1 Hadoop을 사용하는 이유
오픈소스다.
1.1 Hadoop의 필요성
온라인 서비스와 온라인 데이터 처리 기술이 발전하면서, 데이터의 양과 종류가 다양해졌다.
정형 데이터의 경우 기존에 있던 RDBMS에 저장할 수 있지만, 웹 로그 등의 비정형 데이터를 RDBMS에 저장하기에는 데이터의 크기가 너무 크고, RDBMS의 복잡하고 상세한 기능이 필요하지도 않았다.
또한 RDBMS는 대용량, 고스펙의 장비에 운용하는데, 자주 사용하지 않는 데이터를 무작정 RDBMS를 늘려서 보관하는 것은 비용이 너무 크다.
하둡은 값비싼 장비가 아닌 x86 리눅스 서버라면 어떤 수준의 장비든지 하둡을 설치해서 운용할 수 있다.(commodity servers 같은 누구나 쓸 수 있는 서버)
또한 데이터 용량이 커지면 단순히 노드를 늘려서(scale-out) 대응할 수 있고, 이것을 재설치나 재구성 없이 할 수 있다는 점도 대용량을 위한 큰 장점이다. (다운타임 없이)
또한 하둡은 데이터의 복제본을 저장하기 때문에 유실이나 장애에도 데이터 복구를 할 수 있다는 점 또한 장점이다.
또한 여러대의 서버에 데이터가 저장되어있기 때문에 CPU자원, 메모리자원이 나눠져 있어서 프로세싱 또한 데이터가 분산된 서버에서 동시에 처리할 수 있다.
이런 분산 컴퓨팅을 통해서 기존의 데이터 처리 방법보다 큰 성능의 향상을 얻을 수 있다.
- 사례: 2008년 뉴욕타임즈에서 130년 분량의 신문기사 1100만 페이지를 AWS의 EC2, S3, Hadoop 을 이용해서 하루만에 모두 PDF로 변환 했다.
이 때 소요된 비용은 200만원이었다.- 당시 일반 서버에서 일반적인 병렬처리로 진행할 경우 약 14년이 걸리는 작업이었다.
1.2 Hadoop의 특징
하둡의 상세 기능은 많지만, 고수준(High-Level)에서 꼽을 수 있는 주요 특징은 다음과 같다.
Scalable: Hadoop can reliably store and process petabytes.Economical: It distributes the data and processing across clusters of commonly available computers. These clusters can number into the thousands of nodes.Efficient: By distributing the data, Hadoop can process it in parallel on the nodes where the data is located. This makes it extremely rapid.Reliable: Hadoop automatically maintains multiple copies of data and automatically redeploys computing tasks based on failures.
1.3 Hadoop 생태계
1.3.1 Hadoop V2로의 진화
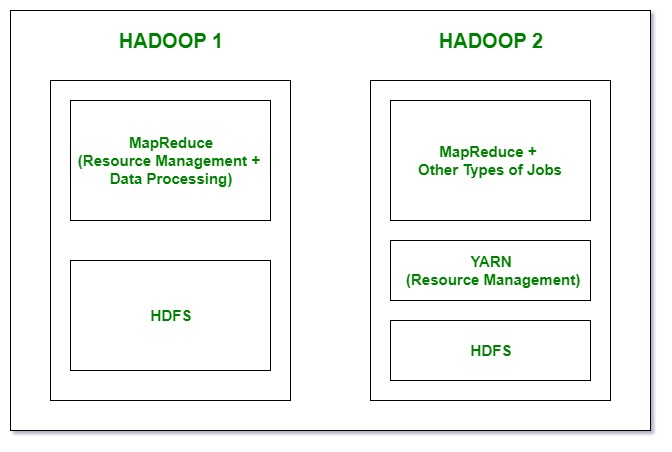
image source : https://www.geeksforgeeks.org/big-data/difference-between-hadoop-1-and-hadoop-2/
Hadoop v1 은 단순히 분산 파일 관리 시스템인 HDFS와 분산 데이터 처리를 위한 MapReduce 프레임워크만 제공했다.
MapReduce 는 데이터가 위치한 곳에서 연산을 처리할 수 있기 때문에 강력했지만, 사용이 불편했다.
Hadoop v2로 업그레이드 되며 아키텍처에서 큰 변화가 있었다. 노드와 파일시스템은 HDFS 를 근간으로 하지만, 그 이외에 모든 작업을 Yarn 이라는 Resource Management 프레임워크를 이용해서 유연하게 분산 처리 작업을 작성하고 활용할 수 있는 아키텍처로 바꾼 것이다.
내가 하는 작업이 내가 필요한 데이터가 있는 곳에서 이루어질 가능성을 높이는 걸 로컬리티라고 함. 네트워크 비용을 안 쓰니까 데이터 I/O 하는데 속도가 빨라짐. 이걸 Yarn이라는 중간 계층에서 추상화된 형태로 제공.
1.3.2 Yarn의 역할
Yarn 의 도입으로 기본 프레임워크인 MapReduce 뿐만 아니라, Tez, Flink, Spark 분산 처리를 위한 프레임워크나 도구들이 HDFS 와 HDFS가 설치된 컴퓨팅 자원을 더 쉽게 이용할 수 있게 되었다. 이것은 HDFS의 활용도를 높임과 동시에 강력한 생태계를 구축할 수 있도록 만들었다.
웹 어플리케이션 서버 쓰는 친구들은 원래는 데이터가 어느 노드에 있는지 찾았어야 했는데 안 찾아도 yarn이 이걸 알아서 해 주니까 남는 자원을 여유 있게 동적으로 할당받아서 쓸 수 있으면서 HDFS에 있는 로컬리티를 높이는 작업을 쉽게 할 수 있음.
1.3.3 Winner Takes All
대용량 데이터를 다루기 위해서는 기술적인 난이도가 높을 뿐만 아니라, 다양한 컴퓨팅 하드웨어, 소프트웨어와의 호환성 등으로 개발 공수가 크다.
또한 데이터가 많은 만큼 버그로 인한 사이드 이펙트 또한 커서, 안정적으로 사용하기 위해서는 성숙에 드는 시간이 필요하다.
하둡 에코시스템은 HDFS와 Yarn 을 기반으로 이 성숙의 과정을 거쳐오며 발전한 에코시스템인 만큼, 대용량 시스템에서 이 에코시스템을 대체할만한 대체자가 나오기 쉽지 않다.
이로 인해 새로운 대용량 분산시스템이 등장할 때는 새로운 시스템을 만들더라도 하둡 생태계를 지원하는 방향으로 기술 개발이 이루어지고 있다. ( 대표적으로 spark)
