4 Hadoop 3 Eraser Coding
Hadoop3 이전에 data fault tolerance를 어떤 식으로 보장했는지 짚고 넘어가 보자.
4.1 Hadoop 의 data fault tolerance
4.1.1 Software Data Tolerance
Hadoop 은 기본적으로 같은 data block 에 대해서 3개의 복제본을 유지한다.
이 data block 은 fault tolerance 를 위해 물리적으로 다른 위치에 위치시킨다.
다른 머신, 다른 rack, 다른 data center 단위로 분산해서 위치시켜서 물리적인 위치에 따른 fault 에 대해서도 데이터가 유실되지 않도록 한다.
복제본 정책은 데이터 유실에 대비하는 좋은 수단이 되지만, 이 때문에 발생하는 trade-off가 있다.
- 데이터를 3벌(혹은 그 이상) 저장해야 하기 때문에 write 작업에 시간이 더 오래 걸린다
- 데이터 복제본 유지를 위해서 실제 데이터의 양보다 3배 이상의 데이터 공간이 필요하다
4.1.2 Hardware Data Tolerance
Hadoop Cluster 은 위처럼 소프트웨어로 유실을 방지할 수 있다. 하지만, 유실에 대한 대비(감내) 수준을 더 높이기 위해 HW 차원에서의 방법을 적용하기도 한다.
HW RAID 구성을 통해서 소프트웨어의 변경 없이 데이터의 Fault Tolerance 수준을 높일 수 있다.
단, RAID 구성을 위해서는 추가적인 데이터 공간이 필요하고, 저장 과정이나 복구 과정에서 자원을 더 소모하므로 비용이 높아진다.
4.2 RAID
4.2.1 RAID란?
RAID는 Redundant Array of Inexpensive Disks의 약자이다. (저렴한 디스크들의 중복 배열)
RAID는 하드 디스크를 여러개의 독립적인 드라이브의 배열로 가상화 하는 방식이다.
이 방식을 통해서 performance, capacity, reliability 를 개선할 수 있다.
RAID는 이 기능을 위해 만들어진 컨트롤러인 RAID 하드웨어 컨트롤러를 사용하는 방식과, 운영체제 수준에서 소프트웨어 드라이브로 구현하는 방식 두 가지가 있다.
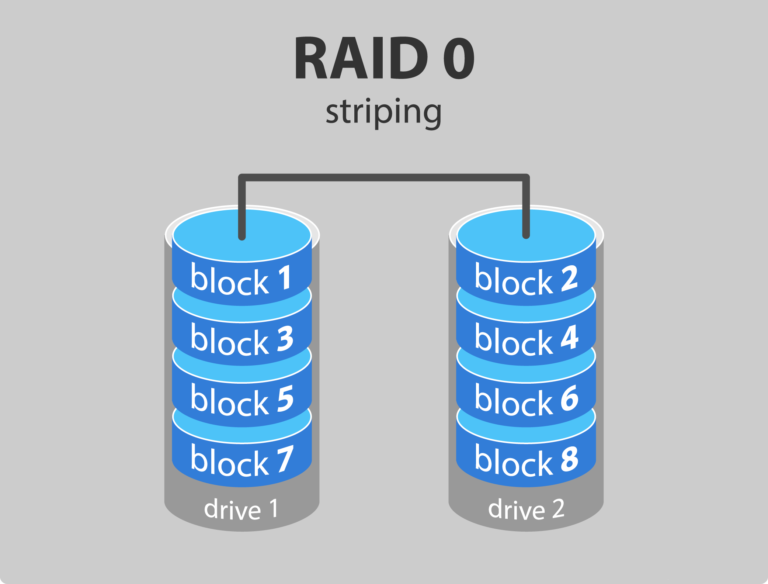
4.2.2 RAID 0
https://enumerateit.com/the-benefits-of-raid-and-implementation/
RAID 0 은 데이터를 블록단위로 나누어서 전체 데이터 영역에 array로 분포하도록 나누는 방식이다.
드라이브의 수 만큼 동시에 read/write 가 가능하므로 속도가 빠르다.
storage 의 용량을 모두 사용할 수 있고, 오버헤드 또한 없다.
RAID 0의 단점은 dedundant 하지 않다는 것이다. 데이터의 복제가 없다.
하나의 드라이브가 고장나면 해당 드라이브에 위치한 모든 블록의 데이터가 유실된다. (하드웨어 수준에서)데이터의 보관과 복구가 필요하다면 추천하지 않는다.
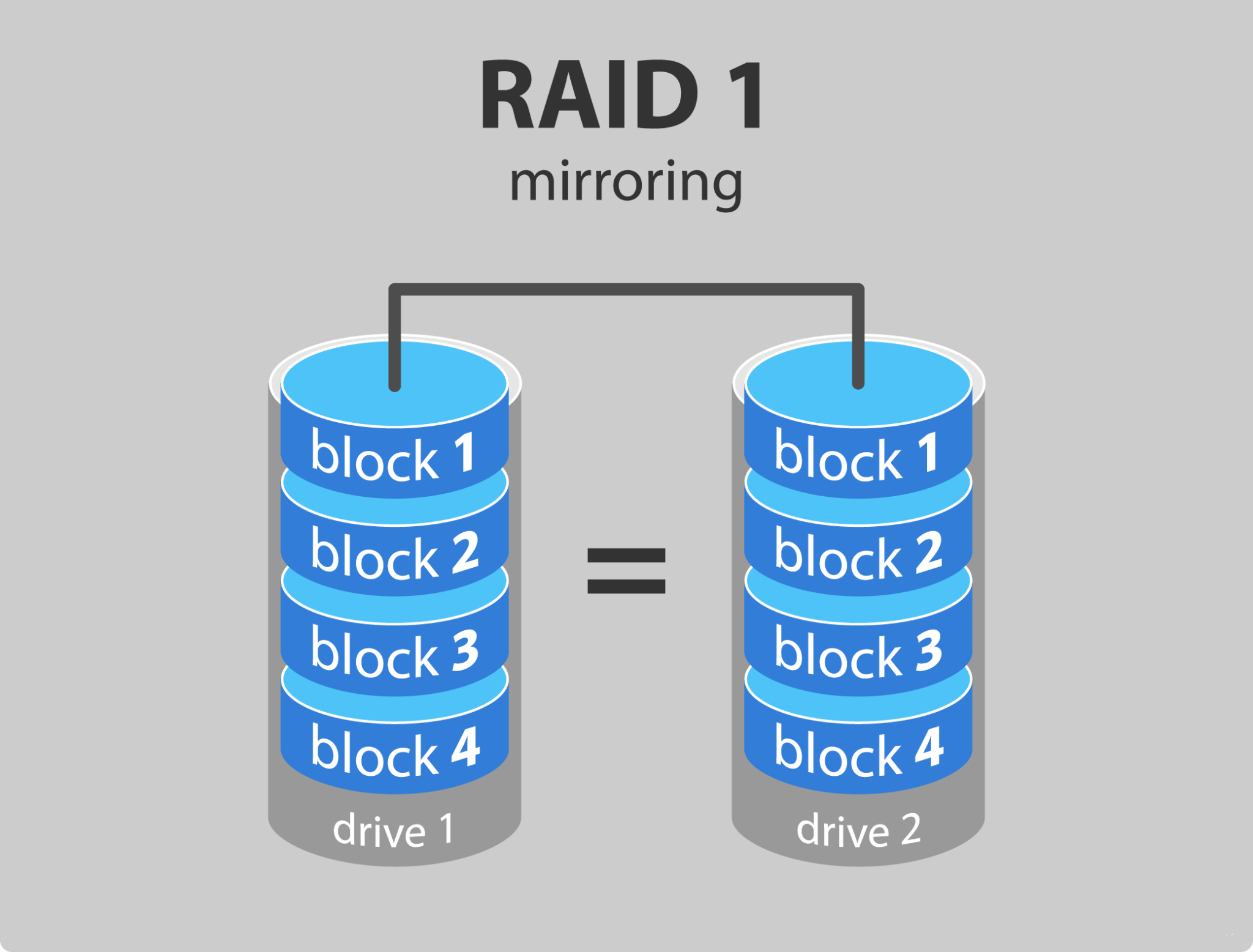
4.2.3 RAID 1
https://enumerateit.com/the-benefits-of-raid-and-implementation/
RAID 1은 같은 데이터에 대해서 최소한 두개의 드라이브를 사용하는 방식이다.
하나의 드라이브가 고장나도라도, 다른 하나로 인해 유실을 방지하고 지속적인 읽기 쓰기가 가능하다.
RAID 1 은 두 개의 드라이브 중 어디서든 가까운 위치에서 읽으면 되므로 read의 성능 또한 좋다.
하지만 write 시 두 벌 이상 저장해야하므로 RAID 0보다 write 속도가 느리다.
또한 두 개의 드라이브를 준비했지만, 사실상 이용가능한 용량은 하나 분량이므로 capacity 가 전체 디스크 용량대비 50%로 줄어든다.
4.2.4 Parity
Computer Science 에서 활용되는 Parity bit 는 1개의 bit 를 추가해서 데이터의 위변조를 확인할 수 있도록 하는 데이터를 말한다.
다음은 parity bit의 역할이 even parity bit 인 경우, odd parity bit 인 경우에 추가되는 8번째 자리의 bit의 사례이다.
| 7 bits of data | (count of 1-bits) | 8 bits including parity(even) | 8 bits including parity(odd) |
|---|---|---|---|
| 0000000 | 0 | 00000000 | 00000001 |
| 1010001 | 3 | 10100011 | 10100010 |
| 1101001 | 4 | 11010010 | 11010011 |
| 1111111 | 7 | 11111111 | 11111110 |
parity even 기준으로
원본이 0000000으로 1이 하나도 없다면 even 에서는 짝수를 유지하기 위해 parity bit 자리를 0 으로 설정한다.
원본이 1010001으로 1이 3개라면 even 에서는 짝수를 유지하기 위해 parity bit 자리를 1로 설정한다.
RAID에서 parity block 는 유실된 하나의 블록들의 데이터와 특별한 연산을 통해서 복구할 수 있는 bit로 구성된 블록을 의미한다.
아래 예제는 parity 연산이 xor 이고, 연산 결과가 0인 경우의 예이다.
- A==B : 0
- A!=B : 1
예제 - 정상 상태
| DISK 1 | DISK 2 | DISK 3 | DISK 4 | DISK 5 | |
|---|---|---|---|---|---|
| A block | 0 | 0 | 0 | 0 | Parity 0 ⊕ 0 ⊕ 0 ⊕ 0= 0 |
| B block | 0 | 1 | 0 | Parity 0 ⊕ 1 ⊕ 0 ⊕ 1= 0 | 1 |
| C block | 0 | 1 | Parity 0 ⊕ 1 ⊕ 1 ⊕ 0= 0 | 1 | 0 |
| D block | 1 | Parity 1 ⊕ 0 ⊕ 0 ⊕ 1= 0 | 0 | 0 | 1 |
| E block | Parity 1 ⊕ 0 ⊕ 0 ⊕ 0= 1 | 1 | 0 | 0 | 0 |
A block
B block의 패리티 블록은 Disk 5번이 아닌 4번이다.
그 이유는 Disk 5번 블록은 A블록이 이미 패리티 블록으로 쓰고 있는데
B block의 패리티 블록도 Disk 5번으로 지정했을 경우 해당 디스크가 나가면 패리티 전체가 날아가 버리게 되니까 패리티 블록을 각각 다른 디스크에 위치하도록 조정이 된다.
DISK 3의 Failure 발생
| DISK 1 | DISK 2 | DISK 3 | DISK 4 | DISK 5 | |
|---|---|---|---|---|---|
| A block | 0 | 0 | Failure | 0 | Parity 0 ⊕ 0 ⊕ 0 ⊕ 0= 0 |
| B block | 0 | 1 | Failure | Parity 0 ⊕ 1 ⊕ 0 ⊕ 1= 0 | 1 |
| C block | 0 | 1 | Parity Failure | 1 | 0 |
| D block | 1 | Parity 1 ⊕ 0 ⊕ 0 ⊕ 1= 0 | Failure | 0 | 1 |
| E block | Parity 1 ⊕ 0 ⊕ 1 ⊕ 0= 1 | 1 | Failure | 0 | 0 |
각 블록에 대해 장애가 나지 않은 디스크에 있는 블록들을 모두 xor 연산을 하면 DISK 4의 원본 bit를 복구할 수 있습니다.
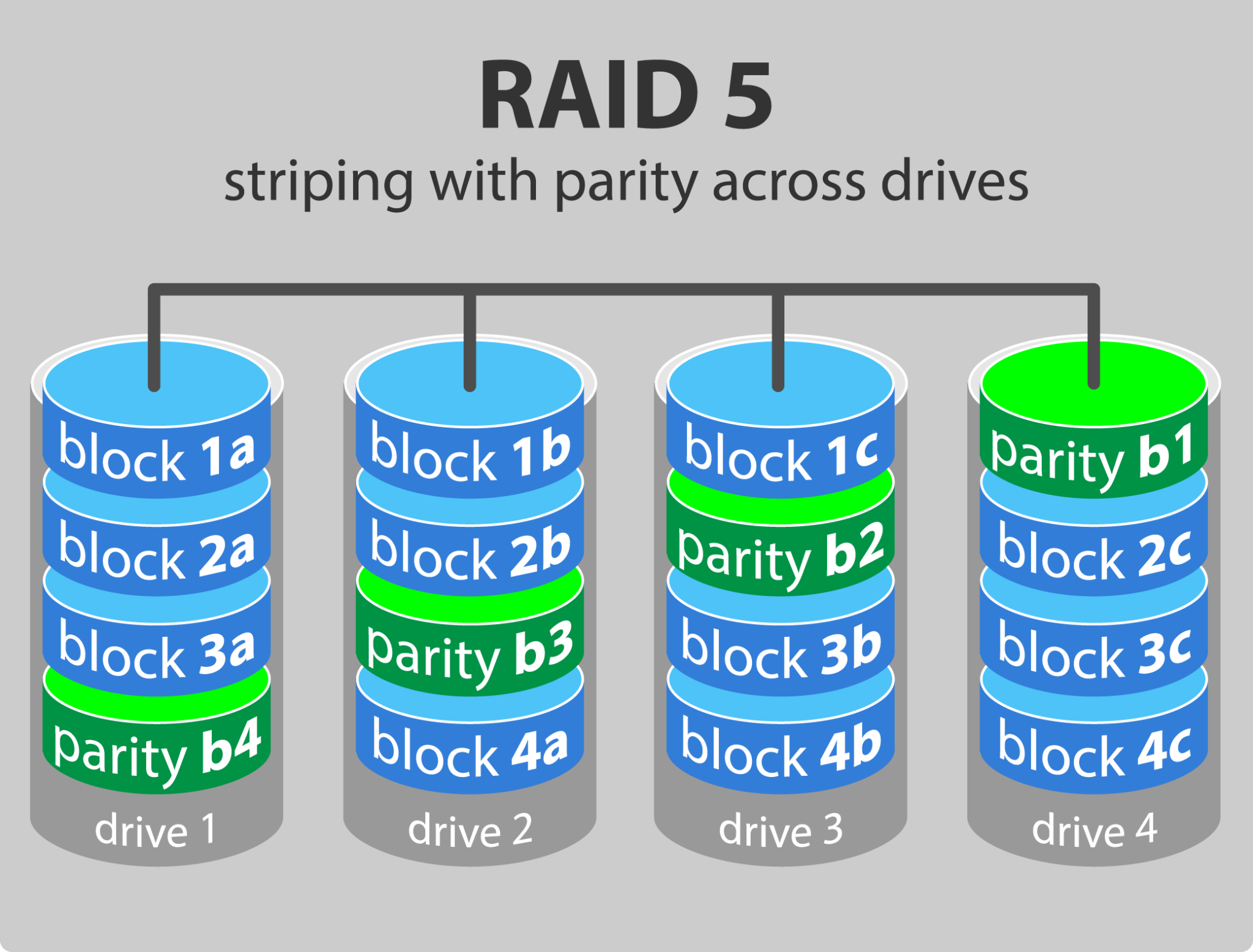
4.2.5 RAID 5
https://enumerateit.com/the-benefits-of-raid-and-implementation/
RAID 5 는 최소한 3개 이상의 드라이브로 구성해야한다.(하나가 장애가 났을 때 패리티 블록으로 연살할 대상이 있어야 복구가 되니까)
RAID 5는 하나의 데이터 블록이 여러개의 드라이브에 걸쳐 존재하도록 블록을 나눈다.
개별 블록에 대해 통째로 복제본을 유지하지 않는다. 다만, parity 라 불리는 블록을 추가로 다른 드라이브에 분산해서 저장한다.
하나의 드라이브에 장애가 발생하면, 해당 드라이브에 위치했던 블록의 데이터는 다른 드라이브에 있는 블록과 패리티 블록을 이용해서 복구할 수 있다.
단일 드라이브 장애에 대해 Zero downtime이 보장되고, read 는 빠르다.(각 drive에서 나눠서 읽을 수 있기 때문)
RAID 5 는 전체 디스크 용량의 33%(num of drive = 3) 이하에 대항하는 분량만 패리티 블록을 위해 사용하므로,
데이터 복구는 보장하면서도 RAID 1과 비교하면 capacity 가 높다.
다만, 데이터 저장시에 parity 가 계산되어야 하므로 (그냥 복제에 비해서)write 성능이 느리다. 또한 동시에 2개 이상의 드라이브에 장애가 발생하면 데이터는 복구 불가능하다.
가장 많이 활용되는 RAID 5 구성은 4개의 드라이브로 구성해서 25% 의 capacity loss 로 구성하는 것을 선호한다.
드라이브 수는 최대 16개 까지 구성가능하다.
데이터 드라이브 수가 제한된 파일 및 애플리케이션 서버에 적합하다.
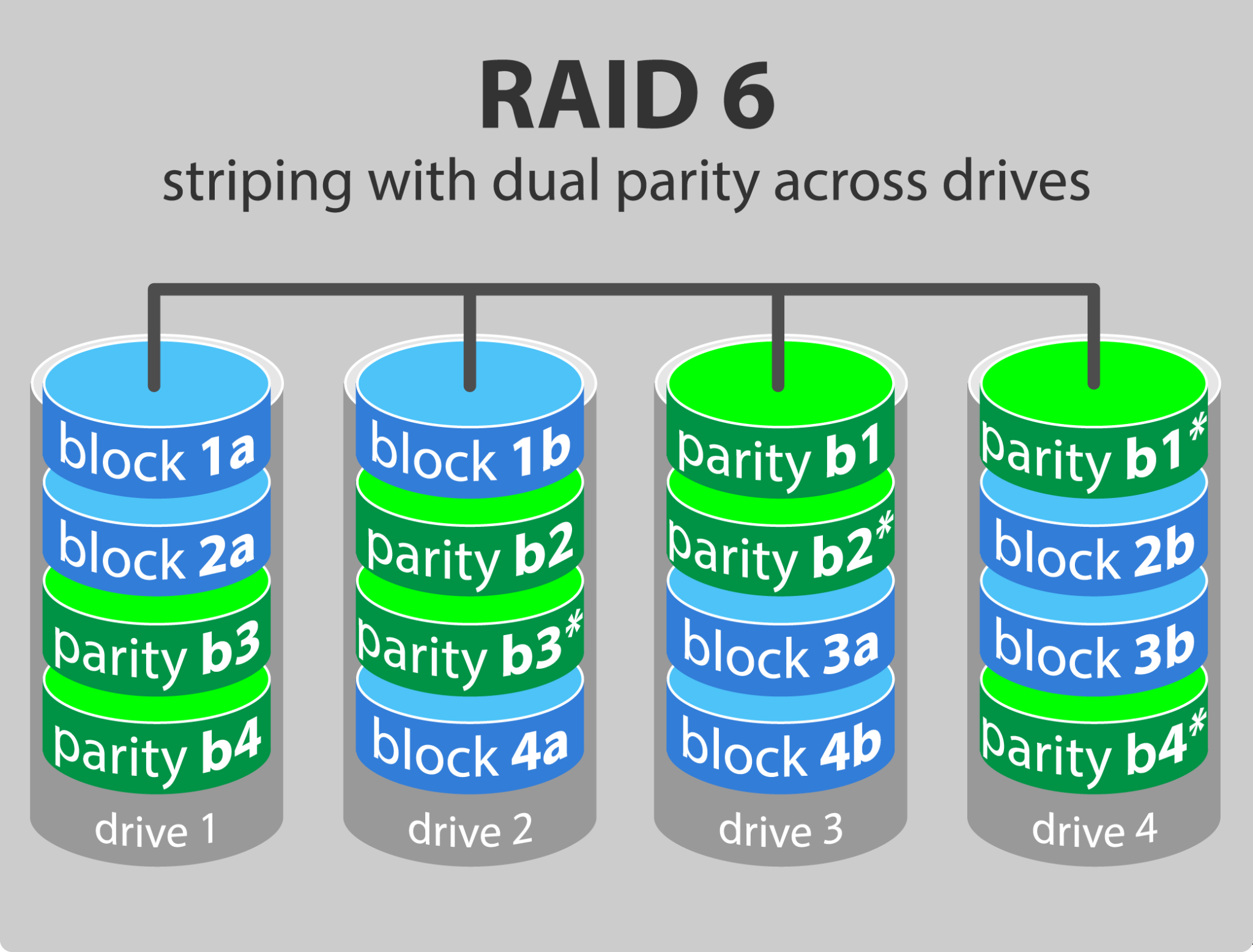
4.2.6 RAID 6
https://enumerateit.com/the-benefits-of-raid-and-implementation/
RAID 6는 RAID5와 유사하지만, parity 가 두개의 드라이브에 나누어 쓰여진다.
또한 parity 연산이 XOR이 아니라 Reed-Solomon 부호로 패리티를 생성한다.
따라서 최소한 4개의 드라이브로 구성해야하고, 동시에 두개의 드라이브의 장애에 대해 복구할 수 있다.
read 는 RAID 5 정도로 빠르지만, parity block 이 하나 더 추가되기 때문에 write 는 RAID 5보다 느리다.
RAID 6는 read 위주의 transaction 이 필요한 웹서버에 적합하다. write 가 heavy 한 데이터베이스 등에는 부적합하다.
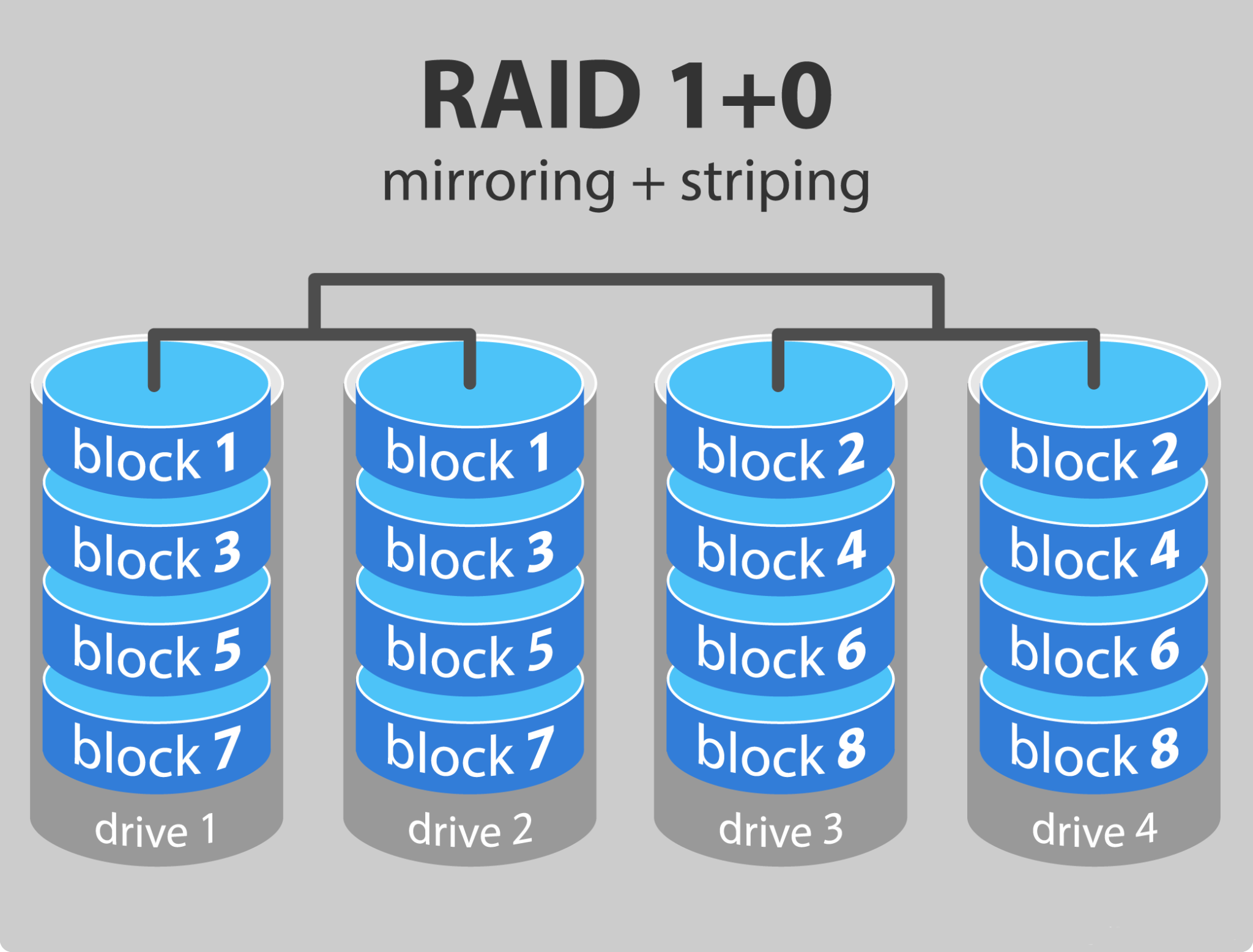
4.2.7 RAID 10
https://enumerateit.com/the-benefits-of-raid-and-implementation/
RAID 10 은 RAID 0 과 RAID 1 의 장점을 하나로 합친 시스템이다.
모든 데이터 블록에 대해서 복제본을 다른 드라이브에 유지하면서도, 전체 데이터 블록 array를 서로 두 개 의 드라이브에 나누어 분배하는 방식이다.
최소한 4개의 드라이브가 필요하다.
RAID 10은 RADI 0 수준의 속도와 RAID 1수준의 dedundancy 를 보장한다.
하나의 드라이브에 장애가 생겨도 복제본이 유지된 드라이브를 통해 복구가 가능하다. 다만 capacity 는 RAID 1과 동일하게 50%이다.
RADI 5, 6에 비해 비싼 방법이다.
4.2.8 정리
| Features | RAID 0 | RAID 1 | RAID 5 | RAID 6 | RAID 10 |
|---|---|---|---|---|---|
| Minimum number of drives | 2 | 2 | 3 | 4 | 4 |
| Fault tolerance | None | Single-drive failure | Single-drive failure | Two-drive failure | Up to one disk failure in each sub-array |
| Read performance | High | Medium | Low | Low | High |
| Write Performance | High | Medium | Low | Low | Medium |
| Capacity utilization | 100% | 50% | 67% – 94% | 50% – 88% | 50% |
| Typical applications | High end workstations, data logging, real-time rendering, very transitory data | Operating systems, transaction databases | Data warehousing, web serving, archiving | Data archive, backup to disk, high availability solutions, servers with large capacity requirements | Fast databases, file servers, application servers |
4.2.9 어떤 RAID를 쓰나요?
fault tolerance 와 성능을 모두 고려한다면 RAID 5, 6, 10 중에 선택할 수 있다.
다 RAID 10 의 capacity loss 가 너무 크기 때문에, 현실적으로 RAID 5를 많이 선택한다.
4.3 Eraser Coding
4.3.1 Hardware RAID vs Software RAID
하드웨어 RAID
- 별도의 하드웨어인 RAID 컨트롤러 카드를 통해 RAID를 구현한다.
- 시스템에 부담이 적게 읽기/쓰기나 패리티 계산 등의 속도 빠르다.
- RAID 컨트롤러 카드의 가격 비싸다.
- 전문적으로 데이터센터를 차리는 경우에만 대량으로 구입해서 해두지, 작은 규모에서는 RAID컨트롤러를 설치해서 하기가 부담스럽다.
소프트웨어 RAID
- 기존 컴퓨터 구조를 그대로 이용하면서 RAID를 이용한다.
- RAID를 적용할 디스크만 있으면 별도의 하드웨어가 필요없어 비용 아낄 수 있다.
- 다른 작업들과 CPU 리소스를 공유하기 때문에 전반적인 작업 속도가 느려질 수 있다.
4.3.2 Eraser Coding
Hadoop 의 Eraser Coding(이하 EC) 은 RAID 방식을 소프트웨어로 구현한 것이다.
RAID 5,6 과 같이 패리티를 이용해 복구한다. 차이점은 패리티를 계산하는 방법에 차이가 있다.
RAID 6 처럼 데이터를 조각으로 나눠 Reed-Solomon와 같은 알고리즘을 사용하여 데이터 패리티를 생성한다.
여기서 RAID와 차이점은 데이터 보호 수준을 유연하게 설정할 수 있다는 점이다.
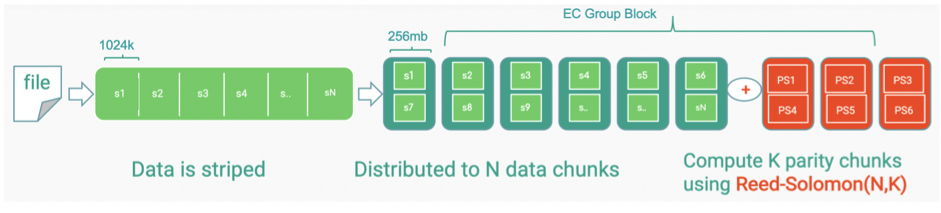
n개의 블록 조각을 연산을 통해 k개의 패리티를 생성한다.
이 n+k개 중 최대 k개의 데이터가 손실되어도 n개의 데이터만 살아있으면 원본 데이터가 복구 가능하다.
- N: 몇개의 chunk 로 나눌지
- K: 몇개의 parity 로 구성할지
- RS(N,K) 로 표현함.
https://db-blog.web.cern.ch/blog/emil-kleszcz/2019-10-evaluation-erasure-coding-hadoop-3
https://medium.com/@dsfan/hdfs-erasure-encoding-019b796b93db
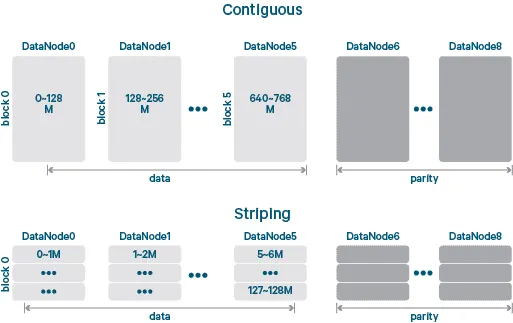
위 그림은 EC가 적용되기 전의 Hadoop의 block을 기반으로 parity 를 구성하는 것과, stripping 후에 parity를 구성한 것의 차이를 나타내는 그림이다.
Hadoop 의 논리적인 하나의 블록 사이즈는 여전히 동일하다.
contigous block 그림은 논리적 블록을 실제 스토리지 블록에 1대1로 매핑하는 것이다.
하나의 파일을 읽을 때 하나의 블록에 대해서 순차적으로 읽을 수 있다.
striped block 은 논리적 블록을 더 작은 단위인 셀(cell)로 쪼갠다.
write 는 셀들의 stripes 을 여러개로 구성된 storage block의 셋에 round robin으로 돌면서 저장한다.
read 또한 여러개의 storage block의 셋으로부터 cell들의 stripes 로 읽어들인다.
이 방법을 통해서 논리적인 블록 1개에 대해서 병렬처리가 가능해진다.
하둡 3에서 Erasure Coding(EC)은 단순히 패리티만 생성하는 것이 아니라, 먼저 블록을 스트리핑(Striping)한 뒤 패리티를 구성한다. 예를 들어, 블록 0의 크기가 128MB이고 이를 1MB 단위로 나눈다고 가정하면, 01MB, 12MB와 같이 쪼개진 각 셀(Cell)이 서로 다른 DataNode에 분산 저장된다. 이렇게 분산된 셀들은 연결되어 논리적인 블록 0을 구성하며, 이는 Hadoop 레이어에서 하나의 블록처럼 보이지만 실제 물리적으로는 여러 노드에 걸쳐 저장된다.
이렇게 나뉜 각 셀에 대해 패리티를 계산하고, 해당 패리티 블록을 별도로 저장한다. Hadoop에서 논리적인 하나의 블록 크기(예: 128MB)는 EC 적용 전후 모두 동일하다. 다만 Contiguous Block 방식에서는 논리 블록과 물리 스토리지 블록이 1:1로 매핑되어 순차적으로 저장되지만, Striping 방식에서는 여러 스토리지 블록 집합에 라운드로빈 방식으로 셀을 분산 저장한다. 각 셀은 Stripe 단위로 묶이며, Stripe들을 합친 것이 하나의 논리 블록이 된다.
읽기 작업 시에도 Striping 구조가 장점을 가진다. Contiguous Block 방식에서는 블록 0 전체를 다 읽어야 블록 1로 넘어갈 수 있는 순차적 접근 방식이지만, Striping 방식에서는 여러 노드에서 Stripe 단위로 병렬 읽기가 가능하다. Stripe에는 순서가 있으므로, 읽어들인 Stripe들을 순서대로 결합하면 하나의 블록을 재구성할 수 있다. 이로 인해 읽기 동시성이 크게 향상된다.
또한, 패리티를 저장하는 단위가 작아지므로 패리티 연산과 패리티 기반 복구 과정의 부하가 줄어든다. RAID 5나 RAID 6의 패리티 방식과 유사하지만, 단순 복제본을 두는 것보다 패리티 계산 과정이 추가되므로 쓰기 성능은 떨어질 수 있다. 반면, 병렬 읽기 덕분에 읽기 성능은 개선될 수 있다. 결국, 셀 단위 스트리핑과 Stripe 기반 병렬 읽기를 통해 하나의 논리 블록을 구성한다는 점이 Hadoop 3 Erasure Coding의 가장 큰 차이점이다.
4.3.3 Eraser Coding 장점
Eraser Coding 을 통해서 데이터의 복구 가능성은 높이면서 Storage 의 capacity loss 를 줄일 수 있다.
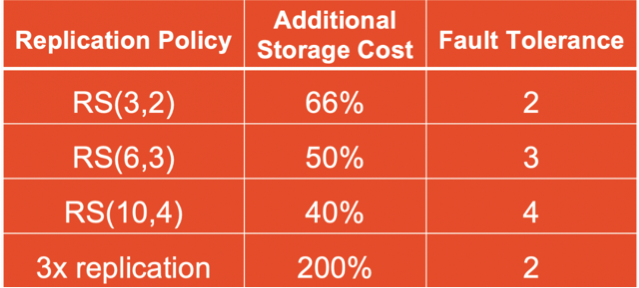
N과 K를 어떻게 설정하느냐에 따라 그 효율은 달라지지만, 최소한 기존에 3개 replica 로 최소한 2배 이상의 storage 를 추가로 사용하는 것보다는 모든 경우에 좋다.
https://db-blog.web.cern.ch/blog/emil-kleszcz/2019-10-evaluation-erasure-coding-hadoop-3
예를 들어 RS(3,2)로 설정한 경우, 하나의 논리 블록을 셀 단위로 나눈 뒤 3개의 데이터 셀로 스트리핑하여 저장한다. 여기에 원본 데이터 보호를 위해 추가로 2개의 패리티 셀이 생성된다. 따라서 전체 저장 셀 수는 원본 3개 + 패리티 2개 = 5개이며, 추가 스토리지 비용은 원본 대비 로 약 66%이다.
이렇게만 봐도 원래 200% 가 필요했던 것 보다 추가 비용이 줄었는데, falut tolerance는 높아졌다.
또한 striped block 을 통해서 논리적인 블록 1개에 대한 병렬성이 높아지므로, read performance 는 오히려 기존보다 증가했다.
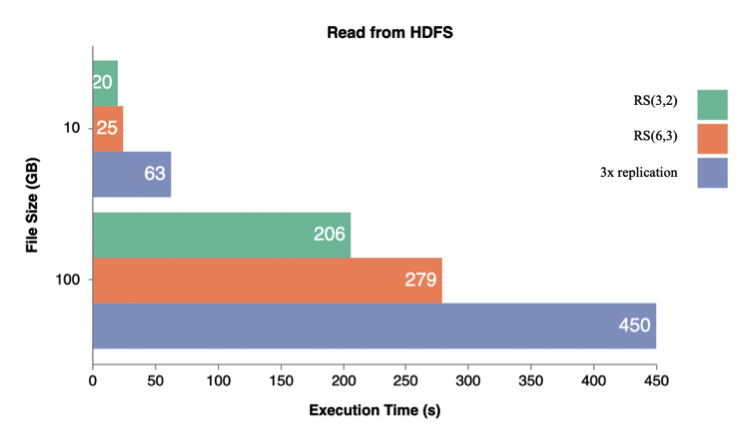
-
성능 지표 참고자료 : https://db-blog.web.cern.ch/blog/emil-kleszcz/2019-10-evaluation-erasure-coding-hadoop-3
-
file size가 클수록 Read 속도가 빨라지는 것을 볼 수 있다.
4.3.4 Eraser Coding 단점
RAID 에서 살펴본 것과 마찬가지로, Eraser Coding 은 단순 복사에 비해 encoding 과정이 추가되므로(복구시엔 decoding)
write 시에 parity 계산 과정이 추가되므로 write 의 성능이 떨어질 수 밖에 없다.
다만, intel 이 제공하는 ISA-L encoder library 덕분에 이 단점이 어느정도 상쇄될 수 있었다. (약 30% 감소)
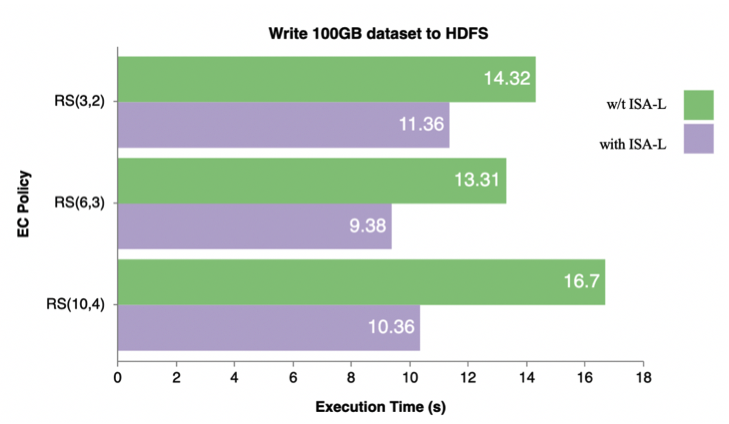
- 성능 지표 참고자료 : https://db-blog.web.cern.ch/blog/emil-kleszcz/2019-10-evaluation-erasure-coding-hadoop-3
이 자료에서는 어떤 환경에서 어떤 데이터셋을 사용했는지, 그리고 어떤 프레임워크로 테스트했는지까지 상세하게 기록되어 있다.
성능 테스트 또한 하나의 프레임워크를 기반으로 수행하는데, 벤치마크 전문가들은 다양한 규모와 특성을 가진 데이터셋을 활용하여 일관된 테스트를 진행한다. 서비스나 사용자마다 데이터 특성과 쿼리 패턴이 매우 다양하기 때문에, 이를 통일된 기준으로 비교하기 위해 표준 벤치마크 세트가 필요하다. 대표적인 예가 TPC-DS Benchmarking이다. TPC는 일종의 컨소시엄(또는 재단)으로, 여러 가지 표준 벤치마크를 제공한다.
데이터 사이언스 분야에서는 이러한 벤치마크를 실행하면, 자신이 사용하는 툴이나 플랫폼의 성능을 객관적으로 측정하고, 다른 환경과 비교할 수 있다. TPC-DS의 경우 SQL 쿼리 세트를 제공하며, Spark SQL과 함께 10GB, 100GB, 1TB 등의 데이터 크기에서 테스트할 수 있도록 설계되어 있다.
해당 자료에서는 이러한 TPC-DS 벤치마크를 활용해 Spark SQL 기반의 테스트를 진행했고, 데이터 크기별 성능 결과와 그래프가 직관적으로 제시되어 있다. 또한 데이터 소스와 테스트 시나리오 구성 방법도 명확하게 설명되어 있어, 앞으로 우리가 자체 성능 테스트를 설계할 때 참고 자료로 활용하기 적합하다. 이를 기반으로 테스트를 구성하면 신뢰성이 높고, 시간이 지나도 재활용할 수 있는 유용한 자료가 될 것이다.
