2 HBase 구성요소
2.1 배경
2.1.1 BigTable 이전
2003년, 구글의 GFS - https://research.google/pubs/pub51/
MapReduce - https://research.google/pubs/pub62/
GFS + MapReduce로 구글이 보유하고 있는 전체 검색 색인을 포함한 대용량 데이터 처리의 중추를 담당했다.
- 적은 수의 큰 파일에는 적합하지만, 수백만개의 작은 파일을 처리하는 데는 부적합하다.
- 마스터 노드의 메모리에 유지하고 있는 데이터는 궁극적으로 파일 수에 의존하기 때문에.
- 파일 수가 많아질수록 마스터 노드의 메모리에 가해지는 압박이 한층 더 심해진다.
그래서 웹서비스에서 사용할 수 있는 실시간에 준하는 데이터 접근이 가능해야 했다.
2.1.2 BigTable
2006년 BigTable - http://static.googleusercontent.com/media/research.google.com/ko//archive/bigtable-osdi06.pdf
- 이것이 결국 HBase를 뒷받침 하는 틀이 됨
- 빅테이블은 거대하게 확장할 수 있도록 구조화된 데이터를 관리하는 분산 저장 시스템이다.
- 희소하고, 분산형이며, 영구 저장식 다차원 정렬 맵이다.
왜 희소 구조가 장점인가?
1. 저장 공간 절약 : 값이 없는 셀을 저장하지 않음
2. 확장성 : 새로운 컬럼이 추가되더라도 기존 스키마 전체를 바꿀 필요 없음
3. 유연성 : 서로 다른 row가 서로 다른 column set을 가져도 됨
HBase와 Bigtable 개념 연결
- 분산형(distributed)
- HBase는 Region 단위로 데이터를 쪼개고, 여러 RegionServer에 분산 저장한다. (Bigtable의 Tablet과 동일한 개념)
-
영구 저장식(persistent)
- 모든 데이터는 HDFS(Hadoop Distributed File System)에 영구 저장된다. (Bigtable은 GFS 사용)
-
다차원 정렬 맵(multidimensional sorted map)
- HBase의 데이터 접근도 Row Key + Column Family + Column Qualifier + Timestamp라는 다차원 좌표계 기반이다.
- 이 모델이 바로 Bigtable 논문에서 정의한 구조가 HBase로 그대로 구현된 사례이다.
- 정렬이 아예 되어 있어서 색인이 빠르다
Bigtable의 다차원 정렬 맵과 HBase의 관계
-
Row Key (행 단위 접근) → 1차원 축
- HBase에서 Row Key는 사전순 정렬(lexicographical ordering)을 따른다.
- 이는 Bigtable의 "Sorted Map" 특성과 동일하다.
- 덕분에 특정 범위(Row Key Range)에 대한 Scan 연산이 빠르게 수행된다.
-
Column Family와 Column Qualifier → 2차원 축
- Bigtable은 Row마다 수많은 컬럼을 가질 수 있는데, 컬럼이 Family 단위로 그룹화된다.
- HBase 역시 동일하게 Column Family → Column Qualifier 구조를 따른다.
- 이 덕분에 "희소성(sparsity)"이 보장된다: 값이 없는 Column은 물리적으로 저장하지 않는다.
-
Timestamp (Versioning) → 3차원 축
- Bigtable에서 각 Cell은 다수의 버전을 가질 수 있으며, Timestamp를 기준으로 정렬된다.
- HBase도 동일하게 Row + Column Family + Column Qualifier + Timestamp 조합으로 Cell을 식별한다.
- 이를 통해 "시간 축"이 추가된 4차원 좌표계처럼 동작한다.
즉, HBase의 데이터는 내부적으로 이렇게 좌표계에 의해 관리된다:
(Row Key, Column Family, Column Qualifier, Timestamp) → Value2.2 HBase 의 데이터 모델
2.2.1 데이터모델의 구성요소
HBase 에서는 가장 작은 하나의 record의 단위를 cell 이라고 표현한다.

https://miro.medium.com/v2/resize:fit:1400/format:webp/1*-LmF71rOWU9MnigYN_TSfg.png
{kind=link}
Cell은 record 단위고, 모든 것을 Byte 단위로 처리한다.
그 안에 의미 단위로 구성요소들이 있다.
Key Length , Value Length : 헤더 같은 것. int(4Byte)로 되어 있고
몇 번째 Byte부터 몇 번째 Byte까지 읽어야 Key/Value 구나 라는 걸알 수 있음
2.2.2 기본적인 특징
- 가장 기본단위는 컬럼
- 컬럼이 모이면 로우
- 로우는 로우키(row-key)라는 유일한 주소를 가진다.
- 로우가 다수 모이면 테이블을 이루고
- 다시 테이블은 여러개가 될 수 있다.
- 각 컬럼은 여러 개의 버전을 가질 수 있는데, 버전의 값은 각각 별도의 셀에 저장된다.
2.2.3 그 이상의 특징
-
모든 로우는 언제나 로우 키를 기준으로 사전식 정렬.(2진수 수준에서 바이트 단위로 왼쪽부터 비교)
- RDBMS 에서 PK와 같은 기능을 한다.
- +유일하다.
-
BigTable에는 단일 색인만 고려되었지만, HBase는 secondary index 기능이 추가되었다. (대량의 대이터들은 부하&부담 때문에 잘 사용하진 x)
2.2.4 로우는 컬럼으로 이루어진다.
- 컬럼은 차례대로 컬럼 패밀리로 그룹화된다.
- 컬럼패밀리는 데이터를 의미적으로 또는 주제별로 분류하게 해준다.
- 그룹화된 데이터에 압축이나 메모리 상주 같은 특정 기능을 적용하게도 해준다.
- 컬럼패밀리 안의 모든 컬럼은
HFile이라는 하나의 저수준 저장파일에 함께 저장된다.
2.2.5 컬럼패밀리는..
- 테이블이 생성될 때 정의되어야 함.
- 빈번하게 변경되지 말아야 함.
- 수가 너무 많아서도 안 됨.
- 훨씬 적은 수로 제한된다.
- 출력 가능한 문자로 구성 되어야 함.
2.2.6 컬럼은..
CF:{qualifier}형태로 사용- 컬럼은 반드시 컬럼패밀리(Column Family) 이름과 컬럼명(qualifier)을 조합한 형태로 지정된다. 예를 들어 info:name에서 info가 컬럼패밀리, name이 컬럼명이다. 이 구조 덕분에 관련 컬럼들을 그룹화하고 효율적으로 저장·조회할 수 있다.
- 어떤 byte array라도 쓸 수 있다.(empty도 가능)
- 컬럼에 저장되는 값은 문자열, 숫자, 이미지, JSON 등 모든 형태의 바이트 배열을 허용한다. 즉, 정해진 데이터 타입에 구애받지 않고 자유롭게 데이터를 넣을 수 있으며, 값이 비어 있는(empty) 경우도 허용된다.
- 수에 제한이 없다.
- 한 로우(row) 내에 존재할 수 있는 컬럼 수에는 이론상 제한이 없다. 따라서 필요에 따라 수백, 수천, 수만 개의 컬럼을 동적으로 추가할 수 있다.
- 데이터 타입과 길이에도 제한이 없다.
- 컬럼 값의 타입이나 길이에 제약이 없으므로, 작은 문자열부터 수 MB 이상의 큰 바이너리 데이터까지 자유롭게 저장할 수 있다. 단, 실제 시스템 성능 및 저장소 한계에 따라 실무에서는 적절히 관리해야 한다.
모든 로우와 컬럼은 table context내에서 정의된다. 모든 컬럼패밀리에 대해 몇 가지 개념이 추가된다.
- 모든 셀(컬럼의 실제 값)은 타임스탬프를 갖는다. 시스템 내부적으로 할 수 있고, 사용자가 부여할 수도 있다.
- 셀 하나의 서로 다른 버전은 타임스탬프에 대해 내림차순으로 저장되어 최근의 값을 먼저 읽을 수 있다.
- 몇 개의 버전을 저장할지 결정할 수 있다. (보통 두 개 이상 두지 x)
- predicate deletion을 제공한다. - 삭제 룰(예. TTL)을 넣을 수 있다
- SQL에서 predicate는 WHERE 절, JOIN 조건 등에 쓰이는 불리언 조건식을 가리킴
- Java, Python 등에서는 참/거짓을 반환하는 함수를 가리킴
2.2.7 HBase에서 구현한 빅테이블 모델은 한 마디로
- 희소(sparse)하고, 분산형이며, 영구저장식 다차원 맵이며, 로우키, 컬럼키, 타임스탬프로 색인된다.
- 이들을 조합하면
(Table, RowKye, ColumnFamily, Column, Timestamp) -> value- 위 값들이 있어야 value를 찾을 수 있다.
- 프로그래밍 언어로 표현하면
SortedMap< // Table
Rowkey, List<
Sortedmap< // Column Family
Column, List< // list of Cell for a column
Value, Timestamp
>
>
>
>2.3 Web Table 사례
인터넷 주소를 색인하는 시스템.
빅테이블 및 HBase의 전통적인 사용 사례.
웹테이블은 인터넷을 크롤링하는 도중 수집되는 웹페이지들을 저장한다.
rowkey: inversion of url (e.g. org.hbase.www)
CF(Column Family): contents, anchor, inbound, language
content CF에서 다중버전 기능을 활용하면 HTML의 예전 버전 몇 개를 저장할 수 있고, 이를 이용하면 어떤 페이지가 얼마나 자주 갱신되는지 여부 등의 분석자료로 활용할 수 있다.
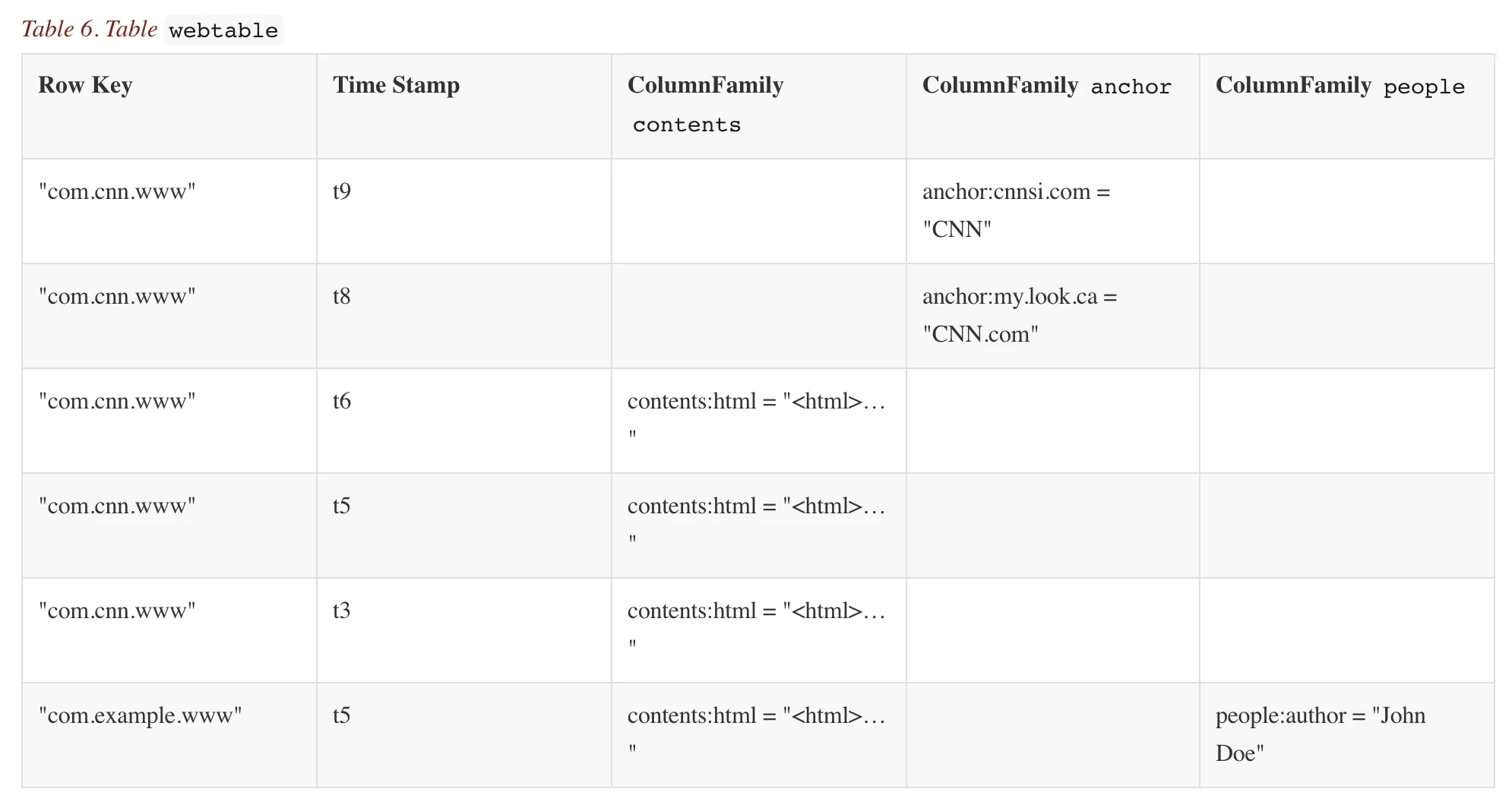
- 실제로 저장할때에는 빈 공간은 생기지 않는다.
물리적으론 column Family로 저장한다.
column Family : anchor

column Family : contents

2.4 Region과 자동 샤딩
Region은 HBase의 확장성 및 로드밸런싱의 기본 단위다.
- 리전은 기본적으로 함께 저장된 인접한 범위의 로우들이다. (101-199, 200-299, ...)
리전이 너무 커지면 시스템에 의해 동적으로 분할된다.
- 리전의 수 및 필요한 저장 파일의 수를 줄이기 위해 합쳐지기도 한다.
- RDBMS sharding 에서 사용되는 range partition과 동일한 용어다.
steps
- 최초에는 리전이 하나.
- 시스템은 하나의 리전이 설정된 최대 크기를 넘지 않도록 모니터링
- 리전의 크기가 한계를 넘으면 중간값에서 둘로 분리되어, 대략 동일한 크기의 두 개의 리전을 생성
- 각 리전은 딱 하나의 리전 서버에서 운용, 각 서버는 많은 리전을 운용가능.
💡 빅테이블 논문에서는 리전 개수를 서버당 10-1000개로, 각 리전의 크기를 100-200MB로 목표했다. 하지만 HW스펙의 변화에 맞춰갈 필요가 있음.
현대의 장비로는 HBase 는 리전의 개수는 빅테이블 논문수치와 비슷하지만, 각 리전의 크기는 1G-2G 정도.. 지금은 더 할 수 있음
리전의 분할은 거의 즉각적일 정도로 매우 빠르다.
- 압축 작업이 분할된 리전을 별도의 파일에 비동기적으로 재작성할 때까지는 단순히 원래의 저장 파일에서 접근되기 때문에.
- 분할되어도 기존 저장 파일에 대한 접근은 그대로 유지되며, 새로운 리전용 파일로 압축 작업(compaction)이 비동기적으로 진행될 때까지 기존 데이터에서 바로 읽을 수 있기 때문이다.
분할 자체는 메타데이터 수준에서 즉시 처리되고, 실제 파일 재작성은 백그라운드에서 천천히 진행되는 구조이다.
2.5 저장소 API
기본적으로 설정할 수 있는 모든 것이 API에 있다.
scan
- 로우의 특정 범위를 효과적으로 iterate할 수 있는 API
- 반환된 컬럼, 또는 셀의 버전 개수를 제한할 수 있다.
- 필터로 컬럼 비교도 할 수 있고, start/end 지정한 시간 범위 사용해서 버전 선택할수도 있다.
고급기능
- 단일 row transaction 지원.
- 하지만 안 씀 ...ㅋ
- API를 이용하는 수준에서 row 단위의 atomicity가 보장된다고 보면 됨
- 셀(Cell)의 값을 단순 데이터 저장소로만 쓰는 것이 아니라 카운터(counter)로 활용할 수 있다.
incrementColumnValue같은 연산을 사용하면, 원자적(atomic)으로 읽고 바로 갱신이 가능하다.- 여러 클라이언트가 동시에 같은 카운터 셀을 갱신하려고 해도 충돌 없이 안전하게 동작한다.
- 한 번, 연산으로 일기 후 갱신될 수 있으니까 강력한 전역 카운터를 가질 수 있다.
- 클라이언트에서 제공한 코드를 서버의 주소공간(address space)에서 실행할 수 있는 옵션도 있다.
- coprocessor
- 클라이언트가 요청한 스캔 범위의 데이터 블록을 서버에서 먼저 선처리한 후, 그 결과만 클라이언트로 전송하면, 클라이언트는 적은 양의 데이터로 추가 작업을 수행할 수 있다
- 경량 일괄처리 작업 구현에 사용가능
- 연산자 바탕으로 데이터 분석하거나 요약하는 표현식 사용가능
- coprocessor
- MapReduce와 통합해서 사용가능 - 테이블을 맵리듀스 잡의 입력값으로 변환, 타깃을 산출하는 wrapper제공.
데이터로의 접근은 선언적(declarative)하지 않고, 클라이언트 API를 통해서 명령적(imperitive)하다.
- 결국 Byte단위로 scan 해봐야 아니까.
2.6 구현
HBase에서는 모든 데이터가 HFile에 영구 저장된다.
데이터는 HFile 이라는 파일에 저장된다.
- 데이터는 key-value 쌍으로 고정되어 있으며, 한 번 기록되면 변경되지 않는다.
- 저장 시 key 기준으로 정렬되어 있어 범위 탐색(range scan)이 효율적이다.
- HFile끼리도 정렬되어 있다.
- HFile 내부는 연속적인 블록으로 구성되어 있고, 각 블록에 대한 색인(index)이 파일 끝에 기록된다.
- 파일이 열리면 색인(index)은 메모리에 로드되어 빠른 랜덤 접근을 지원한다.
- O(1)에 찾아갈 수 있게 함
- HFile은 특정 key 접근뿐 아니라 시작 key와 끝 key를 지정하면 해당 범위의 데이터를 탐색할 수 있는 API도 제공한다.
모든 HFile이 블록 색인을 가지고 있으므로, 검색은 단 한 번의 디스크 판독으로 수행된다.
- 검색대상인 key를 가질 것으로 예상되는 블록을 지정한다.
- 이것은 메모리에 저장되어 있는 블록 색인에서 binary search(이진 탐색)을 통해 결정한다.
이 특징이 RDBMS와 가장 큰 차이점이고, 거기서 대용량 데이터를 저장하고 있는 시스템 하에서 검색 성능이 일관되고 빠르게 나올 수 있는 것이 가장 큰 차이점.
- 디스크에서 블록을 읽어 들여 실제 키를 얻는다.
이 HFile은 HDFS에 저장되어있다.
Scalable (확장성):
HDFS는 데이터를 여러 노드에 분산 저장하므로, 데이터 양이 늘어나도 클러스터에 새로운 노드를 추가하여 쉽게 저장 공간과 처리 용량을 확장할 수 있다. HFile 역시 이러한 분산 환경에서 자동으로 분산 저장되므로, HBase 전체의 데이터 규모가 커져도 효율적으로 관리할 수 있다.
Permanent (영속성):
HDFS는 데이터를 복제(replication)하여 저장하므로, 노드 장애가 발생해도 데이터가 손실되지 않는다. 따라서 HFile에 저장된 데이터도 안정적으로 보존되며, 장애 복구 시에도 안전하게 재현할 수 있다.
즉, HFile이 HDFS 위에 존재한다는 사실만으로 대규모 데이터 관리와 장애 내성이라는 두 가지 장점을 모두 누릴 수 있는 구조가 된다.
데이터가 갱신되면
- WAL(write-ahead log)에 쓰여진다. - HBase에서는 commit log라고 한다.
- 데이터는 이후 메모리 상의 memstore에 저장된다.
- 메모리상의 데이터가 설정된 최대 값을 넘어서면(memstore가 가득 차면) 디스크에 HFile로 flush된다.
- flush 이후에는 커밋로그에서 flush된 부분을 삭제할 수 있다.
- memstore → Disk 로 flush하는 동안에도 읽기/쓰기 연산을 중단없이 수행할 수 있다.
a. memstore를 메모리 안에서 계속 교체하므로 가능하다.- 꽉 찬 기존의 mem-table이 File로 변환되는 사이에 비어있는 새 멤테이블이 갱신된 내용을 받는다.
- memstore에 저장된 데이터는 이미 디스크상의 HFile과 정확히 맞아 떨어지는 키에 의해 정렬되어있으므로 추가적인 정렬이나 기타 특별한 처리가 필요 없다.
💡 빅테이블에서 이야기하는 '집약성'의 의미를 알 수 있다.
모든 파일은 키에 의해 정렬된 key-value 쌍으로 되어있다. 그래서 정렬된 순으로 읽어들이는 블록 단위 연산에 유리하다.
그래서 키를 설계할 때, 관련성 있는 데이터들을 모아둘 수 있는 키를 지정해야한다.앞선 웹테이블 예제에서. 뒤집은 FQND으로 키를 설계한 이유가 여기에 있다.
www.hbase.org
block.hbase.org
xxx.hbase.org
등이 org.hbase.XXX 의 키 설계에 의해서 인접하게 정렬되기 때문이다.
저장파일은 고정 불변이다.
- 값을 삭제할 때 단순히 파일에서 key-value 쌍을 제거할 수 없다.
- 해당 키가 삭제되었음을 나타내는 표시를 한다.(*tombstone marker) - window 가 내부적으로 파일 삭제할 때 하는 기법.
- 읽기를 수행할 때, 이 삭제 표시가 되어있다면 제외하고 반환한다.
데이터를 다시 읽을 때는,
- memstore에 저장된 내용과, disk에서 읽은 내용을 통합해서 전달한다.
- 데이터를 읽을 때는 WAL(Write ahead log)이 사용되지 않는다.
- WAL는 memstore → Disk 되기 전에 서버가 고장 났을 때의 복구를 위해 존재한다.
HFile이 점점 많아지면..
compaction을 이용해서 파일들을 큰 파일로 병합하는 housekeeping기능을 수행한다.
- minor compaction
- n-way compaction 이라고도 함
- 작은 여러개의 파일을 하나의 큰 파일에 다시 쓴다. → 파일 개수를 줄인다.
- 각각의 HFile 내부는 모두 정렬되어있으므로 병합할 때 재정렬 할 필요가 없다.
- 대신 file I/O를 하므로 디스크 입출력 성능에만 영향을 미친다.
- major compaction
- 하나의 리전 안의 컬럼패밀리 하나를 구성하는 모든 파일을 새로운 파일 하나로 다시 쓰는 작업을 수행.
- 모든 key-value쌍을 탐색하므로 삭제 표시가 달린 데이터를 지울 수 있다.
- 술어적 삭제도 여기서 처리된다.
- TTL 지났거나, versioning 한도에 찼을 경우 마킹만 되는데, 실제 삭제는 여기서 된다. 컴퓨터 점유하고 있는 바이트가 삭제되는 것은 이곳.
💡 이 compaction 방법은 LSM트리의 방법과 비슷하다.
차이점은, LSM 트리가, 디스크 상에 B-Tree와 같은 구조로 배열된 다중페이지 블록에 데이터를 저장한다는 것이다.
하지만 LSM 트리처럼 전체 멤스토어가 새로운 저장파일로 병합되는 작업이 즉시 이루어지지 않는다.
좀 다르게 말하면, HBase의 설계를 Log-Structured Sort-and-Merge-Maps 라고 할 수도 있다.
배경작업인 컴팩션 작업은 LSM트리의 병합에 해당하지만, LSM트리라는 이름이 붙여진 이유가 되는 부분 트리를 갱신하는 작업 대신 저장 파일 계층에서 발생하기 때문이다.
LSM트리란?
마스터 서버의 역할
- 리전 서버에 리전을 할당
- 이 작업을 위해서 주키퍼를 사용
- 리전 서버 간에 리전의 부하 분산을 처리하는 역할
- 과부하가 걸린 서버의 부하를 덜어주고
- 여유공간이 많은 서버에 리전을 옮긴다
- 데이터가 거쳐가는 경로는 아니다. 마스터 서버는 관리하는 역할만.
- 테이블 및 컬럼패밀리의 생성 같은 스키마 변경 및 기타 메타데이터 작업을 수행한다.
2.7 HBase 의 주요특징 정리
페타바이트 급 저장소로 좋은 이유
- 부하 분산
- 부하 분산이 리전 단위로 manual 하게 작업하지 않아도 자연스럽게 된다.
- 정렬된 로우 - 인접한 key-value를 읽는데 좋음
- 저장 수준부터 모두 정렬이 되어 있으니 인접한 key-value 찾을 때, bulk로 읽을 때 좋다.
- 블록 입출력 작업에 최적화
- 대용량에 좋다
검색
- 검색테이블 스캔에는 O(n),
- Row-key scan O(log n)
- 극단적인 경우(블룸필터를 사용) O(1)
확장 가능한 스키마
- 락을 완전히 배제
- 로우 수준의 원자성 (API을 썼을 때)
컬럼 지향 구조
- NULL의 저장공간이 필요 없기 때문에 wide,sparse한 테이블 설계 가능
로우 수준의 원자성
- 단 하나의 서버에서만 운용되므로 일관성
- 충돌 회피
- 변경이력을 유지할 수 있다.
