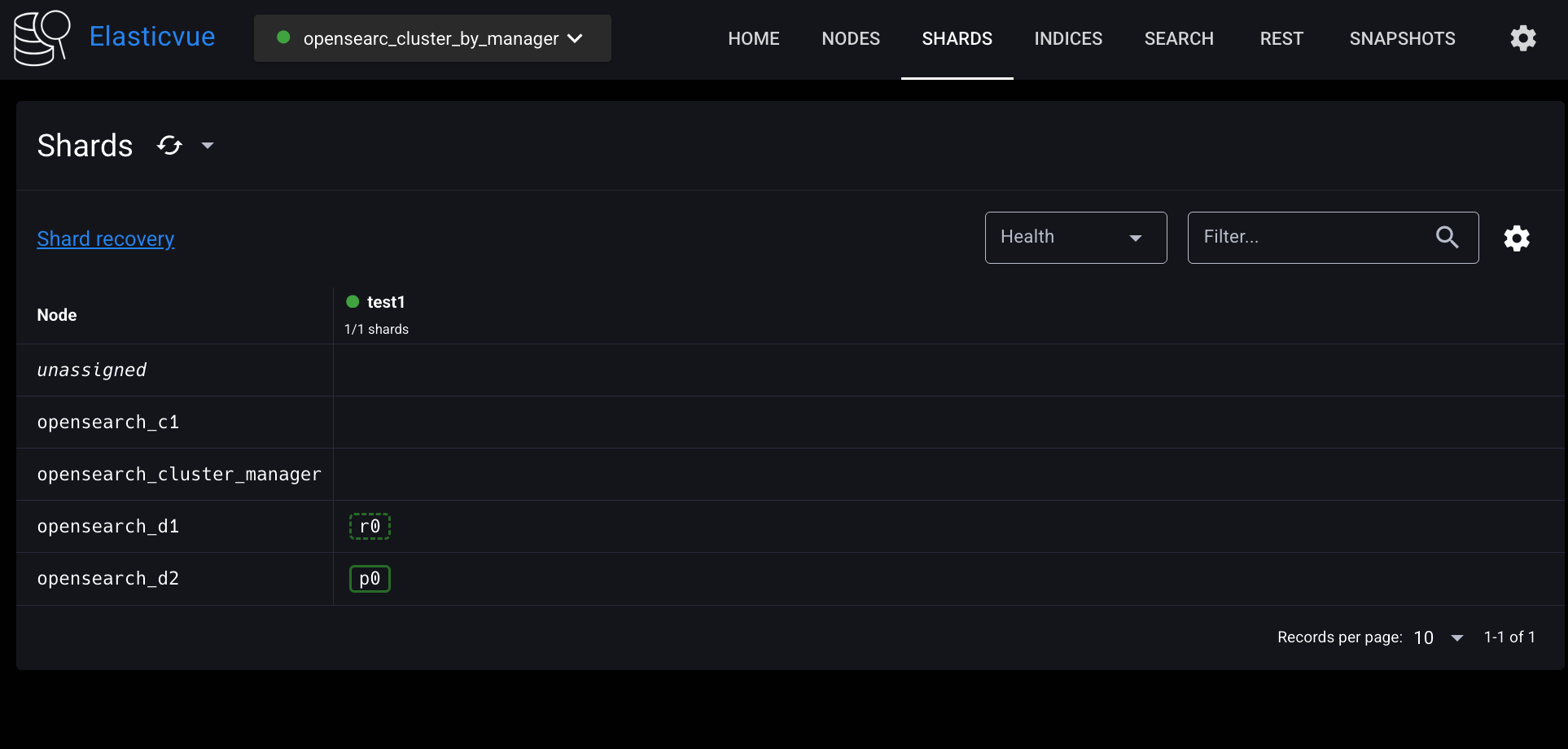
opensearch_d2 에 프라이머리 샤드가 위치해 있고
opensearch_d1 에 레플리카 샤드가 위치해 있는 걸 확인할 수 있다.
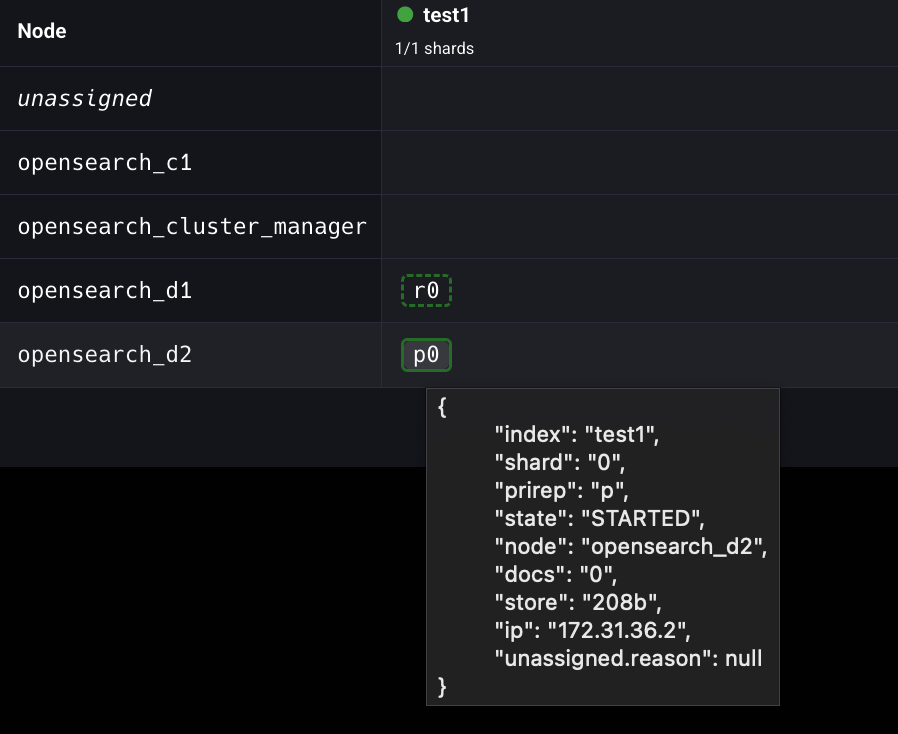
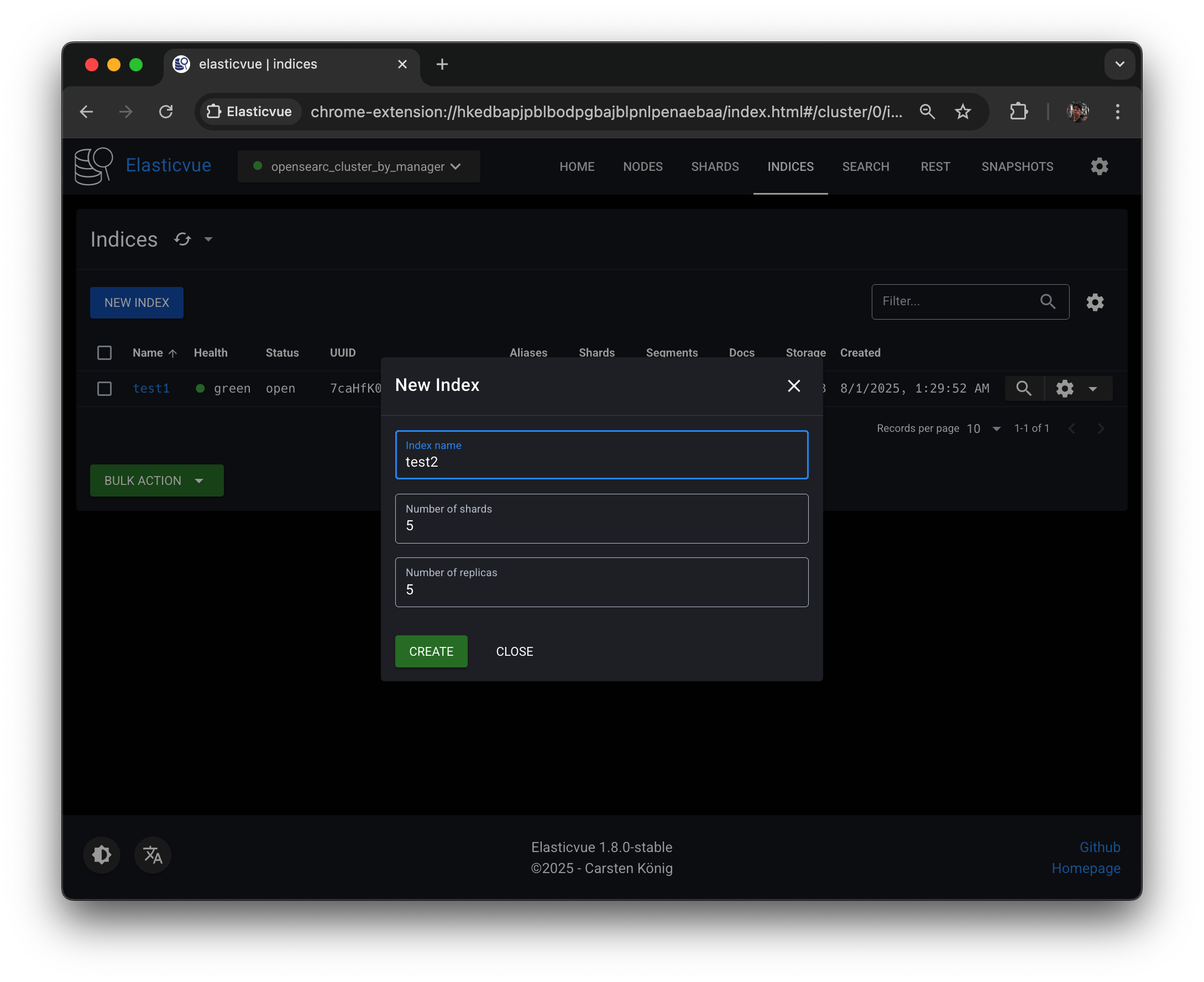
프라이머리 샤드 5개, 프라이머리 샤드 당 레플리카 샤드 5개로 test2 인덱스를 생성해보자.
처음에는 yellow 상태로 시작이 되고 shard를 위치시키고 Replica를 위치시키는 작업이 다 끝나면 정상적으로 잘 끝났다면 GREEN 상태로 바뀔 것.
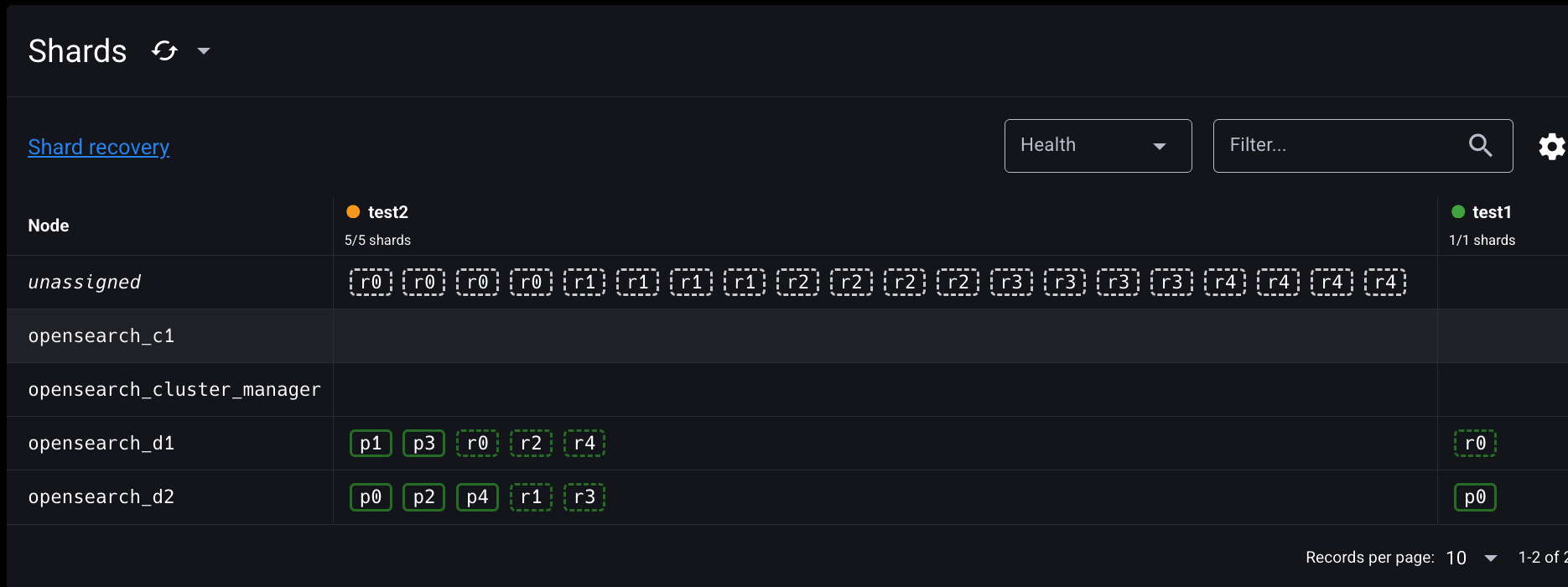
프라이머리샤드는 실선, 레플리카 샤드는 점선이다.
어느 노드에 위치할지는 오픈서치, 매니저가 결정하는 거고,
노드 넘버는 다른 수 있다.
프라이머리 샤드와 레플리카 샤드 쌍이 서로 다른 데이터 노드에 배치된 것을 확인할 수 있다.
그런데 unassigned는 무엇일까? 샤드의 상태는 다음과 같이 크게 4가지로 구분할 수 있다.
unassigned: 샤드가 어떤 노드에도 할당되지 않은 상태initializing: 샤드를 노드 메모리에 적재중인 상태 (메모리에 모두 적재된 것이 아니므로, 샤드 사용 불가능)started: 샤드가 메모리에 모두 적재되어 사용 가능한 상태 (프라이머리 샤드가 started 상태가 되어야 레플리카 샤드 할당 가능)relocating: 샤드가 다른 노드로 재배치중인 상태
샤드의 상태에 따라 인덱스의 상태 또한 결정된다. Elasticvue의 INDICES 탭에서 Health 컬럼을 보면 인덱스의 상태를 확인할 수 있다.
red: 한 개 이상의 프라이머리 샤드가 unassigned 된 경우 (인덱스 읽기/쓰기 모두 불가능)yellow: 프라이머리 샤드는 모두 정상적으로 노드에 할당되었지만, 한 개 이상의 레플리카 샤드가 unassinged 된 경우 (인덱스 읽기/쓰기 모두 가능하지만, 장애 발생시 인덱스를 사용하지 못할 수 있음)green: 프라이머리 샤드와 레플리카 샤드 모두 정상적으로 노드에 할당된 경우
test2 인덱스의 경우 프라이머리 샤드는 모두 정상적으로 노드에 할당되었기 때문에 yellow 상태인 것을 확인할 수 있다.
4.1.3 샤드 할당에 대한 정보 확인
아까 만들 때 replica 개수를 5개로 했었다.
- replica 개수는 primary를 제외한 개수다.
할당되지 못하고 남은 replica 들은 Unassigned에 들어있다.
test2 인덱스의 레플리카 샤드 일부가 정상적으로 노드에 할당되지 못한 이유는 무엇일까? GET /_cluster/allocation/explain API로 샤드가 할당되지 않은 이유를 알 수 있다. Elasticvue REST 클라이언트를 활용해서 다음 API를 호출해보자.
$ curl -XGET $OPENSEARCH_REST_API/_cluster/allocation/explain?pretty=true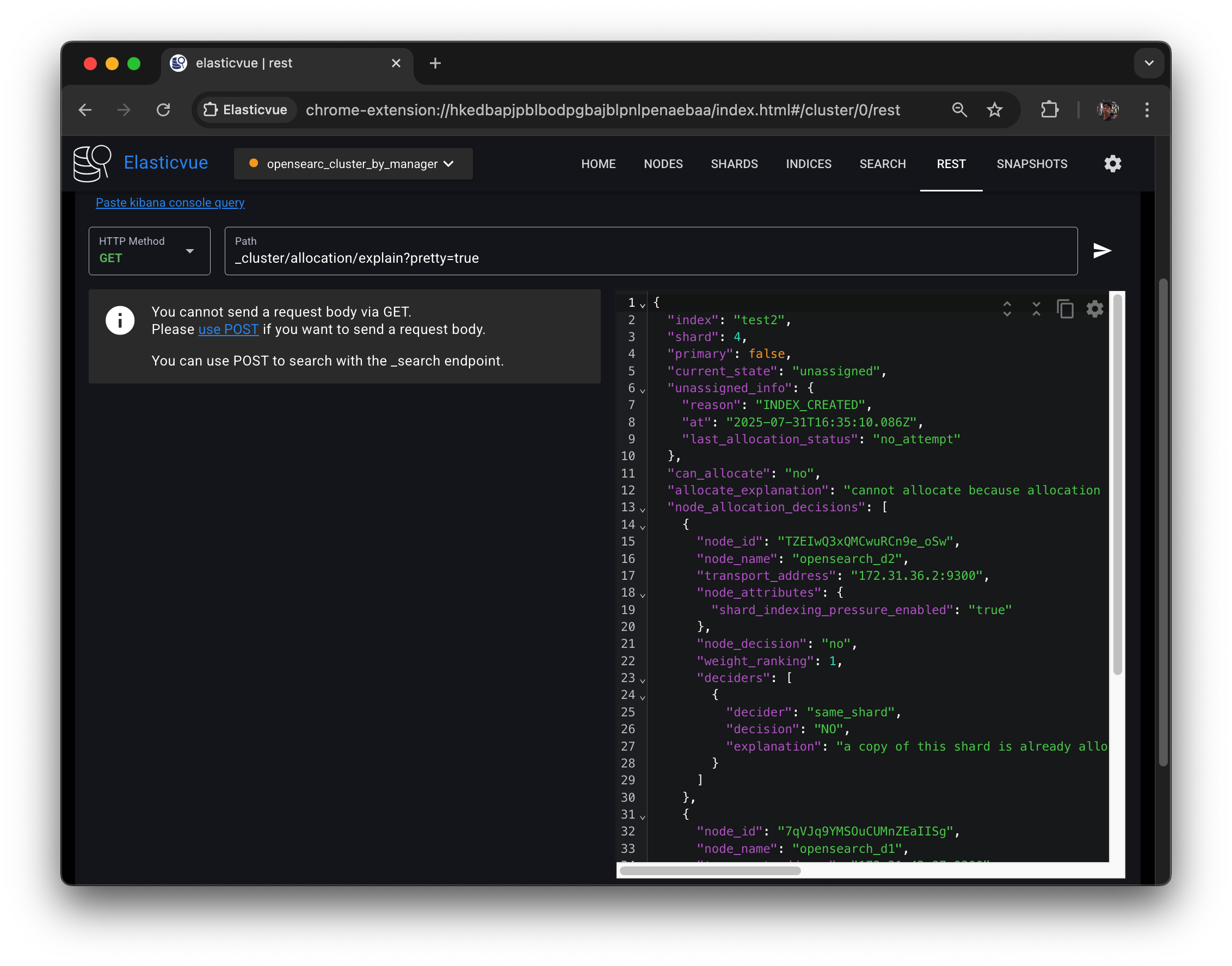
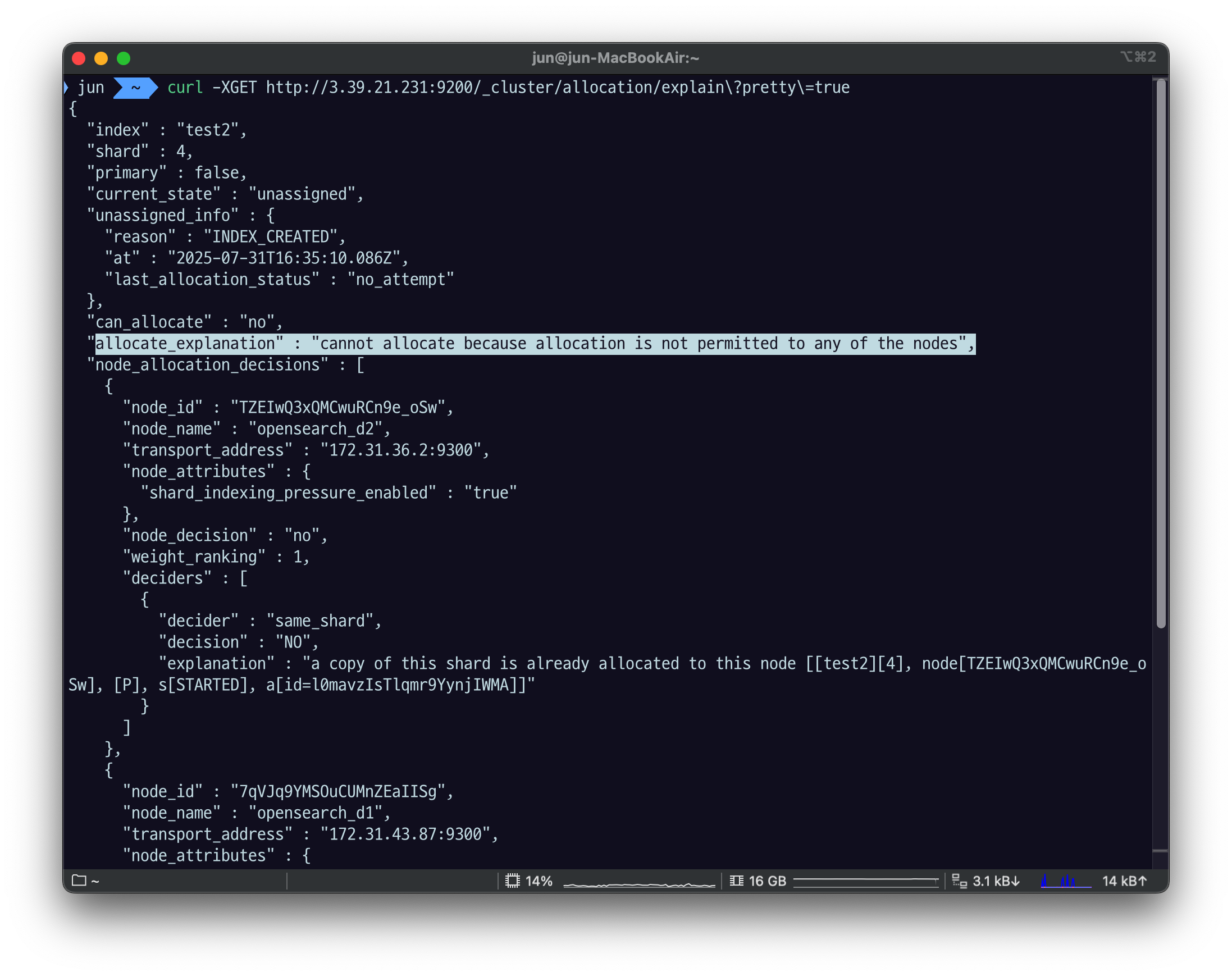
allocation을 어떤 노드에도 할 수가 없다고 나온다.
그리고 노드 별로 왜 그런지 나오는데,
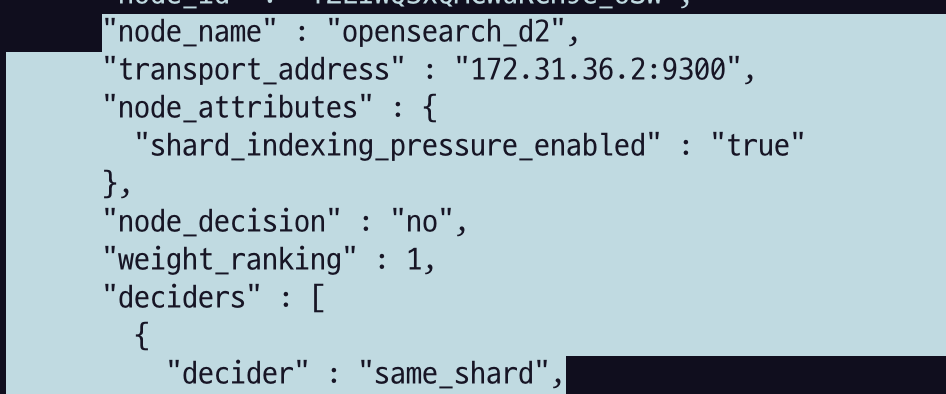
d2에 대해 same shard다 라고 못하는 이유를 알려준다.
explanation을 보면 a copy of this shard is already allocated to this node [[test2][3], node[OpwmNmeiQSCd19yKmZfKfQ], [R], s[STARTED], a[id=_FKc6P1oRuKDZqO6Bpccyw]]라고 설명하고 있다. 즉 프라이머리 샤드의 레플리카 샤드가 노드에 이미 존재하는 경우, 동일한 노드에 또 다른 레플리카 샤드를 할당할 수 없다는 뜻이다. OpenSearch가 프라이머리 샤드와 동일한 노드에 레플리카 샤드를 할당하지 않고, 동일한 노드에 동일한 프라이머리 샤드의 복제본을 두 개 이상 할당하지 않기 때문이다.
4.1.4 unassigned 샤드 문제 해결
4.1.3과 같은 이유로 발생한 unassigned 샤드 문제는 두 가지 방법으로 해결할 수 있다.
- 인덱스의 레플리카 수를 줄여서 unassigned 샤드 제거
- 클러스터에 노드를 추가해서 unassigned 샤드를 새로운 노드로 재배치
먼저 인덱스의 레플리카 수를 줄여서 문제를 해결해보자. 다음 요청으로 test2 인덱스의 레플리카 샤드 개수를 프라이머리 샤드 당 1개로 변경할 수 있다.
$ curl -XPUT "$OPENSEARCH_REST_API/test2/_settings?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"number_of_replicas": 1
}
'세팅 확인 한 번 하고
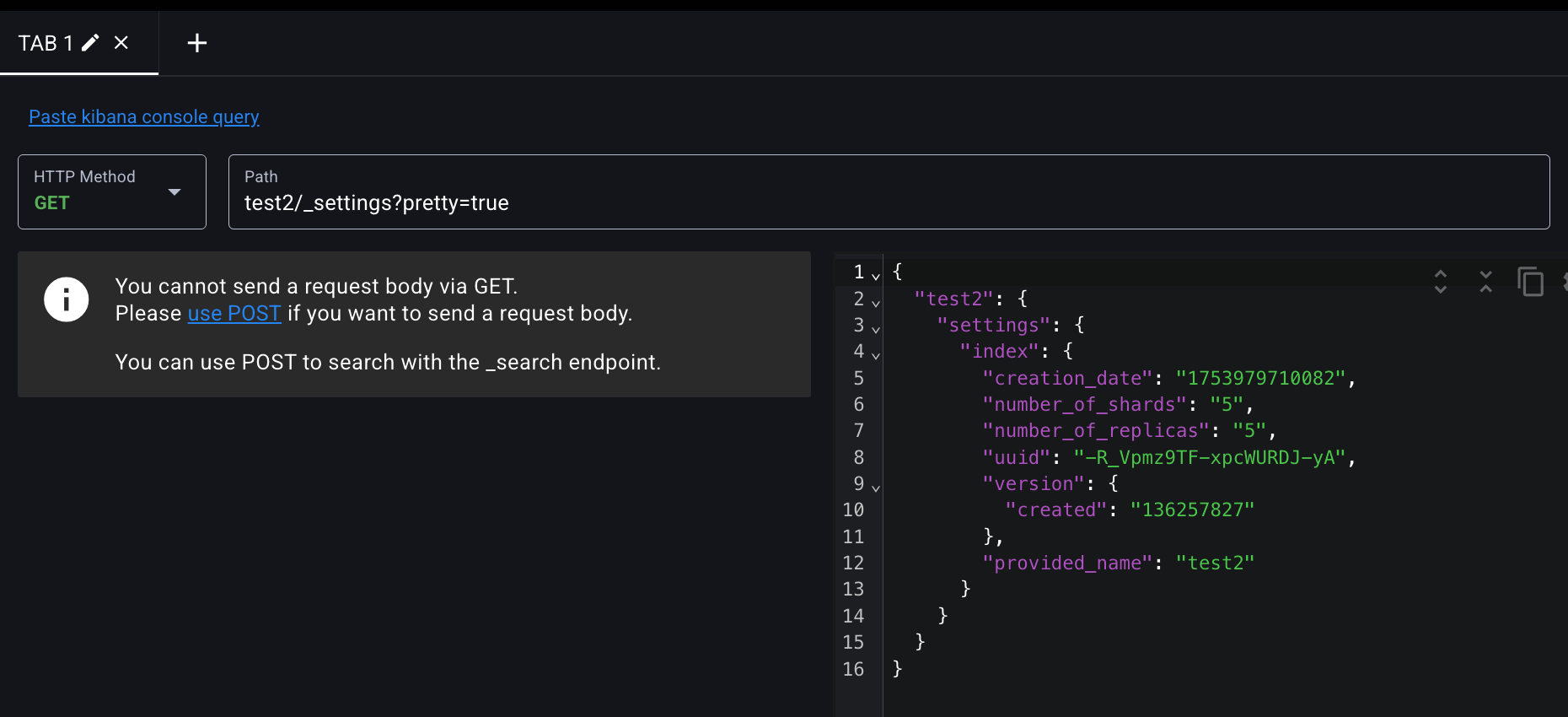
METHOD를 PUT으로 바꾸고
body에다가
{
"number_of_replicas" : 1
}를 입력하고 SEND REQUEST 날려주면
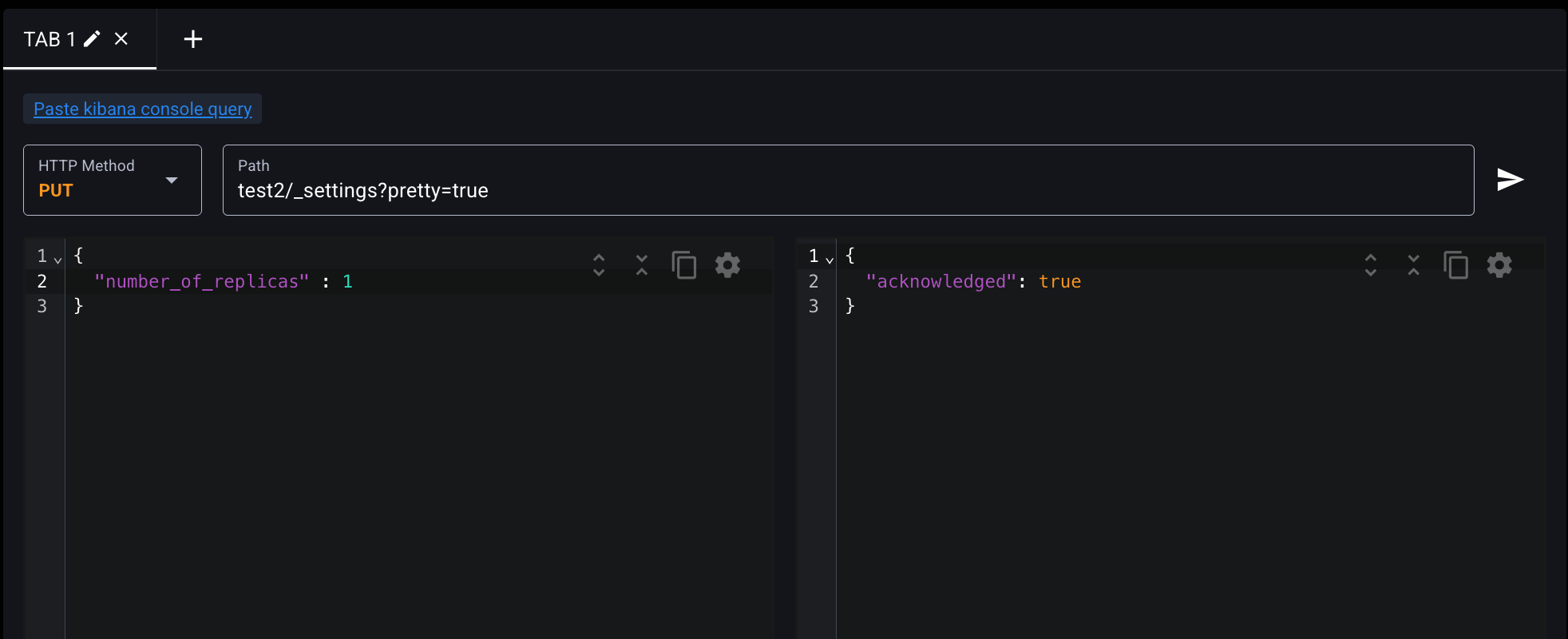
ack:true 나오고
Shards 탭에 들어가서 확인해보면
unassigned 샤드가 사라지고, 인덱스의 상태도 green으로 변경된 것을 확인할 수 있다.
이번에는 클러스터에 데이터 노드를 추가해서 문제를 해결해보자. 먼저 test2 인덱스의 레플리카 샤드 개수를 프라이머리 샤드 당 2개로 늘려서 문제 상황을 재현해보자.
$ curl -XPUT "$OPENSEARCH_REST_API/test2/_settings?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"number_of_replicas": 2
}
'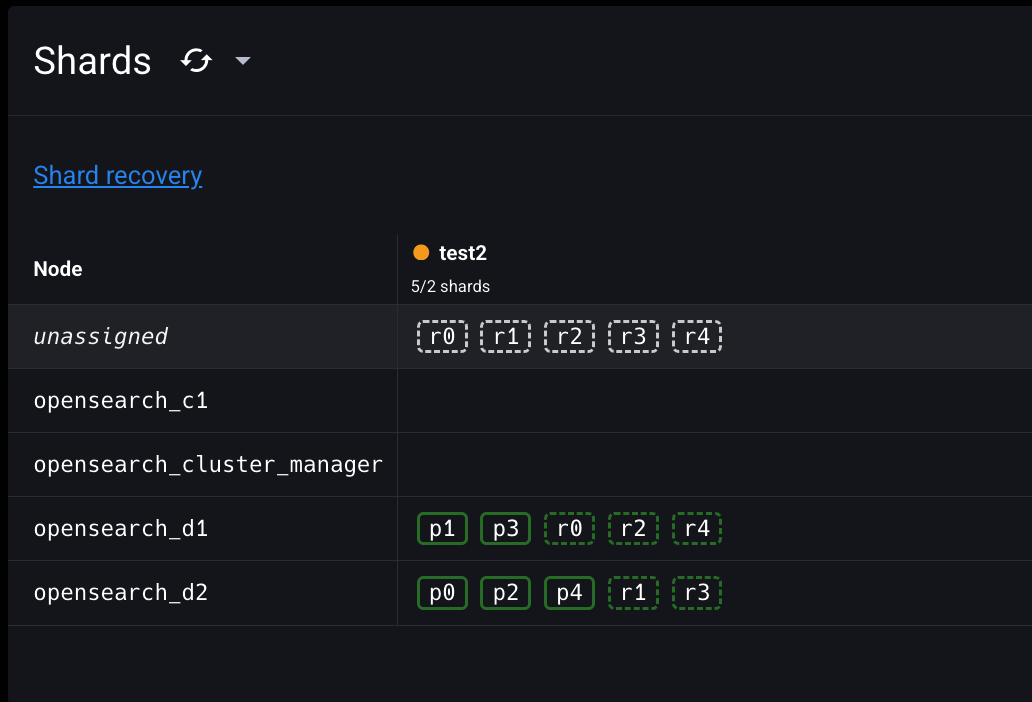
총 5개의 레플리카 샤드가 unassigned 상태인 것을 확인할 수 있다.
AMI를 활용해서 EC2 인스턴스를 1개 더 생성하고, OpenSearch config를 다음과 같이 수정해주자.
plugins.security.disabled: true
cluster.name: opensearch-cluster
node.name: opensearch-d3
node.roles: [ data, ingest ]
network.host: 0.0.0.0
discovery.seed_hosts: ["<CLUSTER_MANAGER_NODE_PUBLIC_IP>"]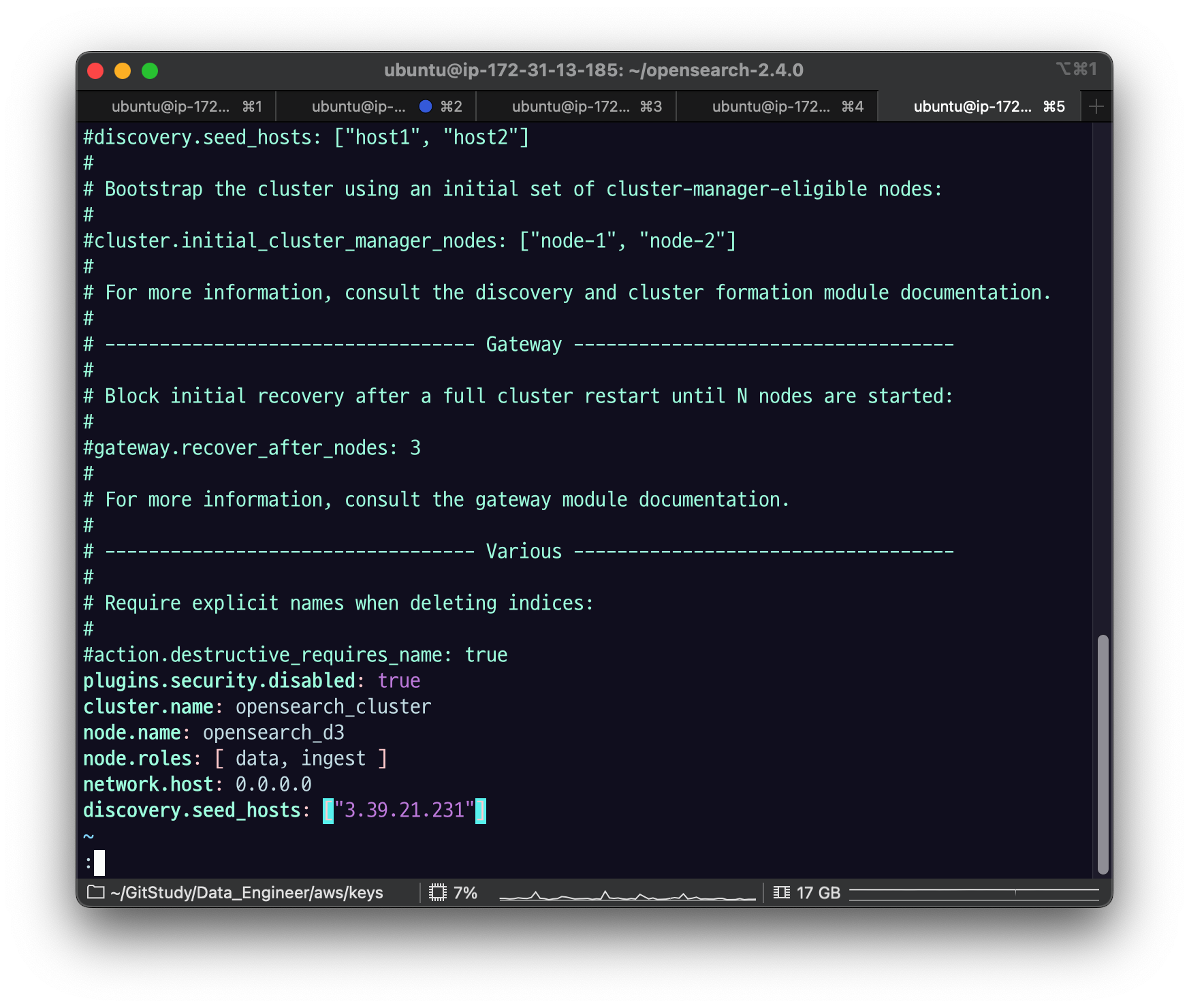
노드를 재시작하고
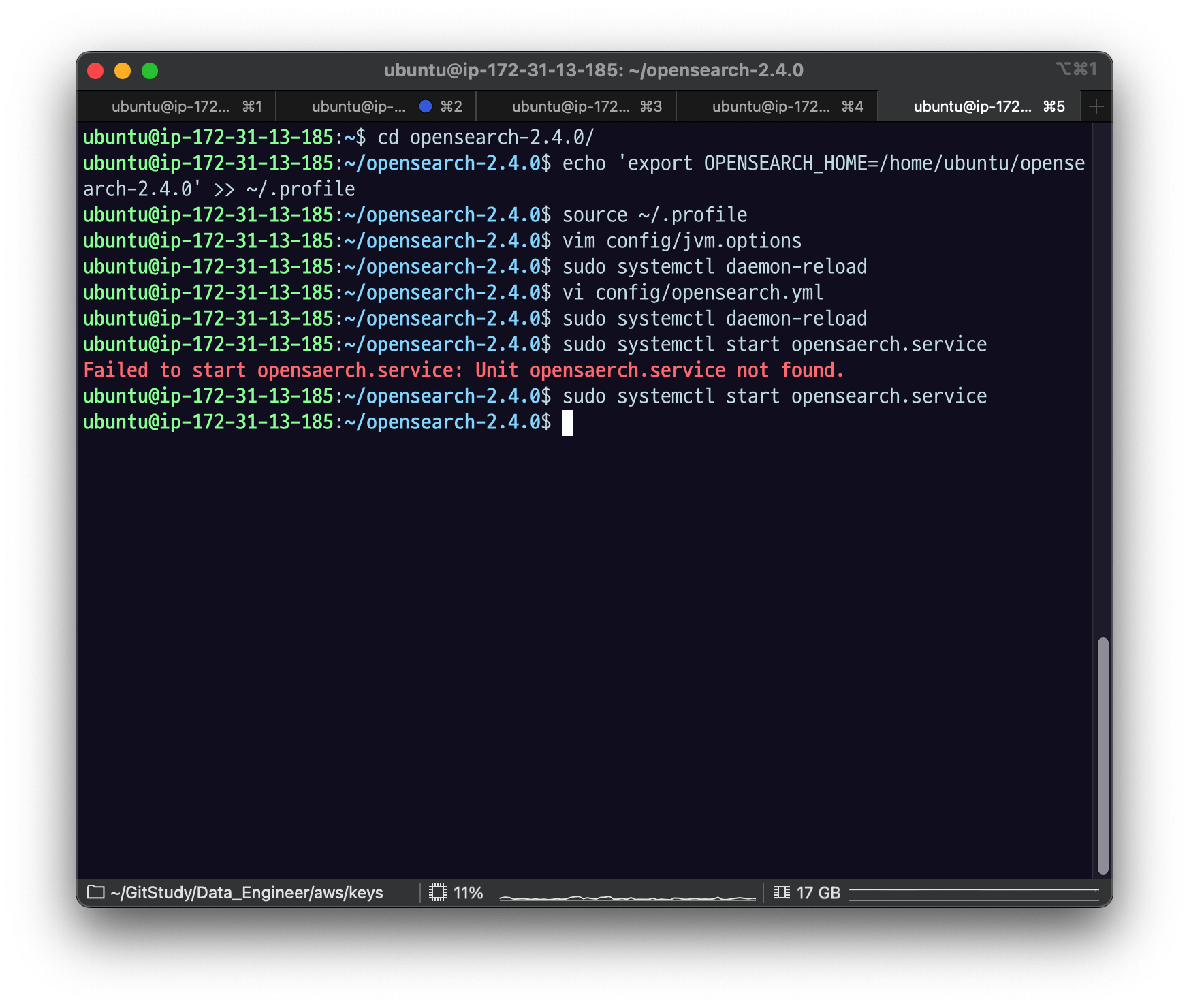
Elasticvue를 확인해보면 클러스터에 opensearch-d3 노드가 추가된 것을 확인할 수 있다.
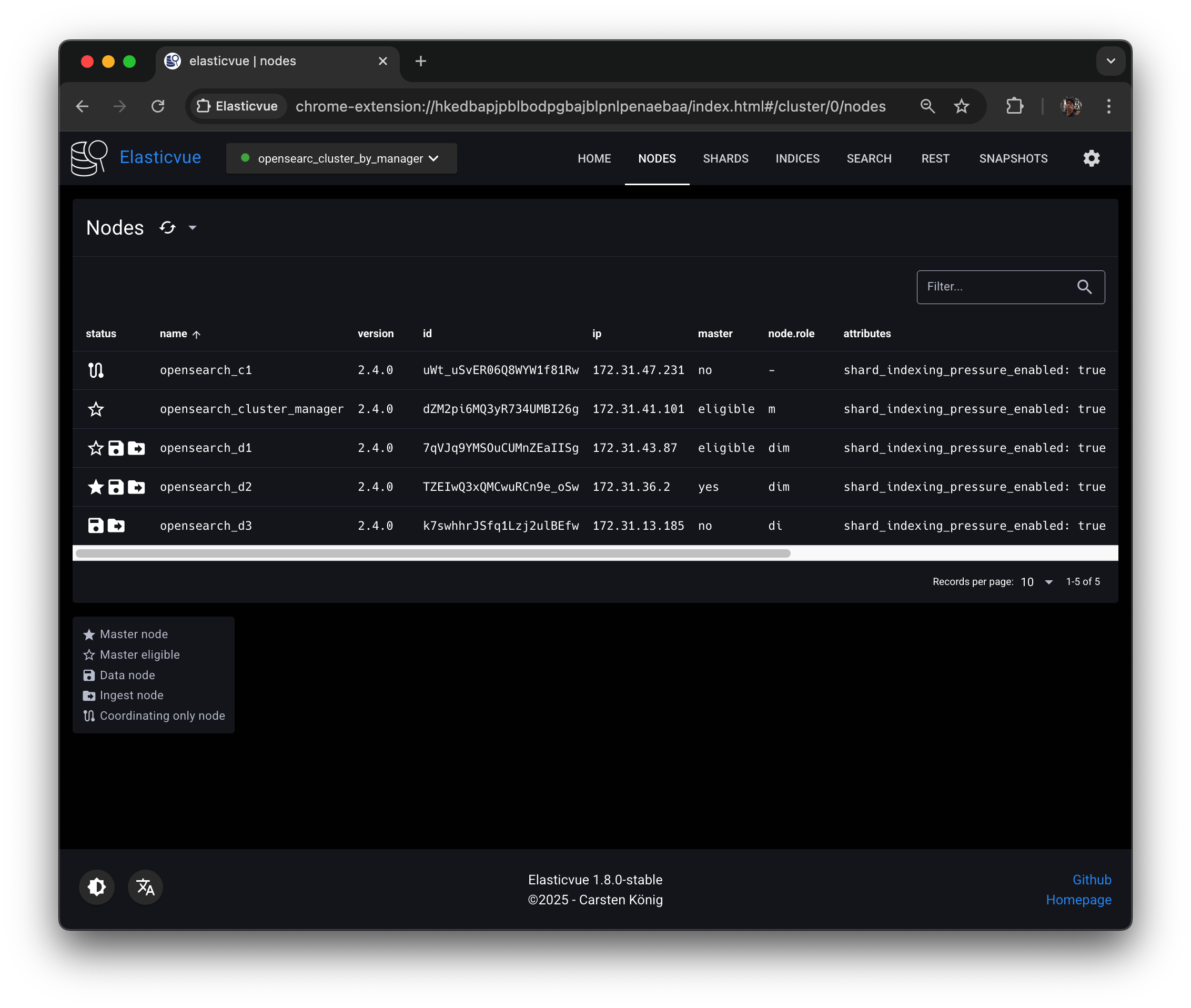
unassigned 상태였던 모든 레플리카 샤드가 opensearch-d3 노드에 자동으로 재배치되면서 인덱스 상태도 green으로 정상화되었다.
4.1.5 수동 샤드 재배치
앞서 본 것처럼 기본적으로 OpenSearch 클러스터는 샤드 할당과 재배치를 자동으로 수행한다.
데이터의 장애 대응에 대해서 고민을 하거나 데이터 부하 관점에서 봤을 때,
지금 이 상태가 좋은 상태인 것일까?
우선 가장 일을 많이 하는 것은 primary shard 다.
해당 인덱스에 대한 모든 요청에 진입점이 되는 건 primary shard기 때문에
replica shard가 병렬로 읽기 처리에 대해서는 대신할 수 있지만 그것도 어쨋든
primary shard를 거쳐서 간다.
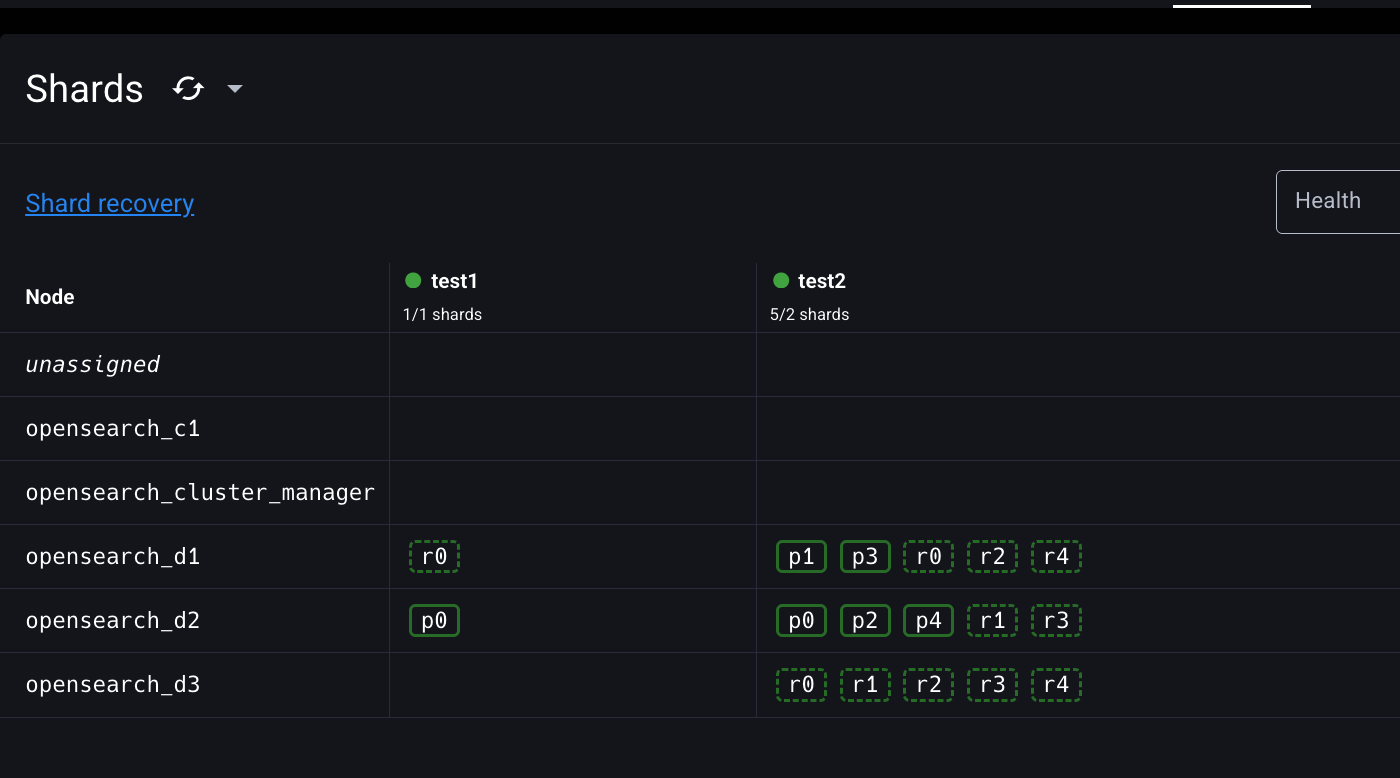
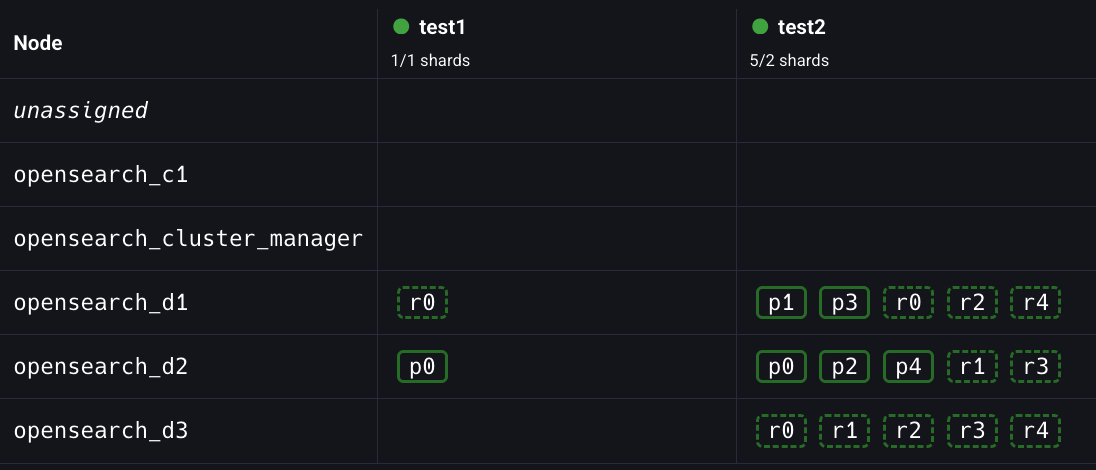
위에 상태를 보면 d1에는 프라이머리샤드가 2개, d2에는 3개, d3에는 0개가 있다
프라이머리샤드가 가장 많은 일을 하니까 그거에 의해 생기는 부하가 위 비율대로라면
2:3:0 으로 차이가 나게 된다.
위 세 노드의 하드웨어 스펙이 동일하다고 하면, JVM 스펙이 동일하다고 하면 d2가 제일 부하를 많이 받아서 d2가 죽었을 때에 대한 임펙트도 크고 해당 노드에 위치한 프라이머리 샤듣들에게 요청하는 데이터 처리가 느려질 수도 있다.
그래서 부하를 고르게 나눠주면 좋다.
수동으로 샤드를 재배치하고 싶다면 reroute API를 사용하면 된다.
이거는 index 하위에 있는 게 아니라 _cluster 에다가 해야된다.
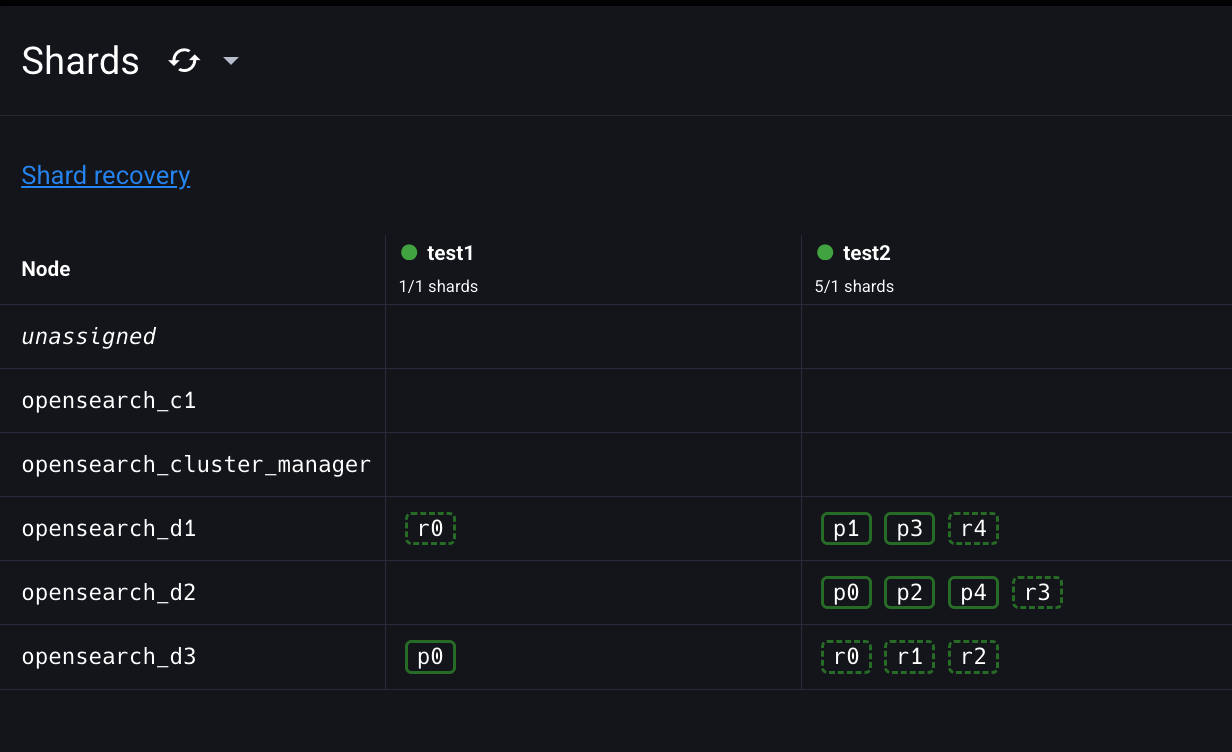
test2 index p4(프라이머리샤드4번)를 d3로 옮겨보자.
다음 요청으로 test1 인덱스의 프라이머리 샤드를 opensearch-d2 노드에서 opensearch-d3 노드로 재배치해보자.
$ curl -XPOST "$OPENSEARCH_REST_API/_cluster/reroute?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"commands": [
{
"move": {
"index": "test2",
"shard": 4,
"from_node": "opensearch_d2",
"to_node": "opensearch_d3"
}
}
]
}
'API는 post로 지정하고
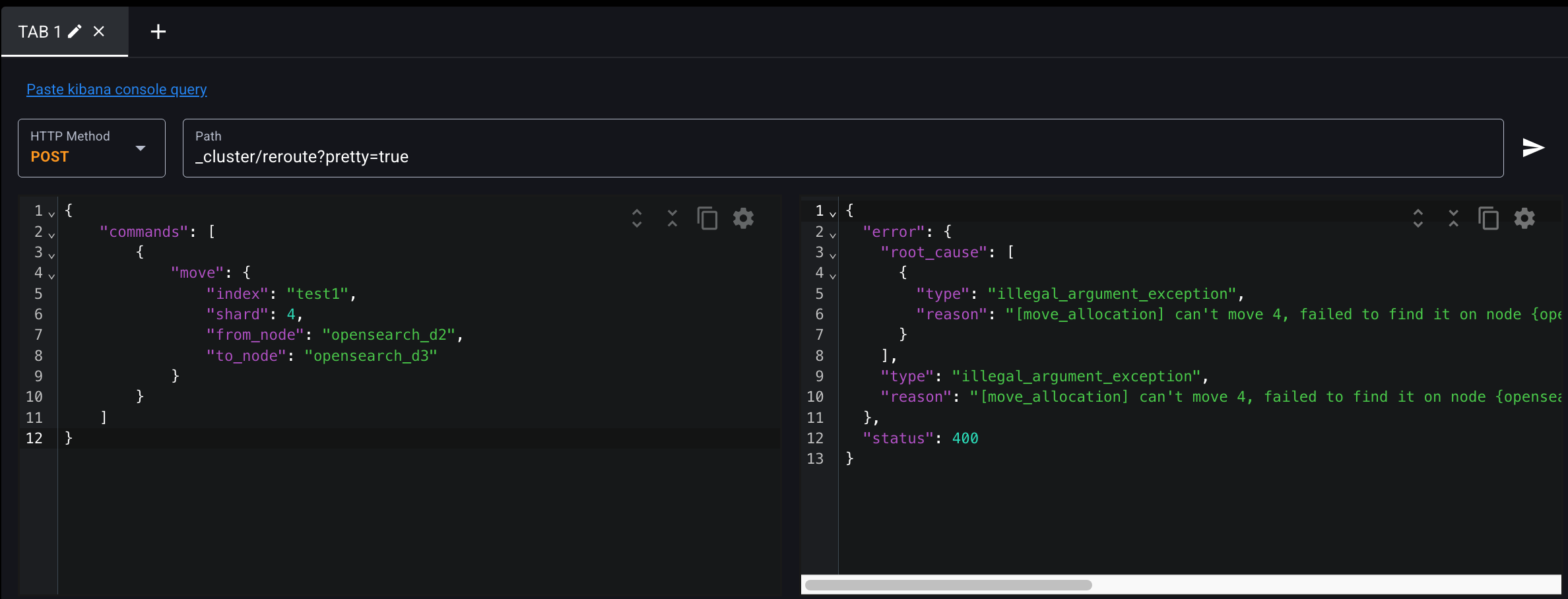
SEND REQUEST 눌러보면 에러가 났다.
이유를 알아보기 위해 아래 POST 를 진행해서 알아보자.
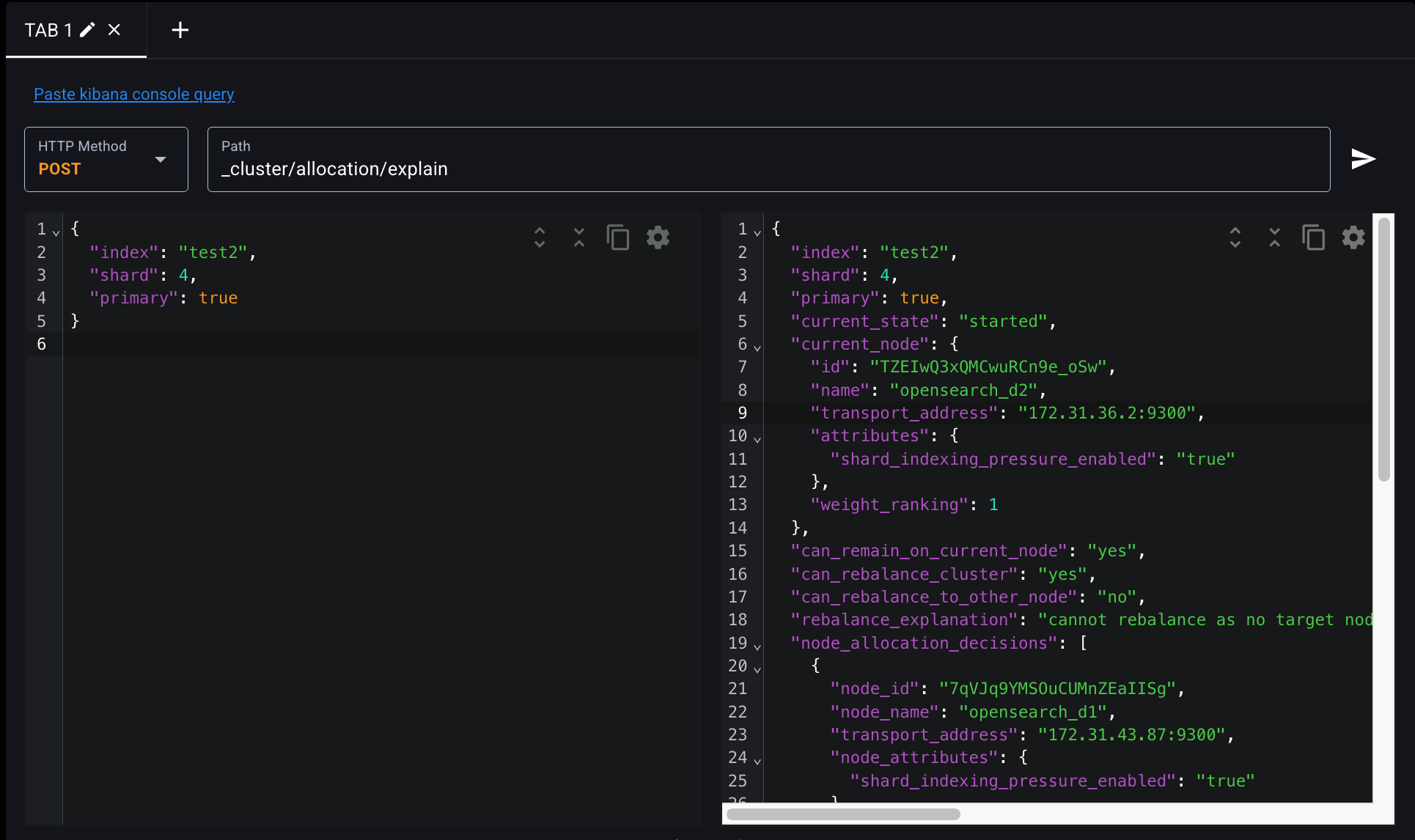
_cluster/allocation/explain{
"index": "test2",
"shard": 4,
"primary": true
}
문제
"rebalance_explanation": "cannot rebalance as no target node exists that can both allocate this shard and improve the cluster balance"
즉, 현재 프라이머리 shard 4는 opensearch_d2에 있고, 나머지 노드들은 이미 이 shard의 replica를 가지고 있기 때문에 옮길 수 있는 대상 노드가 없음.
각 노드 상황:
opensearch_d1: 이미 test2의 shard 4의 replica 존재 → 이동 불가
opensearch_d3: 동일하게 replica 존재 → 이동 불가
그러면 어떻게 해야되냐?!
아까 했던 것 처럼 리플리카 수를 조정해서 없애고
프라이머리 샤드 옮긴 뒤에 리플리카를 다시 생성하는 방법이 있다.
번거로우니test2 index 말고 test1 index에서
d2노드 에 있는 프라이머리샤드를 를 d3노드로 옮겨보도록 하자.
$ curl -XPOST "$OPENSEARCH_REST_API/_cluster/reroute?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"commands": [
{
"move": {
"index": "test1",
"shard": 0,
"from_node": "opensearch_d2",
"to_node": "opensearch_d3"
}
}
]
}
'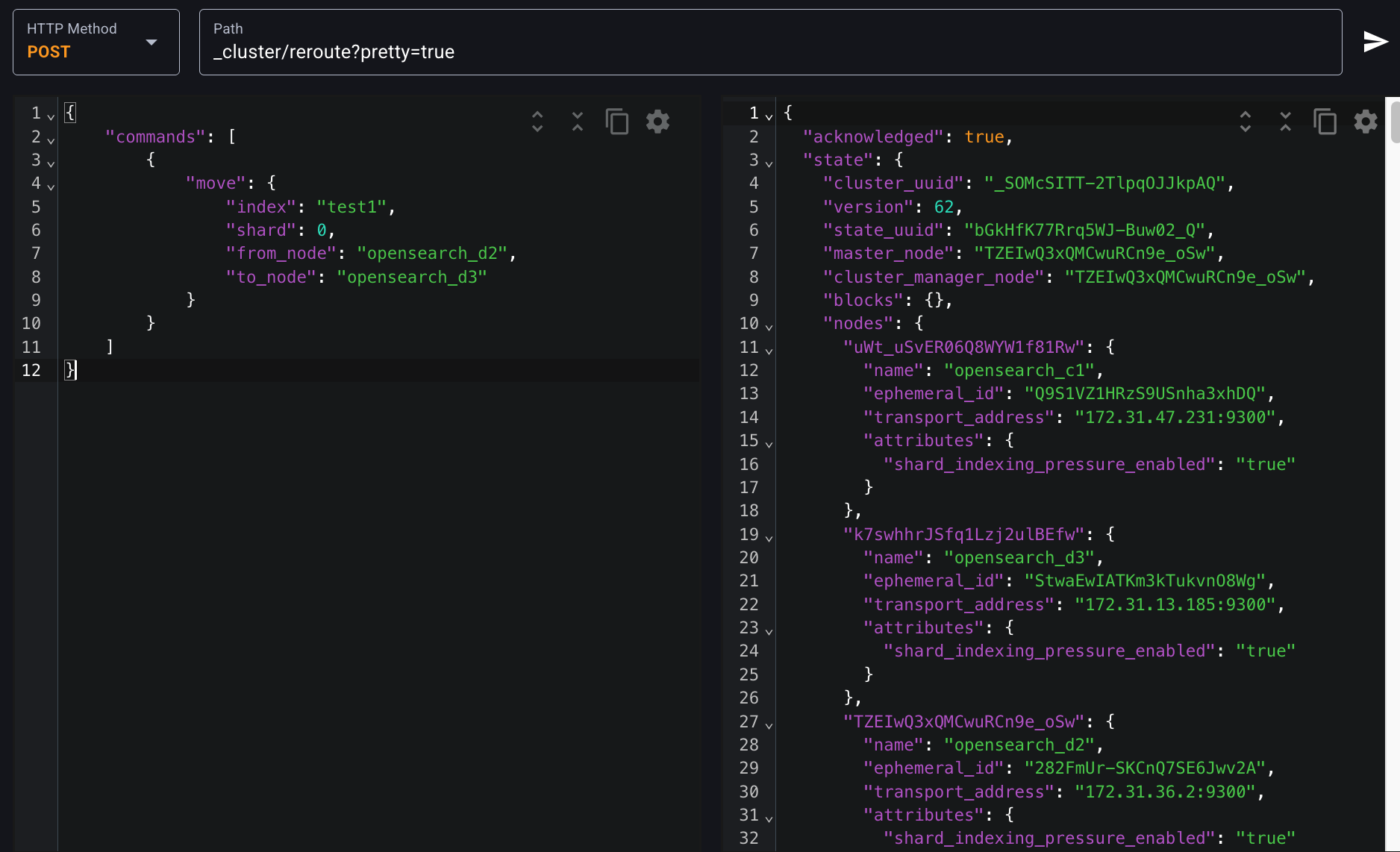
"acknowledged": true 나왔고,
응답 본문의 state.routing_table.indices.test1.shards.0을 보면 프라이머리 샤드가 relocating 상태로 바뀐 것을 확인할 수 있다.
[
{
"state": "RELOCATING",
"primary": true,
"node": "OpwmNmeiQSCd19yKmZfKfQ",
"relocating_node": "m0-xttC6SK6V7e34R5IOSw",
"shard": 0,
"index": "test1",
"expected_shard_size_in_bytes": 4327,
"allocation_id": {
"id": "y0nEcSbfSiGlXKPclHu7Hg",
"relocation_id": "pvTwn9XzRhyJpOt_x6SiZQ"
}
},
{
"state": "STARTED",
"primary": false,
"node": "2usKiujOSGSH5JwEYRFGrA",
"relocating_node": null,
"shard": 0,
"index": "test1",
"allocation_id": {
"id": "cxX3hEamRsGfFF95zhHoEg"
}
}
]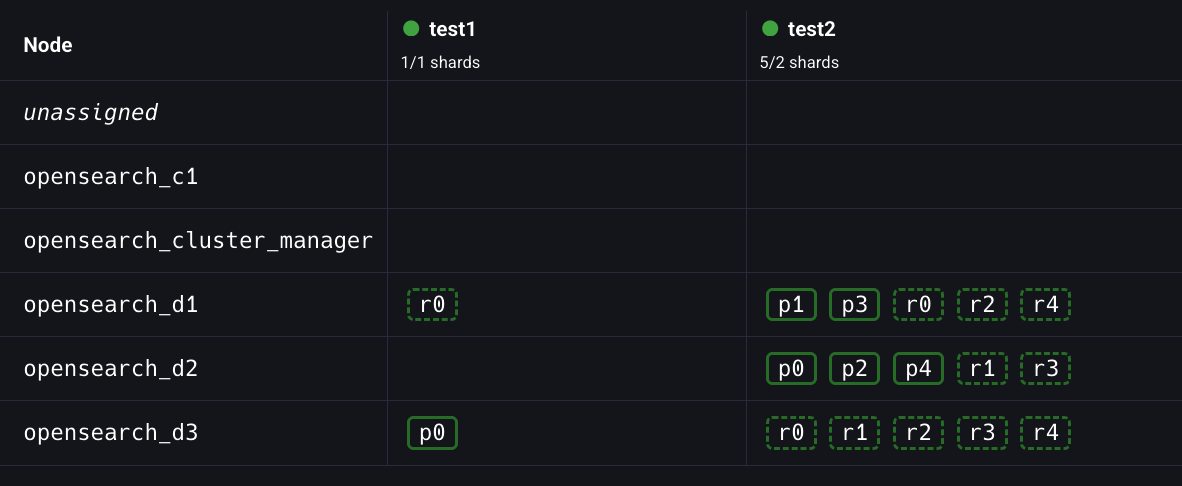
성공적으로 샤드가 재배치될 경우 샤드 상태는 started로 바뀐다.
replica shard를 지우고
index test2, d2 node의 p4도
d3 node로 이동시켜보자.

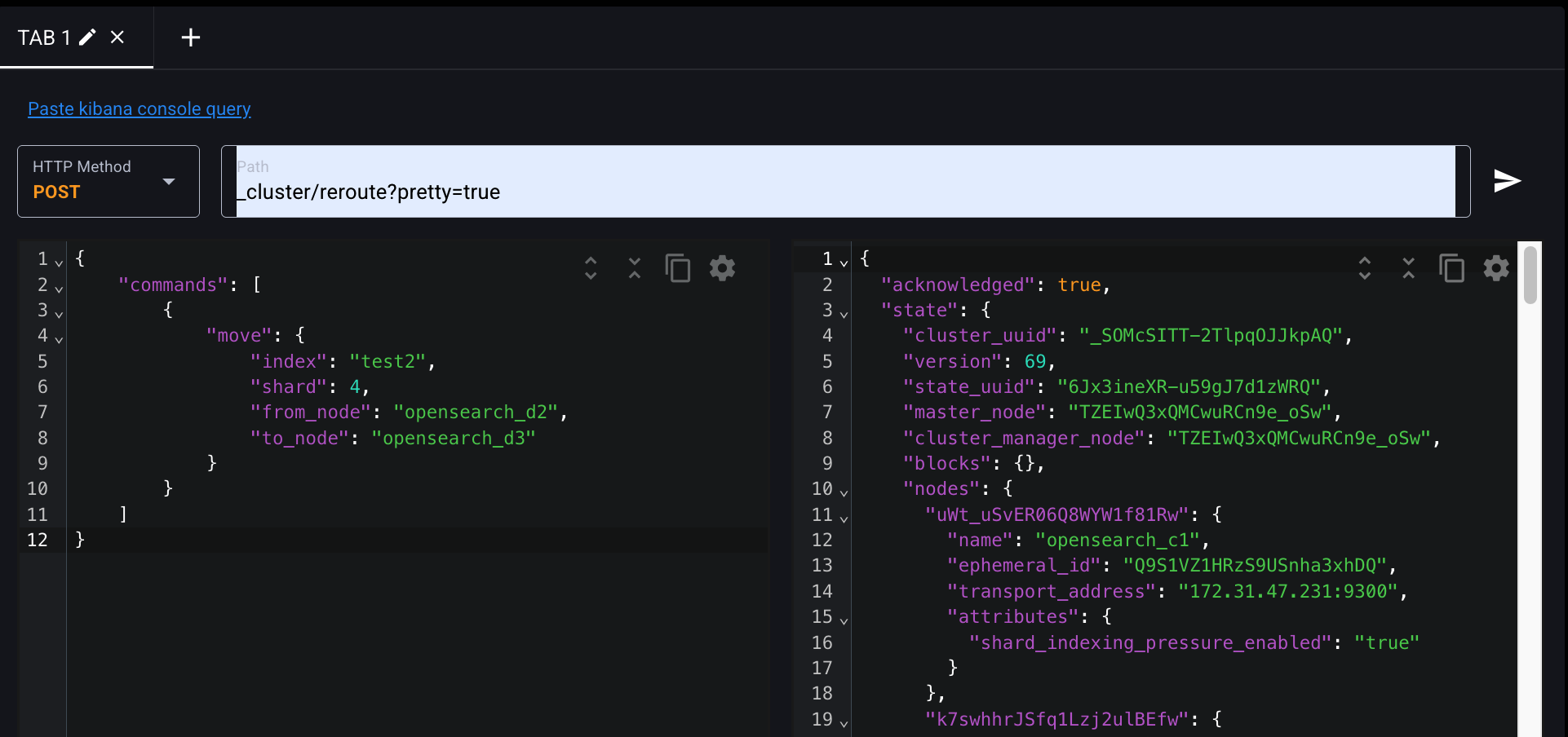
어? p0가 다시 d2로 이동했다.
OpenSearch의 자동 클러스터 재배치(logic) 또는 할당 실패 후 rollback 때문인데,
reroute 성공했지만 나중에 다시 할당되었거나 노드 리소스 상태나 replica 갱신 상태에 따라 다시 이동되는 경우가 있다.
특히 기본적으로 cluster.routing.allocation.enable = all 설정이 되어 있으면, 클러스터는 자율적으로 재밸런싱을 수행함.
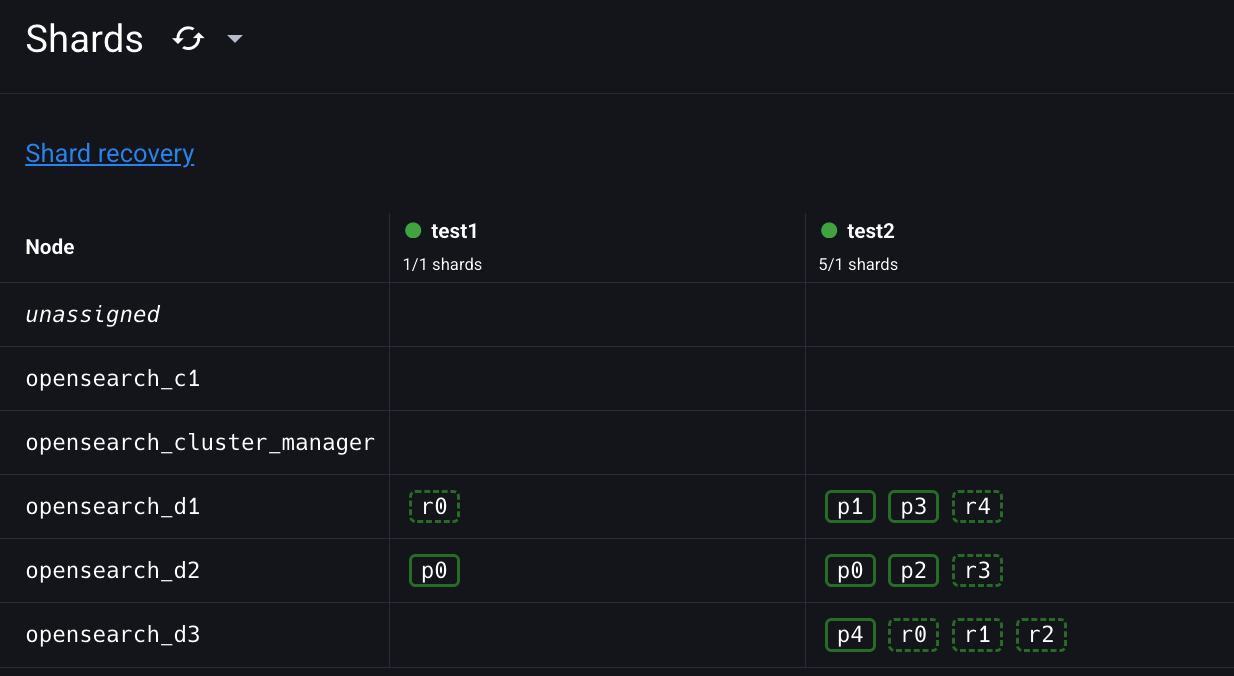
우리는 복제본을 두개씩 넣고 싶었으니까
다시 replica 개수를 두개로 만들고
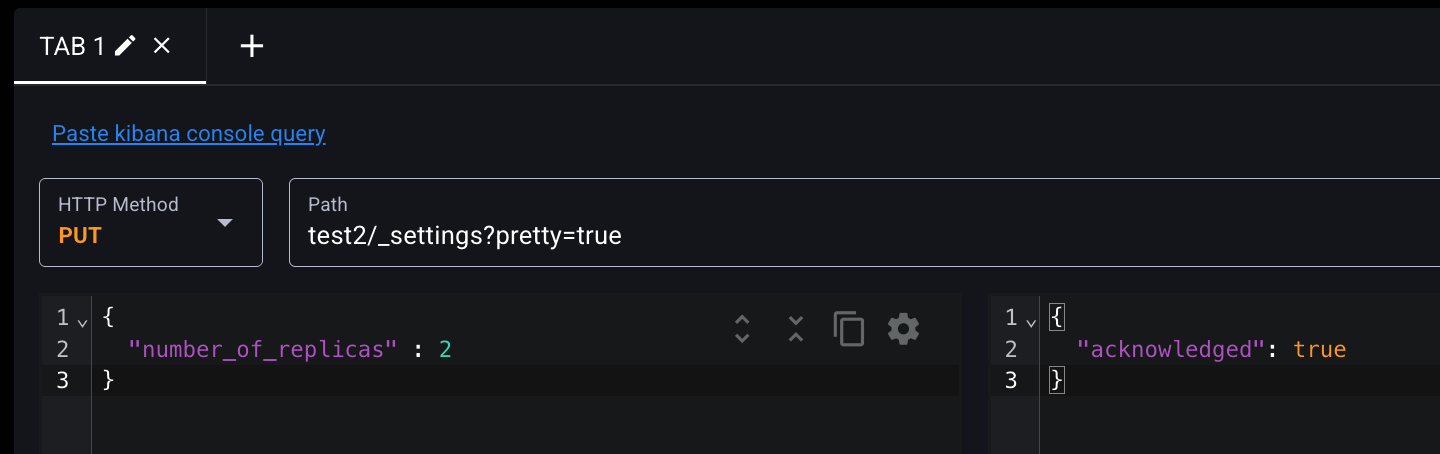
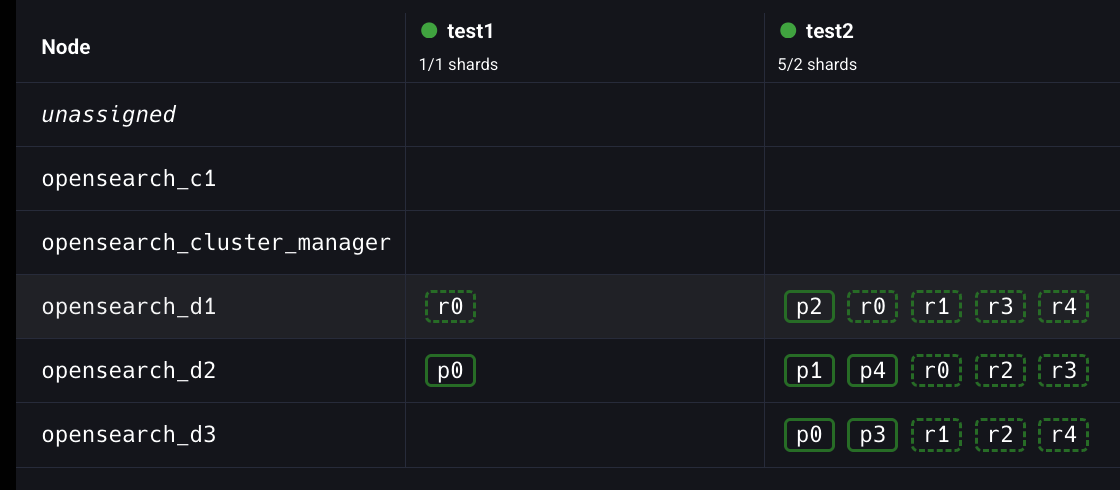
다음과 같이 Elasticvue에서 GUI 클릭으로 샤드를 재배치할 수도 있다.
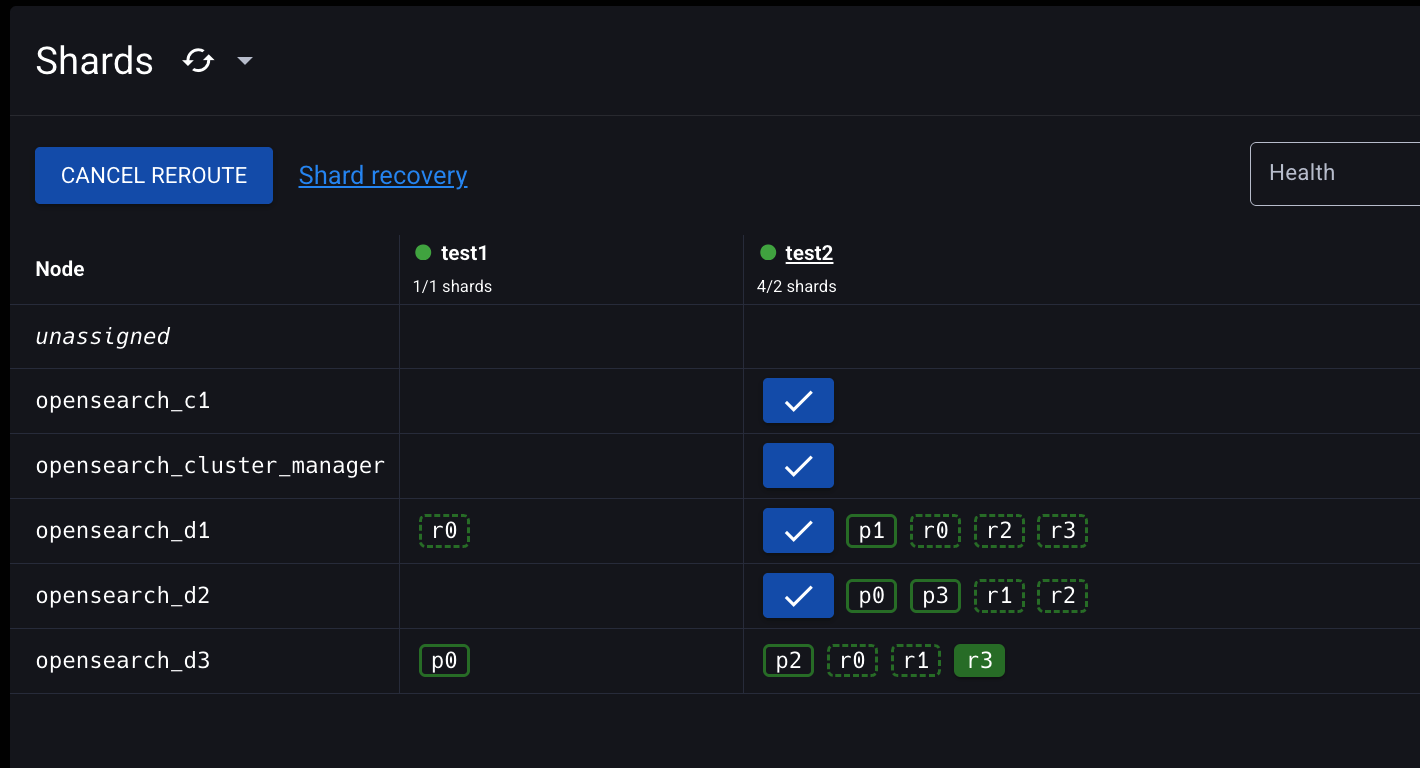
4.1.6 레플리카 샤드 승격(Shard promotion)
다음과 같은 상태에서 opensearch-d2 노드를 멈춰보자. EC2 인스턴스를 stop하거나, $ sudo systemctl stop opensearch.service를 실행하면 된다.
sudo systemctl stop opensearch.service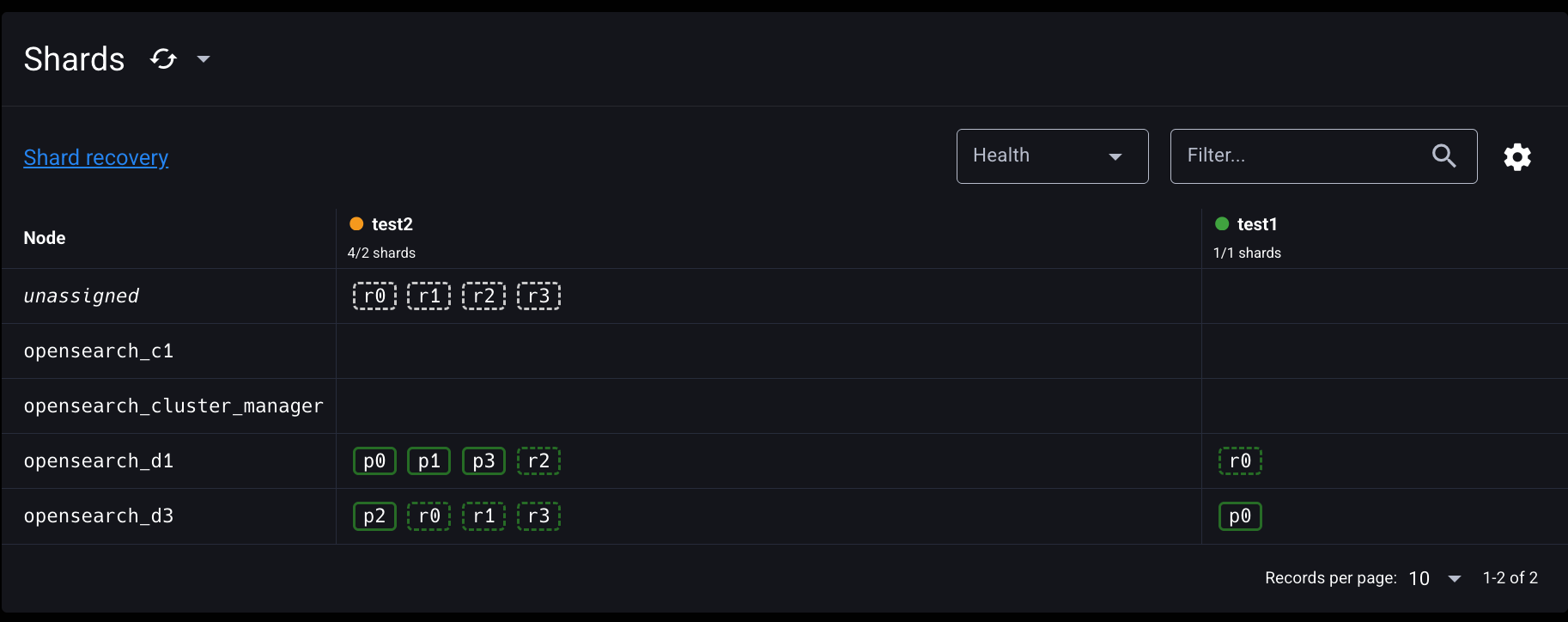
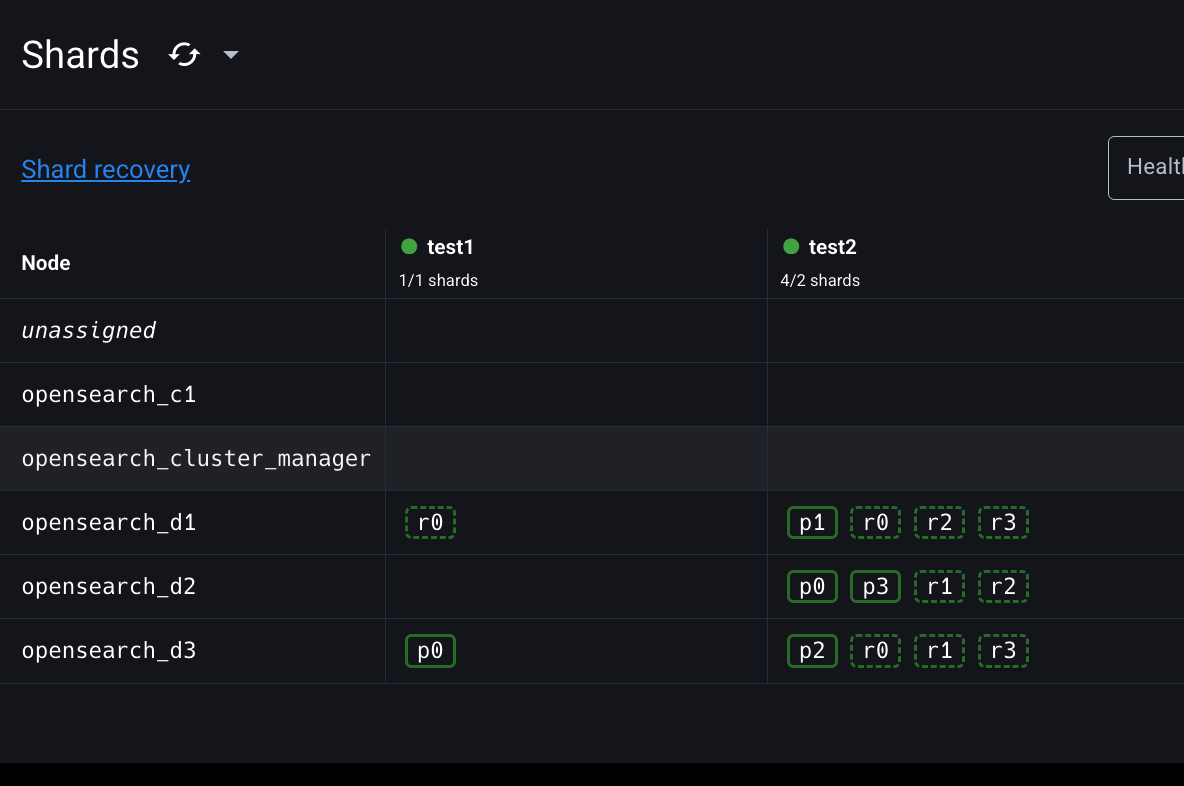
노드가 이탈한 즉시 opensearch-d3의 레플리카 샤드 일부가 프라이머리 샤드로 승격된 것을 확인할 수 있다.
delayed_timeout 설정 때문에 unassigned 레플리카 샤드는 아직 재배치되지 않았다.
기본 delayed_timeout 설정대로 약 1분 정도 기다리면 test1 인덱스의 unassigned 레플리카 샤드가 opensearch-d3로 재배치된 것을 확인할 수 있다. test2 인덱스의 unassigned 레플리카 샤드는 노드 부족으로 인해 재배치되지 못했다.
opensearch-d2 노드를 클러스터에 복귀시켜보자.
sudo systemctl restart opensearch.servicetest2 인덱스의 unassigned 레플리카 샤드가 opensearch-d2 노드에 재배치된 것을 확인할 수 있다.
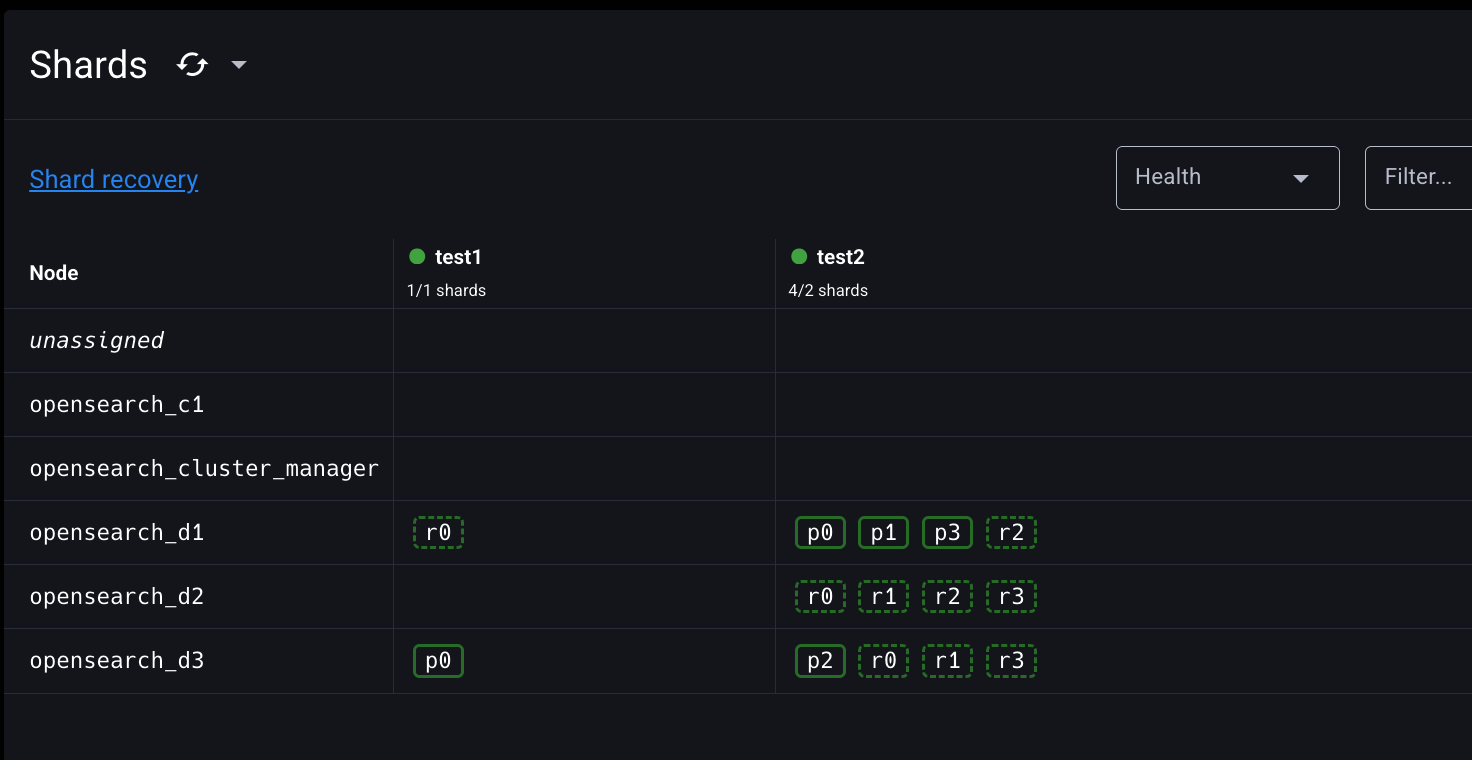
이번에는 opensearch-d3 노드를 멈추고, 1분 안에 클러스터에 복귀시켜보자.
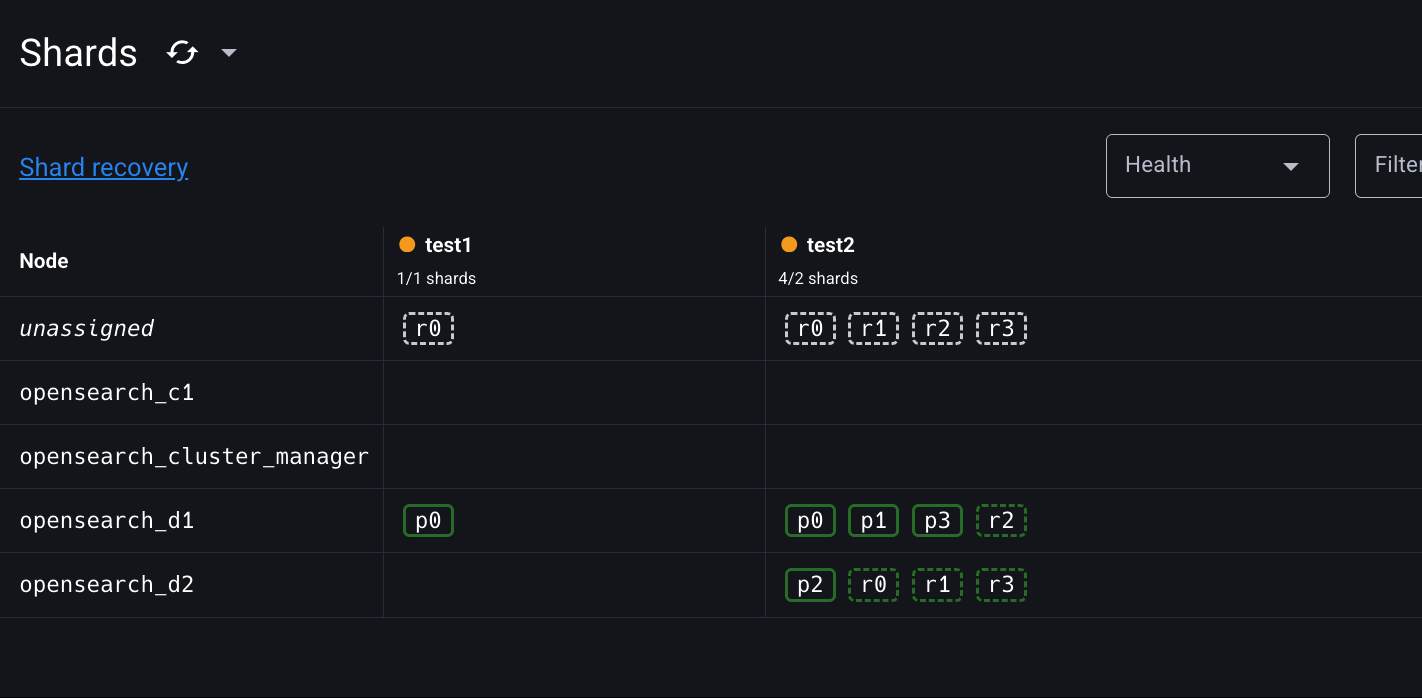
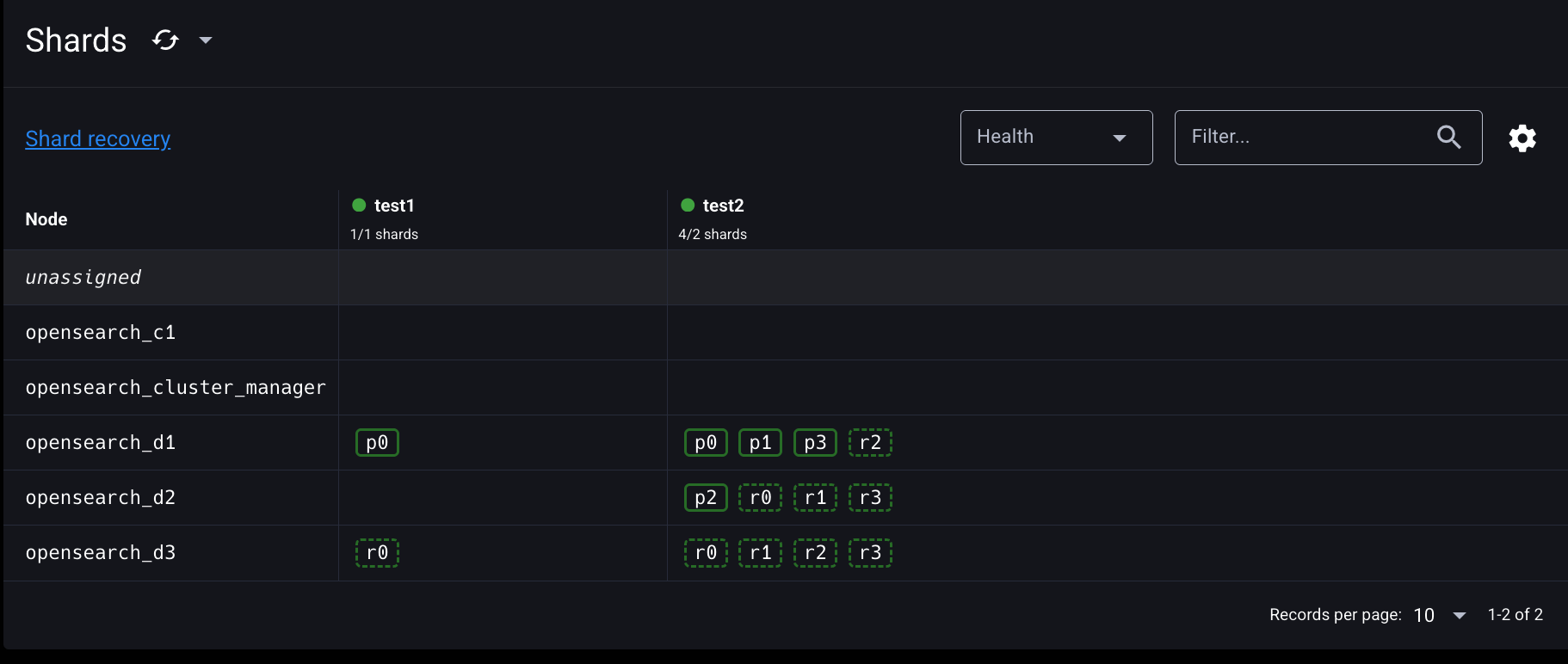
test1 인덱스의 unassigned 레플리카 샤드가 opensearch-d3 노드에 재배치된 것을 확인할 수 있다. opensearch-d3 노드에는 이미 test1 인덱스의 0번 샤드 정보가 디스크에 저장되어 있기 때문에 opensearch-d2 노드보다 더 빠르게 레플리카 샤드를 재배치할 수 있다.
