3.3 OpenSearch의 레플리카 샤드
3.1.2에서 설명한 레플리카 샤드에 대해 자세히 알아보자.
3.3.1 샤드를 복제하는 이유
출처: https://codingexplained.com/coding/elasticsearch/understanding-replication-in-elasticsearch
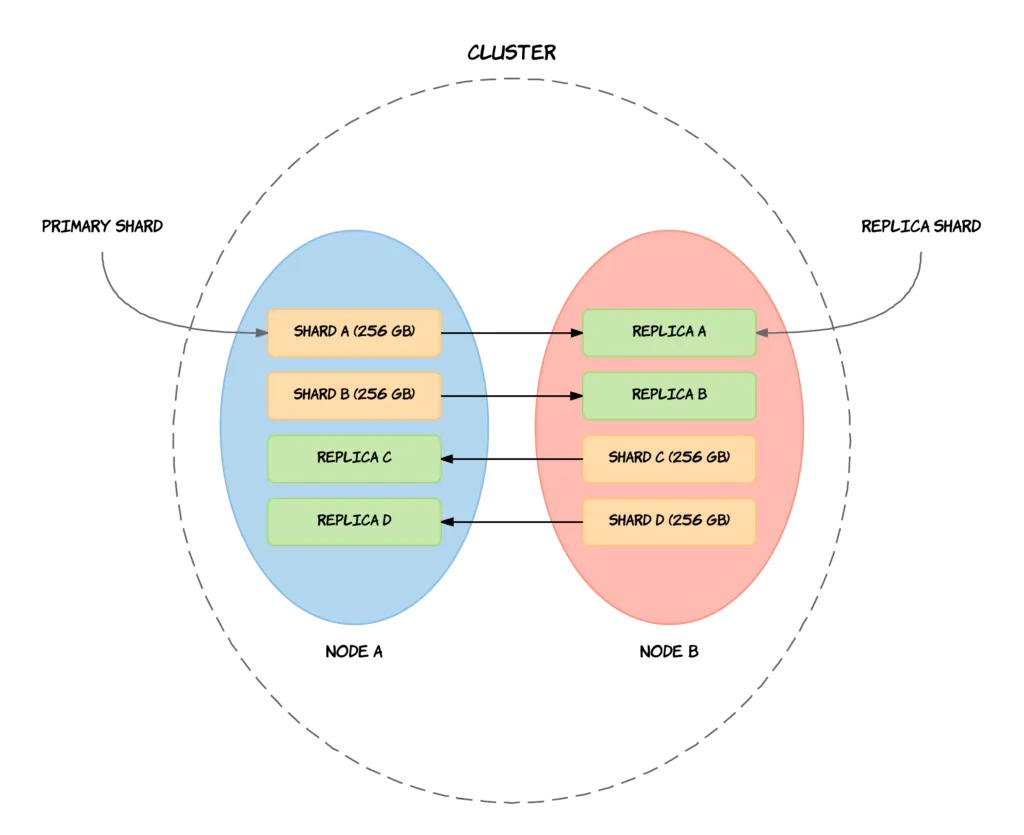
레플리카 샤드의 주된 목적은 노드나 샤드에 장애가 발생했을 경우에 백업 역할을 수행해서 고가용성(HA)을 제공하는 것이다. 고가용성을 실현하기 위해 레플리카 샤드는 프라이머리 샤드와 같은 노드에 할당되지 않는다. 즉 노드 하나가 클러스터를 이탈하더라도 다른 노드에 프라이머리 샤드의 레플리카가 최소한 1개 이상 존재하기 때문에 요청에 정상적으로 응답할 수 있다.
또한 부수적인 목적으로, 레플리카 샤드는 OpenSearch의 검색 성능을 높여준다. 프라이머리 샤드가 위치한 노드에 부하가 심해 응답이 느린 경우, 해당 프라이머리 샤드의 레플리카 샤드가 위치한 다른 노드에 대신 요청해 좀 더 빠른 검색을 수행할 수 있다. 부하 상태 노드에 추가적인 부하를 주는 것을 막을 수 있으므로, 클러스터의 전체적인 처리 성능 안정성도 높일 수 있다. 클러스터에 검색 요청이 많다면 인덱스 당 두 개 이상의 레플리카 샤드를 할당해서 검색 성능을 높이는 것이 좋다.
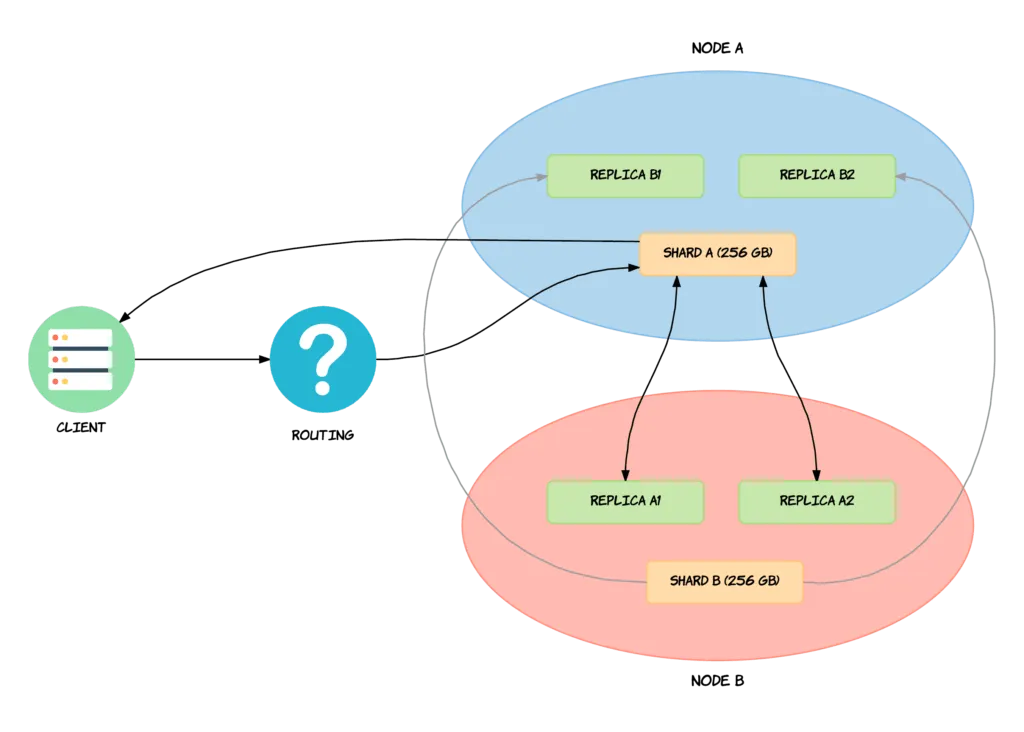
클라이언트가 Shard A에 Read요청을 했다고 하자. 마침 NODE A가 프라이머리에 샤드도 많고 데이터도 많고 ingest도 같이 수행하고 해서 NODE가 커졌고, 클라이언트가 응답받는데 걸리는 시간이 늘어났다. 이런 경우에는 NODE A 에 부하가 많으니까, SHARD A 와 똑같은 REPLICA A가 NODE B에 있어. 여기서 읽을래? 해서 요청이 NODE B의 REPLICA A 로 가서 데이터를 읽을 수 있도록 해준다.
이렇게 노드를 나눠서 부하를 분산해서, NODE Balance 를 할 수 있다. 대신 Read요청에 대해서만.
내가 클러스터를 구성할 건데 나는 Write는 별로 없고, Read가 대부분이고, 그리고 단순 Read가 아닌 집계가 많아. 그래서 이게 특정 NODE에 많이 몰릴 것 같아.
이런 경우엔 REPLICA 개수를 한 개가 아니라 두개, 세개 이렇게 해서 집계하면 집계 성능도 좋아진다.
성능이 좋아진다는 말은
원래 Client <> SHARD A 응답이 1초 걸릴 게
REPLICA 개수를 두개, 세개 둔다고 Client <> REPLICA A의 응답이 0.5초 내에 응답할 수 있다는 말이 아니다. 부하가 생겼을 때 부하를 다른 쪽으로 넘겨준다는 거니까 병렬 처리가 증가하는 건 아니고 전체적으로 일정하고 고르게 성능을 내고 싶을 때, REPLICA를 증가시켜서 Latency를 줄이고 Read 성능을 높이는 방법이다.
절대적 성능 자체를 올려주는 게 아니라 부하 줄여서 성능이 고르게 나오게 하는 관점에서 Read성능을 좋게 한다는 뜻.
레플리카 샤드 개수는 인덱스를 생성할 때 정의되며, 기본적으로 프라이머리 샤드 한 개 당 레플리카 샤드 한 개가 생성된다. 즉 기본 설정으로 인덱스를 생성하는 경우, 프라이머리 샤드 5개와 레플리카 샤드 5개를 합쳐서 총 10개의 샤드가 생성된다.
3.3.2 샤드 동기화
출처: https://codingexplained.com/coding/elasticsearch/understanding-replication-in-elasticsearch
프라이머리 샤드는 여러 개의 레플리카 샤드로 복제될 수 있는데, 모든 레플리카 샤드는 프라이머리 샤드와 동기화된 상태를 유지해야 한다. 레플리카 샤드 그룹이 프라이머리 샤드와 동일한 상태를 유지하지 못할 경우, 쿼리 결과의 일관성이 떨어지게 된다. 예를 들어 도큐먼트가 레플리카 샤드 A에서만 삭제되었다면 A에서 쿼리가 수행될 경우에는 도큐먼트를 읽어올 수 없지만, 다른 레플리카 샤드에서 쿼리가 수행될 경우에는 도큐먼트를 읽어올 수 없게 된다.
OpenSearch는 모든 샤드를 동기화하기 위해 프라이머리 샤드를 모든 인덱싱 작업의 진입점으로 사용한다. 즉 도큐먼트 추가, 수정, 삭제 등 인덱스에 영향을 미치는 모든 요청은 가장 먼저 프라이머리 샤드로 전달된다. 프라이머리 샤드는 다음과 같은 과정을 거쳐 레플리카 샤드와 동기화된 상태를 유지한다.
-
요청된 작업을 검증하고, 유효하지 않은 경우 거부한다. (예를 들어
number타입으로 매핑된 필드에object타입이 요청된 경우)- 정상적인 요청인지, 권한이 있는지, size limit, mapping상태 등
-
로컬에서 요청된 작업을 수행한다.
-
모든 in-sync 레플리카 샤드에 동일한 작업을 요청하며, 여러 개의 in-sync 레플리카 샤드가 있는 경우 모든 작업은 병렬적으로 수행된다.
- 클러스터 매니저 노드는 프라이머리 샤드로부터 작업을 요청받아야 하는 레플리카 샤드 목록을 관리한다. 이 목록에 있는 샤드를 in-sync 레플리카 샤드라고 하며, 프라이머리 샤드가 사용자에게 승인한 모든 인덱스 작업은 in-sync 레플리카 샤드에서 성공적으로 처리됐다는 것이 보장된다. 즉 프라이머리 샤드와 모든 in-sync 레플리카 샤드는 동일한 상태라는 것이 보장된다.
- 레플리카 샤드가 오프라인 상태인 경우 in-sync 레플리카 샤드 목록에서 제외되며, 프라이머리 샤드는 해당 레플리카 샤드에 작업을 요청할 필요가 없다.
-
모든 in-sync 레플리카 샤드가 성공적으로 작업을 수행하고, 프라이머리 샤드에 응답하면, 프라이머리 샤드는 클라이언트에게 요청된 작업을 승인한다.
1~4를 처리하던 중에 프라이머리 샤드 또는 레플리카 샤드에 장애가 발생할 수도 있다. 프라이머리 샤드에 장애가 발생한 경우 해당 샤드를 호스팅하는 노드는 클러스터 매니저에게 메시지를 전송한다. 클러스터 매니저가 레플리카 샤드 중 하나를 새로운 프라이머리 샤드로 승격시키면, 인덱싱 작업은 새로운 프라이머리 샤드로 전송된다. 또한 클러스터 매니저는 노드 상태를 모니터링하여 프라이머리 샤드를 사전에 강등시킬 수도 있다.
프라이머리 샤드에서 작업이 성공했음에도 불구하고, 레플리카 샤드에서 작업이 실패할 수도 있다. 이 경우 프라이머리 샤드는 문제가 있는 샤드를 in-sync 레플리카 셋에서 제거해달라고 클러스터 매니저에게 요청한다. 클러스터 매니저가 샤드 제거를 승인한 경우에만 프라이머리 샤드는 최종적으로 클라이언트의 요청을 승인한다. 이후 클러스터 매니저는 시스템을 정상적인 상태로 복원하기 위해 다른 노드에 새로운 레플리카 샤드를 생성할 것을 요청한다.
요약
샤드 동기화의 과정은 Primary Shard가 주도해서 진행이 되고 그래서 모든 클라이언트의 요청은 Primary Shard로 먼저 도달을 하는데 Primary Shard나 Replica Shard나 어디에 문제가 발생하면 클러스터 매니저가 어떤 Shard가 Primary인지 어떤 Shard가 Replica인지 In-Sync상태인지 이 목록을 관리하면서 Active한 Primary Shard의 상태 관리 Replica에 대한 복제관리 요거를 클러스터 매니저가 시도한다. 그리고 복제가 In-Sync Replica까지 다 복제가 되어야 클라이언트는 응답을 받을 수 있다.
