2 OpenSearch의 텍스트 인덱싱과 전문 검색
전문 : Full-text
챕터 1에서 OpenSearch의 기본적인 구성 요소와 CRUD에 대해 알아봤다. 챕터 2에서는 OpenSearch의 핵심이라고 볼 수 있는 인덱싱과 전문 검색에 대해 알아보려고 한다.
앞서 OpenSearch는 필드의 매핑 타입에 따라 인덱싱하는 방법이 다르다고 설명했다. OpenSearch에서 string 데이터는 보통 keyword 타입과 text 타입으로 매핑된다. 두 타입의 핵심 차이점은 인덱싱할 때 분석 과정의 유무다. text 타입은 도큐먼트가 추가되거나 업데이트 될 때마다 분석 과정을 거치는 반면, keyword 타입은 텍스트 그대로 인덱싱된다.
인덱싱 방법이 다르기 때문에 검색되는 방법도 다르다. text 타입을 검색할 때는 도큐먼트의 텍스트 그대로를 사용하지 않고, 별도로 저장된 데이터 구조를 활용하여 쿼리를 수행하는 반면, keyword 타입은 검색할 때 도큐먼트의 텍스트 그대로를 사용한다.
- text type은 ingest 단계에서 load 가 크다.
- keyword type은 cardinality 가 적은 필드에 사용하는 것이 성능에 좋다.

출처: https://codingexplained.com/coding/elasticsearch/understanding-analysis-in-elasticsearch-analyzers
위의 그림은 text 타입의 인덱싱 과정을 표현한 것이다. 도큐먼트의 text 필드에 대해 텍스트 분석을 수행하고, 이후 분석 결과를 역색인(Inverted index)이라는 데이터 구조에 맞춰 저장한다. 지금부터 텍스트 분석과 역색인에 대해 알아보자.
2.1 OpenSearch의 텍스트 분석(Analysis)
2.1.1 OpenSearch 텍스트 분석기(Analyzer) 구성 요소
OpenSearch의 텍스트 분석 과정은 분석기에 의해 수행된다. 분석기는 3가지 요소로 구성되며, 특징은 다음과 같다.
- 캐릭터 필터(Character filters)
- 분석기에 여러 개의 캐릭터 필터를 추가할 수 있다. (선택 요소)
- 입력받은 텍스트에서 약속된 문자를 추가, 제거, 변경한다.
- 예를 들어, 텍스트에서 HTML 태그를 삭제하기 위해 사용할 수 있다.
- 마스킹 (김**)
- 토크나이저(Tokenizer)
- 분석기에는 하나의 토크나이저만 설정할 수 있다. (필수 요소)
- 캐릭터필터는 안 돌 수 있는데 토크나이저는 무조건 수행됨.
- 텍스트를 개별 토큰으로 분리한다. (토큰은 일반적으로 단어 단위)
- 토큰으로 분리할 때 토큰에 대응되는 단어가 원본 텍스트에서 시작하고 끝나는 위치 정보를 저장한다.
- 예를 들어 "Hello, world!"가 "hello"와 "world"로 토크나이징 됐다면, "world"의 위치 정보는
(7, 12)로 표현할 수 있다. - 토큰의 위치 정보를 활용하면 원본 텍스트에서 토큰과 매칭되는 단어를 찾을 수 있다.
- 위치 정보 외에도 토큰 순서 등 다양한 메타데이터가 함께 저장된다.
- 예를 들어 "Hello, world!"가 "hello"와 "world"로 토크나이징 됐다면, "world"의 위치 정보는
- 다양한 종류의 토크나이저가 있는데, OpenSearch에서는 standard 토크나이저를 기본으로 사용한다.
- standard 토크나이저는 유니코드 텍스트 분할(Unicode Text Segmentation) 알고리즘을 사용하며, 공백 기준으로 텍스트를 분리하고, 쉼표, 마침표, 세미콜론 등의 기호를 제거한다.
- whitespace 토크나이저의 경우 standard와 달리 기호를 제거하지 않는다.
- 토크나이저 종류에 따라 토크나이징 알고리즘이 다르기 때문에 목적에 맞게 선택하면 된다.
- 분석기에는 하나의 토크나이저만 설정할 수 있다. (필수 요소)
또 다른 예시로,
"Data Science is fun!"이라는 문장에서"Science"라는 단어가 토큰으로 추출되었다면,
그 위치 정보는(5, 12)로 표현할 수 있다.
"Data Science is fun!""Science"는 5번째 문자에서 시작해 12번째 문자에서 끝난다.- 공백 포함 인덱스 계산:
인덱스: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 문자: D a t a S c i e n c e i s f u n !- 따라서
"Science"는 index(5, 12)범위에 해당한다.
- 토큰 필터(Token filters)
- 분석기에 여러 개의 토큰 필터를 추가할 수 있다. (선택 요소)
- 분리된 토큰들에 대해 토큰을 추가, 삭제, 변경할 수 있다.
- 캐릭터 필터는 텍스트를 입력 값으로 받지만, 토큰 필터는 토큰들을 입력 값으로 받는다.
- 대표적으로 lowercase 토큰 필터와 stop 토큰 필터가 있다.
- lowercase 토큰 필터는 모든 문자를 소문자로 변환한다.
- stop 토큰 필터는 불용어(stop word)를 제거한다. 불용어는 "the", "a", "and", "at"과 같이 크게 의미 없는 단어를 뜻한다. 불용어는 문법적인 필요에 의해 사용되는 경우가 대부분이므로, 검색에 관해서는 큰 가치를 갖지 못할 때가 많다.
텍스트
2.1.2 OpenSearch 텍스트 분석 과정

출처: https://codingexplained.com/coding/elasticsearch/understanding-analysis-in-elasticsearch-analyzers
OpenSearch는 도큐먼트에서 string 데이터 필드 탐지하면 해당 필드를 text 필드로 지정하고 standard 분석기를 적용한다. 위의 그림은 standard 분석기의 기본 동작을 설명한다.
- standard 분석기에는 캐릭터 필터가 없기 때문에 입력된 텍스트는 바로 토크나이저로 전송된다.
- standard 분석기는 standard 토크나이저를 사용하여 다양한 기호를 걸러내고, 공백으로 텍스트를 분리한다. 아래 그림에서 토크나이징 결과 하이픈과 느낌표가 삭제된 것을 확인할 수 있다.
- 토크나이저가 출력한 토큰 배열은 토큰 필터 체인으로 전송된다.
1. 첫 번째로 standard 토큰 필터로 전송된다. 이 토큰 필터는 실제로는 아무것도 하지 않는다. 이후 기본 필터링을 추가해야 될 경우에 대비해서 플레이스 홀더 역할을 한다.
2. stop 토큰 필터로 전송된다. 기본적으로 비활성화되어 있기 때문에 아무 것도 하지 않는다.
3. lowercase 토큰 필터로 전송된다. 모든 토큰을 소문자로 변환한다. 아래 그림에서 "I’m"이 "i’m"으로 변환된 것을 확인할 수 있다.

출처: https://codingexplained.com/coding/elasticsearch/understanding-analysis-in-elasticsearch-analyzers
standard 외의 분석기를 사용하고 싶다면 명시적으로 분석기 타입을 지정해주면 된다. 위의 그림은 HTML 태그를 삭제하는 캐릭터 필터를 추가한 분석기다.
필요한 경우 토크나이저와 다양한 필터를 조합하여 커스텀 분석기를 만들 수 있으며, 캐릭터 필터와 토큰 필터는 선택 사항이기 때문에 필터가 필요 없다면 토크나이저 한 개로만 분석기를 구성할 수도 있다. 본 강의에서는 OpenSearch에서 제공하는 기본 standard 분석기를 사용할 예정이며, 커스텀 분석기에 대해 궁금하다면 공식 문서를 참고하면 된다. (https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-custom-analyzer.html)
2.1.3 OpenSearch 텍스트 분석 실습
GET /_analyze API로 텍스트를 분석해볼 수 있다.
아래 명령어로 "Hello, world!"라는 텍스트를 standard 분석기로 분석해보자. 응답 본문을 보면 "Hello,"가 "hello"로, "world!"가 "world"로 토크나이징된 것을 확인할 수 있다. 토크나이저에서 모든 기호를 삭제하고, 토큰 필터 체인에서 모든 문자를 소문자로 변환했기 때문이다. 또한 start_offset과 end_offset 정보를 통해 어떤 토큰이 어떤 단어와 매칭되는지 알 수 있다.
$ curl -XGET "$OPENSEARCH_REST_API/_analyze?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"analyzer": "standard",
"text": "Hello, world!"
}
'
{
"tokens" : [
{
"token" : "hello",
"start_offset" : 0,
"end_offset" : 5,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "world",
"start_offset" : 7,
"end_offset" : 12,
"type" : "<ALPHANUM>",
"position" : 1
}
]
}다음 명령어로 텍스트 배열을 분석할 수도 있다.
$ curl -XGET "$OPENSEARCH_REST_API/_analyze?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"analyzer" : "standard",
"text" : ["first array element", "second array element"]
}
'
{
"tokens" : [
{
"token" : "first",
"start_offset" : 0,
"end_offset" : 5,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "array",
"start_offset" : 6,
"end_offset" : 11,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "element",
"start_offset" : 12,
"end_offset" : 19,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "second",
"start_offset" : 20,
"end_offset" : 26,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "array",
"start_offset" : 27,
"end_offset" : 32,
"type" : "<ALPHANUM>",
"position" : 4
},
{
"token" : "element",
"start_offset" : 33,
"end_offset" : 40,
"type" : "<ALPHANUM>",
"position" : 5
}
]
}토크나이저, 토큰 필터, 캐릭터 필터를 임시로 커스텀해서 분석할 수도 있다. 다음 명령어로 uppercase 토큰 필터를 사용하여 텍스트를 대문자로 변환할 수 있다.
$ curl -XGET "$OPENSEARCH_REST_API/_analyze?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"tokenizer": "standard",
"filter": ["uppercase"],
"text": "OpenSearch Custom Analyzer"
}
'
{
"tokens" : [
{
"token" : "OPENSEARCH",
"start_offset" : 0,
"end_offset" : 10,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "CUSTOM",
"start_offset" : 11,
"end_offset" : 17,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "ANALYZER",
"start_offset" : 18,
"end_offset" : 26,
"type" : "<ALPHANUM>",
"position" : 2
}
]
}다음 명령어로 html_strip 캐릭터 필터를 사용하여 텍스트에서 HTML 태그를 제거할 수 있다.
$ curl -XGET "$OPENSEARCH_REST_API/_analyze?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"tokenizer": "standard",
"filter": ["lowercase"],
"char_filter": ["html_strip"],
"text": "<b>Hello</b> world!"
}
'
{
"tokens" : [
{
"token" : "hello",
"start_offset" : 3,
"end_offset" : 12,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "world",
"start_offset" : 13,
"end_offset" : 18,
"type" : "<ALPHANUM>",
"position" : 1
}
]
}모든 text 타입 필드는 인덱싱 또는 검색할 때 standard 분석기를 기본으로 사용한다. 다른 분석기를 사용하고 싶다면 인덱스 매핑을 추가할 때 analyzer를 지정해주면 된다. 다음 명령어로 book 인덱스에서 description 필드는 whitespace 분석기를 사용하도록 설정해보자.
$ curl -XPUT "$OPENSEARCH_REST_API/book" \
-H "Content-Type: application/json" \
-d '
{
"mappings": {
"properties": {
"description": {
"type": "text",
"analyzer": "whitespace"
}
}
}
}
'
{"acknowledged":true,"shards_acknowledged":true,"index":"book"}analyze API 경로에 인덱스 이름을 추가하고(GET /:index/_analyze), 요청 본문에 필드 이름을 추가하면 analyze API는 해당 필드의 분석기 사용하여 텍스트를 분석한다. 다음 명령어로 book 인덱스의 description 필드에 분석기가 잘 설정됐는지 확인할 수 있다. standard 분석기가 사용됐다면 "test!"가 "test"로 변환됐을텐데 whitespace 분석기를 사용했기 때문에 느낌표가 제거되지 않았다.
$ curl -XGET "$OPENSEARCH_REST_API/book/_analyze?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"field" : "description",
"text" : "OpenSearch analyze test!"
}
'
{
"tokens" : [
{
"token" : "OpenSearch",
"start_offset" : 0,
"end_offset" : 10,
"type" : "word",
"position" : 0
},
{
"token" : "analyze",
"start_offset" : 11,
"end_offset" : 18,
"type" : "word",
"position" : 1
},
{
"token" : "test!",
"start_offset" : 19,
"end_offset" : 24,
"type" : "word",
"position" : 2
}
]
}만약 인덱스에 해당 필드 매핑이 없다면 standard 분석기를 사용하게 된다.
$ curl -XGET "$OPENSEARCH_REST_API/book/_analyze?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"field" : "unknown",
"text" : "OpenSearch analyze test!"
}
'
{
"tokens" : [
{
"token" : "opensearch",
"start_offset" : 0,
"end_offset" : 10,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "analyze",
"start_offset" : 11,
"end_offset" : 18,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "test",
"start_offset" : 19,
"end_offset" : 23,
"type" : "<ALPHANUM>",
"position" : 2
}
]
}
인덱스의 모든 text 타입 필드에 기본 분석기를 설정할 수 있다. 다음 명령어로 인덱스에 기본 분석기를 설정해보자.
$ curl -XPUT "$OPENSEARCH_REST_API/music" \
-H "Content-Type: application/json" \
-d '
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": "whitespace"
}
}
}
}
}
'
{"acknowledged":true,"shards_acknowledged":true,"index":"music"}GET /:index/_analyze API에서 필드를 지정하지 않으면 인덱스의 기본 분석기를 사용해서 텍스트를 분석한다. 다음 명령어로 music 인덱스에 기본 분석기가 잘 설정됐는지 확인해보자.
$ curl -XGET "$OPENSEARCH_REST_API/music/_analyze?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"text" : "OpenSearch analyze test!"
}
'
{
"tokens" : [
{
"token" : "OpenSearch",
"start_offset" : 0,
"end_offset" : 10,
"type" : "word",
"position" : 0
},
{
"token" : "analyze",
"start_offset" : 11,
"end_offset" : 18,
"type" : "word",
"position" : 1
},
{
"token" : "test!",
"start_offset" : 19,
"end_offset" : 24,
"type" : "word",
"position" : 2
}
]
}2.2 OpenSearch의 역인덱스(Inverted index)
텍스트를 분석하고 토크나이징 한 게 결국 inverted index를 위한 것.
2.1에서 text 타입 필드는 분석기를 사용하여 인덱싱한다는 것을 알았다. 앞서 인덱싱은 검색 효율을 높이기 위해 데이터를 구조화하는 방법이라고 배웠다. 그렇다면 텍스트를 분석하고 토크나이징하는 것이 어떻게 검색 효율을 높일 수 있다는 것일까? 답은 분석한 데이터를 저장하는 구조에 달렸다.
2.2.1 역인덱스와 전문 검색(Full text search)
텍스트 분석기로 분석된 데이터는 최종적으로 역인덱스에 구조화되어 저장된다. 역인덱스의 목적은 텍스트를 효율적이고 빠른 전문 검색이 (빠르게)가능한 구조로 만들어 저장하는 것이다.
전문 검색이란 특정 단어가 포함된 문서를 찾아내는 검색 방식이다. 예를 들어 관계형 데이터베이스에서 특정 단어가 포함된 레코드를 찾는 상황을 떠올려보자. LIKE 또는 정규표현식을 사용해볼 수 있겠지만, LIKE와 정규표현식은 인덱스를 사용하지 않고 테이블 풀 스캔을 하기 때문에 속도가 느리다는 단점이 있다. 전문 검색에서도 인덱스를 사용하여 검색 속도를 높일 수 있도록 고안된 것이 역인덱스 데이터 구조다.
OpenSearch가 전문 검색을 지원하는 것은 text 타입 필드에 대해 검색을 수행할 때 인덱싱에 사용된 JSON 문서가 아닌, 토큰화된 역인덱스 데이터에 대해 쿼리를 하기 때문에 가능하다.
"i am a boy", "she is a girl", "jun is a boy"
RDB에서 텍스트 검색을 위해 LIKE '%boy%'와 같은 쿼리를 사용하면, 문자열의 중간이나 뒷부분에 검색어가 위치하기 때문에 일반적인 B-Tree 인덱스를 사용할 수 없다. 이 경우 인덱스는 검색에 활용되지 못하고, 결국 전체 테이블을 디스크에서 조회하는 Full Table Scan이 발생하게 된다.
데이터가 많아질 경우 디스크 I/O가 급격히 증가하고, 메모리 사용량도 순간적으로 커지기 때문에 성능 저하가 발생한다.
반면, Inverted Index는 각 단어를 키로 삼아 해당 단어가 포함된 문서나 레코드의 목록을 인덱스로 구성하기 때문에,'boy'라는 단어가 들어간 행을 찾을 때 해당 단어와 연결된 문서 ID만 바로 추출해 올 수 있다.
이 방식은 전체 데이터를 스캔할 필요 없이 메모리 상에서 빠르게 원하는 결과를 조회할 수 있게 해주며, 텍스트 검색 성능을 비약적으로 향상시킨다.
이러한 이유로, 비정형 텍스트 데이터에서 특정 단어를 빠르게 찾고자 할 경우에는 RDB보다는 Inverted Index 기반의 검색 시스템을 사용하는 것이 더 효율적이다.
2.2.2 OpenSearch의 역인덱스 구조
역인덱스는 도큐먼트의 필드 수준에서 작동하기 때문에 text 타입 필드 하나 당 inverted index가 한 개씩 생성된다. 인덱스에 5개의 text 타입 필드가 있다면, 해당 인덱스는 총 5개의 역인덱스를 갖고 있는 것이다.
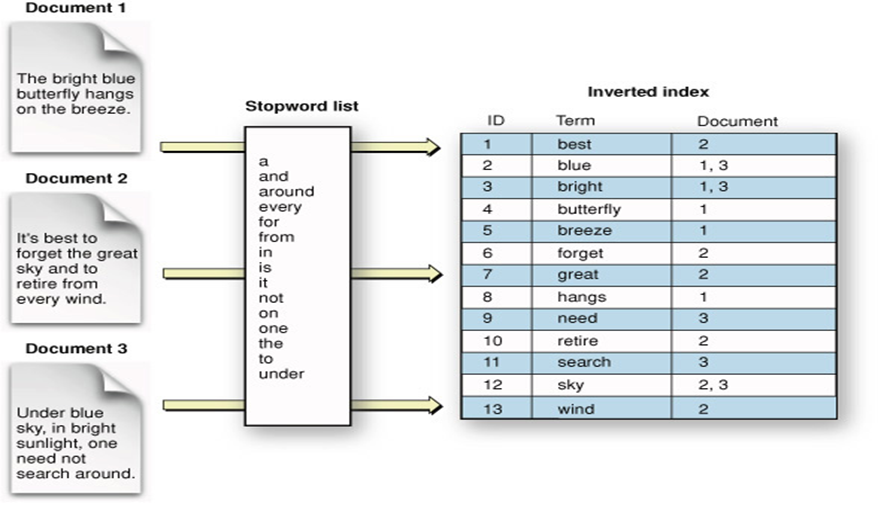
출처: https://stackoverflow.com/questions/47003336/elasticsearch-index-sharding-explanation
위의 그림은 도큐먼트가 분석기를 거쳐 역인덱스로 구조화되는 과정을 보여준다. 분석기에서 캐릭터 필터와 토크나이저, 토큰 필터를 거쳐 최종적으로 추출된 단어들은 용어(Term)라고 불린다. 역인덱스는 고유한 용어들에 대해 용어가 등장하는 도큐먼트의 정보를 저장한다. 기본적으로 역인덱스는 용어와 해당 용어가 포함된 도큐먼트 간의 매핑이라고 볼 수 있다.
위의 그림은 역인덱스에 대한 이해를 돕기 위해 실제보다 단순화한 것이다. 실제 역인덱스에는 용어를 포함하는 도큐먼트 수, 필드의 평균 길이 등 다양한 메타데이터가 함께 저장되기 때문에 인덱싱 과정 및 데이터 구조가 훨씬 복잡하다. OpenSearch는 인덱싱과 검색에 Lucene을 사용하고 있으므로, 인덱싱에 대해 더 알고 싶다면 Lucene의 공식 문서를 참고하면 된다. (https://lucene.apache.org/core/3_0_3/fileformats.html)
정리하면 OpenSearch의 text 타입 필드는 분석기가 적용되고, 분석 결과는 역인덱스에 저장된다. OpenSearch에서 검색 쿼리를 수행하면, 실제로 도큐먼트 자체를 검색하는 것이 아니라 역인덱스에 대해 검색을 수행하는 것이다. 텍스트 인덱싱 과정에 대해 이해하지 못하면 이후 쿼리를 수행할 때 원하는 결과를 얻지 못할 수 있으므로 잘 짚고 넘어가자.
2.2.3 OpenSearch의 쿼리
OpenSearch는 데이터를 검색할 때 용어 수준 쿼리(Term-level query)와 전문 쿼리(Full-text query)라는 두 가지 유형의 쿼리를 지원한다.
전문 쿼리는 전문 검색을 하기 위해 사용되며, 검색어와 도큐먼트가 일치하는 정도에 따라 관련성 점수를 계산하고, 결과를 내림차순으로 정렬하여 보여준다. 검색어는 인덱싱 당시 사용된 분석기와 동인한 분석기로 분석되는데, 검색어가 도큐먼트의 필드와 동일한 분석 프로세스를 거친다는 것을 의미한다. 전문 쿼리는 text 타입으로 매핑된 필드에만 수행할 수 있다.
용어 수준 쿼리는 검색어와 정확히 일치하는 용어를 찾기 위해 사용된다. keyword 타입이 아닌 경우에도 용어 수준 쿼리를 수행할 수 있다.
예를 들어 "Hello, world!"를 쿼리해보자. 용어 수준 쿼리를 사용하는 경우 대소문자와 특수 문자까지 정확하게 일치하는 검색어("Hello, world!")로 쿼리해야 한다. 반면, 전문 쿼리를 사용하는 경우 "hello world"로만 검색해도 도큐먼트를 찾을 수 있다.
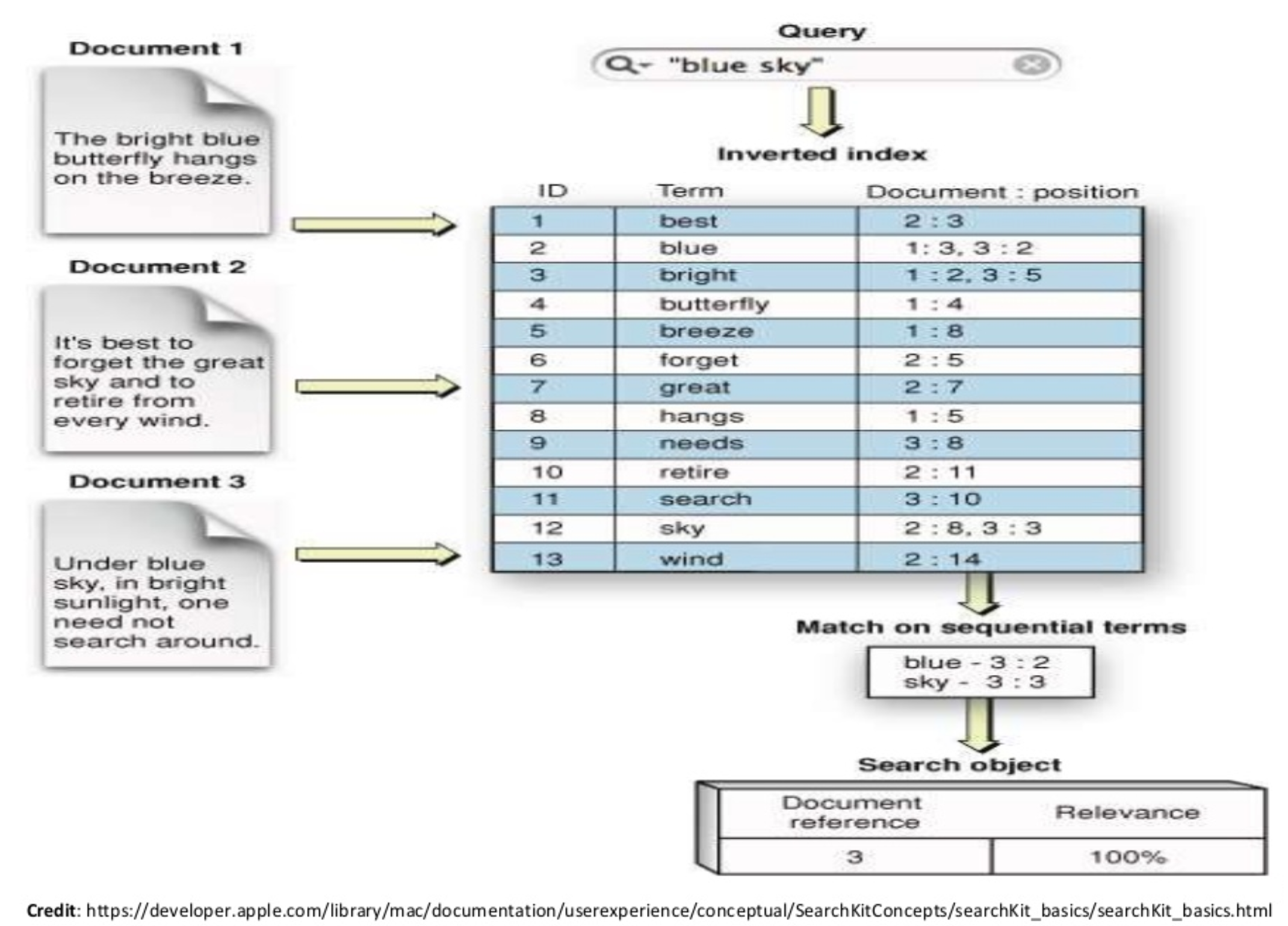
출처: https://www.bogotobogo.com/Hadoop/ELK/ELK_Elastic_Search_Tutorial.php
위의 그림은 전문 쿼리 동작 과정을 보여준다. OpenSearch에서 "blue sky"를 쿼리하면 검색어는 분석기를 거쳐쳐 "blue"와 "sky"로 토큰화된다. 토큰화된 검색어와 토큰화된 도큐먼트 용어들이 매칭되어 관련성 점수를 계산하고, 관련성 점수가 높은 순으로 정렬하여 검색 결과를 반환한다.
2.2.4 OpenSearch 쿼리 실습
다음 명령어로 실습을 위한 인덱스를 생성한다. category 필드는 keyword 타입으로, review 필드는 text 타입으로 매핑한다.
$ curl -XPUT "$OPENSEARCH_REST_API/food?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"mappings": {
"properties": {
"category": {
"type": "keyword"
},
"review": {
"type": "text"
}
}
}
}
'
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "food"
}도큐먼트 벌크 API를 사용하여 도큐먼트를 생성하자.
$ curl -XPOST "$OPENSEARCH_REST_API/_bulk?pretty=true" \
-H "Content-Type: application/json" \
-d '
{ "index" : { "_index" : "food", "_id" : "1" } }
{ "category" : "Fruit", "review": "Fruits are the means by which flowering plants disseminate their seeds." }
{ "index" : { "_index" : "food", "_id" : "2" } }
{ "category" : "Meat", "review": "Meat is animal flesh that is eaten as food." }
{ "index" : { "_index" : "food", "_id" : "3" } }
{ "category" : "Vegetable", "review": "Vegetables are parts of plants that are consumed by humans or other animals as food." }
{ "index" : { "_index" : "food", "_id" : "4" } }
{ "category" : "Bread", "review": "Bread is a staple food prepared from a dough of flour and water, usually by baking." }
{ "index" : { "_index" : "food", "_id" : "5" } }
{ "category" : "Fish", "review": "Fish are aquatic, craniate, gill-bearing animals that lack limbs with digits." }
'
{
"took" : 40,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "food",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "food",
"_id" : "2",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "food",
"_id" : "3",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "food",
"_id" : "4",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "food",
"_id" : "5",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 1,
"status" : 201
}
}
]
}text 타입인 review 필드에 대해 전문 쿼리를 해보자. "flour, water"라는 일부 단어만으로 해당 단어가 포함되는 도큐먼트를 찾아냈다.
$ curl -XGET "$OPENSEARCH_REST_API/food/_search?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"query": {
"match": {
"review": "flour, water"
}
}
}
'
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 2.496951,
"hits" : [
{
"_index" : "food",
"_id" : "4",
"_score" : 2.496951,
"_source" : {
"category" : "Bread",
"review" : "Bread is a staple food prepared from a dough of flour and water, usually by baking."
}
}
]
}
}전문 쿼리를 사용하면 검색어가 여러 도큐먼트에 포함된 경우 연관성이 높은 순서대로 찾아서 보여준다.
$ curl -XGET "$OPENSEARCH_REST_API/food/_search?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"query": {
"match": {
"review": "are"
}
}
}
'
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 0.70343614,
"hits" : [
{
"_index" : "food",
"_id" : "3",
"_score" : 0.70343614,
"_source" : {
"category" : "Vegetable",
"review" : "Vegetables are parts of plants that are consumed by humans or other animals as food."
}
},
{
"_index" : "food",
"_id" : "1",
"_score" : 0.56853056,
"_source" : {
"category" : "Fruit",
"review" : "Fruits are the means by which flowering plants disseminate their seeds."
}
},
{
"_index" : "food",
"_id" : "5",
"_score" : 0.549705,
"_source" : {
"category" : "Fish",
"review" : "Fish are aquatic, craniate, gill-bearing animals that lack limbs with digits."
}
}
]
}
}keyword 타입인 category 필드에 대해 전문 쿼리를 해보자. keyword 타입에 전문 쿼리를 사용하는 경우에도 검색어는 토큰화되는데, keyword 타입은 매핑할 때 keyword 분석기가 적용되기 때문에 검색어 또한 standard 분석기가 아닌 keyword 분석기를 사용하여 토큰화된다. keyword 분석기는 텍스트 전체를 단일 토큰으로 변환하는 분석기다. 따라서 "Bread"를 쿼리하면 "Bread" 자체로 토큰화되기 때문에 일치하는 도큐먼트를 찾을 수 있는 것이다.
$ curl -XGET "$OPENSEARCH_REST_API/food/_search?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"query": {
"match": {
"category": "Bread"
}
}
}
'
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.3862942,
"hits" : [
{
"_index" : "food",
"_id" : "4",
"_score" : 1.3862942,
"_source" : {
"category" : "Bread",
"review" : "Bread is a staple food prepared from a dough of flour and water, usually by baking."
}
}
]
}
}위의 예제에서 검색어 분석기에 standard 분석기를 적용해보자. 이 경우 검색어 토큰화에만 standard 분석기가 적용되기 때문에 "Bread"는 "bread"로 토큰화되는 반면, 인덱싱된 텍스트는 여전히 "Bread"이기 때문에 일치하는 문서를 찾을 수 없다.
$ curl -XGET "$OPENSEARCH_REST_API/food/_search?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"query": {
"match": {
"category": {
"query": "Bread",
"analyzer": "standard"
}
}
}
}
'
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}keyword 타입인 category 필드에 대해 용어 수준 쿼리를 해보자.
$ curl -XGET "$OPENSEARCH_REST_API/food/_search?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"query": {
"term": {
"category": "Bread"
}
}
}
'
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.3862942,
"hits" : [
{
"_index" : "food",
"_id" : "4",
"_score" : 1.3862942,
"_source" : {
"category" : "Bread",
"review" : "Bread is a staple food prepared from a dough of flour and water, usually by baking."
}
}
]
}
}용어 수준 쿼리는 띄어쓰기 하나까지 정확하게 일치해야 한다.
$ curl -XGET "$OPENSEARCH_REST_API/food/_search?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"query": {
"term": {
"category": " Bread "
}
}
}
'
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}text 타입인 review 필드에 대해 용어 수준 쿼리를 해보자. 다음 명령어로 용어 수준 쿼리를 하면서 Bread 도큐먼트를 찾아오지 않을까 기대한 사람도 있을 것이다. 용어 수준 쿼리는 검색어를 토큰화하지 않고 검색어 그대로를 역인덱스에서 찾는다. ["bread", "is", "a", …]와 같이 토큰화된 역인덱스에서 "Bread is a staple food prepared from a dough of flour and water, usually by baking." 텍스트 전체와 일치하는 용어가 있는지 찾기 때문에 Bread 도큐먼트를 찾을 수 없는 것이다.
$ curl -XGET "$OPENSEARCH_REST_API/food/_search?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"query": {
"term": {
"review": "Bread is a staple food prepared from a dough of flour and water, usually by baking."
}
}
}
'
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}text 타입인 review 필드에 대해 용어 수준 쿼리를 하면서 Bread 도큐먼트를 찾아오고 싶다면, 직접 검색어를 토큰화해야 한다. 예를 들어 "Bread"는 standard 분석기 기준으로 "bread"로 토큰화되므로, "bread"로 찾으면 Bread 도큐먼트를 찾을 수 있다.
$ curl -XGET "$OPENSEARCH_REST_API/food/_search?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"query": {
"term": {
"review": "bread"
}
}
}
'
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.2484756,
"hits" : [
{
"_index" : "food",
"_id" : "4",
"_score" : 1.2484756,
"_source" : {
"category" : "Bread",
"review" : "Bread is a staple food prepared from a dough of flour and water, usually by baking."
}
}
]
}
}그러나 첫 글자만 대문자로 바꿔서 "Bread"로 찾을 경우 도큐먼트를 찾지 못한다. 이미 역인덱스에는 "Bread"가 소문자로 토큰화되어 저장됐기 때문이다.
