2 HDFS
2.1 HDFS 의 Design Goal
2.1.1 Hardware Failure
HDFS를 구성하는 분산 서버에는 다양한 장애가 발생할 수 있다.
예를 들면 하드디스크에 오류가 생겨서 데이터 저장에 실패하는 경우, 디스크 복구가 불가능해 데이터가 유실되는 경우, 네트워크 장애가 생겨 특정 분산 서버에 네트워크 접근이 안되는 경우 등이 있다.
HDFS는 이런 장애를 빠른 시간에 감지하고 대처할 수 있게 설계되어있다.
HDFS에 데이터를 저장하면, 복제본도 함께 저장되어 데이터 유실을 방지한다.
분산 서버 사이에는 주기적으로 health check 를 통해 빠른 시간에 장애를 감지하고 대처할 수 있게 된다.
2.1.2 Streaming Data Access
RDB는 요청이 들어오면, 해당 데이터가 디스크의 어디에 저장되어 있는지를 찾아야 한다. 이러한 접근 방식을 ‘랜덤 데이터 접근(Random Data Access)’이라고 한다.
HDFS는 클라이언트의 요청을 빠르게 처리하는 것보다 동일한 시간 내에 더 많은 데이터를 처리하는 것을 목표로 한다.
HDFS는 이것을 위해 Random Access 를 고려하지 않는다. user와 상호작용하는 것보다는 batch 처리에 더 맞게 디자인 되어있다.
따라서 은행 서비스, 쇼핑몰과 같은 trasnactional 서비스에서 기존 파일시스템 대신 HDFS 를 쓰는 것은 적합하지 않다.
HDFS는 Random Access 대신 Streaming 방식으로 데이터를 접근하도록 설계되어 있다. Client 는 HDFS 명령어/API를 통해서 연속된 흐름(streaming)으로 데이터에 접근할 수 있다.
Streaming 방식으로 데이터를 접근한다는 것은,
디스크에서 데이터를 읽을 때 임의의 위치를 계속 건너뛰는 것이 아니라, 한 번 찾은 위치로부터 데이터를 순차적으로 이어서 읽어오는 방식을 의미한다.
이를 통해 디스크의 물리적인 읽기 헤더(헤드)가 계속 움직이지 않고, 한 방향으로 연속적으로 읽기(read) 작업을 수행할 수 있게 된다.
따라서 읽어야 할 데이터의 양이 크더라도, 순차적 접근(sequential access) 방식 덕분에 랜덤 접근(random access) 보다 I/O 성능이 훨씬 좋다.
2.1.3 Large Data Sets
HDFS는 하나의 파일이 GB ~ TB 수준의 데이터 크기로 저장될 수 있게 설계되었다.
이것으로 높은 데이터 전송 대역폭(bandwidth)를 지원하고 하나의 클러스터에서 수백대의 노드를 구성할 수 있다. 하나의 인스턴스에서는 수백만개(tens of million) 이상의 파일을 지원한다.
인프라에 소형 x86 서버로도 HDFS를 구성할 수는 있지만, 네트워크 대역폭이 1Gbps에 불과할 경우 충분한 성능을 기대하기 어렵다.
특히 HDFS는 대용량 데이터를 고속으로 읽고 쓰는 데 최적화된 분산 파일 시스템이기 때문에, 노드 간 데이터 전송 성능이 매우 중요하다.
따라서 HDFS를 본격적으로 운영하려면, 최소한 10Gbps 이상의 네트워크 대역폭을 갖춘 환경을 권장한다.
2.1.4 Simple Coherency Model
- 간단한 일관성 모델
데이터베이스에서 데이터의 무결성은, 데이터의 입력이나 변경을 제한해서 데이터의 안정성을 깨는 동작을 막는 것을 의미한다.
HDFS는 write-once-read-many access model 이 필요하다.
HDFS에서는 한 번 저장한 데이터는 수정할 수 없고, 읽기만 가능하게 무결성을 지킨다.
데이터 수정은 불가능하지만, 파일의 이동, 삭제, 복사는 지원한다.
최초에는 수정이 안되었지만, 현재는 end of file 위치에 append 가 가능하다.
- 스트리밍 데이터니까. append가 가능하게 되었다.
이런 Simple Data Coherency Model 은 데이터 접근에 대한 높은 throughput 을 가능하게 한다. 이 방식은 대량 데이터를 집계하는 MapReduce 에서 큰 장점을 발휘한다.
2.1.5 Moving Computation is Cheaper than Moving Data
데이터를 이용해서 computing processing 을 한다면, 데이터가 processor와 가까울 수록 효율이 좋다.
데이터의 양이 클수록 이 영향이 크다. Network 혼잡을 줄이고 시스템 전체의 throughput 을 높일 수 있다.
HDFS는 이것을 위해 computing 자원을 data가 있는 위치로 이동시키는 것을 선택한다.
- 유연하게 가능한 이유가 yarn 때문이다.
Data를 이동시키는 것보다 비용이 싸고 빠르기 때문이다.
HDFS는 이러한 방식을 위한 인터페이스를 제공한다.
2.1.6 Portability Across Heterogeneous Hardware and Software Platforms
- 이기종 하드웨어 및 소프트웨어 플랫폼 이식성
HDFS는 쉽게 HW/SW 플랫폼을 옮길 수 있도록 디자인 되었다.
인텔 칩, AMD칩이 설치된 하드웨어에서 동일한 기능으로 동작한다. CentOS나 Redhat LInux 상관없이 동일하게 동작한다.
- HDFS의 서버의 코드가 Java로 구현되어있기 때문에 가능하다.
대용량 데이터 셋의 플랫폼으로 채택되는 주요한 이유중 하나이다.
2.2 HDFS Architecture - Block based file system
2.2.1 Block based file system 이란?
https://data-flair.training/blogs/data-block/
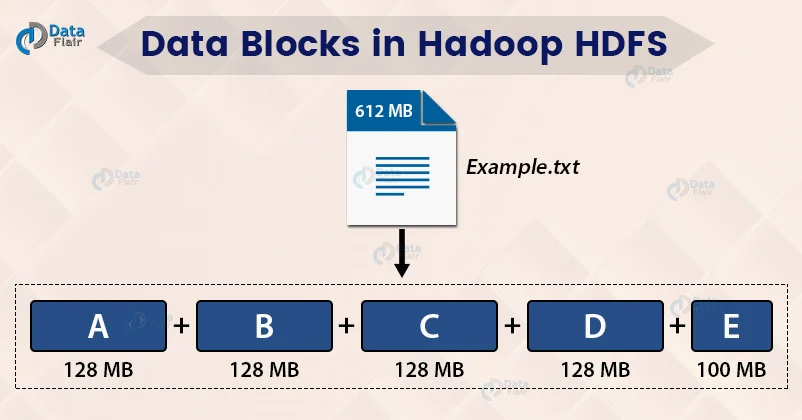
HDFS는 블록 구조의 파일 시스템이다.
HDFS에 저장되는 모든 파일은 일정 크기의 블록으로 나눠져서 여러 서버에 분산되어 저장된다.
블록 크기는 기본 128MB로 되어있고, 설정으로 변경이 가능하다.
블록단위로 분산해서 저장하기 때문에 로컬 디스크보다 큰 규모의 데이터를 저장할 수 있고, 저장할 수 있는 용량을 페타바이트 단위까지 확장할 수 있다.
2.2.2 파일과 Block
-
하나의 파일은 하나 또는 복수의 block 에 저장된다. 이때 어떤 파일이 어느 블록에 저장되어있는지는 메타데이터로 namenode가 메모리에서 관리한다.
-
복수의 파일이 하나의 block에 저장될 수 없다.
-
하나의 File의 사이즈가 block size 를 넘어가면, 여러개의 블록에 나누어 저장된다.
- 예 1) 하나의 파일 사이즈가 128MB+10bytes 라면, 128MB 블록 하나, 10bytes 블록 하나에 나뉘어 저장된다.
-
하나의 File 사이즈 또는 하나의 블록 사이즈를 초과하는 크기의 하나의 파일이 블록 사이즈로 딱 나누어떨어지지 않아서 남은 사이즈가 하나의 블록 사이즈보다 작다면, 해당 블록은 그 크기만큼 점유한 블록으로 관리된다.
- 예 1) 하나의 파일이 1MB이고 블록사이즈가 128MB라면, 128MB 블록 하나에 할당되어 1MB만 저장된다.
- 예 2) 하나의 파일이 129MB이고 블록 사이즈가 128MB라면, 해당 파일은 128MB 블록 한개, 1MB 블록 한개에 구성된다.
-
실제 디스크를 점유하는 공간은 블록 내에 파일이 차지하는 크기이다.
- 예) 블록 사이즈 128MB이고, 할당된 파일의 사이즈가 1MB 이라면, 실제 디스크 사용량은 1MB이다.
2.2.3 Block system의 장점
Block 크기를 적당한 수준(64MB, 128MB) 으로 고정해서 얻을 수 있는 장점은 다음과 같다.
-
Disk Seek time 감소
HDFS는 디스크 접근 시 발생하는 탐색 시간(seek time)을 최소화하기 위해, 블록 크기를 상대적으로 크게(64MB 또는 128MB) 설정한다. 일반적인 HDD에서 탐색 시간은 약 10ms이며, 디스크 I/O 대역폭은 100MB/s 수준이다. HDFS는 탐색 시간이 전체 블록을 읽는 데 걸리는 시간의 약 1% 수준으로 제한되도록 설계되었고, 이 기준에 따라 약 100MB 정도의 블록이 적절하다. 다만 메모리 정렬 및 처리 효율 등을 고려해 Hadoop v1에서는 64MB가 기본 블록 크기로 채택되었다. 이처럼 큰 블록 크기를 사용하면 디스크 접근 횟수를 줄이고, 그만큼 탐색 시간의 비중도 줄어들어 전체 I/O 성능이 향상된다.
RDB에서도 유사한 방식이 적용된다. 디스크에서 데이터를 조회할 때, 단일 레코드만 메모리로 로드하는 것이 아니라 일정 크기의 페이지 단위로 데이터를 읽어온다. 이로 인해 디스크 탐색 횟수를 줄이고, 연속적인 데이터 접근 성능을 높일 수 있다. 예를 들어, MySQL은 기본적으로 16KB 페이지 크기를 사용하며, Oracle은 최대 64KB까지 페이지 크기를 설정할 수 있다. 이런 페이지 기반 접근 방식은 HDFS에서 블록 단위로 데이터를 처리하는 설계와 개념적으로 유사하다.
-
Metadata size 감소
namenode(단일서버)는 블록 위치, 파일명, 디렉토리 구조, 권한 정보 등의 메타데이터 정보를 메모리에서 관리한다.
예를 들어 블록 사이즈가 128MB이라면, 200MB의 파일에 대해 2개 블록에 해당하는 메타데이터만 저장하면 된다. 하지만 일반적인 파일시스템은 블록(page) 크기가 4k~8k이기 때문에 동일한 크기의 파일을 저장할 경우 훨씬 많은 메타데이터가 생성된다.
200MB의 파일에 대해서 만약 블록 크기가 4k 이라면, 5만개의 블록이 생성되고 메타데이터 또한 5만개 분을 하나의 namenode에서 관리해야한다. namenode는 모든 메타데이터를 관리하는 단일 서버이므로 이렇게 메타데이터의 양이 늘어나는 것은 성능과 HDFS 안정성에 심각한 영향을 미친다.- namenode는 일반적으로 100만개 블록을 저장할 경우, 1GB의 heap memory를 사용한다.
-
Communication cost between Client and NameNode
클라이언트는 HDFS에 저장된 파일을 접근할 때, namenode에 먼저 해당 파일을 구성하는 데이터 블록의 위치를 조회한다.
데이터 블록이 작아서 그 갯수가 많다면, 이 조회에서 필요한 데이터가 많아지거나 조회 횟수가 증가할 것이다.
클라이언트는 스트리밍 방식으로 데이터를 읽고 쓰기 때문에 특별한 경우를 제외하면 namenode 와 통신할 필요가 없다.
2.3 HDFS Architecture - Name Node and Data Node
2.3.1 Overview
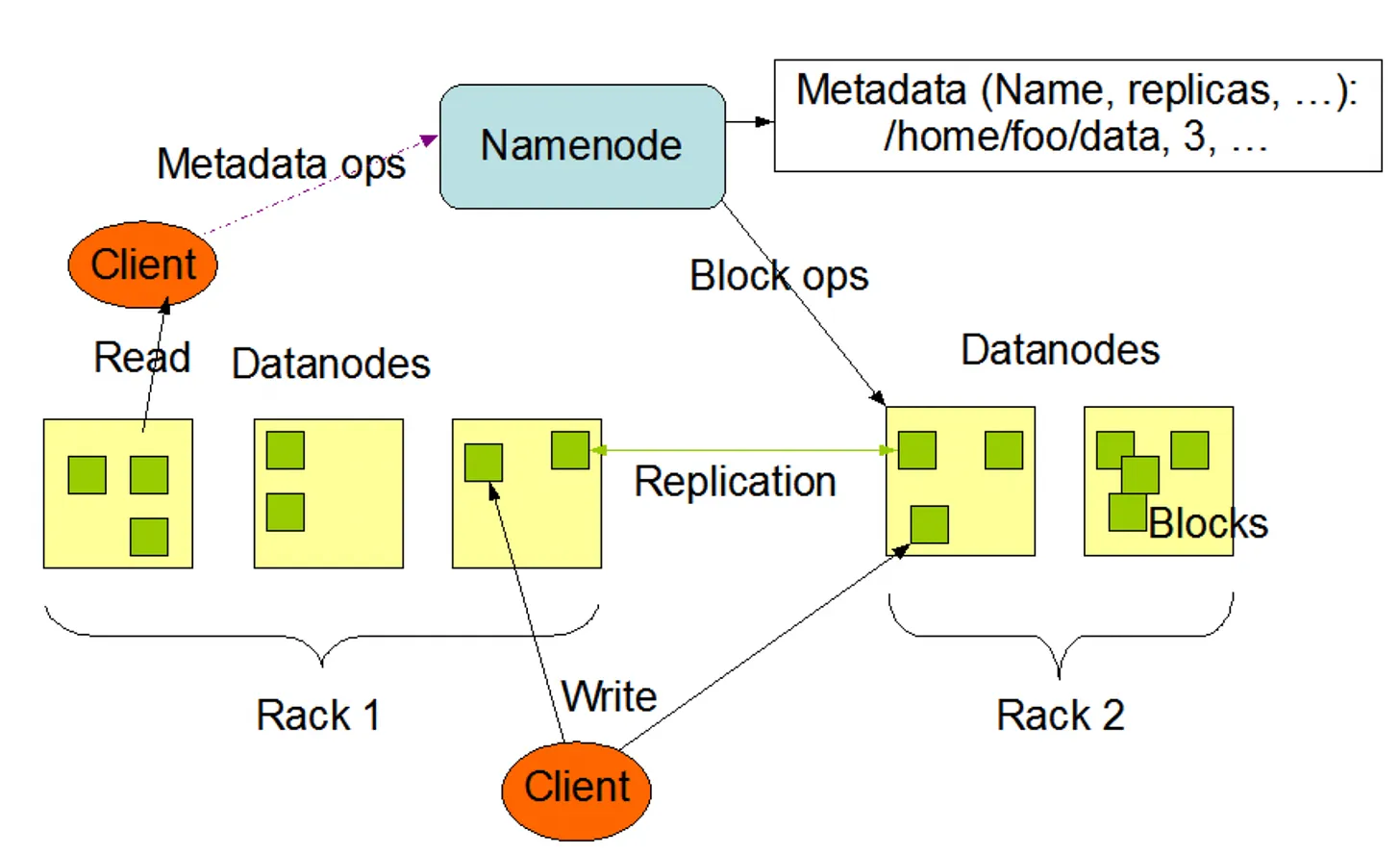
image source : https://vivekbansal.substack.com/p/basics-of-hadoop
2.3.2 Name node
네임노드는 블록의 위치, 권한 등의 정보를 유지한다.
기본적으로는 모든 현재 정보는 메모리에 유지하고, 두 종류의 파일로도 기록한다.
- Fsimage: File System Image 이다. name node 가 생성된 이후로부터의 HDFS의 namespace 정보를 모두 가지고 있다.
- Edit log: Fsimage 로부터 현재까지의 변경사항 로그이다.
Name node 는 다음과 같은 기능과 역할을 한다.
-
Metadata Management
파일 시스템을 유지하기 위한 메타데이터를 관리한다.
메타데이터는 파일 시스템 이미지(file name, directory, size, access/auth control)와 파일에 대한 블록 매핑 정보로 구성된다. 클라이언트에게 빠르게 응답해야 하므로 메모리에서 데이터를 관리한다.File system namespace의 모든 변경사항을 관리한다.
-
Data Node Management
Data Node 의 리스트를 관리, 유지, 변경 한다.
명시적인 admin 명령 또는 Monitoring 결과에 따라 대상을 변경한다. -
Data Node Monitoring
데이터노드는 네임 노드에게 3초마다 heart beat 를 전송한다.
heart beat 는 데이터노드 상태 정보와 데이터노드에 저장되어있는 블록의 목록(block report)으로 구성된다.
네임노드는 heart beat 데이터를 기반으로 데이터노드의 실행 상태, 용량 등을 관리한다. 그리고 일정 기간동안 heat beat 를 전송하지 않는 데이터 노드는 장애가 발생한 서버로 판단한다. -
Block Management
네임노드는 블록에 대한 정보를 관리한다.
장애가 발생한 데이터 노드를 발견하면, 해당 데이터 노드에 위치한 블록을 새로운 데이터 노드로 복제한다.
또한 용량이 부족한 데이터노드가 있다면, 용량의 여유가 있는 데이터 노드로 블록을 이동시킨다.
복제본의 수를 관리해서, 복제본의 수와 일치하지 않는 블록이 있다면 블록을 추가로 복제하거나 삭제한다. -
Client request
클라이언트가 HDFS에 접근할 때 언제나 네임노드에 먼저 접속한다.
파일을 저장하는 경우, 기존 파일의 저장 여부, 권한 체크 등을 한다.
파일을 조회하는 경우 실제 블록의 위치정보를 반환한다.
2.3.3 Data Node
데이터노드는 클라이언트가 HDFS에 저장하는 파일을 디스크에 유지한다.
저장하는 파일은 크게 두 종류이다.
- 실제 데이터인 로우(raw) 데이터
- chekcsum, created time 등 메타데이터가 설정된 파일
chekcsum : 로우데이터가 유효한지 확인
DataNode의 기능
- client 로부터 실제데이터의 read/write request 를 받아 처리한다.
- Name Node로부터 명령을 받아서 자신의 디스크에 있는 block을 생성, 복제, 삭제를 수행한다.
- HDFS 의 상태를 Name Node에게 heart beat 로 보낸다.
- 자신이 가진 block들의 리스트와 상태를 Name Node 에게 보낸다.
2.4 HDFS Architecture - Replication
하둡은 복제본을 자동으로 유지하기 때문에 유실로부터 안전하다.
대용량의 데이터를 다루기에 아주 좋다.
2.4.1 Block size 와 replication factor
HDFS는 여러대의 서버로 이루어진 클러스터에 큰 크기의 파일들을 신뢰성있게 저장하도록 디자인 되어있다.
각 파일의 내용은 여러개의 block의 리스트로 저장한다. 각 블록은 fault tolerance (고장 감내성)를 위해서 복제된다.
각 파일마다 block size 와 replication factor 가 지정된다.
HDFS의 fault tolerance는 개별 블록 수준에서 구현된다. 즉, 각 블록이 복제(replication)되어 여러 노드에 저장되기 때문에, 하나의 블록에 장애가 발생해도 다른 복제본을 통해 데이터를 복구할 수 있다.
이러한 구조 덕분에 파일 전체도 자연스럽게 fault-tolerant하게 된다. 왜냐하면 HDFS에서 하나의 파일은 여러 블록으로 구성되며, 그 각각의 블록이 모두 복제되어 있기 때문이다.
여기서 fault tolerance란 고장이 발생하지 않는다는 의미가 아니라, 고장이 발생하더라도 시스템이 이를 견디고 정상 동작을 유지하거나 빠르게 복구할 수 있는 능력을 의미한다.
따라서 실제 장애(fault)가 발생했을 때 데이터 손실 없이 안정적으로 복구되거나, 서비스의 중단 없이 처리되는 구조라면 이를 fault-tolerant하다고 한다.
하나의 파일의 모든 블록은 마지막 블록을 제외하고는 모두 같은 사이즈이다.(기본128MB)
단, 가변 길이 블록에 대한 지원이 append 와 hsync에 대해서는 가능해서 마지막 블록을 채우지 않고도 새 블록을 시작할 수 있다.
어플리케이션은 파일의 replica 수를 지정할 수 있다. 이것을 replication factor 라고 한다.
replication factor 는 파일 생성 시점에 정해지고, 생성 이후에 변경할 수도 있다.
HDFS의 파일들은 (append, truncate 를 제외하면) 한 순간에 하나의 writer 만 존재할 수 있다.
블록의 replication 에 대한 결정은 namenode 가 한다.
namenode 는 주기적으로 datanode 로부터 heart beat 와 block report를 받는다.
heart beat 는 datanode의 기능이 정상적으로 작동중인지를 알린다.
blockreport 는 해당 데이터노드에 있는 모든 block 의 리스트 정보를 포함하고 있다.
2.4.2 The purpose of Replica Placement
- 복제본을 어디에 위치시킬 건지
replica 의 위치는 HDFS의 신뢰성(reliability)과 성능(performance)에 큰 영향을 미친다.
replica 위치에 대한 최적화 규칙이 HDFS와 기존의 다른 분산 파일시스템과의 가장 큰 차이점이기도 하다.
이 기능에 많은 경험과 튜닝이 녹아있다.
replica placement와 관련된 모든 정책은 data reliability, availability, network bandwidth utilization을 개선하는 방향으로 이루어진다.
그 중 가장 첫번째 대표적인 것이 rack-aware replica placement이다.
2.4.3 Rack-Awareness
https://data-flair.training/blogs/rack-awareness-hadoop-hdfs/
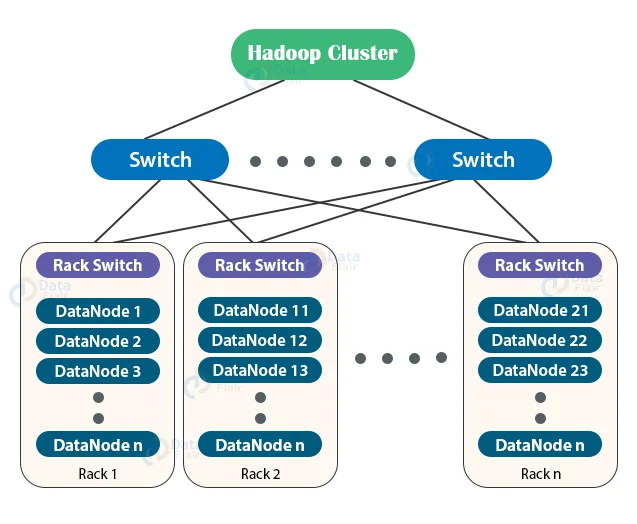
대용량 HDFS 클러스터에 존재하는 computing instance 들은 통상 많은 서버 랙(rack)에 위치한다.
- rack에는 하드웨어를 잘 유지하기 위한 전원공급장치, 네트워크 장치, 안에 있는 친구들을 관리하기 위한 도구들이 설치가 되어 있음
서로 다른 두 개의 랙에 위치한 두 개의 서버는 랙마다 존재하는 switch 를 거쳐서 통신하게 된다.
이 때, network bandwidth는 같은 랙에 있는 다른 서버와 통신할 때보다 더 증가하게 된다.
- Rack의 datanode들의 ip가 몇 번이고, 어떤 녀석들이 있는지 알고 있음.
1.1.1.0:80 로 접근할거야 라는 요청이 왔을 때, 렉 스위치가 그 주소는 여기 렉에는 없어~ 라고 응답하거나 여기있어~ 라고 응답을 라우팅 해줄 수 있음.
렉 안에 있는 스위치는 렉 안에 있는 녀석들이랑 밖에 있는 다른 스위치랑 연결해 주는 친구임.
밖에 있는 스위치들이 다른 렉정보들을 알고 라우팅을 해 준다.
이것들이 구성해서 하나의 하둡 클러스터를 이룬다.
Hadoop Rack Awareness 를 통해 namenode 는 각 datanode 의 rack id 를 알고 있다.
하둡 클러스터는 이 렉 정보를 알고 있다는 건데 왜 이 렉정보가 필요하냐?
datanode 1번이랑 datanode2번이랑 통신한다고 했을 때 네트워크가 물리적인 공간을 안 넘어나가고 OSI 7 Layer에서 L2레이어 안에서 응답이 되고 빨리 응답할 수 있다.
replica 를 위치시는 가장 간단한 정책은, 하나의 replica 는 unique rack 에 존재하도록 하는 것이다.
이것은 하나의 rack 이 통째로 장애가 났을때를 대비해서 데이터의 유실을 방지해준다.
또한 이 정책은 replica 들을 전체 랙에 골고루 분산하도록 유도하기 때문에 클러스터 전체의 부하를 분산(load balance)하는 효과도 쉽게 가져갈 수 있다.
하지만 이 정책은 write 시 여러개의 rack 걸쳐서 block 데이터를 전파해야 하므로 write operation의 비용(cost)를 증가시킨다.
2.4.4 Block Placement Policy Default
https://maninekkalapudi.medium.com/hdfs-hadoop-distributed-filesystem-f46ecc2993cd
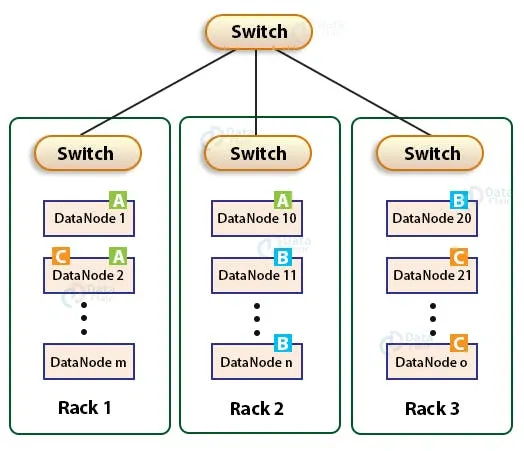
대부분의 경우 replication factor=3 이다.
이때의 HDFS 의 기본 placement policy(BlockPlacementPolicyDefault)는 다음과 같다.
-
하나의 replication 은 가능한한 writer 와 같은 rack 에 있는 datanode에 저장하도록 한다.
-
만약 writer 가 하나의 데이터노드에서 동작한다면, 기본적으로 하나의 replica 는 해당 데이터노드의 local에 저장하도록 한다.
-
만약 writer 가 데이터노드에 있는 것이 아니라면, writer 가 동작하는 노드와 같은 rack 에 있는 datanode를 random 하게 선택해서 저장한다.
-
-
나머지 두 개의 replica 는 writer와 다른 랙의 서로 다른 두 datanode 에 저장되도록 한다.
따라서 총 unique rack 의 수는 2이다.
이 정책은 다음과 같은 장점이 있다.
- write 시 rack 들 간에 발생하는 traffic을 줄여서 write 성능을 높인다.
- 만약 node failure의 가능성보다 rack failure 의 가능성이 낮다면, 이 정책은 data reliability and availability guarantees 에 영향을 미치지 않는다.
다음과 같은 단점이 있다.
- 총 network bandwidth을 줄이지는 못한다. (replica 별로 unique rack 에 위치시키는 것과 비교해서)
- 데이터가 rack 들 사이에 골고루 분산되지 못한다. 1:2로 위치하므로
만약 replication factor 가 3보다 크다면 4번 째 replica 는 다음 정책을 따른다.
- 다음 복제본은 랙당 복제본 수를 상한선 보다 낮게 유지하면서 무작위로 결정된다.
- 상한선 = (replicas - 1) / racks +2
- rack =3, replicas = 4 라고 한다면 (4-1)/3 + 2 = 3 <랙 당 복제본 수 상한선은 3>
namenode 는 기본적으로 하나의 datanode 가 같은 블록에 대해서 여러개의 replica 를 갖는것을 허용하지 않는다. 따라서 하나의 블록이 가질 수 있는 최대 replica 수는 총 datanode 수와 같다.
- m + n + o 개수보다 더 큰 리플리케이션 펙터는 가질 수 없다.
Storage Types and Storage Policies 정책이 추가된 이후로, namenode 는 replica placement 규칙에 rack-awareness 에다가 추가적인 정책을 고려한다.
- rack awareness 를 1순위로해서 replica 가 위치할 노드를 고른다. - 후보 노드가 된다.
- 후보 노드가 policy 에 의한 storage 를 필요로 하는지 체크한다.
- 후보 노드가 해당하는 storage type 을 가지고 있지 않다면, namenode는 다른 후보노드를 찾는다.
- 위 과정으로 replica 가 위치할 노드를 찾지 못한다면, fallback storage type 을 가진 노드를 찾는다.
Storage Types: ARCHIVE, DISK, SSD, RAM_DISK and NVDIMM
Storage Policies: Hot, Warm, Cold, All_SSD, One_SSD, Lazy_Persist, Provided and All_NVDIMM
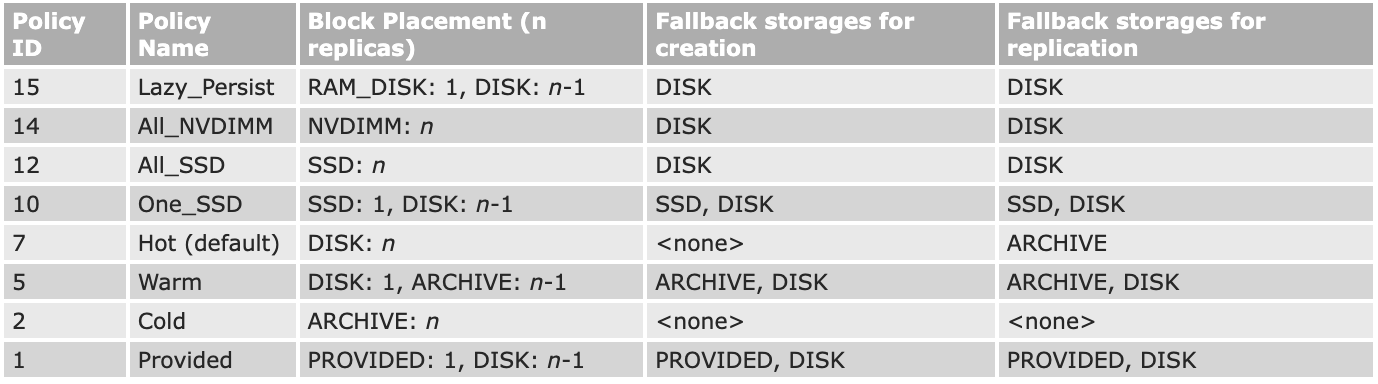
기본정책 외에 추가로 4 종류의 pluggable policies 가 있다.
2.4.5 Replica Selection - Read
글로벌 bandwidth 소비를 줄이고, read latency 를 줄이기 위해서 HDFS는 read 요청에 대해서 reader 와 가까운 곳에 있는 replica 로부터 데이터를 읽도록 시도한다.
reader node 와 같은 rack 에 replica 가 존재한다면, 해당 read 요청은 그 replica 에서 데이터를 읽는다.
만약 HDFS 클러스터가 여러 데이터센터에 걸쳐져 있다면, 같은 데이터센터에 있는 replica 를 읽는 것을 선호한다.
2.4.6 Safemode
namenode 가 최초로 기동될 때 namenode 는 Safemode 라는 특별한 상태에 들어간다.
이 Safemode 에서는 replication 이 발생하지 않는다.
Datanode 로부터 받은 blockreport 의 내용을 종합해서 모든 블럭에 대한 replication 이 일정 수준(%)을 넘어서 잘 구성되어있다면, 그 때 이 Safemode 에서 빠져나온다. 이 % 값은 변경이 가능하다.
Safemode 에서 빠져나온 뒤에, 모자란 replication factor가 있는 블록이 있다면 복제를 수행한다.
HDFS에서 리플리케이션은 데이터 블록을 여러 DataNode에 복제하여 저장함으로써 내구성과 가용성을 확보하는 방식이다.
리플리케이션 정책에서 고려하는 요소 중 가장 중요한 것은 Rack Awareness이다.
Rack Awareness는 블록 배치 시 클러스터의 물리적 네트워크 구조인 랙 정보를 인식하여, 쓰기 로컬리티를 높이면서도 높은 가용성을 유지하기 위해 사용한다.
기본 정책은 첫 번째 복제본을 클라이언트와 가까운 같은 랙의 DataNode에 저장하고, 두 번째 복제본은 다른 랙의 DataNode에 저장하며, 세 번째 복제본은 두 번째 복제본과 같은 랙의 다른 DataNode에 저장하는 것이다.
이는 모든 복제본을 서로 다른 랙에 배치하면 가용성은 높지만 쓰기 성능이 크게 저하되므로, 성능 저하를 최소화하면서도 장애 대응력을 유지하기 위해 채택된 방식이다.
또한 랙 단위 장애 발생률이 개별 노드 장애보다 훨씬 낮다는 가정에 기반하여 두 개의 복제본을 같은 랙에 배치하며, 정책은 필요에 따라 커스터마이징할 수 있다.
이와 함께 HDFS는 한 랙에 존재할 수 있는 복제본 수의 상한선과 전체 복제본 수의 제한을 두어 네트워크 부하와 저장 공간 낭비를 방지한다.
2.5 HDFS Architecture - File Read/Write
2.5.1 Read Process
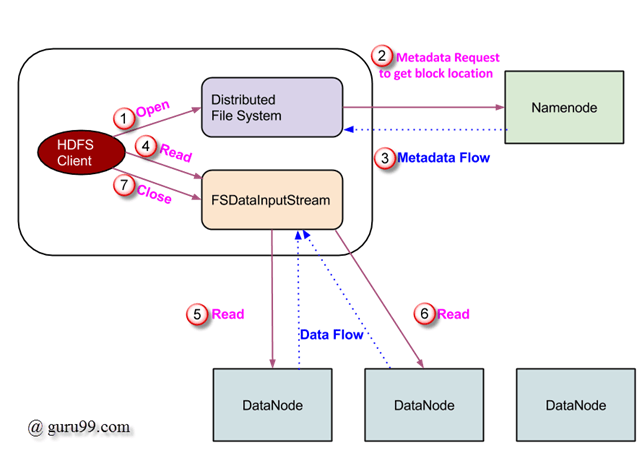
https://www.guru99.com/learn-hdfs-a-beginners-guide.html
왼쪽 상단 박스는 클라이언트의 JVM.
-
클라이언트가 DistributedFileSystem object의 open() 메소드로 HDFS 파일을 읽겠다는 요청을 시작한다.
-
DistributedFileSystem은 RPC로 namenode 에 연결한다.
open 대상이 되는 파일의 메타데이터를 조회한다. (파일이 존재하는지, 파일에 대한 권한이 있는지 등)
메타데이터 안에는 해당 파일이 저장되어있는 block의 location 정보 등이 있다.
한 번에 모든 블록정보를 리턴하지 않고 처음 몇개의 블록의 주소를 리턴한다. -
메타데이터 요청에 대한 응답으로 해당 블록(copy본 포함)을 가진 datanode 들의 주소가 리턴된다.
-
받은 DataNode 주소정보로 FSDataInputStream 객체를 만들어 client에게 전달된다. FSDataInputStream는 DataNode 와 NameNode 와 상호작용할 수 있는 DFSInputStream을가지고 있다. client가 DFSInputStream에 대해 read() 메소드를 호출하고 대상 파일의 첫 번째 블록이 있는 datanode 와 connection 을 맺는다. 이때 연결하는 대상은 primary datanode로, 가장 가까운 데이터 노드를 찾는다.
-
예1 - Local Block First
block A가 datanode 1 에 primary 버전이 있고 datanode 2,3 에 replica 버전이 있다고 했을때, datanode2 에 위치한 client 에서 block A 에 대해 read 요청이 온다면, 자신의 로컬인 datanode 2의 replica 버전에서 데이터를 읽는다.
-
예2 - Rack Awareness
block A가 rack a에 위치한 datanode 1 에 primary 버전이 있고 rack b에 위치한 datanode 2, rack b에 위치한 datanode 3 에 replica 버전이 있다고 했을때, rack2 에 위치한 datanode 4에 있는 client 에서 block A 에 대해 read 요청이 온다면, 자신과 같은 rack2 에 위치한 datanode 2의 replica 버전에서 데이터를 읽는다.
-
-
데이터는 read() 메소드를 반복해서 호출할때마다 stream 형태로 리턴된다. read과정은 end of block 에 도달할 때까지 지속된다.
-
end of block 에 도달하면, DFSInputStream은 datanode 와의 연결을 끊고, 해당 파일의 다음 블록이 위치한 데이터 노드와 연결을 맺는다. 이 과정은 해당 파일의 모든 블록을 읽을 때까지 계속된다.
-
read 과정이 끝나면 client 는 close() 로 모든 연결과 스트림을 닫고 끝낸다.
2.5.2 Write Process
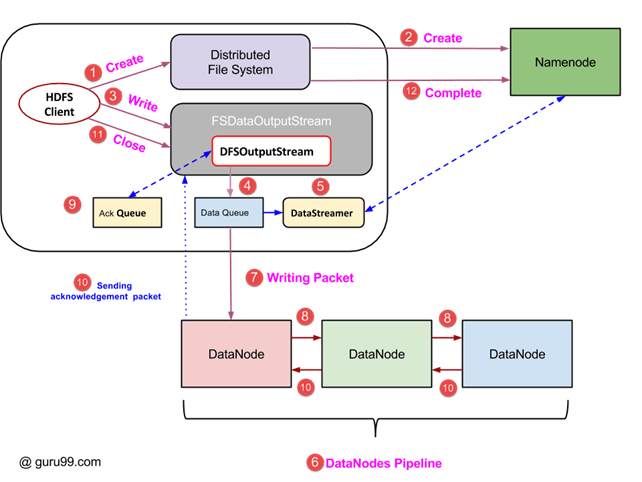
https://www.guru99.com/learn-hdfs-a-beginners-guide.html
- 새로운 파일 생성은 클라이언트가 DistributedFileSystem object 에서 create() 메소드 호출로 시작한다.
- DistributedFileSystem object 는 RPC로 namenode에 연결하고, 새로운 파일 생성을 시작한다. 이때 namenode 는 새로운 파일 생성 요청에 대한 verification을 진행한다. verification 은 파일이 이미 존재하는지, 해당 경로에 대한 권한 등을 확인한다. 이 때 verification 에서 실패하면 client에서는 IOException이 던져진다. verification에 성공하면 namenode 에서 해당 파일 record 가 생성된다.
- namenode 에서 파일 record 가 생성되면 클라이언트에 FSDataOutputStream object 가 리턴된다. FSDataOutputStream로 write 를 수행한다.
- FSDataOutputStream은 datanode 와 namenode 와 상호작용하는 DFSOutputStream 을 가지고 있다. DFSOutputStream은 클라이언트가 데이터를 write 하기 위한 packet을 만든다. 해당 packet 은 DataQueue 에 들어간다.
- DataStreamer는 또한 NameNode에 새 블록 할당을 요청하고, 복제에 사용할 바람직한 DataNode를 선택한다.
- 복제 과정은 DataNode들로 파이프라인을 생성하면서 시작한다. 위 그림의 경우 복제 수준을 3으로 선택했기 때문에 파이프라인에 3개의 DataNode가 있다.
- DataStreamer 는 DataQueue 로부터 데이터를 consume 해서 파이프라인의 첫번째 datanode 에 저장할 패킷을 전송한다.
- 하나의 파이프라인으로 묶인 모든 데이터노드는 저장을 위해 받은 packet 을 모두 저장하고, 이것을 파이프라인의 다음 데이터노드로 foward 한다.
- DFSOutputStream의 Ack Queue는 DataNodes로부터 acknowledgement 을 받으면 저장되는 queue이다.
- 파이프라인의 모든 데이터노드로부터 ack 가 queue 에 들어오면, Ack Queue 는 삭제된다. 만약 하나의 datanode 라도 데이터 저장과 ack 전송에 실패하면, Ack Queue 에 받은 패킷정보를 보고 재시작을 할 수 있다.
- 클라이언트의 write 작업이 끝나면, close() 메소드가 호출된다. close 는 모든 남은 data packet 을 flush 하고 ack 를 기다린다.
- 마지막 ack가 도착하면 클라이언트는 namenode에 write 작업이 끝났음을 알린다.
