2 Hive Architecture
Hive는 전통적인 RDBMS처럼 SQL 유사 언어(HiveQL)를 제공하지만, 실제 쿼리를 실행할 때는 분산 환경에 맞게 변환하여 실행한다.
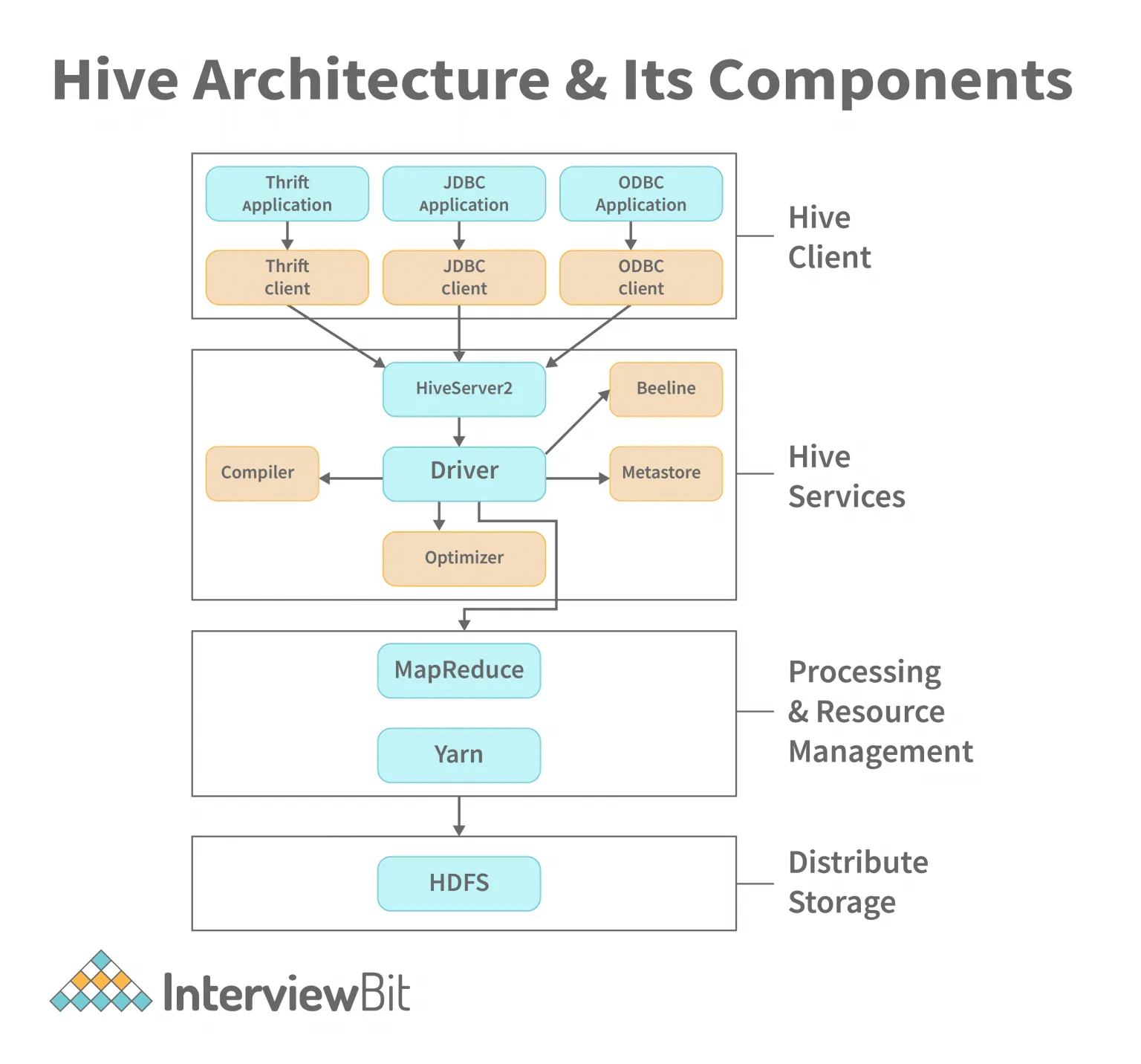
전체 아키텍처는 크게 Client Layer, Service Layer, Processing & Resource Management Layer, Distributed Storage Layer로 구분된다.
각 레이어는 쿼리 실행의 단계별 역할을 담당하며, 이들이 유기적으로 연결되어 Hive 쿼리가 실행된다.
https://www.interviewbit.com/blog/wp-content/uploads/2022/06/Hive-Architecture-1536x1432.png
{kind=link}
2.1 Hive Client
Hive Client Layer는 사용자가 Hive에 쿼리를 전달하는 인터페이스 역할을 한다.
-
Hive는 JDBC, ODBC, Thrift와 같은 다양한 프로토콜을 지원한다.
-
따라서 Python, Java, C++, Ruby 등 다양한 언어로 작성된 애플리케이션은 해당 프로토콜을 지원하는 Hive Client Driver를 이용하여 Hive Server에 연결할 수 있다.
-
Beeline은 Hive 전용 CLI로, JDBC를 이용해 Hive Server2에 직접 연결한다
즉, Hive Client Layer는 사용자의 쿼리를 Hive 시스템으로 전달하기 위한 진입점이다.
2.2 Hive Service
Hive Services Layer는 Hive의 핵심 서비스들이 동작하는 영역으로, 클라이언트로부터 전달된 요청을 실제 실행 가능한 계획으로 변환한다.
2.2.1 Hive Server 2
-
Hive Server 2는 클라이언트의 쿼리를 받아들이는 서버이다.
-
JDBC, ODBC, Thrift 프로토콜을 모두 처리할 수 있다.
-
Hive Server 1은 한 번에 하나의 요청만 처리할 수 있었지만, Hive Server 2는 멀티 스레드를 지원하여 동시에 여러 요청을 병렬로 처리할 수 있다.
즉, Hive Server 2는 동시성(concurrency)과 확장성(scalability) 측면에서 큰 개선이 이루어진 구성 요소이다.
2.2.2 Hive Driver
-
Hive Driver는 Hive Server 2로 들어온 쿼리를 받아 세션을 관리하고 실행 과정 전체를 조율한다.
-
Driver는 쿼리를 Compiler에 전달하여 파싱과 검증을 수행하게 하고, Metastore에서 필요한 메타데이터를 조회한다.
-
이후 실행 계획을 최종적으로 관리하며, Execution Engine에 계획을 전달한다.
즉, Driver는 Hive 쿼리 실행의 컨트롤 타워 역할을 한다.
2.2.3 Metastore
-
Metastore는 Hive 테이블과 관련된 모든 메타데이터를 저장하고 관리한다.
-
관리하는 정보에는 테이블 스키마(컬럼, 파티션), HDFS 상의 파일 위치, 데이터 포맷(SerDe), 접근 권한 정보 등이 포함된다.
-
메타스토어는 Hive 서버 내부에 구성할 수도 있지만, 일반적으로는 외부 RDBMS(MySQL, PostgreSQL 등)를 사용한다.
-
이는 대규모 데이터 및 사용자 환경에서 HA 구성과 안정적인 메타데이터 관리를 가능하게 하기 때문이다.
2.2.4 Compiler(paser)
-
Compiler는 Driver로부터 받은 HiveQL 쿼리를 파싱하고, 문법적 검증(syntax check)과 의미적 검증(semantic analysis), 타입 검사(type check)를 수행한다.
-
검증이 끝나면 실행 계획(Execution Plan)을 생성한다.
-
Hive의 실행 계획은 DAG(Directed Acyclic Graph) 형태로 표현되며, 각 단계가 Map 또는 Reduce 작업에 매핑된다.
2.2.5 Execution Engine
Execution Engine은 Compiler가 생성한 실행 계획을 실제 실행 환경에 맞게 수행한다.
Execution Engine은 선택 가능하며, 기본적으로는 MapReduce를 사용한다. 필요에 따라 Apache Tez 같은 대체 엔진을 사용할 수 있다.
Execution Engine은 논리적 실행 계획을 실제 물리적 작업으로 변환하는 실행자이다.
2.2.6 Beeline
-
Beeline은 Hive 전용 CLI 툴로, JDBC를 통해 Hive Server 2에 직접 연결한다.
-
사용자는 Beeline을 통해 HiveQL 쿼리를 입력하고 실행할 수 있다.
2.3 Processing and Resource Management
-
Processing & Resource Management Layer는 Hive에서 생성된 실행 계획을 어떤 분산 실행 엔진을 통해 수행할지 결정한다.
-
Hive의 실행 계획은 DAG 형태로 구성되며, DAG의 각 단계는 Map 태스크 또는 Reduce 태스크로 매핑된다.
-
Hive는 실행 엔진으로 기본적으로 MapReduce를 사용하지만, 더 나은 성능을 위해 Apache Tez나 Spark와 같은 대안도 선택할 수 있다.
-
실행 엔진은 YARN과 연동되어 필요한 리소스를 할당받고 작업을 스케줄링한다.
이 계층은 실행 계획을 적절한 실행 엔진과 자원 관리 프레임워크에 연결하는 다리 역할을 한다.
2.4 Distributed Storage
-
Distributed Storage Layer는 Hive 쿼리가 실제로 데이터를 읽고 쓰는 계층이다.
-
Hive의 모든 데이터는 결국 HDFS, Amazon S3, Azure Blob Storage와 같은 분산 파일 시스템에 저장된다.
-
Hive는 실행 계획에 따라 데이터를 읽어오고, 가공하며, 그 결과를 다시 분산 스토리지에 저장한다.
Hive의 최종 입력과 출력은 항상 분산 스토리지를 기반으로 한다.
