5 Fair Call Queue
Fair Call Queue 는 Client의 요청을 담아놓는 Queue 이다.
특정 클라이언트(헤비 클라이언트)의 요청때문에 전체 요청의 처리가 늦어지지 않도록 하기 위해 만들어졌다.
5.1 FIFO queue 의 단점
Fair Call Queue 가 도입되기 전에
Hadoop Node 에서 client 의 요청은 FIFO queue 에 담겨져서 먼저 요청이 온 순서대로 처리했다.
Client로 부터 요청이 오면 reader thread 는 단일 FIFO Queue 에 요청을 담고, Handler 가 처리할 작업이 없다면 FIFO에서 하나씩 요청을 꺼내서 처리하는 방식이었다.
아래 그림은 하나의 Hadoop 노드를 나타낸다고 볼 수 있으며, 해당 노드가 DataNode이든 NameNode이든 기본 네트워크 구조는 동일하다. 클라이언트가 요청을 보낼 때, 예를 들어 노드가 8020 포트를 리슨하고 있다면 해당 포트로 연결 요청이 들어온다. 연결이 수립되고 요청(Request)이 전달되면, 이를 처리하는 Reader는 스레드(Thread) 단위로 동작한다. Reader Thread는 여러 개가 존재하며, 각 Reader Thread는 클라이언트 요청을 하나씩 받아서 FIFO(Call Queue)에 순서대로 넣는다.
이때 각 요청은 도착 순서대로 Call Queue에 1번, 2번, 3번과 같이 쌓인다. Handler는 자신의 작업이 끝난 경우, Call Queue에서 다음 요청을 하나씩 꺼내 해당 Operation을 수행한다. 따라서 전체 구조는 단순히 Reader Thread가 요청을 수신하여 큐에 넣고, Handler가 큐에서 요청을 꺼내 순차적으로 처리하는 형태로 동작한다.
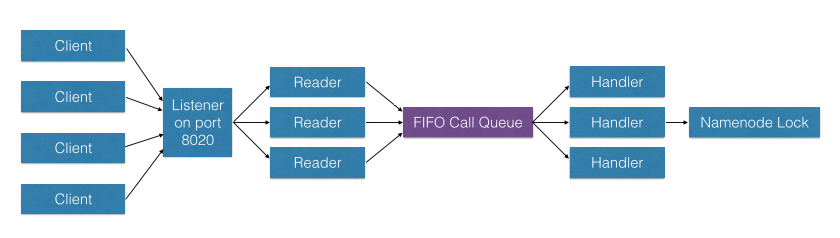
https://innovation.ebayinc.com/stories/quality-of-service-in-hadoop/
단순 FIFO Queue 를 이용해서 Client 의 요청을 처리하는 방식은 heavy user 로 인해 빈번하게 Hadoop Node 의 응답을 느리게 만들었다.
특히 namenode 의 경우 단일 서버에서 모든 요청을 처리하기 때문에, 병목이나 부하에 민감한데, 수 ms 에서 수백 ms 까지도 응답이 느려지는 일이 잦았다.
기존에는 이런 작업들을 강제 종료시키는 방법으로 처리했다. 하지만 이런 방식은 생산적이지도 않을 뿐더러, 이미 처리된 작업에 대해서 이러한 작업을 수행할 때 오류 등이 발생해서 cluster 동작을 수시간 이용 못하는 경우 까지도 생겼다.
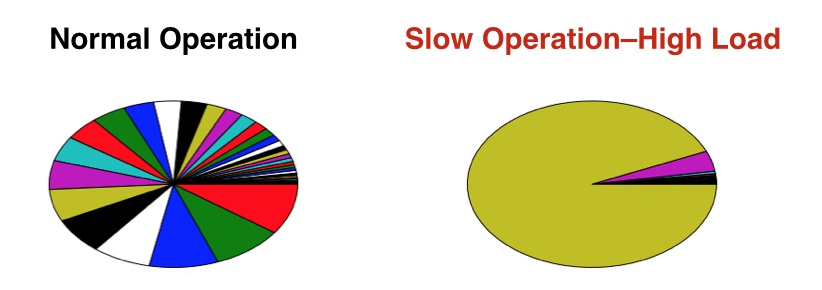
https://innovation.ebayinc.com/stories/quality-of-service-in-hadoop/
위 자료는 이베이에서 조사했던 자료인데, 각 유저별로 요청을 다른 색으로 표현한 것이다.
이러한 문제는 소수의 유저의 high load operation 에 의해서 발생하는 경우가 많았다. 그리고 이런 작업은 종종 유저의 잘못된 MapReduce 작업에 의해 발생했다.
바꿔서 말하면, 누구든 잘못된 MapReduce 작업으로 high load 를 발생시킨다면 분산 서비스에 대한 공격을 수행할 수 있다는 것이다.
DDoS(distributed denial-of-service attack) 방식으로 공격이 가능해진다.
5.2 Fair Call Queue 의 도입
라우터에서 사용하는 QoS(Quality of service) capabilities의 기능에서 영감을 받아 만들었는데,
Reader Thead랑 Hander Thread 사이에 있던 FIFO Queue 를 Fair Call Queue 로 교체했다.
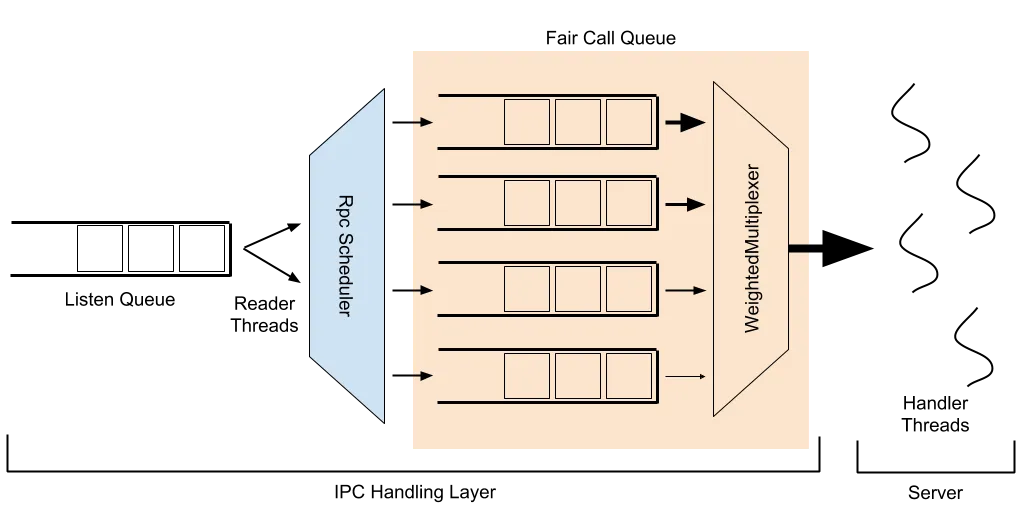
https://hadoop.apache.org/docs/r3.3.3/hadoop-project-dist/hadoop-common/FairCallQueue.html
5.2.1 Fair Call Queue 구성요소
Fair Call Queue는 크게 RPC Scheduler, Queue, Weighted Multiplexer의 세 가지 요소로 구성되어 있으며, Multiplexer와 Scheduler는 Multi-Level Queue 형태로 연결되어 있다..
Fair Call Queue 는 이 3가지의 구성요소 이루어져있다.
-
RPC Scheduler
Reader Thread가 수신한 요청을 여러 개의 Queue로 분배하는 역할을 한다. 즉, 어떤 요청을 어떤 Queue에 담을지를 결정하는 것이 RPC Scheduler의 핵심 기능이다. 이 과정에서 요청 유형, 우선순위, 또는 기타 정책에 따라 분배 전략이 달라질 수 있다. -
Queue
RPC Scheduler에 의해 분배된 요청들이 저장되는 대기열이다. 여러 개의 Queue가 존재하며, 각 Queue는 특정한 요청 그룹이나 우선순위를 나타낼 수 있다. -
Weighted Multiplexer
여러 Queue에 나누어 저장된 요청을 꺼내어 Handler에게 전달하는 역할을 한다. Handler에 작업을 배정할 때는 “비어 있는 Handler에게 순차적으로 작업을 할당한다”는 기본 규칙은 동일하지만, 어떤 Queue에서 얼마나 많은 요청을 가져올지 비율(Weight)을 조정하는 것이 Weighted Multiplexer의 주요 기능이다.
이렇게 RPC Scheduler, Queue, Weighted Multiplexer 세 가지 구성 요소가 결합되어 Fair Call Queue를 구성한다.
5.2.2 RPC Scheduler 의 역할
RPC 요청이 Listen Queue에 도착하면 여러개의 Reader thread 가 이 요청을 RpcScheduler 에 전달한다.
RPC Scheduler 는 전달받은 요청을 여러 개의 Priority Queue로 분류하여 저장한다
이때 각 요청은 큐에 넣기 전에 우선순위가 지정되며, 해당 우선순위에 따라 적절한 Priority Queue에 할당된다.
Fair Call Queue에 있는 RPC Scheduler 는 구현체를 선택할 수 있도록 pluggable 하게 만들어져있다.
default RPC Scheduler 는 DecayRpcScheduler 이다. (부패. 시간이 지날 수록 priroity를 반영하는 것에 변경이 있겠죠.)
5.2.3 DecayRpcScheduler
DecayRpcScheduler는 사용자별 요청 수(count)를 기록하고, 시간이 지남에 따라 Decay Factor를 적용하여 과거 요청의 비중을 감소시킨다. 이를 통해 최근 요청에 더 높은 가중치를 부여하면서도, 과거 요청량을 완전히 무시하지 않고 반영한다
작동 방식
-
Sweep Period(기본 5초)마다 각 사용자의 요청 수(count)에 Decay Factor(기본 0.5)를 곱한다.
-
이렇게 계산된 값은 누적되며, 시간이 지날수록 과거 요청은 기하급수적으로 비중이 감소한다(rolling weighted count).
-
매 Sweep마다 모든 사용자에 대해 계산된 weighted count를 기준으로 순위를 매기고(priority ranking), 해당 순위에 따라 Priority를 할당한다.
예시
- 첫 5초 동안 user A가 10개의 요청을, user B와 user C가 각각 0개의 요청을 보냈다고 가정한다.
- 두 번째 5초 동안 user A와 user B가 각각 10개의 요청을 보냈고, user C는 1개의 요청을 보냈다고 하자.
- Sweep이 두 번 수행된 후, user A의 첫 번째 요청 10개는 decay factor 0.5를 두 번 곱해
가 된다. 두 번째 요청 10개는 0.5를 한 번만 곱해 가 된다. 따라서 user A의 총 weighted count는 7.5이다.- user B는 첫 번째 기간에는 요청이 없었고, 두 번째 기간에 10개의 요청을 보내 0.5를 곱해 5가 된다.
- user C는 요청이 1개이므로 decay factor가 적용되지 않아 count가 1이 된다.
- 결과적으로 weighted count는 user A=7.5, user B=5, user C=1이 되며, user A가 가장 heavy user임을 알 수 있다.
Priority 할당 규칙
- 기본 Priority 값은 0~3이며, 0이 가장 높은 우선순위(highest priority)이다.
- Priority는 weighted count 비율이 전체 요청량에서 차지하는 비중에 따라 Priority Thresholds를 기준으로 결정된다.
- 50% 이상: Priority 3 (lowest priority)
- 25%~50%: Priority 2 (second lowest priority)
- 12.5%~25%: Priority 1 (second highest priority)
- 12.5% 미만: Priority 0 (highest priority)
- 위 예시에서 전체 요청량은 13.5이며, user A는 로 Priority 3, user B는 37%로 Priority 2, user C는 7%로 Priority 0이 된다.
우선순위 캐싱과 동적 계산(on-the-fly)
- Sweep이 끝나면 각 사용자의 Priority가 캐시되며, 다음 Sweep까지 유지된다.
- Sweep 이후 새로 등장한 사용자는 캐시된 Priority가 없으므로, 요청 시점에 즉시(on-the-fly) Priority를 계산한다.
5.2.4 RPC Multiplexer
multiplexer 는 low-priority queue 와 high priority queue 를 비교해 penalty 를 컨트롤 한다.
multiplexer 는 요청들을 weighted round-robin 방식으로 읽는데, high-priority queue 를 선호하고, lowest-priority queue 로부터 읽는 것의 빈도를 낮추는 방식이다.
이 규칙으로 high-priority 요청은 먼저 처리하고, low-priority 요청에 의한 starvation 을 방지한다.
Handler thread 가 call queue 에서 요청을 가져오려고 할때, 어떤 요청을 가져올지를 RpcMultiplexer 가 결정한다.
현재 Rpc Multiplexer 는 WeightedRoundRobinMultiplexer(WRRM)로 하드코딩 되어있다.
WRRM은 queue 로부터 요청을 weight를 고려해서 처리한다.
WRRM은 기본으로 (8,4,2,1) 4개로 weight를 구분하는 priority level로 구성된다.
- 설정 가능함
- 8개의 request 를 highest priority queue 에서 꺼내서 처리하고
- 4개를 2nd highest 에서
- 2개를 third highest 에서
- 마지막으로 1개를 lowest 에서 꺼내서 handler 에게 주는 방식이다.
5.2.5 Backoff
위에서 설명한 priority-weighting mechanism 에 더해서, backkoff 방법도 설정이 가능하다.
backkoff란?
과도하게 자원을 사용하는 클라이언트나 서비스의 요청 처리 빈도를 인위적으로 늦추거나 제한하는 메커니즘
backoff는 요청을 처리하기보다 client 에게 exception을 throw 하는 방식이다.
이것은 client 에서 exponential backoff 등으로 retry 를 하도록 구현되어있을 것을 기대하고 동작하는 방식이다.
전형적인 경우의 backoff 는 request queue 가 가득 찼을때 발생한다.
이 뿐만 아니라 backkoff by response time 기능도 제공한다.
이것은 더 높은 우선순위 queue에 있는 요청의 처리가 너무 느리다면, 낮은 우선순위 queue의 요청을 backoff 하는 방식이다.
- priority 1에 대한 response time threshold 가 10s 로 세팅되어있고 해당 queue 의 평균 response time 이 12s 라고 하면, priority level 2 이하로 들어오는 요청은 backoff exception 을 받는다. 반면에 priority 0과 1에 있는 요청들은 정상적으로 처리된다.
이 방식의 의도는 높은 우선수위를 가지는 클라이언트에게 까지 영향을 미치는 시스템의 부하가 생겼을 때는, heavy user 에게 backoff 를 강제하겠다는 것이다.
- 따라서 Hadoop Client를 사용하는 어플리케이션 개발자는 backoff 에 의한 exception 이 자주 발생한다면, 자신이 시스템에 부하를 줄 정도로 무거운 요청을 자주 전송하는지 점검해볼 필요가 있다.
5.2.6 Identity Provider
유저를 구분하는 방식은 identity provider 로 규칙을 정할 수 있다.
default는 UserIdentityProvider로, 단순히 client의 username 으로 구분한다.
5.2.8 설정 방식
매뉴얼 의 #Configuration 항목에서 어떻게 설정하는지 확인이 가능하다.
- core-default.xml 에 설정한다.
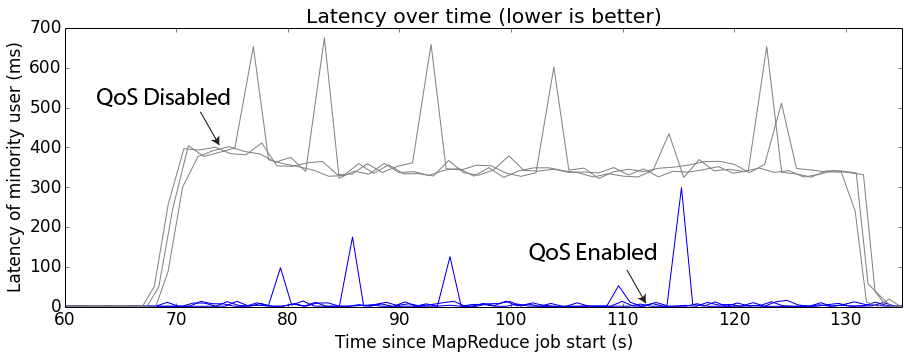
5.3 테스트 결과
테스트 결과 DoS 공격에 대해서 일정 수준 이하의 낮은 latency를 보장할 수 있었다.
5.4 Cost based Fair Call Queue
Fair Call Queue 자체만으로도 헤비 유저에 대한 영향을 줄이는데에 효과가 좋았다.
하지만 Fair Call Queue 에는 각 요청이 얼마나 비싼 작업인지에 대해서는 고려가 되지 않았다.
예를 들어서 namenode 에 대해 다음 요청을 한다면 어떤 요청이 가장 비싼 작업일까?
- 1000개의 getFileInfo 요청
- 1000개의 listStatus on very large directory 요청
- 1000개의 mkdir
답: 1번과 2번이 거의 같고, 3번이 가장 비쌈. mkdir에는 exclusive lock 필요함.
따라서 유저의 요청에 우선순위를 매길 때, cost 까지 고려할 필요가 생겼다.
Fair Call Queue에 cost-based extenstion을 적용하면, 우선순위를 매길 때 해당 유저의 요청을 수행했을 때 걸린 processing time을 집계해서 사용한다.
기본 설정으로는,
- queue time (processing을 위해 기다린 시간) 은 cost 에 포함되지 않는다.
- lock wait time (lock 을 얻기 위해 기다린 시간) 은 cost 에 포함되지 않는다.
- lock 이 없이 수행된 processing time = x 1 weighted
- shared lock 과 함께 수행된 processing time = x10 weighted
- exclusive lock 과 함께 수행된 processing time = x100 weighted
cost based Fair Call Queue 를 활성화 하기 위해서는 다음 설정을 해야한다.
costprovder.impl=org.apache.hadoop.ipc.WeightedTimeCostProvider
