3 HBase 아키텍처
3.1 탐색 대 전송
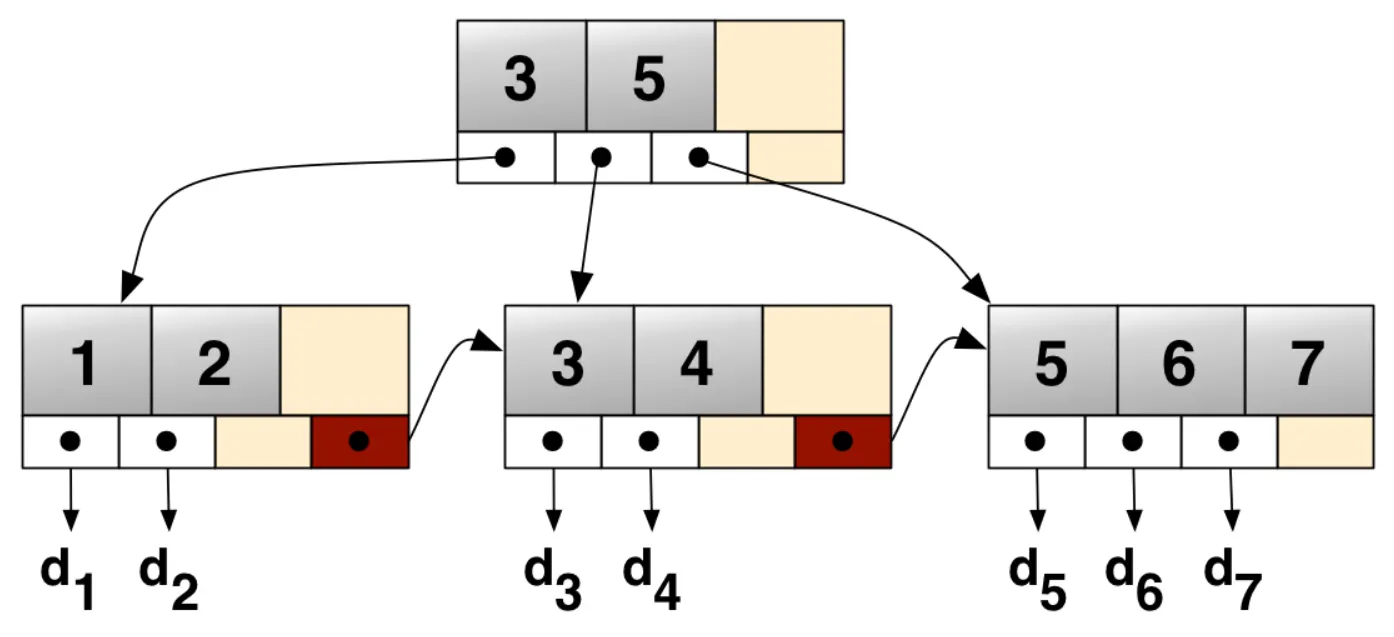
3.1.1 B+ 트리
RDBMS에서 데이터 찾을 때 인덱싱하는 방식
https://medium.com/@nayakdebanuj4/bw-trees-also-known-as-buzz-word-trees-7de93f70cce8
그림에는 next만 있지만, 보통은 prev, next 포인터 다 있음.
이는 동적이며, 각각의 인덱스 세그먼트 (보통 블록 또는 노드라고 불리는) 내에 최대와 최소범위의 키의 개수를 가지는 다계층 인덱스(multilevel index)로 구성된다.
B트리와 대조적으로 B+트리는, 모든 레코드들이 트리의 가장 하위 레벨에 정렬되어있다. 오직 키들만이 내부 블록에 저장된다.
B+트리에서 중요한 가치는 블록-지향적인 storage context(예: filesystem)에서 검색을 효율적으로 할 수 있다는 점이다. 바이너리 서치 트리에 비해 B+트리 노드의 fanout(한 노드의 자식 노드의 수)이 훨씬 높아서 검색에 필요한 I/O 동작 회수를 줄일 수 있기 때문이다
장점
- 범위 스캔에 효율적이다. (모든 키가 정렬된 리스트)
- 페이지 단위의 집약성을 보장한다.
- B+트리를 기반으로 하는 대부분의 제품에 OPTIMIZE TABLE명령이 있다.
- 테이블을 정렬해서 디스크 상의 연속된 공간에 다시 저장해서 범위검색의 효율성을 높인다.
리프페이지에 저장되어 있는 정보
[prev page link]
[next page link]
key1 -> rowid1
key2 -> rowid2
key3 -> rowid33.1.2 LSM 트리
HBase 에서 데이터를 찾을 때 인덱싱 하는 방식과 가장 유사함.
메모리 → 파일 단계
- 입력되는 데이터는 모두 로그파일에 순차적으로 저장된다.
- 인메모리 저장소를 최신 값으로 갱신한다.
- 인메모리 저장소가 가득 차면 디스크에 새로운 파일을 생성해서 정렬된 key→record 쌍을 메모리에서 비우면서 파일에 저장한다.
- 파일에 저장된 데이터는 로그 데이터에서 삭제할 수 있다.
하나의 페이지 블록에 가득 차는 단계
- 저장파일은 B-트리와 비슷하게 정렬되지만, 모든 노드가 완전히 채워지고 나서 단일 페이지나 복수 페이지 블록처럼 저장되어서 순차적 디스크 접근에 최적화된다.
- 저장 파일의 갱신은 단계적 병합(rolling merge)방식으로 수행된다.
- 비워진 인메모리 데이터를 기존 디스크 상의 복수 페이지 블록이 용량 한계에 도달할 때 까지 추가한 후, 새로운 페이지 블록을 생성한다.
여러개의 블록 파일이 병합되는 단계
- 백그라운드 프로세스가 파일을 종합해서 더 큰 파일로 변환
변경사항의 적용
- 디스크상의 트리가 분할될 수 있다. (여기서 리전이 분할될 수 있는 게 나옴)
- 모든 저장 파일은 항상 키를 기준으로 정렬되므로 새롭게 추가되는 키를 기존의 키 사이에 위치시키기 위한 재정렬은 필요 없다.
탐색
- 병합해서 client에게 전달
- 인메모리
- 디스크
삭제
- delete marker를 저장한다.
- 탐색할 때 delete marker 노드를 건너 뛴다.
- 이 노드는 페이지가 비동기적으로 다시 쓰여질 때 최종적으로 버려진다.
predicate deletion: house keeping을 위한 백그라운드 포르세스에서 처리하는 것
- 병합프로세스에서 predicate를 검사하고 true면 새로작성되는 블록에서 해당 레코드를 제외한다.
3.1.3 탐색 대 정렬 병합 (Search vs Sort-Merge)
배경
- CPU, RAM 성능은 무어의 법칙에 따라 빠르게 개선되고 있지만, 디스크 I/O(특히 random seek) 속도는 상대적으로 크게 발전하지 못했다.
- CPU/RAM: 16~24개월마다 2배 증가
- 디스크 탐색 속도: 매년 약 5% 증가
이로 인해 디스크 접근 패턴이 데이터베이스 성능의 핵심 병목이 된다.
두 개의 데이터베이스 패러다임
- 탐색(Search) 기반 접근
-
전통적 RDBMS, B-트리 / B+트리 인덱스
-
특징
- 레코드 단위의 무작위 탐색(Random Seek)을 수행
- 각 접근마다 log(N) 시간이 소요
- 결국 전체 성능은 디스크 탐색 속도에 의해 제한됨
- 전송(Transmission) 기반 접근
-
LSM(Log-Structured Merge) 트리 계열 DB (예: HBase, Cassandra)
-
특징
- 데이터를 모아서 정렬 후 일괄 병합(Merge Sort)
- 순차 읽기/쓰기(Sequential I/O) 중심 → 디스크 전송 속도에 근접
- 쓰기 비용은
log(갱신 수)수준 - 데이터가 전송되었다면 그 때 완료가 되었다고 보면 됨
계산 예시 (대규모 데이터 갱신 시)
조건
- Bandwidth: 10MB/s
- Disk Search Time: 10ms
- Record Size: 100B (100억 건 = 약 1TB)
- Page Size: 10KB (10억 페이지)
- 갱신량: 전체의 1% (1억 건)
갱신시 걸리는 시간
| 방식 | 시간 | 이유 |
|---|---|---|
| 무작위 B-트리 | 1000일 | 1억 건을 각각 random seek 필요. seek latency 누적. |
| 일괄처리 B-트리 | 100일 | 갱신을 모아서 batch 처리. seek 비용 감소했지만 여전히 탐색 지배적. |
| 정렬 병합(LSM) | 1일 | 데이터를 모아 정렬 후 순차 병합. bandwidth 한계까지 활용 가능. |
대규모 환경에서는 탐색 기반(B-트리)보다 전송 기반(정렬 병합)이 압도적으로 효율적이다
HBase 같은 분산 DBMS가 LSM 트리를 채택하는 이유도 바로 이 점 때문이다.
즉, 디스크 탐색 속도 한계를 피하고, 순차 전송 속도를 극대화하기 위한 설계이다.
3.1.4 B+ 트리 vs LSM트리
B+ 트리
-
제한된 범위에서 성능 최적화
- 전통적인 RDBMS에서 많이 사용되며, 일정 규모에서는 빠른 탐색 성능을 제공한다.
-
변경 작업에 취약
- 삽입·갱신·삭제가 많아질수록 효율이 급격히 떨어진다.
- 데이터를 임의 위치에 자주 추가하면 페이지가 빠르게 파편화(fragmentation) 된다.
- 페이지를 정렬된 형태로 꽉 차게 해놓는 게 아니라 포인터 방식으로 해놓았기 때문
-
디스크 탐색 의존
- 갱신과 삭제 작업은 디스크 전송 속도가 아닌 디스크 탐색 속도에 좌우되므로, 대규모 데이터 환경에서는 병목이 발생한다.
LSM트리
-
전송 속도 기반 동작
- 모든 쓰기를 순차적 쓰기로 변환해, 디스크의 순차 전송 속도를 활용한다.
-
대규모 데이터 확장성
- 로그 파일과 메모리 계층을 활용하여 일정한 쓰기 속도를 보장하고, 대용량 환경에서도 안정적이다.
-
읽기/쓰기 분리
- 두 연산이 서로 충돌하지 않으며, 쓰기 성능이 안정적으로 유지된다.
-
정렬된 저장 구조
- 디스크에 저장된 데이터는 항상 정렬 상태를 유지한다.
- 덕분에 범위 검색 시 추가적인 탐색 비용이 거의 들지 않고, 예측 가능한 영역만 접근하면 된다.
-
비용의 투명성
- 예를 들어, 저장 파일이 5개라면 최대 5번의 디스크 탐색이 필요함을 쉽게 예측할 수 있다.
- 반면, 전통적인 RDBMS 쿼리는 몇 번의 디스크 탐색이 발생할지 사전에 추정하기 어렵다
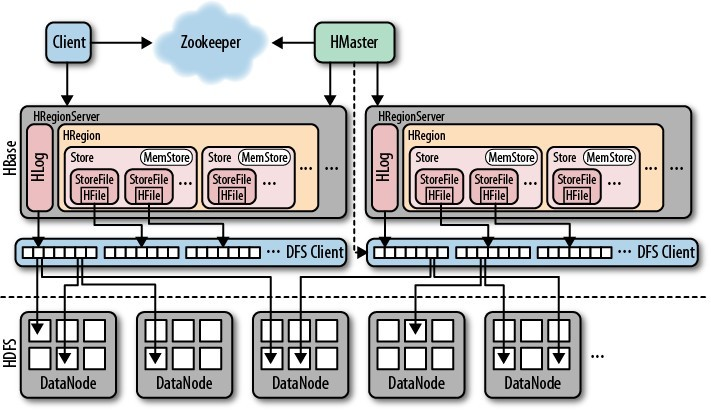
3.2 저장소
http://khansikandar.com/bigdata/2019/08/19/hbase.html
3.2.1 개요
HBase는 두 종류의 파일을 처리한다.
- WAL 저장용
- HLog file이라고 부름
- 실제 데이터 저장용
- HFile 이라고 부름
이들 파일은 주로 HRegionServer에서 관리되며, 특수한 경우에는 HMaster가 저수준 파일 처리를 담당할 수도 있다.
HDFS 위에 저장될 때는 데이터가 여러 블록 단위로 분할되며, 이는 설정을 통해 제어 가능하다.
클라이언트 요청의 흐름
- 클라이언트 → ZooKeeper
클라이언트는 먼저 ZooKeeper 앙상블에 접속하여 HBase 클러스터 메타데이터를 확인한다.
-
루트 리전 서버 확인
- 루트 리전을 관리하는 서버(호스트명)를 얻는다.
-
메타(.META.) 리전 서버 확인
- 루트 리전 정보를 이용해 메타 테이블 리전을 관리하는 서버를 찾는다.
- 루트/메타 서버 정보는 캐싱되므로, 이 과정은 최초 한 번만 수행된다.
-
메타 테이블 쿼리
- 메타 서버에 쿼리하여 특정 로우키(Row Key)가 속한 리전의 서버 정보를 얻는다.
- 이렇게 해서 해당 로우가 실제 어느 리전에 저장되었는지 알 수 있다.
- 이 정보 또한 캐싱되어, 이후 동일한 범위의 접근 시 추가 쿼리가 필요 없다.
- Region이 분할되거나 병합되기 전까지는 이 매핑 정보가 변하지 않으므로, 클라이언트는 이를 캐싱하여 반복적으로 활용할 수 있다.
- 다만, Region 정보가 변경되었는데 클라이언트가 여전히 캐시된 정보를 기반으로 요청을 보내면 예외(Exception)가 발생한다.
- 따라서 HBase 애플리케이션 개발 시, 클라이언트는 HBase에서 발생하는 예외를 감지하여 Region 정보를 갱신하고 재시도(Retry) 하도록 구현하는 것이 중요하다.
-
점점 최적화되는 접근 경로
- 시간이 지날수록 클라이언트는 캐시를 활용하여 메타 서버를 거치지 않고도 바로 리전에 접근할 수 있다.
HRegionServer의 역할
HRegionServer는 HBase에서 데이터를 실질적으로 저장하고 관리하는 프로세스이다. 주요 역할은 다음과 같다.
-
리전 열기(Open Region)
- 요청이 들어오면 해당 리전을 열고 HRegion 객체를 생성한다.
-
Store 인스턴스 관리
- 각 테이블의 HColumnFamily마다 하나의 Store 인스턴스를 유지한다.
- 각 Store 인스턴스에는 여러 개의 StoreFile(HFile wrapper)인스턴스가 존재할 수 있다.
- StoreFile은 HFile에 대한 wrapper, 추상화된 클래스다
-
MemStore 유지
- 각 Store는 메모리 버퍼(MemStore)를 가지고 있어, 새로운 쓰기 연산은 먼저 메모리에 저장된다.
-
HLog 관리
- HRegionServer 전체에서 공유하는 HLog 인스턴스(WAL)가 존재하며, 쓰기 연산이 먼저 기록된다.
3.2.2 쓰기 경로
클라이언트가 HTable.put(Put) 요청을 보내면, 해당 요청은 데이터를 저장할 리전을 담당하는 HRegionServer의 HRegion 인스턴스로 전달된다. 쓰기 경로는 아래 단계로 진행된다.
기본 쓰기 흐름
-
WAL 기록
HLog클래스에 구현된 WAL(Write-Ahead Log)에 먼저 데이터를 기록한다.- WAL은 Hadoop의 SequenceFile 형식을 사용한다.
-
WAL 키 저장
- WAL에는
HLogKey인스턴스가 함께 저장되며, 여기에는 데이터와 함께 일렬 번호(sequence number)가 포함된다. - 서버 장애가 발생했을 때, WAL은 아직 HDFS에 반영되지 않은 변경 사항을 재현하는 데 사용된다.
- WAL에는
-
MemStore 저장
- WAL 기록이 끝나면 데이터는 MemStore에도 저장된다.
- MemStore는 메모리 버퍼 역할을 하며, 쓰기 요청을 빠르게 처리한다.
-
Flush 조건 확인
- MemStore가 가득 차면, 디스크로 Flush 요청이 발생한다.
- Flush 작업은 HRegionServer 내부의 별도 스레드에서 수행된다.
-
HFile 기록
- Flush가 실행되면 MemStore의 내용은 HDFS에 새로운 HFile로 기록된다.
- 이때 "마지막으로 flush된 sequence id"도 함께 저장되어, WAL에서 어느 시점까지 반영되었는지를 추적할 수 있다.
Preflushing (사전 비우기)
Preflushing은 서버 종료나 테이블 생성 같은 이벤트 시 MemStore를 미리 비우는 과정이다.
-
조건:
hbase.hregion.preclose.flush.size에 설정된 값보다 MemStore가 클 경우 실행된다. -
장점:
- 모든 MemStore가 디스크에 기록되면 리전을 안전하게 닫을 수 있고, 재시작 시 WAL 재현이 불필요하다.
- Preflushing 시점에는 서버와 리전이 여전히 접근 가능하다.
- 이후 실제 Close 단계에서 차단 시간(downtime)이 짧아진다.
- 따라서 graceful stop(서비스 중단 최소화)이 가능하다.
- region에 대한 가용성 향상된다.
- 서버 및 리전이 접근 가능한 상태로 남아있기 때문
- 미리 비우기 이후에 리전에 요청은 차단됨
- 미리 비우기 단계 도중 추가된 데이터는 차단 단계에서 처리 됨
3.2.3 파일
HBase는 HDFS 위에 /hbase 루트 디렉터리를 두고, 그 안에 로그 파일(WAL), 테이블 데이터, 리전 파일 등을 저장한다. (루트 디렉터리는 클러스터 설정에 따라 변경 가능하다.)
관리자는 hadoop dfs -lsr 명령을 통해 디렉터리와 파일 구조를 확인할 수 있다.
루트 디렉터리 파일
WAL 파일
/hbase/.logs디렉터리에 위치한다..logs밑에는 각 HRegionServer별 하위 디렉터리가 있으며, 해당 서버가 관리하는 모든 리전은 하나의 HLog 파일을 공유한다.- 현재 쓰기 중인 WAL 파일은 크기가 표시되지 않는다.
- 데이터가 HFile로 flush되면 WAL은
oldlogs디렉터리로 이동하며, TTL 설정값에 따라 자동 삭제된다. - 마스터는
hbase.master.cleaner.interval주기에 따라 오래된 로그를 정리한다.
테이블 파일
각 테이블 디렉터리 최상위에는 .tableinfo 파일이 존재한다.
이 안에는 HTableDescriptor(java)가 직렬화(serialized) 형태로 저장되어 있으며, 테이블 및 컬럼 패밀리 스키마 정보가 포함된다.
리전 파일
테이블 디렉터리 안에는 해당 테이블의 모든 리전을 위한 별도 디렉터리가 생성된다
디렉터리 이름은 리전 이름의 MD5 해시값으로 지정되어, HDFS 명명 규칙을 항상 만족한다.
리전 파일 경로 규칙
/<HBase root dir>/<table name>/<encoded region name>/<column family name>/<file name>- 컬럼 패밀리(CF) 디렉터리 안의 파일 이름은 Java의 랜덤 제너레이터로 생성되어 중복되지 않는다.
- 각 리전 디렉터리에는
.regioninfo파일이 있으며, 이는HRegionInfo객체가 직렬화된 형태이다.- 예:
hbase hbck같은 외부 도구는 이 파일을 참조하여 누락된 메타데이터를 복구할 수 있다.
- 예:
임시 디렉터리와 파일
-
.tmp- 컴팩션(compaction) 중간 결과가 저장된다.
- 컴팩션이 완료되면 결과 파일은 상위 리전 디렉터리로 이동하며, 리전이 다시 열릴 때
.tmp디렉터리는 삭제된다. .tmp가 없다는 것은 해당 리전에 아직 컴팩션이 수행되지 않았음을 의미한다.
-
.splitlog/recovered.edits- WAL 재현(replay) 중 아직 커밋되지 않은 변경사항은
.splitlog에 저장된다. - 로그 분할이 성공하면 파일은
recovered.edits디렉터리에 원자적으로 이동한다. - 따라서
recovered.edits가없으면 해당 리전에 대해 WAL 재현이 수행되지 않았음을 의미한다.
- WAL 재현(replay) 중 아직 커밋되지 않은 변경사항은
-
splits- 리전이 최대 크기(max size)를 초과해 분할될 경우 생성된다.
- 기존 리전을 둘로 나눈 새로운 자식 리전들이 임시 저장되며, 이후 몇 초 내에 테이블 디렉터리로 이동하여 실제 리전으로 등록된다.
3.2.4 리전 분할
HBase의 리전(region)은 테이블을 수평적으로 나눈 단위이며, 리전의 크기가 커지면 자동으로 분할된다.
분할은 테이블의 확장성을 높이고, 부하 분산을 가능하게 한다.
분할기준
리전은 다음 조건 중 하나를 만족할 때 두 개의 자식 리전으로 분할된다.
hbase.hregion.max.filesize값(리전 최대 파일 크기)을 초과할 때HColumnDescriptor에서 지정한 컬럼 패밀리 단위 크기를 초과할 때
분할 방식:
- 원본 리전(부모)을 절반으로 나누어 두 개의 새로운 리전을 만든다.
- 초기 단계에서는 참조파일(reference file)만 생성되므로 속도가 빠르다.
분할과정
- Split 디렉터리 생성
- 부모 리전 아래에 splits 디렉터리가 만들어진다.
- 부모 리전 닫기
- 원본 리전을 닫아 새로운 요청을 받지 못하게 한다.
- 자식 리전 준비
- 멀티스레드 방식으로 splits 디렉터리 안에 새로운 리전 파일 구조를 생성한다.
- 자식 리전 이동
- 준비가 끝나면 두 개의 새로운 리전 디렉터리를 테이블 디렉터리로 이동한다.
- 메타 테이블 갱신
- 메타 테이블에 새로운 리전 정보가 반영된다.
column=info:regioninfo, ... startkey=>'row-500' endkey=>'row-700', ... split=true
column=info.:splitA, ... startkey=>'row500', endkey=>'row550', ...
column=info.:splitB, ... startkey=>'row550', endkey=>'row700', ...
참조파일 (Reference File)
- 부모 리전의 데이터를 직접 복사하지 않고, 참조파일을 생성한다.
- 참조파일 이름은 랜덤 숫자 + 참조된 리전 해시값 접미어로 구성된다.
- 이후 컴팩션(compaction)이 실행될 때 실제 데이터가 물리적으로 분리되어 정리된다.
3.2.5 읽기 경로 (Read Path)
HBase의 읽기 과정은 단순히 "파일에서 데이터 찾기"가 아니라, MemStore, 여러 HFile, Tombstone, BloomFilter 등을 조합하는 복잡한 절차다.
저장 구조와 전제 조건
- HBase는 컬럼 패밀리(CF) 단위로 여러 개의 저장 파일(HFile)을 관리한다.
- HBase는 CF하나 당 여러 개의 저장 파일을 사용한다.
- 저장 파일에는 실제 데이터, 즉 key-value 인스턴스가 저장된다.
- HBase는 CF하나 당 여러 개의 저장 파일을 사용한다.
- 저장 파일은 MemStore → Flush → HFile 과정에서 만들어진다.
- 저장 파일은 immutable(불변) 속성을 가지므로, 삭제는 직접 제거하는 대신 Tombstone(삭제 마커)를 기록해 나중에 컴팩션 시 정리된다
읽기 흐름
-
파일 후보군 줄이기
- 모든 HFile을 읽는 것은 비효율적이므로,
타임스탬프,Bloom Filter등을 활용해, 요청된 row key와 무관한 파일은 건너뛴다.
- 모든 HFile을 읽는 것은 비효율적이므로,
-
MemStore + HFile 스캔
- 제외되지 않은 HFile과 MemStore를 스캔하여 대상 row key를 찾는다. (log(N))
-
StoreScanner 사용
- 각 CF 단위로 StoreScanner가 동작한다.
- CF 자체가 요청 대상에서 제외되면 해당 CF 파일은 아예 읽지 않는다.
- 내부적으로 KeyValueHeap을 사용해 여러 StoreScanner 결과를 타임스탬프 순서로 정렬한다.
- 이 과정에서 Tombstone 마커를 만나면 → 해당 데이터와 삭제 대상은 무시된다.
if (cell == Tombstone) {
skip(cell);
skip(deleted_target);
}-
데이터 정렬 및 병합
- StoreScanner는 HFile + MemStore 데이터를 조합한다.
- KeyValueHeap클래스를 사용해 모든 데이터를 타임스탬프 기준으로 내림차순 정렬한다.
- Bloom Filter 기반의 2차 배제도 수행한다.
- 예: 특정 시점 이후 버전만 읽을 때("30분 이상 지난 버전은 제외" 같은 조건)
- StoreScanner는 HFile + MemStore 데이터를 조합한다.
-
QueryMatcher 최종 필터링
- 최종적으로 반환할 key-value는 QueryMatcher에서 판별한다.
- QueryMatcher는 "요청 조건과 일치하는지"를 검사하고, 최종 데이터셋을 만든다.
