1 OpenSearch 구성 요소와 동작 방식
1.1 OpenSearch 실습 환경 준비
1.1.1 OpenSearch 설치
터미널에서 다음 명령어를 실행한다.
cd /home/ubuntu \
&& sudo apt update \
&& sudo apt install build-essential -y \
&& wget https://artifacts.opensearch.org/releases/bundle/opensearch/2.4.0/opensearch-2.4.0-linux-x64.tar.gz \
&& tar -xvf opensearch-2.4.0-linux-x64.tar.gz \
&& echo 'export OPENSEARCH_HOME=/home/ubuntu/opensearch-2.4.0' >> ~/.bashrc \
&& source ~/.bashrc설치에 성공한 경우 을 실행하면 다음과 같이 버전 정보를 확인할 수 있다.
$OPENSEARCH_HOME/bin/opensearch —version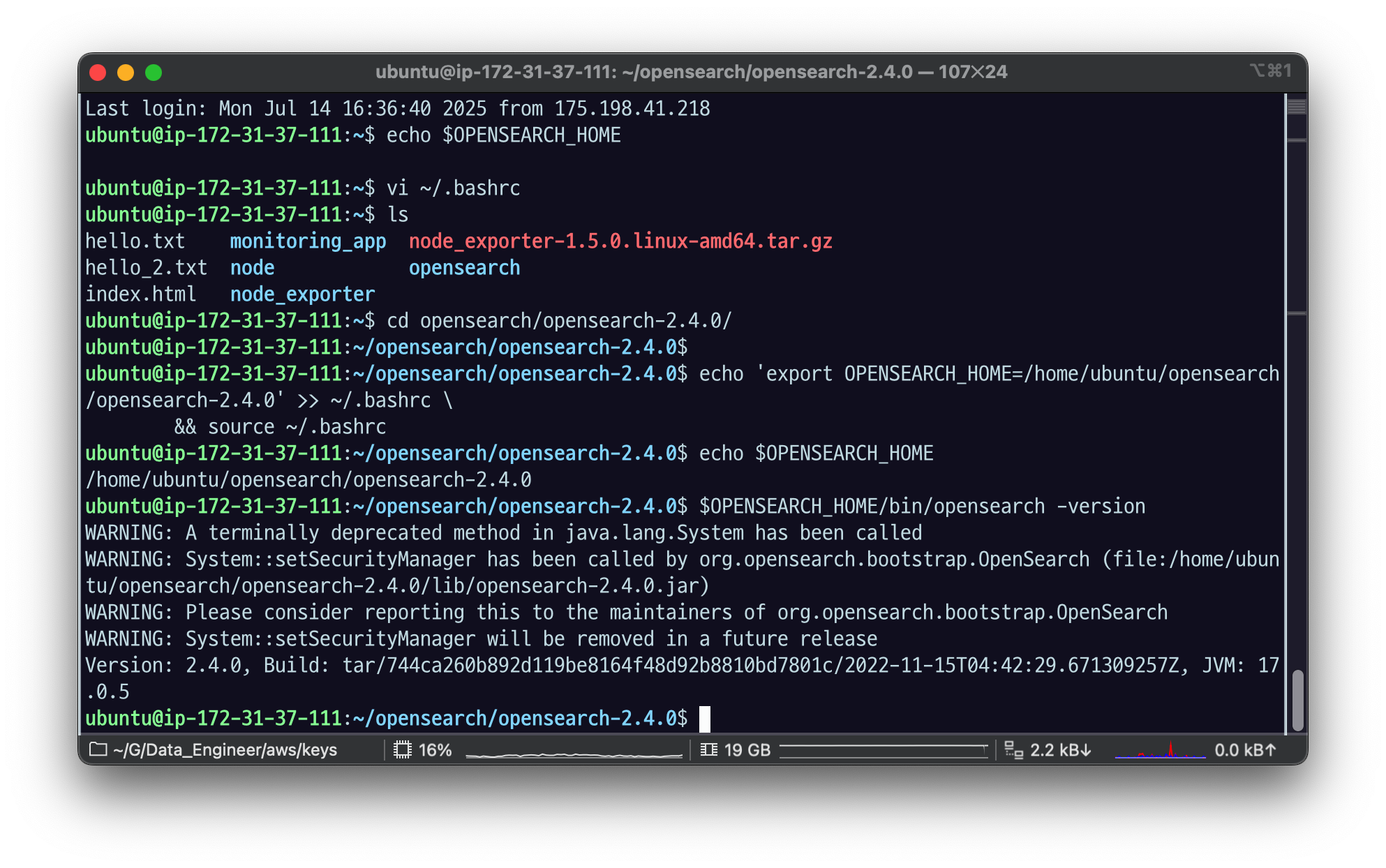
Version: 2.4.0, Build: tar/744ca260b892d119be8164f48d92b8810bd7801c/2022-11-15T04:42:29.671309257Z, JVM: 17.0.5warning message
- System.setSecurityManager()는 Java 17에서 더 이상 권장되지 않는(deprecated) 메서드입니다.
- OpenSearch 2.4.0 내부 코드에서 여전히 이 메서드를 사용하고 있어서, Java 18 이상에서는 동작하지 않거나 에러가 발생할 가능성이 있습니다.
이 챕터에서의 실습은 single-node만으로 충분하다.
세부 설정은 <EFK로 서버 로그 수집하기>의 4.1.3~4.1.7을 참고하자.
1.1.2 OpenSearch 실행
<EFK로 서버 로그 수집하기>의 4.1.8~4.1.9를 참고하자.
다음 명령어를 사용하면 working directory 경로와 상관 없이 OpenSearch를 실행할 수 있다.
$OPENSEARCH_HOME/bin/opensearch1.1.3 환경 변수 설정
OpenSearch REST API Url을 환경 변수로 export 한다.
- 이후 실습에서 endpoint를
$OPENSEARCH_REST_API로 지정해서 사용한다.
export OPENSEARCH_REST_API=http://1.2.3.4:9200OpenSearch의 모든 기능이 REST API 형태기 때문에 REST 클라이언트 툴이 필요하다. 본 강의에서는 curl을 사용하여 OpenSearch 노드에 요청을 보낼 예정이다.
1.2 OpenSearch의 구성 요소
OpenSearch를 구성하는 개념은 다음과 같다.
- 클러스터 : 여러 개의 기능으로 구성되어 있는 하나의 기능을 하는 오픈 서치의 클러스터.
- 노드 : 그 중 하나하나의 서버를 노드라고 함
- 샤드 : 거기에 위치해있는 데이터를 샤드라고 함
- 인덱스 : 테이블과 같은 어떤 형식이 있는 대상 집합의 데디터의 묶음
- 도큐먼트 : 개별 레코드
- 필드 : 도큐먼트 안에 특정 필드가 존재한다
- 매핑 : 도큐먼트 형식 맵핑
- 분석기
당장 모든 개념을 이해할 필요는 없다. 먼저 인덱스, 도큐먼트, 필드, 매핑부터 알아보자.
1.2.1 OpenSearch와 관계형 데이터베이스 비교
OpenSearch는 데이터를 저장하고, 인덱싱하고, 쿼리 기반으로 데이터를 찾는다는 점에서 데이터베이스와 유사점이 많다. 그래서 본격적으로 OpenSearch의 구성 요소를 설명하기 전에 관계형 데이터베이스와 비교해보면서 이해를 돕고자 한다.
| OpenSearch | 관계형 데이터베이스 |
|---|---|
| 인덱스 | 테이블 |
| 도큐먼트 | 행(레코드) |
| 필드 | 열(컬럼) |
| 매핑 | 스키마 |
1.2.2 인덱스
OpenSearch에서 데이터를 검색하려면 먼저 데이터를 인덱싱해야 한다. 인덱싱이란 검색 엔진에서 빠른 검색을 위해 데이터를 구조화하는 방법을 의미한다. OpenSearch에서는 인덱싱 결과로 생성된 구조를 인덱스라고 부른다.
OpenSearch에서 인덱스는 쉽게 말해 도큐먼트가 저장되는 공간이며, 논리적인 구분 단위다. 종합하면 OpenSearch에서 인덱싱이란 도큐먼트를 검색에 최적화된 데이터 형태로 변환해서 인덱스라는 공간에 저장한다는 뜻이다.
인덱스는 1.2.1의 표처럼 관계형 데이터베이스의 테이블과 유사한 개념으로 볼 수 있다.
인덱스 이름은 다음과 같은 제한이 따른다.
- 모든 문자는 소문자여야 한다.
- 밑줄(
_) 또는 하이픈(-)으로 시작할 수 없다. - 공백,
,,:,",*,+,/,\,|,?,#,>,<은 포함될 수 없다.
1.2.3 매핑
도큐먼트를 인덱싱하려면 매핑을 거쳐야 한다. 매핑은 도큐먼트의 필드와 필드의 데이터 타입을 정의하고, 이 매핑 정의에 따라 도큐먼트를 OpenSearch가 이해할 수 있는 데이터 구조로 변환하는 과정이다. 데이터 타입별로 인덱싱하는 방법이 다르기 때문에 인덱싱 및 검색 성능을 높이려면 매핑을 잘 활용해야 한다.
- 오픈서치가 자바로 만들어져 있는데 자바는 정적 타입 언어기 때문에 타입을 모르면 정렬을 할 수 없다 그래서 매핑이 있어야 한다)
매핑은 1.2.1의 표처럼 관계형 데이터베이스의 스키마와 유사한 개념이다. 인덱스 당 하나의 매핑 정의만 가질 수 있기 때문에 동일한 인덱스에 저장된 도큐먼트는 모두 동일한 방식으로 매핑된다. 관계형 데이터베이스에서 동일한 테이블에 저장된 데이터는 모두 동일한 스키마를 따르는 것과 비슷하다.
- 관계형 데이터베이스랑 조금 다른 건 이 친구는 필드가 기본적으로 nullable 이다.
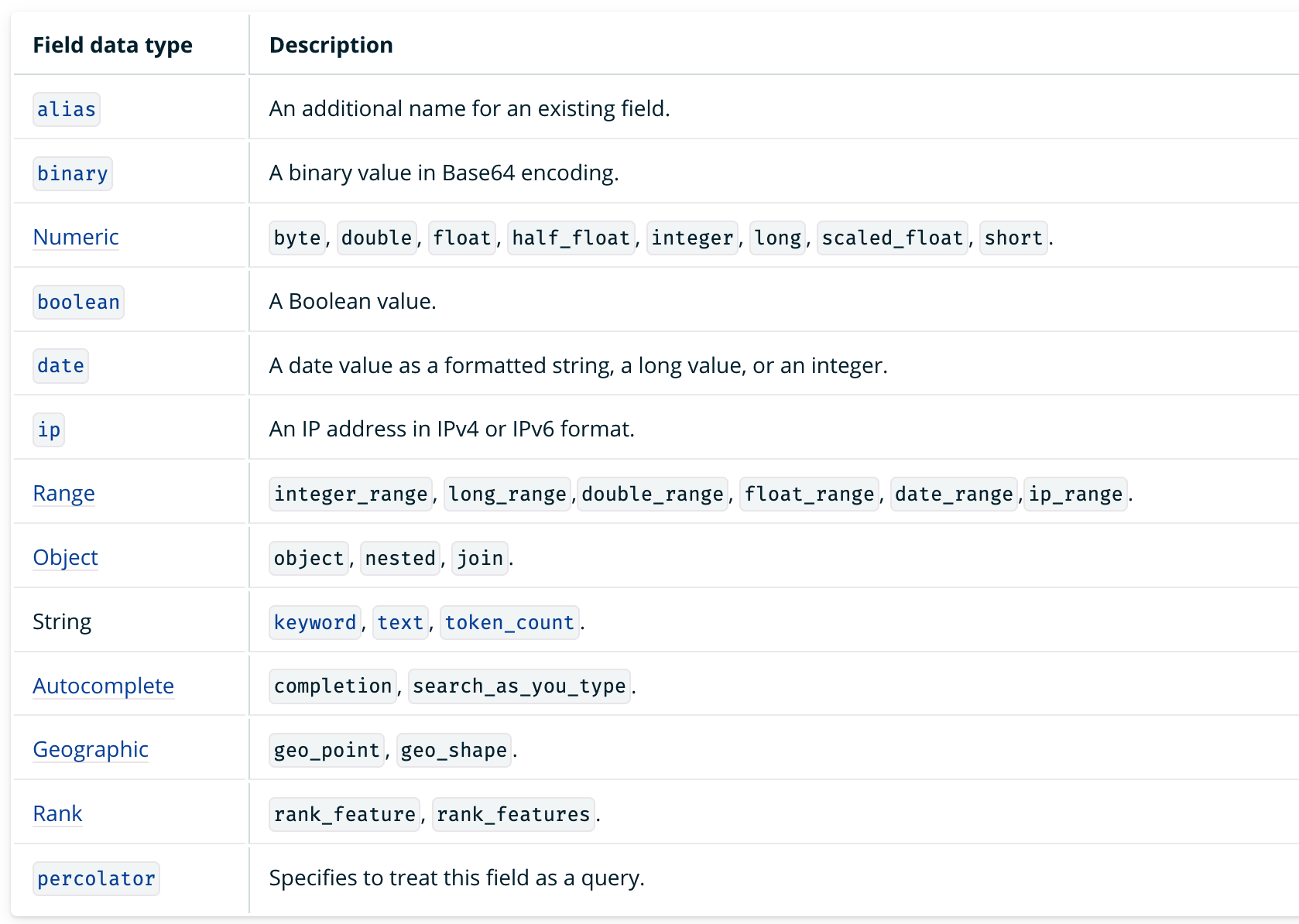
OpenSearch가 지원하는 데이터 타입은 공식 문서에서 확인할 수 있다.(https://opensearch.org/docs/2.3/opensearch/supported-field-types/index/)
1.2.4 명시적 매핑과 다이나믹 매핑
매핑 정의는 다음 두 가지 방법으로 가능하다.
명시적 매핑은 필드의 데이터 타입을 직접 정의하는 것이다. 처음부터 매핑이 정의된 인덱스를 생성하는 방법도 있고, 인덱스 생성 후 매핑 API를 활용하여 별도로 매핑을 정의하는 방법도 있다.
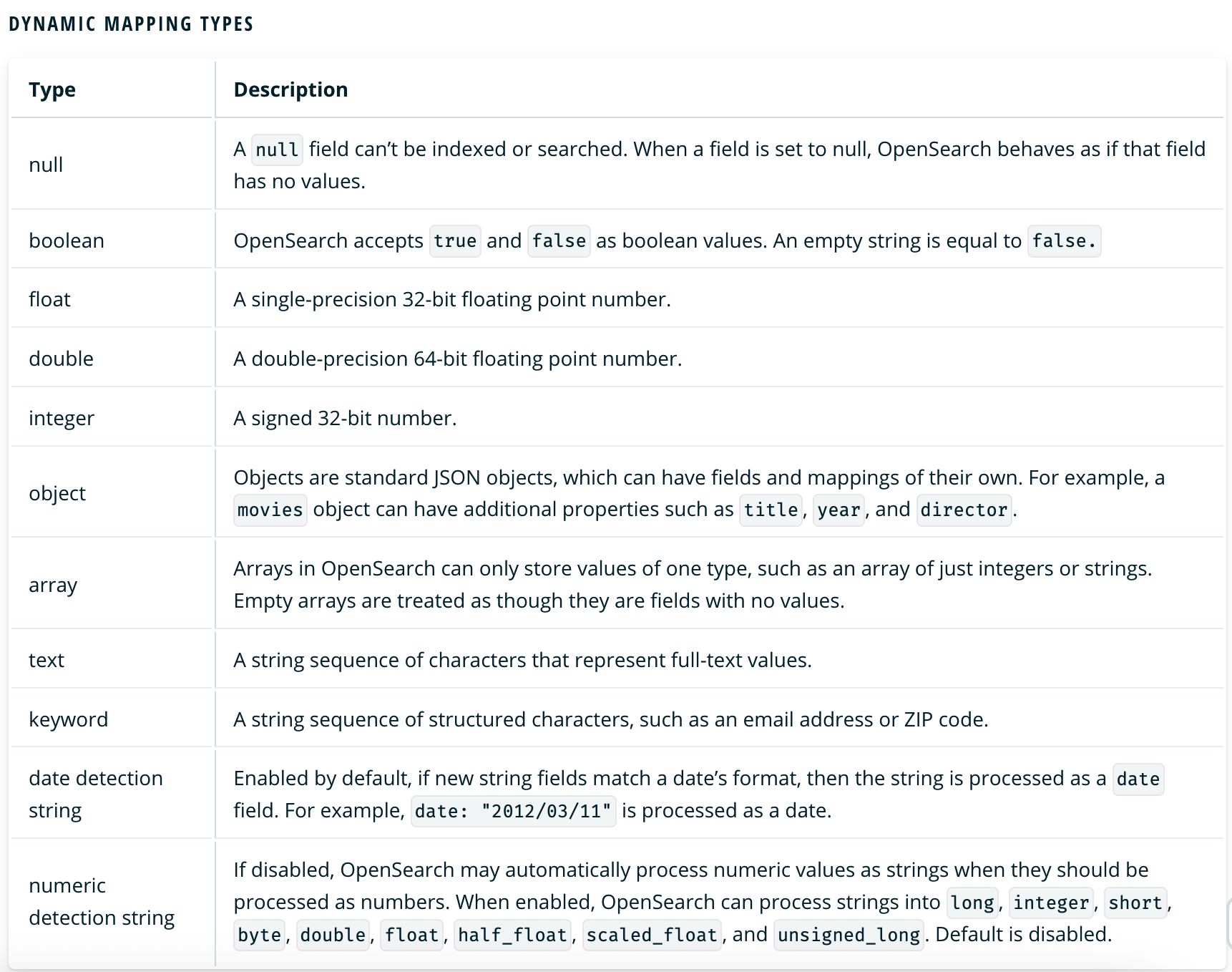
다이나믹 매핑은 OpenSearch가 자동으로 필드의 데이터 타입을 정의해주는 것이다. 매핑 정의가 없는 인덱스에 도큐먼트를 생성하려고 하면 OpenSearch는 도큐먼트의 원본 데이터에 맞춰 적절한 타입으로 매핑해준다.
예를 들어 원본 데이터 타입이 integer인 경우 다이나믹 매핑은 이 필드의 데이터 타입을 long으로 매핑한다.
다이나믹 매핑의 경우 OpenSearch가 지원하는 데이터 타입 중 일부 타입만 지원하고 있다. 예를 들어 명시적 매핑을 사용하면 필드 타입을 ip 타입으로 지정할 수 있지만, 다이나믹 매핑은 ip 타입을 지원하지 않기 때문에 “127.0.0.1”을 text 타입으로 매핑한다. 다이나믹 매핑에서 지원하는 데이터 타입은 공식 문서에서 확인할 수 있다.(https://opensearch.org/docs/2.3/opensearch/mappings/#dynamic-mapping)
1.2.5 도큐먼트와 필드
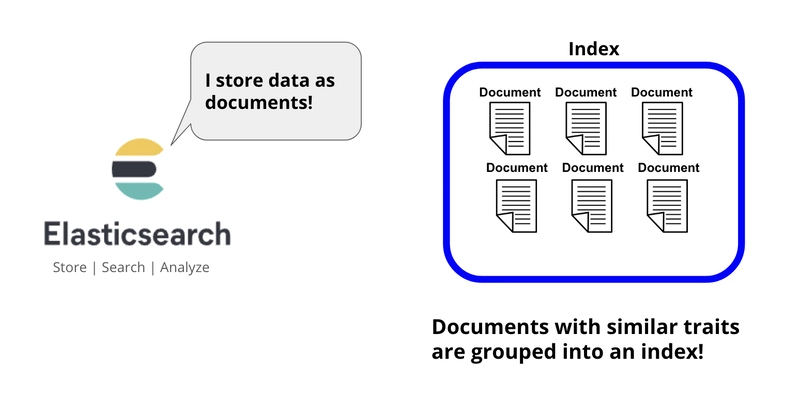
도큐먼트는 인덱스에 저장되는 문서 단위(하나의 데이터셋, 레코드)로, 1.2.1의 표처럼 관계형 데이터베이스의 레코드와 유사한 개념이다. 도큐먼트는 JSON 형식이며, 인덱스 내에서 고유 ID를 사용하여 식별된다.
하나의 도큐먼트는 여러 필드와 값을 가질 수 있으며, 필드는 1.2.1의 표처럼 관계형 데이터베이스의 컬럼과 유사한 개념이다.
1.3 OpenSearch CRUD
OpenSearch REST API를 사용하여 인덱스, 매핑, 도큐먼트를 직접 생성하고 삭제해보자.
JSON 응답을 읽기 쉽도록 특정 예제에서 ?pretty=true 쿼리를 사용했다. 그 외에도 OpenSearch에서는 모든 REST API 작업에서 사용할 수 있는 공통 쿼리를 지원하고 있다. (https://opensearch.org/docs/1.1/opensearch/common-parameters/)
1.3.1 인덱스 생성: PUT /:index
다음 명령어로 movie 인덱스를 생성할 수 있다.
curl -XPUT $OPENSEARCH_REST_API/movie
{"acknowledged":true,"shards_acknowledged":true,"index":"movie"}1.3.2 인덱스 확인: HEAD /:index
다음 명령어로 movie 인덱스 존재 여부를 확인할 수 있다.
curl --head $OPENSEARCH_REST_API/movie
HTTP/1.1 200 OK
content-type: application/json; charset=UTF-8
content-length: 231인덱스 확인 API는 200 또는 404만 반환하는데, 200일 경우 인덱스가 존재함을, 404일 경우 인덱스가 존재하지 않음을 의미한다.
1.3.3 인덱스 조회: GET /:index
다음 명령어로 movie 인덱스 정보를 조회할 수 있다. movie 인덱스 설정이나 매핑을 확인할 수 있다. 아직 매핑 설정을 하지 않았기 때문에 mappings 필드값이 빈 객체임을 확인할 수 있다.
curl -XGET "$OPENSEARCH_REST_API/movie?pretty=true"
{
"movie": {
"aliases": {},
"mappings": {},
"settings": {
"index": {
"creation_date": "1671238681112",
"number_of_shards": "1",
"number_of_replicas": "1",
"uuid": "4aBMDFDIROOxrvDdcho1Hw",
"version": {
"created": "136257827"
},
"provided_name": "movie"
}
}
}
}1.3.4 명시적 매핑: PUT /:index/_mapping
다음 명령어로 movie 인덱스에 매핑을 생성할 수 있다. movie 인덱스에 저장할 도큐먼트의 title 필드 타입을 text로 설정해보자.
$ curl -XPUT $OPENSEARCH_REST_API/movie/_mapping \
-H "Content-Type: application/json" \
-d '
{
"properties": {
"title": {
"type": "text"
}
}
}
'
{"acknowledged":true}GET /:index를 호출해보면 mappings 필드에 값이 잘 들어간 것을 확인할 수 있다.
curl -XGET "$OPENSEARCH_REST_API/movie?pretty=true"
{
"movie": {
"aliases": {},
"mappings": {
"properties": {
"title": {
"type": "text"
}
}
},
"settings": {
"index": {
"creation_date": "1671238681112",
"number_of_shards": "1",
"number_of_replicas": "1",
"uuid": "4aBMDFDIROOxrvDdcho1Hw",
"version": {
"created": "136257827"
},
"provided_name": "movie"
}
}
}
}매핑에 새로운 필드를 추가하는 것은 자유롭다. 다음 명령어로 movie 인덱스에 genre 필드를 추가해보자. 필드 타입은 keyword로 설정한다.
curl -XPUT $OPENSEARCH_REST_API/movie/_mapping \
-H "Content-Type: application/json" \
-d '
{
"properties": {
"genre": {
"type": "keyword"
}
}
}
'
{"acknowledged":true}GET /:index를 호출해보면 mappings 값에 genre 필드가 추가된 것을 확인할 수 있다.
curl -XGET "$OPENSEARCH_REST_API/movie?pretty=true"
{
"movie": {
"aliases": {},
"mappings": {
"properties": {
"genre": {
"type": "keyword"
},
"title": {
"type": "text"
}
}
},
"settings": {
"index": {
"creation_date": "1671238681112",
"number_of_shards": "1",
"number_of_replicas": "1",
"uuid": "4aBMDFDIROOxrvDdcho1Hw",
"version": {
"created": "136257827"
},
"provided_name": "movie"
}
}
}
}genre 필드 타입을 text로 변경하기 위해 다음 명령어를 실행하면 400 에러가 발생한다. 이미 매핑된 필드를 수정하거나 삭제할 수 없기 때문이다. 필드 이름이나 데이터 타입을 변경하고 싶다면 새로운 인덱스를 만들거나 reindex API를 사용해야 한다. reindex API는 다른 챕터에서 설명할 예정이다.
curl -XPUT "$OPENSEARCH_REST_API/movie/_mapping?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"properties": {
"genre": {
"type": "text"
}
}
}
'
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "mapper [genre] cannot be changed from type [keyword] to [text]"
}
],
"type": "illegal_argument_exception",
"reason": "mapper [genre] cannot be changed from type [keyword] to [text]"
},
"status": 400
}1.3.5 도큐먼트 생성과 다이나믹 매핑: POST /:index/_doc
다음 명령어로 도큐먼트를 movie 인덱스에 저장해보자. (1.3.4에서 명시적으로 매핑한 필드 사용) POST를 사용하여 인덱싱할 경우 OpenSearch가 도큐먼트의 ID를 자동으로 생성해주며, 응답 본문의 _id 필드를 통해 생성된 ID 값을 알 수 있다.
curl -XPOST "$OPENSEARCH_REST_API/movie/_doc?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"title": "Love Actually",
"genre": "Drama"
}
'
{
"_index": "movie",
"_id": "UmWZHYUBtcIfY_yDBLc2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}도큐먼트에 title 필드 값만 있어도 인덱싱할 수 있다. 즉, 매핑한 모든 필드를 사용할 필요는 없다.
curl -XPOST "$OPENSEARCH_REST_API/movie/_doc?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"title": "Interstellar"
}
'
{
"_index": "movie",
"_id": "VWWnHYUBtcIfY_yD0bdt",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1
}1.3.4에서 명시적으로 매핑한 필드(title과 genre) 외의 다른 필드를 사용해서 도큐먼트를 생성할 수 있다. 이것이 바로 다이나믹 매핑이다. 다음 명령어로 도큐먼트를 생성해보자.
$ curl -XPOST "$OPENSEARCH_REST_API/movie/_doc?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"title": "Top Gun: Maverick",
"rate": 8.4,
"director": "Joseph Kosinski"
}
'
{
"_index": "movie",
"_id": "U2WZHYUBtcIfY_yDN7fc",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}GET /:index를 호출해보면 mappings에 rate와 director 필드가 추가된 것을 확인할 수 있다.
curl -XGET "$OPENSEARCH_REST_API/movie?pretty=true"
{
"movie": {
"aliases": {},
"mappings": {
"properties": {
"director": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"genre": {
"type": "keyword"
},
"title": {
"type": "text"
},
"rate": {
"type": "float"
}
}
},
"settings": {
"index": {
"creation_date": "1671238681112",
"number_of_shards": "1",
"number_of_replicas": "1",
"uuid": "4aBMDFDIROOxrvDdcho1Hw",
"version": {
"created": "136257827"
},
"provided_name": "movie"
}
}
}
}다이나믹 매핑을 사용하면 OpenSearch가 도큐먼트의 필드 값을 보고 데이터 타입을 자동으로 추론해주는데, string 필드의 경우 다이나믹 매핑을 사용하면 text와 keyword 타입이 모두 지원되는 멀티 필드로 구성된다.
멀티 필드는 동일한 필드를 여러 방식으로 인덱싱하고 싶을 때 사용하며 fields 파라미터로 생성할 수 있다. 위의 응답 본문에서
{
"director": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}는 director 필드를 text 타입으로 매핑하고, keyword라는 서브 필드를 만들어 keyword 타입으로 매핑하겠다는 뜻이다. 이렇게 멀티 필드로 구성할 경우 OpenSearch는 director 필드의 동일한 값을 text 타입으로 한 번, keyword 타입으로 한 번, 총 두 번 인덱싱한다.
데이터 타입을 잘못 입력한 도큐먼트를 인덱싱하려고 하면 OpenSearch는 자동으로 데이터 타입을 변환해준다. 예를 들어 float 타입으로 매핑된 rate 필드에 string 타입 값 “7.9”를 넣으려고 하면 인덱싱 과정에서 강제로 float 타입으로 변환된다.
curl -XPOST "$OPENSEARCH_REST_API/movie/_doc?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"title": "Titanic",
"rate": "7.9"
}
'
{
"_index": "movie",
"_id": "U2WZHYUBtcIfY_yDN7fc",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}자동 타입 변환이 불가능한 경우도 있다. 이 때는 400 에러가 발생한다.
curl -XPOST "$OPENSEARCH_REST_API/movie/_doc?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"title": "Good Will Hunting",
"rate": "Impressive"
}
'
{
"error": {
"root_cause": [
{
"type": "mapper_parsing_exception",
"reason": "failed to parse field [rate] of type [float] in document with id 'VmWsHYUBtcIfY_yDp7cA'. Preview of field's value: 'Impressive'"
}
],
"type": "mapper_parsing_exception",
"reason": "failed to parse field [rate] of type [float] in document with id 'VmWsHYUBtcIfY_yDp7cA'. Preview of field's value: 'Impressive'",
"caused_by": {
"type": "number_format_exception",
"reason": "For input string: \"Impressive\""
}
},
"status": 400
}1.3.6 도큐먼트 조회: GET /:index/_doc/:id, GET /:index/_search
1.3.5에서 인덱싱한 도큐먼트를 조회해보자.
다음 명령어는 ID로 조회하는 방법이다.
curl -XGET "$OPENSEARCH_REST_API/movie/_doc/UmWZHYUBtcIfY_yDBLc2?pretty=true"
{
"_index" : "movie",
"_id" : "UmWZHYUBtcIfY_yDBLc2",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"title" : "Love Actually",
"genre" : "Drama"
}
}또는 쿼리 DSL를 사용해서 movie 인덱스 내의 모든 도큐먼트를 조회할 수도 있다.
$ curl -XGET "$OPENSEARCH_REST_API/movie/_search?pretty=true"
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "movie",
"_id" : "UmWZHYUBtcIfY_yDBLc2",
"_score" : 1.0,
"_source" : {
"title" : "Love Actually",
"genre" : "Drama"
}
},
{
"_index" : "movie",
"_id" : "U2WZHYUBtcIfY_yDN7fc",
"_score" : 1.0,
"_source" : {
"title" : "Top Gun: Maverick",
"rate" : 8.4,
"director" : "Joseph Kosinski"
}
},
{
"_index" : "movie",
"_id" : "VGWcHYUBtcIfY_yDsrdt",
"_score" : 1.0,
"_source" : {
"title" : "Titanic",
"rate" : "7.9"
}
},
{
"_index" : "movie",
"_id" : "VWWnHYUBtcIfY_yD0bdt",
"_score" : 1.0,
"_source" : {
"title" : "Interstellar"
}
}
]
}
}title이 Titanic인 도큐먼트를 찾고 싶다면 다음과 같이 검색하면 된다.
curl -XGET "$OPENSEARCH_REST_API/movie/_search?q=title:Titanic&pretty=true"
{
"took" : 27,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.4599355,
"hits" : [
{
"_index" : "movie",
"_id" : "VGWcHYUBtcIfY_yDsrdt",
"_score" : 1.4599355,
"_source" : {
"title" : "Titanic",
"rate" : "7.9"
}
}
]
}
}쿼리 DSL에 대해 더 알고 싶다면 공식 문서를 참고하자. (https://opensearch.org/docs/latest/opensearch/query-dsl/index/)
1.3.7 도큐먼트 수정: PUT /:index/_doc/:id, POST /:index/_update/:id
아래 명령어로 1.3.5에서 인덱싱한 도큐먼트를 업데이트할 수 있다.
curl -XPUT "$OPENSEARCH_REST_API/movie/_doc/VGWcHYUBtcIfY_yDsrdt?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"director": "Richard Curtis"
}
'
{
"_index": "movie",
"_id": "VGWcHYUBtcIfY_yDsrdt",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 4,
"_primary_term": 3
}업데이트 후 도큐먼트를 조회해보니 기존에 인덱싱했던 title과 genre 필드가 없어졌다. PUT을 사용하면 동일한 도큐먼트 ID가 존재할 경우 덮어쓰기 작업을 수행하기 때문이다. ID가 존재하지 않는다면 요청된 ID를 사용하여 새로운 도큐먼트를 만들게 된다.
curl -XGET "$OPENSEARCH_REST_API/movie/_doc/VGWcHYUBtcIfY_yDsrdt?pretty=true"
{
"_index" : "movie",
"_id" : "VGWcHYUBtcIfY_yDsrdt",
"_version" : 2,
"_seq_no" : 4,
"_primary_term" : 3,
"found" : true,
"_source" : {
"director" : "Richard Curtis"
}
}덮어쓰기 말고 특정 필드 값만 업데이트하고 싶다면 POST /:index/_update/:id를 사용하면 된다. 아래 명령어로 rate와 genre 필드 값을 업데이트하고, rank 필드를 새롭게 추가해보자.
curl -XPOST "$OPENSEARCH_REST_API/movie/_update/U2WZHYUBtcIfY_yDN7fc?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"doc": {
"rate": 10,
"genre": "Drama",
"rank": 1
}
}
'
{
"_index": "movie",
"_id": "U2WZHYUBtcIfY_yDN7fc",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 5,
"_primary_term": 3
}도큐먼트가 성공적으로 업데이트된 것을 확인할 수 있다.
curl -XGET "$OPENSEARCH_REST_API/movie/_doc/U2WZHYUBtcIfY_yDN7fc?pretty=true"
{
"_index" : "movie",
"_id" : "U2WZHYUBtcIfY_yDN7fc",
"_version" : 2,
"_seq_no" : 5,
"_primary_term" : 3,
"found" : true,
"_source" : {
"title" : "Top Gun: Maverick",
"rate" : 10.0,
"director" : "Joseph Kosinski",
"genre" : "Drama",
"rank" : 1
}
}rank 필드도 인덱스 mappings에 새롭게 추가된 것을 확인할 수 있다. 도큐먼트 업데이트 API로 필드를 추가해도 다이나믹 매핑이 작동한다.
$ curl -XGET "$OPENSEARCH_REST_API/movie/_mappings?pretty=true"
{
"movie" : {
"mappings" : {
"properties" : {
"director" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"genre" : {
"type" : "keyword"
},
"title" : {
"type" : "text"
},
"rank" : {
"type" : "long"
},
"rate" : {
"type" : "float"
}
}
}
}
}1.3.8 도큐먼트 삭제: DELETE /:index/_doc/:id
다음 명령어로 movie 인덱스에 저장된 도큐먼트를 삭제할 수 있다. 삭제한 도큐먼트는 복구할 수 없으므로 주의해야 한다.
curl -XDELETE "$OPENSEARCH_REST_API/movie/_doc/VGWcHYUBtcIfY_yDsrdt?pretty=true"
{
"_index": "movie",
"_id": "VGWcHYUBtcIfY_yDsrdt",
"_version": 3,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 6,
"_primary_term": 3
}1.3.9 인덱스 닫기: POST /:index/_close
다음 명령어로 movie 인덱스를 닫을 수 있다. 사용하지 않는 인덱스가 있다면 힙 메모리, 검색 성능에 영향을 미칠 수 있으므로 오버헤드를 줄이기 위해 임시로 닫아주는 것이 좋다. 닫힌 인덱스는 디스크에는 저장되어 있지만, 힙 메모리에 로드되지 않아 오버헤드를 주지 않고, 읽기, 쓰기, 검색 모두 불가능한 상태가 된다.
curl -XPOST "$OPENSEARCH_REST_API/movie/_close?pretty=true"
{
"acknowledged": true,
"shards_acknowledged": true,
"indices": {
"movie": {
"closed": true
}
}
}인덱스를 닫은 후에 검색 작업을 하려고 하면 400 에러가 발생하는 것을 확인할 수 있다.
$ curl -XGET "$OPENSEARCH_REST_API/movie/_search?pretty=true"
{
"error" : {
"root_cause" : [
{
"type" : "index_closed_exception",
"reason" : "closed",
"index" : "movie",
"index_uuid" : "4aBMDFDIROOxrvDdcho1Hw"
}
],
"type" : "index_closed_exception",
"reason" : "closed",
"index" : "movie",
"index_uuid" : "4aBMDFDIROOxrvDdcho1Hw"
},
"status" : 400
}1.3.10 인덱스 열기: POST /:index/_open
다음 명령어로 닫힌 movie 인덱스를 활성화할 수 있다.
curl -XPOST $OPENSEARCH_REST_API/movie/_open
{"acknowledged":true,"shards_acknowledged":true}검색 작업이 가능하다면 성공적으로 인덱스가 활성화된 것이다.
curl -XGET "$OPENSEARCH_REST_API/movie/_search?pretty=true"
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "movie",
"_id" : "UmWZHYUBtcIfY_yDBLc2",
"_score" : 1.0,
"_source" : {
"title" : "Love Actually",
"genre" : "Drama"
}
},
{
"_index" : "movie",
"_id" : "U2WZHYUBtcIfY_yDN7fc",
"_score" : 1.0,
"_source" : {
"title" : "Top Gun: Maverick",
"rate" : 8.4,
"director" : "Joseph Kosinski"
}
},
{
"_index" : "movie",
"_id" : "VGWcHYUBtcIfY_yDsrdt",
"_score" : 1.0,
"_source" : {
"title" : "Titanic",
"rate" : "7.9"
}
},
{
"_index" : "movie",
"_id" : "VWWnHYUBtcIfY_yD0bdt",
"_score" : 1.0,
"_source" : {
"title" : "Interstellar"
}
}
]
}
}1.3.11 인덱스 삭제: DELETE /:index
다음 명령어로 movie 인덱스와 인덱싱된 모든 도큐먼트를 삭제할 수 있다. 삭제한 인덱스와 도큐먼트는 복구할 수 없으므로 주의해야 한다.
curl -XDELETE $OPENSEARCH_REST_API/movie
{"acknowledged":true}1.3.12 도큐먼트 벌크 API
인덱싱 성능을 높이기 위해 도큐먼트 벌크 API를 사용할 수 있다. 도큐먼트 벌크 API를 사용하면 한 번의 요청으로 많은 도큐먼트를 생성, 수정, 삭제할 수 있기 때문에 네트워크 오버헤드가 줄어들고, 더 많은 인덱싱 스루풋을 확보할 수 있다. 그래서 가능하면 배칭 작업으로 인덱싱을 처리하는 것이 좋다.
벌크 작업 중 중간에 몇 개가 실패해도 전체 작업이 중단되지는 않는다. 실패한 작업이 있는지 확인하고 싶다면 벌크 API 응답에 포함된 items 배열을 확인하면 된다.
다음 명령어로 벌크 데이터를 생성해볼 수 있다.
curl -XPOST "$OPENSEARCH_REST_API/_bulk?pretty=true" \
-H "Content-Type: application/json" \
-d '
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_id" : "2" } }
{ "create" : { "_index" : "test", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
'
{
"took": 204,
"errors": false,
"items": [
{
"index": {
"_index": "test",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1,
"status": 201
}
},
{
"delete": {
"_index": "test",
"_id": "2",
"_version": 1,
"result": "not_found",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1,
"status": 404
}
},
{
"create": {
"_index": "test",
"_id": "3",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1,
"status": 201
}
},
{
"update": {
"_index": "test",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1,
"status": 200
}
}
]
}더 자세한 설명은 공식 문서를 참고하면 된다. (https://opensearch.org/docs/latest/api-reference/document-apis/bulk/)
