1. 중견기업 규모의 전사 데이터 엔지니어링 요구사항
해당 내용은 데이터 엔지니어링 강사님이 경험한 내용들과 현실적 문제들을 고려한 인프라 환경 구성 예시이다. 강의가 제작되고 몇년이 지났고, 해당 내용이 정답은 아니기에 이런 식으로도 구성을 할 수 있구나~ 정도로 참고를 하자.
1.1 왜 전사 데이터 엔지니어링 시스템이 필요할까?
우선 강의를 들어가기 전에 왜 이 주제를 선택했는가? 에 대한 설명을 해보자.
전사 데이터 엔지니어 라는 건 우리 회사 서비스가 막 성장해서 유저 수도 꽤 되고,
예를 들어 B2C 라고 한다면 MAU 유저가 10만 명 이상 ~ 100만 이상인 경우,
중소기업 이라고 할 수 도 있고 중견기업이라고 할 수 도 있는데, 내부에 프로덕트도 많고, 데이터도 많고, 데이터 활용에 대한 요구사항은 기하급수적으로 많아질 것.
데이터활용도가 높아지니까 사람들이 데이터 관련 전문 엔지니어가 있지 않을까. 이런 고민을 하게 되는데, 왜 그런 필요가 생기는지 크게 두가지 포인트를 뽑았다.
1. 비용
- 데이터 인프라는 기능성 뿐만 아니라 안정성이 중요하고, 데이터 사이즈가 클수록 기술의 전문성에 대한 허들이 높기 때문에 Managed. Service 또는 SaaS 형 제품을 초기에 많이 선택함.
- 사용한 만큼 비용을 낼 수 있다면 비용대비 생산성 향상에 큰 도움
회사가 성장 중이라면 전문 데이터 엔지니어가 회사에 있을 가능성이 낮다.
회사에서는 그냥 백엔드 개발자 한 명이 대충 며칠 공부해가지고 설치해서 쓰면 결국 어느 장애 지점이 됐을 때, 관리도 잘 안되기도 하고, 장애가 생겼을 때 잘 해결하지도 못하고 여러 이슈 때문에 파묻혀가지고 레거시가 되고 이런 게 생기니까 아마 처음에는 자체적으로 해결하려는 노력이 있겠지만 허들이 높기 때문에 Managed, SaaS 형 제품을 선택할 가능성이 높다. (비용이 너무 문제가 아니라면)
이런 걸 다룰 수 있는 엔지니어를 뽑는다고 하면 이 사람의 연봉 + 사람 뽑는데 HR 추가적 비용. 엔지니어 연봉의 두배~세배 지출이 나간다고 생각을 해야함. 사람 있으면 혼자 일 못하죠. 두세 명 팀으로 뽑아야 하고 그게 또 세 배가 되고. 그리고 엔지니어들이 또 커뮤니케이션을 함. 전사적 커뮤니케이션 코스트가 올라가는 격. 복잡도도 커지고. 그런데 우리 회사는 빨리 성장해야 되는데, 그래서 이런 관리형 제품을 선택하는 경우가 많다.
- 데이터 사이즈가 커지면, Managed Service, SaaS 제품의 라이센스 비용은 데이터 용량에 비례해서 추가가 됨. 이 규모가 연간 수억~ 수백억 까지 달함.
2. 기능
-
상용 제품에 나와있는 데이터 인프라의 기능이 자신의 요구사항에 맞지 않는 경우, 직접 개발하고자 하는 필요가 생김
-
상용 제품이 같은 작업에 대해 직접 개발해서 최적화하는 것보다 시스템 자원을 더 많이 소모하는 경향이 있음.(일반적인 요구사항을 담기 위해 동작하므로) 데이터가 클 수록 비용이 더욱 증가.
데이터 인프라 설치하려면 또 서버 사이즈가 크다. 디스크도 크고, CPU도 많고 램도 크고 이러니까 비용이 일반 어플리케이션 I/O 하는 서버보다 많이 듦
위와 같은 한계지점이 발생할 때, 전문성 있는 데이터 엔지니어 몇개의 팀이 직접 오픈소스를 이용해서 시스템을 설치하고 운영하면 회사에서는 다음과 같은 이점을 얻을 수 있다.
- 비용 절감
- 최적화 가능
- 추가적인 기능 개발
단, 이 시스템을 개발하고 유지보수하면서 발생하는 기회비용은 역시 있다.
- 개발 시간
- 개발 능력
한 팀(6명)의 데이터 엔지니어 자체를 구하기 힘들다. 힘들게 모아서 팀이 구성됐어도 팀워크도 맞춰야 하고, 처음엔 제품들이 없으니까 오픈소스 이용한다고 하지만 회사의 데이터가 크고 요구사항이 복잡하니까 그냥 쓰면 안되고 또 디벨롭을 해야 함. 직원들에게 배포하기 전까지 개발 기간이 필요하다.
개발 기간도 기간인데, 얘가 또 안정화 될 때 까지 여러 번 배포하고 테스트하고 검증을 해야 함. 이 과정에서 많은 시간과 전사적인 노력또한 필요하다. 개발이 끝나기 전까지 불안정한 프로그램 쓰느라고 사내 있는 다른 엔지니어들이 고통을 받게 된다.. 의욕 개떨어짐 ㅋㅋ 사스 툴 쓰면 몇 번 딸깍이면 되는데 왜 직접 한다고 해가지고 맨날 버그생기고 그러냐. 바로 그런 얘기 나옴.
이런 전체적인 비용 생각하면 실제 투입된 서버비용, 라이센스 비용 뿐 아니라, 추가적인 생산성 관련 무형의 비용이 더 크다.
여기서 끝이 아니다?
엔진어 뽑아놨는데 개발 능력이 안 돼서 뽑아 놓고 1년 기다렸는데, 사스 보다 Saas 제품보다 품질이 너무 안 좋아. 이런 경우도 또 기회비용이 발생한다. 이 고통은 또 다른 사람들에게 전가됨.. 또 잘 하는 사람이 언제까지 있을지 모른다. 공무원이 아니기 때문에.. 이런 리스크 들이 있다~
회사 규모가 커져서 위에 적혀있는 리스크들을 감수하고서도
팀 꾸려서 할 가치가 있다고 판단 했다고 치고.
이제 회사의 요구 사항을 확인해 보자.
1.2 데이터의 용도에 따른 구분
회사 또는 서비스의 규모가 커지면 데이터의 양이 많아지기 때문에 성격에 따라서 전문적인 요구사항이 생긴다. 크게 다음과 같은 용도로 구분할 수 있다.
- 서비스: 서비스 또는 시스템의 주요 기능에서 직접 사용되는 데이터.
- 민감도가 높은 데이터.
- e.g. user table, order table
- 로그: 서비스 또는 시스템의 운영과정에서 수집되는 로그 데이터.
- 비동기적으로 전송/사용 되는 데이터. (내가 바로 필요한 데이터가 아님 전송은 해 놓고.)
- e.g. user action event, http access log, server log, App debugging log
- 집계(aggregation) : 서비스 또는 로그 데이터에서 일정 집계 조건에 따라서 통계를 구한 데이터.
- 서비스에 직접 활용되지 않는다.
- 유저가 한 달 소비 금액을 집계해서 화면에 꼭 보여줘야 해. 이런 경우는 aggregation 데이터라고 하지 않고 service 데이터라고 하는 게 조금 더 맞는 표현
- 분석가, BM 들이 주로 활용.
- e.g. DAU, MAU, cost per user.
- 서비스에 직접 활용되지 않는다.
1.3 서비스 데이터 요구사항
중견기업은 이런 요구사항이 있을 법 해! 해서 뽑은 거니까 절대적인 건 아니고 이 이후에 어떤 아키텍쳐, 어떤 기능들을 선택할 건지에 대한 근거로 하기 위한 임의의 요구사항.
1.3.1 서비스용 데이터 시스템 요구사항
- 100TB 이상(1PB 미만)의 데이터에 대해서 실시간 CRUD 작업을 하고 싶다.
- 데이터의 유실이 없어야 한다.
- 시스템은 HA가 가능해야 한다.
- 데이터는 실시간으로 활용한다. (방금 넣은 거 바로 조회 가능)
- 최신의 데이터에 대한 C,R 의 비율이 많다.
- 정렬된 데이터로 조회가 가능해야 한다.
- 최대 3년 보관 가능해야 한다.
1.4 로그 데이터 요구사항
1.4.1 시스템 요구사항
- 각 부서, 서비스, 서버에서 다양한 포맷으로 로그를 남긴다.
- 여러 형식으로 남는 로그 데이터에 대해서 time series 로 저장되고 검색할 수 있는 시스템이 필요하다.
- 로그에 대한 수집, 파싱등은 각 개발 컴포넌트 담당자가 한다.
- 로그 시스템은 일정기간 동안의 데이터에 대해 빠른 검색을 제공해야한다.
- 로그의 일부분으로도 검색이 가능해야 한다.
- 로그 레벨의 심각도에 따라 Alert 가 가능해야 한다.
- 로그에서 민감정보는 감출 수 있어야 한다.
- 검색을 자주(서비스 수준으로) 하지는 않는다.
1.4.2 User 요구사항
- 실시간 로그를 시각화로 확인할 수 있으면 좋다. (그래프 추이 등)
- 추가 개발 없이 로그 검색이 가능해야 한다.
1.5 집계, 분석 데이터
1.5.1 시스템 요구사항
- Arithmetic 연산이 가능해야 한다.
- 평균, 분산, 표준편차와 같은 연산이 (쉽게) 가능해야 한다.
- 일정 기간별로 집계가 가능해야 한다.
- 실시간 계산 또한 가능해야 한다.
- vector, geo, linear regression 등의 advanced 연산도 가능하면 좋다.
1.5.2 User 요구사항 (+분석가, BM 등의 비전문가)
- (SQL, DSL, UI 등으로) 정식 집계가 아닌 ad-hoc query 를 할 수 있어야 한다.
- 전문적인 프로그래밍 language 를 모르고도 사용할 수 있어야 한다. (SQL, DSL 등 학습비용이 적은 언어 도구는 가능)
- Excel, Tableau 등의 분석도구랑 연동이 되어야 한다.
- 연산 규칙을 저장할 수 있고 반복 가능해야한다.
위에 있는 요구사항들을 토대로 구성을 한다고 하면, 어떤 시스템이 필요할지, 지금까지 배운 기술 스텍이랑 각 기술 별 특장점들 이런 거 생각했을 때 이런 시스템을 구현하려면 어떤 기술 스택을 어떤 아키텍쳐로 또 어떤 식으로 구성을 해서 제공을할 것인지 미리 아키텍쳐를 짜 보자.
2 Opensearch 로 중견 기업 규모의 데이터 인프라 구성하기
2.1 Architecture
- 리전을 나눠서 구성하는 것은 상식적이기 때문에 아키텍쳐에는 포함하지 않았다.
2.1.1 All-in-one Architecture
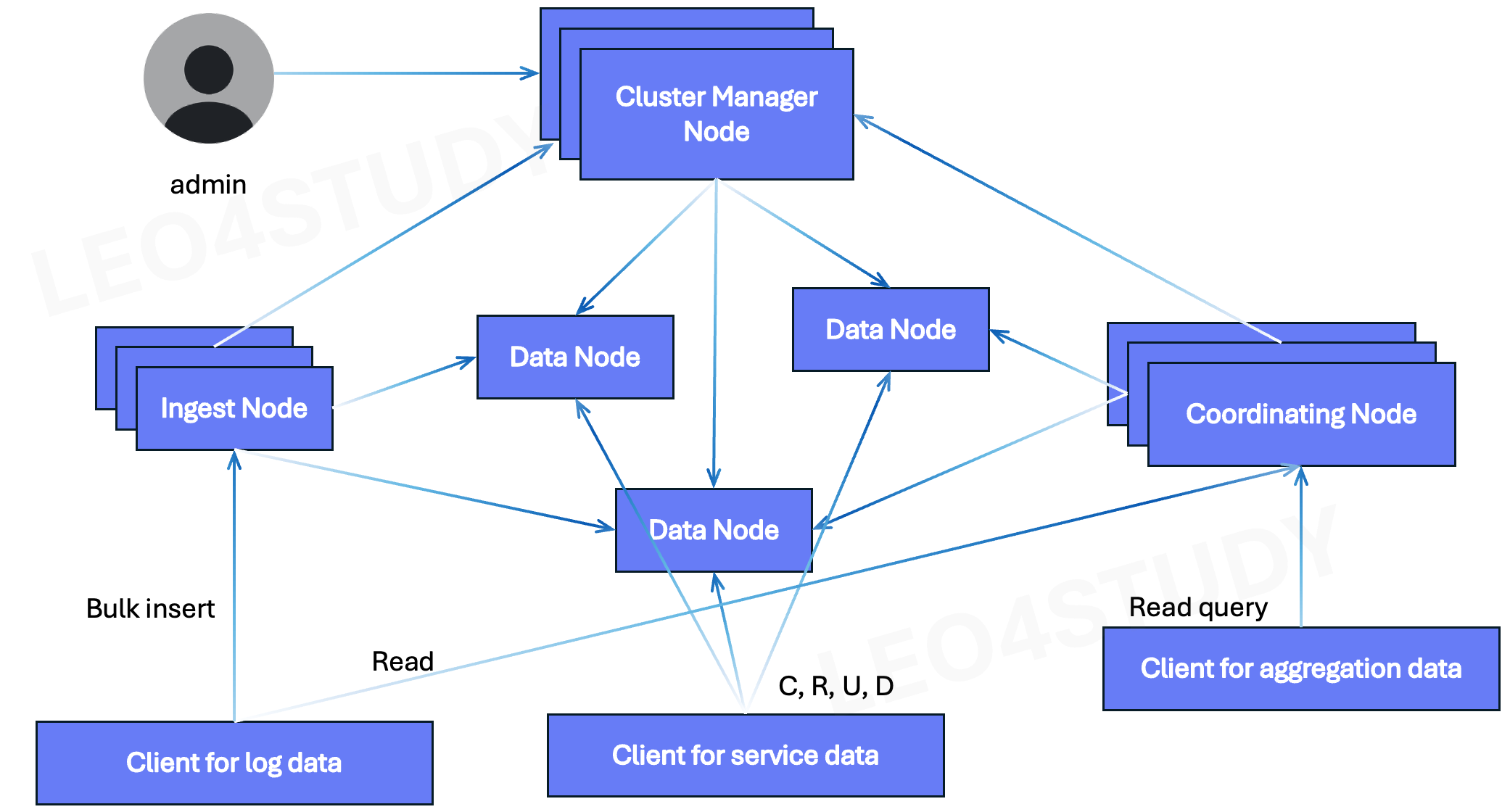
Opensearch 클러스터 하나로 모든 요구사항을 다 담는 구성이다. 데이터가 많지 않고, client가 많지 않을 때 선택할 수 있다.
우리가 서비스가 성장하고 있고, 로그 데이터, 서비스 데이터, 어그리게이션 데이터 다 필요한데, 데이터 양은 수 페타까지 아니면 수백 테라바이트까지 이렇게 막 많지 않아. 수 테라바이트 아니면 수십 테라바이트 정도라면 이 구성으로도 사용할 수 있다.
OpenSearch All-in-One 아키텍처는 로그 데이터, 서비스 데이터, 어그리게이션(집계) 데이터를 단일 클러스터에서 통합적으로 운영할 수 있도록 구성되어 있다.
먼저, **클러스터 안정성과 고가용성(HA)**을 보장하기 위해 복수의 Manager Node를 구성하며, 이 중 하나가 **선출(eligible)**되어 클러스터의 상태를 관리한다. 나머지 Manager Node들은 대기 상태로 있다가 장애 상황에서 자동으로 전환되어 HA를 가능하게 한다.
**데이터 노드(Data Node)**는 클라이언트 애플리케이션이 CRUD 작업을 수행하는 주체로, 특히 서비스용 데이터를 저장하고 제공하는 역할을 한다. 실제로 데이터 노드에는 복수의 샤드(Shard)가 존재하며, 각 샤드는 분산 저장된 데이터 조각을 의미한다.
로그 데이터의 경우, 주로 대량 적재 후 간헐적으로 조회되는 특성이 있다. 이러한 로그는 보통 Bulk Insert 방식으로 적재되며, 이 과정은 Ingest Node를 통해 수행된다. 클라이언트는 직접 데이터 노드에 접근하지 않고, Ingest Node를 통해 데이터를 수집하며, Ingest Node는 필요한 파싱이나 변환 후 데이터를 Data Node에 전달한다.
반면, 조회 작업은 Coordinator Node를 통해 수행된다. 특히 로그 데이터에 대해 통계나 집계 작업이 필요할 경우, 클라이언트는 Coordinator Node에 질의를 보내고, 이 노드는 분산된 샤드에 쿼리를 전파하여 데이터를 수집한 뒤 최종 집계 및 결과 병합을 자체적으로 수행한다. 이 구조를 통해 Coordinator Node가 CPU와 메모리를 활용하여 집계 부하를 흡수하고, 데이터 노드에는 최소한의 로드만 전달되도록 한다.
이는 서비스 데이터의 안정성을 확보하기 위한 전략이기도 하다. 서비스 데이터는 실시간 트랜잭션이 많고 중요도가 높기 때문에, 로그나 집계 데이터의 조회 요청이 데이터 노드 자원(CPU, 메모리)을 과도하게 점유할 경우, 서비스 성능 저하가 발생할 수 있다. 따라서, Coordinator Node와 Ingest Node를 명확히 분리하여, 자원 간섭을 최소화하는 구조로 설계하였다.Ingest Node에서 Data Node와 Manager Node로의 흐름 정리
Aggregation & Log Data의 Read 경로: Coordinator Node를 통하는 이유
2.1.2 Purpose-of-use Architecture
위에 있는 구조에서 용도 별로, 데이터의 성격 별로 쪼갠 것.
1. Service Cluster
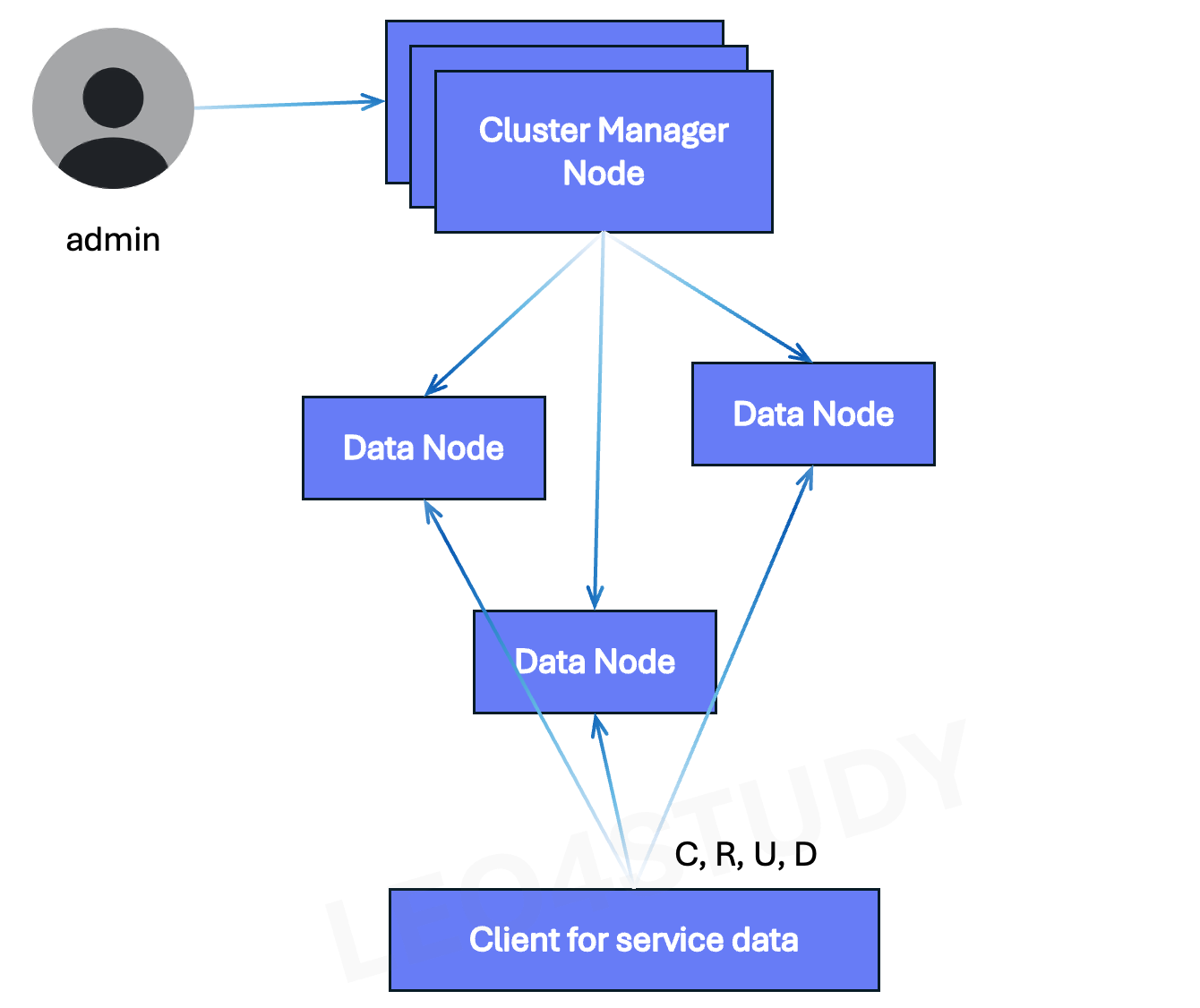
서비스용 클러스터는 실제로 데이터 노드로만 구성되어 있고, 클라이언트는 데이터 노드에 붙는다.
2. Log Cluster
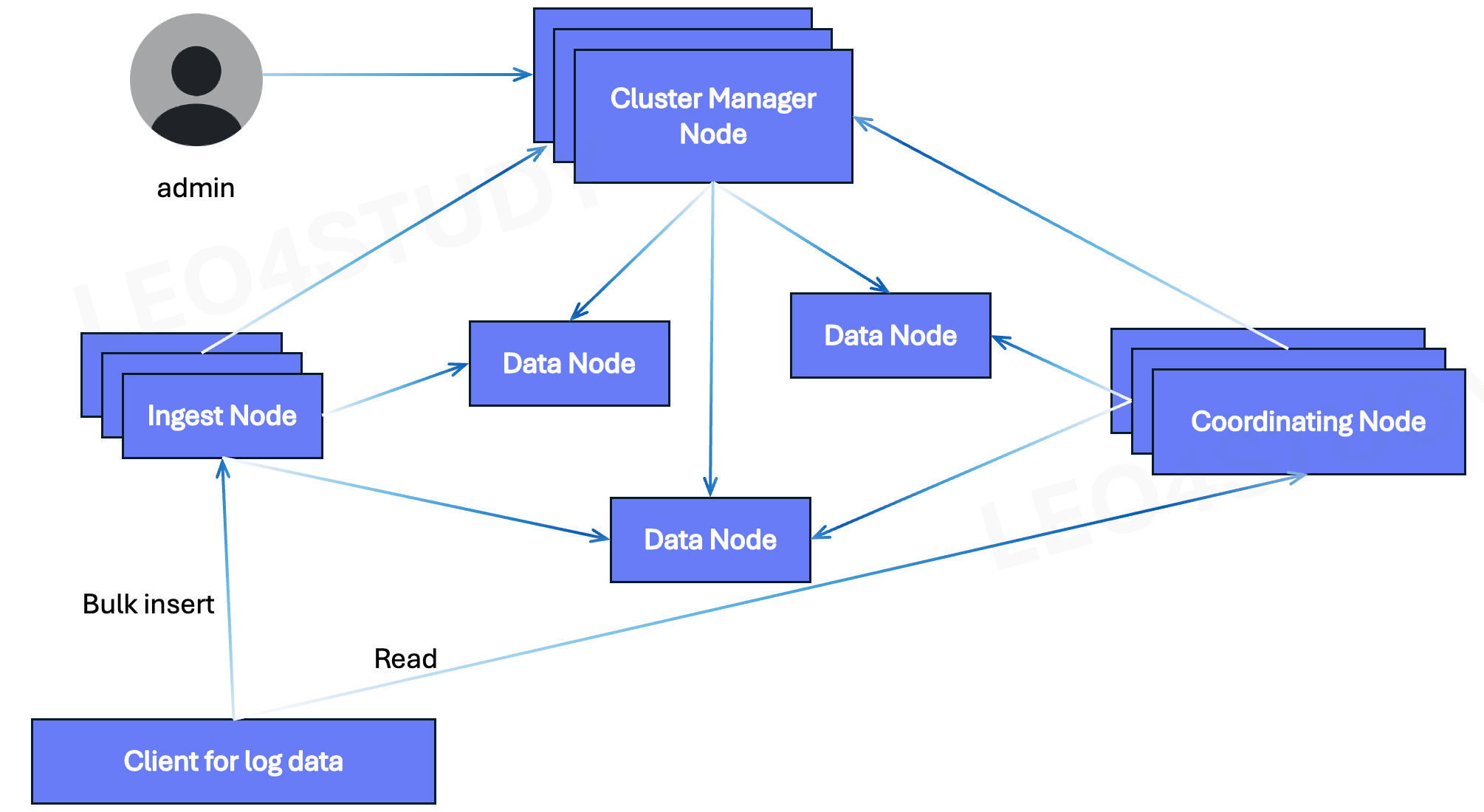
로그 클러스터는 인제스트 노드랑 코디네이팅 노드를 준비한 다음 로그 데이터에 대한 클라이언트는 insert는 인제스트에, read는 코디네이팅에.
그래서 인제스트, 코디네이팅에서 데이터를 데이터 노드에 적재하고 조회할 수 있도록 한 클러스터.
3. Aggregation Cluster
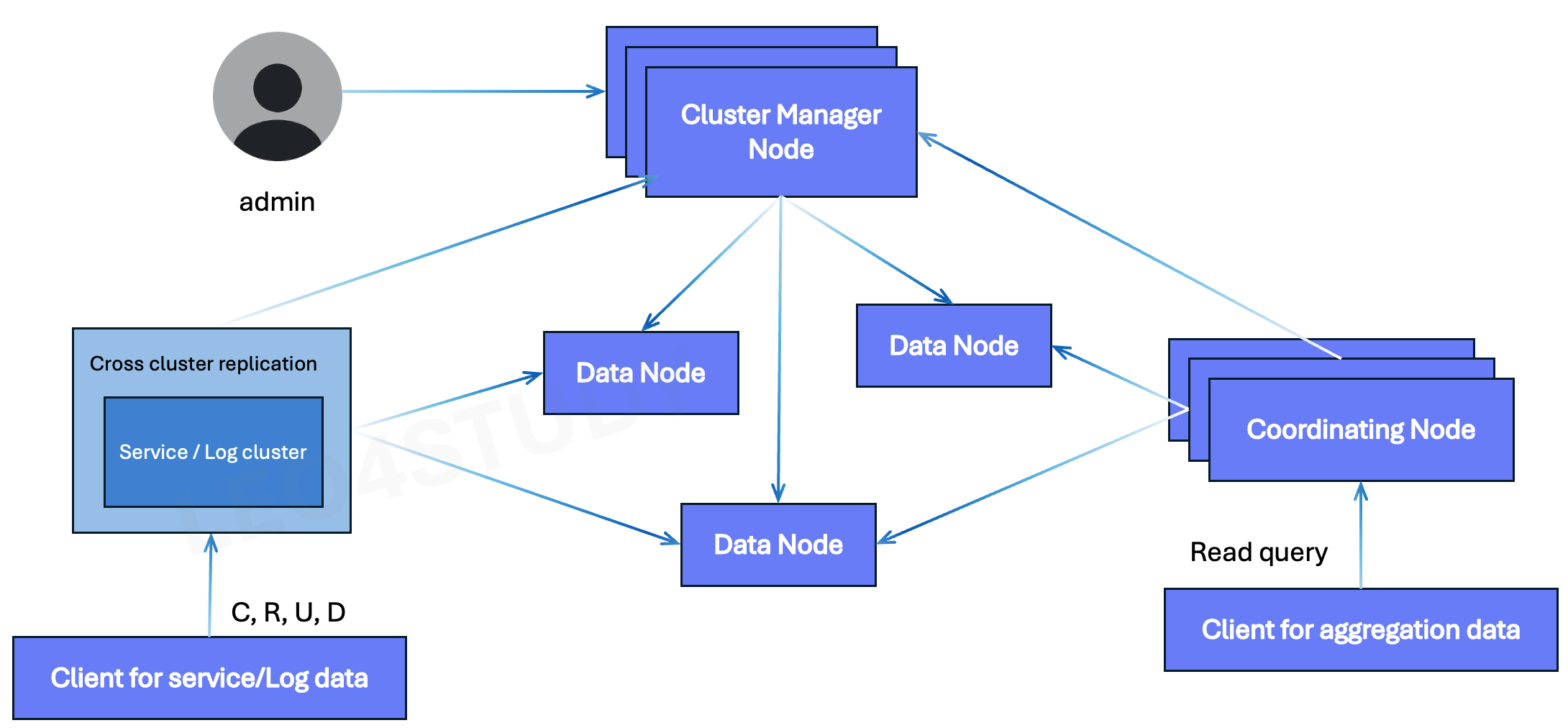
어그리게이션 클러스터의 아키텍처는 다양한 방식으로 구성할 수 있으나, 이 중 가장 이상적인 방식은 서비스 클러스터 또는 로그 클러스터와 분리된 전용 클러스터를 구성하는 것이다.
어그리게이션 클러스터의 관점에서 보면, 서비스 클러스터나 로그 클러스터에 저장된 데이터는 원본(raw) 데이터이며, 이를 기반으로 집계를 수행해야 한다. 이때 집계 처리는 다음과 같은 두 가지 방식 중 하나로 구성할 수 있다.
1. 서비스/로그 클러스터에서 직접 집계를 수행한 후, 결과 데이터를 어그리게이션 클러스터로 마이크로 단위로 가져오는 방식
2. 집계용 전용 클러스터를 별도로 구성하여, 원본 클러스터의 데이터를 직접 복제해온 후 자체적으로 집계를 수행하는 방식
후자의 경우에는 Cross-Cluster Replication (CCR) 기능을 활용할 수 있다. CCR은 서로 다른 매니저 노드를 가진 독립된 클러스터 간에 인덱스를 자동 복제할 수 있도록 해주는 기능이다. 이를 통해 원본인 서비스/로그 클러스터의 데이터를 어그리게이션 클러스터의 데이터 노드로 복제할 수 있으며, 이는 별도의 플러그인 설정을 통해 구현된다.
이와 같은 아키텍처를 사용하는 이유는, 집계 과정에서 발생하는 높은 부하가 원본 클러스터에 영향을 미치지 않도록 격리할 수 있기 때문이다. 실제 집계는 어그리게이션 클러스터의 Coordinator Node를 통해 로컬 데이터 노드에서만 수행되며, 이로 인해 서비스 클러스터나 로그 클러스터에는 추가적인 로드가 전파되지 않는다.
따라서 집계 성능을 높이면서도 원본 데이터를 보호할 수 있는 장점이 있으며, 이러한 이유로 본 아키텍처에서는 Cross-Cluster Replication 기반의 분리형 구조를 채택하였다.위의 All-in-one 과 유사하지만, 용도별로 클러스터를 구분한 것이다. 3가지 모두 구분하지 않더라도, 최소한 서비스 데이터는 별도의 클러스터로 분리하는 것이 안정적인 운영(지속적인 SLA달성)에 좋다.
SLA란?
SLA (Service Level Agreement) 는
서비스 제공자와 고객(또는 내부 조직) 간에 합의된 서비스 품질 기준을 의미한다.
SLA 항목 예시
항목 설명 예시 가용성(Availability) 시스템이 정상 작동하는 비율 99.9% → 월 43분 이상 다운되면 위반 응답 시간(Response Time) 사용자 요청에 대한 응답 속도 1초 이내 응답 처리량(Throughput) 단위 시간당 처리 건수 초당 1,000건 이상 처리 배치 완료 시간 ETL 파이프라인 완료 시점 매일 오전 6시까지 데이터 적재 완료 에러율 실패율 API 호출 중 1% 미만 오류
2.2 기술 스택 선택의 이유
Opensearch가 여러가지 용도에 대해서 사용성이 좋다.
- rest되고, 클라이언트 라이브러리가 언어 별로 있다.
- 사용성이 좋다 : 하나 설치만으로 (C,R,U,D), aggregation, advanced ML, anomaly detection, alert, scheduling 등등의 기능들 사용할 수 있다.
성능도 일정 수준까지는 잘 나온다.(수 PB까지)
- 샤딩, replication을 통한 안정성도 확보. HA.
여기에 더해 사용용도를 구분해서 인프라를 구축하고 제대로 사용한다면 안전하고 더 빠르고 더 쉽게 사용할 수 있는 시스템으로 만들 수 있다.
물론, 각 용도별 최적화할 수 있는 기술을 별도로 선택하는 것도 좋다.
- 메타데이터는 RDB 해야지~ 왜냐면 트렌젝션 해야되니까. eventually consistancy 나 사용할 수 있지 주문정보같은 중요한 건 락 걸어야되는 건 RDB 써야지. 어떻게 이걸 분산 DB로 써. 그리고 커넥션 맺고 있을 때 얘 응답시간 잘 나와? RDB는 그래도 튜닝 잘 하면 5MS도 나올 텐데, 엘라스틱서치 빨리 나오는 것도 있는데 조회시간이 튈 때 많던데? 50ms까지 느려지던데? 이렇게 생각할 수도 있음.
다만, 이 경우 시스템의 복잡도와 운영비용이 크게 증가한다.
- 우선은 오픈서치 하나 구축하는것 만 해도 마스터 세 대, 데이터 세 대 총 최소 6대가 필요하다. 여기에 인제스트에 코디네이팅까지 한다면 더 많아지는데. 이 비용이 다른 데이터베이스까지 관리한다? 스케줄러나 워크플로우까지 관리한다.? 엄청 복잡도가 커진다.
만약 한 팀이 전사수준의 데이터 인프라를 모두 구축한다면 기술스택이 단순한 대신, 최적화와 고도화를 통해 요구사항을 만족시킬 수도 있다.
페타바이트를 넘지 않는 데이터 사이즈의 경우 Opensearch 하나로도 전사수준에서 데이터 활용에 대한 상당부분의 요구사항을 만족시킬 수 있을 것으로 예상한다.
- 물론 오픈서치가 페타바이트를 못 한다는 게 아니고. 엘라스틱 서치는 상업용이다. 거기서 발표하는 벤치마크나 자료들을 보면 보통 수십 페타까지 된다. 근데 이런 여러가지 용도에 대해서 실시간으로 안정적인 성능을 내면서도 여러가지 기능을 다 사용할 수 있다는 것이 수십페타까지 될까? 는 검증하기 힘들다고 생각함. 이정도까지만 돼도 스트레스를 받더라도 복잡도가 높아지더라도 다른 시스템으로 넘어가는 게. 결국 높은 수준의 요구사항을 만족시킬 수 있을 것 같아서 페타파이트를 넘지 않는다면 이라는 가정을 둔 것.
2.3 서비스 데이터
ex. 유저정보, 주문 정보 등.
2.3.1 데이터의 특징
- 집계는 거의 사용되지 않는다.
- 데이터의 생성 또는 업데이트가 개별 document 단위로 이루어진다.
- consistency, HA가 중요하다.
- latencyrk 낮을 수록 좋다.!
2.3.2 클러스터 구성
-
hot → warm → cold 도 가능하지만, 서비스 특징에 따라 hot → cold 도 고려할만함.
-
예를 들어, 대부분의 유저 정보는 실시간으로 조회되므로 hot 상태에 존재해야 한다. 하지만 1년 이상 장기 미접속한 계정은 cold 영역으로 이동하여 저장 비용을 절감할 수 있다.
-
Hot 데이터의 비중이 높을 경우, 용량 관리와 샤드 모니터링이 중요해지므로 클러스터의 상태를 정기적으로 점검해야 한다.
-
-
특별한 요구사항이 아니면 data node에 직접 CRUD 를 하도록 한다.
-
서비스 데이터는 대부분 단건 단위로 처리되며, 응답 시간이 중요한 특성을 가진다. 이 경우, Ingest Node를 거치게 되면 전처리 지연과 네트워크 홉 증가로 인해 latency가 증가할 수 있다.
-
Ingest Node는 대량의 Bulk Insert나 검색용 전처리가 필요한 경우에만 사용하는 것이 효과적이다.
-
마찬가지로, 조회 요청(SELECT) 역시 Coordinator Node를 거치면 다른 노드에서 가져온 결과를 집계하는 과정에서 추가 CPU와 메모리 리소스를 사용하게 되므로, 집계 연산이 불필요한 단순 READ의 경우 Data Node에 직접 접근하는 것이 latency를 줄이는 데 유리하다.
-
-
각 노드의 Disk 사이즈는 일정 수준을 유지하고, 데이터 노드의 수를 늘린다.
-
클라이언트에서 Data Node에 직접 CRUD 요청을 보내는 구조이므로, 연결 수요가 높아질 수 있다.
-
이때 하나의 노드에 리소스를 집중하는 방식(Scale-Up)보다는, 다수의 Data Node로 분산하는 방식(Scale-Out)이 안정성과 확장성 측면에서 유리하다.
-
또한 샤드 분산 및 부하 분산을 고려할 때에도, 균형 잡힌 디스크 사이즈와 충분한 수의 데이터 노드 확보가 클러스터 운영의 핵심이다.
-
| 항목 | 권장 접근 방식 | 이유 |
|---|---|---|
| 장기 미사용 유저 데이터 | Cold 노드로 이동 | 저장 비용 절감 |
| 실시간 CRUD (서비스 데이터) | Data Node 직접 접근 | 응답 시간 최소화 |
| Bulk Insert + 전처리 필요 시 | Ingest Node 사용 | 파싱, 변환 처리 효율화 |
| 단순 READ 요청 | Data Node 직접 접근 | Coordinator Node의 집계 부하 방지 |
| 클러스터 확장 | 스케일 아웃 | 연결 수요 대응 및 샤드 분산 |
2.3.3 Index 관리
1. Life cycle
- event 성격의 데이터 또는 TTL 성격의 데이터(예: 주문 정보)는 Timeline 기반의 lifecycle을 갖는다.
- 반면, 지속적으로 보관이 필요한 메타데이터(예: 사용자 정보, 설정값)는 단일 인덱스 테이블로 관리된다.
- 단일 인덱스가 너무 커질 경우, 특정 필드 기준으로 샤딩(sharding) 하여 분리할 수 있다.
이 경우, 클라이언트가 데이터가 저장된 위치를 판단하는 추가 로직이 필요하다. - 예시
- Hash 기반 샤딩
- user_id % 4 → user_bucket_0 ~ user_bucket_3 에 저장
- 클라이언트는 조회 시 user_id를 기준으로 버킷을 계산해야 함
- 카테고리 기반 샤딩
- 나이대 구간 → user_2029, user_3039, user_4049 등
- 클라이언트는 나이에 따라 테이블을 선택해야 함
- Hash 기반 샤딩
Timeline 기반(
yyyymmdd)의 라이프사이클을 갖는다
2. 샤드 구성
- 샤드 수를 충분히 늘려 데이터 분산을 극대화한다.
- 데이터는 주로 Create / Read 위주이며, 집계(Aggregation)는 거의 사용하지 않으므로, 분산에 따른 불이익이 적다.
- 분산도가 높을수록:
- 데이터 저장이 고르게 분산되고,
- 클라이언트 요청 부하도 균등하게 분산된다
샫가 나눠져있을 때의 단점은 많이 모아야 한다. 그래서 샤드의 수가 많아지면 집계에 불리한 건데. 집계할 게 아니니까.
3. Replica
- replica 를 5 이상으로 넉넉히 둔다. (3도 부족해)
- 메타데이터는 중요도가 높고, 유실 시 복구가 어려우므로, 장애 대비가 반드시 필요하다.
2.3.4 Client
- Client 의 RPS(request/sec)가 일정하다면, connection을 유지하는 것이 네트워크 부하 감소에 좋다.
- 단 특정 노드에 connection 수가 편중되어서 많이 몰린다면, 해당 노드의 network 부하로 해당 노드에 위치한 샤드에 대한 성능이 안좋아지거나 클러스터 전체의 상태가 안좋아질 수 있다. (샤드 상태가 뭐 not green으로 판단되면 다른 애한테 복제 띄우려고 하다가 다시 복구돼. 이런 식으로 일시적으로 샤드가 필요한 것 보다 리플리카가 많아지고. 디스크도 많이 차지하게 된다)
- 따라서 socket 또는 fd 모니터링을 필수로 해야한다.
- 단일 client instance 에서 다수의 connection 을 맺지 않도록 한다.
- 지금은 권장하지 않지만 로우레벨 클라이언트로 쓰는 것도 한 가지 방법.
- 단 특정 노드에 connection 수가 편중되어서 많이 몰린다면, 해당 노드의 network 부하로 해당 노드에 위치한 샤드에 대한 성능이 안좋아지거나 클러스터 전체의 상태가 안좋아질 수 있다. (샤드 상태가 뭐 not green으로 판단되면 다른 애한테 복제 띄우려고 하다가 다시 복구돼. 이런 식으로 일시적으로 샤드가 필요한 것 보다 리플리카가 많아지고. 디스크도 많이 차지하게 된다)
- 1이 아니라면, http 로 단건 요청을 하는 것이 좋다.
- Transaction 이 없으므로, 실시간의 consistency 요건에 대해서 다음과 같은 조치가 필요할 수 있다.
- SLA 수준을 낮춘다.
- 데이터 반영 즉시 > 1초 이내
- 서비스 스펙을 변경한다.
- 1~2초 정도는 실패할 수 있는데 다시하면 될 겁니다
- 운영으로 푼다.
- user > server(오픈서치 입장에서 client) > 오픈서치
- 유저 요청을 서버에서 put하고 잘 됐는지 폴링. 됐으면 그 때 user에 응답
- SLA 수준을 낮춘다.
Client 의 RPS(request/sec)가 일정하다면 예를 들어 0으로 떨어지는 게 거의 없고, 피크 시간이 아니더라도, 새벽시간이라도 꾸준히, 피크시간 대비 30% 정도가 나온다면 connection을 유지하는 것이 네트워크 부하 감소에 좋다
우선 지금 오픈서치의 하이레벨 클라이언트의 기본은 커넥션을 유지하는 게 아니라 단 건 요청이다. 하면 HTTP 커넥션을 끊어버리는.
로우레벨 클라이언트(TCP), 하이레벨 클라이언트(HTTP)
2.4 로그 파이프라인
2.4.1 데이터의 특징
- (서비스처럼) 실시간으로 필요하지 않다.
- eventually consistency 로 충분하다.
- 개별 로그사이의 연관성이 (저장시점에는) 없다.
- time-series 데이터이다.
- 로그가 발생하는 시스템/서버가 여러 곳에 분산되어 있다.(server, sdk 등)
- 로그의 형식과 내용이 다양하고, 서비스별로 커스터마이징되어 있다.
- 간헐적인 조회와 집계에 주로 활용된다
- 정기적이고 규칙적인 집계 작업(예: 일별 집계, 주간 리포트 등)이 수행된다.
- 데이터의 중요도/심각도 정보가 있다.
참고
로그 데이터는 본질적으로 대용량, 분산, 비정형성, 시간이 중요한 특성을 갖기 때문에, 데이터 수집, 저장, 조회 모두에 특화된 구조와 운영 정책이 필요하다.
개별 로그 사이의 연관성이 (저장시점에) 없다?
- 각 로그 한 건 한 건이 저장될 때, 그 로그가 이전이나 이후의 다른 로그들과 직접적인 관계를 갖지 않는다는 의미.
- 로그는 독립적으로 생성되고 저장되고,
이전에 저장된 로그를 참고하거나 의존하지 않는다는 뜻.
2.4.2 클러스터 구성
-
모든 데이터가 time-series 이므로 hot-warm-cold 로 운영
- 서비스에서 실시간 활용을 위한 로그가 아닌, 모니터링, 장애 탐지를 위한 로그라면 hot 없이 warm - cold 로만 운영해서 유지 비용을 더욱 낮출 수도 있다.
- 여기서 말하는 warm-cold는 OpenSearch에서 노드에 직접 warm/cold 마크를 설정한다는 의미가 아니라, 상대적으로 저렴한 자원(HDD를 사용하는 노드나, 2~3년 이상 된 노드 등)을 의미론적으로 warm 또는 cold 노드로 간주한다는 뜻이다.
- 서비스에서 실시간 활용을 위한 로그가 아닌, 모니터링, 장애 탐지를 위한 로그라면 hot 없이 warm - cold 로만 운영해서 유지 비용을 더욱 낮출 수도 있다.
-
2.4.4처럼 자동화된 로그 수집 파이프라인 있다면, 수집에 load 가 크므로 ingest 노드를 다수 운영하는 것이 좋음.- 대량의 insert에 대해서 data-node 만 이용할시, data-node 의 부하증가로 client 의 요청이 지연/병목이 되거나, 다른 쿼리(특히 aggregation)에 영향을 줄 수 있다.
2.4.3 Index 관리
-
dynamic mapping을 적용한다.
- 데이터 용량만 잘 관리하면 매우 효율적인 설정이다. (기본적으로 너무 편하다)
- 해당 인덱스는 간헐적으로 조회되기 때문에, 텍스트나 키워드 필드가 다소 많은 저장 공간을 차지하더라도 용량 최적화보다는 필요한 시점에 데이터를 조회할 수 있는 유연성이 더 중요하다.
- 자동화된 파이프라인 ops 환경을 구축한다면, text/keyword 구분을 할 수 있다면 더욱 좋다. (하지만 필수는 아니다)
- 데이터 용량만 잘 관리하면 매우 효율적인 설정이다. (기본적으로 너무 편하다)
-
index pattern 을 time-series 에 맞게 적용한다.
- 예: my-service-log-YYYY.MM.dd
-
TTL 기반의 lifecycle 을 적용한다.
- 예: 7일 후 warm, 30일 후 remove
- 이건 데이터 사이즈마다 다를 수 있다
- 예: 7일 후 warm, 30일 후 remove
-
@timestamp는 중요하므로 사용하는 쪽에서 지정할 수 있도록 한다.
-
shard
- 로그로부터 집계가 필요하다면, shard의 수를 과하게 쪼개지 않도록 한다.
- (서비스의 기능과 상관이 있다던지 해서) 집계에서 계속 사용되는 로그라면 과하게 쪼개지 않도록 하고
- 에러로그 같은 건 샤드 수를 쪼개서 라이프 사이클만 잘 관리하면 된다.
- hot-warm-cold transition을 생각한다면, shard의 크기가 너무 크다면 transition 수행시 노드의 부하가 크다.
- 과하게 쪼개지 말라고 했지, 크게 만들라곤 안 했다
- transition 할 때 로드가 크다. 샤드가 크면 전환할 때 노드 부하가 큼.
- 타임라인 기준으로 하면 특정 시간에 몰려서 전체 부하가 커짐
- 로그로부터 집계가 필요하다면, shard의 수를 과하게 쪼개지 않도록 한다.
-
replica
- 유실에 민감한 event 데이터라면, replica 를 5 이상으로 둔다.
- 그 외 단순 time-series log 라면 replica 를 2 또는 3으로 낮은 수준으로 둔다.
2.4.4 Client
-
Client 는 필수로 무조건 bulk API를 사용해서 데이터를 넣는다.
- 이거 안 하면 엄청 부하가 큼. 건 수가 많은데 bulk api 안 쓰면 소켓을 많이 쓴다. 이것 때문에 같은 인스턴스에 컨테이너 이런 환경을 쓴다면 같은 노드에 있는 다른 칱구들에게 큰 영향을 미칠 수 있다.
-
Client 가 insert에 대해 바라보는 주소는 ingest node 의 주소이다.
- 데이터 직접 넣지 않는다.
2.4.5 그 외 시스템
- 전사용 로그 파이프라인이라면, 수집 채널을 일원화 하거나 규칙을 만들어서 관리하면 생산성을 대폭 향상 시키고 잘못된 사용에(벌크 api안 쓰고 등) 의한 장애 상황을 줄일 수 있다.
- 단, 자동화 시스템이 성숙해지기 위한 기간이 필요하다.
- 설치한다고 되는 게 아니라 파라미터 튜닝을 해야 될 수도 있고 인프라 세팅을 다시 해야 할 수도 있고 또는 거기에 추가적인 로직을 개발해야 할 수도 있고.
예
- 설치한다고 되는 게 아니라 파라미터 튜닝을 해야 될 수도 있고 인프라 세팅을 다시 해야 할 수도 있고 또는 거기에 추가적인 로직을 개발해야 할 수도 있고.
- 새로운 로그 수집 요건에 대해 kafka topic 생성과 schema 입력을 git-ops 또는 schema-registry등으로 자동화로 관리.
- user(app 개발자) 는 최초에 topic 생성과 schema 를 지정하면, 그 이후는 로그 전송만 신경쓰면 됨.
- K8S 클러스터에 daemonset 으로 로그 수집 인스턴스를 띄워 놓음.
- 노드의 지정된 path 에 파일이 쓰이면 자동으로 수집
- 단, 자동화 시스템이 성숙해지기 위한 기간이 필요하다.
Kafka는 분산 메시지 큐 시스템으로, 다양한 로그 수집 요구사항에 따라 주제(topic)별 pub-sub 아키텍처를 유연하게 구성할 수 있다. 일반적으로, 앱 개발자(app 개발자)는 Kafka의 퍼블리셔 역할을 수행하며, 로그를 Kafka로 전송한다. 이후 데이터 엔지니어는 Kafka로부터 메시지를 구독(subscription)한 뒤, OpenSearch로 적재하고 조회하는 파이프라인을 구성하게 된다.
Kafka는 논리적인 topic 구조를 활용하여 로그를 주제별로 구분할 수 있어, 수집 시스템 구성에 매우 적합하다. 또한 로그의 데이터 포맷에 따라 다음과 같은 자동화 방식을 적용할 수 있다:
- JSON 기반 로그라면 OpenSearch의 dynamic mapping을 통해 자동 필드 매핑이 가능하다.
- 보다 엄격한 스키마 관리가 필요한 경우, Kafka + Schema Registry 또는 GitOps 기반 schema 자동화 관리를 통해 topic 생성 및 스키마 등록을 자동화할 수 있다.
→ 예: 개발자가 로그 수집 요청 시, GitOps를 통해 topic 및 schema를 PR로 등록하면, 병합(Merge) 이후 자동으로 시스템에 반영됨.
Kubernetes 환경에서는 노드 단위로 로그 수집을 수행하기 위해 DaemonSet을 활용할 수 있다. DaemonSet은 각 노드에 하나씩 로그 수집 에이전트를 배포하며, 로그 수집 경로를 사전에 정의해 둘 수 있다.
일반적인 구성은 다음과 같다:
- 각 노드의 특정 경로(예: /var/log/app 등)에 로그 파일이 기록되면,
- DaemonSet에 의해 설치된 로그 수집 에이전트가 해당 파일을 자동으로 감지 및 수집한다.
- 수집된 로그는 OpenSearch에 적재되며, 개발자는 추가 설정 없이 OpenSearch에서 실시간으로 로그를 조회할 수 있다.
이러한 방식은 개발자에게 로그 전송 책임만 부여하고, 로그 수집 및 저장, 조회 체계는 플랫폼 엔지니어링 팀 또는 데이터 엔지니어가 책임지는 역할 분리 기반 구조에 적합하다.
2.5 통계/분석 데이터
2.5.1 데이터의 특징
- 원본 데이터의 집합을 이용해서 연산을 거쳐 생성된 데이터이다.
- index(table)의 종류가 기하급수적으로 늘어날 수 있다.
- 데이터 양이 어느 정도만 된다면 활용하고 싶어하는 사람들이 급격히 늘어남.
- Mau면 Mau 따로, DAU면 DAU 따로. 이런 식으로 종류 별로 테이블링이 안 되기 때문에
- 검증된 집계 연산은 주기적으로 동작한다.
- 시각화 도구로 조회하는 일도 잦다.
2.5.2 클러스터 구성
-
서비스 데이터를 담고 있는 cluster 에 연산을 요청한다면 부하를 조심해야한다.
- 따라서, 시간 단위(예: 1시간, 1분 등)로 데이터를 쪼개어 분석 클러스터에 저장한 뒤, 해당 클러스터에서 반복적으로 조회 및 분석하는 방식을 추천한다.
- 예를 들어, 원본 데이터를 서비스 클러스터에 저장하고, 이를 기반으로 한 시간 단위의 집계 결과만을 별도 분석 클러스터에 저장하면, 서비스 클러스터의 부하를 최소화할 수 있다.
- 데일리나 먼슬리 집계는 분석 클러스터에서 반복적으로 수행하는 것이 바람직하다.
- 따라서, 시간 단위(예: 1시간, 1분 등)로 데이터를 쪼개어 분석 클러스터에 저장한 뒤, 해당 클러스터에서 반복적으로 조회 및 분석하는 방식을 추천한다.
-
Cross-Cluster Replication(CCR)을 활용해 집계 전용 클러스터에 자동 복제 구성을 적용하면, 서비스 클러스터의 부하를 최소화하면서 분석 활용도를 극대화할 수 있다.
- 원본 클러스터에서 직접 분석 클러스터로 CCR을 구성하면, 원본 데이터, 복제본, 집계 결과가 모두 분석 클러스터에 존재하게 되므로, 자유로운 분석이 가능하다.
- 참고: CCR 매뉴얼
-
집계 연산의 속도가 중요하지 않다면, warm only cluster 로 구축하면 비용을 절감할 수 있다.
-
Coordinating Node의 메모리는 충분히 크게 설정하는 것이 좋다 (대용량 클러스터의 경우 64GB 권장).
- 쿼리(건수) 트래픽, 메모리 사용량, 응답 시간을 모니터링하는 것이 중요하다
- 과도하게 오래 걸리는 쿼리는 자동 감지 후, 쿼리를 분할하여 수행할 수 있도록 가이드하는 정책도 고려할 필요가 있다.
- 쿼리(건수) 트래픽, 메모리 사용량, 응답 시간을 모니터링하는 것이 중요하다
-
모든 조회 쿼리는 반드시 Coordinating Node를 통해 수행해야 한다.
- 직접 데이터 노드에 접근하는 것은 피해야 한다
-
Opensearch Dashboard(KIbana), Tableau 등의 시각화 도구는 Coordinating Node에 연결해야 한다.
2.5.3 Index 관리
-
집계하는 원본 데이터는 aging 이 되더라도, 집계된 데이터는 사이즈가 크지 않으므로 aging하지 않을 수도 있다.(하지 않는 경우도 많다)
- 1시간짜리를 집계해서 도큐먼트 하나로 만든 거니까 도큐먼트 하나가 아무리 사이즈가 커도 수십메가 하지는 않는다.
-
shard 는 사이즈가 클수록 집계에 유리하고 Coordinating node의 부하가 줄어든다.
- 샤드 덩어리가 클 수록 집계 연산 줄어듦
2.5.4 Client
- Client 는 Coordinating node에만 집계 쿼리를 요청해야 한다.
- 반복되는 쿼리는 최적화를 진행하는 것이 좋다.
- Job Scheduler 를 통해서 정기/규칙적인 연산을 cluster 에 등록해서 수행할 수 있다.
- 이 잡스케줄러가 메인 플러그인이 아니기 때문에 기능이 제한적이거나 관리가 잘 되지 않을 수 있다
