3.4 OpenSearch 클러스터 구성 실습
3.4.1 OpenSearch 클러스터 시각화 클라이언트
Elasticvue는 다음과 같은 기능을 제공하는 OpenSearch 클라이언트다.
- 클러스터, 노드, 샤드 상태 확인
- 인덱스 관리
- REST API 인터페이스
- 스냅샵 관리
크롬 확장 프로그램으로 쉽게 설치할 수 있고, 복잡한 환경 설정이 필요 없다는 장점이 있다. 다음 링크를 클릭해서 크롬 확장 프로그램에 추가하고, 실행해보자.
https://chrome.google.com/webstore/detail/elasticvue/hkedbapjpblbodpgbajblpnlpenaebaa
Elasticvue를 실행하면 다음과 같은 Setup 화면이 뜬다. Uri에 OpenSearch REST API 주소를 입력하고 CONNECT를 누르자.
다음과 같은 화면이 뜨면 연결에 성공한 것이다.
클러스터, 노드, 샤드 모니터링이 필요한 경우 Elasticvue를 활용해보자.
3.4.2 멀티 노드 클러스터 구성
챕터 1.1에서는 EC2 인스턴스 한 대로 싱글 노드 클러스터를 구성했었다. 챕터 3.4에서는 EC2 인스턴스 여러 대에 OpenSearch 인스턴스를 한 개씩 설치하여 멀티 노드 클러스터를 구성해 볼 것이다. EC2 인스턴스 한 대에 여러 개의 OpenSearch 인스턴스를 설치할 수도 있지만, OpenSearch에서 권장하는 방법은 아니다.
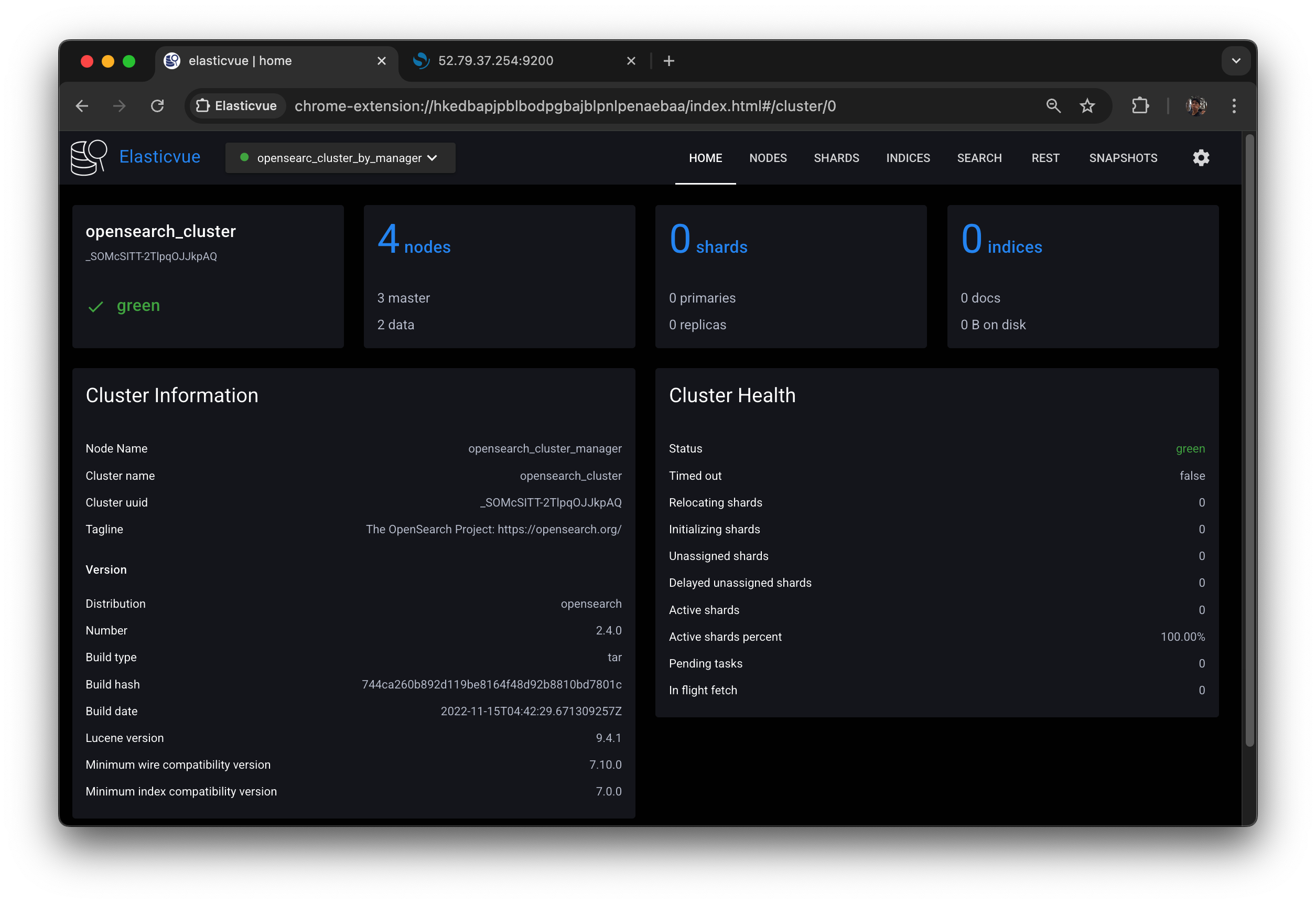
지금부터 다음과 같은 4노드 클러스터를 구성할 것이다.

출처: https://opensearch.org/docs/latest/opensearch/cluster/
- 클러스터 매니저 노드 1개 (전용 노드)
- 코디네이터 노드 1개 (전용 노드)
- 데이터 & 인제스트 노드 2개
4노드 클러스터를 구성하려면 EC2 인스턴스 4대가 필요하다. EC2 인스턴스 4개를 띄우고, 모든 인스턴스에 한 번씩 접속해서 OpenSearch를 설치하는 것은 번거로운 일이다. 반면 AMI를 활용하면 클릭 몇 번으로 OpenSearch가 미리 설치된 EC2 인스턴스를 시작할 수 있다. AMI는 EC2 인스턴스의 소프트웨어 구성이 정의된 템플릿이며, 기본적으로 EC2 인스턴스에 연결된 모든 EBS 볼륨의 상태도 같이 복제된다. 즉 AMI를 사용하면 특정 EC2 인스턴스와 똑같은 환경의 인스턴스를 시작할 수 있다.
- AMI 를 사용하기위한 베이스는
EFK로 서버 로그 수집하기 강의자료의 4.1.1~4.1.3 과 4.1.9 를 따라한다.- opensearch를 실행은 시키지 않는다.
⚠️ AMI 생성 전 EC2 인스턴스에서 $ sysctl vm.max_map_count로 vm.max_map_count가 262144 이상인지 확인하자. 만약 262144보다 작다면 <EFK로 서버 로그 수집하기>의 4.1.1-4.1.3를 참고해서 vm.max_map_count를 262144 이상으로 설정해줘야 한다. 챕터 1.1에서는 싱글 노드 클러스터로 실습했기 때문에 선택 사항이었지만, 멀티 노드 클러스터의 경우 vm.max_map_count를 262144 이상으로 설정해주지 않으면 다음과 같은 에러 메시지를 띄우면서 bootstrap check가 실패하게 된다. (멀티 노드 클러스터 기능을 사용할 경우 프로덕션 레벨의 OpenSearch 인스턴스로 간주되기 때문)
ERROR: [2] bootstrap checks failed
[1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
⚠️ AMI 생성 전 EC2 인스턴스에서 $ rm -rf $OPENSEARCH_HOME/data/nodes/*를 실행해서 OpenSearch 데이터를 초기화해야 한다. 해당 경로에는 같은 EC2 인스턴스 안에서 클러스터링된 모든 노드의 정보가 저장되어 있으며, OpenSearch는 데이터 경로를 지정하지 않는 이상 기본적으로 $OPENSEARCH_HOME/data/nodes/0에 노드 정보를 저장한다. 데이터 경로에는 노드 ID 정보가 저장되어 있기 때문에 서로 다른 노드가 같은 데이터 경로를 바라볼 경우 ID 충돌이 발생한다.
EC2 콘솔에서 OpenSearch가 설치된 EC2 인스턴스를 선택하고 (한국어 콘솔의 경우) 우측 상단의 작업 → 이미지 및 템플릿 → 이미지 생성 버튼을 눌러 AMI를 생성하자. AMI는 생성 요청 후 사용 가능 상태로 바뀌기까지 약 5~10분 가량의 시간이 걸린다.
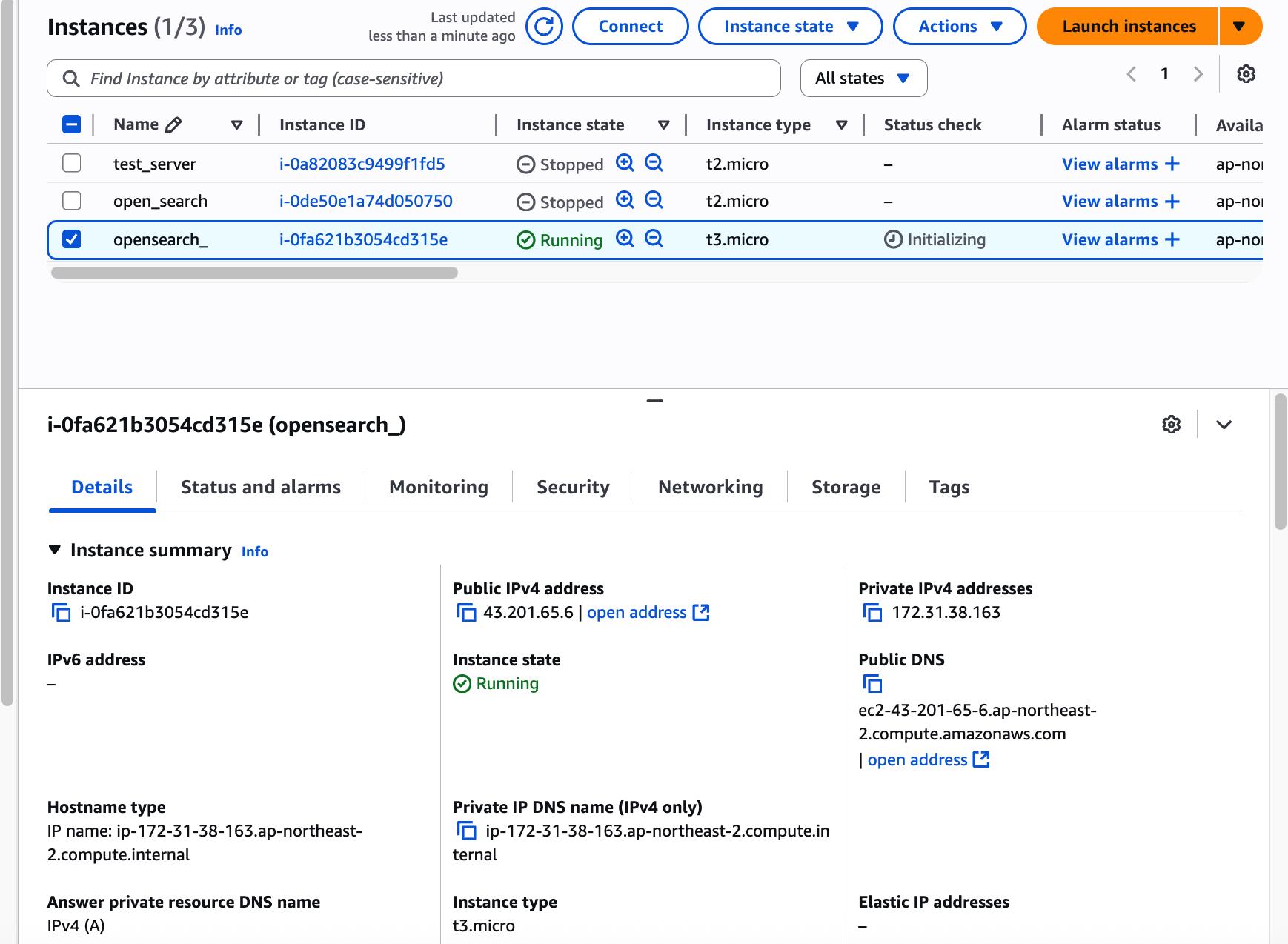
인스턴스 하나 생성하자
sudo apt update
sudo apt install build-essential -y# x64
wget https://artifacts.opensearch.org/releases/bundle/opensearch/2.4.0/opensearch-2.4.0-linux-x64.tar.gz
# ARM64
wget https://artifacts.opensearch.org/releases/bundle/opensearch/2.4.0/opensearch-2.4.0-linux-arm64.tar.gz# x64
tar -xvf opensearch-2.4.0-linux-x64.tar.gz
# ARM64
tar -xvf opensearch-2.4.0-linux-arm64.tar.gzcd opensearch-2.4.0.profile 에 저장해서 꺼져도 설정 사라지지 않도록 해주자.
echo 'export OPENSEARCH_HOME=/home/ubuntu/opensearch-2.4.0' >> ~/.profile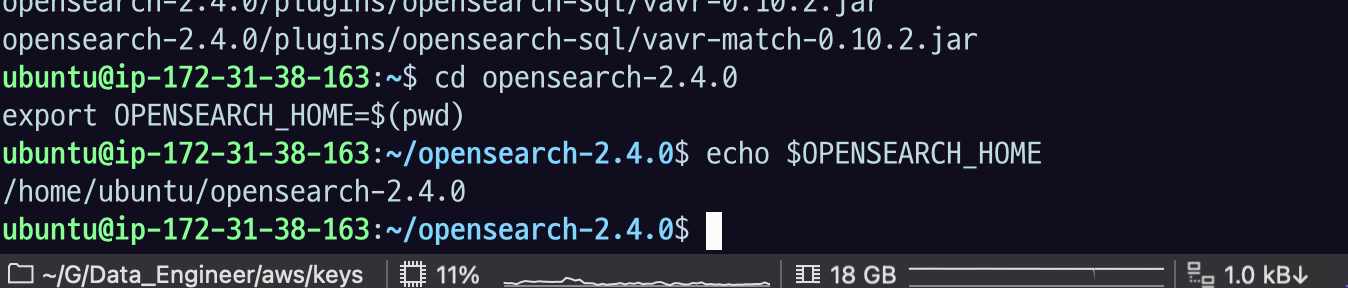
important system settings
- Disable memory paging and swapping performance on the host to improve performance.
sudo swapoff -aEdit the sysctl config file
sudo vi /etc/sysctl.confIncrease the number of memory maps available to OpenSearch.
# Add a line to define the desired value
# or change the value if the key exists,
# and then save your changes.
vm.max_map_count=262144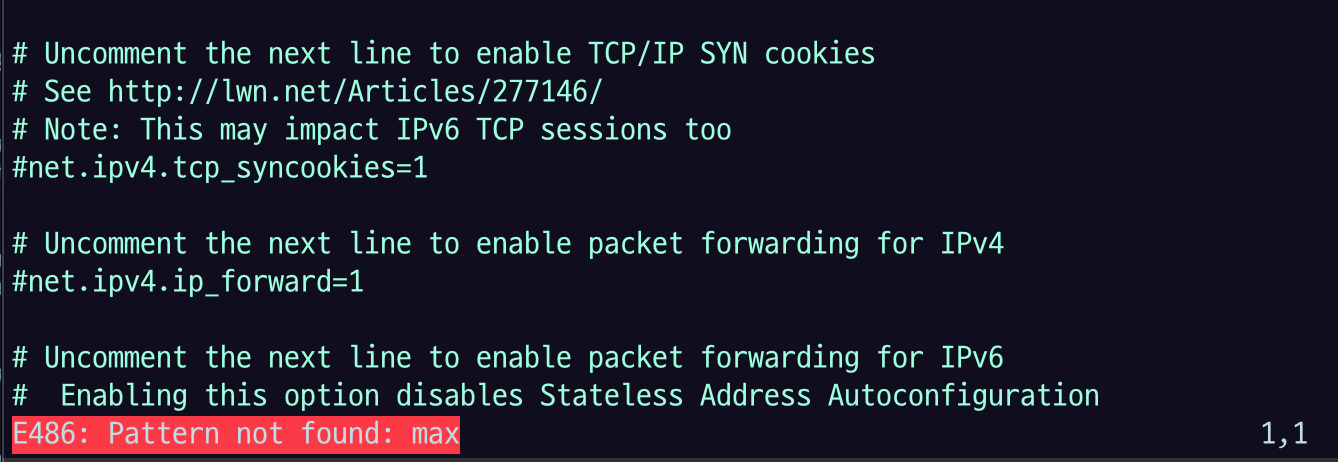
/ max 검색으로 max 관련 설정 있는지 확인해보고 없으니까 마지막에 붙여 넣자
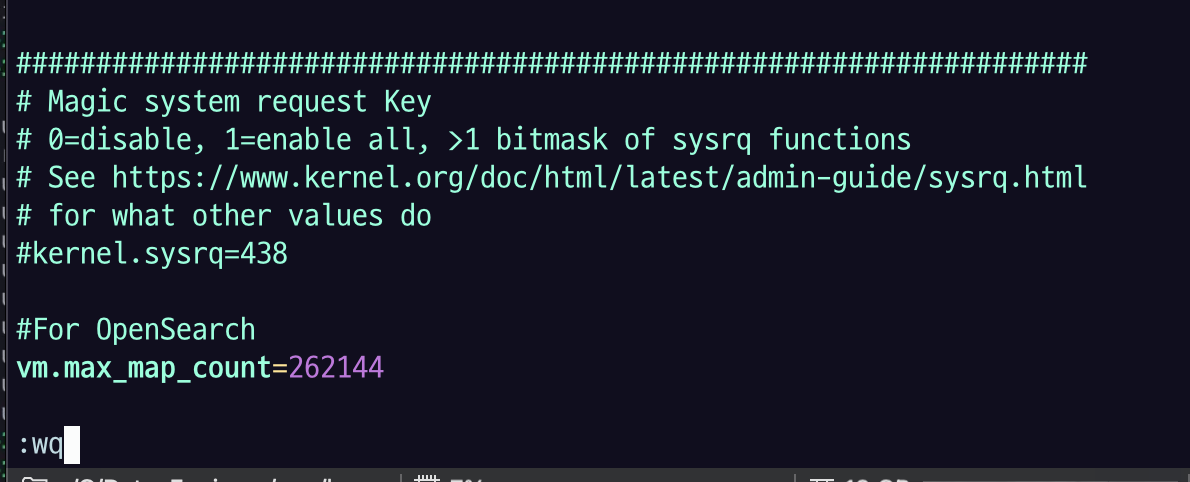
저장을 한 뒤에 sysctl -p 로 적용을 하자.
Reload the kernel parameters using sysctl
sudo sysctl -p
Verify that the change was applied by checking the value
cat으로 마지막 확인을 하면 잘 나오는 것을 확인할 수 있다.
cat /proc/sys/vm/max_map_count
여기까지 세팅이 완료 되었다면 실행을 하지 않고,
.yaml도 그대로 두고, plugin도 그대로 두고.
systemctl로 들어가서 systemctl 파일 만드는 것 까지만 한다.
systemctl 로 system service 로 등록하기
설정파일
sudo vi /etc/systemd/system/opensearch.service
들어가면 아무 것도 없다.
아래 내용 복붙.
[Unit]
Description=OpenSearch
Wants=network-online.target
After=network-online.target
[Service]
Type=forking
RuntimeDirectory=data
WorkingDirectory=$YOUR_OPENSEARCH_HOME
ExecStart=$YOUR_OPENSEARCH_HOME/bin/opensearch -d
User=$YOUR_USER
Group=$YOUR_USER
StandardOutput=journal
StandardError=inherit
LimitNOFILE=65535
LimitNPROC=4096
LimitAS=infinity
LimitFSIZE=infinity
TimeoutStopSec=0
KillSignal=SIGTERM
KillMode=process
SendSIGKILL=no
SuccessExitStatus=143
TimeoutStartSec=75
[Install]
WantedBy=multi-user.target붙여넣기 저장한 뒤에 vi 편집기에서 잠시 나와서

pwd 주소 저장해두고
$YOUR_OPENSEARCH_HOME 을 아까 저장한 pwd 주소로 수정해주자.
User, Group도 바꿔주고.
:%s/$YOUR_USER/ubuntu/g
저장하고 나오자.
등록
sudo systemctl daemon-reloadsudo systemctl enable opensearch.service
이 상태로 실행하지 않고 AMI 설정하는 걸로 넘어가자.
AMI 설정
AWS EC2 로 넘어와서 방금 만든 EC2 인스턴스가 있는 화면으로 가보자.
인스턴스 선택하고
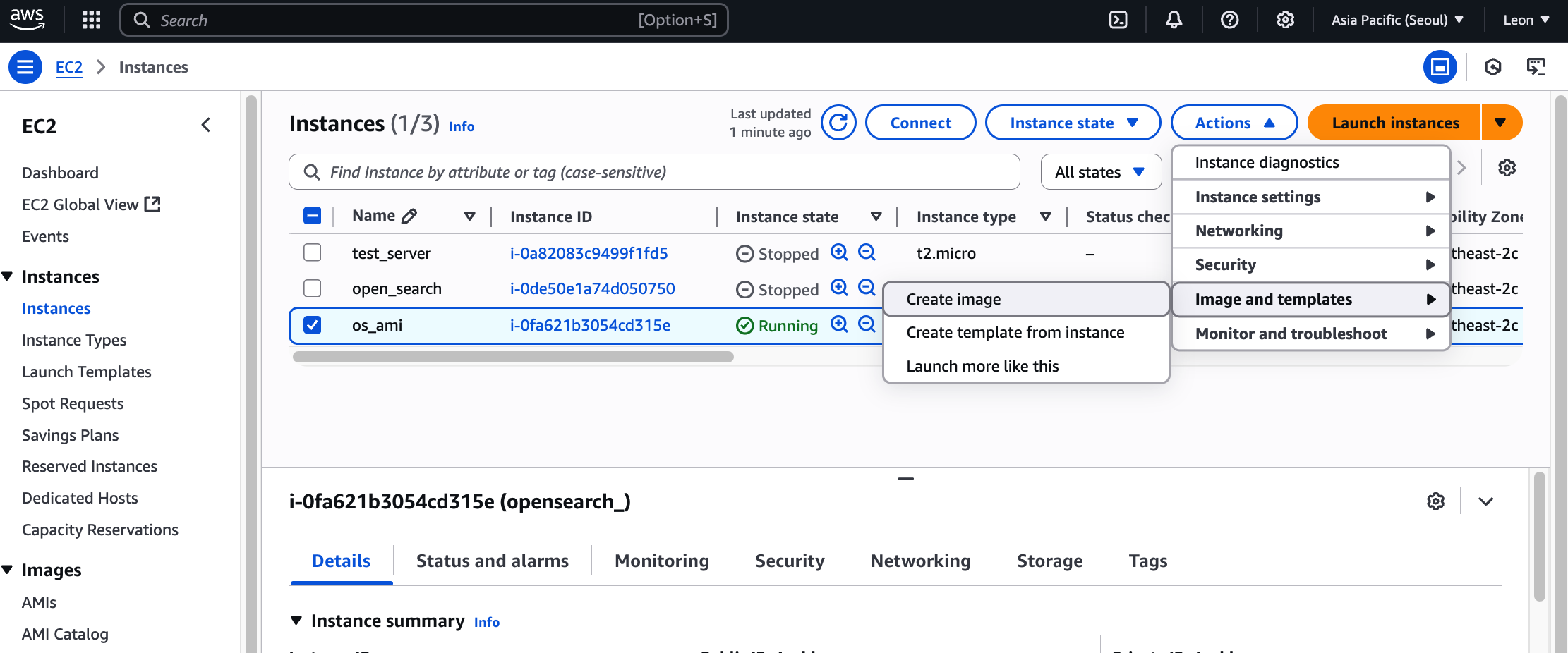
Actions > Image and templates > Create image 클릭
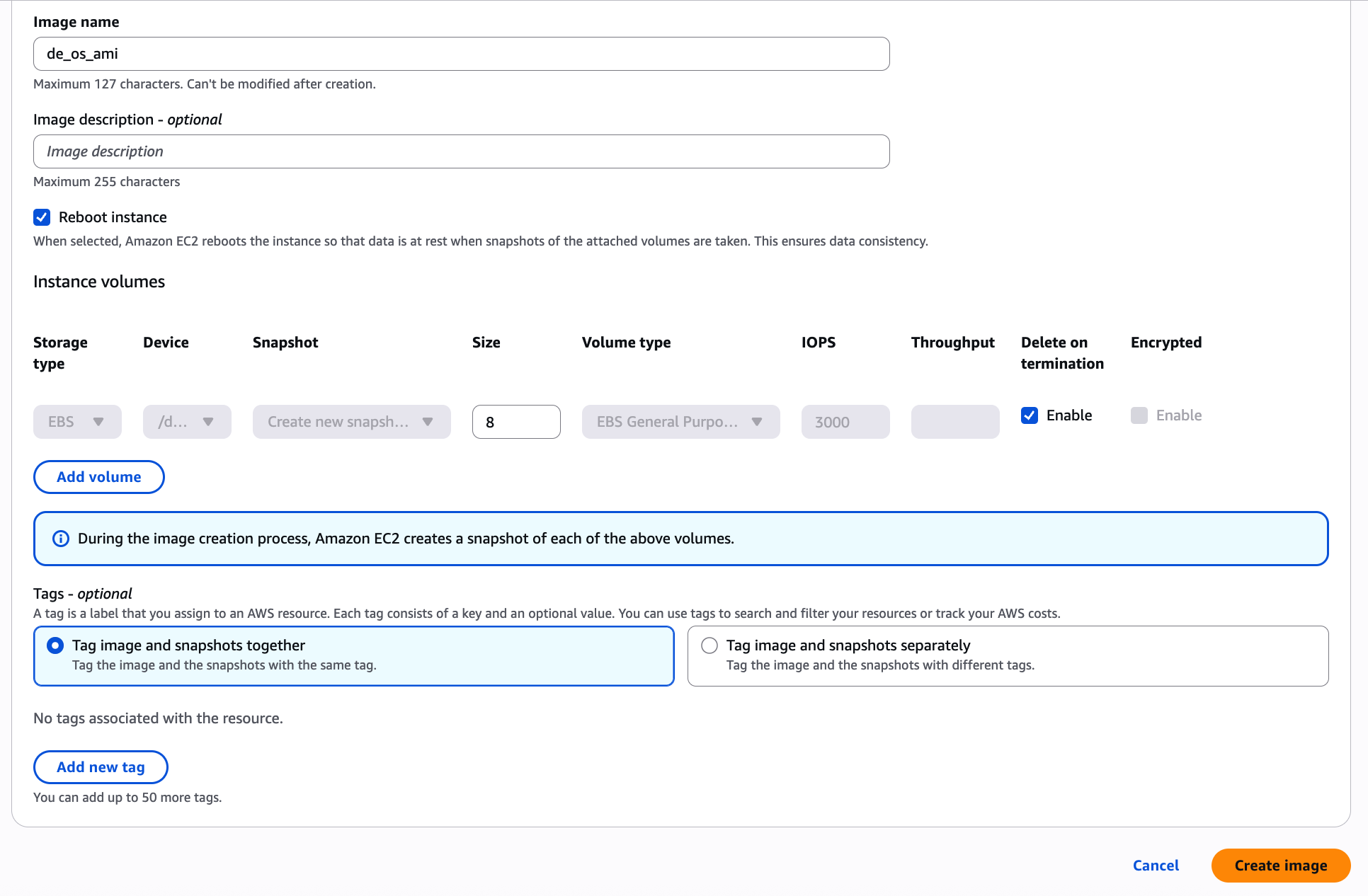
AMI 이름 설정하고
볼륨설정은 따로 할 수 있지만 수정 x
Create image 클릭.

Available 상태인지 확인해야 한다고 함.
확인하려면
Images > AMIs 로 이동해서 확인해보면
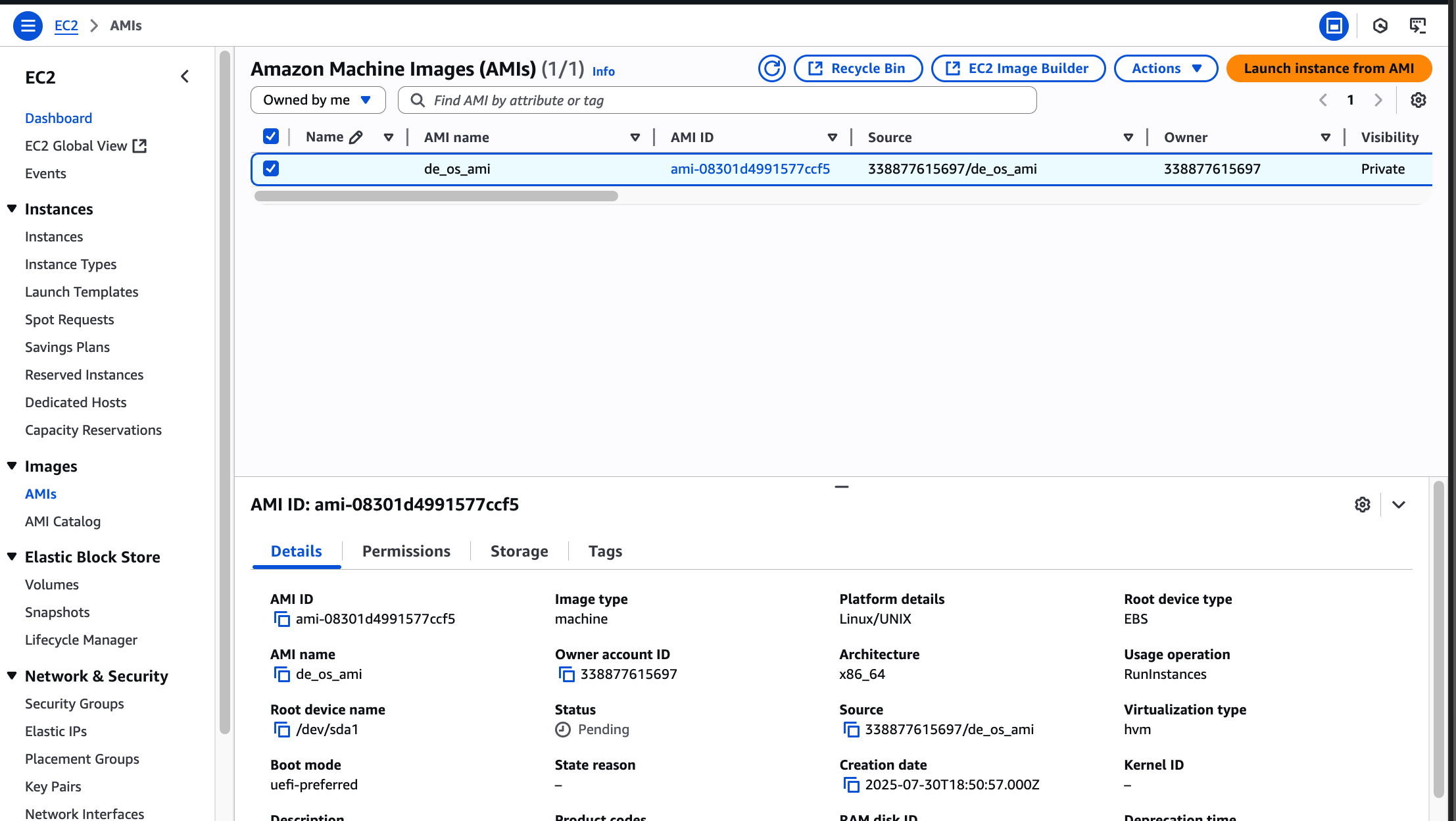
아직 pending 상태이다.
현재 컴퓨터 스냅샷 뜨고 파일 만들어야 하니까 시간이 좀 걸린다.
Available 상태로 바뀌면
Launch instance from AMI 클릭.
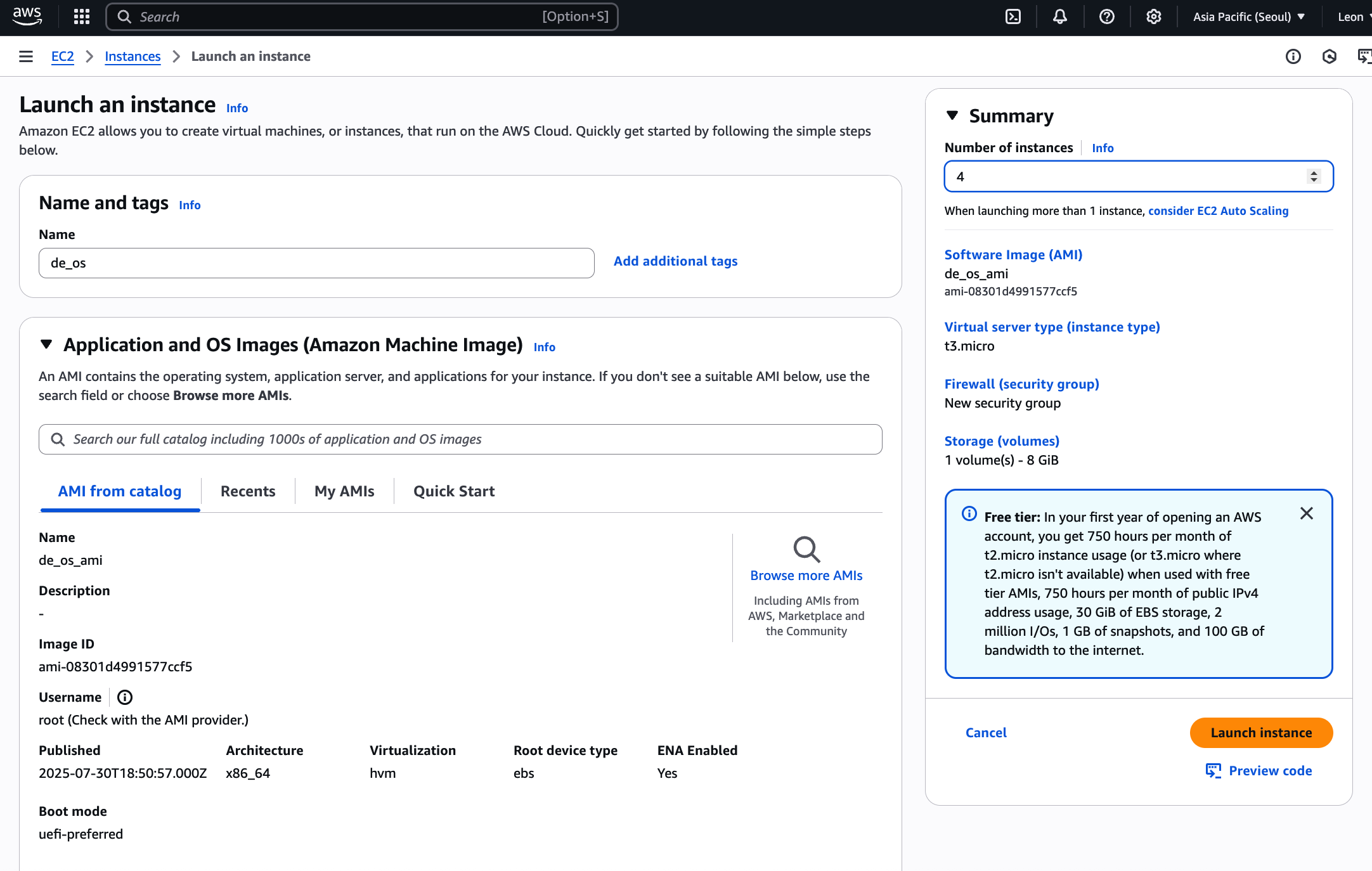
이름 적어주고 Number of Instance는 4개로 지정해주자.
방금 만든 인스턴스로 나중에 다시 만들어야 할 수도 있으니까 그대로 두자.
인스턴스는 t3.micro 로 선택함.
나머지 key pair 나 네트워크 세팅은 내 환경에 맞게 하던 대로 하면 된다.
세팅이 전부 완료되었다면
Launch Instance 클릭해 인스턴스들을 만들어주자.
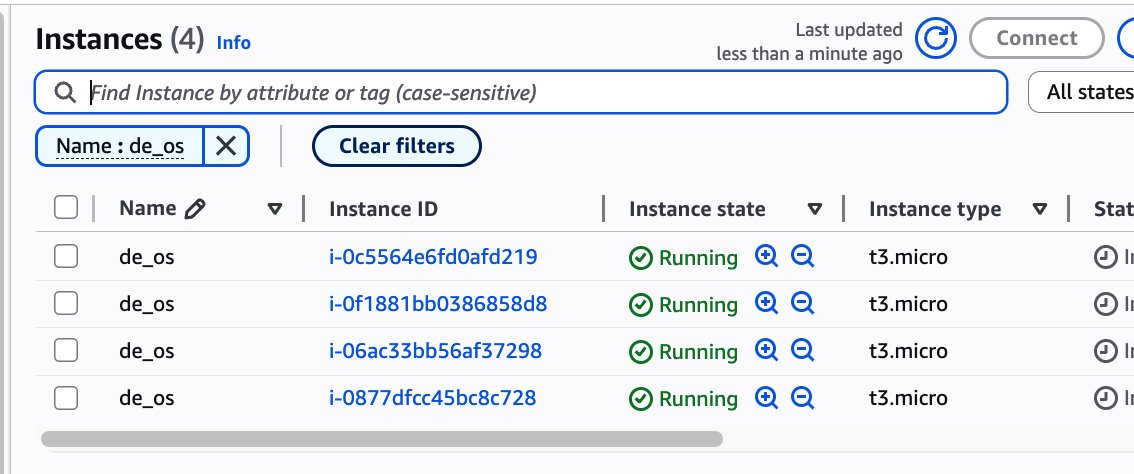
name 으로 필터링해서 보면 잘 만들어진 것을 볼 수 있다
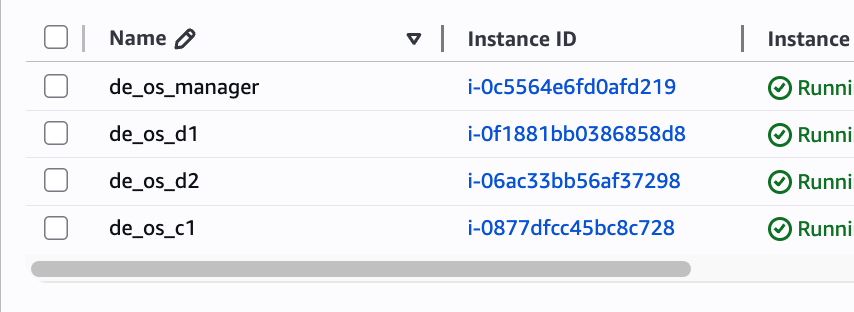
헷갈리지 않도록 인스턴스 이름에 노드 타입을 추가해주자.
모든 인스턴스 대상으로 OpenSearch config를 수정해줘야 한다. config 파일 경로는 다음과 같다.
vi $OPENSEARCH_HOME/config/opensearch.ymlconfig에는 다음 속성 값을 수정해주면 된다.
cluster.name: 클러스터 이름- 클러스터 이름을 지정하지 않을 경우 opensearch라는 이름으로 클러스터가 생성된다. 프로덕션 환경에서는 클러스터 이름을 지정해주는 것이 좋다. 프로덕션과 동일한 네트워크에서 노드를 개발하다 실수로 프로덕션 클러스터에 해당 노드를 가입시킬 수 있기 때문이다. 네트워크를 분리해서 개발하는 것이 가장 좋겠지만, 혹시 모를 상황에 대비하는 것이 좋다.
node.name: 노드 이름node.roles: 노드 타입network.host: 노드의 IP 주소discovery.seed_hosts: 클러스터에 속한 클러스터 매니저 또는 후보 노드의 IP 주소 목록- 노드가 처음 실행될 때
discovery.seed_hosts에 설정된 IP 주소로 클러스터 매니저 또는 후보 노드를 찾고, 해당 노드를 클러스터로 바인딩하는 과정을 디스커버리라고 한다. - IP 주소로 노드를 찾았을 때 클러스터 이름이 일치하지 않거나 찾은 노드가 클러스터 매니저 또는 후보 노드가 아닐 경우 다른 IP 주소로 디스커버리 과정을 반복한다.
- 노드가 처음 실행될 때
cluster.initial_cluster_manager_nodes: 클러스터를 맨 처음 실행할 때, 최초로 뜨는 node.name 최초로 기동하는 cluster_manager 서버가 자기 자신의 node.name 을 입력하면 된다.
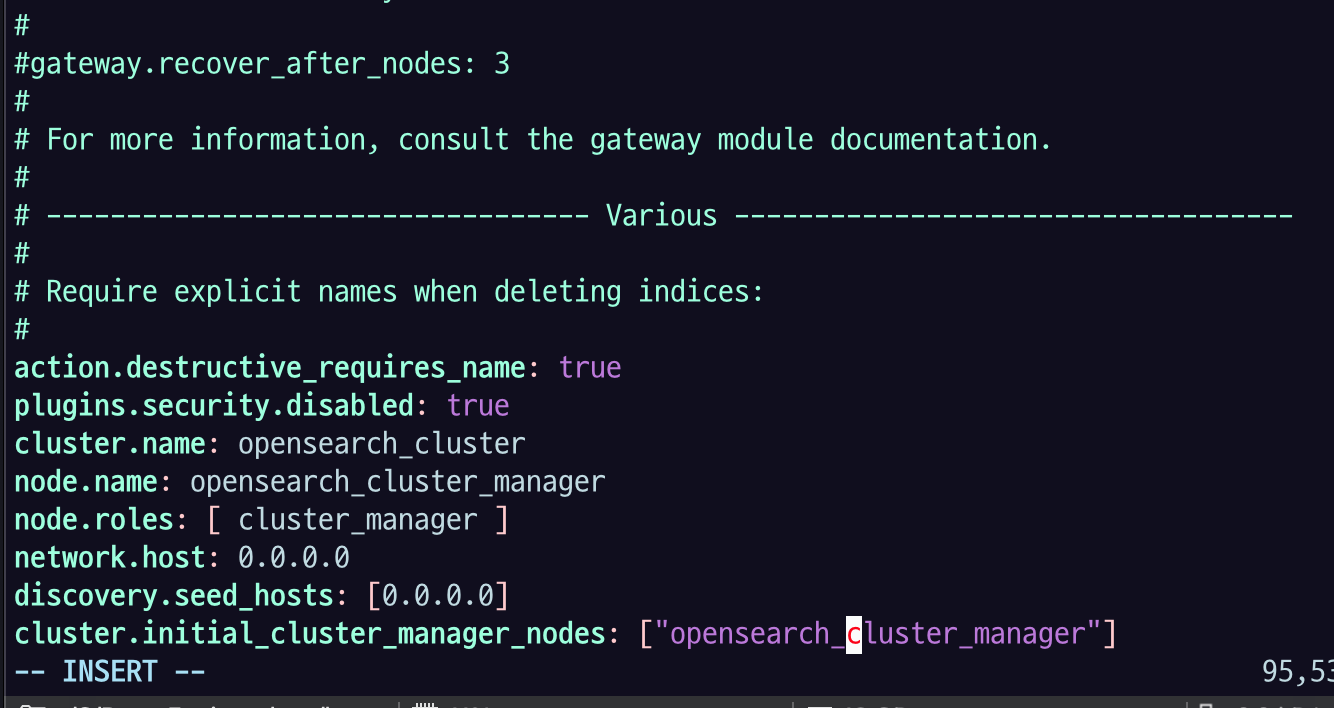
de-opensearch-cluster-practice_manager EC2 인스턴스에 접속해서 다음과 같이 OpenSearch config를 수정하고 $ sudo systemctl restart opensearch.service로 OpenSearch 노드를 재시작하자.
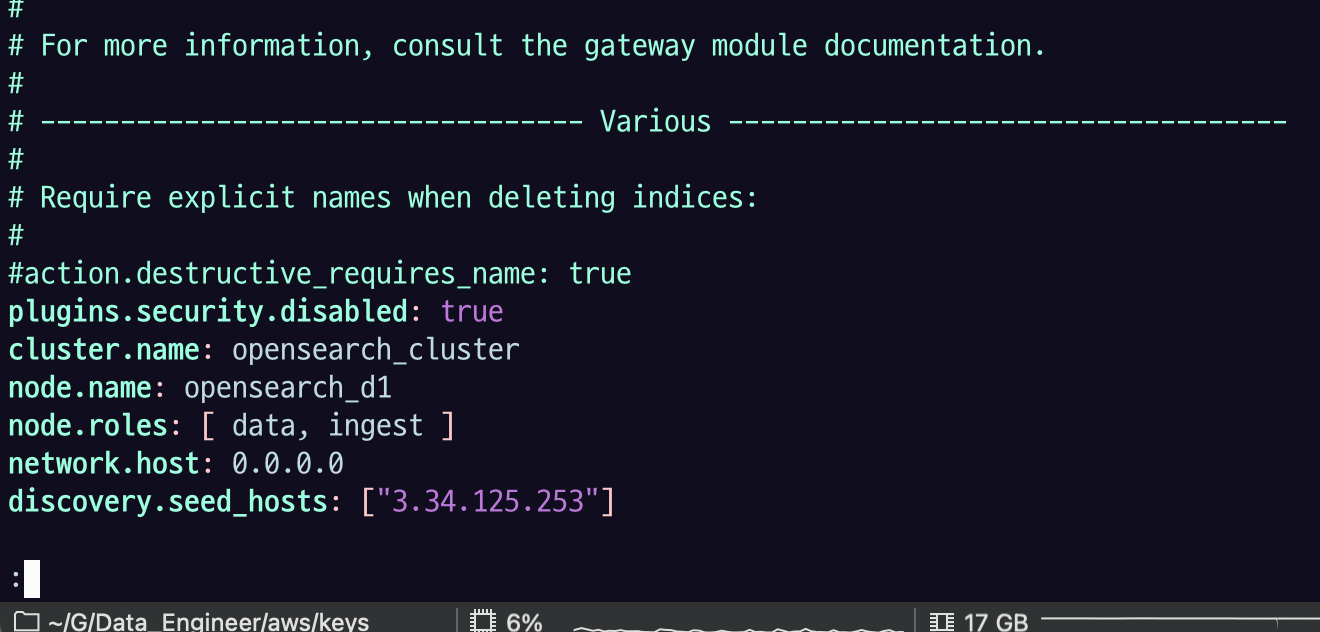
plugins.security.disabled: true
cluster.name: opensearch_cluster
node.name: opensearch_cluster_manager
node.roles: [ cluster_manager ]
network.host: 0.0.0.0
discovery.seed_hosts: [0.0.0.0]
cluster.initial_cluster_manager_nodes: ["opensearch_cluster_manager"]plugins.security.disabled: true : 세큐리티 설정 안하겠다는 건데, 세큐리티 관련 플러그인들을 지웠다면 이 줄을 주석 처리 해줘야 함.
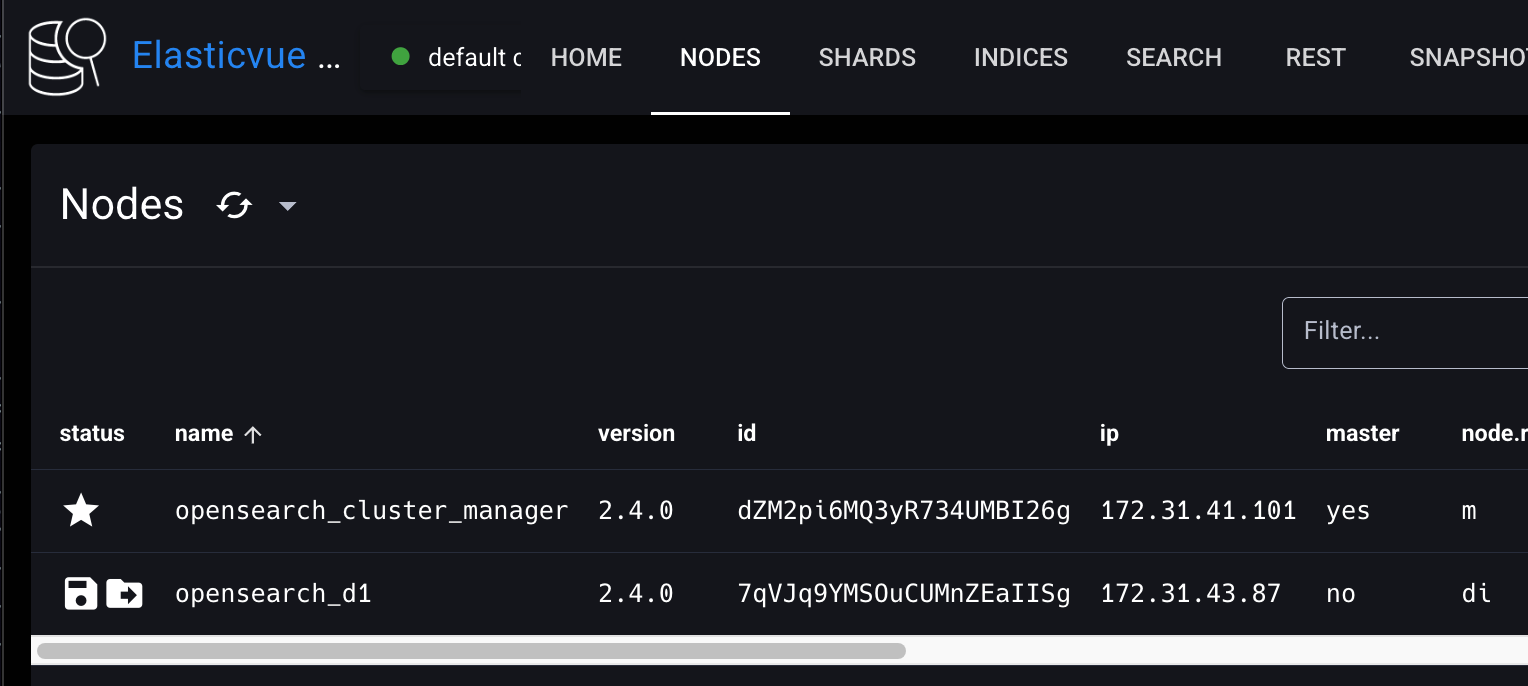
Elasticvue에 클러스터 매니저 노드를 연결하고 NODES 탭을 클릭해보자. 클러스터에 opensearch_cluster_manager 노드가 바인딩된 것을 확인할 수 있다.
discovery.seed_hosts : 매니저에 디스커버리 시드 호스트 넣는다고 했는데 자기 자신이니까 0.0.0.0
cluster.initial_cluster_manager_nodes : 이니셜 클러스터 노드의 이름을 넣어줘야 함. 자기 자신에 대해서 시드로 갖고 자신 매니저 노드 이름을 찾는다.
sudo systemctl restart opensearch.service근데 오류남 ㅠㅠ
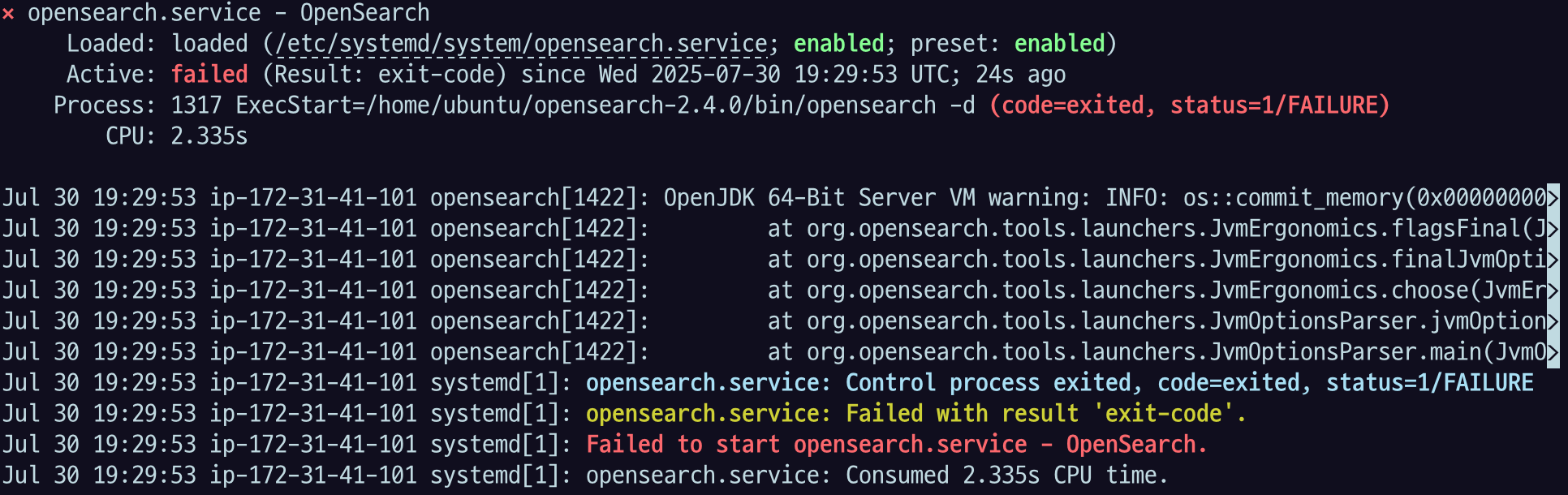
이 에러는 보통 JVM 힙 메모리 설정이나 시스템 메모리 부족 관련 문제인데
해결 방법 : OpenSearch의 JVM 메모리 설정 줄이기 를 시도해보았다.
OpenSearch의 JVM 힙 설정 파일 편집:
vim config/jvm.options기본값이 -Xms1g,-Xmx1g 로 설정되어 있었는데,
-Xms668m,-Xms668m 로 수정하고
sudo systemctl restart opensearch.service로 opensearch 재실행 해주면 됨!
돌리면 돌아는 가는데.. 너무너무 느려졌다.
하다보니까 EC2 type을 바꿔야 겠다 싶음
당장 EC2 설정 바꿔야겠다는 생각이 들었다. 너무 너무 느려서 뭘 할 수가 없는 상태가 되어 버렸다.
- 모든 인스턴스를
t3.micro에서t3.small로 바꿨다.
원래는 t3.small (2GB RAM) 이상 또는 t3.medium (4GB) 이상의 인스턴스를 쓰는 것이 좋다.
tail -f logs/opensearch_cluster.log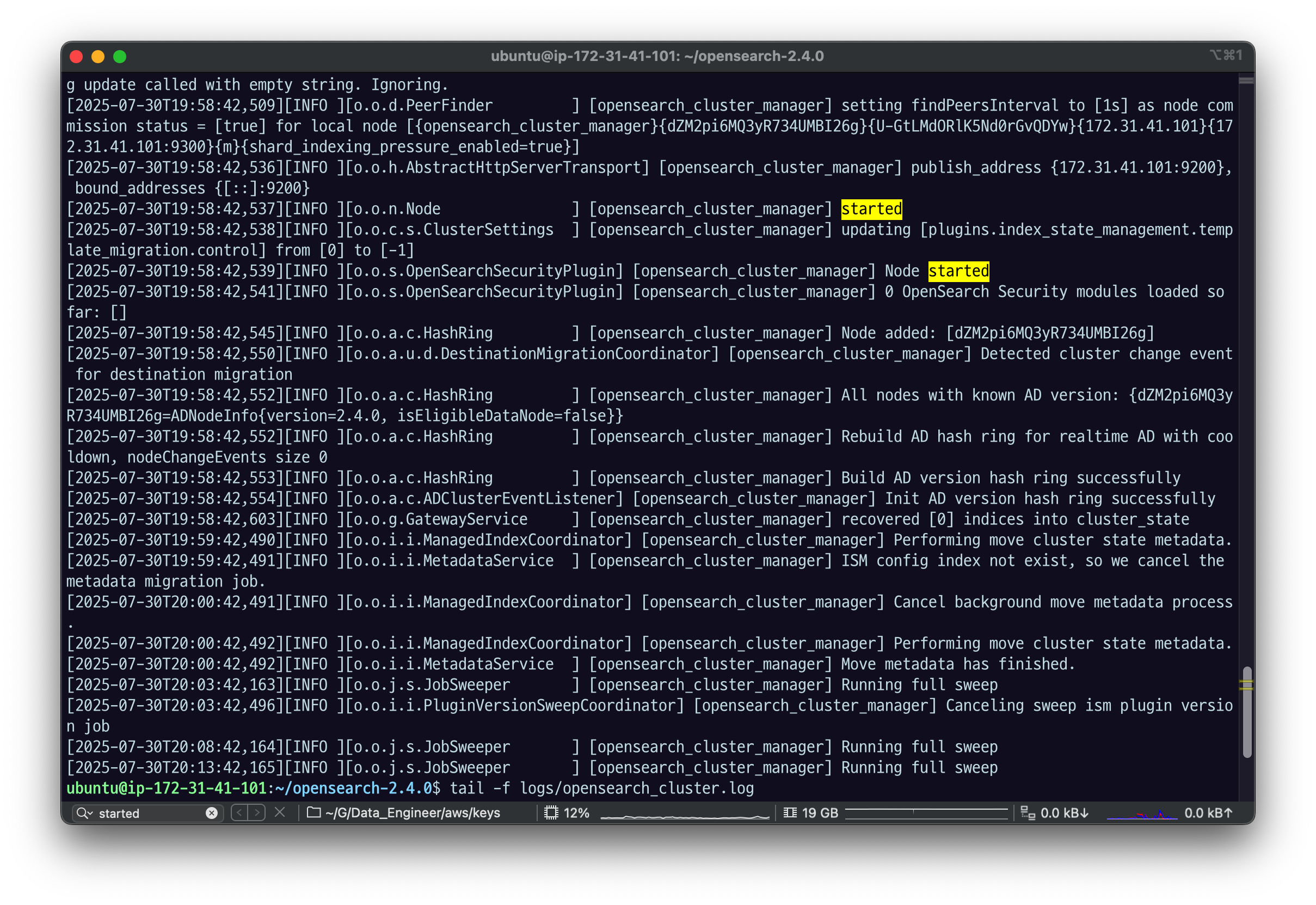
publish_address {172.31.41.101:9200}, bound_addresses {[::]:9200}
포트를 사용해 뜬 것
enforcing bootstrap checks
부트스트랩 체크한다~ 라는 로그인데
부팅할 수 있는 여러가지 과정들을 체크함.
체크할 때 여기서 실패하는 경우가 있다.
이름이 잘못되었다던가, 디스커버리가 실패했다면
여기서 실패할 확률이 높다.
위 모든 설정들이 잘 되었다면
Node started,
recovered [0] indices into cluster_state 등의 메세지가 나올 것.
노드 시작됐다는 메세지, 아직 아무런 인덱스를 만들지 않아서 인덱스에 올라간 것도 없다는 메세지임.
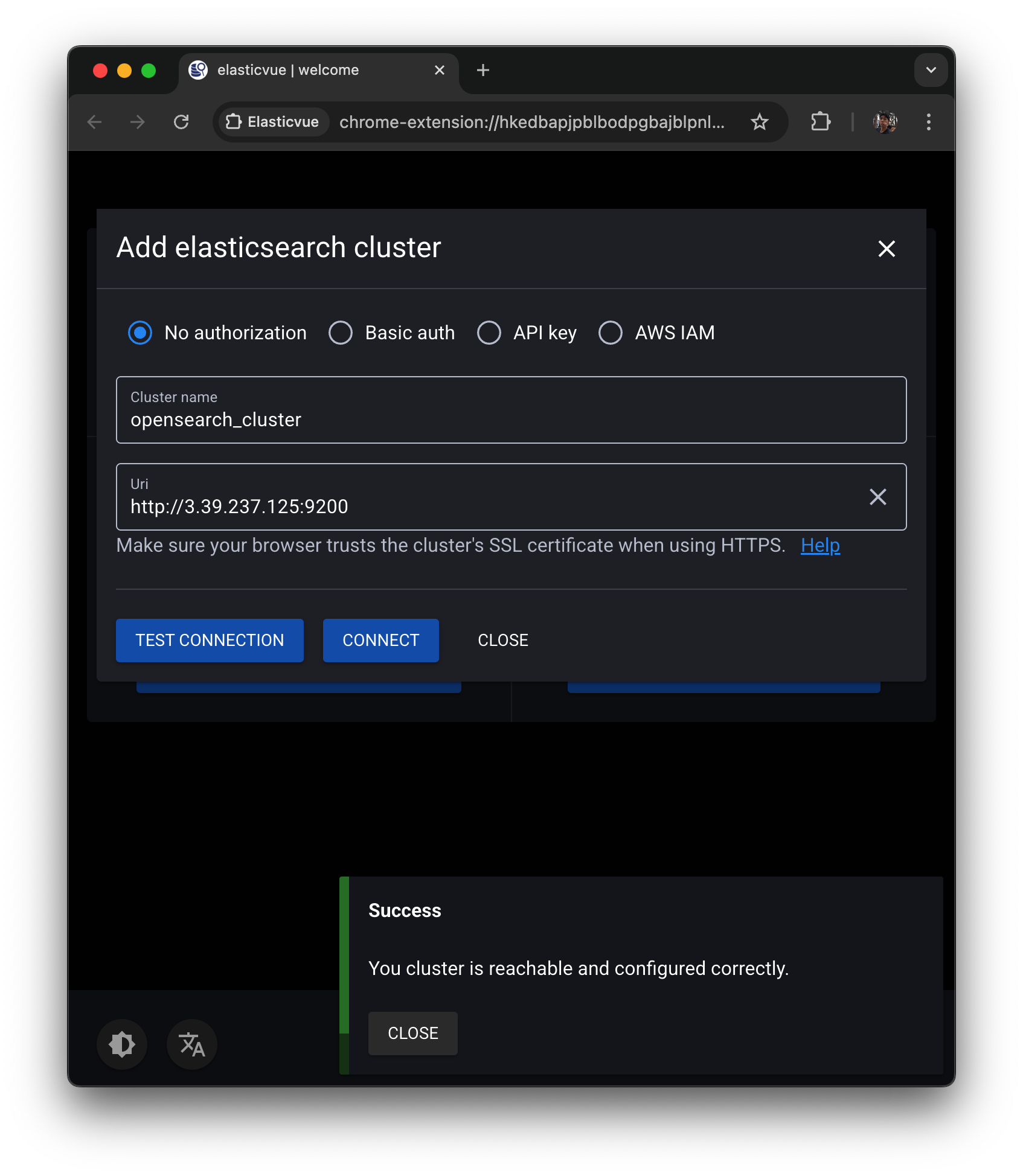
elasticvue 에 들어가서 test connection 눌러보면
Success 메세지가 나오고
connect 하면 된다.
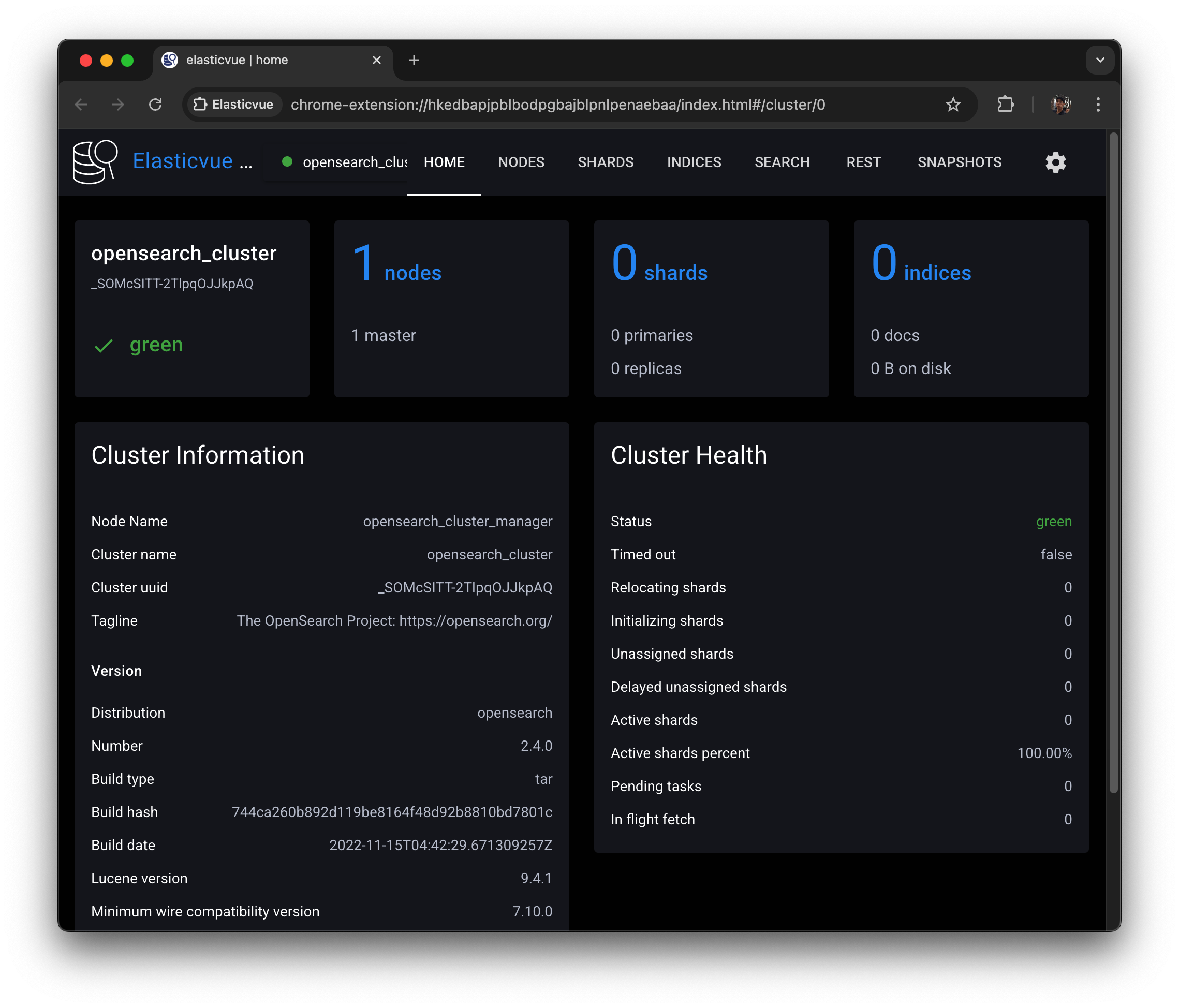
클러스터 status 가 green이고 number_of_nodes가 아직 한 개인 것을 확인할 수 있다.
Nodes 에 들어가서 보면
CPU 사용률, Ram, JVM heap, disk 볼 수 있다.
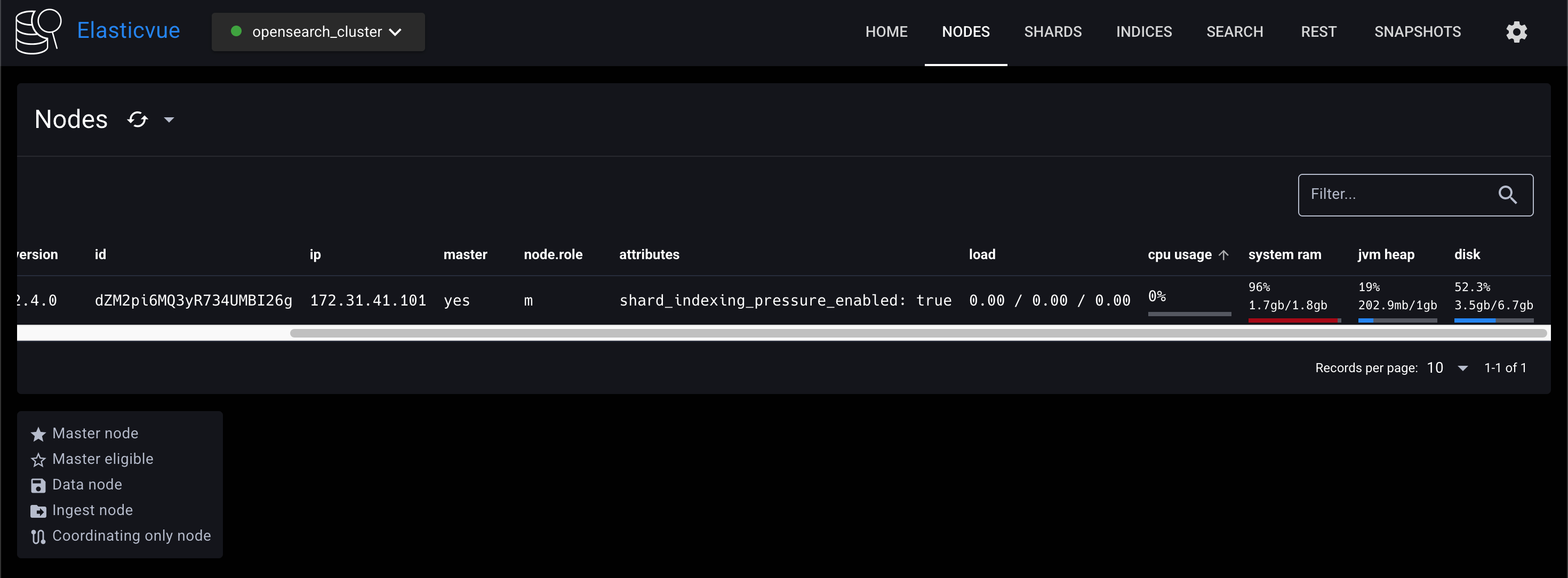
동일한 과정으로 데이터 노드에 접속해서 설정해주자.
de-opensearch-cluster-practice_data1 EC2 인스턴스에 접속해서 다음과 같이 OpenSearch config를 수정하고 $ sudo systemctl restart opensearch.service로 OpenSearch 노드를 재시작하자.
plugins.security.disabled: true
cluster.name: opensearch_cluster
node.name: opensearch_d1
node.roles: [ data, ingest ]
network.host: 0.0.0.0
discovery.seed_hosts: ["<CLUSTER_MANAGER_NODE_PUBLIC_IP>"]CLUSTER_MANAGER_NODE_PUBLIC_IP : manager 노드의 퍼블릭 Ip주소를 넣어주면 된다.
sudo systemctl daemon-reload
sudo systemctl restart opensearch.serviceps -ef | grep opensearch
tail -f logs/opensearch_cluster.log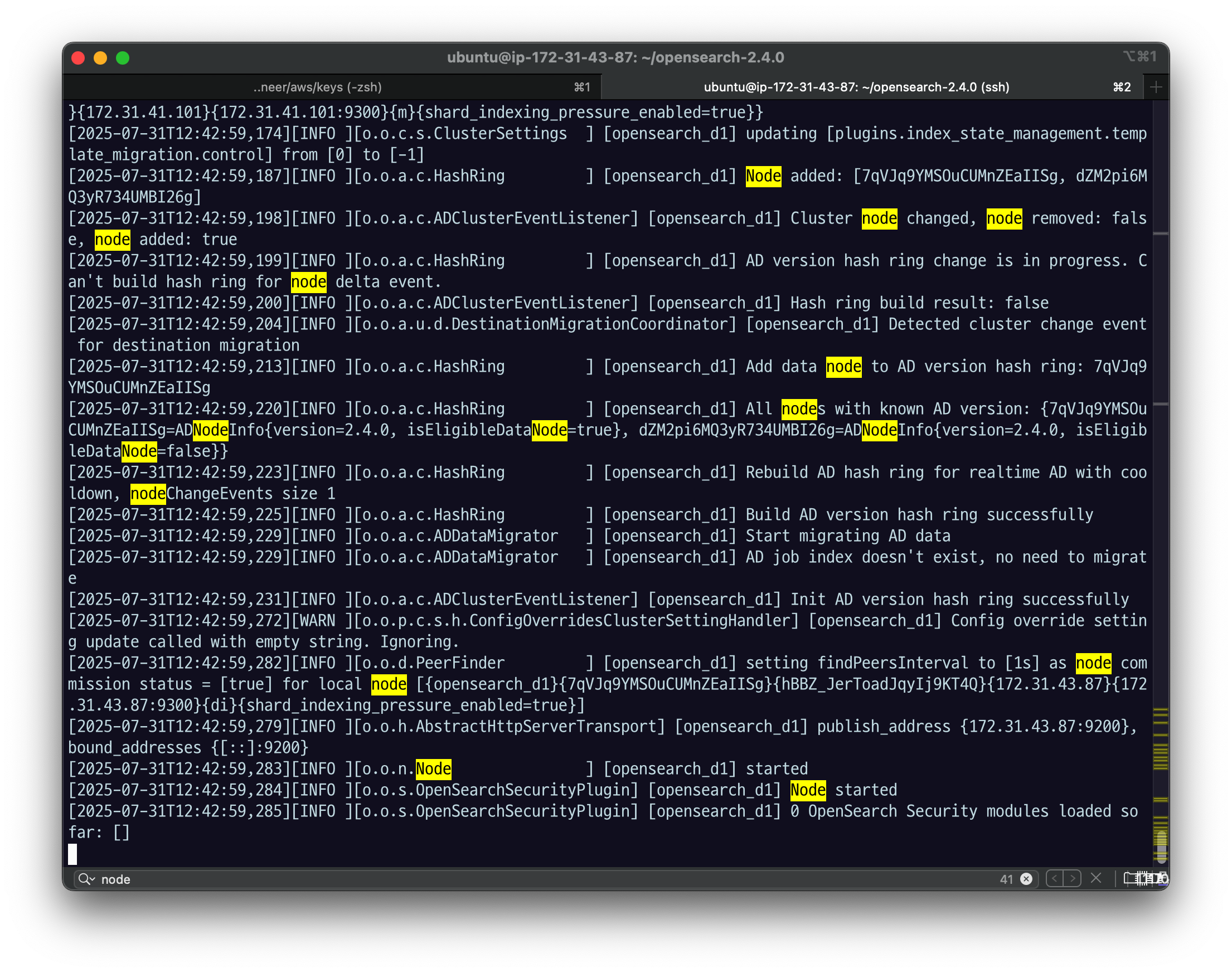
앞에서 discovery 잘 했고
node started 까지 잘 떠서 address binding이 되고 뜬 걸 확인할 수 있다.
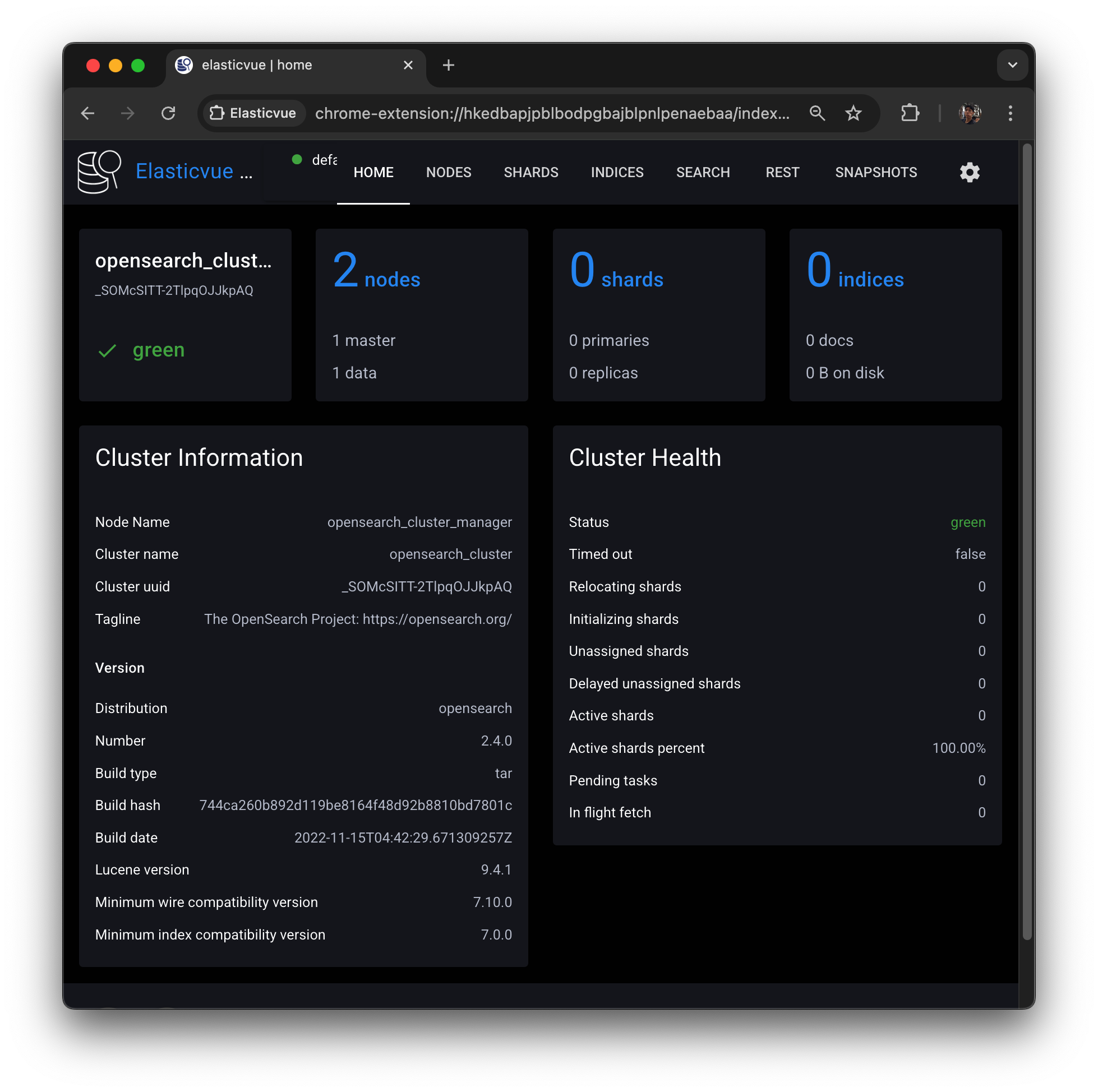
Elasticvue의 NODES 탭을 새로고침하면, 클러스터에 opensearch-d1 노드가 추가 바인딩된 것을 확인할 수 있다. (주소는 맨 처음 manager 주소 그대로)
de-opensearch-cluster-practice_data2 EC2 인스턴스에 접속해서 다음과 같이 OpenSearch config를 수정하고 $ sudo systemctl restart opensearch.service로 OpenSearch 노드를 재시작하자.
plugins.security.disabled: true
cluster.name: opensearch_cluster
node.name: opensearch_d2
node.roles: [ data, ingest ]
network.host: 0.0.0.0
discovery.seed_hosts: ["<CLUSTER_MANAGER_NODE_PUBLIC_IP>"]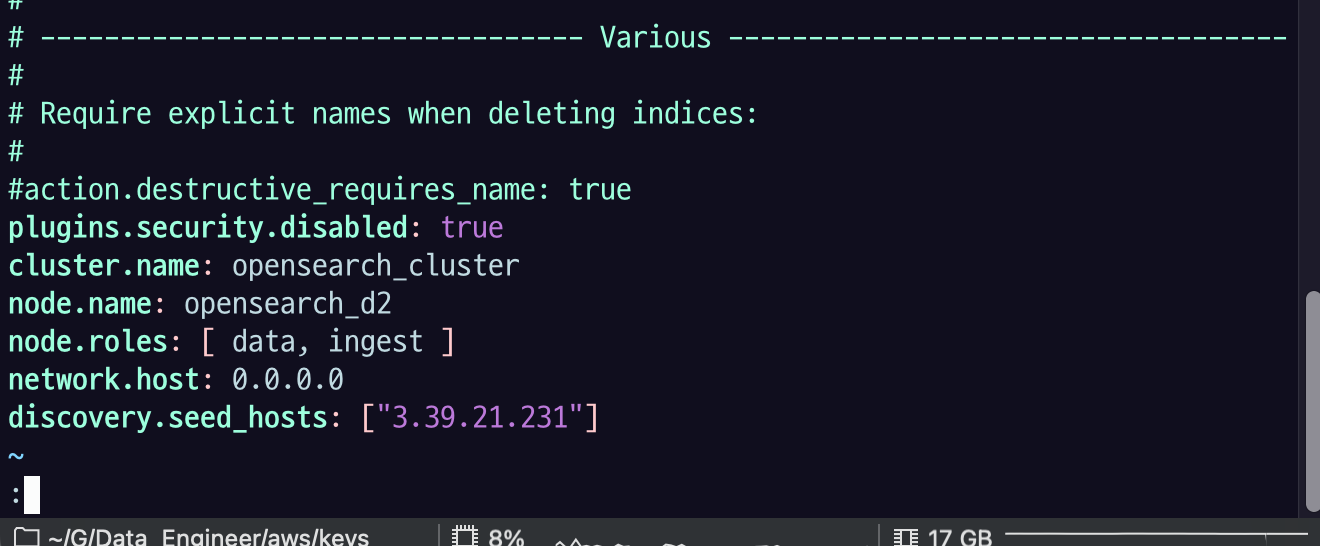
sudo systemctl daemon-reload
sudo systemctl restart opensearch.service
ps -ef | grep opensearch
tail -f logs/opensearch_cluster.log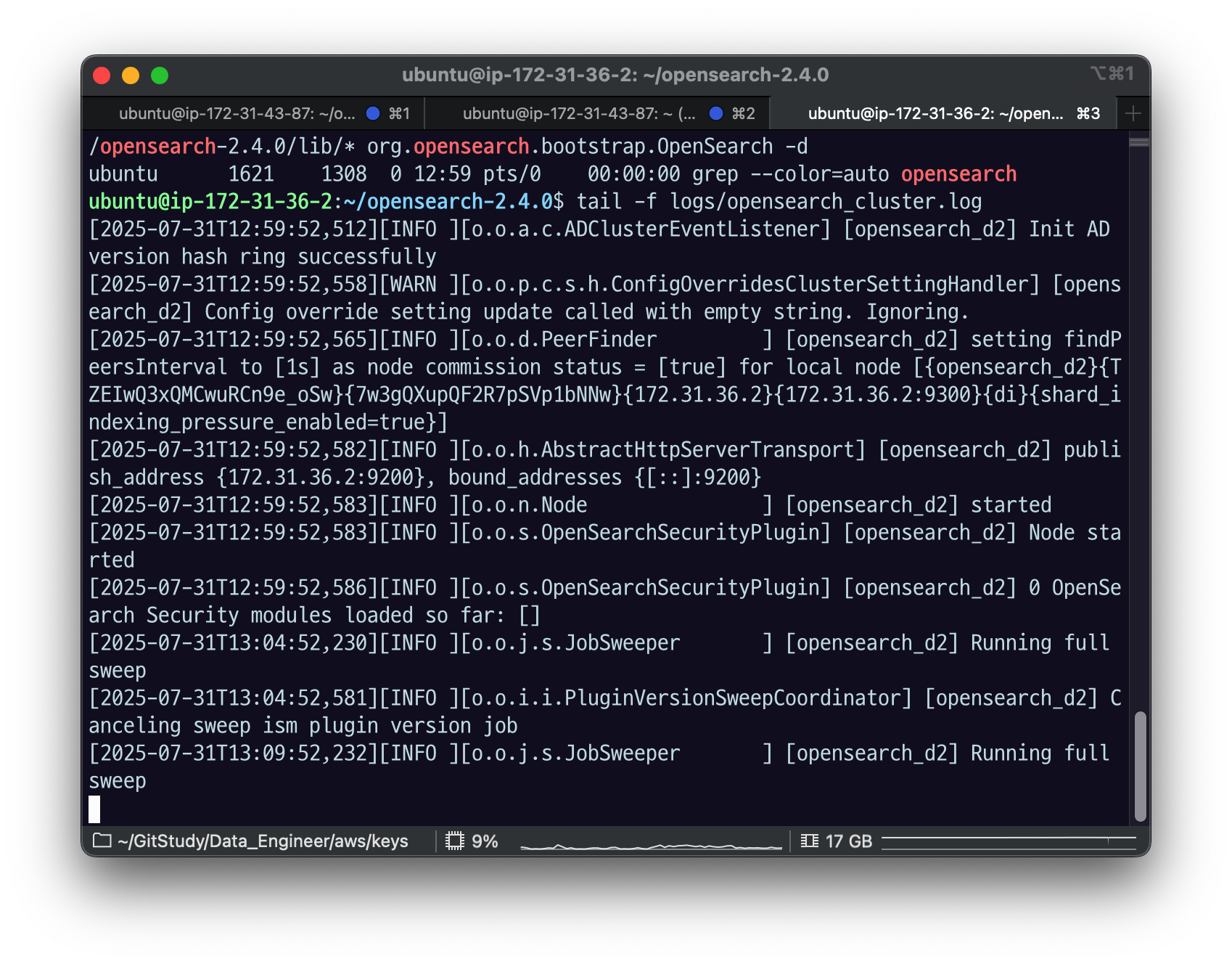
node started 됨
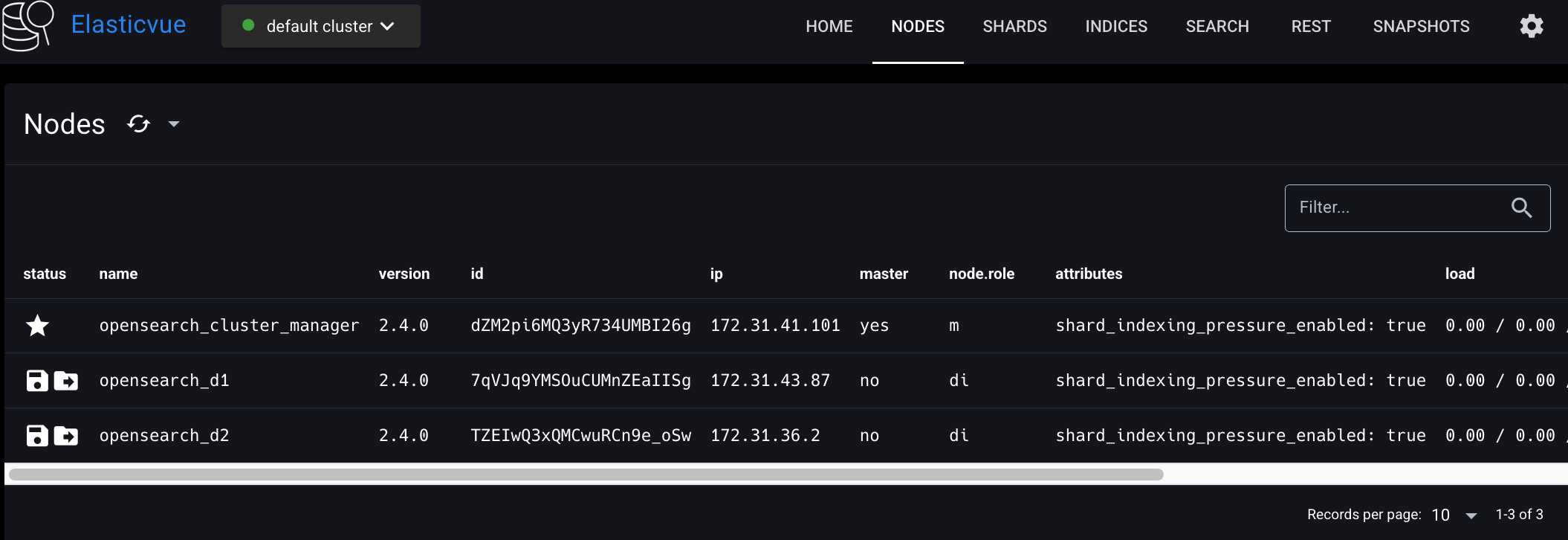
Elasticvue의 NODES 탭을 새로고침하면, 클러스터에 opensearch-d2 노드가 추가 바인딩된 것을 확인할 수 있다.
de-opensearch-cluster-practice_coordinator EC2 인스턴스에 접속해서 다음과 같이 OpenSearch config를 수정하고 $ sudo systemctl restart opensearch.service로 OpenSearch 노드를 재시작하자.
모든 노드는 코디네이터 노드 역할을 수행하므로, node.roles를 빈 배열로 설정하면 해당 노드는 코디네이터 역할만 수행하는 코디네이터 전용 노드가 된다.
plugins.security.disabled: true
cluster.name: opensearch_cluster
node.name: opensearch_c1
node.roles: []
network.host: 0.0.0.0
discovery.seed_hosts: ["<CLUSTER_MANAGER_NODE_PUBLIC_IP>"]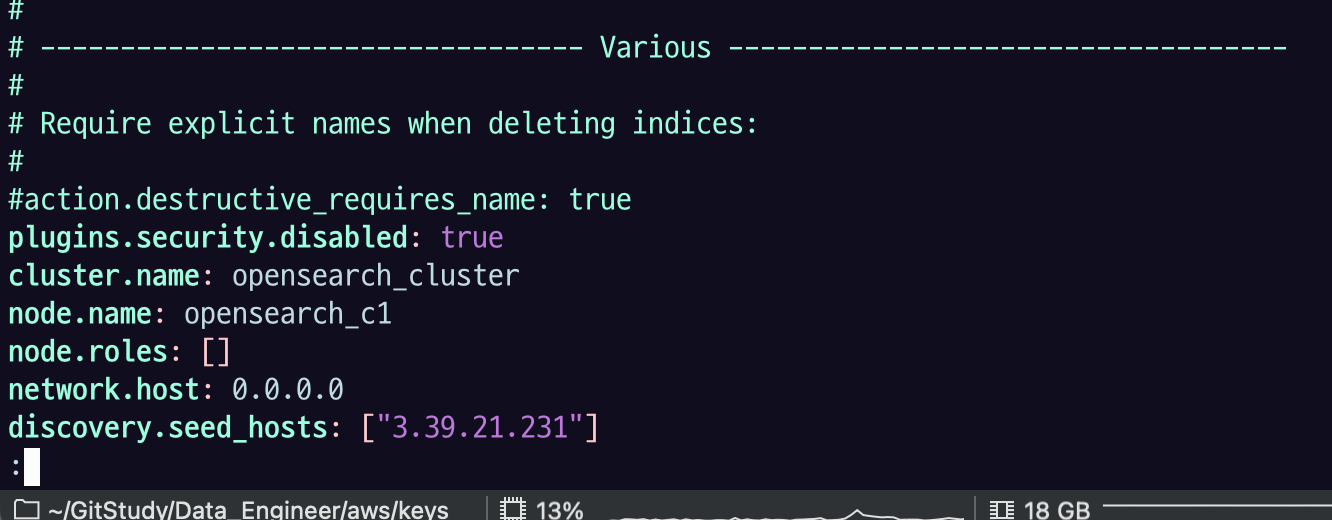
sudo systemctl daemon-reload
sudo systemctl restart opensearch.service
ps -ef | grep opensearch
tail -f logs/opensearch_cluster.log
Elasticvue의 NODES 탭을 새로고침하면, 클러스터에 opensearch_c1 노드가 추가 바인딩된 것을 확인할 수 있다.
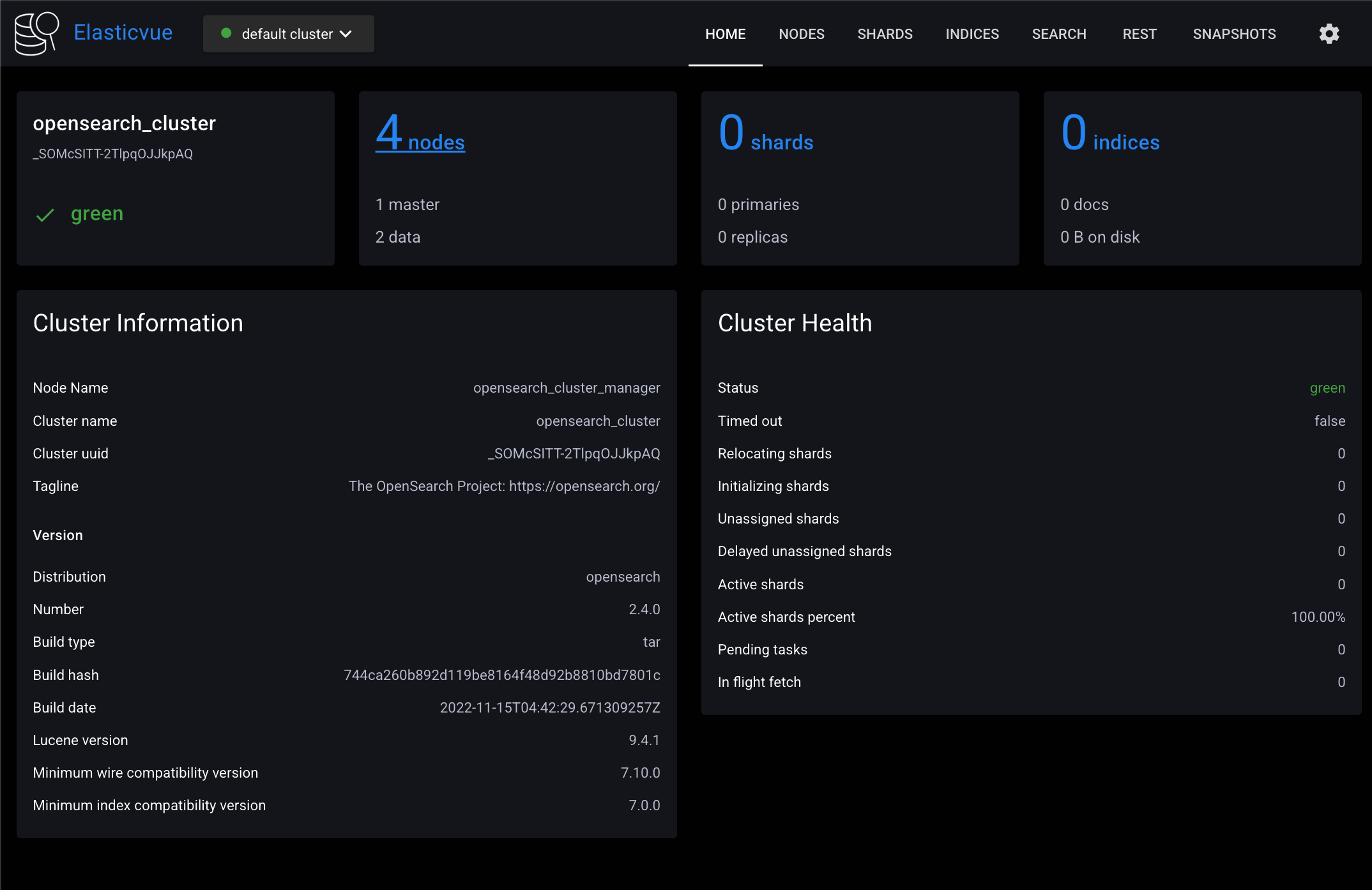
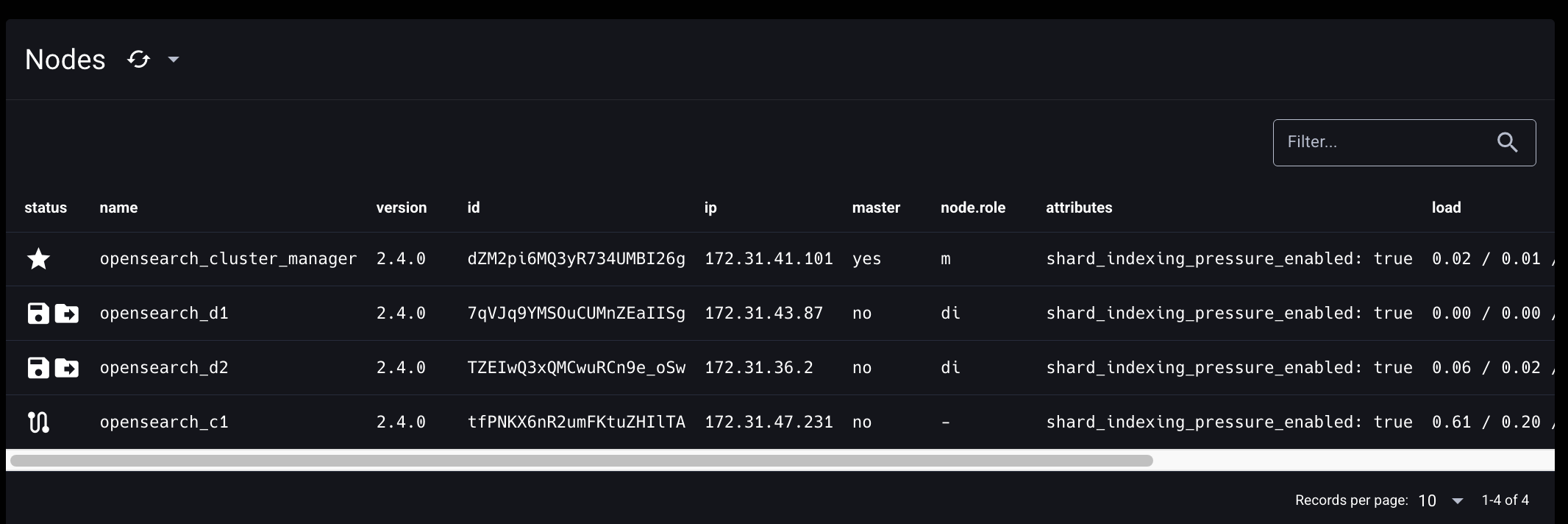
3.4.3 클러스터 매니저 노드 재선출
opensearch-cluster_manager 노드가 실행중인 EC2 인스턴스에 접속해서 다음 명령어로 클러스터 매니저 노드를 중지시켜보자.
sudo systemctl stop opensearch.service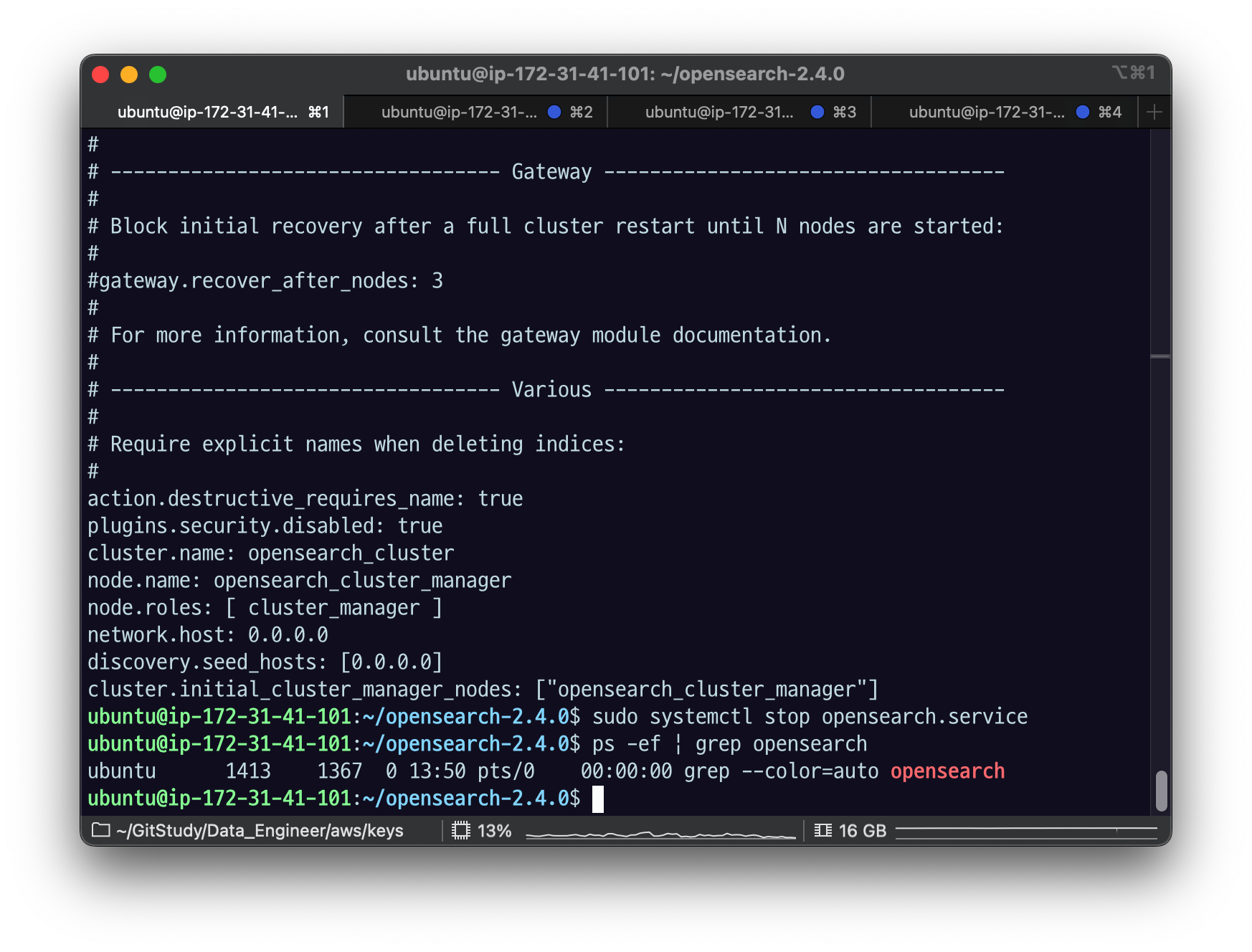
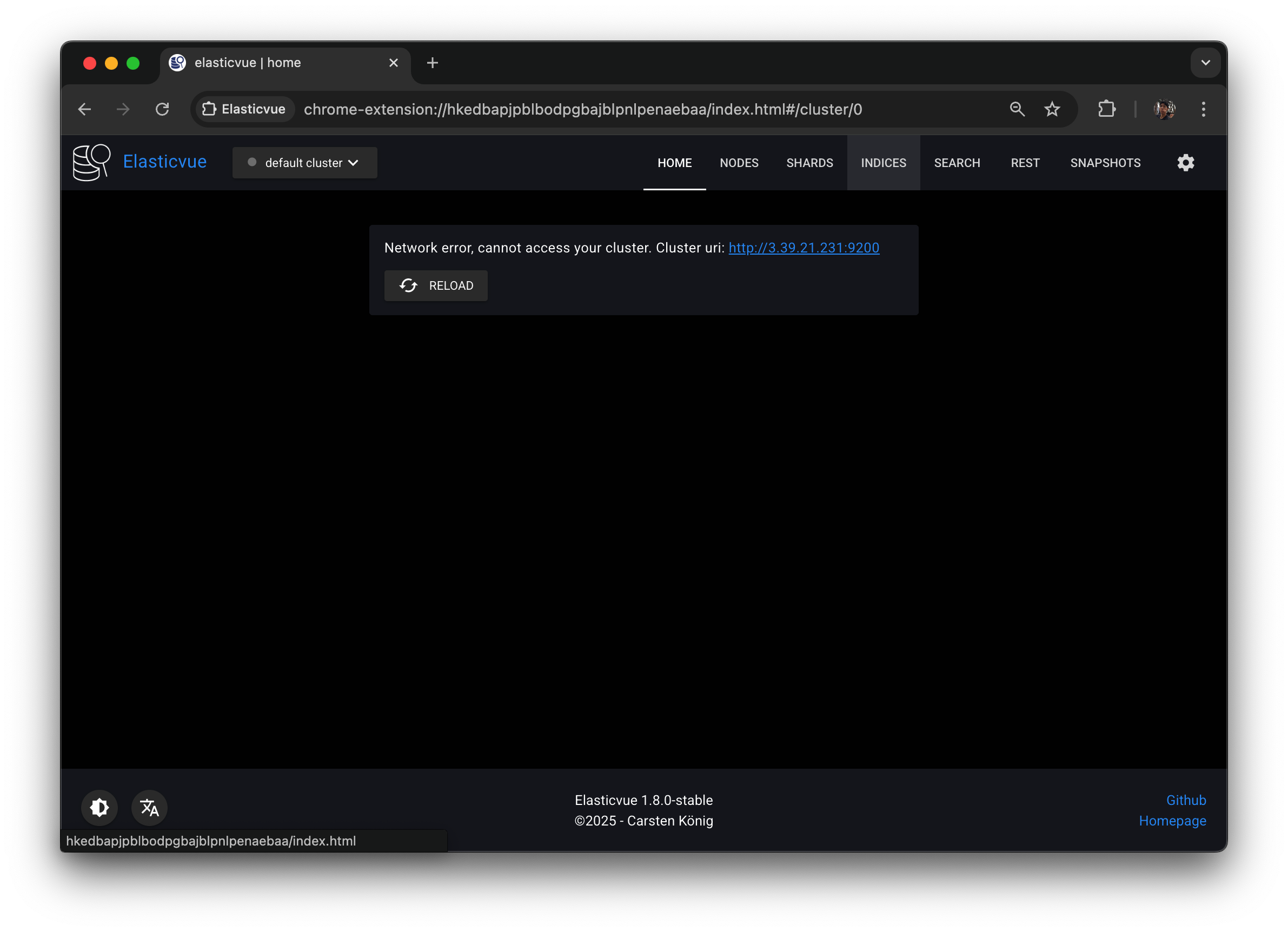
Elasticvue의 NODES 탭을 새로고침하면, 노드를 찾을 수 없다는 화면이 보일 것이다.
Elasticvue를 opensearch-c1 노드의 public IP로 연결할 경우 코디네이터 노드와 해당 노드에 포함된 샤드의 정보는 확인할 수 있지만, 클러스터, 노드, 인덱스의 정보는 확인할 수 없다.
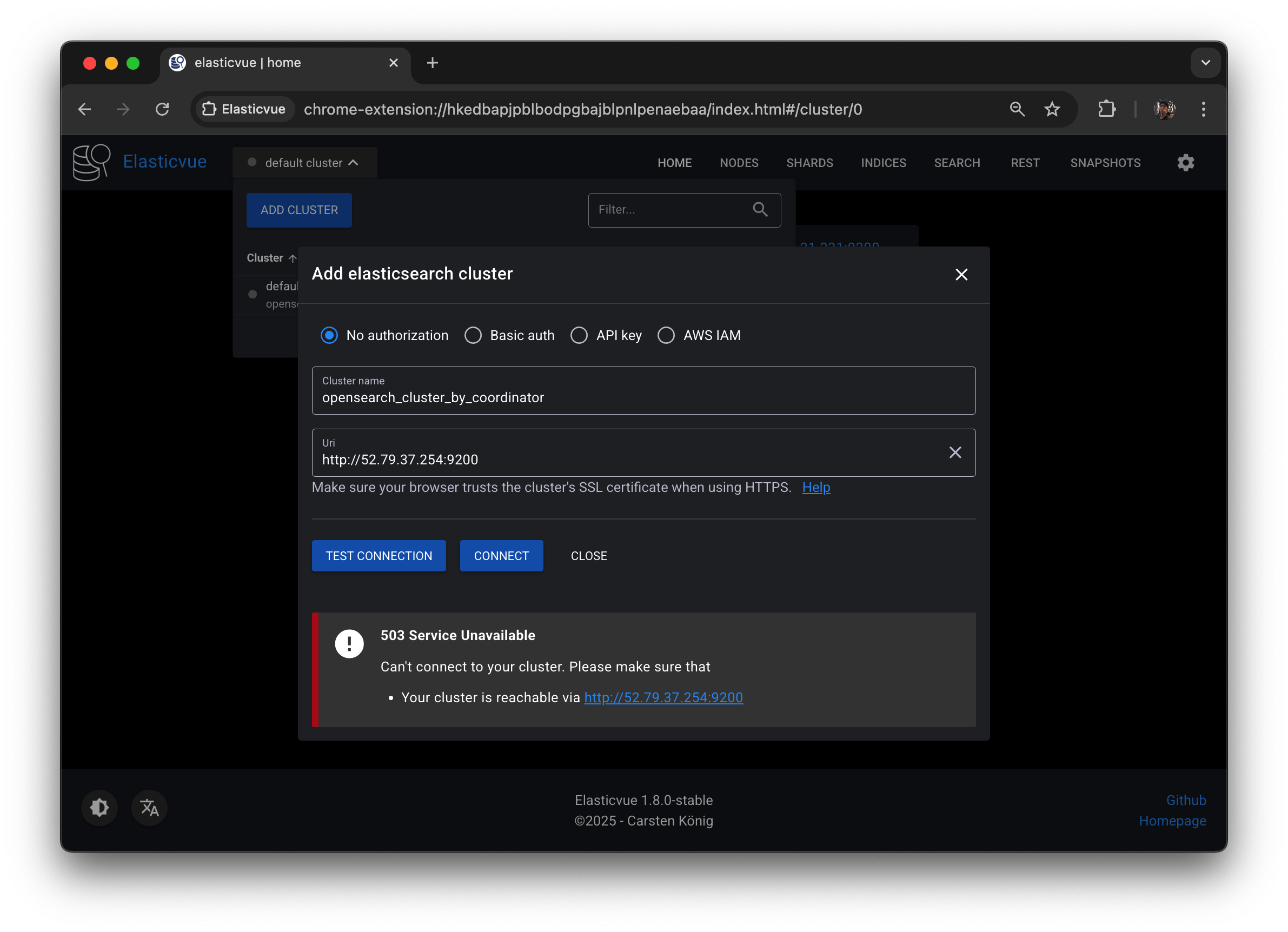
원래는 node information 정도는 나와 줘야 하는데 연결 자체가 안되는 모습.
elasticvue 가 업데이트 된 듯 하다.
클러스터 매니저 노드는 클러스터 설정, 인덱스 설정, 노드 상태를 관리하는 역할을 담당하기 때문에 매니저 노드가 없는 상황에서는 Elasticvue도 해당 정보를 읽어올 수 없다.
{
"error": {
"root_cause": [
{
"type": "cluster_manager_not_discovered_exception",
"reason": null
}
],
"type": "cluster_manager_not_discovered_exception",
"reason": null
},
"status": 503
}클러스터 매니저 노드에 장애가 발생하는 상황에 대비하기 위해서는 클러스터 매니저 후보 노드를 설정해둬야 한다. node.roles에 cluster_manager를 포함하는 경우 클러스터 매니저 후보 역할을 수행하게 된다.
opensearch-d2 노드의 node.roles를 다음과 같이 수정하고 노드를 재시작하자.
node.roles: [ data, ingest, cluster_manager ]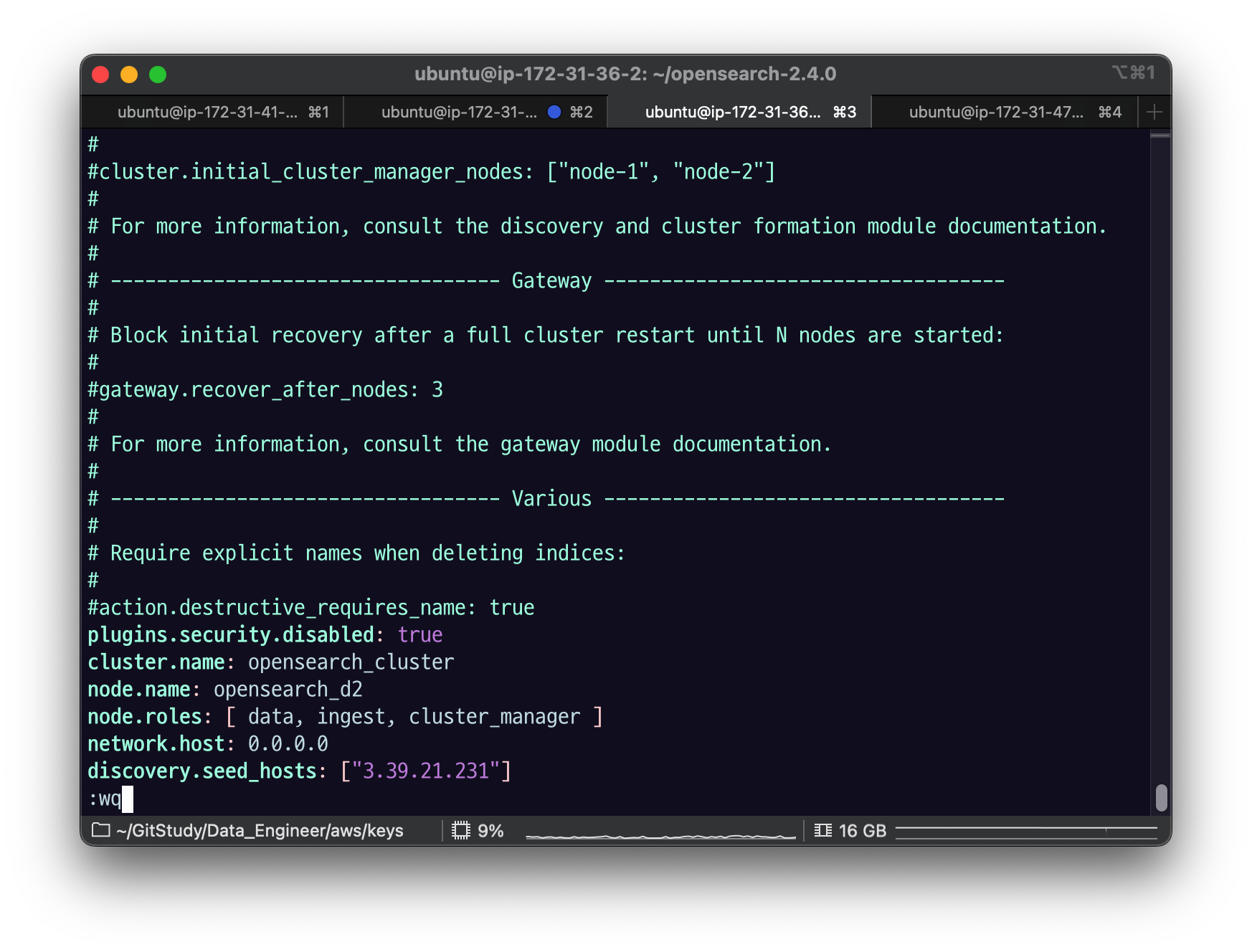
restart opensearch.service
grep opensearch
tail -f logs/opensearch_cluster.log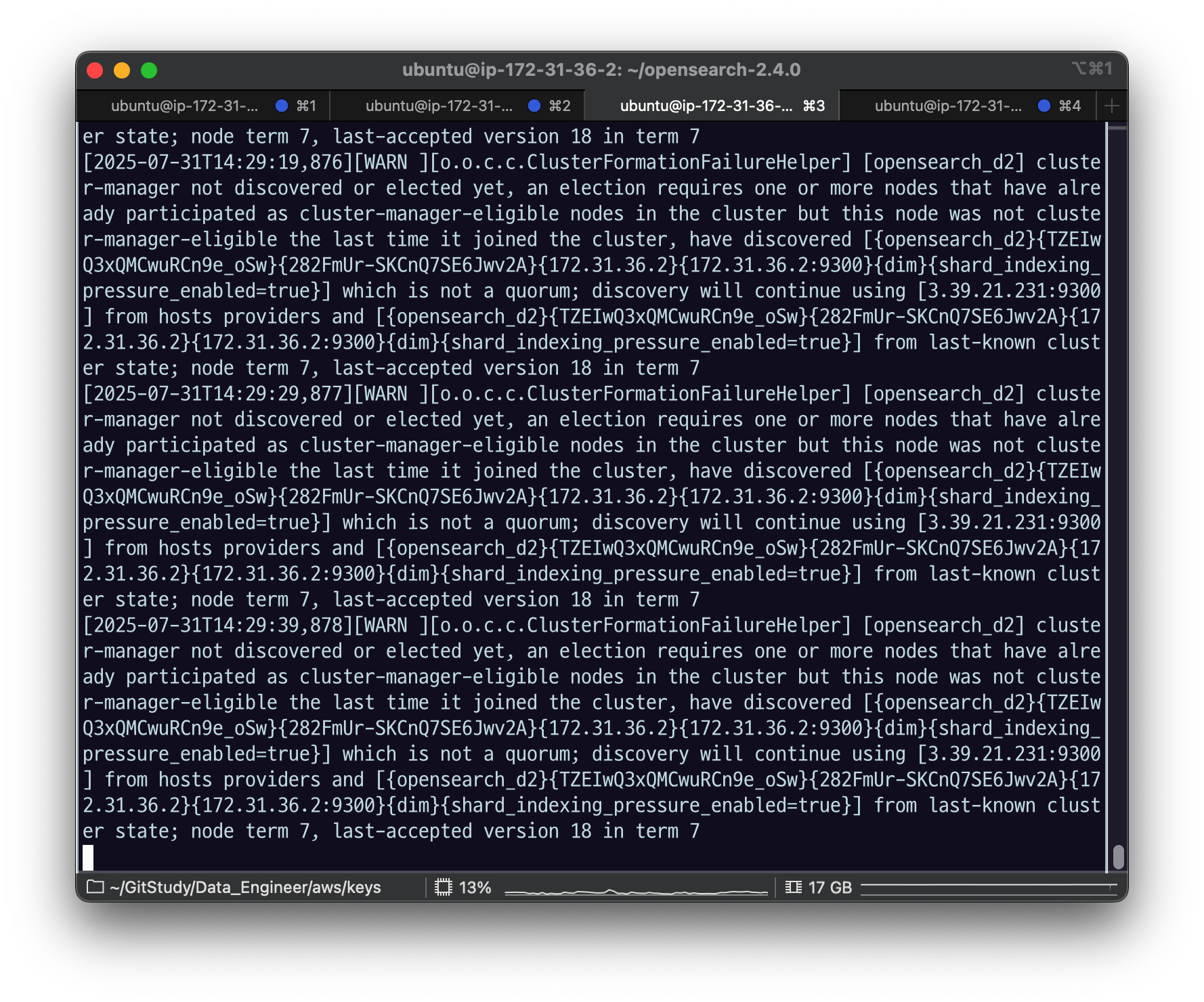
잘 된 모습.
모든 노드의 discovery.seed_hosts에 opensearch-d2 노드의 IP 주소가 등록되어 있지 않기 때문에 discovery에 실패하게 된다. 따라서 Elasticvue에서는 여전히 클러스터 정보를 읽어올 수 없을 것이다. (Elasticvue는 코디네이터 노드에 연결된 상태)
코디네이터가 바라보는 seed host가 여전히 아까 매니저 노드였던 그 친구니까 지금 d2 노드에 대해 매니저 역할을 줬다고 하더라도 discovery 과정에서 실패했기 때문에 클러스터 구성을 하지 못하게 된다.
이 경우 opensearch-cluster_manager 노드를 재시작해야 클러스터를 활성화시킬 수 있다.
manager 서버에서.
vi config/opensearch.ymlseed_hosts 를 내 자기 자신이 아니라 d2에 있던 data2 노드의 ip 주소를 넣어주자.
그리고 cluster.initial_cluster_manager_nodes 를 데이터노드의 이름인 opensearch_d2 로 바꿔주자.
이름 확인
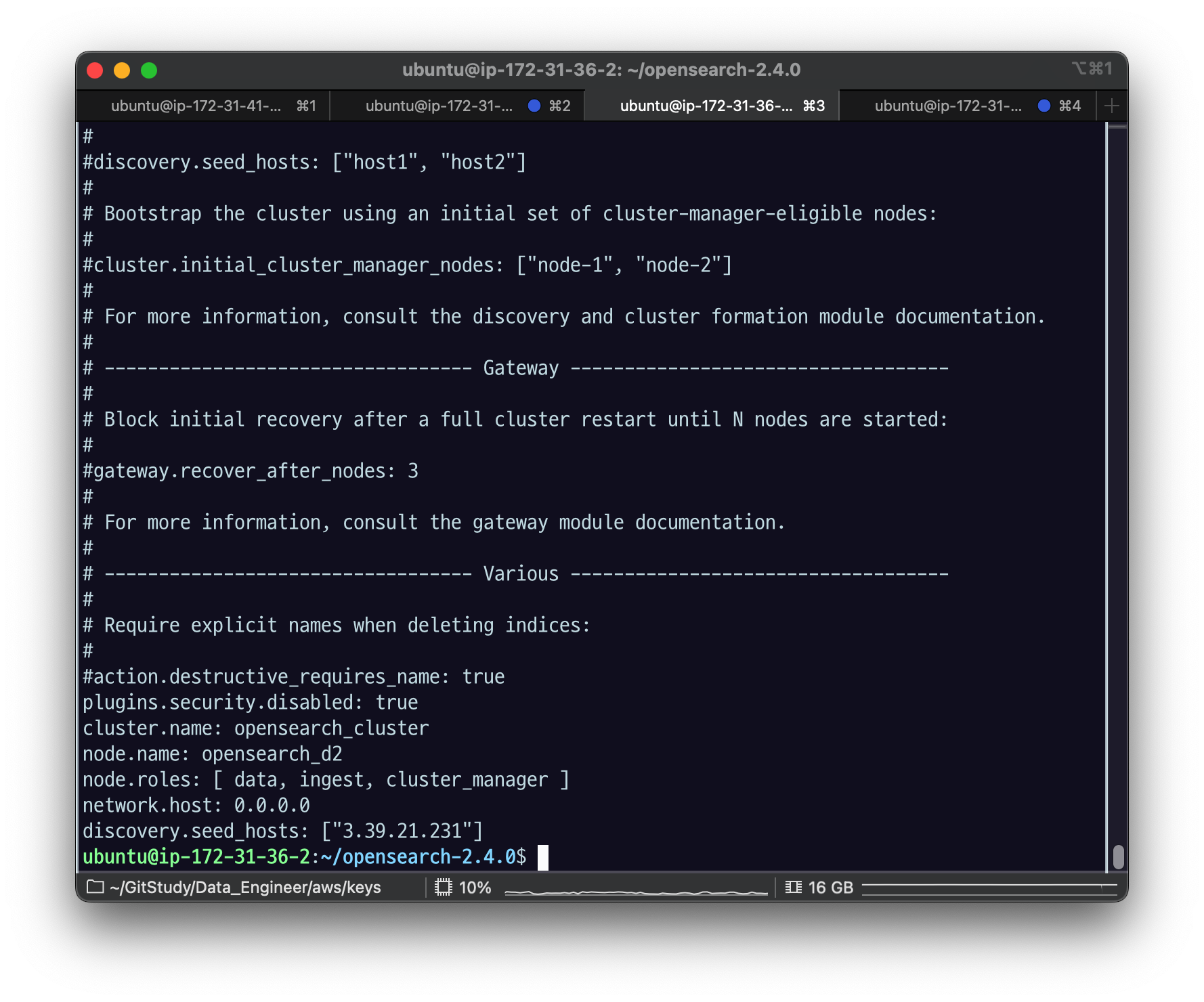
opensearch_d2 라고 되어있음.
manager node 의 config/opensearch.yml
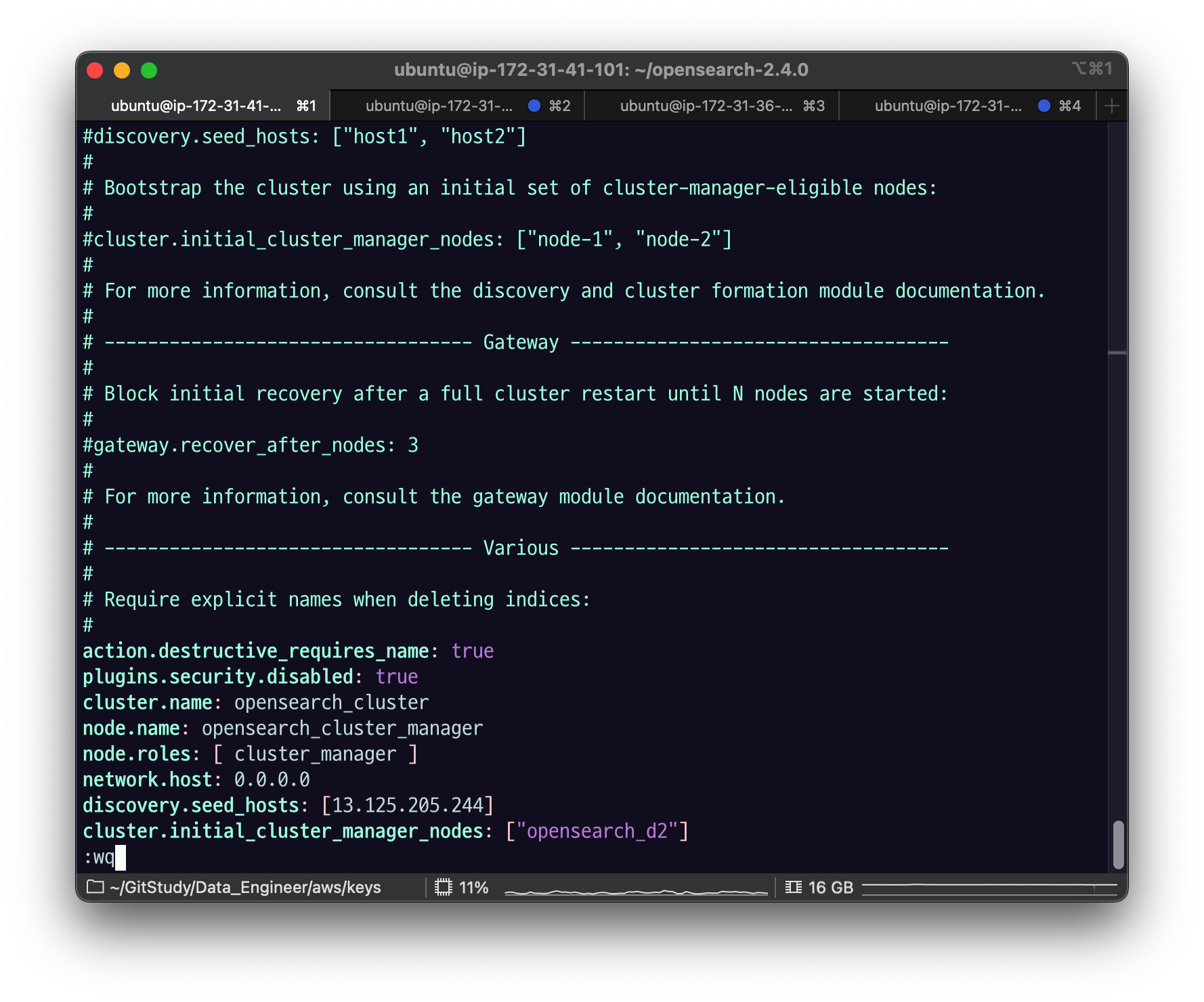
discovery.seed_hosts를 d2노드의 ip 주소로 바꾸고,
cluster.initial_cluster_manager_nodes 를 아까 찾은 opensearch_d2 로 수정한다.
sudo systemctl daemon-reload
sudo systemctl start opensearch.service
ps -ef | grep opensearch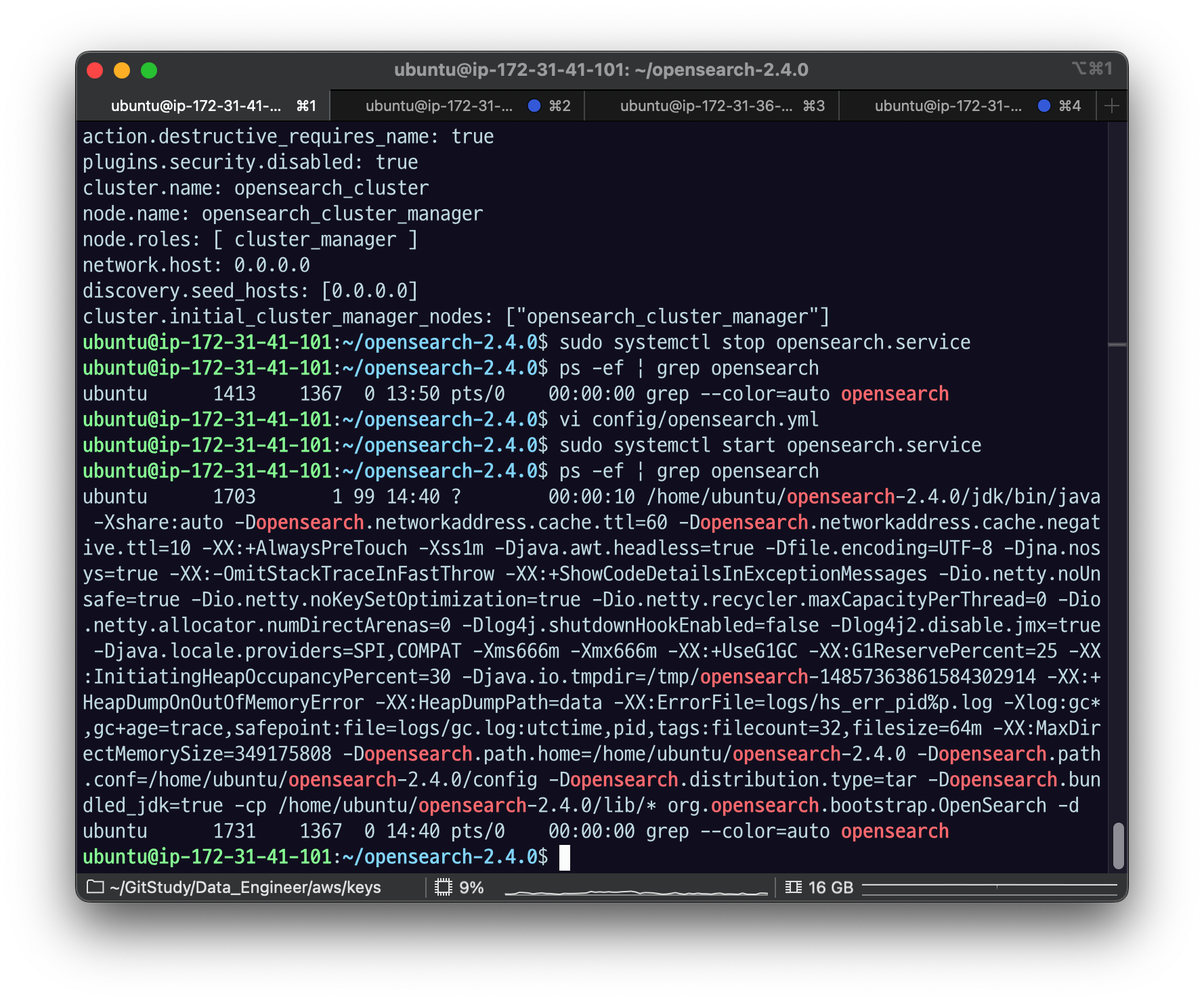
이후 Elasticvue를 확인해보면 opensearch-d2 노드에 클러스터 매니저 후보(master eligile) 역할이 추가된 것을 확인할 수 있을 것이다.
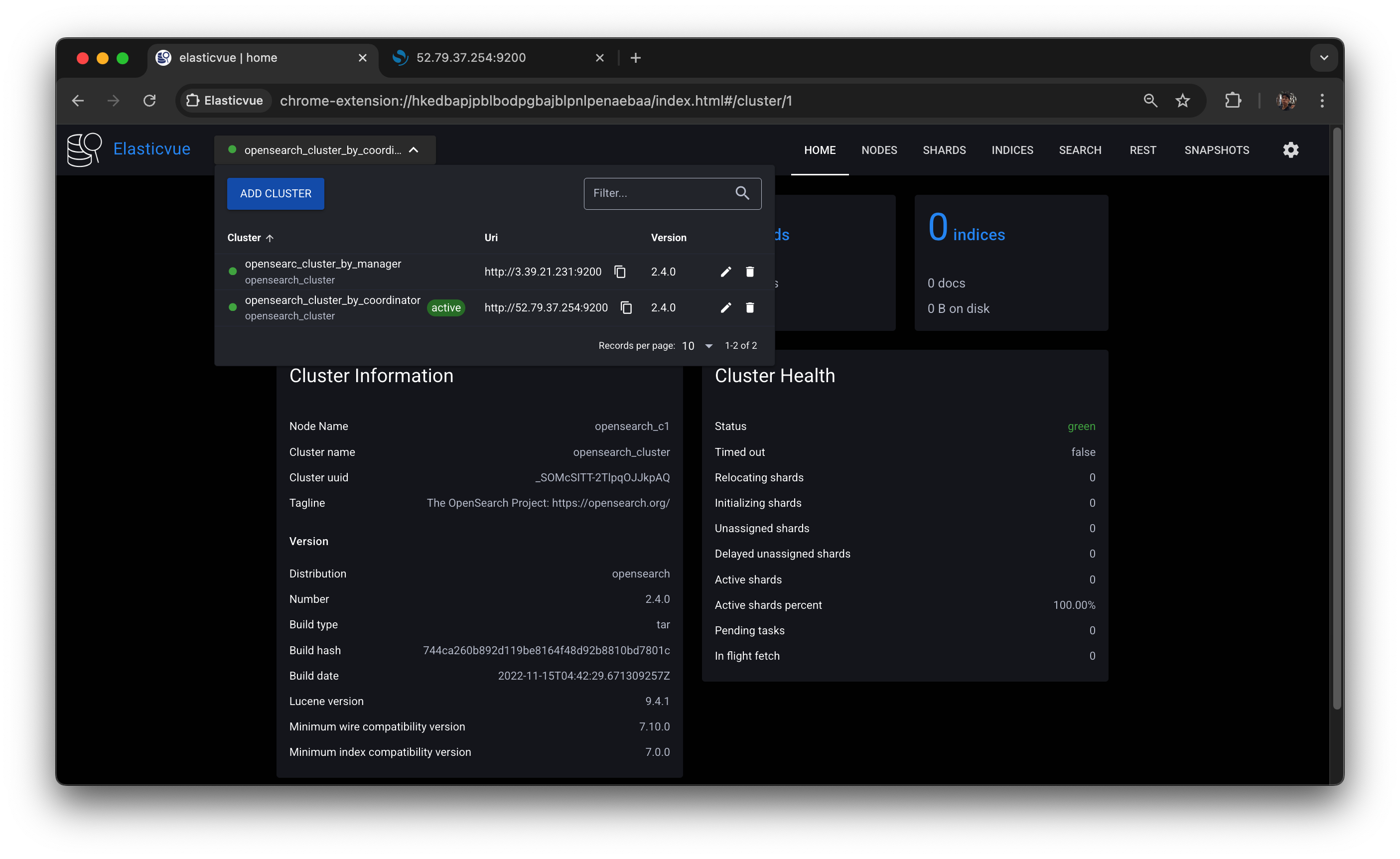
코디네이터 노드가 알고 있는 건 매니저 서버고, 매니저 서버는
data2 노드를 시드로 해서 서로서로 구성이 잘 되어 있는 걸 확인할 수 있다.
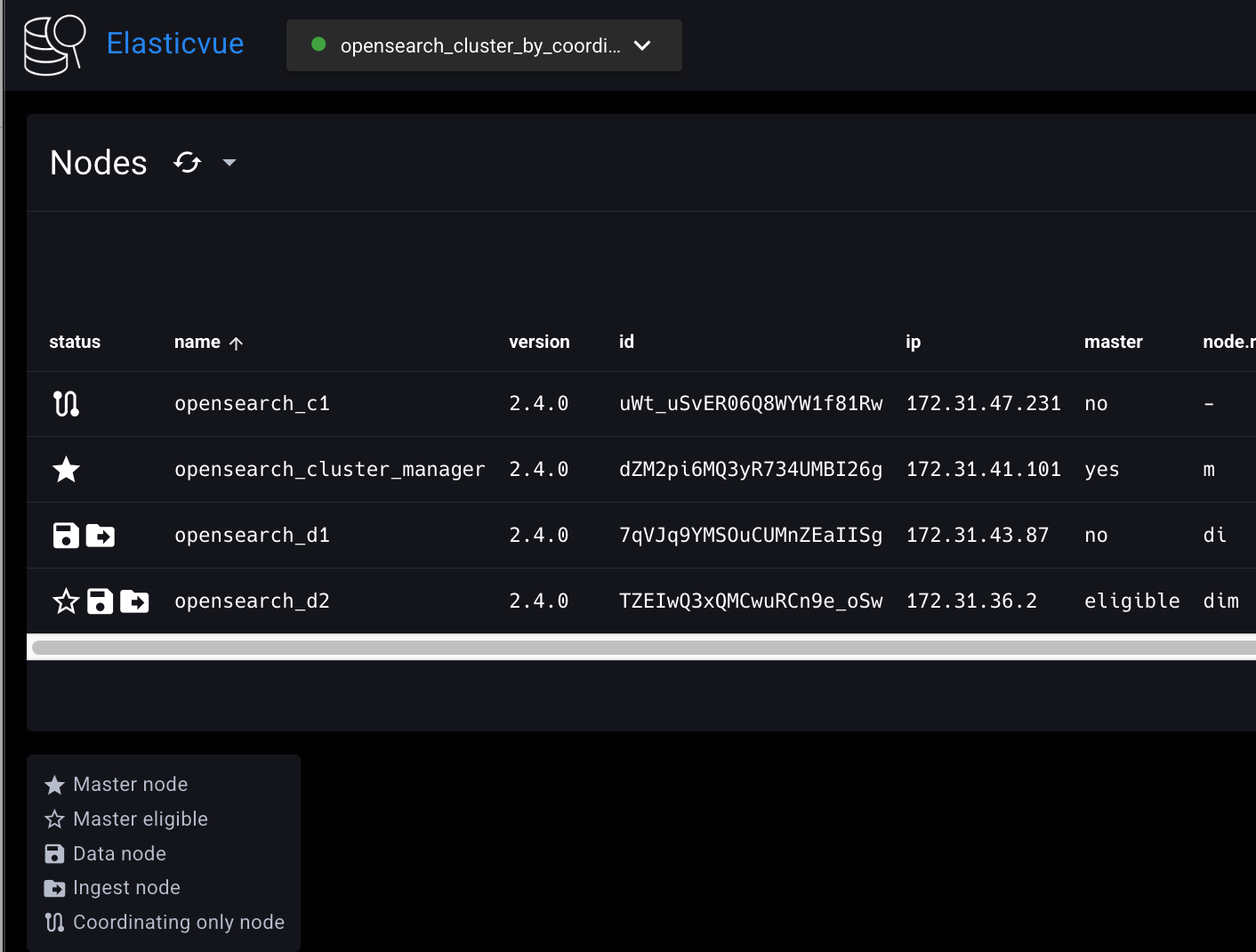
d2가 mater_eligible이 된 것을 확인할 수 있다.
opensearch-cluster_manager 노드를 다시 중지시켜보자.
sudo systemctl stop opensearch.service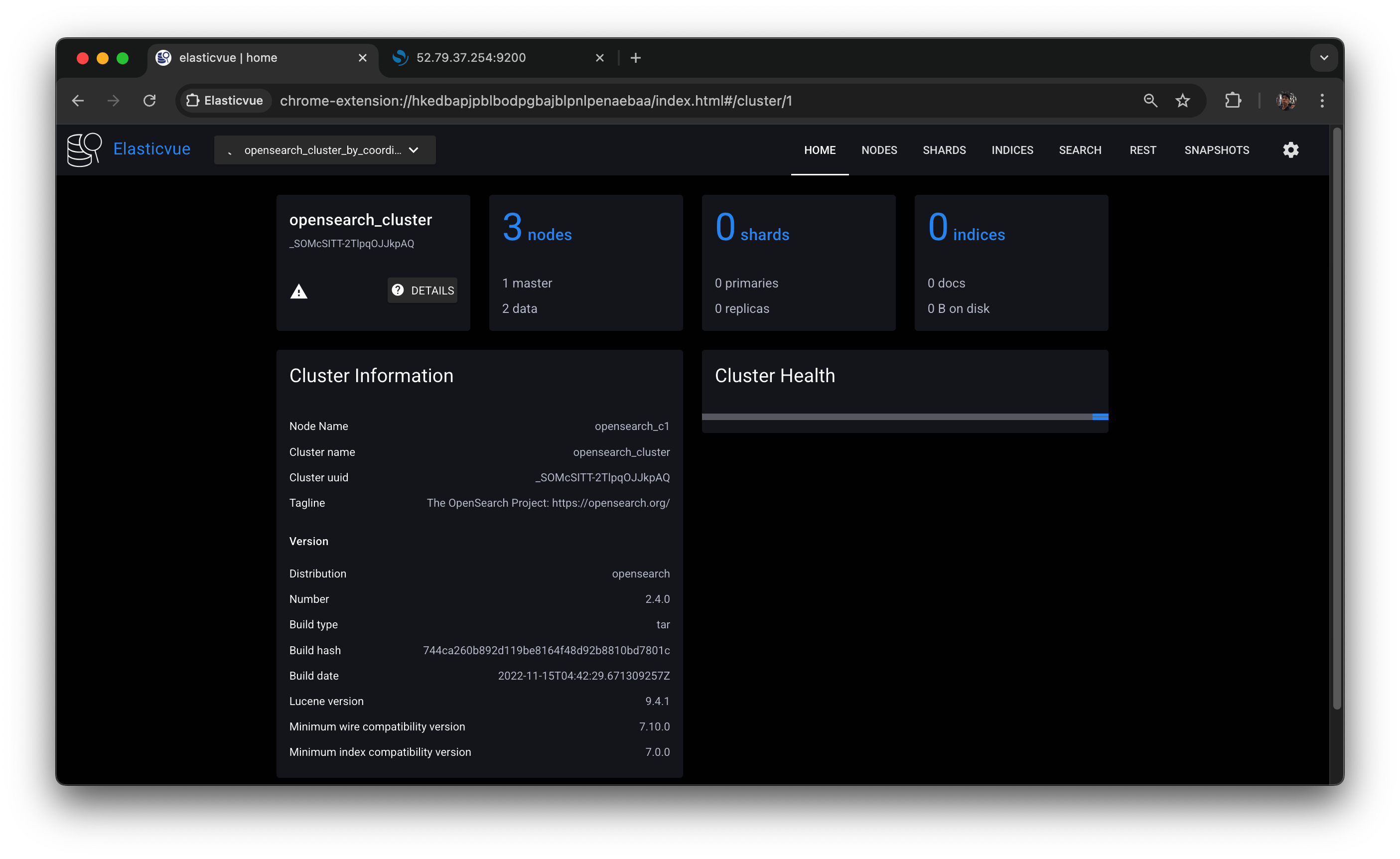
업데이트 해보면 클러스터 헬스가 나오지 않는 모습.
opensearch-d2가 새로운 클러스터 매니저 노드로 선출되고 클러스터가 정상화될 것이라는 예상과는 달리 클러스터는 여전히 작동을 멈춘 상태다. 이유는 에러 로그를 통해 알 수 있는데, 클러스터 매니저 노드 선출에 필요한 최소 후보 노드 수를 충족하지 못했기 때문이다.
- message:
which is not a quorum;
[2022-12-25T09:51:57,621][WARN ][o.o.c.c.ClusterFormationFailureHelper] [opensearch-d2] cluster-manager not discovered or elected yet, an election requires a node with id [k3y5PllfSzCZQKACMQN4tg], have discovered [{opensearch-d2}{OpwmNmeiQSCd19yKmZfKfQ}{Q-z5SfsoSB2-U4o5GLVVwg}{172.31.100.141}{172.31.100.141:9300}{dim}{shard_indexing_pressure_enabled=true}] which is not a quorum; discovery will continue using [13.125.209.78:9300] from hosts providers and [{opensearch-d2}{OpwmNmeiQSCd19yKmZfKfQ}{Q-z5SfsoSB2-U4o5GLVVwg}{172.31.100.141}{172.31.100.141:9300}{dim}{shard_indexing_pressure_enabled=true}, {opensearch-cluster_manager}{k3y5PllfSzCZQKACMQN4tg}{mTQPHU7tTNOV8YfUONlEuQ}{172.31.100.191}{172.31.100.191:9300}{m}{shard_indexing_pressure_enabled=true}] from last-known cluster state; node term 10, last-accepted version 84 in term 10coordinator가 클러스터 헬스를 모르니까
vi config/opensearch.yml시드 호스트에 데이터노드2 의 ip 주소를 넣어주고
다시 띄워보자.
sudo systemctl daemon-reload
sudo systemctl restart opensearch.service
ps -ef | grep opensearch
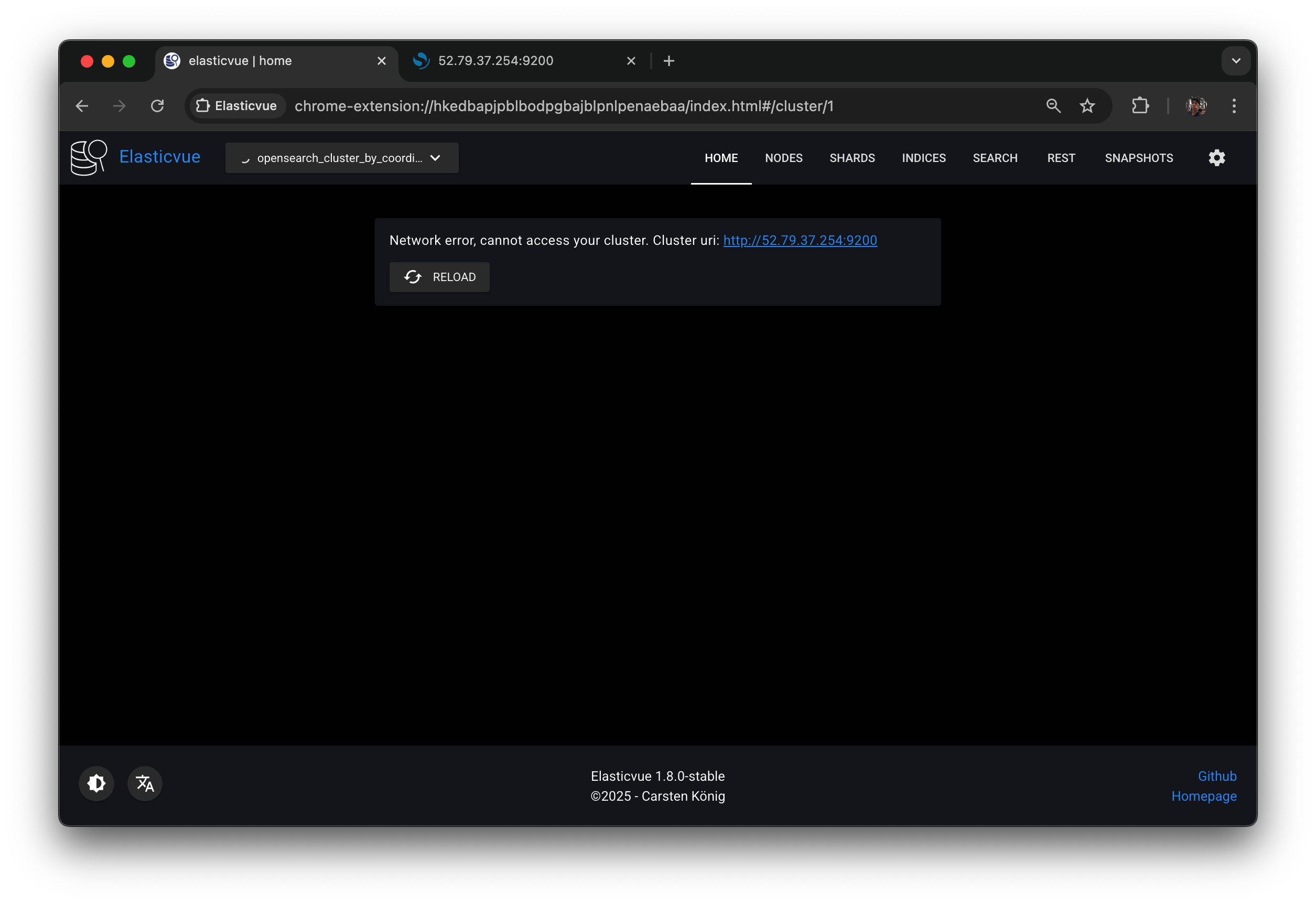
coordinator 가 잘 나오지 않는 모습.
d2에서 로그를 확인해보자.
tail -f logs/opensearch_cluster.log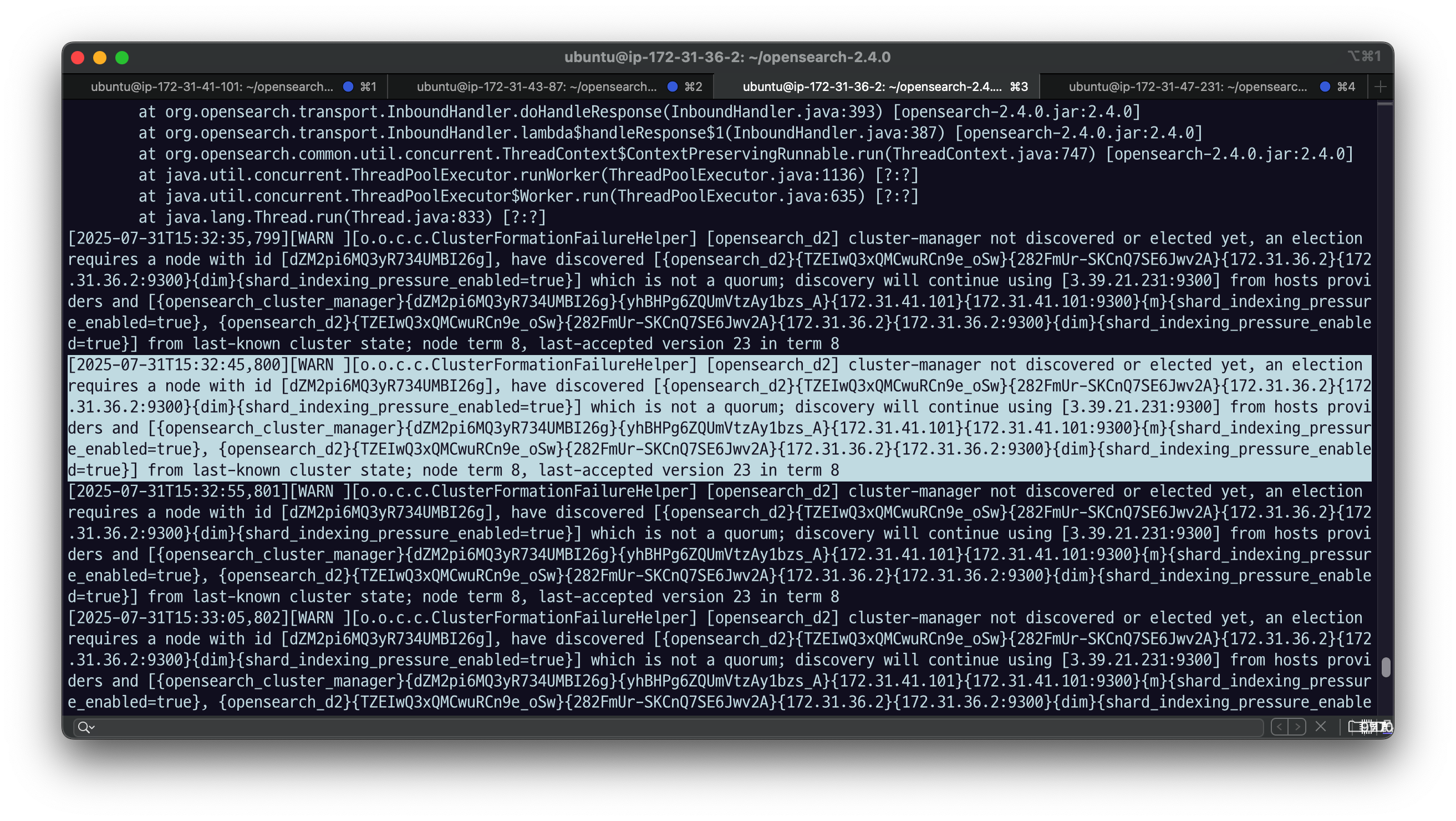
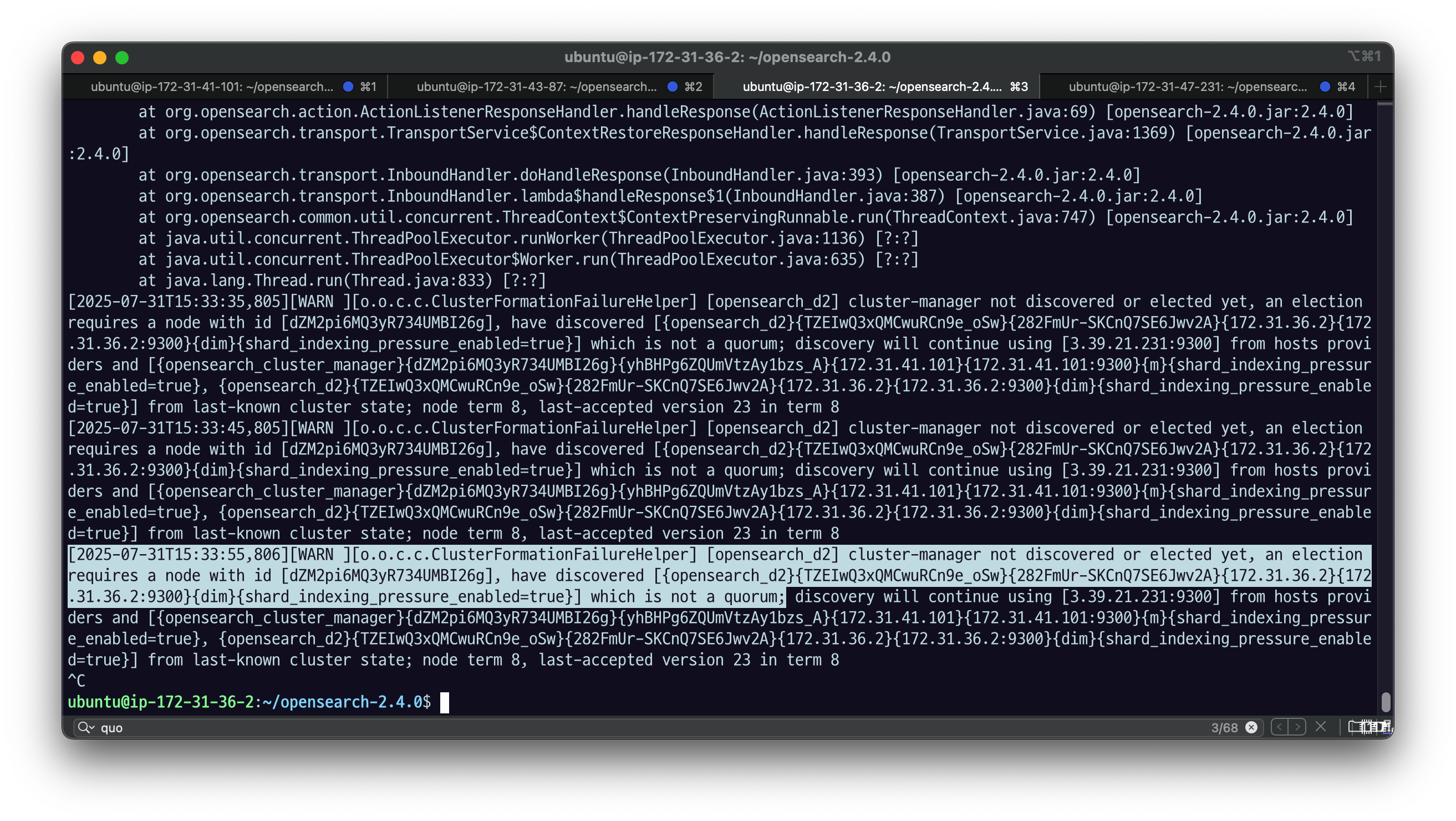
quorum을 구성하지 못했다는 로그로 실패하는 걸 확인할 수 있다.
quorum : 마스터 eligible 이 자기 혼자로는 투표를 할 수가 없다. 그래서 자기를 투표해주는 친구가 있어야 함.
eligible은 최소 두 대가 있어야 함.
최소 후보 노드 수를 충족하기 위해 opensearch-d1 노드의 node.roles를 다음과 같이 수정하고, opensearch-cluster_manager 노드와 opensearch-d1 노드를 모두 재시작하자.
vi config/opensearch.ymlnode.roles: [ data, ingest, cluster_manager ]
sudo systemctl daemon-reload
sudo systemctl restart opensearch.service
manager 노드 중단시켰던 것도 다시 재실행 시키고
sudo systemctl start opensearch.service
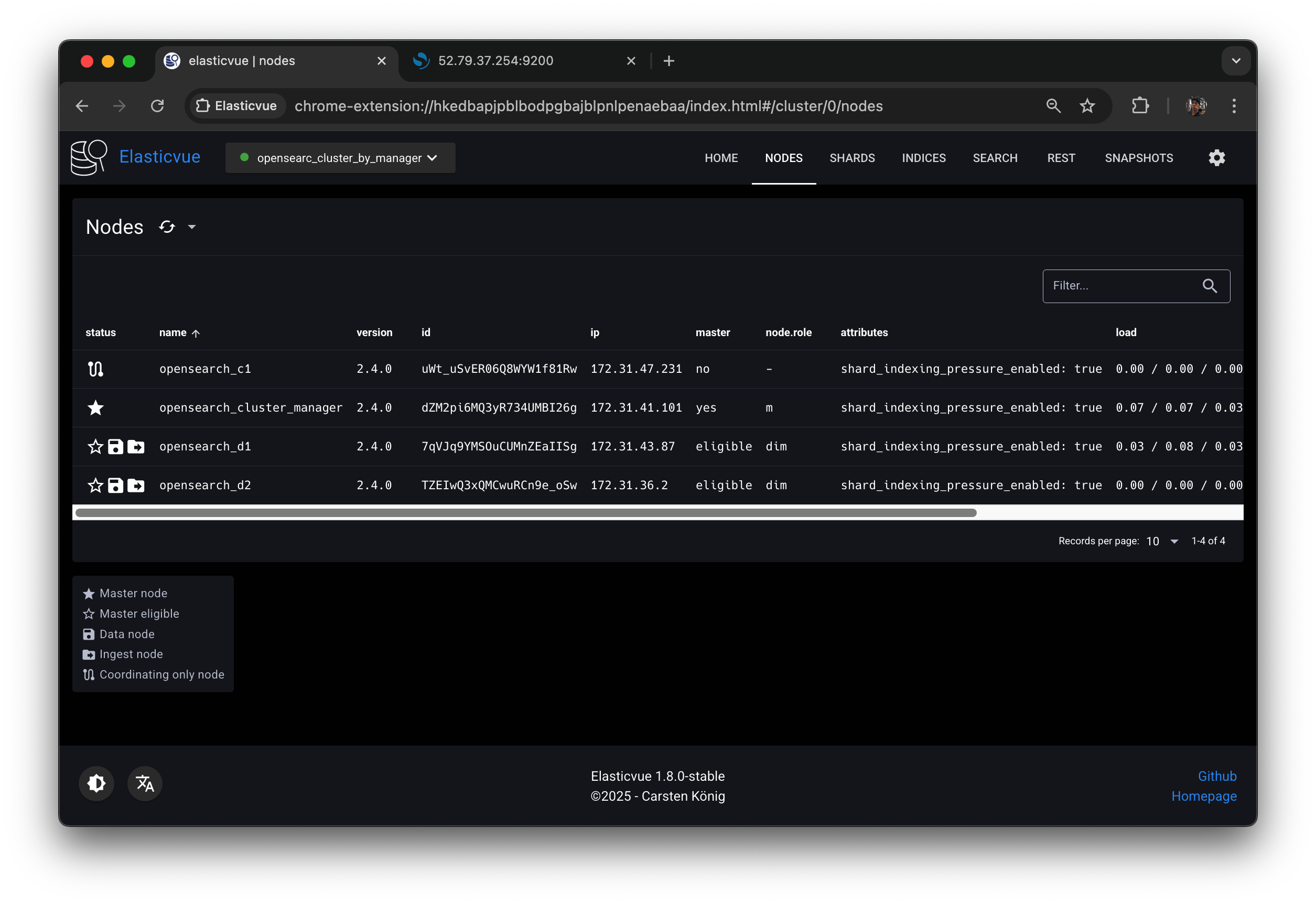
opensearch_cluster_manager 노드가
master yes,
opensearch_d1,opensearch_d2 노드들이
master eligible 이 되었다.
모든 노드가 클러스터링된 것을 확인한 다음 opensearch-cluster_manager 노드를 다시 중지시켜보자.
sudo systemctl stop opensearch.servicedata2에서 로그를 확인해보자
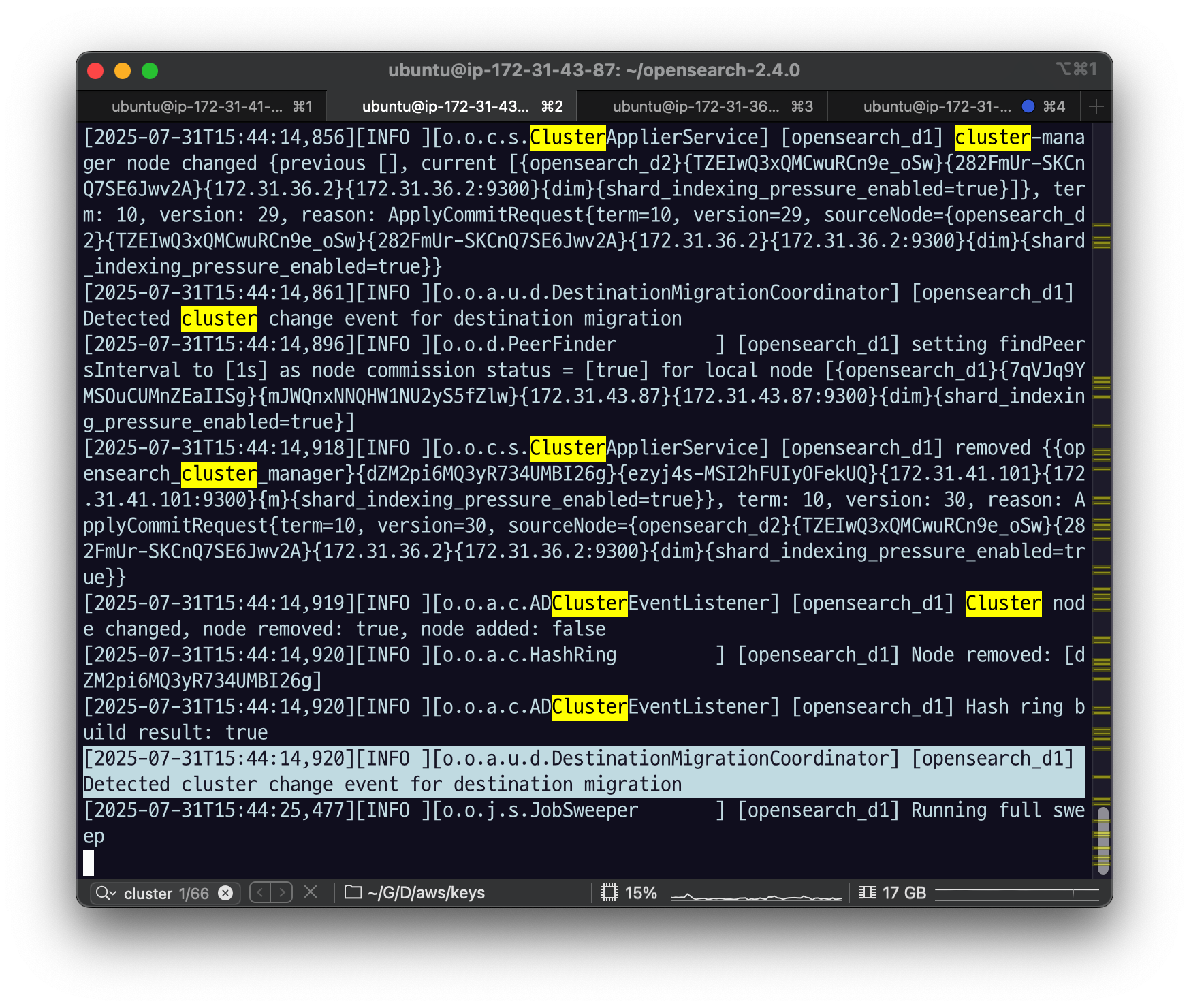
cluser의 상태가 변경되었다는 로그가 나옴.
Elasticvue에서, manager server는 접근이 불가능하니까 안될 거고,
코디네이터로 접속을 해보면
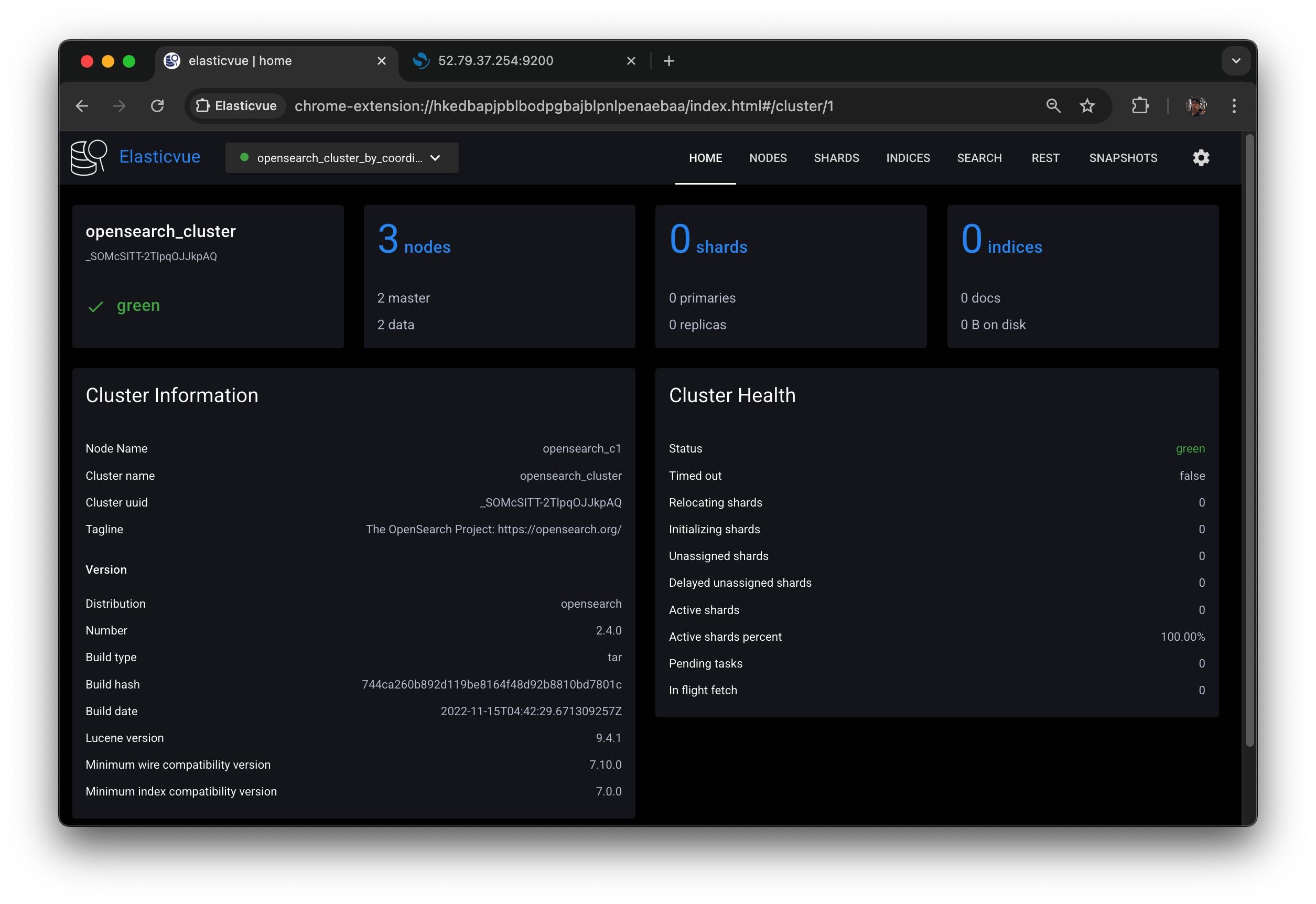
- 아까는 eligible이 하나였을 때, 매니저를 죽였을 때,
클러스터 상태를 조회하지 못했었다. 그런데 이번에는 조회를 할 수 있다
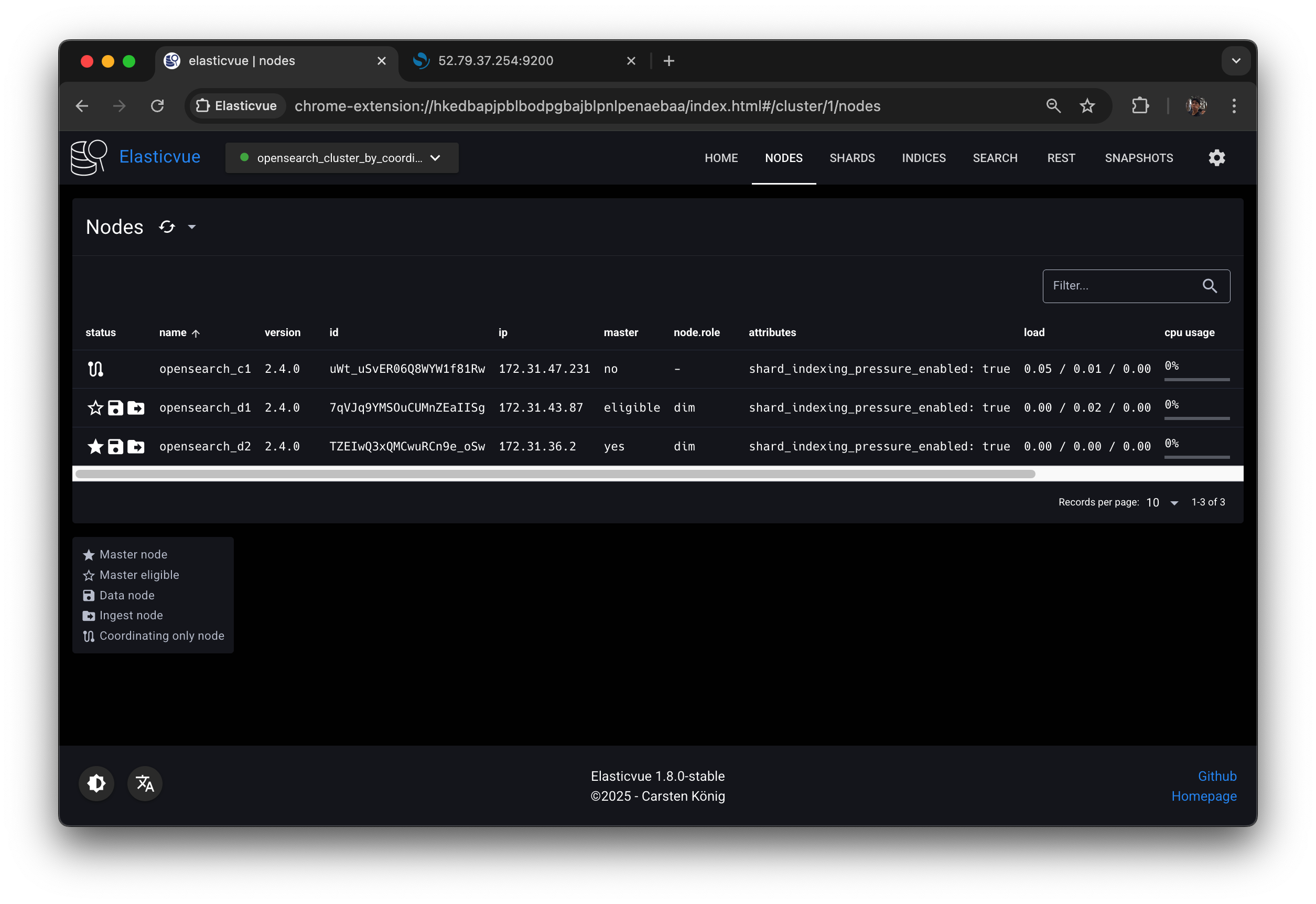
d1은 eligible 그대로고, d2가 매니저로 선택된 것을 확인할 수 있다.
Elasticvue의 NODES 탭을 새로고침하면 다음과 같이 opensearch-d1 (또는 opensearch-d2 ) 노드가 매니저 노드로 선출된 것을 확인할 수 있다.
이 상태에서 opensearch-cluster_manager 노드를 다시 클러스터에 참여시키려면 discovery.seed_hosts를 다음과 같이 수정하고 노드를 재시작해줘야 한다.
discovery.seed_hosts: ["<DATA2_NODE_PUBLIC_IP>"]opensearch-cluster_manager 노드가 다시 클러스터에 참여해도 이미 선출된 매니저 노드는 바뀌지 않고, 그대로 opensearch-d1 노드인 것을 확인할 수 있다.
안전한 클러스터 운영을 위해 클러스터 매니저 후보 노드는 최소 3개 이상(클러스터 매니저 노드 포함)으로 설정하는 것이 좋다. 또한 discovery.seed_hosts에는 모든 클러스터 매니저 후보 노드를 포함시키는 것이 좋다.
OpenSearch와 달리 ElasticSearch의 경우 7.3 버전부터 투표 전용 노드 타입을 지원한다.
클러스터 매니저 후보 노드 중에서 매니저 선출 투표에는 참여할 수 있지만, 본인은 매니저 노드가 될 수 없는 노드를 투표 전용 노드라고 한다.
투표 전용 노드는 매니저 노드가 될 수 없기 때문에 매니저 후보 노드보다 부담없이 사용할 수 있으며, 대다수의 매니저 후보 노드들에 장애가 발생했을 때도 매니저 후보 선출 과정이 정상적으로 진행될 수 있도록 돕는다.
ElasticSearch에서 투표 전용 노드를 만들고 싶다면 node.roles를 다음과 같이 설정해주면 된다.
node.roles: [ cluster_manager, voting_only ]3.4.4 인제스트 노드 파이프라인 설정
클러스터에서 인제스트 타입은 데이터를 넣을 때 전처리 과정을 해주는 전용 노드라고 했었는데 데이터 노드에서 수행하면 데이터 조회나 저장이 지연될 수 있으니 전처리는 따로 처리하기 위해서 CPU위주 작업이고, 인제스트 노드로 구성해서 데이터를 벌크로 밀어넣을 때, 인제스트 노드로 밀어넣는다.
PUT /_ingest/pipeline/test-pipeline API로 인제스트 파이프라인을 생성할 수 있다. Elasticvue의 REST 클라이언트를 사용해서 요청해보자.
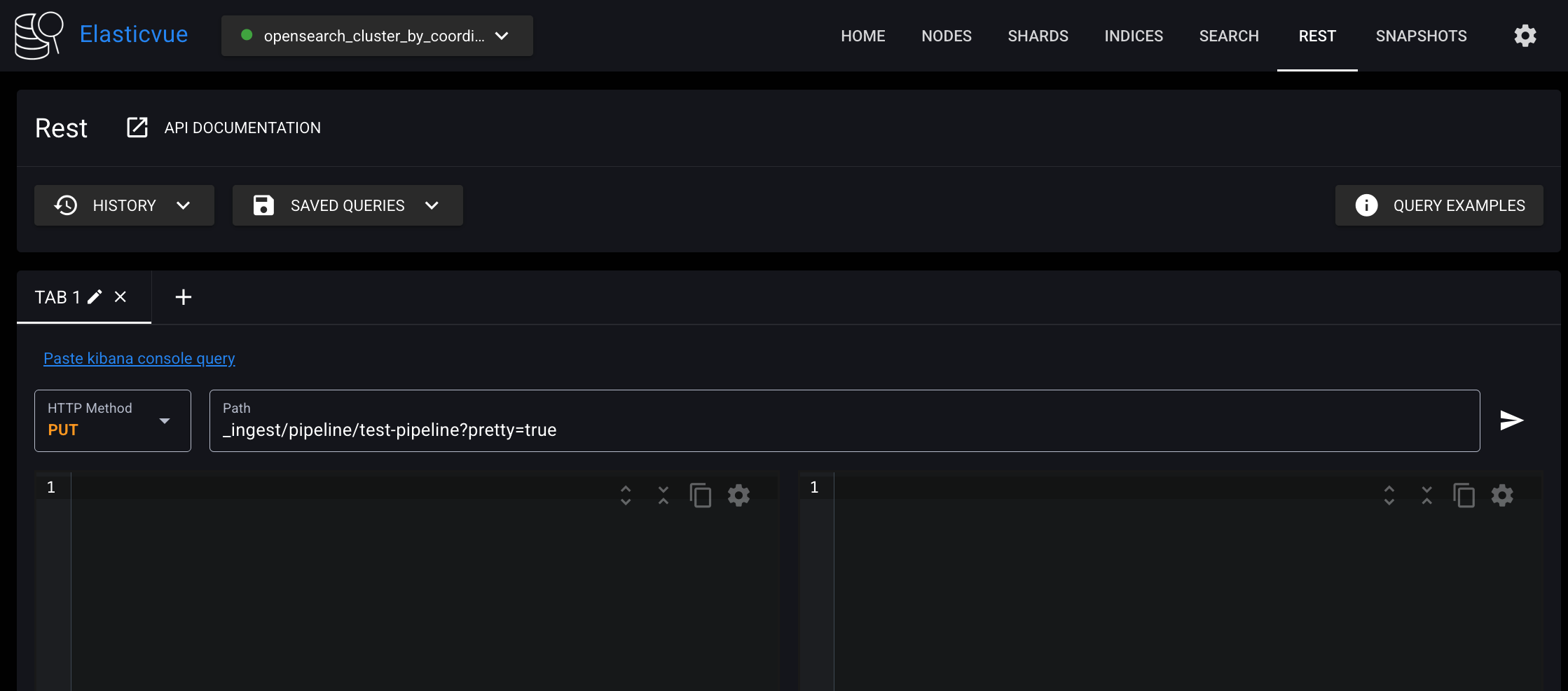
요청 본문에서 processors 필드는 리스트 타입으로, 여러 개의 프로세서를 정의할 수 있고, 해당 프로세서들은 리스트에 정의된 순서대로 실행된다. set 프로세서는 특정 필드의 값을 추가 또는 수정하는 작업을 수행하고, lowercase 프로세서는 string을 소문자로 변환하는 작업을 수행한다.
$ curl -XPUT "$OPENSEARCH_REST_API/_ingest/pipeline/test-pipeline?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"processors": [
{
"set": {
"field": "field1",
"value": 10
}
},
{
"lowercase": {
"field": "field2"
}
}
]
}
'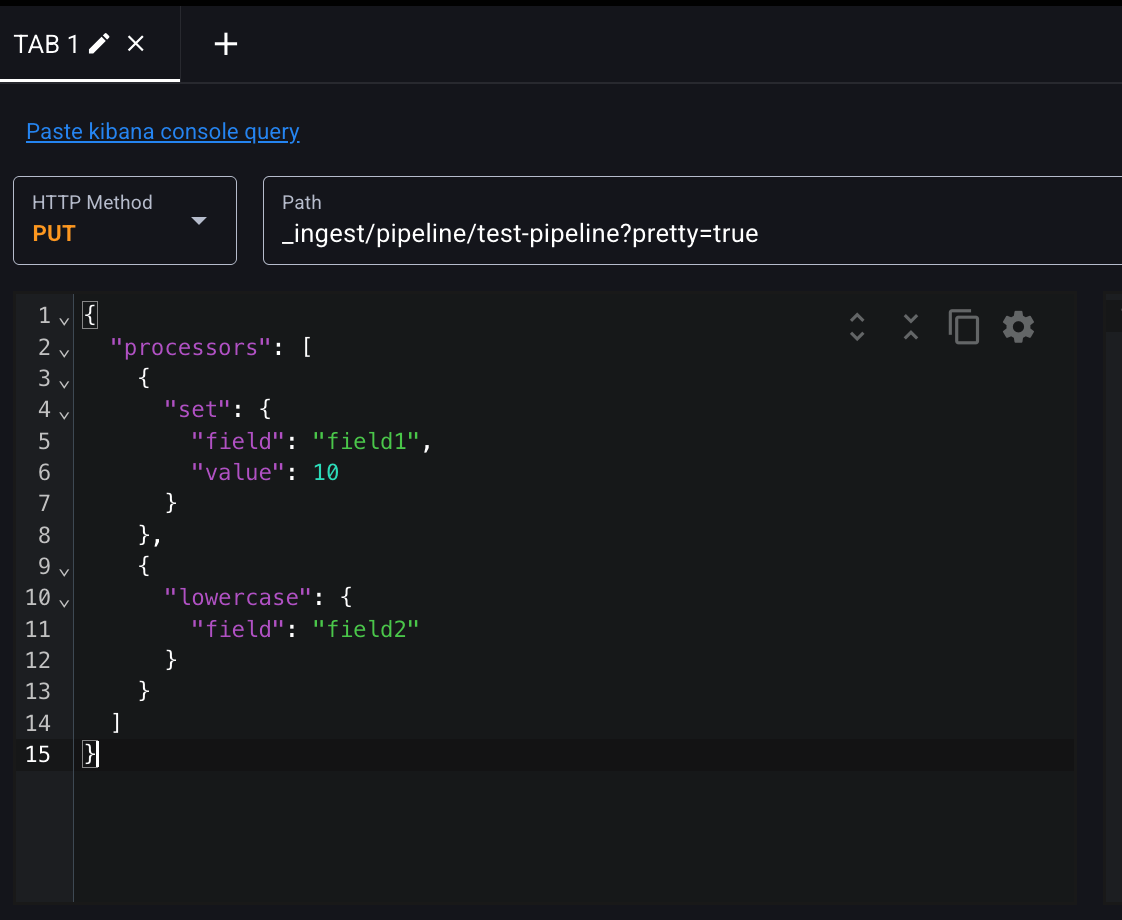
set : 특정 필드의 값을 내가 추가하거나 수정한다. (세팅 작업할 때) 필드가 오고 필드 value어떻게 하겠다.
lowercase : 내가 지정한 필드에 대해 소문자로 변환하겠다는 것
test-pipeline 파이프라인을 사용해서 도큐먼트를 test1 인덱스에 인덱싱해보자.
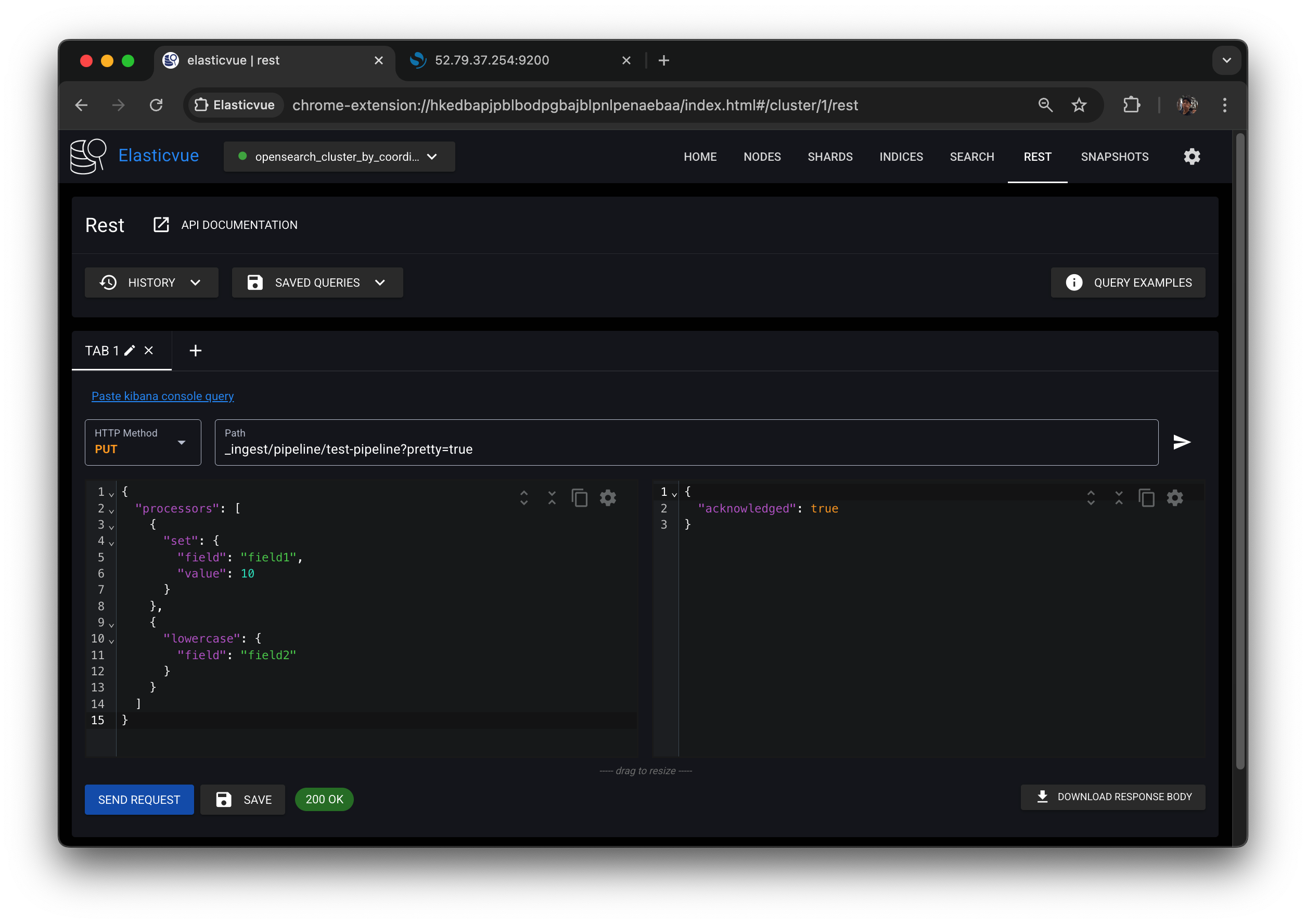
SEND REQUEST 버튼 클릭하면 오른쪽 같이 응답 결과가 json 형식으로 나온다.
ack = true 나오면 적용은 잘 된 것.
이 파이프라인이 적용된 인덱싱을 한 번 해보자.
field1 에 set을 적용했고,
field2 에 lowercase를 적용했으니
해당 내용들을 확인할 수 있도록 필드1은 test라는 글자, 필드2는 대문자와 소문자 섞인 글자들을 넣었다.
curl -XPUT "$OPENSEARCH_REST_API/test1/_doc/1?pipeline=test-pipeline&pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"field1": "test",
"field2": "Hello, OpenSearch!"
}
'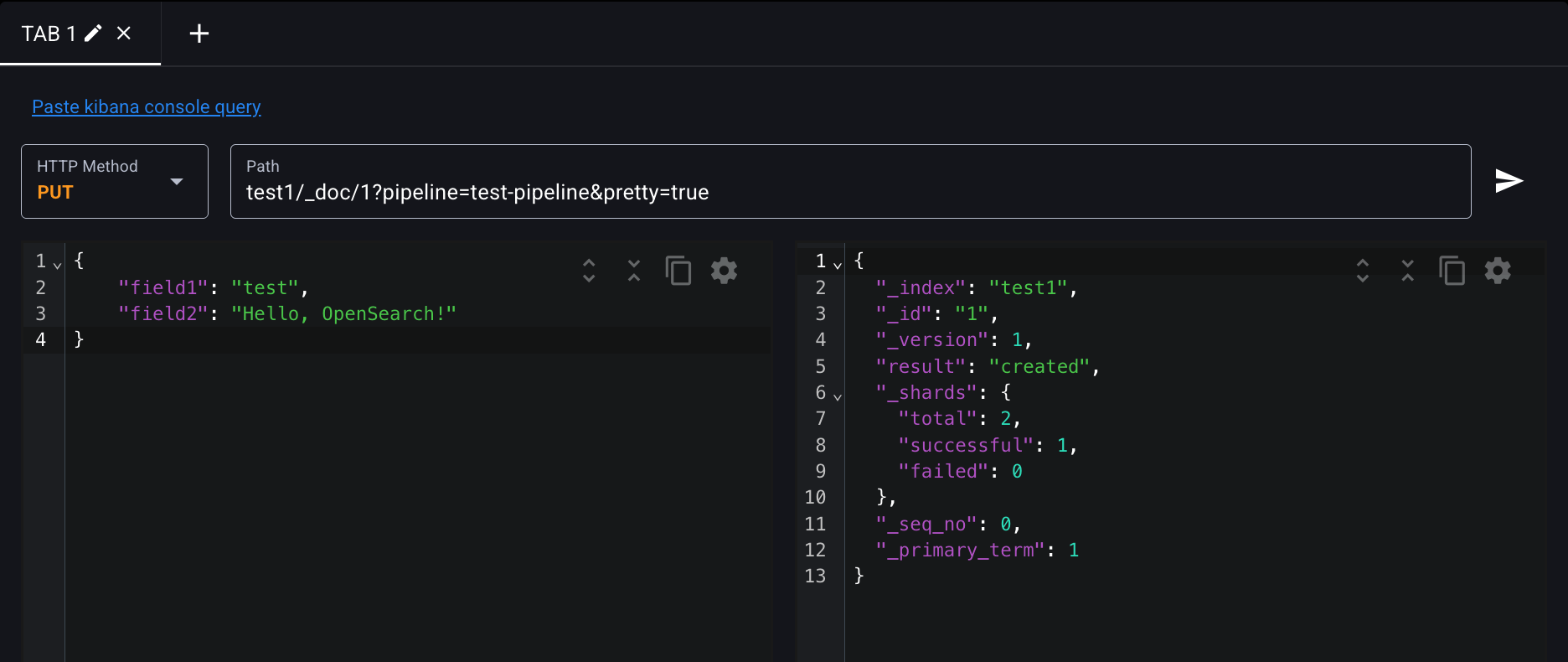
SEND REQUEST 누르면 result : created 결과가 나오게 된다.
인덱싱한 도큐먼트의 field1은 10으로, field2는 모두 소문자로 변경된 것을 확인할 수 있다.
그러면 이거를 조회를 해보자.
HTTP Method : GET
Path : test1/_doc/1?pretty=true
SEND REQUESET 누르면
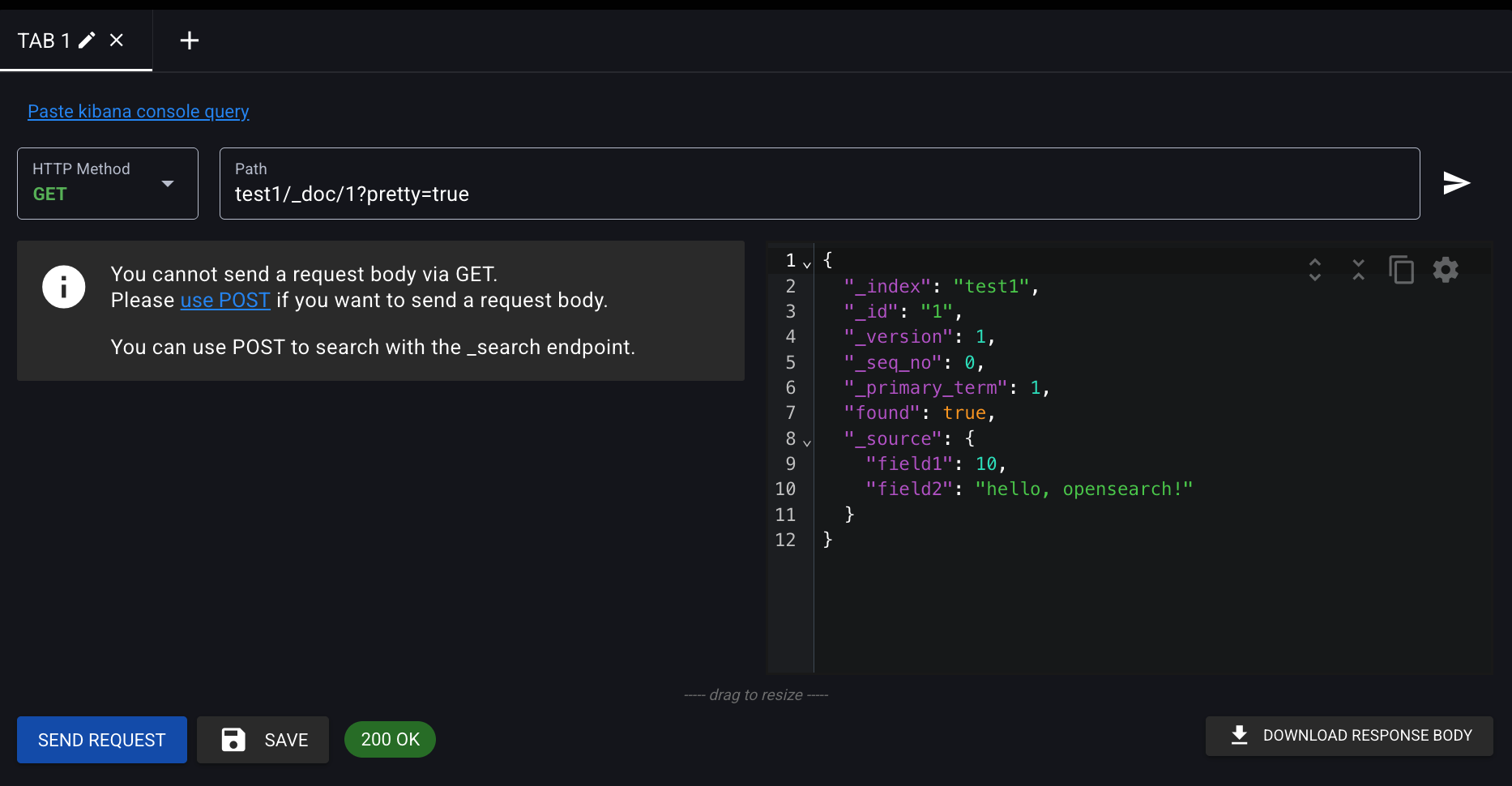
index : test1이고
데이터 내용을 보면
field1은 10, 아까 프로세스에서 SET 으로 아예 값 자체를 덮어 썼음.
field2는 대문자가 전부 사라진 모습
