4.2 인덱스 라이프사이클 관리
인덱스에 도큐먼트를 제한 없이 저장한다면, 인덱스의 크기는 무한히 커질 수 밖에 없다. 인덱스의 크기가 너무 커질 경우 성능 문제가 발생할 수 있으므로, 주기적으로 인덱스를 나눠주는 작업이 필요하다. OpenSearch에서는 ISM(Index State Management)을 통해 자동으로 인덱스의 라이프사이클을 관리할 수 있는데, 예를 들면 다음과 같은 규칙을 설정할 수 있다.
- 인덱스가 특정 크기 또는 도큐먼트 수에 도달하면 새로운 인덱스를 생성한다.
- 매일, 매주 또는 매월 새로운 인덱스를 생성하고 이전 인덱스를 보관한다.
ISM은 내부적으로 rollover와 shrink라는 개념을 사용해서 인덱스를 관리한다.
4.2.1 rollover API
인덱스가 특정 조건에 도달했을 때 새로운 인덱스를 생성하는 API다. ISM 템플릿에 rollover 조건을 설정하면 주기적으로 rollover 조건을 체크하고, 새로운 인덱스를 생성해준다. 본 강의에서는 rollover API를 직접 호출해서 수동으로 인덱스를 rollover해볼 것이다.
rollover를 사용하려면 인덱스 alias 설정이 필요하다. 인덱스 alias는 여러 인덱스를 가리킬 수 있는 가상의 인덱스 이름으로, 여러 인덱스를 동일한 그룹으로 묶고 싶을 때 사용하면 된다. alias가 가리키는 인덱스는 언제든지 변경할 수 있으며, alias를 통해 여러 인덱스에 걸쳐 분산 저장된 도큐먼트를 한 번에 쿼리할 수도 있다. 예를 들어, 월 기준으로 인덱스에 로그를 저장하고, 최근 두 달 동안의 로그를 자주 쿼리하는 경우 last_2_months라는 alias를 생성하고, 매월 해당 alias가 가리키는 인덱스를 업데이트하면 된다. rollover는 인덱스 alias에 대해 수행된다. 즉 인덱스 alias를 rollover하면, 해당 alias에 새로운 인덱스가 생성되는 것이다.
rollver API 실습을 위해 Elasticvue에서 my-index-000001 인덱스를 생성하자. 인덱스 alias를 rollover할 때 기존 인덱스 이름이 my-index-000001과 같이 하이픈과 6자리 숫자 조합으로 끝날 경우 새로운 인덱스의 이름은 my-index-000002처럼 자동으로 숫자가 증가되어 설정된다. 인덱스 이름이 위의 형식과 맞지 않을 경우 target-index 필드를 통해 새로 만들 인덱스 이름을 지정해줘야 한다.
다음 요청으로 my-index-000001 인덱스에 alias 설정을 추가할 수 있다. is_write_index를 true로 설정해야 해당 인덱스에 대한 쓰기 작업이 허용되며, 인덱스 alias의 여러 인덱스 중 하나의 인덱스에만 is_write_index를 true로 설정할 수 있다. 즉 인덱스 alias는 쓰기 가능한 인덱스를 한 개만 가질 수 있다.
$ curl -XPOST "$OPENSEARCH_REST_API/_aliases?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"actions": [
{
"add": {
"index": "my-index-000001",
"alias": "alias1",
"is_write_index": true
}
}
]
}
'다음과 같은 조건으로 alias1을 rollover해보자. 현재 alias1에 인덱싱된 도큐먼트가 없기 때문에 rollover되지 않은 것을 확인할 수 있다.
$ curl -XPOST "$OPENSEARCH_REST_API/alias1/_rollover?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"conditions": {
"max_age": "30d",
"max_docs": 1,
"max_size": "10gb"
}
}
'다음 요청으로 alias1에 도큐먼트를 인덱싱해보자. my-index-000001 인덱스에 도큐먼트가 인덱싱된 것을 응답 본문에서 확인할 수 있다. PUT /alias/_doc API를 사용하면 OpenSearch는 해당 인덱스 alias에 포함된 인덱스 중 쓰기 가능한 인덱스로 요청을 라우팅하기 때문이다.
$ curl -XPUT "$OPENSEARCH_REST_API/alias1/_doc/1?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"text": "Hello, world!"
}
'다시 alias1을 rollover해보자. max_docs 조건을 만족했기 때문에 rollover가 되고, 새로운 my-index-000002 인덱스가 생성된 것을 확인할 수 있다.
$ curl -XPOST "$OPENSEARCH_REST_API/alias1/_rollover?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"conditions": {
"max_age": "30d",
"max_docs": 1,
"max_size": "10gb"
}
}
'Elasticvue에서 Show info 버튼을 눌러서 인덱스 정보를 확인해보자. is_write_index 설정이 변경된 것을 확인할 수 있다. 즉 앞으로 alias1에 대한 쓰기 작업은 my-index-000002 인덱스만 참여하고, alias1에 대한 검색 작업은 my-index-000001과 my-index-000002 인덱스 모두 참여하게 된다. is_write_index은 인덱스 alias 수준의 설정이므로, POST /my-index-000001/_doc으로 my-index-000001에 직접 인덱싱을 요청할 경우 여전히 정상적으로 처리된다.
다음과 같이 alias1에 도큐먼트를 인덱싱하면 my-index-000002에 인덱싱된 것을 응답 본문에서 확인할 수 있다.
$ curl -XPUT "$OPENSEARCH_REST_API/alias1/_doc/2?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"text": "What is your name?"
}
'alias1에 대해 검색을 요청하면, alias1에 포함된 모든 인덱스에 대해 검색 작업이 수행된 것을 확인할 수 있다.
4.2.2 shrink API
shrink API는 인덱스의 프라이머리 샤드 개수를 줄여준다. 내부적으로 shrink API는 기존 인덱스의 모든 데이터를 프라이머리 샤드 개수가 더 적게 설정된 새로운 인덱스로 옮겨서 샤드 병합을 수행한다. 자주 사용하지 않는 인덱스의 경우 shrink API로 샤드 개수를 줄여서 리소스 사용량을 최소화하는 것이 좋다.
shrink API를 사용하기 위한 전제 조건은 다음과 같다.
- 인덱스는 읽기 전용이어야 한다.
- shrink 작업 도중 도큐먼트가 인덱싱되는 것을 막아준다.
- 인덱스의 모든 프라이머리 또는 레플리카 샤드가 동일한 노드에 있어야 한다.
- 예를 들어
p0,p1,r0,r1샤드가 존재하는 경우,p0,r1이 동일한 노드에 있으면 조건을 충족한다. 반드시 모든 샤드가 프라이머리 샤드일 필요는 없다. - 인덱스의 레플리카 샤드를 모두 제거하면 shrink 작업이 더 쉬워진다. 어차피 레플리카 샤드는 병합된 프라이머리 샤드 기준으로 새롭게 생성된다.
- 예를 들어
- 인덱스는 green 상태여야 한다.
test2 인덱스 설정을 수정해서 shrink API를 사용할 수 있도록 만들어보자. 다음 요청은 test2 인덱스에 대해 3가지 작업을 수행한다.
- test2 인덱스의 모든 레플리카 샤드를 제거한다.
- test2 인덱스의 모든 프라이머리 샤드를 opensearch-d3 노드에 재배치한다.
- test2 인덱스를 읽기 전용으로 만든다.
$ curl -XPUT "$OPENSEARCH_REST_API/test2/_settings?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"settings": {
"index.number_of_replicas": 0,
"index.routing.allocation.require._name": "opensearch-d3",
"index.blocks.write": true
}
}
'다음 요청으로 test2 인덱스를 test2-new 인덱스로 shrink해보자. shrink 작업은 원본 인덱스와 동일한 설정으로 새로운 인덱스를 생성하는데, 다음과 같이 settings 필드를 통해 일부 설정을 overwrite할 수 있다. index.routing.allocation.require.name를 null로 초기화해서 인덱스가 여러 노드에 분산되도록 했고, index.blocks.write도 null로 초기화해서 인덱스를 쓰기 가능하도록 만들었다.
$ curl -XPOST "$OPENSEARCH_REST_API/test2/_shrink/test2-new?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"settings": {
"index.number_of_shards": 2,
"index.number_of_replicas": 1,
"index.routing.allocation.require._name": null,
"index.blocks.write": null
}
}
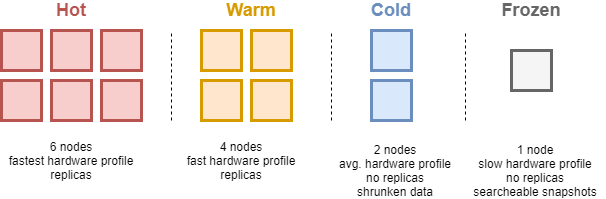
'4.2.3 핫-웜-콜드(Hot-warm-cold) 아키텍처 설정
핫-웜-콜드 아키텍처에서는 데이터 검색 빈도에 따라 핫/웜/콜드 노드에 저장한다. 핫-웜-콜드 아키텍처는 로그, 메트릭 및 트랜잭션 같은 시계열 데이터에 주로 사용된다. 시계열 데이터는 한 번 인덱싱되면 업데이트 될 가능성이 거의 없고, 시간이 지날수록 데이터 검색 빈도가 낮아지기 때문에 오래된 데이터를 저렴한 스토리지로 이동시켜 비용을 절감할 수 있다. 즉 처음에는 데이터를 성능이 좋고 비싼 핫 노드에 인덱싱하고, 일정 시간이 지나면 약간 느리지만 저렴한 웜 노드로 이동시키는 아키텍처를 핫-웜-콜드 아키텍처라고 부른다. 핫-웜-콜드 노드의 특징은 다음과 같다.
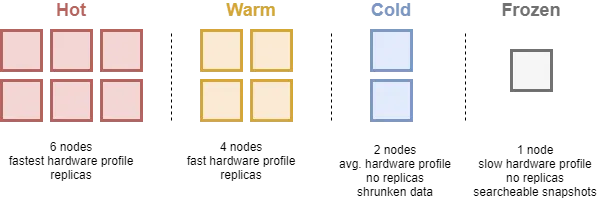
- 핫 노드
- 핫 노드에는 활발하게 검색하고 인덱싱하는 데이터를 저장한다.
- 디스크와 메모리의 IO 성능이 중요하다. (SSD 사용 추천)
- 웜 노드
- 자주 사용되지 않는 데이터는 핫 노드에서 웜 노드로 이동시킬 수 있다.
- 디스크 IO 성능은 중요하지 않지만, 대용량 데이터를 저장할 수 있도록 사이즈가 큰 디스크를 사용하는 것이 좋다. (HDD 사용 추천)
- 콜드 노드
- 더 이상 업데이트되지 않는 데이터를 웜 노드에서 콜드 노드로 이동시킬 수 있다.
- 콜드 노드로 데이터를 마이그레이션할 때 디스크 공간을 절약하기 위해 데이터를 압축할 수 있다.
- 검색 속도가 중요하지 않기 때문에 데이터를 메모리에 띄워 놓지 않고, 검색 요청이 올 때마다 인덱스 파일을 디스크에서 읽을 수도 있다.
예를 들어 최근 로그는 활발하게 인덱싱되고 검색되기 때문에 핫 노드에, 지난주 로그는 최근 로그만큼 자주 검색되지 않기 때문에 웜 노드에, 지난달 로그는 거의 검색되지 않지만 혹시 모를 상황에 대비해서 콜드 노드에 저장할 수 있다.
노드 2개와 ISM으로 핫-웜 아키텍처를 구성해보자. opensearch-d1은 핫 노드로, opensearch-d2는 웜 노드로 사용할 것이다. 모든 인덱스는 처음에는 핫 노드에 저장되고, 이후 ISM에 의해 웜 노드로 이동된다. 먼저 노드에 hot 또는 warm 태그를 붙여줘야 한다.
opensearch-d1 노드 설정 파일을 다음과 같이 수정하고, 노드를 재시작하자.
- 또는 d1, d2 노드 모두 hot 으로 설정한다.
node.attr.temp: hotopensearch-d2 노드 설정 파일을 다음과 같이 수정하고, 노드를 재시작하자.
- d1, d2 를 모두 hot으로 한 경우는 d3 노드를 warm으로 하자.
node.attr.temp: warmtemp라는 노드 속성과 hot, warm과 같은 태그 값은 임의로 설정한 것이며, 다른 어떤 값이든 사용할 수 있다. 단, ISM 템플릿에서도 동일한 값을 사용해야 한다. 다음 요청으로 노드 설정이 잘 적용되었는지 확인해보자.
$ curl -XGET "$OPENSEARCH_REST_API/_cat/nodeattrs?v&h=node,attr,value&pretty=true"인덱스를 생성하면 샤드를 무조건 핫 노드에 할당하도록 인덱스 템플릿을 생성하자. 인덱스 템플릿은 새로운 인덱스를 생성할 때 사용할 설정 값을 미리 정의해놓은 것이다. 다음과 같이 logs-template이라는 인덱스 템플릿을 만든 경우, 앞으로 인덱스 이름이 logs-* 패턴과 일치하면 해당 인덱스는 자동으로 hot 노드에 할당된다. index.plugins.index_state_management.rollover_alias는 해당 인덱스가 rollover할 때 사용할 인덱스 alias를 정의하는 필드다.
$ curl -XPUT "$OPENSEARCH_REST_API/_index_template/logs-template?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"index_patterns": [
"logs-*"
],
"template": {
"settings": {
"index": {
"plugins": {
"index_state_management": {
"rollover_alias": "logs"
}
},
"routing": {
"allocation": {
"require": {
"temp": "hot"
}
}
}
}
}
}
}
'logs-test 인덱스를 생성해보자.
- (d1: hot, d2: warm) 세팅인 경우
- 프라이머리 샤드만 핫 노드에 할당된 것은
hot으로 태깅된 노드가 한 개 뿐인 상황에서 레플리카 샤드를 동일한 노드에 할당할 수 없기 때문이다.
- 프라이머리 샤드만 핫 노드에 할당된 것은
- (d1,d2: hot, d3: warm) 세팅인 경우
- 프라이머리 샤드, 리플리카 샤드 모드 d1, d2 에 각각 할당된다. d3 는 warm이므로 할당되지 않는다.
$ curl -XPUT "$OPENSEARCH_REST_API/logs-test/_doc/1?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"content": "Hello, OpenSearch!"
}
'- d1: hot, d2: warm, d3-nothing 인경우. replica를 위치할 hot이 없으므로 yellow
- (d1,d2: hot, d3: warm) 세팅인 경우
다음과 같은 방식으로 인덱스를 관리하는 ISM 정책을 생성해보자. 테스트를 위해 index_patterns에는 일부러 wildcard를 사용하지 않았다. 즉 logs-000001 인덱스에 대해서만 ISM 정책이 적용될 것이다.
- 인덱스는 hot 상태에서 시작하고, 샤드는 핫 노드에 할당된다.
- hot 인덱스는 1분 후에 rollover를 한다.
- rollover를 하고 5분이 지나면 warm 상태가 되고, 레플리카 샤드가 제거되면서 웜 노드에 재배치된다.
$ curl -XPUT "$OPENSEARCH_REST_API/_plugins/_ism/policies/hot-warm?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"policy": {
"description": "hot-warm architecture",
"error_notification": null,
"default_state": "hot",
"states": [
{
"name": "hot",
"actions": [
{
"retry": {
"count": 3,
"backoff": "exponential",
"delay": "1m"
},
"rollover": {
"min_index_age": "1m"
}
}
],
"transitions": [
{
"state_name": "warm",
"conditions": {
"min_rollover_age": "5m"
}
}
]
},
{
"name": "warm",
"actions": [
{
"retry": {
"count": 3,
"backoff": "exponential",
"delay": "1m"
},
"replica_count": {
"number_of_replicas": 0
}
},
{
"retry": {
"count": 3,
"backoff": "exponential",
"delay": "1m"
},
"allocation": {
"require": {
"temp": "warm"
},
"include": {},
"exclude": {},
"wait_for": false
}
}
],
"transitions": []
}
],
"ism_template": [
{
"index_patterns": [
"logs-000001"
]
}
]
}
}
'다음 요청으로 ISM 정책이 적용될 logs-000001 인덱스를 생성하고, logs alias에 추가해주자.
$ curl -XPUT "$OPENSEARCH_REST_API/logs-000001?pretty=true"
-H "Content-Type: application/json" \
-d '
{
"aliases": {
"logs": {
"is_write_index": true
}
}
}
'다음과 같이 explain API를 활용하면 해당 인덱스에 어떤 ISM 정책이 적용되었고, 현재 어떤 상태에 있는지 확인할 수 있다. 인덱스에 ISM 정책이 적용되는 데는 몇 분 정도 걸린다.
$ curl -XGET "$OPENSEARCH_REST_API/_plugins/_ism/explain/logs-000001?pretty=true"1단계: hot-warm 정책이 logs-000001 인덱스에 성공적으로 적용되면 다음과 같은 응답 본문이 온다. 현재는 hot 상태에 있다.
2단계: logs-000001 인덱스가 rollover되면서 logs-000002 인덱스가 생성됐다.
3단계: rollover 를 성공적으로 마치고, transition 을 evaluation 했다. 하지만 아직 조건이 맞지 않아서 다음 시도를 기다릴 때 다음과 같은 응답이 나온다.
- failed 가 false 이므로 실패한 것은 아니다.
4단계: Transition 조건이 맞아 transition을 시도하고 있다. 이 과정에서 노드간 복사가 일어나므로 시간이 오래 걸린다.
완료: warm 으로의 transition 이 완료되면 다음과 같은 메세지를 받을 수 있다.
샤드 결과
logs-000001 인덱스가 warm 상태로 바뀌면서 레플리카 샤드가 없어지고, 웜 노드(opensearch-d2)로 이동한 것을 확인할 수 있다.
📌 ElasticSearch에서는 ILM(Index Lifecycle Management)을 통해 인덱스 라이프사이클을 관리할 수 있다. ISM과 ILM은 모두 rollover된 인덱스 기반으로 작동하며, 인덱스는 인덱스 크기, 도큐먼트 개수 등을 기준으로 rollover된다. ISM에서 핫-웜 노드 타입은 앞서 본 것처럼 노드 속성으로 구분되는 반면, ISM은 노드 타입 자체로 구분된다. 예를 들어 ElasticSearch는
node.roles: [ data_hot ]처럼 설정하면 핫 노드로 구분할 수 있다. 또한 ISM은 핫-웜-콜드 아키텍처를 구성하기 위해 직접 템플릿을 정의해야 하지만, ILM은 기본 템플릿으로 제공된다.
