OpenSearch 클러스터가, ElasticSearch 클러스터가 지금 내가 사용하는 프로젝트나 회사에 잘 구축이 되어 있다, 그냥 사용만 하면된다면
1,2에서 배운 내용으로 과부하만 되지 않는다면 사용하는 데 큰 문제는 없을 것.
이번 챕터에서는 아키텍쳐 수준에서 OpenSearch의 분산 시스템의 구성을 알아보고 우리가 봤던 API, Indexing, Document의 저장이라던지 이런 게 실제로 어떻게 분산되어서 저장되고 처리되는지를 조금 더 알아볼 수 있다. 이거 배운다고 실무적으로 큰 임팩트가 없을 수도 있지만. 예상치 못한 문제가 발생했을 때. 아니면 더 높은, 고수준의 시스템을 설계해야된다고 했을 때 이런 내용들은 알아두면 도움이 될 것.
필요할 때 알아본다기 보다는 이미 알고 있어야 그런 상황을 맞닥뜨렸을 때 바로바로 써먹을 수 있다.
3.1 OpenSearch의 분산 아키텍처 구성 요소
OpenSearch가 데이터를 분산 처리하기 위해 사용하는 분산 아키텍처의 핵심 구성 요소는 다음과 같다.
- 클러스터(Cluster)
- 노드(Node)
- 샤드(Shard)
- 세그먼트(Segment)
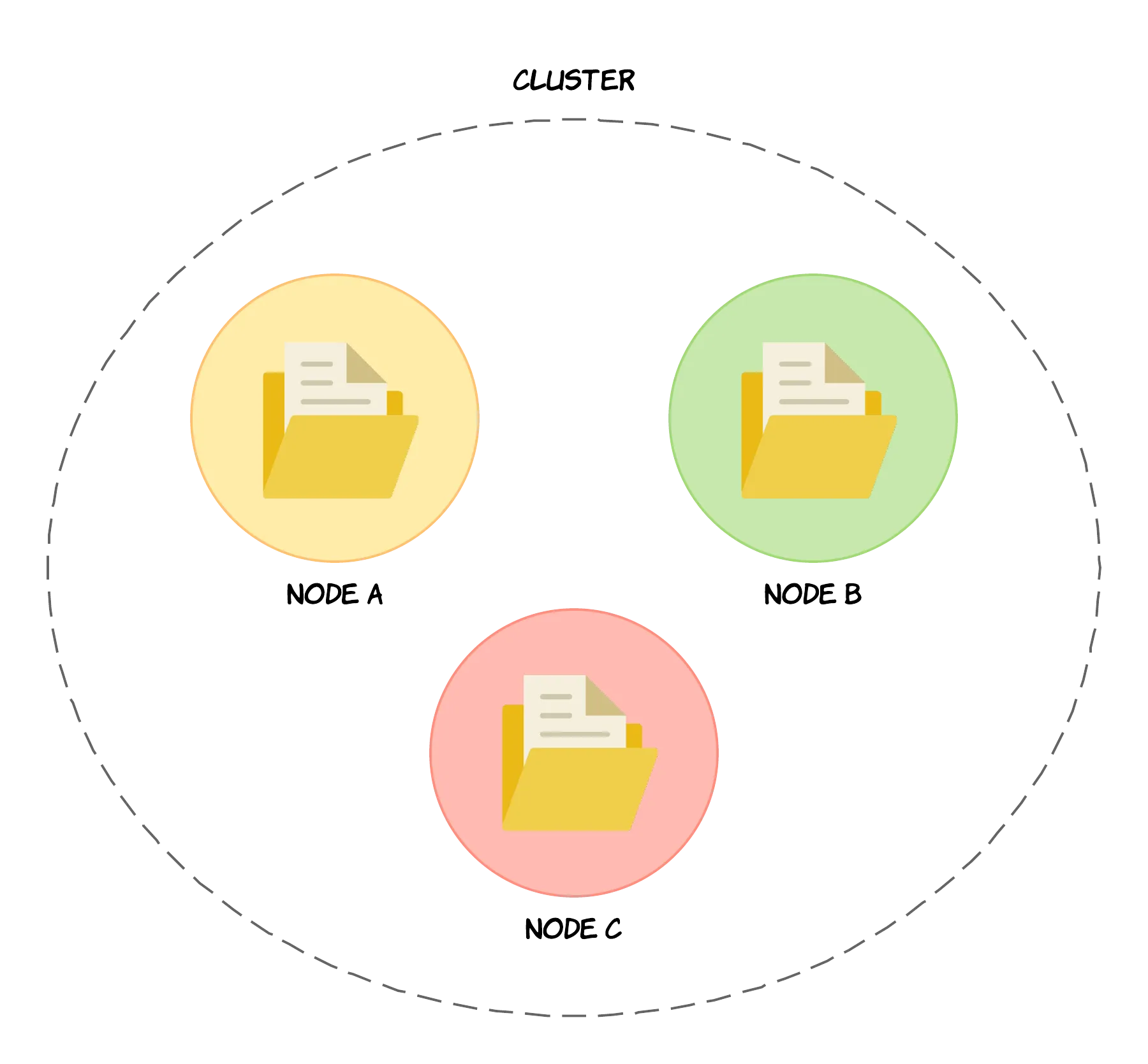
3.1.1 클러스터(Cluster)와 노드(Node)
출처: https://codingexplained.com/coding/elasticsearch/introduction-elasticsearch-architecture
클러스터는 노드의 집합이며, 노드는 클러스터를 구성하는 하나의 OpenSearch 인스턴스(하나의 JVM 인스턴스)로써 도큐먼트가 저장되는 곳이다. 쉽게 말해 노드는 OpenSearch가 설치된 물리 혹은 논리(가상) 서버다. 일반적으로 물리적인 서버 하나에 노드 하나를 설치하는 방식을 권장하지만(서버 죽으면 같이 죽으니까), 단일 서버에 복수의 노드를 설치해도 된다. 클러스터와 노드는 모두 고유한 이름으로 식별된다.
클러스터는 도큐먼트를 여러 노드에 분산시켜 저장할 수 있고, 모든 노드는 클러스터의 인덱싱 및 도큐먼트 검색 기능에 참여한다. OpenSearch에는 다양한 노드 타입이 있으며, 타입에 따라 수행하는 역할이 다르다. 하나의 노드에 복수의 타입을 할당할 수 있다.(클러스터를 운영한다고 하면 아까 PM과 마찬가지로 하나의 노드에 하나의 역할만 부여하는 것을 권장하고 있다)
노드와 외부 클라이언트 간의 통신은 Application 계층에서 HTTP 프로토콜로 동작하는 반면, 클러스터 내부에 있는 노드 간의 통신은 Transport 계층에서 동작한다. 외부 클라이언트가 REST API를 사용하여 클러스터에 요청을 전송하면 특정 타입의 노드는 해당 요청을 수신하고, 필요한 경우 Transport 계층을 사용하여 다른 노드로 추가 작업을 요청한다. 기본적으로 모든 노드는 외부 클라이언트의 HTTP 요청을 처리할 수 있지만, 클라이언트의 HTTP 요청를 처리하는 역할은 특정 타입의 노드만 수행하도록 제한된다.
3.1.2 샤드(Shard)
출처: https://nidhig631.medium.com/primary-shards-replica-shards-in-elasticsearch-269343324f86
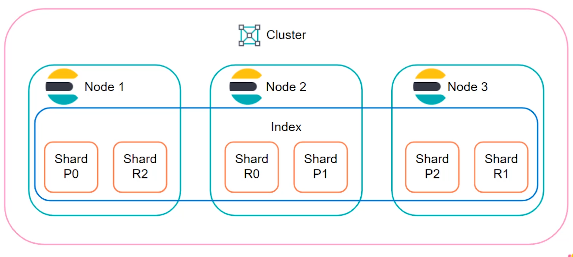
OpenSearch가 확장성이 뛰어난 이유 중 하나는 샤딩(Sharding) 때문이다. 샤딩은 데이터를 여러 개의 조각으로 나눠 분산 저장하여 관리하는 기술이며, 샤드란 샤딩을 통해 나눠진 데이터 블록이다. OpenSearch에서는 인덱스를 샤딩하여 샤드로 관리하고, 노드는 복수의 샤드로 구성된다. 앞서 도큐먼트를 인덱스에 저장한다고 했지만, 사실 인덱스는 논리적 단위이며 실제 도큐먼트의 인덱싱과 검색은 샤드에서 이뤄진다. 즉 분산된 샤드를 하나의 논리적 단위로 묶은 것이 인덱스다.
OpenSearch에서 샤드는 왜 필요할까? 다음과 같은 상황을 가정해보자. 1TB 크기의 인덱스에 복수의 도큐먼트가 저장되어 있고, 클러스터에는 총 2개의 노드가 있으며, 각 노드의 여유 저장 공간은 512GB다. 즉 인덱스를 하나의 노드에 저장할 수 없는 상황이다. 인덱스의 크기가 단일 노드의 하드웨어 리소스 제한을 초과하는 경우 인덱스를 샤딩하여 문제를 해결할 수 있다. 앞선 예의 경우, 다음 그림처럼 1TB 인덱스를 256GB 도큐먼트 묶음 4개로 나눈 후에 노드 2개에 분산시켜 저장하면 된다.
OpenSearch는 기본적으로 샤드 복제를 지원한다. 샤드를 복제하면, 원본은 프라이머리 샤드, 복제본은 레플리카 샤드(또는 레플리카)라고 불린다. 프라이머리 샤드와 레플리카 샤드에 대해서는 3.3에서 자세히 설명할 예정이다.
샤딩이 필요한 이유를 정리하면 다음과 같다.
- 여러 물리 장비를 활용하여 클러스터의 하드웨어 리소스를 수평 확장할 수 있다.
- 동일한 인덱스에 대한 요청을 여러 노드에 걸쳐 병렬적으로 처리할 수 있기 때문에 성능이 향상된다.
- 레플리카 샤드 덕분에 고가용성(High availability)과 빠른 처리 속도를 확보할 수 있다. (3.3에서 자세히 설명할 예정)
인덱스의 샤드 개수는 인덱스를 생성할 때 선택적으로 지정할 수 있으며, 기본적으로는 인덱스 하나에 5개의 샤드가 생성된다. 샤드 개수는 클러스터의 하드웨어 스펙과 인덱스의 데이터량 등을 고려하여 적절한 값으로 설정하면 된다.
과거 버전에서는 number of shards 의 default 가 5였다. 하지만 overshard 문제 때문에, 최근에 1로 변경되었다.
overshard 란 인덱스에 저장된 데이터 대비 shard 가 너무 잘게 쪼개져 있어서 불필요하게 성능의 손해가 발생하는 것을 말한다.
인덱스가 생성된 후에는 샤드 개수를 변경할 수 없다. 그러나 원하는 샤드 개수로 새로운 인덱스를 만들고, 기존 인덱스의 데이터를 새로운 인덱스로 이동시켜서 목적을 달성할 수는 있다.
인덱스의 샤드 개수를 변경할 수 없는 이유는 OpenSearch의 라우팅 방식 때문이다. 도큐먼트를 저장할 샤드를 결정하는 것을 라우팅이라고 한다. 도큐먼트는 기본적으로 모든 노드에 걸쳐 고르게 분산되어 저장되기 때문에 하나의 샤드에 많은 데이터가 몰리지 않는다. 라우팅은 기본적으로 자동 처리되며, OpenSearch에서는 다음 공식을 사용하여 도큐먼트가 저장될 샤드를 결정한다.
shard = hash(_routing) % 프라이머리 샤드 개수샤드는 idempotent하다
기본적으로 _routing 값은 저장하려는 도큐먼트의 ID와 동일하다. _routing 값은 해시 함수를 거쳐 숫자로 변환되고, 이것을 프라이머리 샤드 개수로 나눈 나머지 값이 바로 도큐먼트가 저장될 샤드 넘버다.
_routing 값을 직접 지정할 수도 있는데, 이를 커스텀 라우팅이라고 한다. 커스텀 라우팅을 사용하면 같은 _routing 값을 공유하는 도큐먼트들을 동일한 샤드에 저장할 수 있다. 그러나 커스텀 라우팅의 경우 몇 가지 주의해야 할 부분이 있다. 그 중 하나는 도큐먼트가 프라이머리 샤드에 고르게 분산되지 않을 수 있다는 것이다. 예를 들어, movie 인덱스에서 genre를 _routing 값으로 사용하는 경우, 대부분의 영화가 같은 genre라면 도큐먼트는 특정 샤드에 몰릴 수 밖에 없다. (skew)
라우팅 공식에 프라이머리 샤드 개수가 포함되어 있으므로, 인덱스의 샤드 개수를 변경하면 도큐먼트에 대한 라우팅 공식 실행 결과도 바뀌게 된다. 라우팅 공식은 도큐먼트를 ID로 검색할 때도 사용되는데, 샤드 개수를 변경하는 경우 도큐먼트가 저장될 때와 검색될 때의 라우팅 공식이 달라지게 되고, 그 결과 도큐먼트를 찾지 못할 수도 있다. 이것이 인덱스의 샤드 개수를 변경할 수 없는 이유다. OpenSearch의 기본 라우팅 공식을 사용해서 도큐먼트를 인덱싱한 후에 동일한 인덱스에 커스텀 라우팅을 도입하는 경우에도 동일한 문제가 발생할 수 있다.
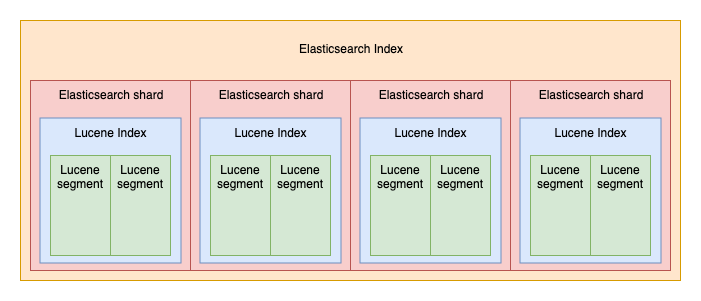
3.1.4 세그먼트(Segment)
출처: https://fdv.github.io/running-elasticsearch-fun-profit/003-about-lucene/003-about-lucene.html
위의 그림처럼 OpenSearch 샤드는 하나의 Lucene 인스턴스다. Lucene 인스턴스는 여러 개의 세그먼트를 포함하고 있다. 세그먼트는 OpenSearch에서 인덱스가 물리적으로 저장되는 가장 작은 단위로, 세그먼트 내부에는 인덱싱된 데이터가 역색인 구조(단어 기반으로 색인을 생성하여 해당 단어가 포함된 문서를 쉽게 찾을 수 있도록 함)로 저장되어 있다. 기본적으로 인덱싱된 도큐먼트는 하나의 세그먼트로 저장된다. Lucene 인덱스는 검색 요청이 들어오면 모든 세그먼트에 걸쳐 순차적으로 검색을 수행하고, 이를 통합해서 하나의 결과로 응답한다.
세그먼트는 한 번 디스크에 저장되면 수정이 불가능한 불변 데이터(Immutable)다. 도큐먼트를 수정할 경우 도큐먼트가 포함된 세그먼트를 변경하지 않고, 수정 사항이 반영된 새로운 세그먼트를 생성한 다음 기존 세그먼트를 삭제하는 방식을 활용한다. 도큐먼트를 삭제하는 경우에도 세그먼트 내의 도큐먼트를 실제로 삭제하지 않고, 삭제할 도큐먼트라고 표시만 해둔 다음 검색할 때는 해당 도큐먼트를 읽지 않도록 처리한다.
세그먼트에 대한 검색은 병렬적으로 수행될 수 없기 때문에 세그먼트 수가 많을수록 검색 속도가 느려진다. 그래서 Lucene은 검색 성능을 높이기 위해 정기적으로 백그라운드에서 세그먼트 파일을 물리적으로 하나의 큰 세그먼트 파일로 병합하고, 삭제 표시한 도큐먼트를 실제로 세그먼트에서 삭제한다. 이를 세그먼트 병합이라고 한다. 세그먼트 병합은 OpenSearch API로 트리거할 수도 있다. 세그먼트 병합은 물리적인 저장 공간에서 이뤄지기 때문에 많은 CPU와 I/O 리소스를 사용한다. 대량의 데이터 인덱싱을 수행할 때는 세그먼트 병합을 비활성화하는 것이 좋고, 적절한 세그먼트 병합 정책과 스케쥴러를 활용하여 서버 성능을 최적화할 수도 있다.
Lucene이 세그먼트를 생성하고 병합하는 방법에 대한 구체적인 설명은 공식 문서를 참고하자.(https://lucene.apache.org/core/9_4_2/index.html)
