3.2 OpenSearch의 노드 타입과 역할
앞서 노드는 타입에 따라 수행하는 역할이 다르다고 했다. OpenSearch에서 제공하는 노드 타입에 대해 알아보자.
기본적으로 모든 노드는 어떤 타입도 될 수 있으며, 다양한 역할을 수행할 수 있다. 노드에 OpenSearch를 설치하고 설정 파일을 수정하지 않으면, 해당 노드는 기본적으로 모든 역할을 수행하게 된다. OpenSearch 설정 파일에서 노드 타입을 지정해줄 경우 하나의 역할만 수행하는 노드가 되는데, 이 노드를 전용 노드라고 부른다.
3.2.1 클러스터 매니저(Cluster manager) 노드
(마스터 노드라고도 불림)
- 클러스터는 반드시 한 번에 하나의 매니저 노드를 가져야 하며, 매니저 노드가 없으면 클러스터가 멈춘다.
- 매니저 노드는 클러스터의 상태를 모니터링하고, 노드에 샤드를 할당하는 등의 역할을 담당한다. 클러스터 상태 정보는 클러스터 설정, 인덱스 설정(매핑 정보, 물리적 위치 등), 노드 상태 등을 포함한다.
- 예를 들어, 매니저 노드는 ping 요청을 실행하여 노드 상태를 확인할 수 있다.
- 노드 상태를 알려면 다른 노드들이 정보를 줘야 함.
- 클라이언트는 매니저노드를 통해서 어떤 데이터노드에 어떤 샤드가 위치해있는지 이런 정보를 알 수가 있다.
- 인덱스 생성, 삭제 등 인덱스 관련 설정 정보를 마스터노드가 알고 있다~
3.2.2 클러스터 매니저 후보(Cluster manager eligible) 노드
-
매니저노드가 하나라고 했는데, 하나만 있으면 HA가 안됨. 기본적으로 분산시스템은 고가용성을 유지해야 하는데
고가용서을 위해서 있는 친구들이 클러스터 매니저 일리저블 노드라고 함. -
매니저 후보 노드는 선출 과정을 통해 매니저 노드가 될 수 있으며, 매니저 후보 노드만 선출 과정에 참여할 수 있다.
-
매니저 노드 선출 과정은 다음과 같다.
- 매니저 후보 노드끼리 서로에게 투표한다.
- 과반수 득표를 얻은 노드가 매니저 노드가 된다.
- 선출된 매니저 노드가 클러스터에서 이탈할 경우 1~2를 반복하여 매니저 노드를 다시 선출한다.
-
매니저노드는 최소 3대는 둬야 한다. (최악 대비)
-
데이터 노드는 몇 노드가 용량이 부족하더라도 최악의 경우 클러스터 전체가 죽지는 않음. 일부 데이터를 이용을 못 하거나 데이터가 추가로 안 들어가거나 이런 문제인 건데 매니저가 없으면 클러스터 전체를 이용할 수 없게 되니까
최소 2대이고 (매니저 포함 3대) 인프라적으로 분리되어 있는 환경이 있으면 좋다. (AWS에서는 A.Z)
3.2.3 데이터(Data) 노드
- 데이터 노드는 모든 데이터 관련 작업(인덱싱, 검색, 집계)을 담당한다.
- 실질적인 데이터 처리를 담당하기 때문에 일반적으로 가장 부하를 많이 받는 노드 타입이다.
- 다른 타입의 노드보다 더 많은 컴퓨터 리소스(CPU, 메모리, 디스크 등)를 사용한다.
- 모니터링을 통해 데이터 노드의 부하 상태를 체크하는 것이 중요하다. (가장 상세하게 모니터링 해야되는 노드)
- 특정 노드에 부하가 몰렸다면, 해당 노드의 샤드를 다른 데이터 노드로 재배치하여 부하를 분산시킬 수 있다.
- 클러스터를 구성할 때 매니저 노드와 데이터 노드를 전용 노드로 구성하는 것이 좋다.
- 단일 노드가 데이터 노드와 매니저 노드의 역할을 같이 수행하는 경우, 데이터 노드의 부하가 매니저 노드의 성능에 영향을 미칠 수 있다.
- 매니저 노드의 성능 저하는 클러스터 전체의 안정성을 해칠 수 있으므로, 가능하면 매니저 노드와 데이터 노드를 전용 노드로 구성하는 것이 좋다.
매니저 노드 같은 경우는 부하가 큰 CPU usage나 Memory Usage나 이런 게 커지지는 않는다. 물론 메모리를 관리해야 함. 메모리가 넘치지 않게 해야함. 매니저는 메모리가 중요하다.
데이터 노드는 모든 자원이 중요하다. CPU, Memory, Disk 모두 다 잘 봐야함.
CPU 느려지면 데이터 검색이 느려짐. 메모리 부족하면 인덱싱이 느려지거나 인덱싱을 못 함. 디스크가 모자라면 데이터 저장을 못 함.
여기까지는 필수, 아래부터는 옵션
3.2.4 인제스트(Ingest) 노드
출처: https://hevodata.com/learn/elasticsearch-ingest-pipeline/
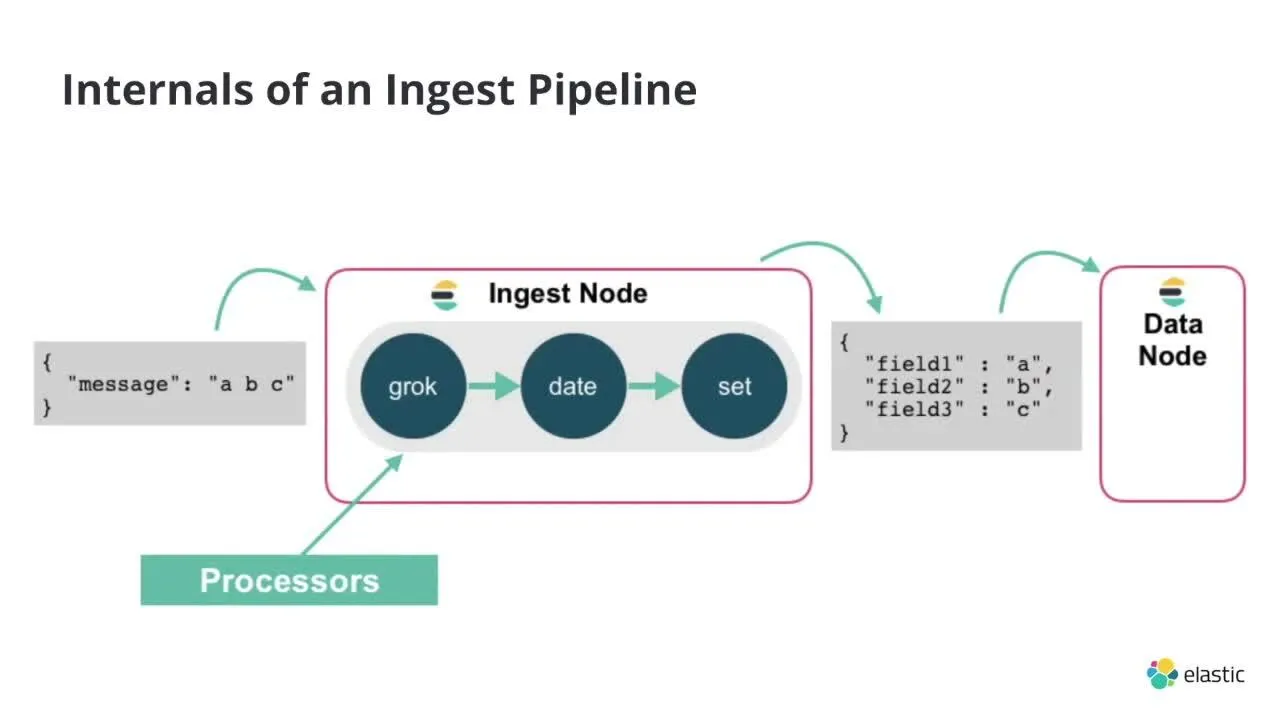
- 인제스트 노드는 인제스트 파이프라인을 실행하는 역할을 담당한다.
- 인제스트 파이프라인은 도큐먼트를 인덱싱하기 전에 도큐먼트를 전처리하는 역할을 담당한다.
- 인제스트 파이프라인은 다양한 프로세서로 구성된다. 프로세서란 파이프라인의 실행 단위로, 프로세서 종류와 순서에 따라 파이프라인의 출력이 달라지게 된다.
- 많은 데이터를 수집하고 복잡한 데이터 전처리 파이프라인을 실행할 계획이라면, 인제스트 전용 노드를 사용하는 것이 좋다.
- 복잡한 데이터 처리를 할거다. 또는 기본적 저장 하더라도 데이터가 많다. 면 인제스트 전용으로 사용하는 게 중요하다.
- 왜냐면 이런 프로세싱이 아니더라도 기본적으로 데이터 노드에 어디다 어떻게 저장할 것인가에 대해서 ingest노드가 결정을 하고 데이터노드에 가기 때문에 그렇다.
- 만약에 데이터 노드에서 직접 이런 걸 하면 자기 안에 샤드에 위치해야될 친구면 자기가 그냥 받아주면 되지만 다른 데이터 노드 샤드에 위치할 친구라면 다른 데이터 노드 다시 또 전달을 해줘야 함. 그로 인해 비용이 커짐.
- 데이터 저장, 색인, 검색에 치중해야 되는 굉장히 중요한 친구인데, 라우팅 해주느라고 자원을 쓰는 게 input 많은 경우엔 큰 문제가 된다. 따라서 데이터가 많다면 프로세싱 로직이 없더라도 인덱스 전용 노드를 쓰는 게 중요하다.
- 인제스트 노드는 로직이 있다. 어디다가 저장할지 이런 걸 논리적인 결정을 함. 라우팅 할 때 mod 연산을 함. CPU 자원을 쓰기 때문에 CPU가 중요하다. CPU 위주 모니터링 필요.
3.2.5 코디네이터(Coordinator) 노드
출처: https://levelup.gitconnected.com/elastic-search-simplified-part-2-342a55a1a7c7
-
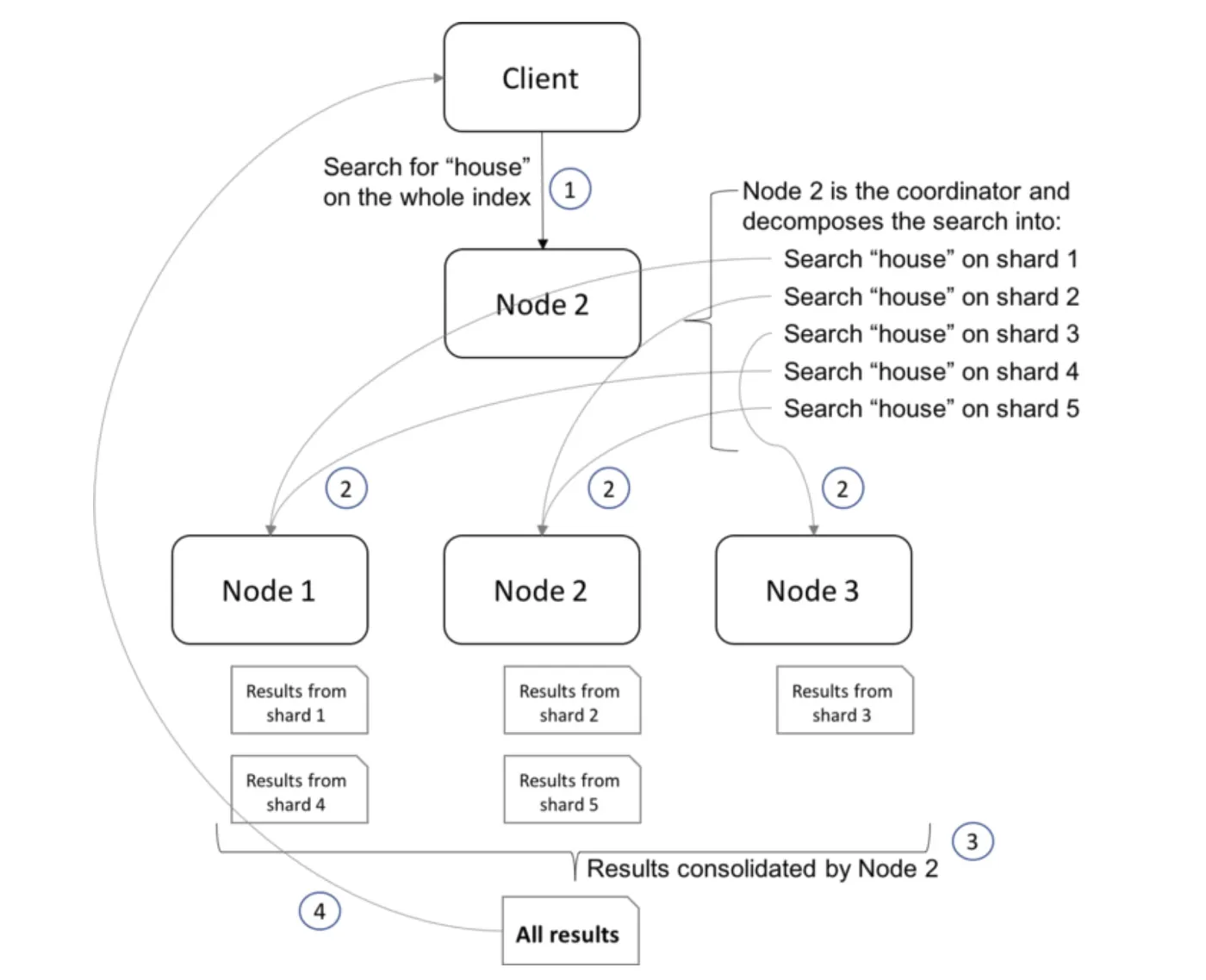
코디네이터 노드는 외부 클라이언트의 HTTP 요청을 처리하는 역할을 처리한다.
- OpenSearch에서 로드밸런서와 비슷한 역할을 수행하며, 요청을 데이터 노드에 위임하고, 결과를 수집하여 하나의 최종 결과로 집계하여 클라이언트에 응답한다.
- 코디네이터 노드가 데이터 쿼리를 요청 받은 경우 다음과 같은 순서로 해당 요청을 처리한다.
- 외부 클라이언트로부터 쿼리를 요청 받는다.
- 클러스터의 모든 노드에게 동일한 쿼리를 요청한다. (클라이언트의 요청에
_routing값이 포함된 경우_routing을 통해 어떤 노드의 어떤 샤드가 해당 데이터를 갖고 있는지 알 수 있으므로, 해당 노드에게만 쿼리를 요청) - 2에서 요청한 노드로부터 결과 데이터를 받아 집계(aggregation)한다.
- 집계 결과를 클라이언트로 보낸다.
-
검색이나 집계 요청이 많은 경우 병목 현상을 방지하기 위해 두 개(이상)의 코디네이터 전용 노드를 사용하는 것이 좋다.
-
데이터를 집계할 때 CPU와 메모리를 많이 사용하기 때문에 가능한 코어가 많은 CPU를 사용하는 것이 좋다.
